Entity Linking Recent Trends
1.0.0
該存儲庫旨在跟踪實體鏈接的進度。還列出瞭如何準備實體表示形式的研究,因為實體表示與實體鏈接是強制性的。
自回家實體檢索
由於知識庫中的實體的事先編碼,由於知識庫中所有實體的比較而導致的計算資源成本以及冷啟動問題,傳統的實體鏈接系統遭受了記憶消耗的影響。
他們不是以前的體系結構,而是利用了一個序列序列,以在上下文中以自動回歸方式生成實體名稱。他們使用受約束的光束搜索,強迫僅解碼有效的實體標識符。
將實體與任意模式聯繫在一起
傳統實體連接系統假定將預測實體聯繫在一起的知識基礎的模式是已知的。他們提出了一種新方法,將未知實體的模式轉換為使用屬性和輔助令牌嵌入BERT嵌入的方法。
同時,他們還提出了一種處理未知屬性的培訓方法。
在媒體中:用於評估命名實體與創意作品的語料庫[論文] [代碼]
路加福音:具有實體感知的自我注意力[link] [codes]的深層上下文化實體表示
他們提出了基於BERT的新預讀任務,其中在Wikipedia的實體註銷語料庫中預測了隨機掩蓋的單詞和實體。
同樣在訓練任務中,他們提出了變壓器的擴展版本,該版本考慮實體覺醒的自我注意力以及計算注意力分數時的令牌(單詞或實體)類型。
可擴展的零擊實體與密集實體檢索鏈接
實體鏈接100種語言[紙]
COMETA:社交媒體中鏈接的醫學實體語料庫[論文]
零拍攝實體與有效的遠程序列建模鏈接[紙]
從零到英雄:在低資源域中鏈接的人類在線實體[鏈接]
改善通過語義增強實體嵌入鏈接的實體
預讀的百科全書:弱監督的知識語語言模型(ICLR'20)[紙]
K-Audapter:將知識注入適配器的預訓練模型[紙]
通過建模潛在實體類型信息(AAAI'20)論文來改善實體鏈接
零射擊實體與密集實體檢索鏈接(11月10日)論文
類似於[Logeswaran等,ACL'19]和[Gillick等,Conll'19]
幻燈片(非官方)
通過雙重和跨注意編碼鏈接的實體[ARXIV]
