LiLT
1.0.0
[2022/10] Lilt wurde hier zu? Huggingface/Transformers hinzugefügt.
[2022/03] Erstmodell und Codefreigabe.
Dies ist die offizielle Pytorch-Implementierung des ACL 2022-Papiers: "Lilt: Ein einfacher, aber effektiver sprachunabhängiger Layout-Transformator für strukturiertes Dokumentverständnis". [offiziell] [Arxiv]
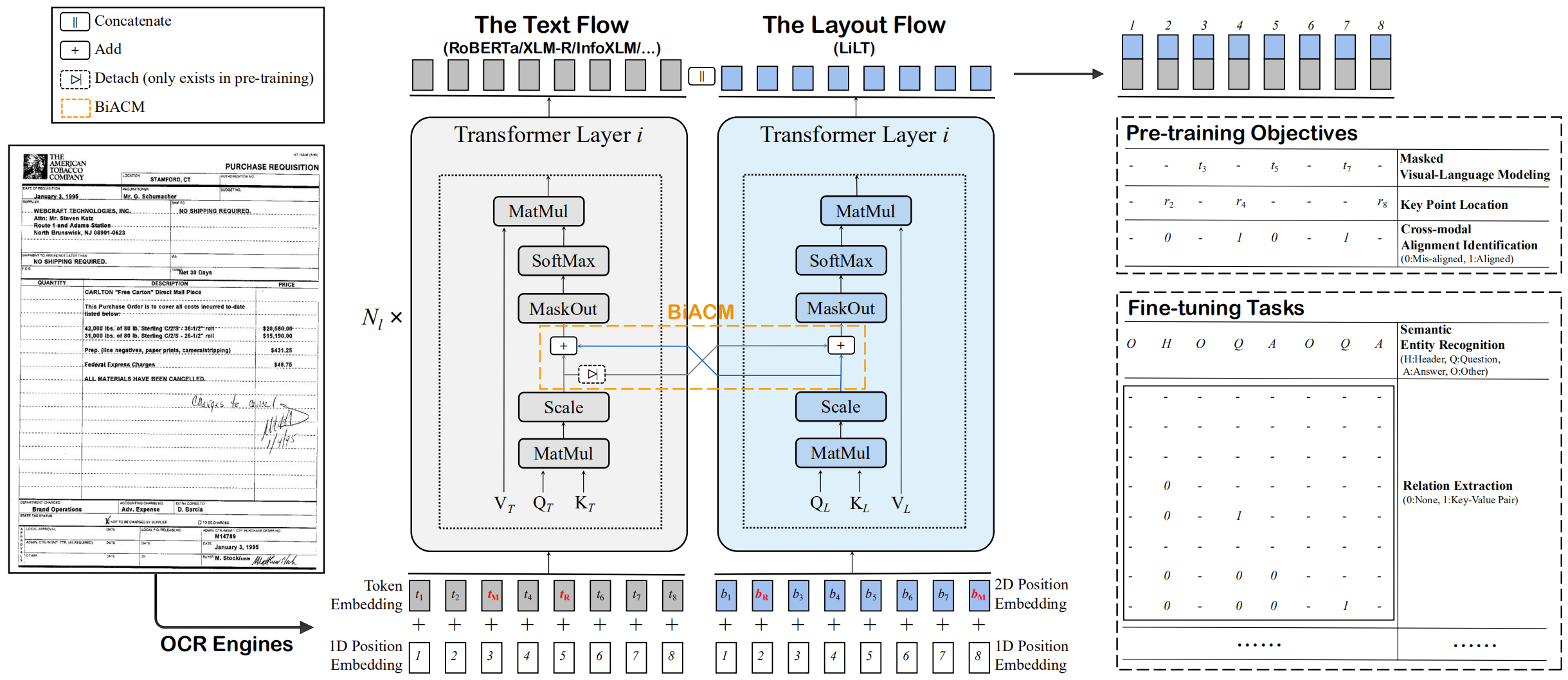
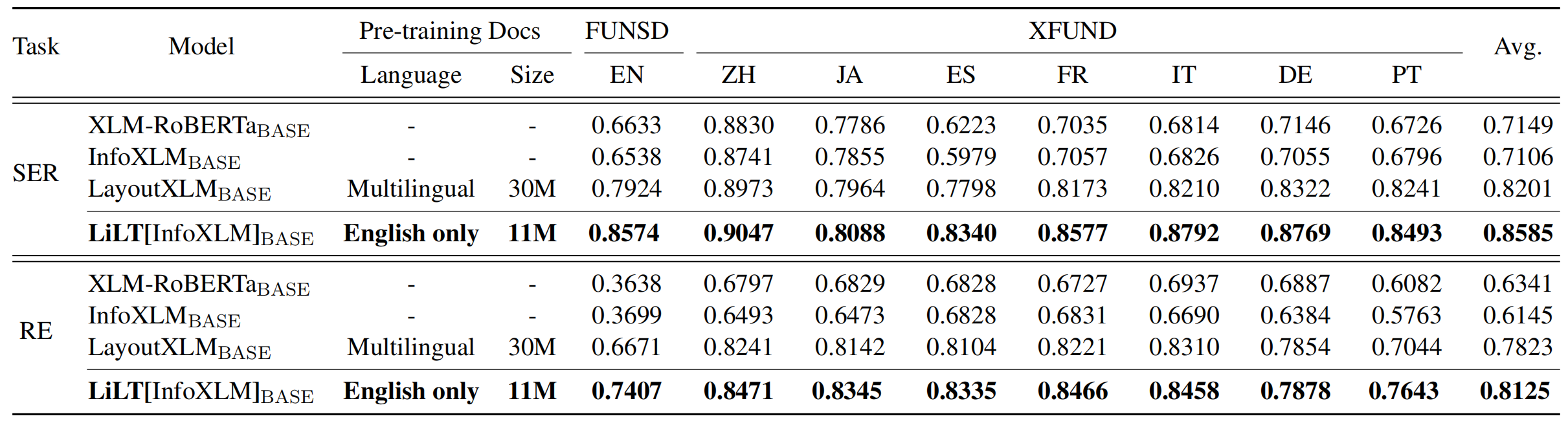
Lilt wird in den visuellreichen Dokumenten einer einzelnen Sprache (Englisch) vorgeschrieben und kann direkt in anderen Sprachen mit den entsprechenden monolinguellen/mehrsprachigen vorgeschriebenen Textmodellen fein abgestimmt werden. Wir hoffen, dass die öffentliche Verfügbarkeit dieser Arbeit dazu beitragen kann, Intelligenzforschungen zu dokumentieren.
Für CUDA 11.x:
conda create -n liltfinetune python=3.7
conda activate liltfinetune
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=11.0 -c pytorch
python -m pip install detectron2==0.5 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
git clone https://github.com/jpWang/LiLT
cd LiLT
pip install -r requirements.txt
pip install -e .Oder überprüfen Sie die DETECTRON2/PYTORCH -Versionen und ändern Sie die Befehlszeilen entsprechend.
In diesem Repository bieten wir die Feinabstimmungscodes für Funsd und XFund.
Sie können unsere vorverarbeiteten Daten (~ 1,2 GB) von hier herunterladen und den entpackten xfund&funsd/ unter LiLT/ einsetzen.
| Modell | Sprache | Größe | Herunterladen |
|---|---|---|---|
lilt-roberta-en-base | En | 293MB | OneDrive |
lilt-infoxlm-base | Mul | 846MB | OneDrive |
lilt-only-base | Keiner | 21 MB | OneDrive |
Wenn Sie die vorgeborene Lilde mit Roberta einer anderen Sprache kombinieren möchten, laden Sie bitte lilt-only-base herunter und verwenden Sie gen_weight_roberta_like.py , um Ihren eigenen vorgeborenen Kontrollpunkt zu generieren.
