LiLT
1.0.0
[2022/10] تمت إضافة Lilt إلى؟ Huggingface/Transformers هنا.
[2022/03] النموذج الأولي والرمز.
هذا هو تطبيق Pytorch الرسمي لورقة ACL 2022: "Lilt: محول تخطيط بسيط معتمد على اللغة لفهم الوثائق المنظم". [رسمي] [Arxiv]
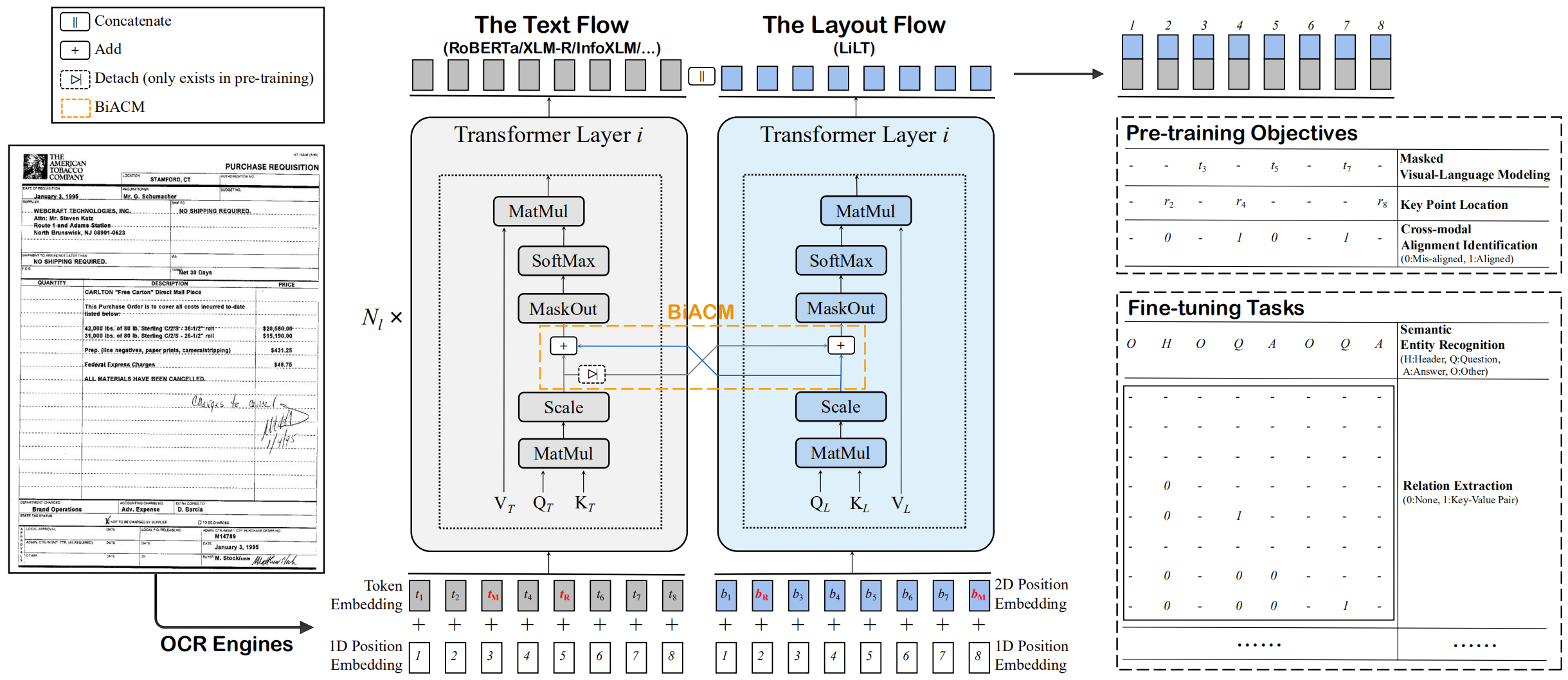
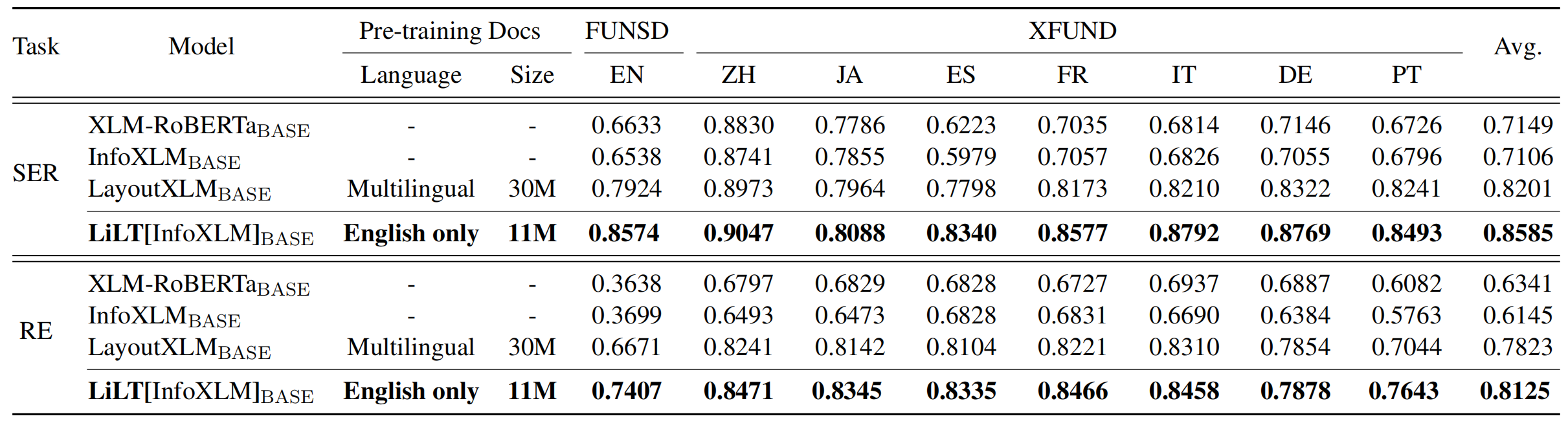
يتم تدريب LILT مسبقًا على المستندات الغنية بصريًا بلغة واحدة (الإنجليزية) ويمكن ضبطها بشكل مباشر على لغات أخرى مع النماذج النصية التي تم تدريبها مسبقًا على الجرف المقابلة. نأمل أن يساعد توافر هذا العمل العام في توثيق أبحاث الاستخبارات.
لـ CUDA 11.x:
conda create -n liltfinetune python=3.7
conda activate liltfinetune
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=11.0 -c pytorch
python -m pip install detectron2==0.5 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
git clone https://github.com/jpWang/LiLT
cd LiLT
pip install -r requirements.txt
pip install -e .أو تحقق من إصدارات Detectron2/Pytorch وتعديل أسطر الأوامر وفقًا لذلك.
في هذا المستودع ، نقدم رموز الضبط الدقيقة لـ FUNSD و XFund.
يمكنك تنزيل بياناتنا المعالجة مسبقًا (~ 1.2 جيجابايت) من هنا ، ووضع xfund&funsd/ Under LiLT/ .
| نموذج | لغة | مقاس | تحميل |
|---|---|---|---|
lilt-roberta-en-base | en | 293 ميجابايت | onedrive |
lilt-infoxlm-base | مول | 846 ميجابايت | onedrive |
lilt-only-base | لا أحد | 21 ميجابايت | onedrive |
إذا كنت ترغب في الجمع بين LILT المدربة مسبقًا مع Roberta للغة الأخرى ، فيرجى تنزيل lilt-only-base واستخدام gen_weight_roberta_like.py لإنشاء نقطة تفتيش تدرب مسبقًا.