實體鏈接的細粒度評估(EMNLP'19)
全球實體鏈接的學習動態環境增強(EMNLP'19)
用於域獨立實體鏈接的細粒度實體鍵入
通過簡單的神經端到端實體鏈接(Conll '19)[紙]調查BERT中的實體知識
學習實體檢索的密集表示(Conll '19)
紙,回購
他們提出了不使用別名表(基於Wikipedia統計或準備的),並通過蠻力/大約最近搜索搜索所有實體,以搜索所有實體。
Enteval:實體表示的整體評估基準(EMNLP '19)
Wikipedia類別重建的學習實體表示(ICLR '19)
知識增強上下文單詞表示(EMNLP '19)[紙]
利用所有信息的趨勢(例如,提到存在的類型,定義和文檔等等等等)似乎正在消失。
儘管Wikipedia域可以使用其超鏈接(=提及 - 實用對,約7,500,000)進行訓練鏈接模型,但是在某些特定領域的情況下,沒有太多提及的實體對。
因此,現在有些論文挑戰了遙遠學習的實體鏈接學習和零射擊學習。
遙遠的學習
與自動噪聲檢測鏈接的實體的遙遠學習
幻燈片(非官方)
他們提出將EL框架作為遙遠的學習問題,其中沒有標記的培訓數據,並為此任務推遲了納入模型。
通過利用未標記的文檔來提高實體鏈接性能
零擊鏈接
通過閱讀實體說明鏈接零擊實體鏈接
幻燈片(非官方)
他們提出了零照片EL,在訓練過程中看不到測試。為了解決零拍攝的EL,他們提出了用於培訓語言模型的領域自適應策略。另外,他們表明提及的描述對EL至關重要。
基於BERT的實體表示學習也出現了。
(評論 @ Nov,19')那時,改善實體鏈接模型本身的研究正在蓬勃發展。
粗體樣式表示其特定數據集的SOTA分數。
| 基線模型 | 年 | 數據集 | 代碼 | 跑步? | 代碼地址 |
|---|---|---|---|---|---|
| 實體通過類型,描述和上下文的聯合編碼鏈接 | EMNLP2017 | Conll-Yago(82.9,ACC),ACE2004,ACE2005,Wiki( 89.0 ,F1) | 張量 | 僅上傳火車模型 | 這裡 |
