LiLT
1.0.0
[2022/10] Lilt ได้รับการเพิ่มลงใน? HuggingFace/Transformers ที่นี่
[2022/03] รุ่นเริ่มต้นและการเปิดตัวรหัส
นี่คือการใช้งาน Pytorch อย่างเป็นทางการของกระดาษ ACL 2022: "Lilt: หม้อแปลงเลย์เอาต์ที่ไม่ขึ้นกับภาษาที่เรียบง่าย แต่มีประสิทธิภาพสำหรับการทำความเข้าใจเอกสารที่มีโครงสร้าง" [เป็นทางการ] [arxiv]
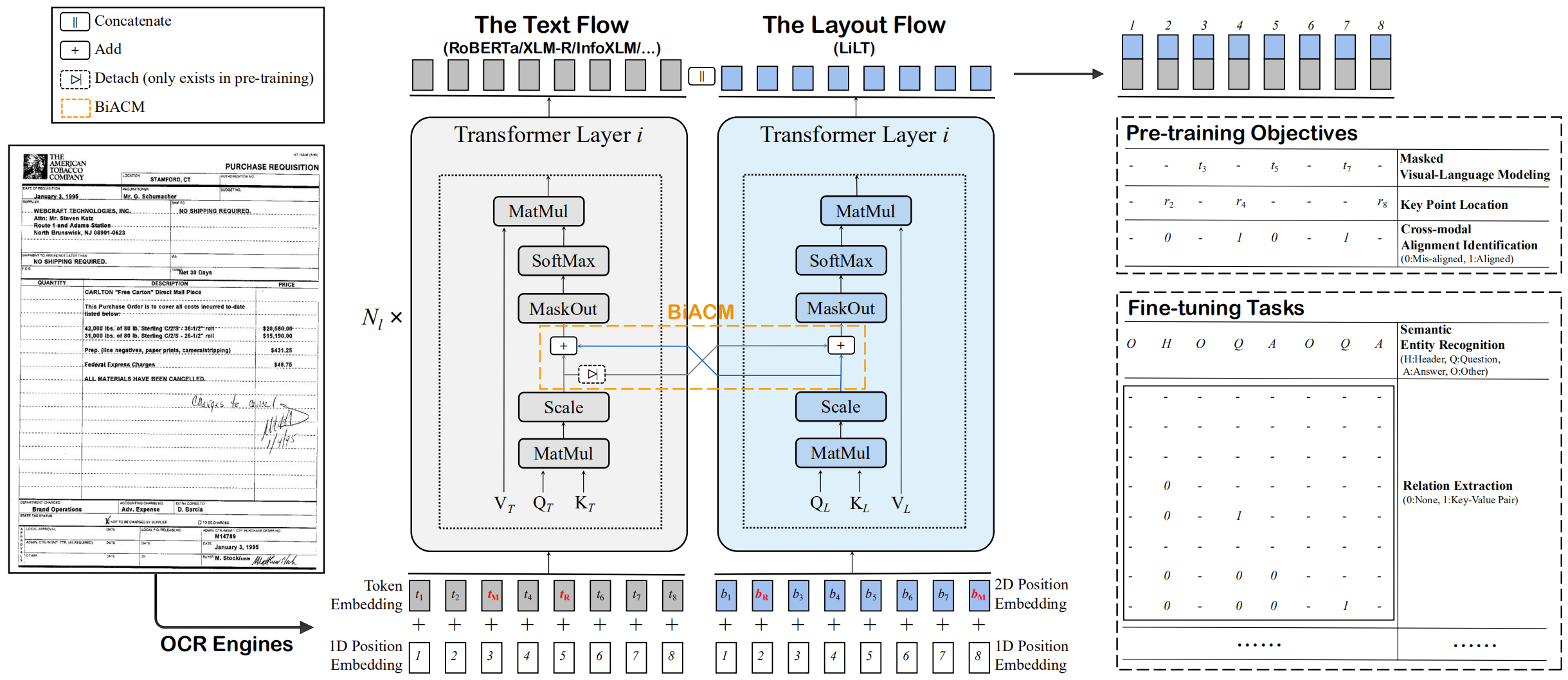
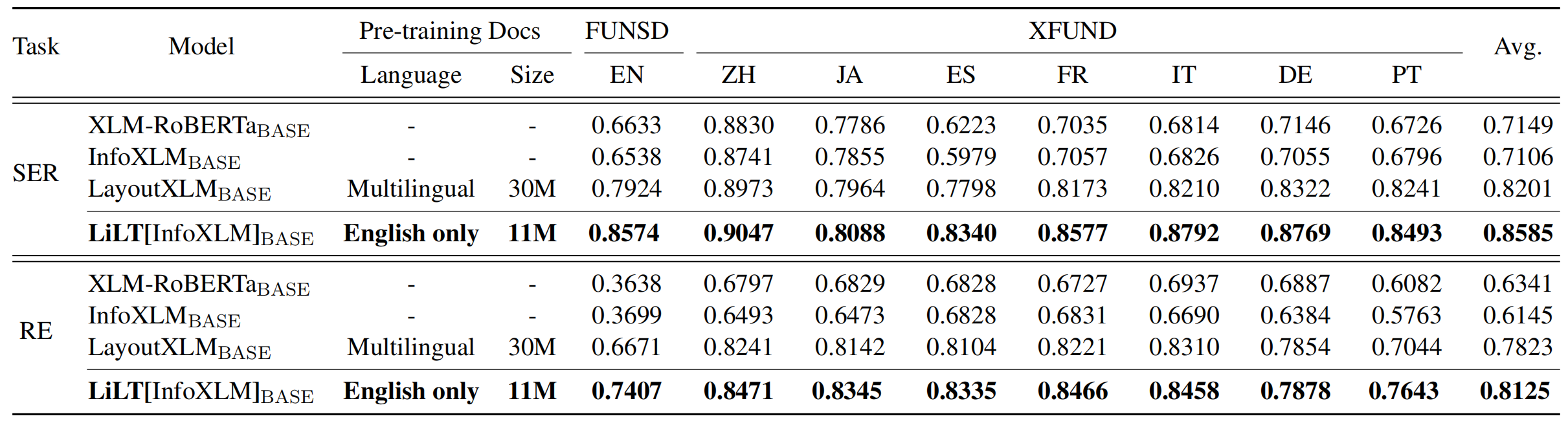
LILT ได้รับการฝึกอบรมล่วงหน้าในเอกสารที่มีความหลากหลายทางสายตาของภาษาเดียว (ภาษาอังกฤษ) และสามารถปรับแต่งได้โดยตรงกับภาษาอื่น ๆ ด้วยโมเดลข้อความที่ได้รับการฝึกฝนมาก่อน/หลายภาษาที่สอดคล้องกัน เราหวังว่าความพร้อมใช้งานสาธารณะของงานนี้สามารถช่วยจัดทำเอกสารการวิจัยข่าวกรอง
สำหรับ cuda 11.x:
conda create -n liltfinetune python=3.7
conda activate liltfinetune
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=11.0 -c pytorch
python -m pip install detectron2==0.5 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
git clone https://github.com/jpWang/LiLT
cd LiLT
