LiLT
1.0.0
[2022/10] LILT был добавлен в?
[2022/03] Первоначальный выпуск модели и кода.
Это официальная реализация Pytorch статьи ACL 2022: «LILT: простой, но эффективный язык, независимый от языка, для понимания структурированного документа». [Официальный] [arxiv]
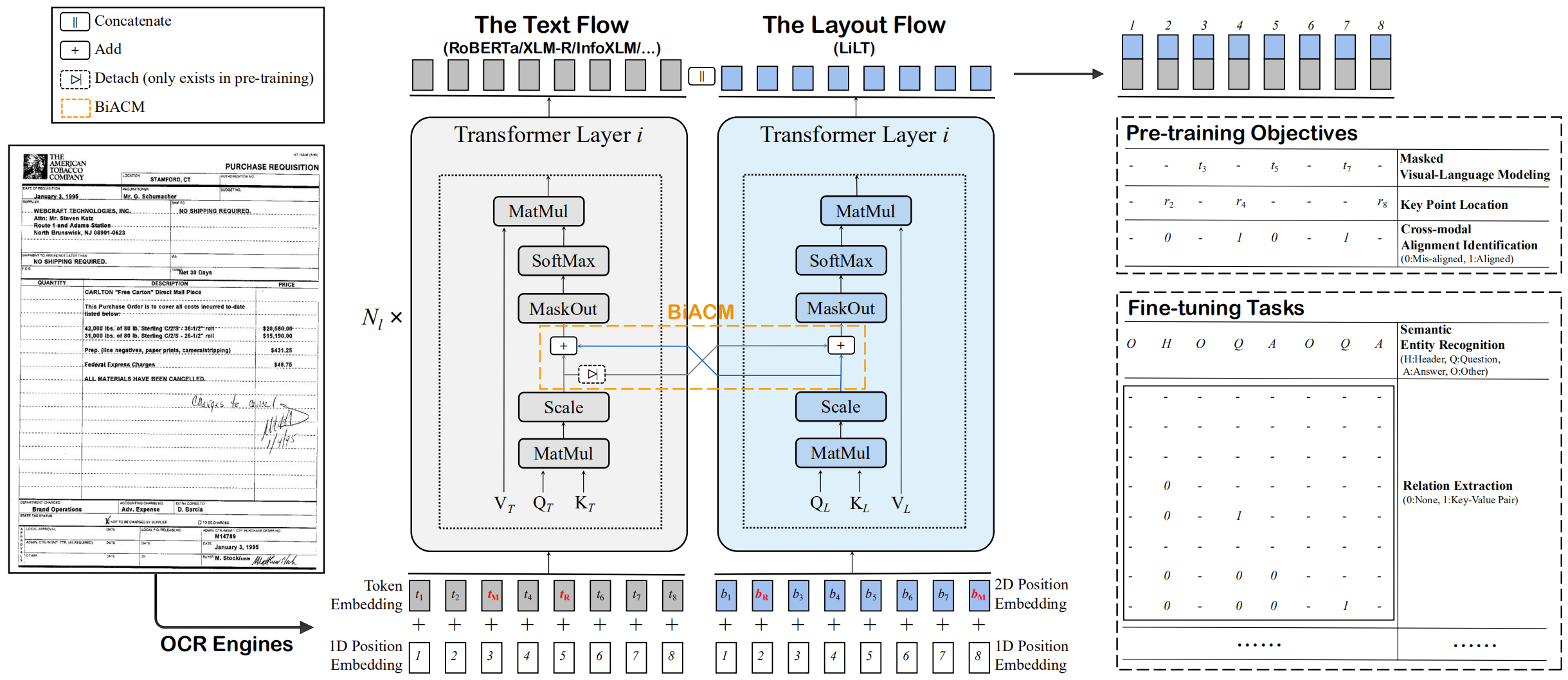
LILT предварительно обучен на богатых визуально документами одного языка (английский) и может быть непосредственно настраивать на других языках с соответствующими готовыми моноязычными/многоязычными предварительно обученными текстовыми моделями. Мы надеемся, что общественная доступность этой работы может помочь документировать исследования разведки.
Для CUDA 11.X:
conda create -n liltfinetune python=3.7
conda activate liltfinetune
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=11.0 -c pytorch
python -m pip install detectron2==0.5 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
git clone https://github.com/jpWang/LiLT
cd LiLT
pip install -r requirements.txt
pip install -e .Или проверьте версии Detectron2/Pytorch и соответственно измените командные строки.
В этом хранилище мы предоставляем коды тонкой настройки для Funsd и Xfund.
Вы можете скачать наши предварительно обработанные данные (~ 1,2 ГБ) отсюда и поместить незамеченные xfund&funsd/ Under LiLT/ .
| Модель | Язык | Размер | Скачать |
|---|---|---|---|
lilt-roberta-en-base | Поступка | 293 МБ | OneDrive |
lilt-infoxlm-base | Мульт | 846 МБ | OneDrive |
lilt-only-base | Никто | 21 МБ | OneDrive |
Если вы хотите объединить предварительно обученный LILT с Roberta на другом языке , пожалуйста, загрузите lilt-only-base и используйте gen_weight_roberta_like.py , чтобы создать собственный предварительно обученный контрольно-пропускной пункт.