| ┗(與上述非常相似)跨語義實體鏈接的聯合多語言監督 | EMNLP2018 | TH-TEST,MCN檢驗,TAC2015 | Pytorch | 檢查 | 這裡 |
| 神經集體實體鏈接(NCEL) | CL2018 | Conll-Yago,ACE2004,Aquaint,TAC2010( 91.0 ,MIC-P),WW | Pytorch | 漏洞 | 這裡 |
| 通過對提及之間的潛在關係建模來改善實體鏈接 | ACL2018 | Conll-Yago( 93.07 ,MIC-ACC),Aquaint,ACE2004,CWEB,Wiki(84.05,F1) | Pytorch | 評估完成 | 這裡 |
| 埃爾登 | NAACL2018 | Conll-PPD(93.0,P-MIC),TAC2010(89.6,MIC-P) | Lua,火炬(LUA) | 漏洞 | 這裡 |
| 深處聯合實體歧義,局部神經關注 | EMNLP2017 | Conll-Yago(92.22,MIC-ACC),CWEB,WW,ACE2004,Aquaint,MSNBC | Lua,火炬(LUA) | 火車跑步(2019/01/15) | 這裡 |
| 用於細粒實體的分層損失和新資源分型和鏈接 | ACL2018 | Medentions,Typenet | Pytorch | 漏洞 | 這裡 |
| 聯合學習命名實體歧義的單詞和實體的嵌入(Yamada,Shindo) | Conll2016 | Conll-Yago(91.5,MIC-ACC),Conll-PPD(93.1,P-MIC),TAC2010(85.5,MIC-ACC) | pytorch/tensorflow(原始),, | 檢查 | 基線原件 |
