LiLT
1.0.0
[2022/10] Lilt telah ditambahkan ke? Huggingface/Transformers di sini.
[2022/03] Model awal dan rilis kode.
Ini adalah implementasi Pytorch resmi dari makalah ACL 2022: "LILT: Transformator tata letak yang sederhana namun efektif untuk bahasa untuk pemahaman dokumen terstruktur". [Resmi] [Arxiv]
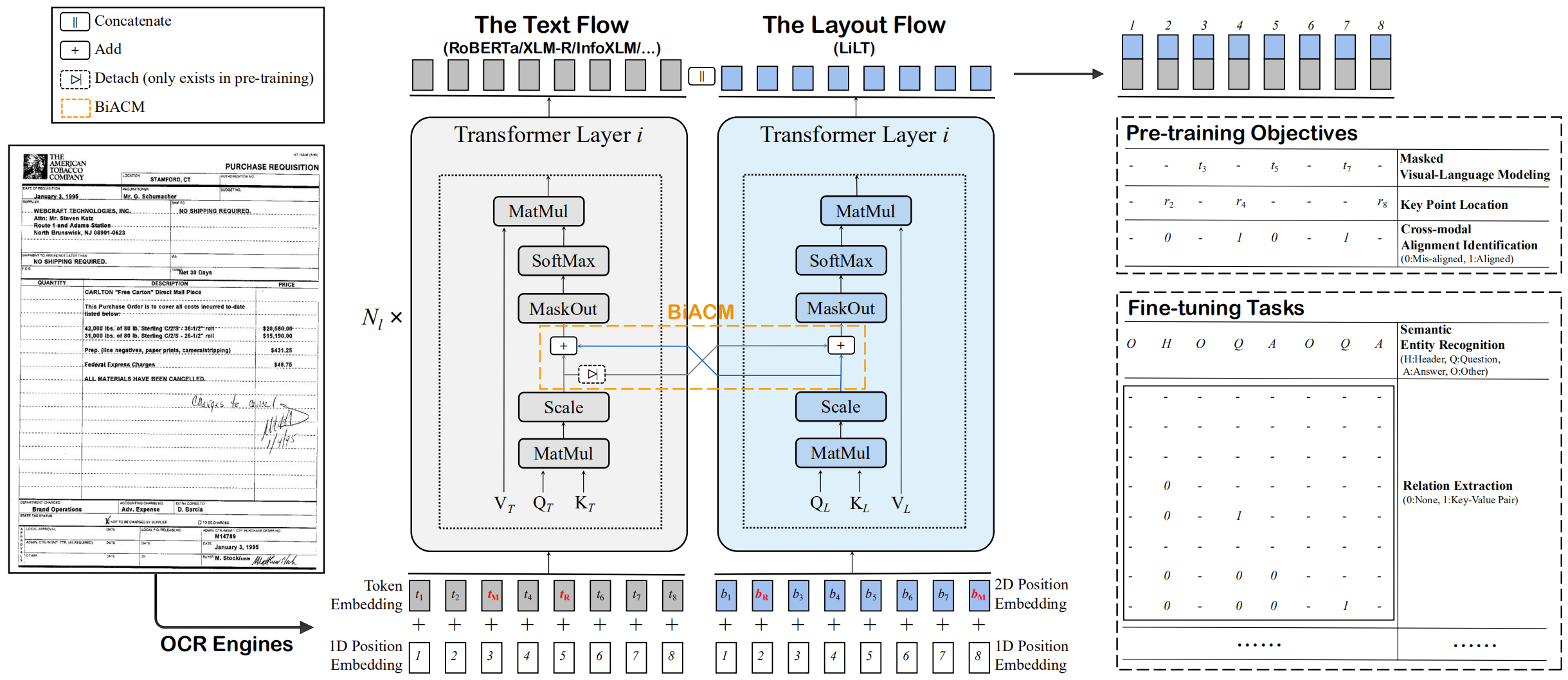
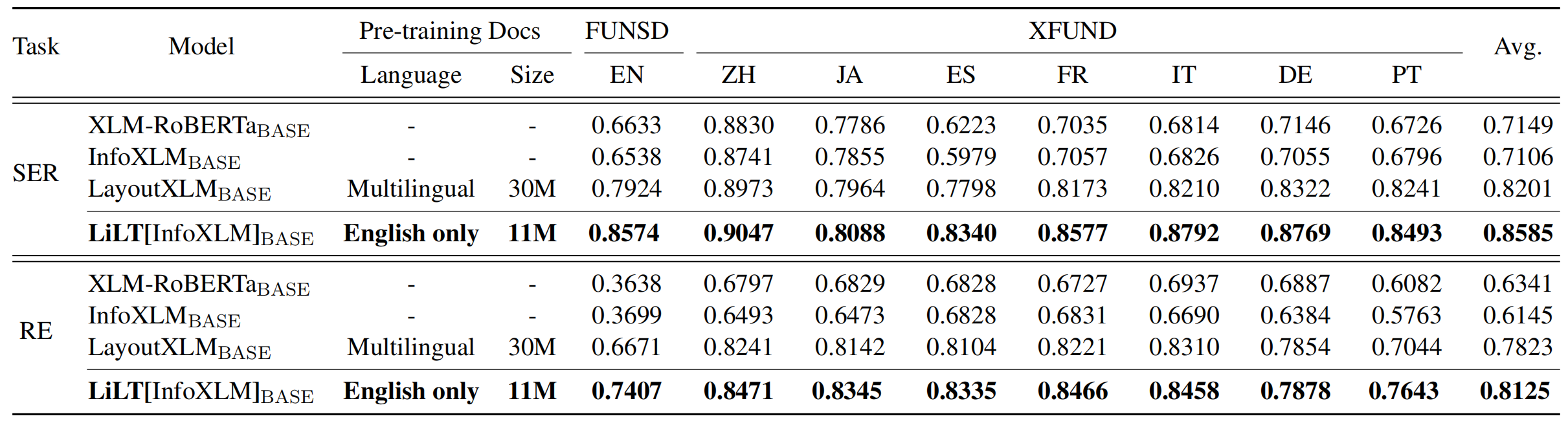
Lilt dilatih sebelumnya pada dokumen-dokumen kaya visual dari satu bahasa (bahasa Inggris) dan dapat secara langsung disesuaikan dengan bahasa lain dengan model tekstual pra-terlatih monolingual/multibahasa yang sesuai. Kami berharap ketersediaan publik dari pekerjaan ini dapat membantu mendokumentasikan penelitian intelijen.
Untuk Cuda 11.x:
conda create -n liltfinetune python=3.7
conda activate liltfinetune
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=11.0 -c pytorch
python -m pip install detectron2==0.5 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
git clone https://github.com/jpWang/LiLT
cd LiLT
pip install -r requirements.txt
pip install -e .Atau periksa versi detectron2/pytorch dan memodifikasi baris perintah yang sesuai.
Dalam repositori ini, kami menyediakan kode fine-tuning untuk FunSD dan XFUND.
Anda dapat mengunduh data pra-diproses kami (~ 1.2GB) dari sini , dan meletakkan xfund&funsd/ Under LiLT/ .
| Model | Bahasa | Ukuran | Unduh |
|---|---|---|---|
lilt-roberta-en-base | En | 293MB | OneDrive |
lilt-infoxlm-base | MUL | 846MB | OneDrive |
lilt-only-base | Tidak ada | 21MB | OneDrive |
Jika Anda ingin menggabungkan lilt pra-terlatih dengan Roberta bahasa lain , silakan unduh lilt-only-base dan gunakan gen_weight_roberta_like.py untuk menghasilkan pos pemeriksaan pra-terlatih Anda sendiri.