Kombinieren Sie beispielsweise lilt-only-base mit englischer roberta-base :
mkdir roberta-en-base
wget https://huggingface.co/roberta-base/resolve/main/config.json -O roberta-en-base/config.json
wget https://huggingface.co/roberta-base/resolve/main/pytorch_model.bin -O roberta-en-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text roberta-en-base/pytorch_model.bin
--config roberta-en-base/config.json
--out lilt-roberta-en-base Oder kombinieren Sie lilt-only-base mit microsoft/infoxlm-base :
mkdir infoxlm-base
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/config.json -O infoxlm-base/config.json
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/pytorch_model.bin -O infoxlm-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text infoxlm-base/pytorch_model.bin
--config infoxlm-base/config.json
--out lilt-infoxlm-base CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_funsd.py
--model_name_or_path lilt-roberta-en-base
--tokenizer_name roberta-base
--output_dir ser_funsd_lilt-roberta-en-base
--do_train
--do_predict
--max_steps 2000
--per_device_train_batch_size 8
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_ser_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 2000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_re_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 5000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_ser_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 16000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_re_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 40000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
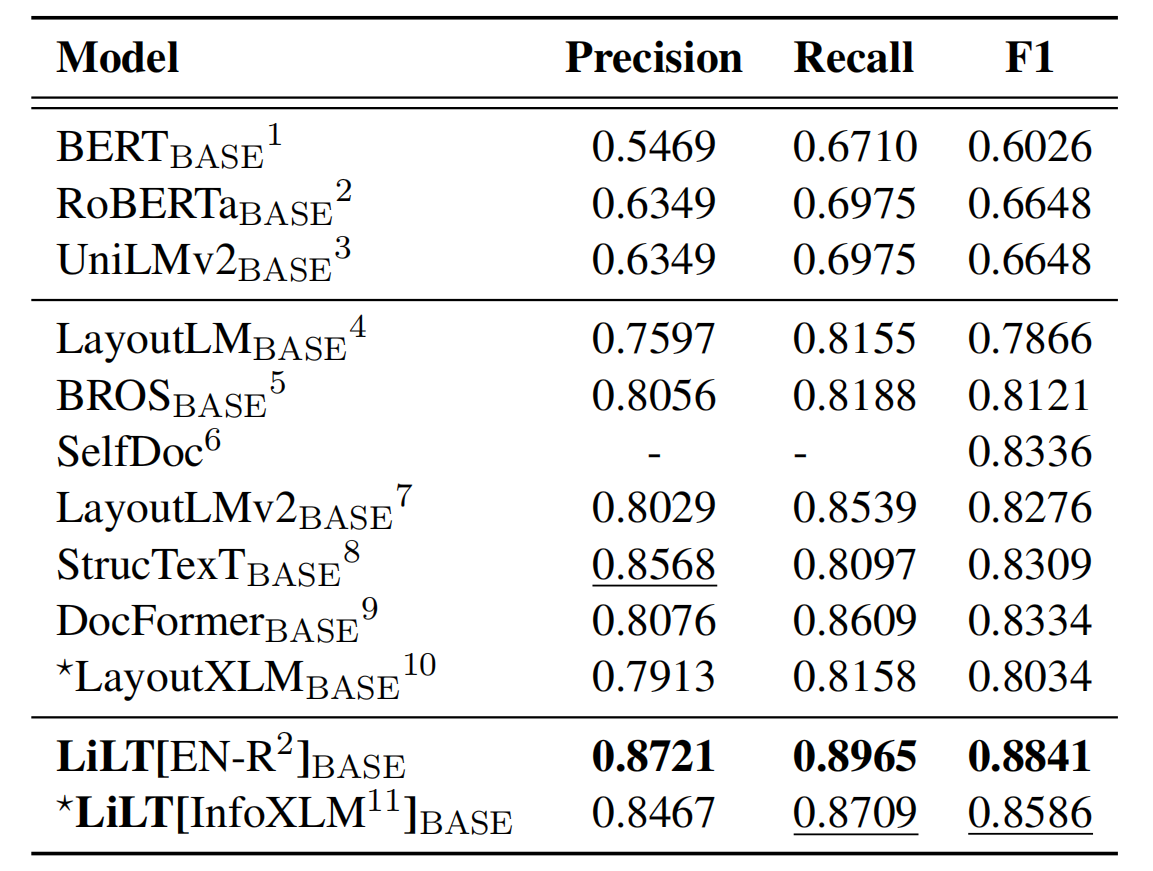
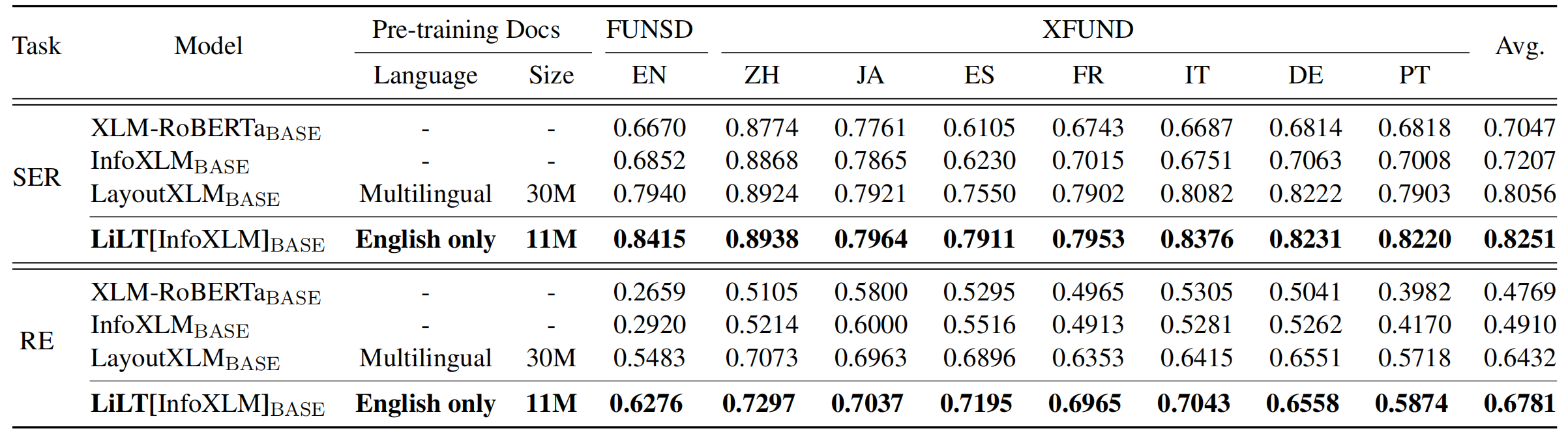
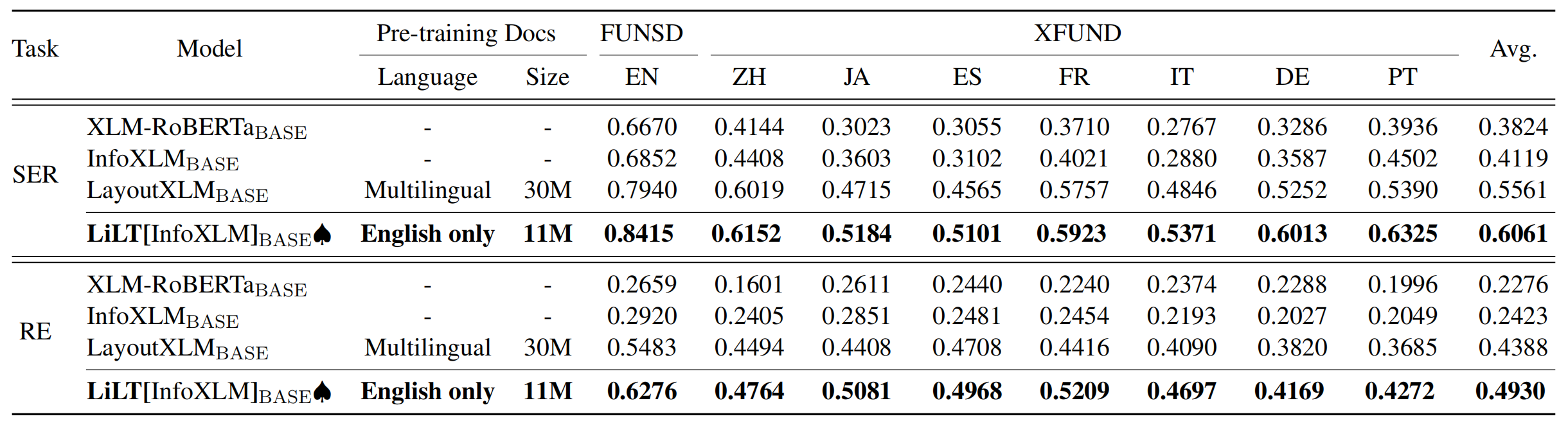
Das Repository profitiert stark von Unilm/Layoutlmft. Vielen Dank für ihre hervorragende Arbeit.
Wenn unser Papier Ihre Recherche hilft, zitieren Sie es bitte in Ihrer Veröffentlichung (en):
@inproceedings{wang-etal-2022-lilt,
title = "{L}i{LT}: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding",
author={Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.534",
doi = "10.18653/v1/2022.acl-long.534",
pages = "7747--7757",
}
Vorschläge und Diskussionen sind sehr willkommen. Bitte kontaktieren Sie die Autoren, indem Sie eine E -Mail an [email protected] senden.