pip install -r requirements.txt
pip install -e .หรือตรวจสอบเวอร์ชัน detectron2/pytorch และปรับเปลี่ยนบรรทัดคำสั่งให้เหมาะสม
ในที่เก็บนี้เราให้รหัสการปรับแต่งสำหรับ FunsD และ XFund
คุณสามารถดาวน์โหลด ข้อมูลที่ประมวลผลล่วงหน้าของเรา (~ 1.2GB) ได้จาก ที่นี่ และใส่ xfund&funsd/ Under LiLT/
| แบบอย่าง | ภาษา | ขนาด | การดาวน์โหลด |
|---|---|---|---|
lilt-roberta-en-base | en | 293MB | OneDrive |
lilt-infoxlm-base | มูล | 846MB | OneDrive |
lilt-only-base | ไม่มี | 21MB | OneDrive |
หากคุณต้องการรวม lilt ที่ผ่านการฝึกอบรมมาก่อนเข้ากับ Roberta ของภาษาอื่น โปรดดาวน์โหลด lilt-only-base และใช้ gen_weight_roberta_like.py เพื่อสร้างจุดตรวจสอบที่ผ่านการฝึกอบรมมาก่อน
ตัวอย่างเช่น รวม lilt-only-base กับภาษาอังกฤษ roberta-base :
mkdir roberta-en-base
wget https://huggingface.co/roberta-base/resolve/main/config.json -O roberta-en-base/config.json
wget https://huggingface.co/roberta-base/resolve/main/pytorch_model.bin -O roberta-en-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text roberta-en-base/pytorch_model.bin
