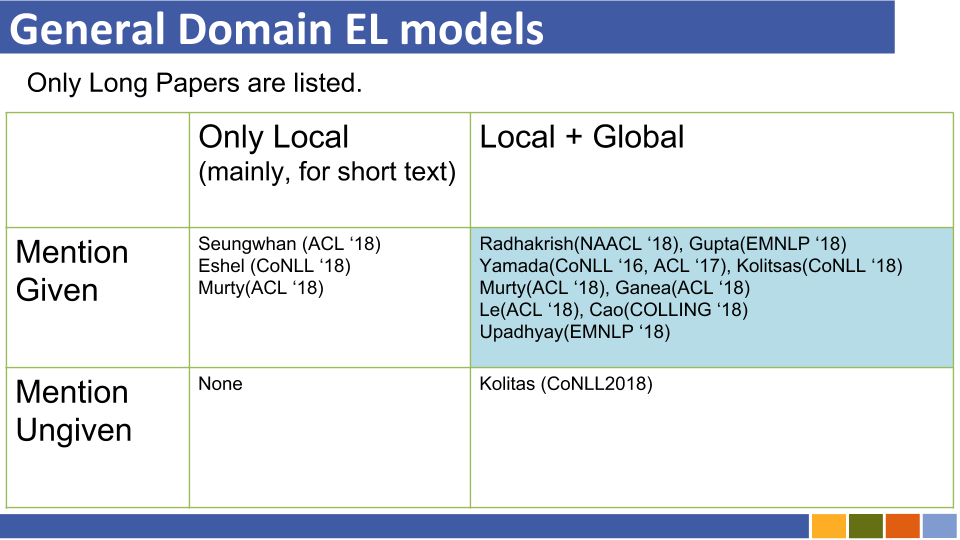
Entity Linking Recent Trends
1.0.0
Repositori ini bertujuan untuk melacak kemajuan dalam tautan entitas. Studi tentang cara mempersiapkan representasi entitas juga terdaftar, karena representasi entitas wajib dengan penghubung entitas.
Pengambilan Entitas Autoregresif
Sistem yang menghubungkan entitas tradisional menderita konsumsi memori karena pengkodean entitas sebelumnya dalam basis pengetahuan, biaya sumber daya komputasi karena perbandingan semua entitas dalam basis pengetahuan, dan masalah awal yang dingin.
Alih-alih arsitektur sebelumnya, mereka mengeksploitasi urutan ke urutan untuk menghasilkan nama entitas dengan cara autoregresif yang dikondisikan pada konteks. Mereka menggunakan pencarian balok terbatas, memaksa untuk hanya mendekode pengidentifikasi entitas yang valid.
Menghubungkan entitas ke basis pengetahuan yang tidak terlihat dengan skema sewenang -wenang
Sistem yang menghubungkan entitas tradisional mengasumsikan bahwa skema basis pengetahuan yang mengikat entitas yang diprediksi bersama -sama diketahui. Mereka mengusulkan metode baru untuk mengonversi skema entitas yang tidak diketahui menjadi embedding Bert menggunakan atribut dan token tambahan.
Pada saat yang sama, mereka juga mengusulkan metode pelatihan untuk menangani atribut yang tidak diketahui.
In Media Res: Corpus untuk mengevaluasi entitas bernama Linking dengan Creative Works [Paper] [Kode]
Luke: Representasi entitas kontekstual yang mendalam dengan perhatian-perhatian-diri [tautan] [kode]
Mereka mengusulkan tugas pretraining baru berdasarkan Bert, di mana kata-kata dan entitas bertopeng secara acak diprediksi dalam corpus yang dianotasi entitas dari Wikipedia.
Juga dalam tugas pretraining, mereka mengusulkan versi yang diperluas dari transformator, yang mempertimbangkan suatu perhatian yang sadar diri dan jenis token (kata atau entitas) saat menghitung skor perhatian.
