LiLT
1.0.0
[2022/10] liltは、ここにハグするフェイス/トランスに追加されています。
[2022/03]初期モデルとコードリリース。
これは、ACL 2022ペーパーの公式のPytorch実装です。「Lilt:構造化されたドキュメント理解のためのシンプルで効果的な言語に依存しないレイアウトトランス」。 [公式] [arxiv]
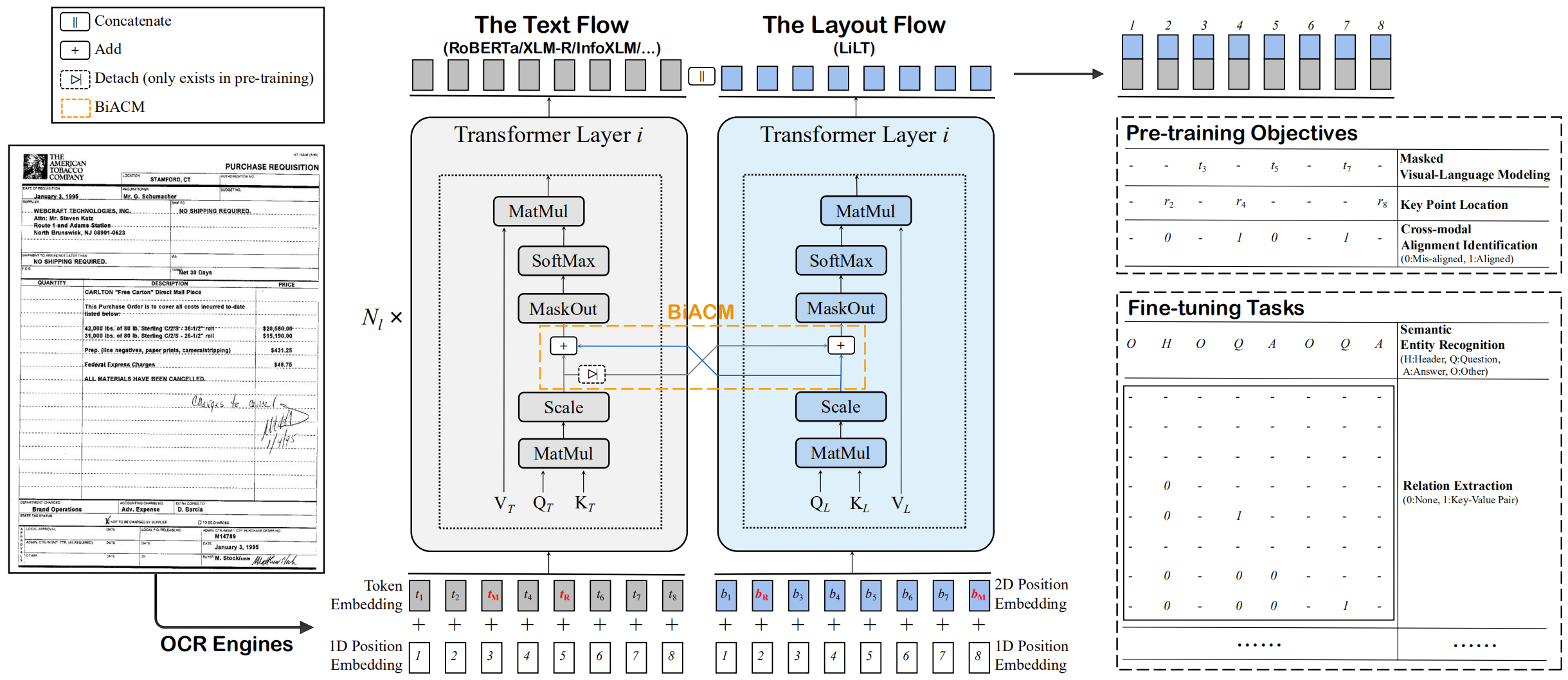
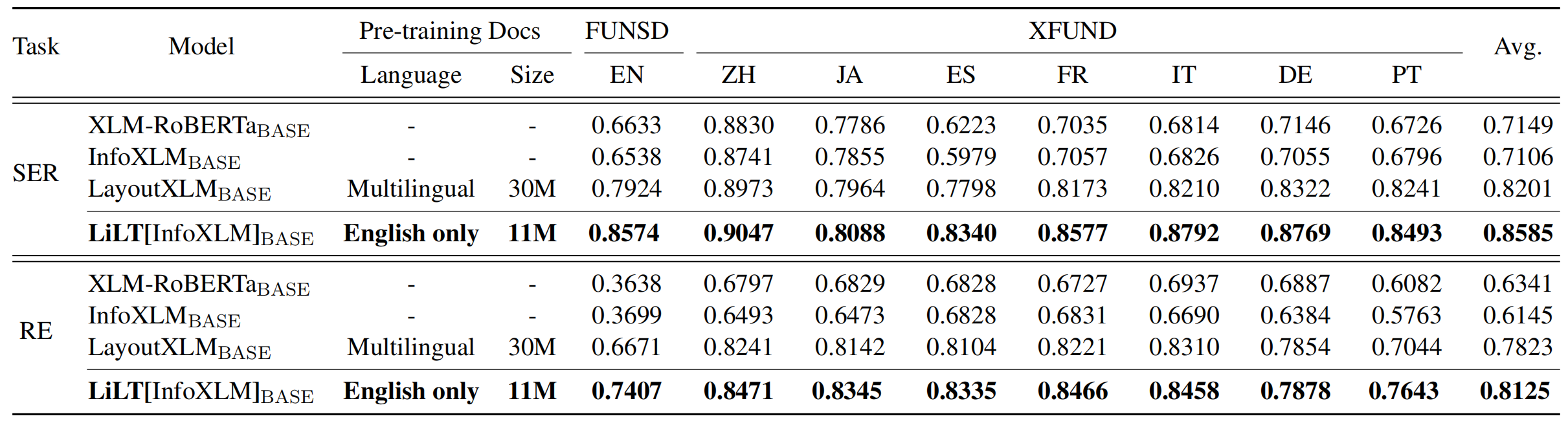
Liltは、単一言語(英語)の視覚的に豊富なドキュメントで事前に訓練されており、対応する既製の単一言語/多言語の事前訓練モデルで、他の言語で直接微調整できます。この作業の一般的な利用可能性が、インテリジェンスの研究を文書化するのに役立つことを願っています。
cuda 11.xの場合:
conda create -n liltfinetune python=3.7
conda activate liltfinetune
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=11.0 -c pytorch
python -m pip install detectron2==0.5 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
git clone https://github.com/jpWang/LiLT
cd LiLT
pip install -r requirements.txt
pip install -e .または、Detectron2/Pytorchバージョンを確認し、それに応じてコマンドラインを変更します。
このリポジトリでは、FunSDとXfundの微調整コードを提供します。