على سبيل المثال ، الجمع بين lilt-only-base مع اللغة الإنجليزية roberta-base :
mkdir roberta-en-base
wget https://huggingface.co/roberta-base/resolve/main/config.json -O roberta-en-base/config.json
wget https://huggingface.co/roberta-base/resolve/main/pytorch_model.bin -O roberta-en-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text roberta-en-base/pytorch_model.bin
--config roberta-en-base/config.json
--out lilt-roberta-en-base أو الجمع بين lilt-only-base مع microsoft/infoxlm-base :
mkdir infoxlm-base
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/config.json -O infoxlm-base/config.json
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/pytorch_model.bin -O infoxlm-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text infoxlm-base/pytorch_model.bin
--config infoxlm-base/config.json
--out lilt-infoxlm-base CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_funsd.py
--model_name_or_path lilt-roberta-en-base
--tokenizer_name roberta-base
--output_dir ser_funsd_lilt-roberta-en-base
--do_train
--do_predict
--max_steps 2000
--per_device_train_batch_size 8
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_ser_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 2000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_re_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 5000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_ser_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 16000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_re_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 40000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
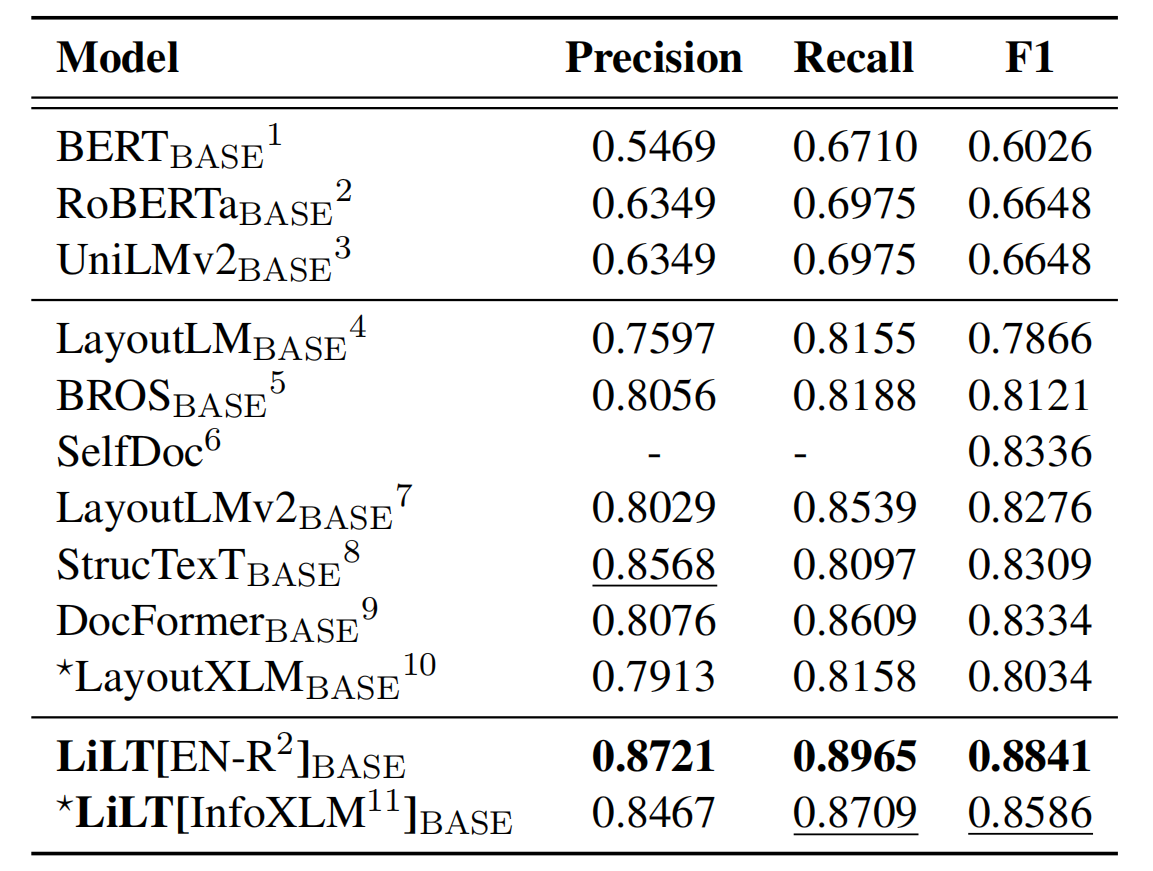
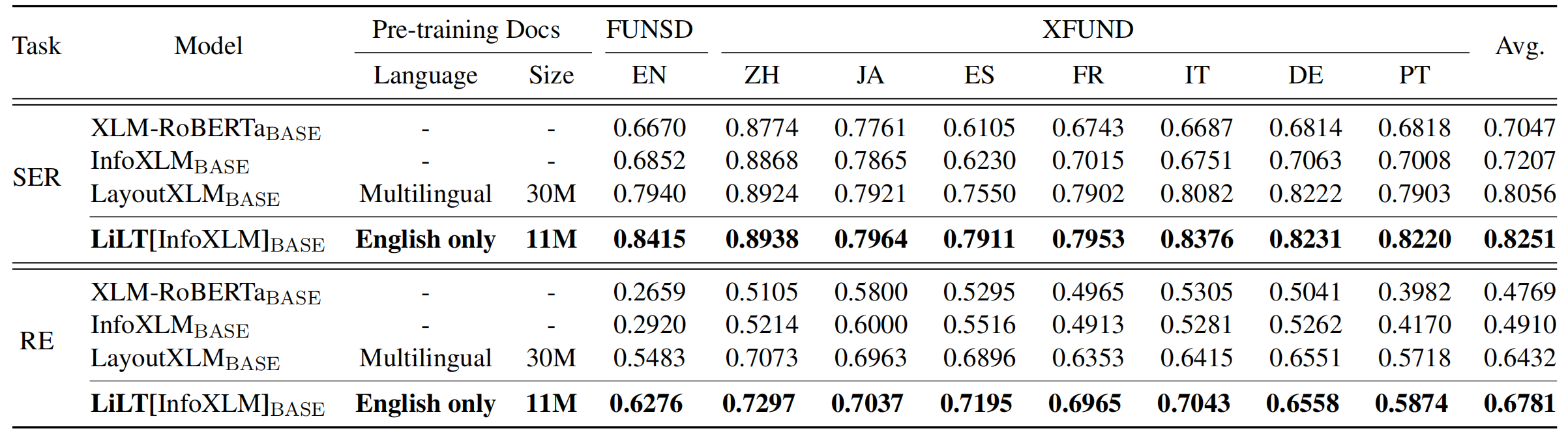
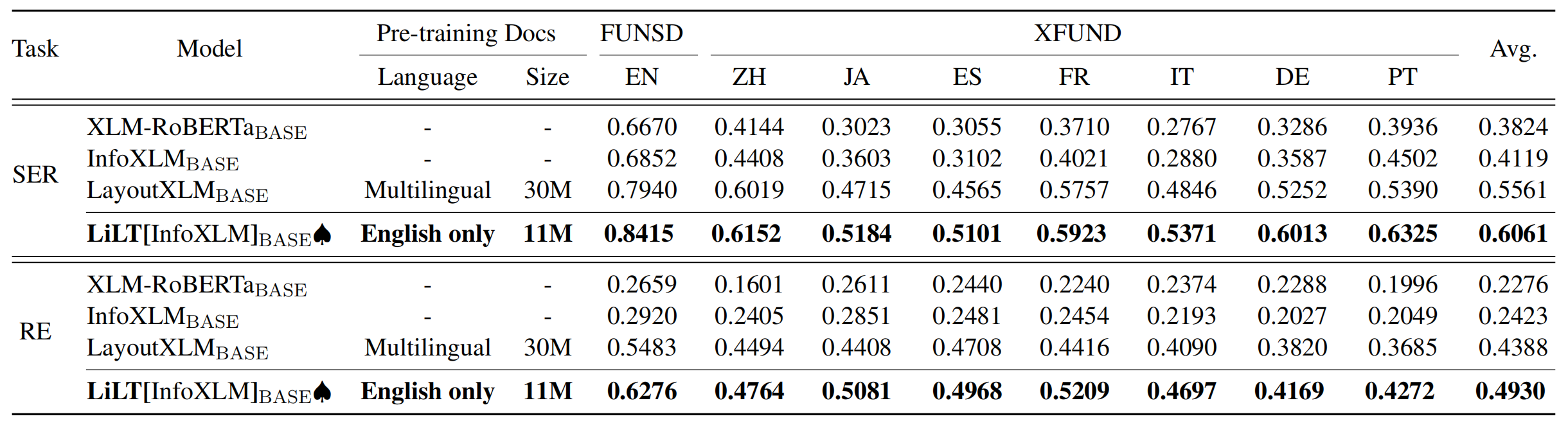
يستفيد المستودع بشكل كبير من Unilm/Layoutlmft. شكرا جزيلا على عملهم الممتاز.
إذا كانت ورقتنا تساعد في بحثك ، فيرجى الاستشهاد بها في منشوراتك (نشرات):
@inproceedings{wang-etal-2022-lilt,
title = "{L}i{LT}: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding",
author={Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.534",
doi = "10.18653/v1/2022.acl-long.534",
pages = "7747--7757",
}
الاقتراحات والمناقشات هي موضع ترحيب كبير. يرجى الاتصال بالمؤلفين عن طريق إرسال بريد إلكتروني إلى [email protected] .