Entitas zero-shot yang dapat diskalakan yang menghubungkan dengan pengambilan entitas padat
Entitas menghubungkan dalam 100 bahasa [kertas]
COMETA: Corpus untuk entitas medis yang menghubungkan di media sosial [kertas]
Entitas zero-shot yang menghubungkan dengan pemodelan urutan jangka panjang yang efisien [kertas]
Dari nol ke pahlawan: entitas manusia-in-loop yang menghubungkan di domain sumber daya rendah [tautan]
Meningkatkan entitas yang menghubungkan melalui semantik yang diperkuat entitas embeddings
Encyclopedia Pretrained: Model Bahasa Pretrained Pengetahuan yang diawasi dengan lemah (ICLR'20) [Kertas]
K-Adapter: Mengenakan pengetahuan ke dalam model pra-terlatih dengan adaptor [kertas]
Meningkatkan Entity Linking dengan Memodelkan Kertas Jenis Entitas Laten (AAAI'20) Kertas
Entitas Zero-Shot Linking dengan Paden Entity Retrieval (10, Nov) Kertas
Mirip dengan [Logeswaran, et al., Acl'19] dan [Gillick, et al., Conll'19]
slide (tidak resmi)
Entitas yang menghubungkan melalui encoder ganda dan silang [ARXIV]
Evaluasi berbutir halus untuk penghubung entitas (EMNLP'19)
Pembelajaran Konteks Dinamis Augmentasi untuk Linking Entitas Global (EMNLP'19)
Pengetikan entitas berbutir halus untuk tautan entitas independen domain
Investigasi Pengetahuan Entitas dalam Bert dengan Simple Neural End-to-End Linking (Conll '19) [Kertas]
Belajar representasi padat untuk pengambilan entitas (Conll '19)
Kertas, repo
Mereka tidak mengusulkan penggunaan tabel alias (yang didasarkan pada statistik wikipedia atau menyiapkan satu) dan mencari semua entitas dengan force brute/perkiraan pencarian terdekat untuk menghubungkan entitas per penyebutan.
Enteval: Benchmark Evaluasi Holistik untuk Representasi Entitas (EMNLP '19)
Representasi Entitas Pembelajaran untuk beberapa Rekonstruksi Kategori Wikipedia (ICLR '19)
Pengetahuan yang Ditingkatkan Representasi Kata Kontekstual (EMNLP '19) [Kertas]
Tren memanfaatkan semua informasi (mis. Jenis dan definisi dan dokumen yang disebutkan di mana ada, dll ...) tampaknya disangkal.
Meskipun domain Wikipedia dapat menggunakan hyperlink-nya (= pasangan yang menyebutkan-entitas, sekitar 7.500.000) untuk model penghubung pelatihan, di bawah beberapa situasi khusus domain tidak ada banyak pasangan yang disebutkan.
Oleh karena itu, beberapa makalah sekarang menantang pembelajaran jauh dan pembelajaran zero-shot dari entitas yang menghubungkan.
Pembelajaran yang jauh
Pembelajaran jauh untuk entitas yang menghubungkan dengan deteksi kebisingan otomatis
slide (tidak resmi)
Mereka mengusulkan membingkai EL sebagai masalah pembelajaran yang jauh, di mana tidak ada data pelatihan berlabel yang tersedia, dan menghilangkan model untuk tugas ini.
Meningkatkan entitas yang menghubungkan kinerja dengan memanfaatkan dokumen yang tidak berlabel
Tautan Zero-Shot
Entitas zero-shot menghubungkan dengan membaca deskripsi entitas
slide (tidak resmi)
Mereka mengusulkan zero-shot el, di mana tidak ada tes yang menyebutkan dapat dilihat selama pelatihan. Untuk mengatasi zero-shot el, mereka mengusulkan strategi domain-adaptif untuk model bahasa pra-pelatihan. Juga, mereka menunjukkan bahwa deskripsi yang menyebutkan-entitas silang sangat penting untuk EL.
Pembelajaran representasi entitas berbasis Bert juga muncul.
(Berkomentar @ Nov, 19 ') Pada masa itu, penelitian untuk meningkatkan model penghubung entitas itu sendiri berkembang.