ここから前処理されたデータ(〜1.2GB)をダウンロードして、未zip xfund&funsd/ under LiLT/を配置できます。
| モデル | 言語 | サイズ | ダウンロード |
|---|---|---|---|
lilt-roberta-en-base | en | 293MB | onedrive |
lilt-infoxlm-base | マル | 846MB | onedrive |
lilt-only-base | なし | 21MB | onedrive |
事前に訓練されたLiltを他の言語のRobertaと組み合わせる場合は、 lilt-only-baseをダウンロードし、 gen_weight_roberta_like.pyを使用して、独自の事前に訓練されたチェックポイントを生成してください。
たとえば、 lilt-only-baseと英語のroberta-baseを組み合わせます。
mkdir roberta-en-base
wget https://huggingface.co/roberta-base/resolve/main/config.json -O roberta-en-base/config.json
wget https://huggingface.co/roberta-base/resolve/main/pytorch_model.bin -O roberta-en-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text roberta-en-base/pytorch_model.bin
--config roberta-en-base/config.json
--out lilt-roberta-en-baseまたは、 lilt-only-baseとmicrosoft/infoxlm-baseを組み合わせます。
mkdir infoxlm-base
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/config.json -O infoxlm-base/config.json
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/pytorch_model.bin -O infoxlm-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text infoxlm-base/pytorch_model.bin
--config infoxlm-base/config.json
--out lilt-infoxlm-base CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_funsd.py
--model_name_or_path lilt-roberta-en-base
--tokenizer_name roberta-base
--output_dir ser_funsd_lilt-roberta-en-base
--do_train
--do_predict
--max_steps 2000
--per_device_train_batch_size 8
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_ser_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 2000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_re_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 