LiLT
1.0.0
[2022/10] LILT a été ajouté à? HuggingFace / Transformers ici.
[2022/03] Modèle initial et version de code.
Il s'agit de la mise en œuvre officielle Pytorch de l'article ACL 2022: "LILT: un transformateur de mise en page indépendant du langage simple mais efficace pour la compréhension des documents structurés". [OFFICIEL] [ARXIV]
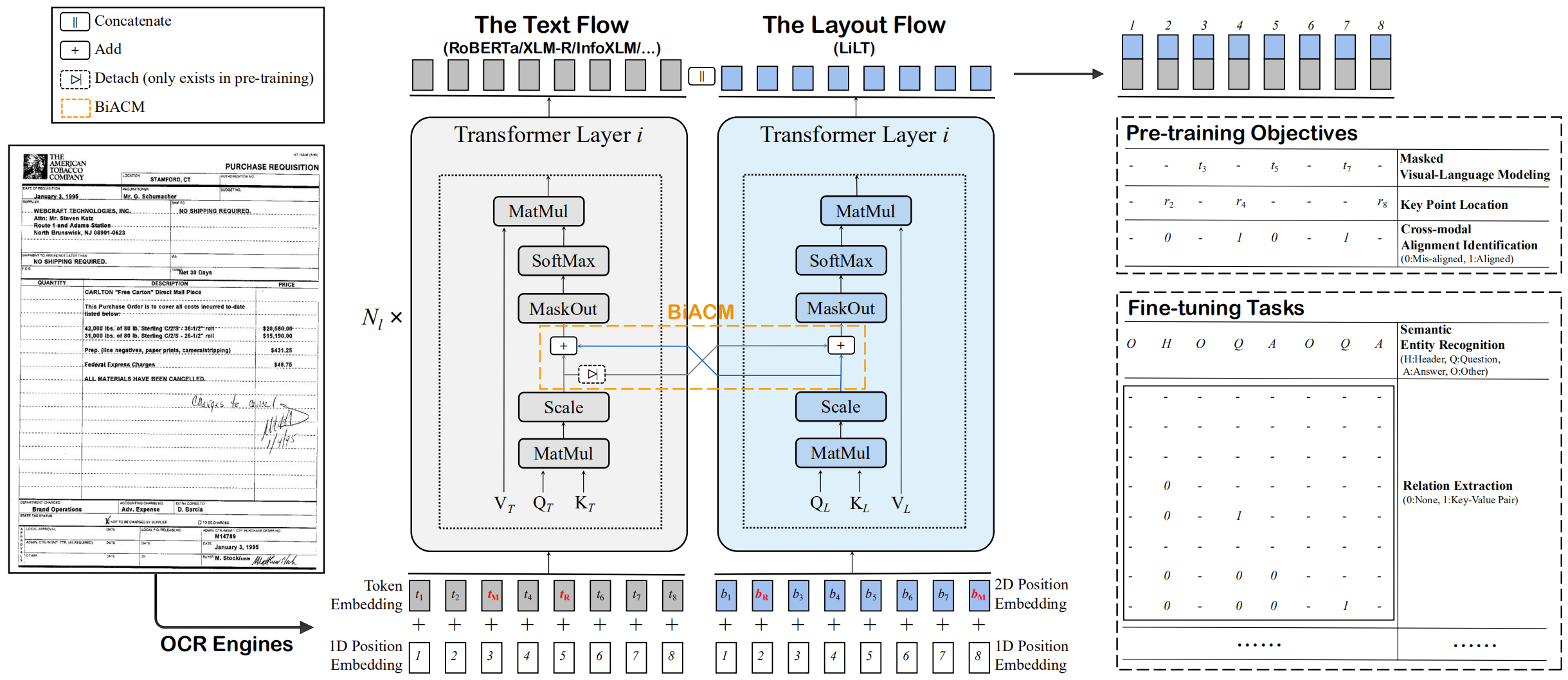
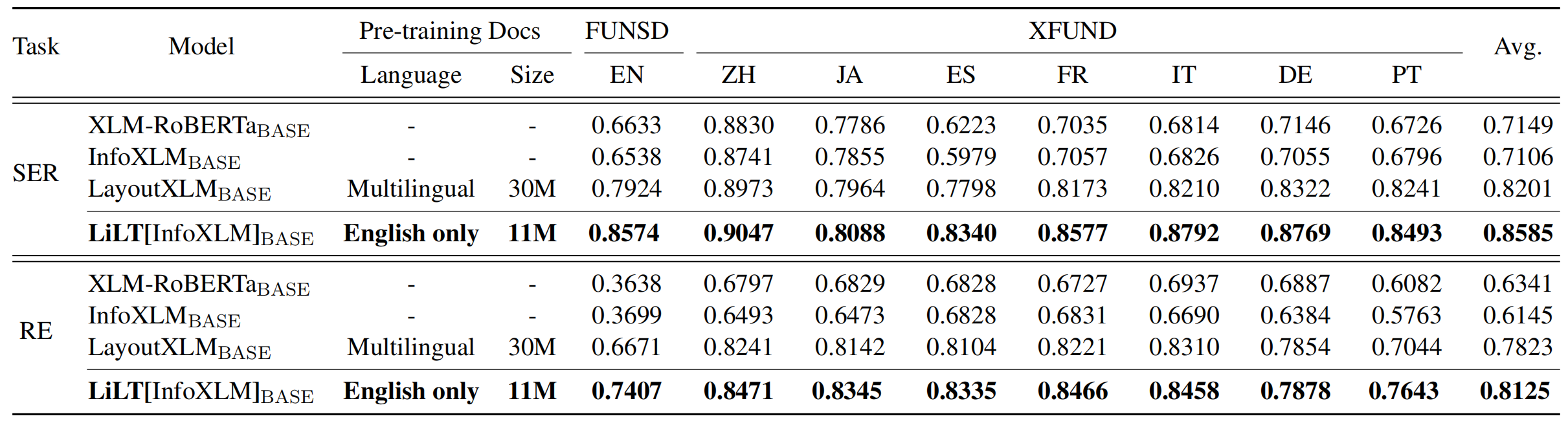
LILT est pré-formé sur les documents visuellement riches en une seule langue (anglais) et peut être directement affiné sur d'autres langues avec les modèles textuels monolingues / multilinguaux / multilinguaux correspondants. Nous espérons que la disponibilité publique de ce travail peut aider à documenter les recherches sur le renseignement.
Pour Cuda 11.x:
conda create -n liltfinetune python=3.7
conda activate liltfinetune
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=11.0 -c pytorch
python -m pip install detectron2==0.5 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
git clone https://github.com/jpWang/LiLT
cd LiLT
pip install -r requirements.txt
pip install -e .Ou vérifiez les versions Detectron2 / Pytorch et modifiez les lignes de commande en conséquence.
Dans ce référentiel, nous fournissons les codes de réglage fin pour FunsD et XFund.
Vous pouvez télécharger nos données prétraitées (~ 1,2 Go) à partir d'ici et mettre le xfund&funsd/ Under Lilt / Under LiLT/ .
| Modèle | Langue | Taille | Télécharger |
|---|---|---|---|
lilt-roberta-en-base | En | 293 Mo | Onedrive |
lilt-infoxlm-base | Mâle | 846 Mo | Onedrive |
lilt-only-base | Aucun | 21 Mo | Onedrive |
Si vous souhaitez combiner le LILT pré-formé avec Roberta de l'autre langue , veuillez télécharger lilt-only-base et utiliser gen_weight_roberta_like.py pour générer votre propre point de contrôle pré-formé.
