LiLT
1.0.0
[2022/10] Se ha agregado lilt a? Huggingface/Transformers aquí.
[2022/03] Modelo inicial y versión de código.
Esta es la implementación oficial de Pytorch del documento ACL 2022: "Lilt: un transformador de diseño independiente del lenguaje simple pero efectivo para la comprensión estructurada de documentos". [Oficial] [ARXIV]
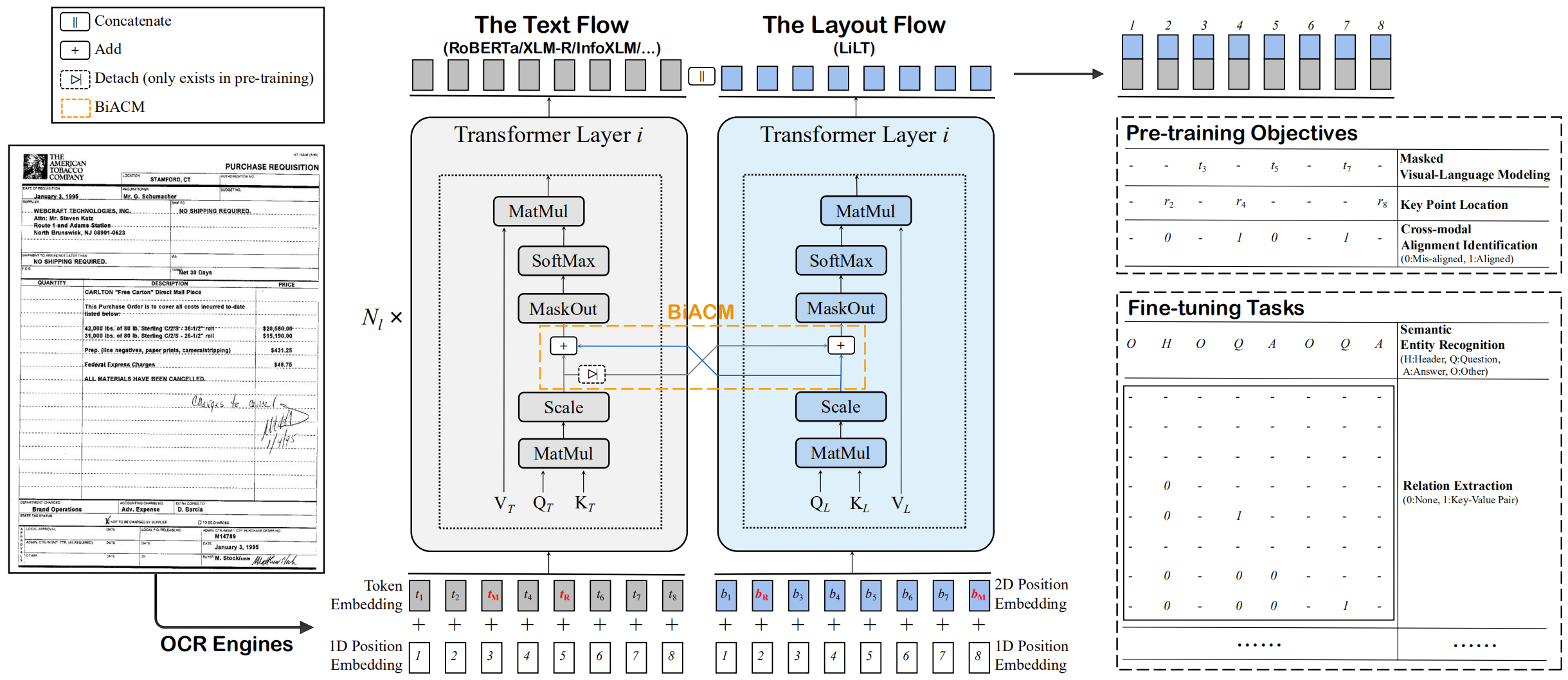
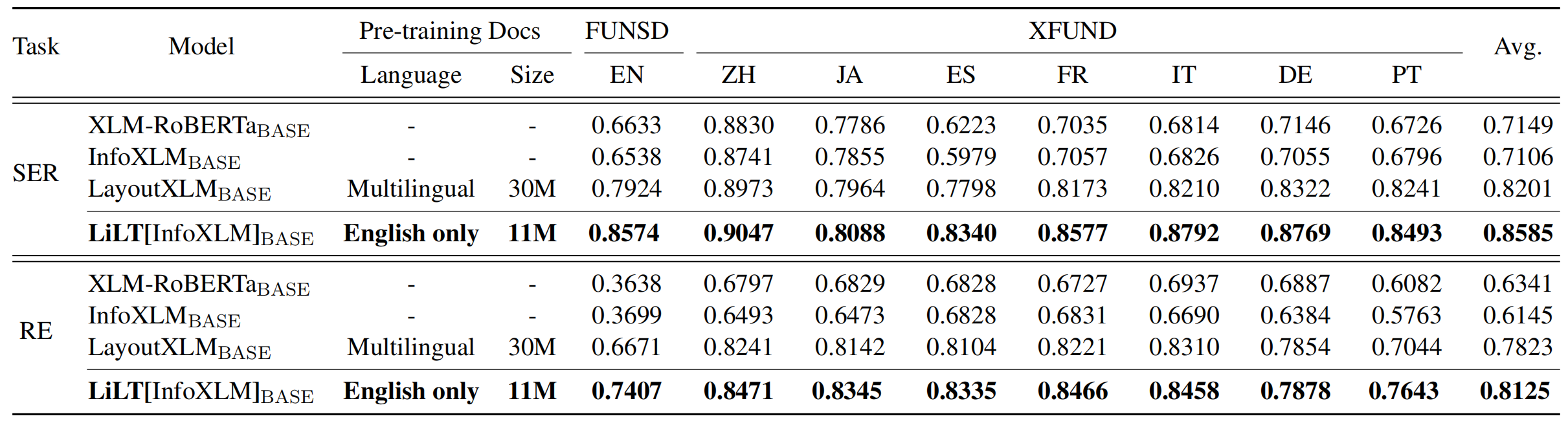
LILT se entrena previamente en los documentos visuales de un solo idioma (inglés) y se puede ajustar directamente en otros idiomas con los modelos textuales monolingües/multilingües previamente monolingües/multilingües correspondientes. Esperamos que la disponibilidad pública de este trabajo pueda ayudar a documentar investigaciones de inteligencia.
Para CUDA 11.x:
conda create -n liltfinetune python=3.7
conda activate liltfinetune
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=11.0 -c pytorch
python -m pip install detectron2==0.5 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
git clone https://github.com/jpWang/LiLT
cd LiLT
pip install -r requirements.txt
pip install -e .O verifique las versiones de Detectron2/Pytorch y modifique las líneas de comando en consecuencia.
En este repositorio, proporcionamos los códigos de ajuste fino para FUNSD y XFUND.
Puede descargar nuestros datos preprocesados (~ 1.2GB) desde aquí , y colocar el xfund&funsd/ Inmised LiLT/ .
| Modelo | Idioma | Tamaño | Descargar |
|---|---|---|---|
lilt-roberta-en-base | Interno | 293MB | Onedrive |
lilt-infoxlm-base | Mul | 846 MB | Onedrive |
lilt-only-base | Ninguno | 21MB | Onedrive |
Si desea combinar el Lilt previamente capacitado con el Roberta de otro idioma , descargue lilt-only-base y use gen_weight_roberta_like.py para generar su propio punto de control previamente capacitado.