Gaya tebal menunjukkan skor SOTA dari dataset tertentu.
| Model Baseline | Tahun | Dataset | kode | Berlari? | Alamat kode |
|---|---|---|---|---|---|
| Entitas menghubungkan melalui pengkodean bersama jenis, deskripsi, dan konteks | EMNLP2017 | Conll-Yago (82.9, ACC), ACE2004, ACE2005, Wiki ( 89.0 , F1) | Tensorflow | Hanya model traind yang diunggah | Di Sini |
| ┗ (Sangat mirip dengan yang di atas) Pengawasan multibahasa sendi untuk menghubungkan entitas lintas-bahasa | EMNLP2018 | Tes TH, MCN-Test, TAC2015 | Pytorch | Memeriksa | Di Sini |
| Saraf Kolektif Linking (NCEL) | CL2018 | Conll-Yago, ACE2004, Aquaint, TAC2010 ( 91.0 , MIC-P), WW | Pytorch | Serangga | Di Sini |
| Meningkatkan entitas yang menghubungkan dengan memodelkan hubungan laten antara menyebutkan | ACL2018 | Conll-Yago ( 93.07 , Mic-ACC), Aquaint, ACE2004, CWEB, Wiki (84.05, F1) | Pytorch | Evaluasi dilakukan | Di Sini |
| Elden | NAACL2018 | Conll-PPD (93.0, P-MIC), TAC2010 (89.6, MIC-P) | Lua, obor (Lua) | Serangga | Di Sini |
| Disambiguasi entitas sendi yang dalam dengan perhatian saraf setempat | EMNLP2017 | Conll-Yago (92.22, Mic-ACC), CWEB, WW, ACE2004, Aquaint, MSNBC | Lua, obor (Lua) | Berlari kereta (2019/01/15) | Di Sini |
| Kerugian hierarkis dan sumber daya baru untuk pengetikan dan tautan entitas yang halus | ACL2018 | Peredaran, typenet | Pytorch | Serangga | Di Sini |
| Pembelajaran bersama tentang penyematan kata dan entitas untuk disambiguasi entitas bernama (Yamada, Shindo) | Conll2016 | Conll-Yago (91.5, MIC-ACC), Conll-PPD (93.1, P-MIC), TAC2010 (85.5, MIC-ACC) | pytorch/tensorflow (asli), | memeriksa | Baseline asli |
| Belajar representasi teks dan entitas yang didistribusikan dari basis pengetahuan (Yamada, Shindo) | ACL2017 | Conll-PPD ( 94.7 , P-MIC), TAC2010 (87.7, MIC-ACC) | Pytorch/keras (asli) | memeriksa | Obor, obor, asli |
CATATAN: Dataset utama untuk pembandingan tugas ini terdaftar di Blink Repository.
Dataset Mewsli-9
Biomedis
MedMentions ([Mohan dan Li, AKBC '19])
Medmentions dibuat sebagai dataset patokan untuk pengakuan entitas yang disebutkan dan entitas yang menghubungkan dalam domain biomedis.
Karena mengandung banyak konsep yang terlalu luas untuk digunakan secara praktis, ST21PV dibangun dengan menyaring konsep -konsep luas dari medis.
BC5CDR ([Li et al., '15'])
BC5CDR adalah dataset yang dibuat untuk tugas pengenalan kimia dan penyakit biokreatatif.
Ini terdiri dari 1.500 artikel, yang mengandung 15.935 kimia dan 12.852 penyakit menyebutkan.
Basis pengetahuan referensi adalah mesh, dan hampir semua menyebutkan memiliki entitas emas di basis pengetahuan referensi.
Wikimed dan PubMedds ([Shikhar et al., '20])
Wikimed mencakup lebih dari 650.000 menyebutkan yang dinormalisasi untuk konsep -konsep di UML. (Dikutip)
Juga, mereka menciptakan Corpus PubMedds beranotasi dengan lebih dari 5 juta menyebutkan dinormalisasi. Perhatikan bahwa dataset ini dibuat oleh pengawasan yang jauh, yang menyebabkan menyebabkan beberapa anotasi yang berisik.