Misalnya, gabungkan lilt-only-base dengan roberta-base bahasa Inggris:
mkdir roberta-en-base
wget https://huggingface.co/roberta-base/resolve/main/config.json -O roberta-en-base/config.json
wget https://huggingface.co/roberta-base/resolve/main/pytorch_model.bin -O roberta-en-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text roberta-en-base/pytorch_model.bin
--config roberta-en-base/config.json
--out lilt-roberta-en-base Atau gabungkan lilt-only-base dengan microsoft/infoxlm-base :
mkdir infoxlm-base
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/config.json -O infoxlm-base/config.json
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/pytorch_model.bin -O infoxlm-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text infoxlm-base/pytorch_model.bin
--config infoxlm-base/config.json
--out lilt-infoxlm-base CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_funsd.py
--model_name_or_path lilt-roberta-en-base
--tokenizer_name roberta-base
--output_dir ser_funsd_lilt-roberta-en-base
--do_train
--do_predict
--max_steps 2000
--per_device_train_batch_size 8
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_ser_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 2000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_re_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 5000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_ser_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 16000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_re_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 40000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
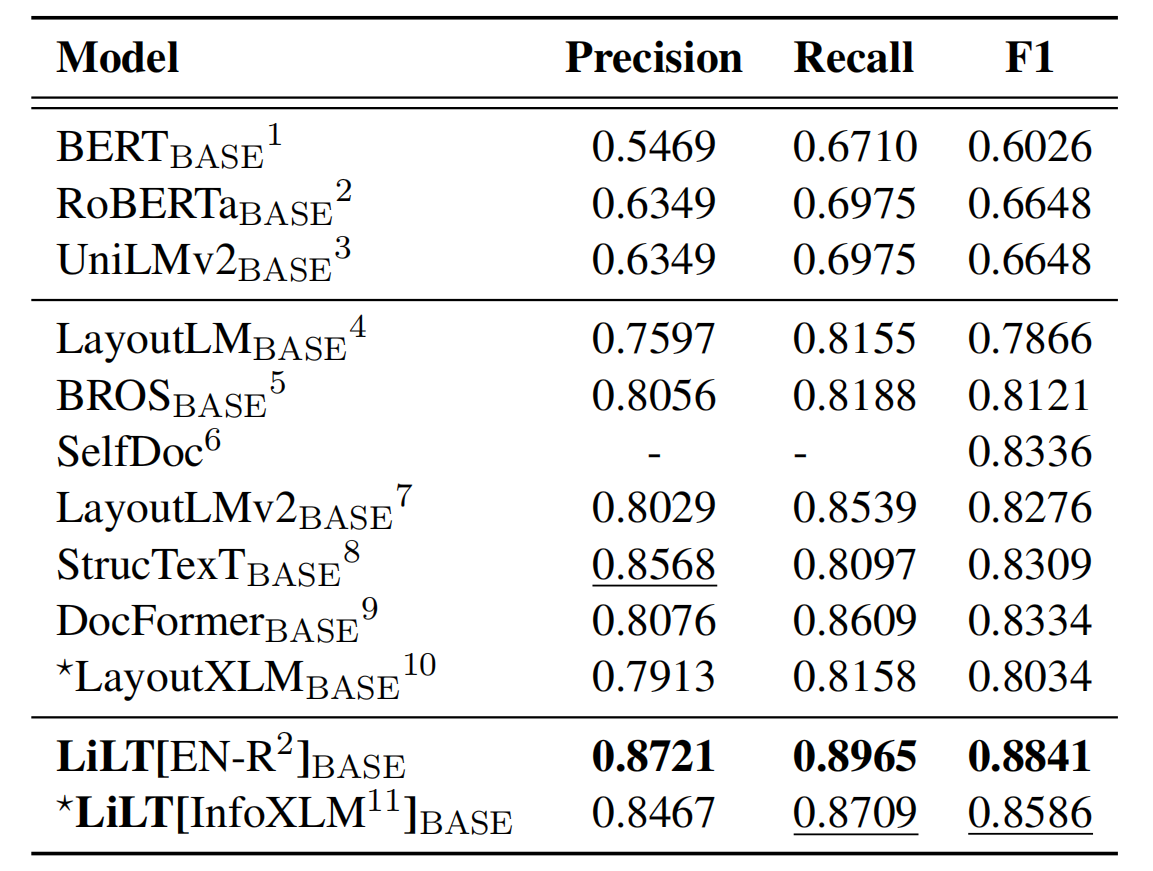
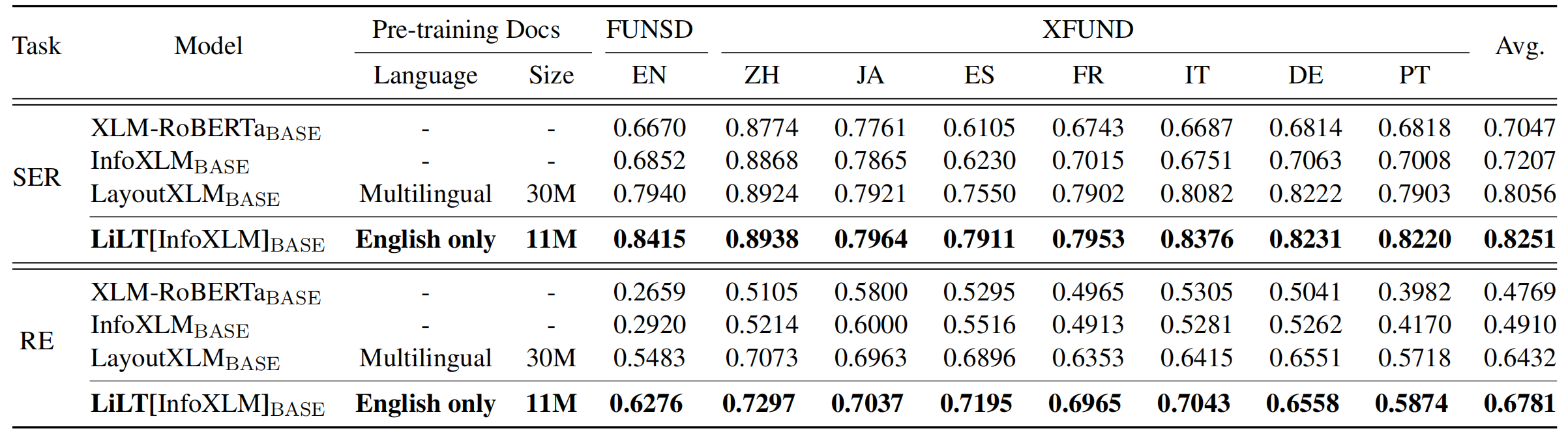
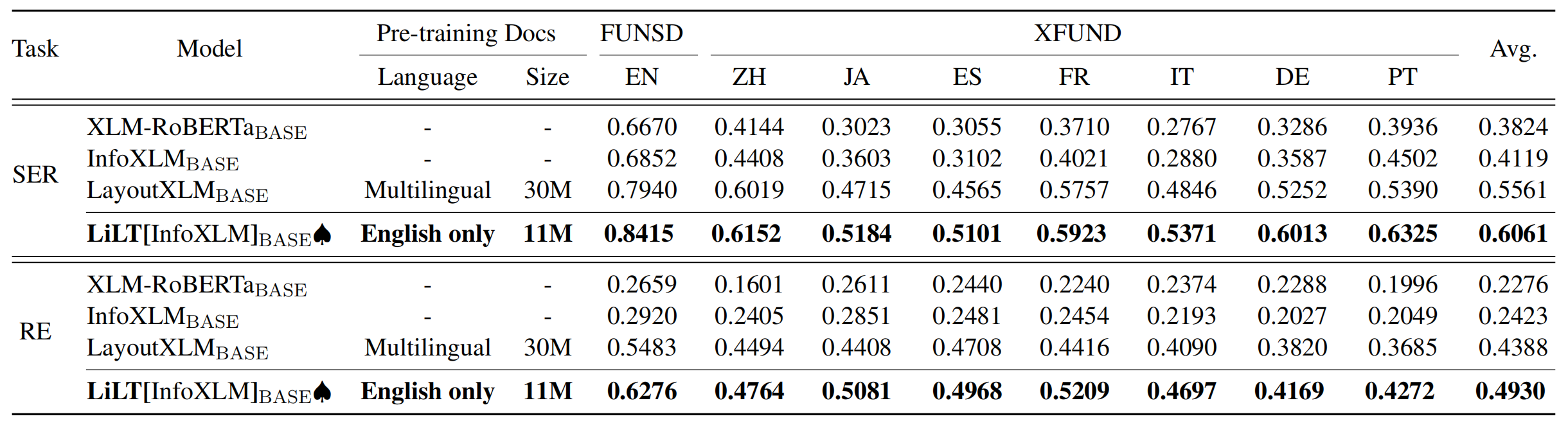
Repositori mendapat manfaat besar dari Unilm/Layoutlmft. Terima kasih banyak atas pekerjaan luar biasa mereka.
Jika makalah kami membantu penelitian Anda, silakan kutip di publikasi Anda:
@inproceedings{wang-etal-2022-lilt,
title = "{L}i{LT}: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding",
author={Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.534",
doi = "10.18653/v1/2022.acl-long.534",
pages = "7747--7757",
}
Saran dan diskusi sangat disambut. Silakan hubungi penulis dengan mengirim email ke [email protected] .