Por ejemplo, combine lilt-only-base con roberta-base en inglés:
mkdir roberta-en-base
wget https://huggingface.co/roberta-base/resolve/main/config.json -O roberta-en-base/config.json
wget https://huggingface.co/roberta-base/resolve/main/pytorch_model.bin -O roberta-en-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text roberta-en-base/pytorch_model.bin
--config roberta-en-base/config.json
--out lilt-roberta-en-base O combinar lilt-only-base con microsoft/infoxlm-base :
mkdir infoxlm-base
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/config.json -O infoxlm-base/config.json
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/pytorch_model.bin -O infoxlm-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text infoxlm-base/pytorch_model.bin
--config infoxlm-base/config.json
--out lilt-infoxlm-base CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_funsd.py
--model_name_or_path lilt-roberta-en-base
--tokenizer_name roberta-base
--output_dir ser_funsd_lilt-roberta-en-base
--do_train
--do_predict
--max_steps 2000
--per_device_train_batch_size 8
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_ser_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 2000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_re_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 5000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_ser_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 16000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_re_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 40000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
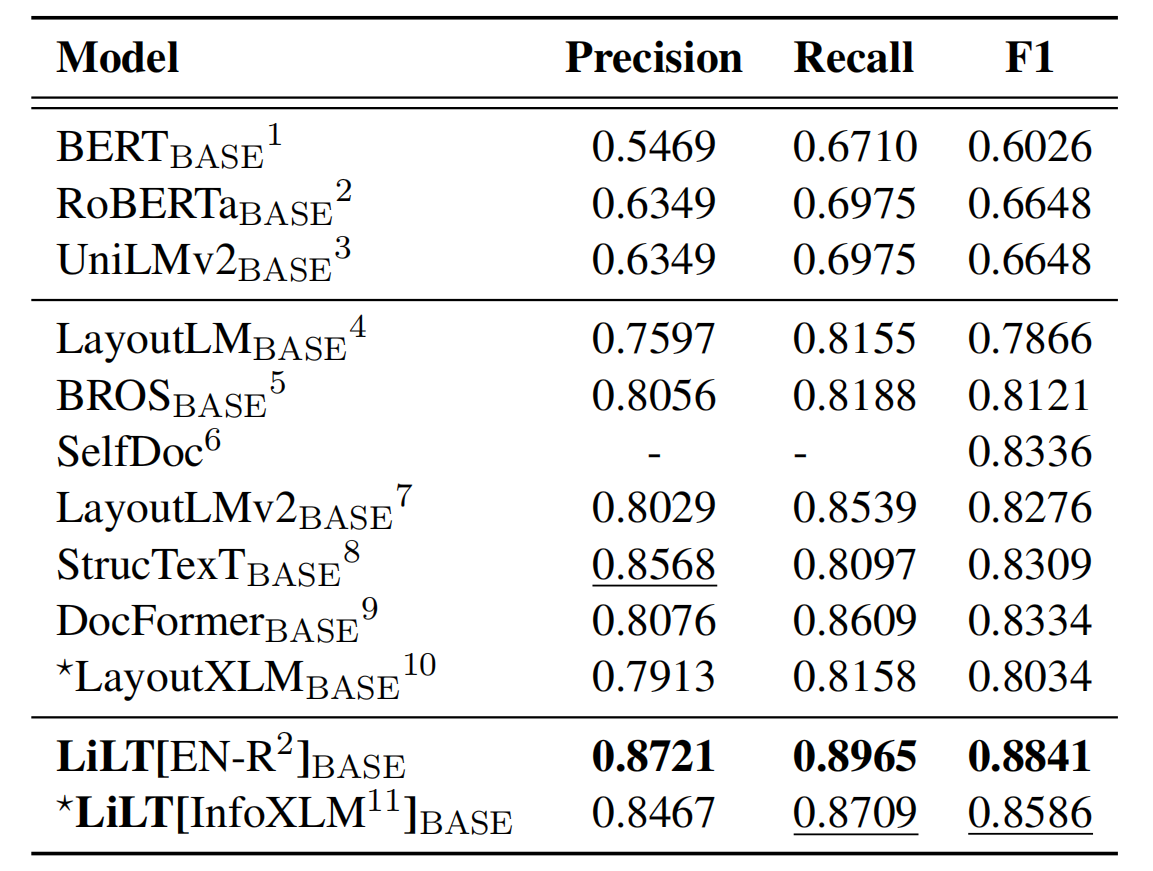
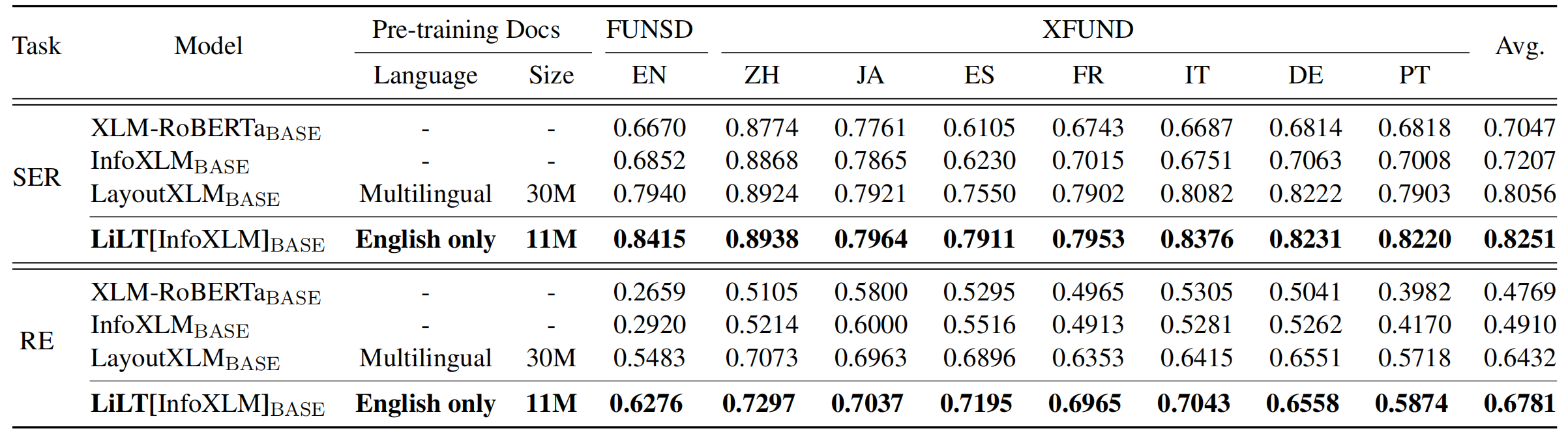
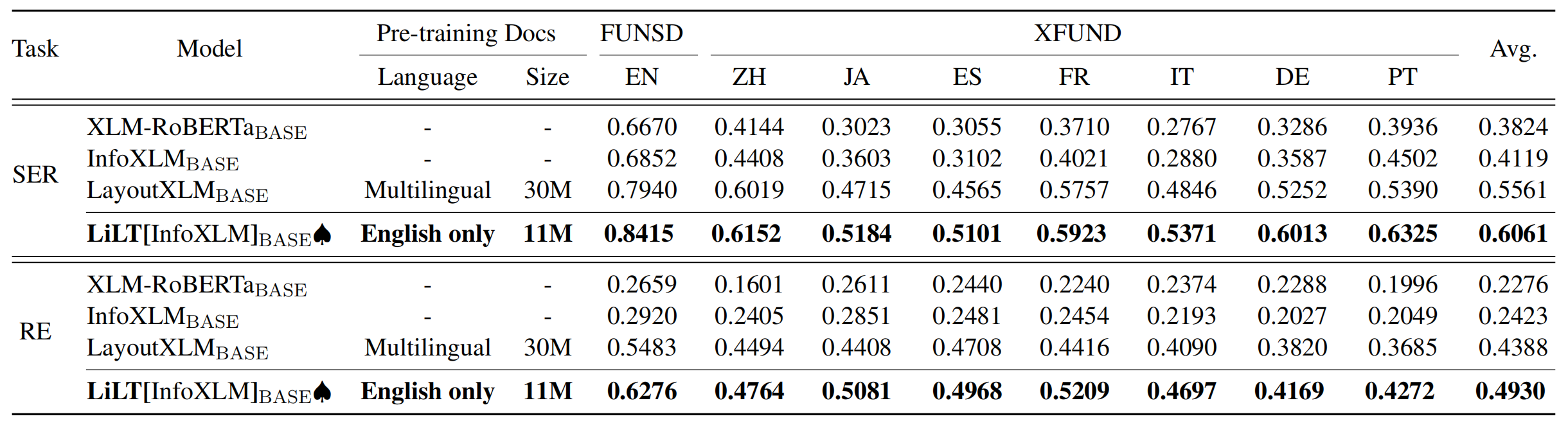
El repositorio se beneficia enormemente de Unilm/Layoutlmft. Muchas gracias por su excelente trabajo.
Si nuestro artículo ayuda a su investigación, cíquelo en su (s) publicación (s):
@inproceedings{wang-etal-2022-lilt,
title = "{L}i{LT}: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding",
author={Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.534",
doi = "10.18653/v1/2022.acl-long.534",
pages = "7747--7757",
}
Las sugerencias y discusiones son muy bienvenidas. Póngase en contacto con los autores enviando correo electrónico a [email protected] .