Zero-shot
Dataset Wikia ([Logeswaran et al., '19])
Dari hyperlink wikia dan tema terkaitnya, mereka menciptakan dataset untuk mengevaluasi generalisasi domain dari tugas yang menghubungkan entitas.
Mereka menciptakan 16 Worlds Dataset, yang dibagi menjadi 8/4/4 untuk kereta / dev / tes dan sepenuhnya independen untuk satu sama lain.
Karena [Gillick et al., Conll'19] pertama-tama mengusulkan sistem pengambilan enkoder bi- (OR, dual-) untuk menghubungkan entitas, beberapa makalah juga memanfaatkan Bert untuk mereka. Ide asli untuk sistem pengambilan berbasis biencoder juga diusulkan oleh [Gillick et al., '18]
Poly-encoder juga dapat diterapkan pada penghubung entitas, seperti yang ditunjukkan Wu et al., 2020.
Encoder berbasis transformator sering diadopsi untuk disebutkan dan penyandian entitas.
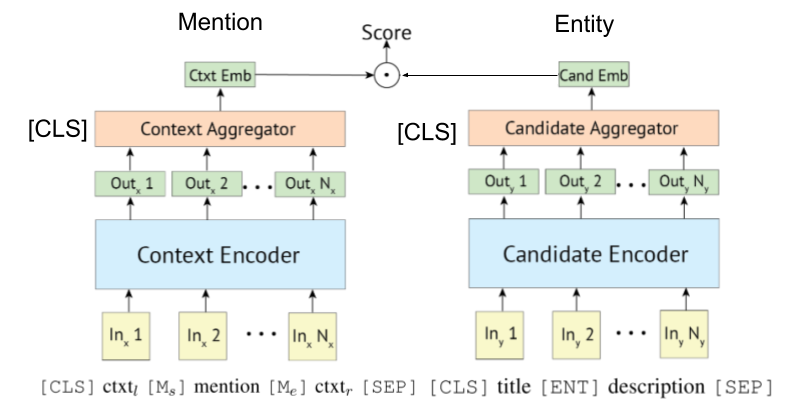
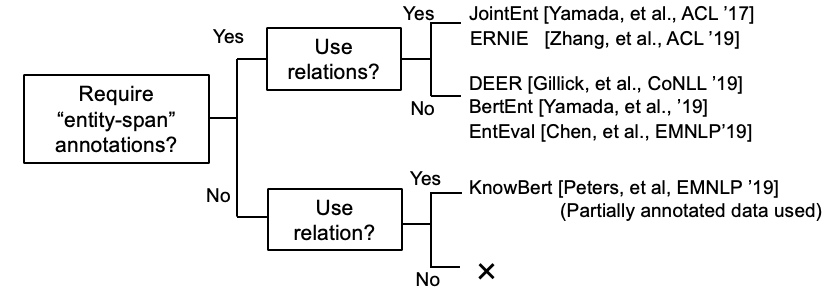
Beberapa penelitian sekarang mencoba memasukkan informasi KB dengan Bert.
Kepler: Model Terpadu untuk Penanaman Pengetahuan dan Representasi Bahasa Pra-Terlatih (Work In Progress @ Nov, '19)
Mengintegrasikan Grafik Pengetahuan Kontekstualisasikan ke dalam Model Bahasa Pra-Terlatih (Work In Progress @ Dec, '19)
K-BERT: Mengaktifkan representasi bahasa dengan grafik pengetahuan
[Petroni, et al., '19] memeriksa apakah Bert sendiri memiliki pengetahuan faktual.