Par exemple, combinez lilt-only-base avec roberta-base :
mkdir roberta-en-base
wget https://huggingface.co/roberta-base/resolve/main/config.json -O roberta-en-base/config.json
wget https://huggingface.co/roberta-base/resolve/main/pytorch_model.bin -O roberta-en-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text roberta-en-base/pytorch_model.bin
--config roberta-en-base/config.json
--out lilt-roberta-en-base Ou combinez lilt-only-base avec microsoft/infoxlm-base :
mkdir infoxlm-base
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/config.json -O infoxlm-base/config.json
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/pytorch_model.bin -O infoxlm-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text infoxlm-base/pytorch_model.bin
--config infoxlm-base/config.json
--out lilt-infoxlm-base CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_funsd.py
--model_name_or_path lilt-roberta-en-base
--tokenizer_name roberta-base
--output_dir ser_funsd_lilt-roberta-en-base
--do_train
--do_predict
--max_steps 2000
--per_device_train_batch_size 8
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_ser_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 2000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_re_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 5000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_ser_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 16000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_re_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 40000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
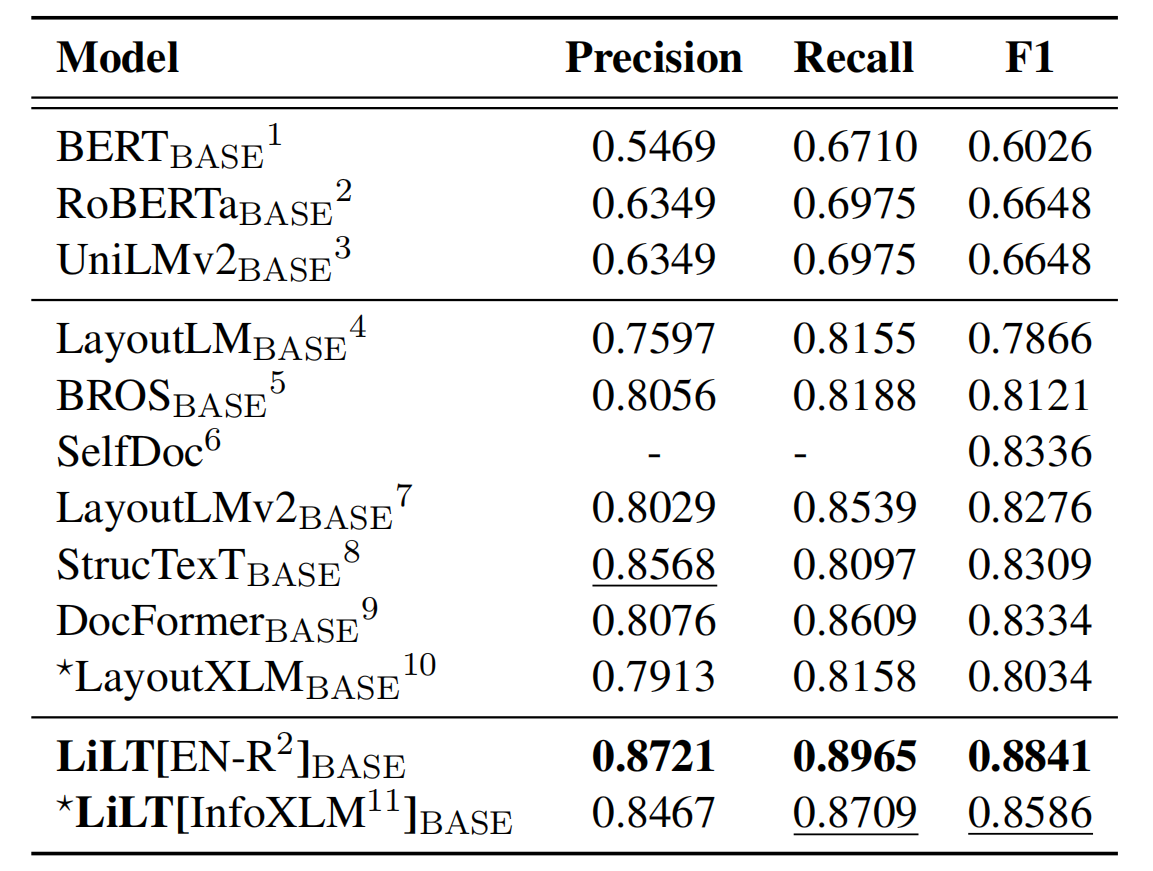
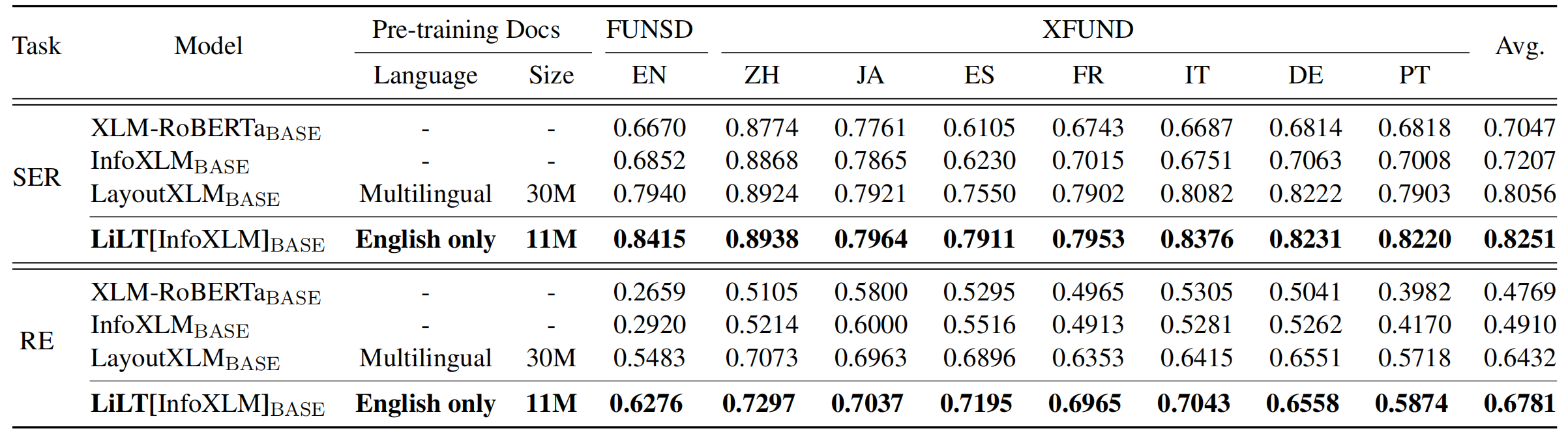
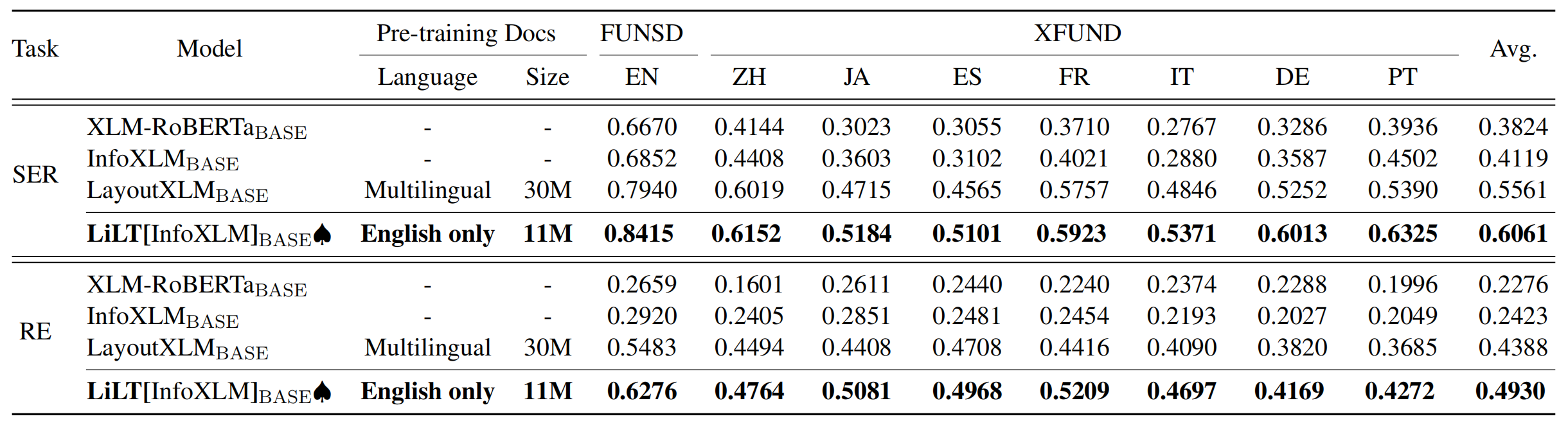
Le référentiel bénéficie grandement de UNILM / Layoutlmft. Merci beaucoup pour leur excellent travail.
Si notre article aide vos recherches, veuillez la citer dans votre ou vos publications:
@inproceedings{wang-etal-2022-lilt,
title = "{L}i{LT}: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding",
author={Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.534",
doi = "10.18653/v1/2022.acl-long.534",
pages = "7747--7757",
}
Les suggestions et les discussions sont grandement les bienvenues. Veuillez contacter les auteurs en envoyant un e-mail à [email protected] .