--config roberta-en-base/config.json
--out lilt-roberta-en-base หรือรวม lilt-only-base กับ microsoft/infoxlm-base :
mkdir infoxlm-base
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/config.json -O infoxlm-base/config.json
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/pytorch_model.bin -O infoxlm-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text infoxlm-base/pytorch_model.bin
--config infoxlm-base/config.json
--out lilt-infoxlm-base CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_funsd.py
--model_name_or_path lilt-roberta-en-base
--tokenizer_name roberta-base
--output_dir ser_funsd_lilt-roberta-en-base
--do_train
--do_predict
--max_steps 2000
--per_device_train_batch_size 8
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_ser_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 2000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_re_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 5000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_ser_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 16000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_re_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 40000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
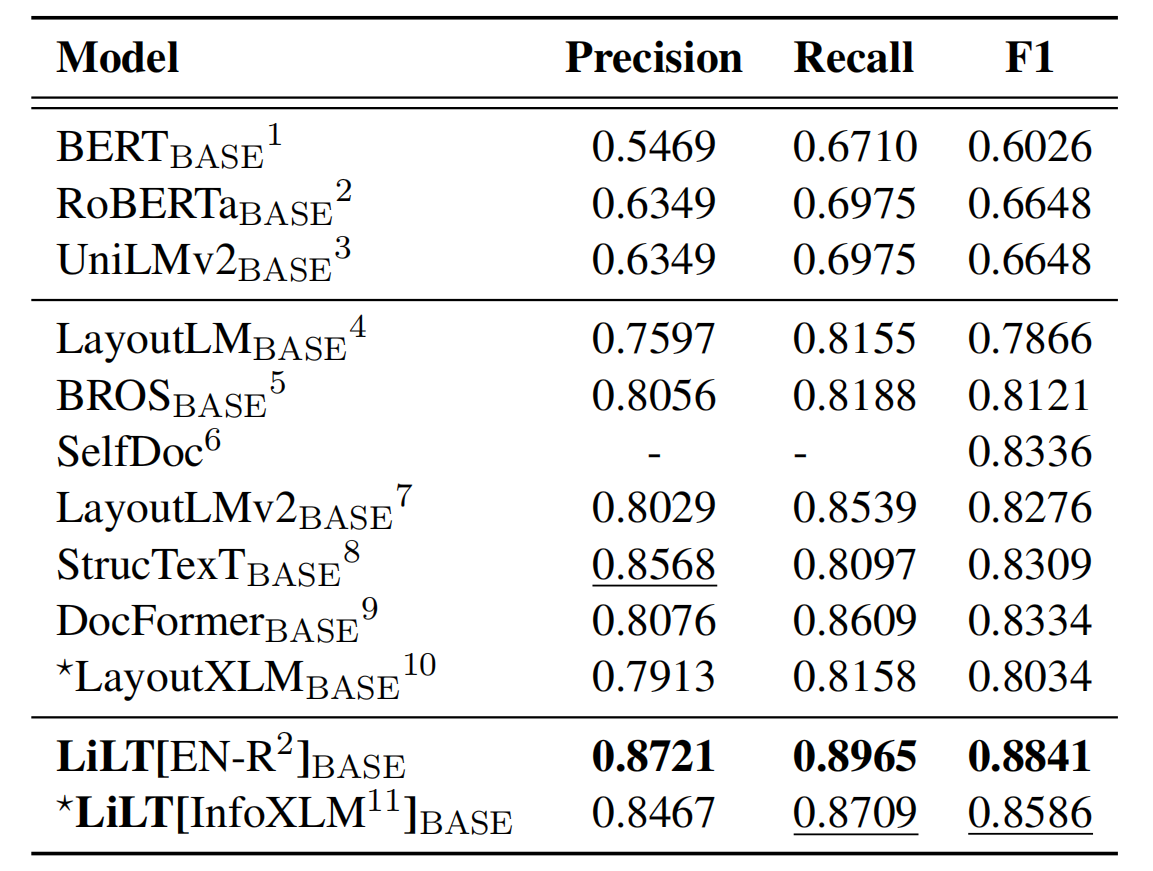
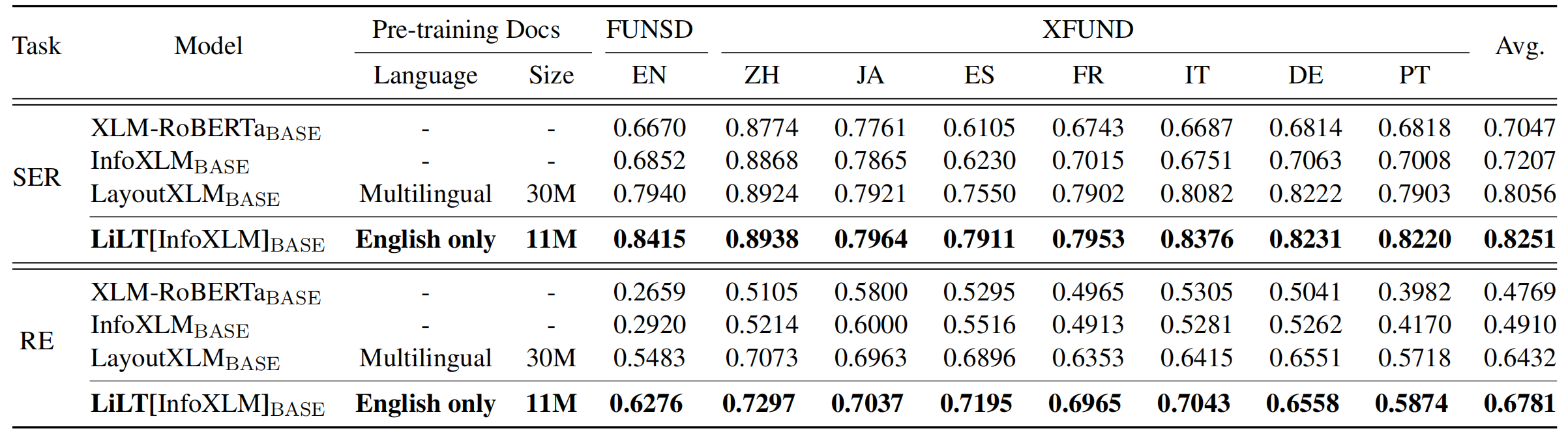
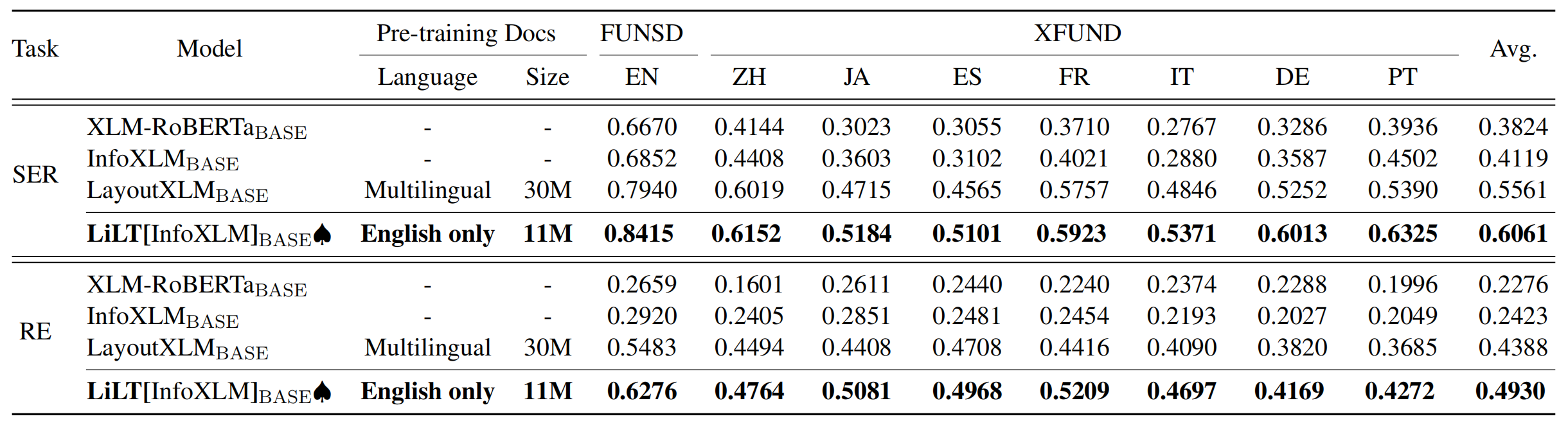
ที่เก็บได้รับประโยชน์อย่างมากจาก Unilm/layoutlmft ขอบคุณมากสำหรับการทำงานที่ยอดเยี่ยมของพวกเขา
หากบทความของเราช่วยงานวิจัยของคุณโปรดอ้างอิงในสิ่งพิมพ์ของคุณ:
@inproceedings{wang-etal-2022-lilt,
title = "{L}i{LT}: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding",
author={Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.534",
doi = "10.18653/v1/2022.acl-long.534",
pages = "7747--7757",
}
ข้อเสนอแนะและการอภิปรายยินดีต้อนรับอย่างมาก กรุณาติดต่อผู้เขียนโดยส่งอีเมลไปที่ [email protected]


