LiLT
1.0.0
[2022/10] Lilt가 여기에 Huggingface/Transformers에 추가되었습니다.
[2022/03] 초기 모델 및 코드 릴리스.
이것은 ACL 2022 논문의 공식 Pytorch 구현입니다. "Lilt : 구조화 된 문서 이해를위한 간단하면서도 효과적인 언어 독립적 인 레이아웃 변압기". [공식] [Arxiv]
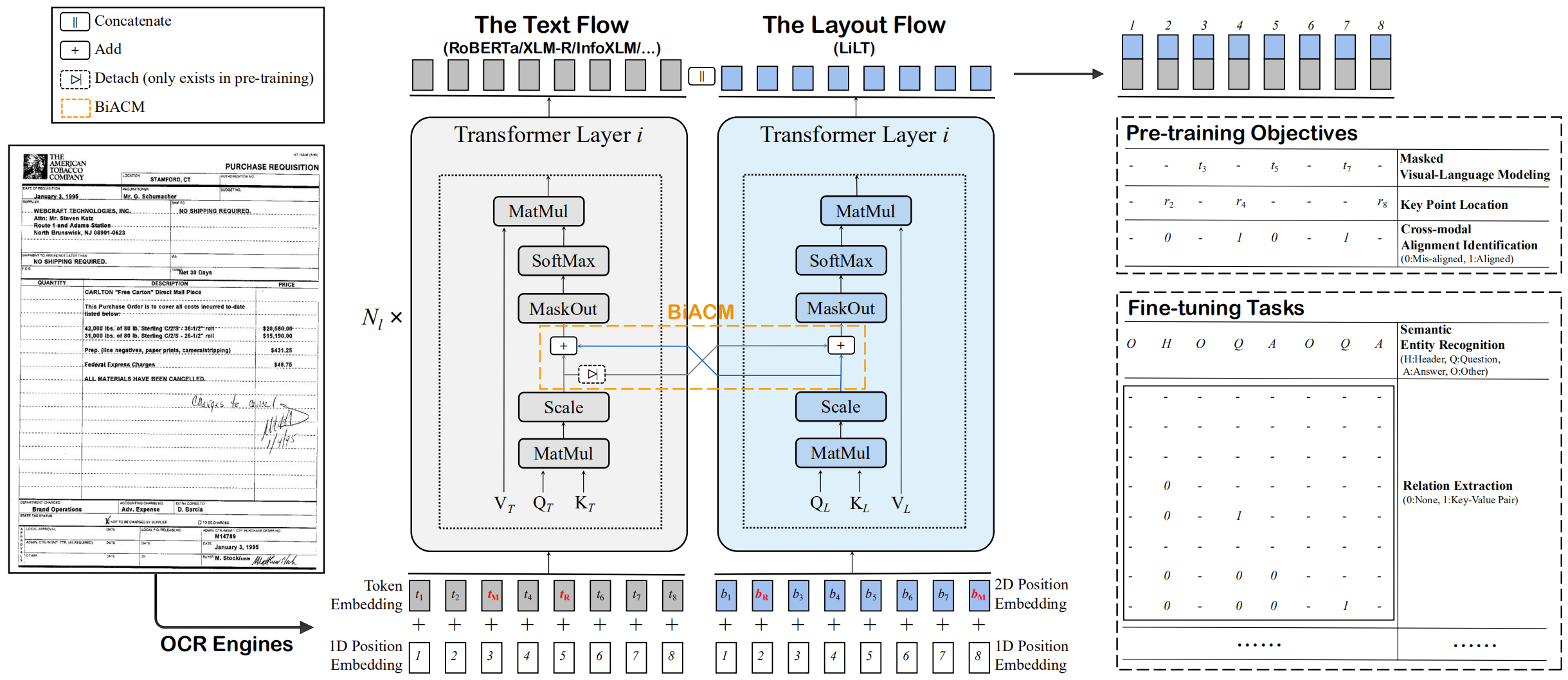
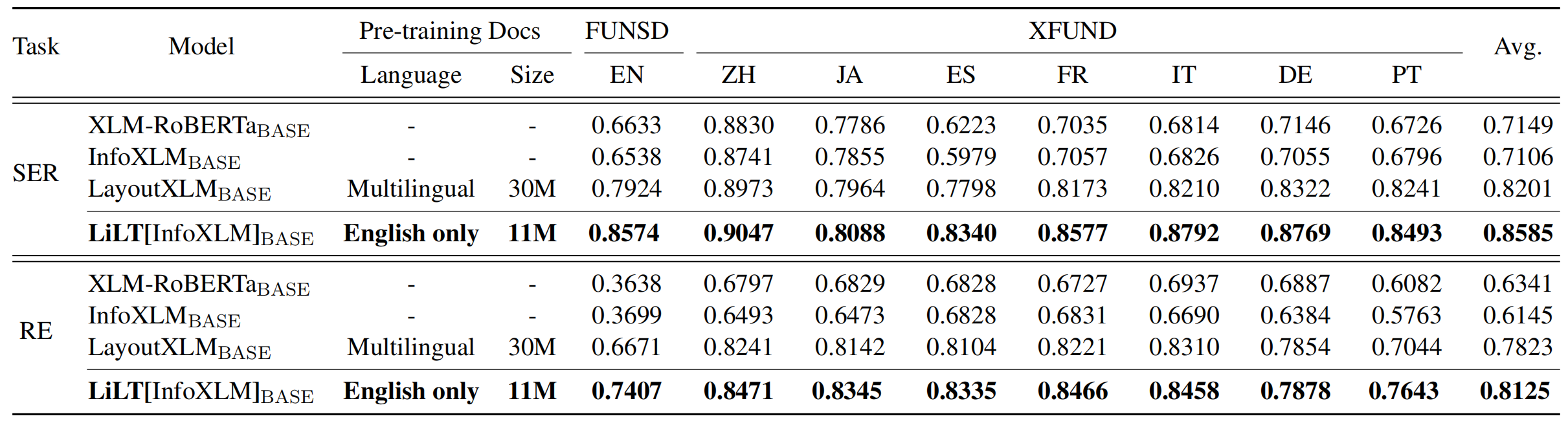
Lilt는 단일 언어 (영어)의 시각적으로 풍부한 문서에서 미리 훈련되며 해당 상용 단일 언어/다국어 사전 훈련 된 텍스트 모델을 사용하여 다른 언어에서 직접 미세 조정할 수 있습니다. 우리는이 작업의 공개 가용성이 인텔리전스 연구를 문서화하는 데 도움이되기를 바랍니다.
Cuda 11.x의 경우 :
conda create -n liltfinetune python=3.7
conda activate liltfinetune
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=11.0 -c pytorch
python -m pip install detectron2==0.5 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
git clone https://github.com/jpWang/LiLT
cd LiLT
pip install -r requirements.txt
pip install -e .또는 Detectron2/Pytorch 버전을 확인하고 그에 따라 명령 줄을 수정하십시오.
이 저장소에서는 FUNSD 및 XFUND에 대한 미세 조정 코드를 제공합니다.
여기 에서 사전 처리 된 데이터 (~ 1.2GB)를 다운로드하고 압축 된 xfund&funsd/ 아래에 LiLT/ 를 배치 할 수 있습니다.
| 모델 | 언어 | 크기 | 다운로드 |
|---|---|---|---|
lilt-roberta-en-base | en | 293MB | OneDrive |
lilt-infoxlm-base | 뮬 | 846MB | OneDrive |
lilt-only-base | 없음 | 21MB | OneDrive |
미리 훈련 된 Lilt와 다른 언어의 Roberta를 결합하려면 lilt-only-base 다운로드하고 gen_weight_roberta_like.py 사용하여 사전 훈련 된 체크 포인트를 생성하십시오.
예를 들어, lilt-only-base 영어 roberta-base 와 결합하십시오.
mkdir roberta-en-base
wget https://huggingface.co/roberta-base/resolve/main/config.json -O roberta-en-base/config.json
wget https://huggingface.co/roberta-base/resolve/main/pytorch_model.bin -O roberta-en-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text roberta-en-base/pytorch_model.bin
--config roberta-en-base/config.json
--out lilt-roberta-en-base 또는 lilt-only-base 와 microsoft/infoxlm-base 결합하십시오.