Например, комбинируйте lilt-only-base с английской roberta-base :
mkdir roberta-en-base
wget https://huggingface.co/roberta-base/resolve/main/config.json -O roberta-en-base/config.json
wget https://huggingface.co/roberta-base/resolve/main/pytorch_model.bin -O roberta-en-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text roberta-en-base/pytorch_model.bin
--config roberta-en-base/config.json
--out lilt-roberta-en-base Или объединить lilt-only-base с microsoft/infoxlm-base :
mkdir infoxlm-base
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/config.json -O infoxlm-base/config.json
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/pytorch_model.bin -O infoxlm-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text infoxlm-base/pytorch_model.bin
--config infoxlm-base/config.json
--out lilt-infoxlm-base CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_funsd.py
--model_name_or_path lilt-roberta-en-base
--tokenizer_name roberta-base
--output_dir ser_funsd_lilt-roberta-en-base
--do_train
--do_predict
--max_steps 2000
--per_device_train_batch_size 8
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_ser_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 2000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_re_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 5000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_ser_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 16000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_re_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 40000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
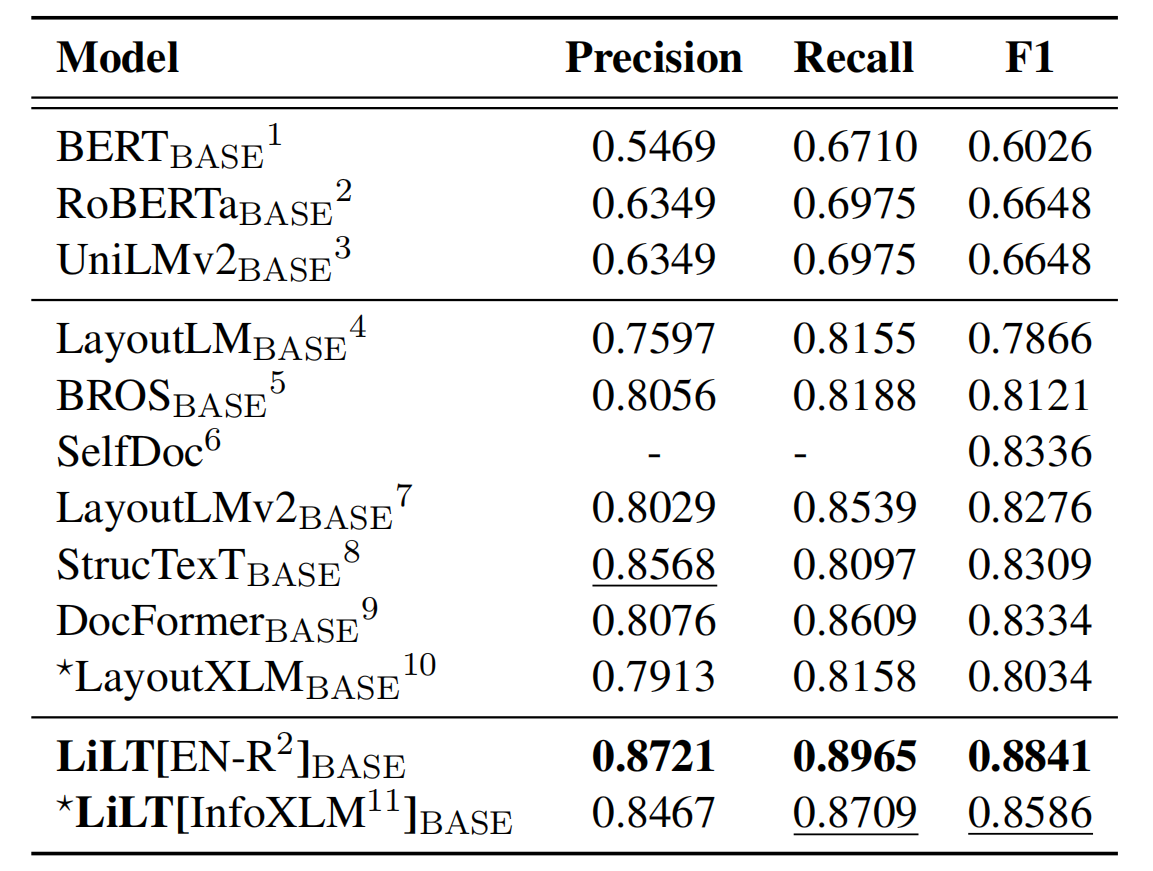
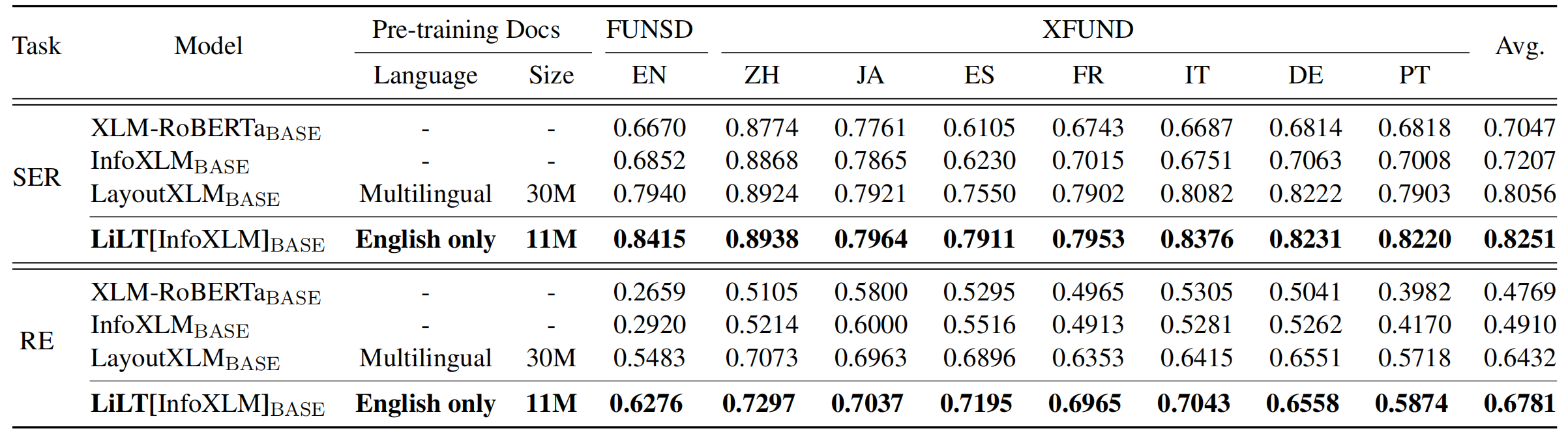
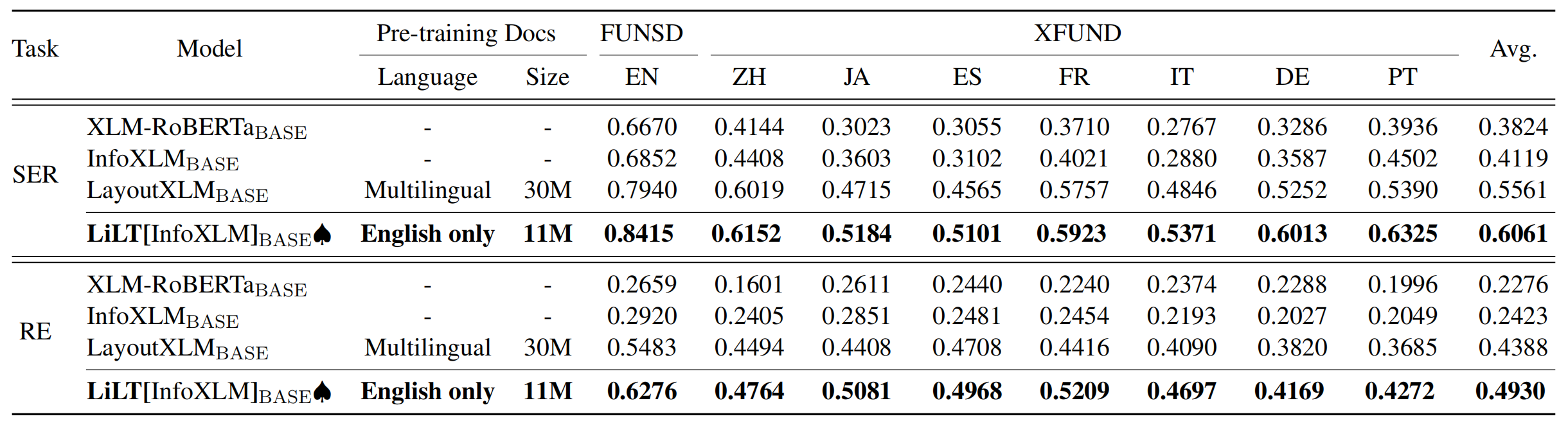
Репозиторий значительно выигрывает от Unilm/Layoutlmft. Большое спасибо за отличную работу.
Если наша статья помогает вашему исследованию, пожалуйста, укажите это в вашей публикации:
@inproceedings{wang-etal-2022-lilt,
title = "{L}i{LT}: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding",
author={Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.534",
doi = "10.18653/v1/2022.acl-long.534",
pages = "7747--7757",
}
Предложения и дискуссии очень приветствуются. Пожалуйста, свяжитесь с авторами, отправив электронное письмо по адресу [email protected] .