| 從知識庫(Yamada,Shindo)學習文本和實體的分佈式表示形式 | ACL2017 | Conll-PPD( 94.7 ,P-MIC),TAC2010(87.7,MIC-ACC) | Pytorch/keras(原始) | 檢查 | 火炬,火炬,原始 |
注意:基準測試此任務的主要數據集在Blink存儲庫中列出。
mewsli-9數據集
生物醫學
Medentions([Mohan and Li,AKBC '19])
Med Mentions是作為基準數據集創建的,用於在生物醫學領域中命名的實體識別和鏈接的實體。
由於它包含了許多概念,這些概念太廣泛而無法實際使用,因此ST21PV的構建是通過從飲食中濾除那些廣泛的概念來構建的。
BC5CDR([Li等,'15'])
BC5CDR是為生物抗衡性V化學和疾病提及識別任務而創建的數據集。
它包含1,500篇文章,其中包含15,935種化學物質和12,852種疾病提及。
參考知識基礎是網格,幾乎所有提及在參考知識基礎中都有一個黃金實體。
Wikimed和PubMedds([Shikhar等,'20])
Wikimed包括超過650,000個提及,將其標準化為UMLS的概念。 (引用)
此外,他們創建了帶有超過500萬個標準化的註釋PubMedds。請注意,該數據集是由遙遠的監督創建的,這導致引起一些嘈雜的註釋。
零射
Wikia數據集([[Logeswaran等,'19])
從Wikia超鏈接及其相關主題中,他們創建了用於評估實體鏈接任務的域概括的數據集。
他們創建了16個世界數據集,這些數據集被分為火車 /開發 /測試的8/4/4,並且完全獨立。
由於[Gillick等人,Conll'19]首先提出了用於實體鏈接的BI-(或雙 - 雙 - )編碼系統,因此一些論文還利用了BERT。 [Gillick et al。 ,'18]也提出了基於生物編碼器的檢索系統的原始想法。
正如Wu等人,2020年所示,多型編碼器也可以應用於實體鏈接。
基於變壓器的編碼器通常用於提及和實體編碼。