mkdir infoxlm-base
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/config.json -O infoxlm-base/config.json
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/pytorch_model.bin -O infoxlm-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text infoxlm-base/pytorch_model.bin
--config infoxlm-base/config.json
--out lilt-infoxlm-base CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_funsd.py
--model_name_or_path lilt-roberta-en-base
--tokenizer_name roberta-base
--output_dir ser_funsd_lilt-roberta-en-base
--do_train
--do_predict
--max_steps 2000
--per_device_train_batch_size 8
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_ser_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 2000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_re_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 5000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_ser_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 16000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_re_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 40000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
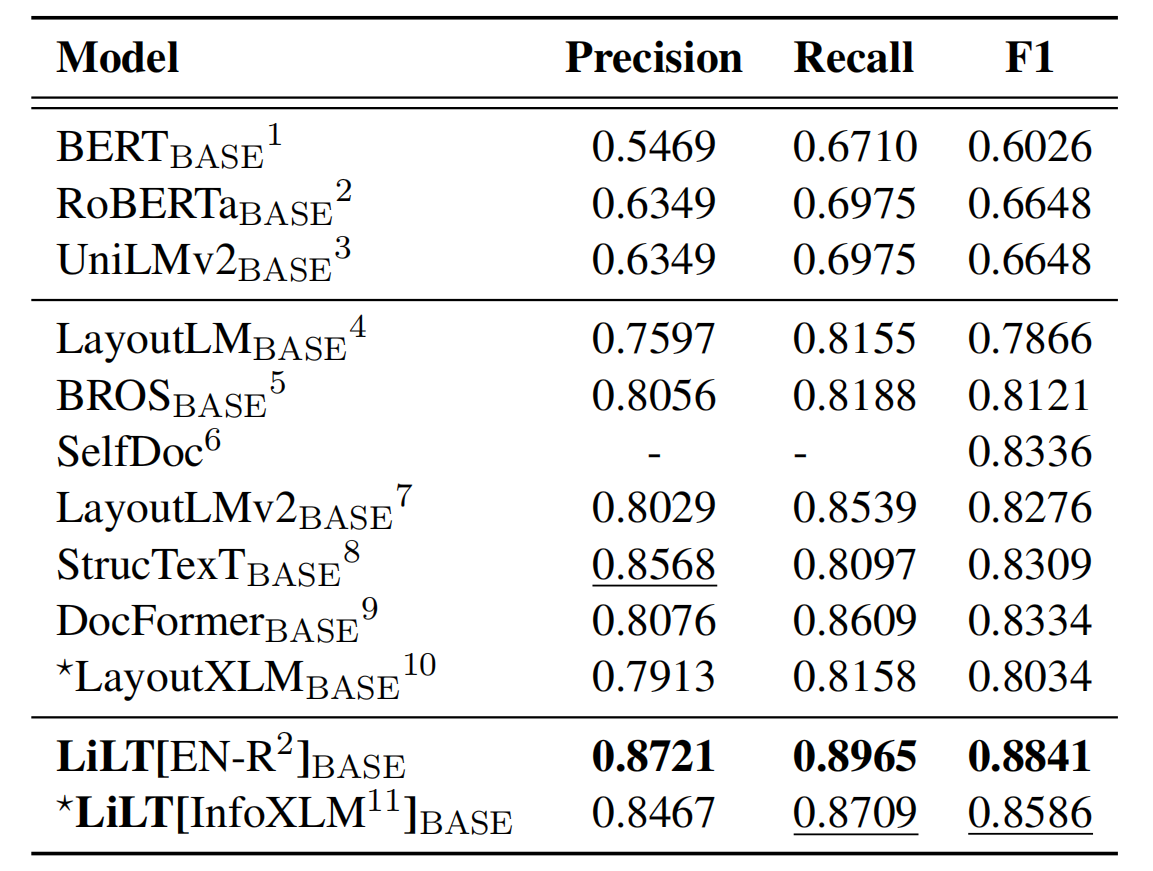
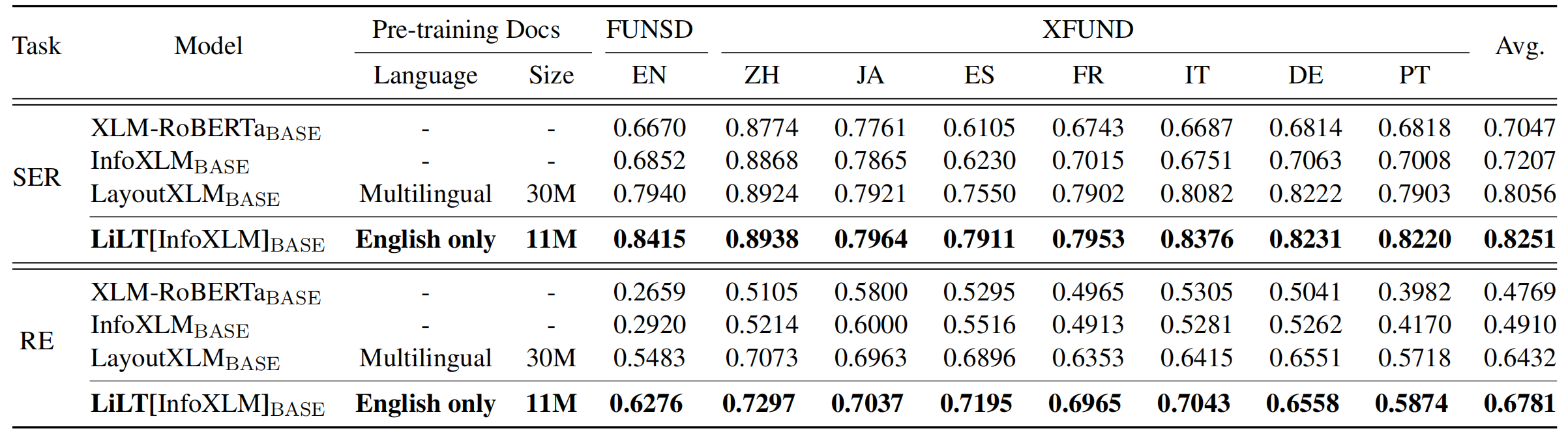
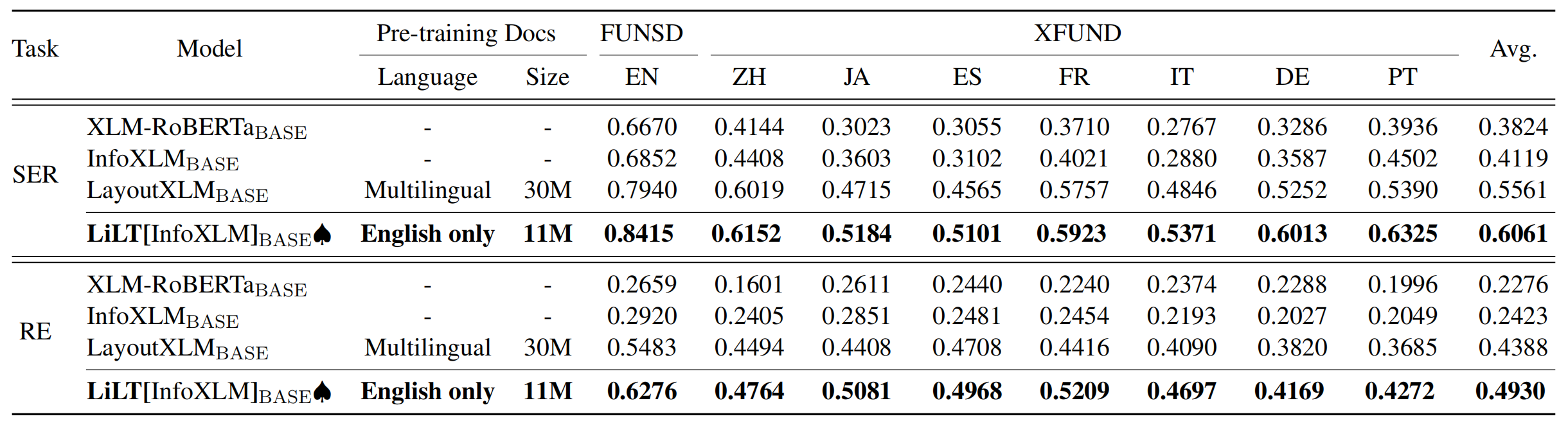
저장소는 UNILM/LAYOUTLMFT에서 크게 이점을 얻습니다. 그들의 훌륭한 작업에 감사드립니다.
우리의 논문이 당신의 연구에 도움이된다면, 당신의 출판물에서 그것을 인용하십시오 :
@inproceedings{wang-etal-2022-lilt,
title = "{L}i{LT}: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding",
author={Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.534",
doi = "10.18653/v1/2022.acl-long.534",
pages = "7747--7757",
}
제안과 토론을 크게 환영합니다. [email protected] 으로 이메일을 보내서 저자에게 문의하십시오.