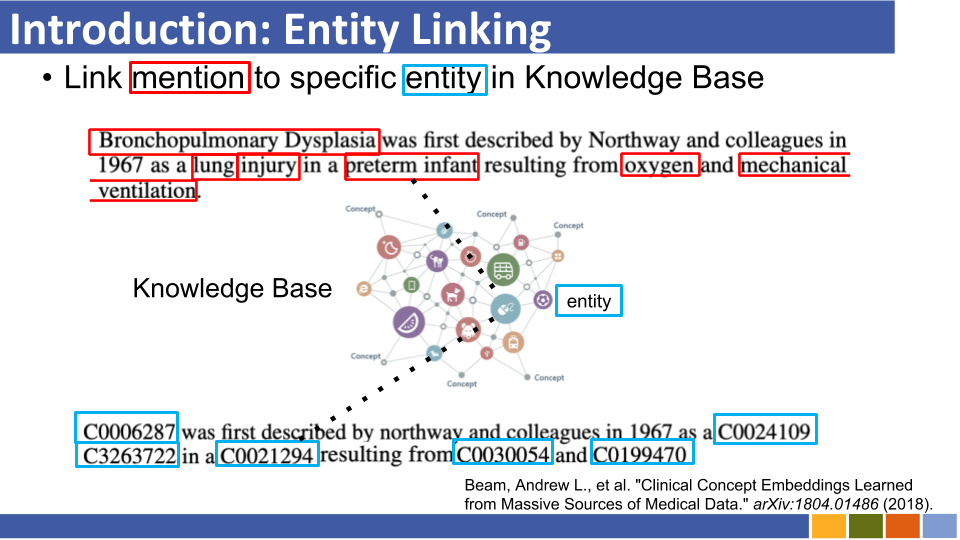
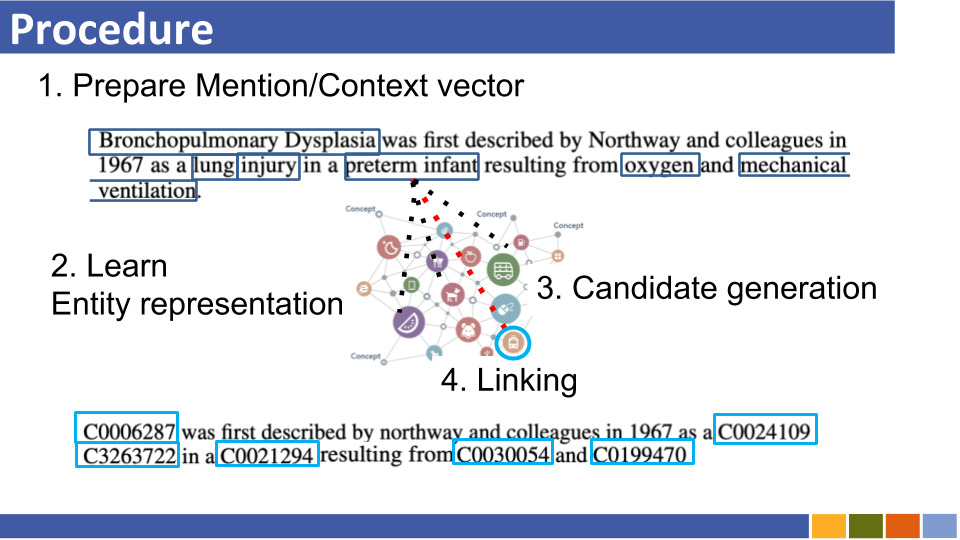
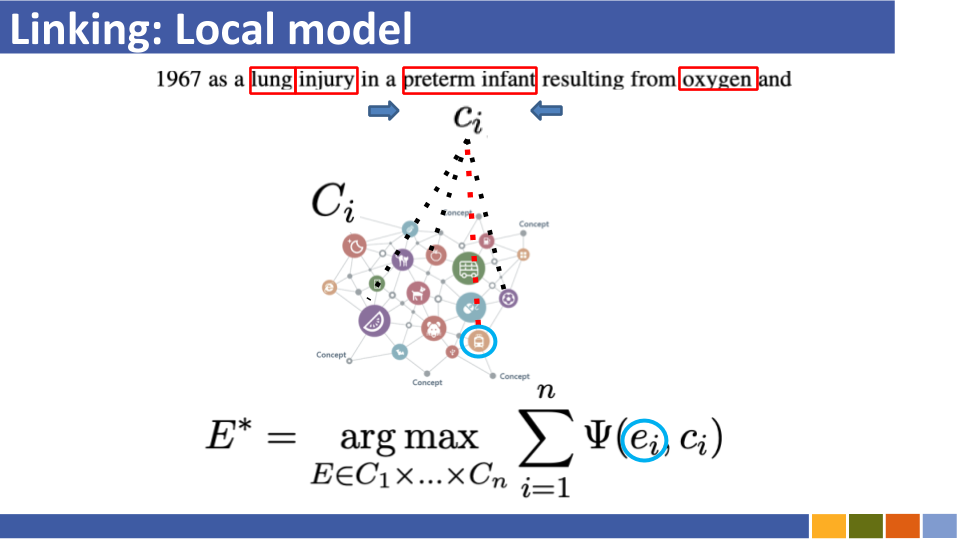
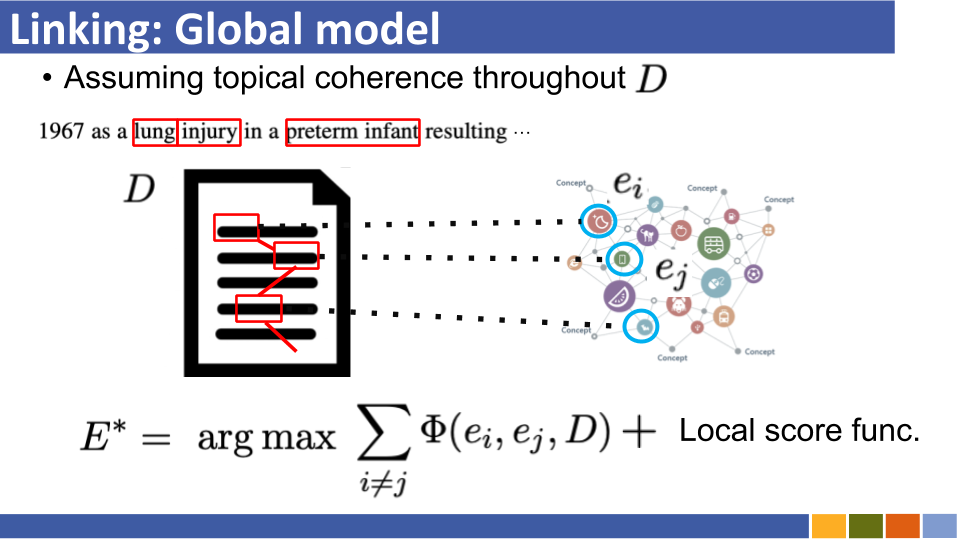
Entitas berbasis bi-encoder yang menghubungkan tutorial dan implementasinya. [link]
Makalah Survei Komprehensif Entitas Linking telah muncul.
(Berkomentar @ Maret, 2020) Saat ini repositori ini menyertakan makalah untuk entitas Linking dan Entity LM. Yang pertama membutuhkan representasi entitas pengkodean untuk disambiguasi, sementara yang terakhir berarti menyuntikkan pengetahuan entitas ke dalam LM selama pelatihan. Jadi mereka benar -benar berbeda, meskipun beberapa pekerjaan entitas LM mengevaluasi modelnya dengan entitas disambiguasi. Kami akan memisahkan mereka di repositori ini, dalam waktu dekat.
Papers El Cross-Lingual.
Dikutip dari Gupta et al. (EMNLP '18)
Entitas Cross-Lingual Linking (XEL) bertujuan untuk entitas dasar menyebutkan yang ditulis dalam bahasa apa pun ke Basis Pengetahuan Inggris (KB), seperti Wikipedia.
Pengawasan multibahasa bersama untuk penghubung entitas lintas-bahasa (EMNLP '18)
Menuju entitas lintas-bahasa nol-sumber daya yang menghubungkan (Shuyan et al., EMNLP Workshop '19)
Entitas Linking untuk Teks Berisik/Pendek
Pencocokan semantik agregat untuk tautan entitas teks pendek (ACL'18) [kertas]
Penggunaan Konteks yang Efektif dalam Entitas Berisik (EMNLP'18) [Kertas]
Linking entitas multimodal
Beberapa kertas lainnya
Kertas Linking Entitas Hanya Daftar
Pembelajaran Bersama Pengakuan Entitas dan Entitas Menghubungkan Kertas