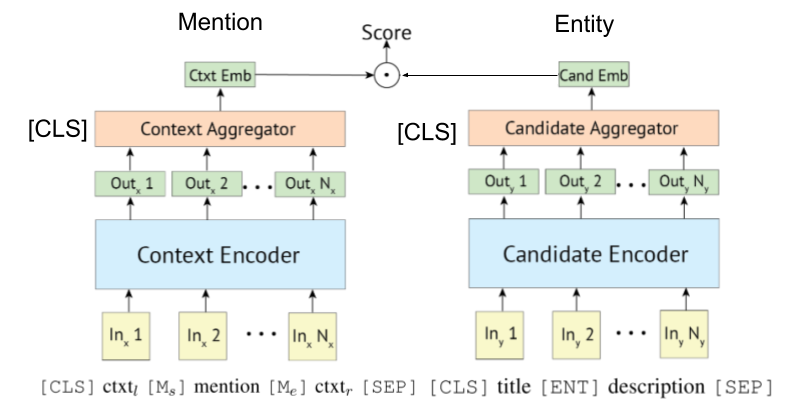
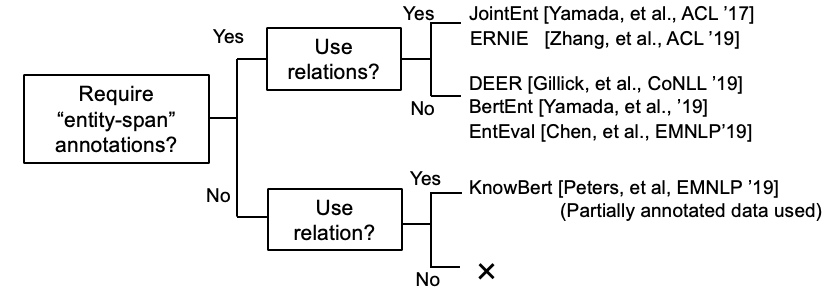
一些研究現在正在嘗試將KB信息與Bert合併。
開普勒:一個統一的知識嵌入和預訓練的語言表示模型(在19月119日,在進行中工作)
將圖形上下文知識集成到預訓練的語言模型中(在進行中工作 @ dec,'19)
K-Bert:通過知識圖啟用語言表示
[Petroni等,'19]檢查了Bert本身是否具有事實知識。
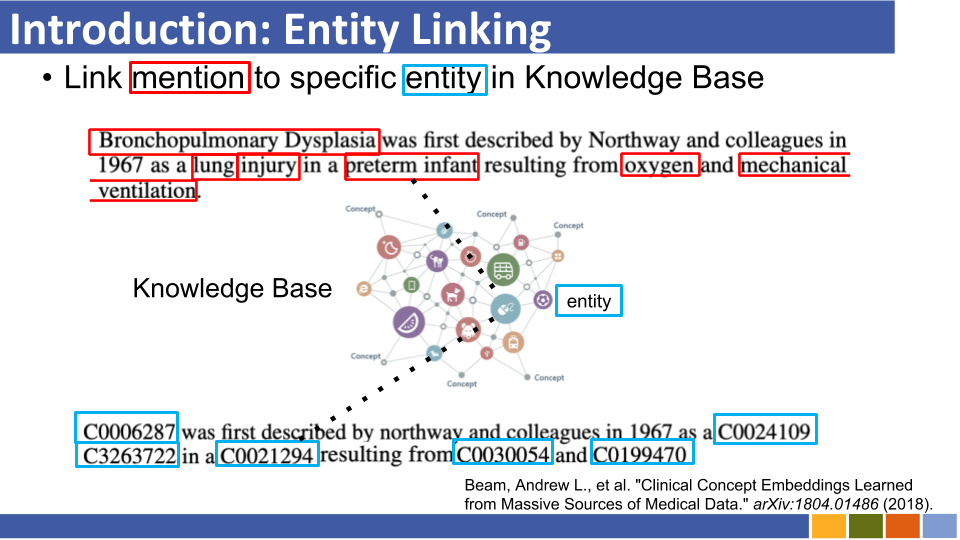
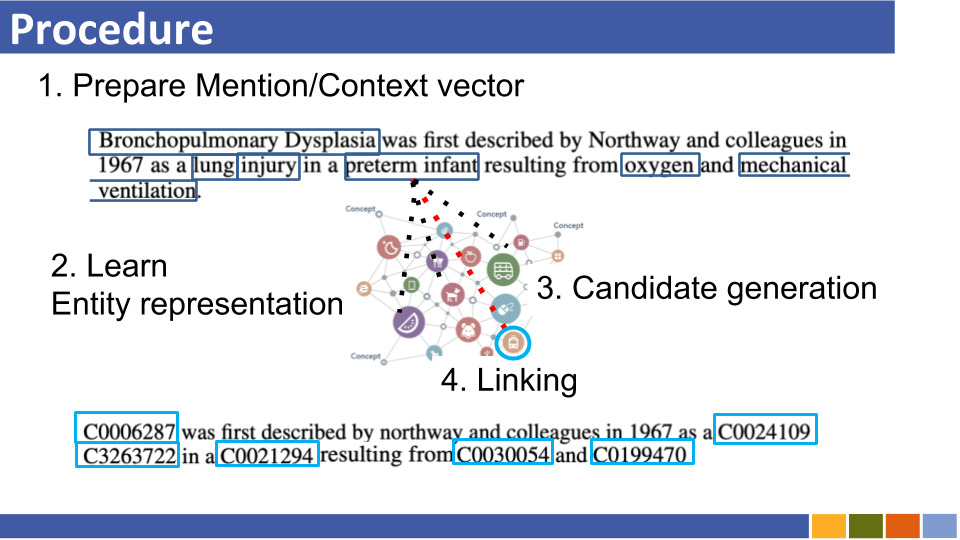
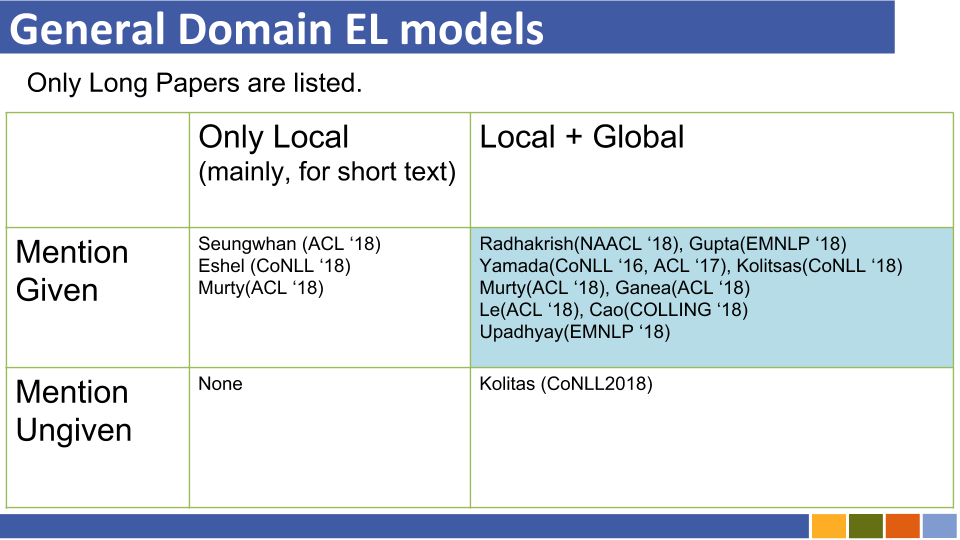
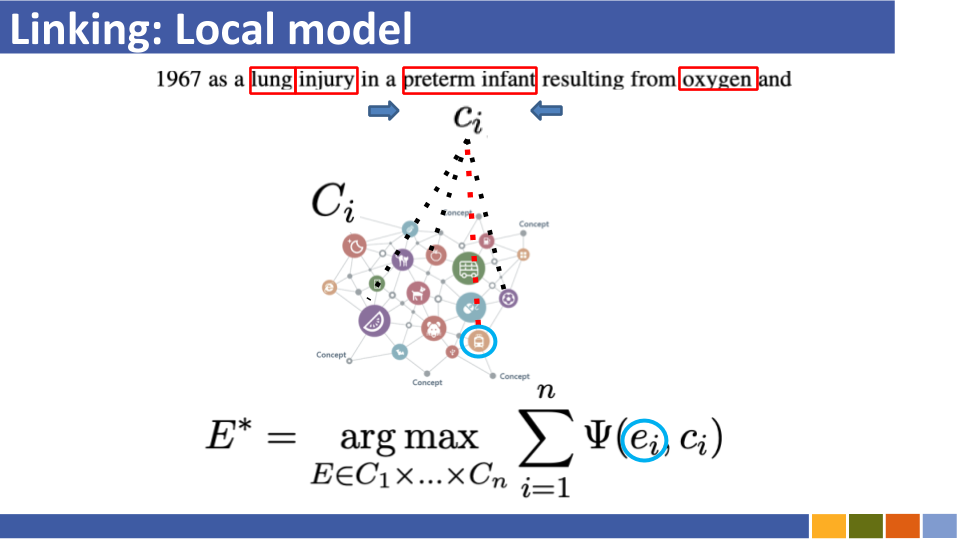
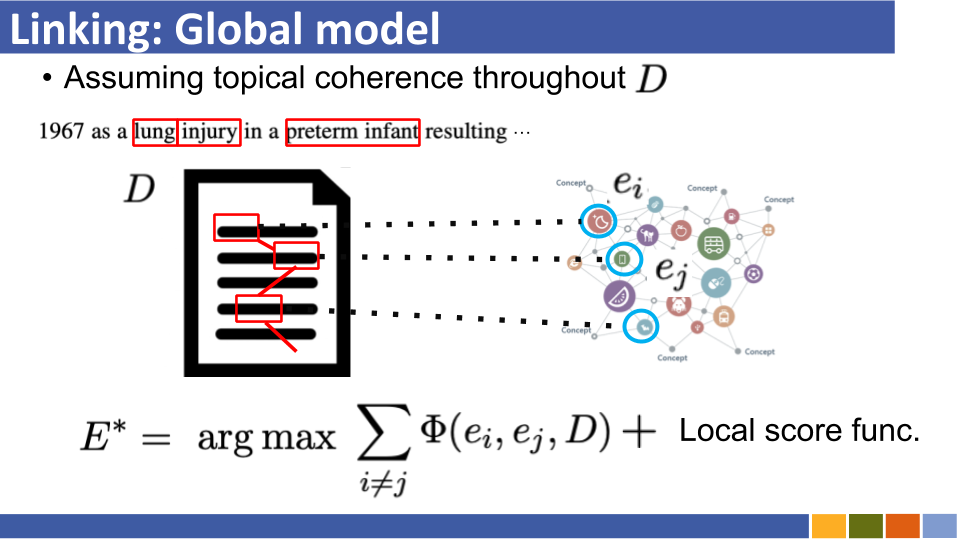
基於雙重編碼的實體將教程及其實施鏈接。 [關聯]
已經出現了綜合的實體鏈接調查文件。
(評論 @ 2020年3月)當前該存儲庫包括用於實體鏈接和實體LM的論文。前者需要編碼實體表示以進行歧義,而後者則意味著在培訓期間將實體知識注入LM。因此,它們完全不同,儘管某些實體LM的工作通過實體歧義評估了其模型。我們將在不久的將來將它們分開。
跨語言EL論文。
引用了Gupta等人。 (EMNLP '18)
跨語性實體鏈接(XEL)旨在以任何語言寫入英語知識庫(KB)(例如Wikipedia)的基礎實體提及。
跨語性實體鏈接的聯合多語言監督(EMNLP '18)
朝向零資源跨語言實體聯繫(Shuyan等人,EMNLP研討會'19)
實體鏈接嘈雜/短文
短文本實體鏈接(ACL'18)[紙]的匯總語義匹配
在嘈雜的實體鏈接(EMNLP'18)[紙]中有效使用上下文
多模式實體鏈接
其他一些論文
僅清單實體鏈接紙
聯合學習指定實體識別和鏈接紙的實體