5000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_ser_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 16000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_re_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 40000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
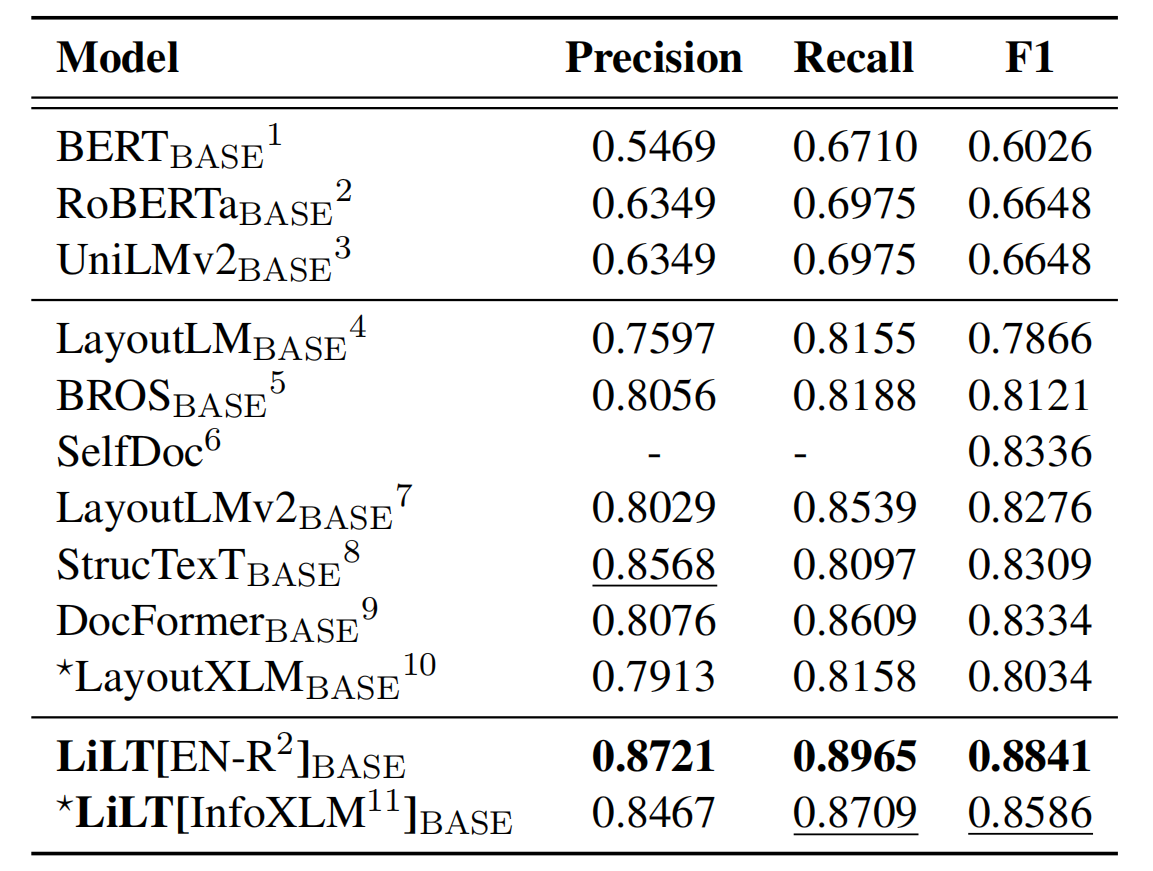
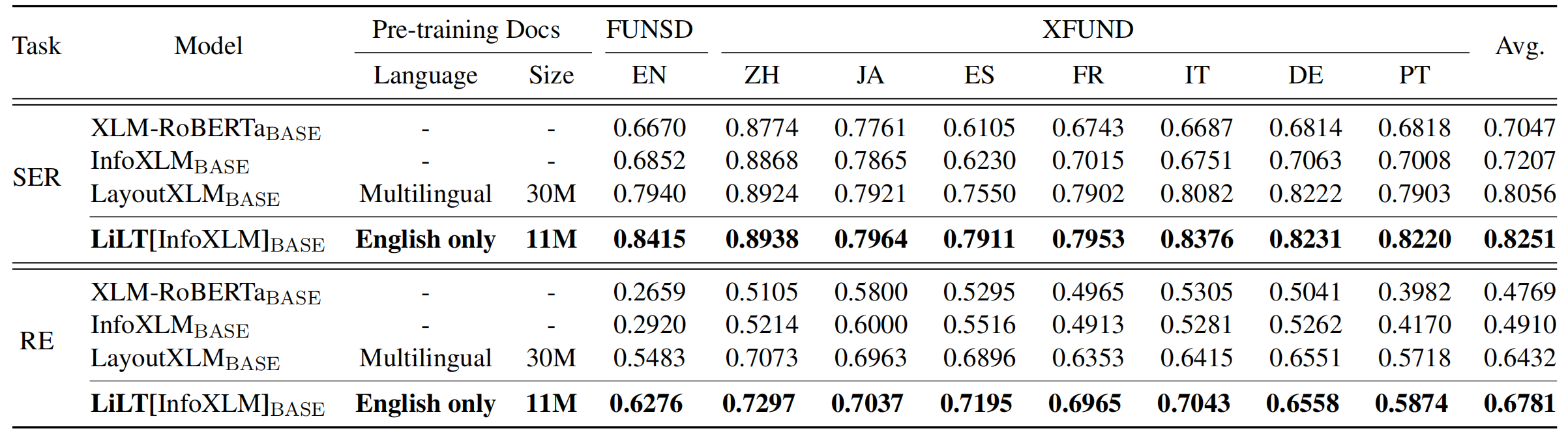
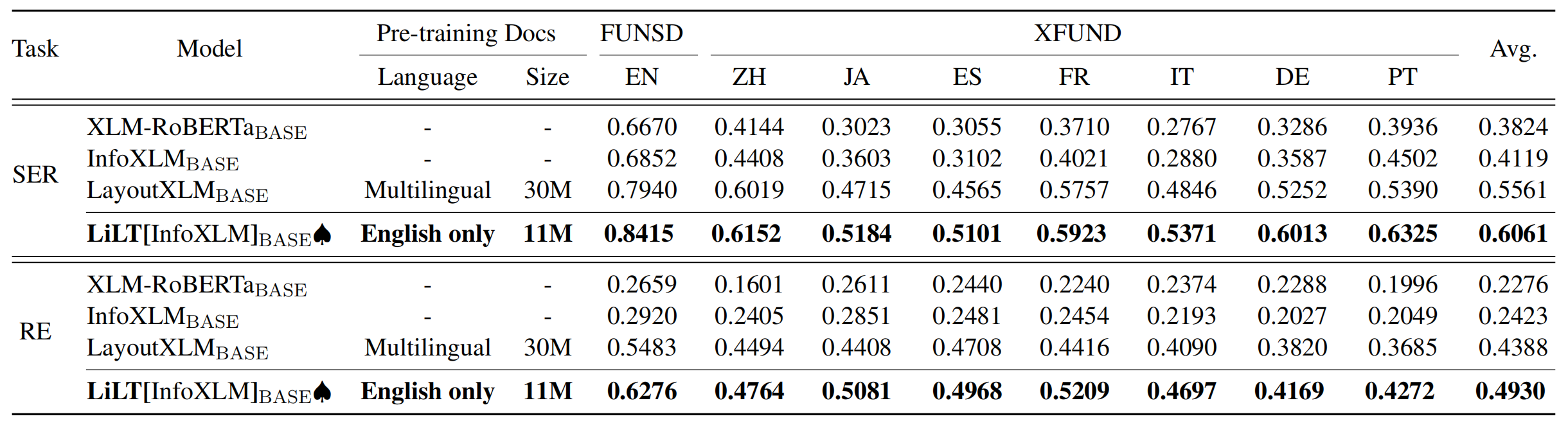
リポジトリは、Unilm/layoutlmftから大きな利益をもたらします。彼らの素晴らしい仕事をどうもありがとう。
私たちの論文があなたの研究に役立つなら、あなたの出版物でそれを引用してください:
@inproceedings{wang-etal-2022-lilt,
title = "{L}i{LT}: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding",
author={Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.534",
doi = "10.18653/v1/2022.acl-long.534",
pages = "7747--7757",
}
提案と議論は大歓迎です。 [email protected]にメールを送信して、著者に連絡してください。


