Entity Linking Recent Trends
1.0.0
Ce référentiel vise à suivre les progrès dans la liaison des entités. Des études sur la façon de préparer les représentations des entités sont également répertoriées, car les représentations d'entités sont obligatoires avec la liaison des entités.
Récupération des entités autorégressives
Les systèmes de liaison d'entités traditionnels souffrent de la consommation de mémoire en raison du codage préalable des entités dans la base de connaissances, du coût des ressources de calcul en raison de la comparaison de toutes les entités dans la base de connaissances et des problèmes de démarrage à froid.
Au lieu d'une architecture précédente, ils exploitent une séquence à la séquence pour générer des noms d'entités de manière autorégressive conditionnée sur le contexte. Ils ont utilisé la recherche de faisceau contrainte, forçant à décoder uniquement l'identifiant d'entité valide.
Lier les entités à des bases de connaissances invisibles avec des schémas arbitraires
Les systèmes de liaison d'entités traditionnels supposent que le schéma de la base de connaissances qui relie les entités prévues ensemble est connue. Ils ont proposé une nouvelle méthode pour convertir le schéma des entités inconnues en incorporation de Bert à l'aide d'attributs et de jetons auxiliaires.
Dans le même temps, ils ont également proposé une méthode de formation pour faire face aux attributs inconnus.
Dans Media Res: un corpus pour évaluer l'entité nommée liant avec des œuvres créatives [document] [codes]
LUKE: Représentations d'entités contextualisées profondes avec une auto-attention à l'entité [lien] [codes]
Ils ont proposé une nouvelle tâche de pré-formation basée sur Bert, dans laquelle des mots et des entités masqués au hasard sont prédits dans le corpus annoté en entité de Wikipedia.
Également dans la tâche de pré-formation, ils ont proposé une version étendue du transformateur, qui considère une auto-atténuer de l'auto-attention et les types de jetons (mots ou entités) lors du calcul des scores d'attention.
Entité à tirs zéro évolutive liant à la récupération de l'entité dense
Entité liant en 100 langues [papier]
COMETA: Un corpus pour une entité médicale reliant les médias sociaux [document]
Entité zéro-shot liant avec une modélisation efficace de séquences à longue portée [papier]
De Zero à Hero: une entité humaine dans la boucle liée dans des domaines de ressources faibles [lien]
Amélioration des entités liant à travers des intérêts sémantiques entités renforcées
Encyclopédie pré-étendue: modèle de langage prétrainé aux connaissances faiblement supervisé (ICLR'20) [document]
K-adapter: infuser les connaissances dans des modèles pré-formés avec des adaptateurs [papier]
Amélioration de la liaison en entité par modélisation du papier de type d'entité latente (AAAI'20)
Entité zéro-shot liant le papier à récupération d'entité dense (10e nov)
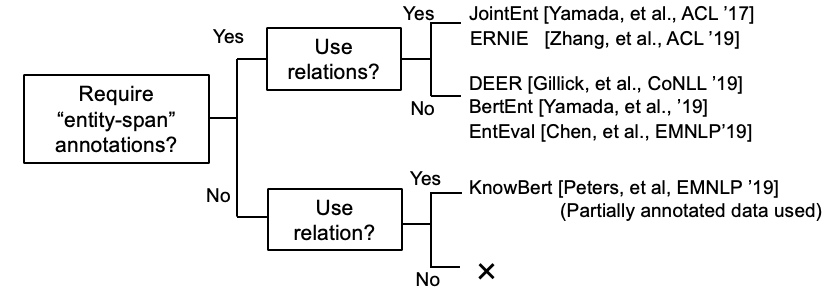
Semblable à [Logeswaran, et al., ACL'19] et [Gillick, et al., Conll'19]
Diapositives (non officielle)
Entité liant les encodeurs à double agencement et à l'attention croisée [ARXIV]
Évaluation à grains fins pour la liaison des entités (EMNLP'19)
Apprentissage du contexte dynamique Augmentation pour la liaison des entités mondiales (EMNLP'19)
Entité à grains fins Typage pour un lien en entités indépendantes du domaine
Enquêter sur les connaissances en entités à Bert avec un lien de fin à l'entité de bout en bout simple (CONLL '19) [Papier]
Apprentissage des représentations denses pour la récupération des entités (Conll '19)
papier, repo
Ils n'ont proposé aucune utilisation de la table d'alias (qui était basée sur les statistiques de Wikipedia ou en préparant une) et en recherchant toutes les entités par recherche brute / approximative la recherche la plus proche de l'entité de liaison par mention.
ETEVAL: une référence d'évaluation holistique pour les représentations d'entités (EMNLP '19)
Représentations d'entités d'apprentissage pour la reconstruction à quelques coups de catégories Wikipedia (ICLR '19)
Les représentations de mots contextuels améliorés de la connaissance (EMNLP '19) [document]
Les tendances de la mise à profit de toutes les informations (par exemple, le type et la définition de la mention et les documents dans lesquels une mention existe, etc ...) semble disparaître.
Bien que le domaine Wikipedia puisse utiliser son hyperlien (= paires de mention de mention, environ 7 500 000) pour le modèle de liaison de formation, dans certaines situations spécifiques au domaine, il n'y a pas tant de paires de mention.
Par conséquent, certains articles remettent désormais à l'épreuve un apprentissage à éloignement et un apprentissage zéro de la liaison des entités.
Apprentissage lointain
Apprentissage distant pour les entités liées à la détection automatique du bruit
Diapositives (non officielle)
Ils ont proposé de cramponner EL comme un problème d'apprentissage lointain, dans lequel aucune donnée de formation étiquetée n'est disponible, et le modèle de renforcement pour cette tâche.
Alimentation de l'entité liant les performances en tirant parti des documents non marqués
Liaison zéro-shot
Lien entité zéro-shot par description des entités de lecture
Diapositives (non officielle)
Ils ont proposé un EL de zéro-tir, en vertu duquel aucune mention de test ne peut être vue pendant la formation. Pour s'attaquer à l'EL à tirs zéro, ils ont proposé une stratégie adaptative au domaine pour le modèle de langue pré-formation. En outre, ils ont montré que la description de la description de l'entrée de la mention est cruciale pour EL.
L'apprentissage de la représentation des entités basée à Bert a également émergé.
(Commenté @ nov, 19 ') À cette époque, les recherches pour l'amélioration du modèle de liaison entités lui-même étaient florissantes.
Bold Style indique son score SOTA d'un ensemble de données spécifique.
| Modèles de base | Année | Ensemble de données | code | Courir? | Adresse de code |
|---|---|---|---|---|---|
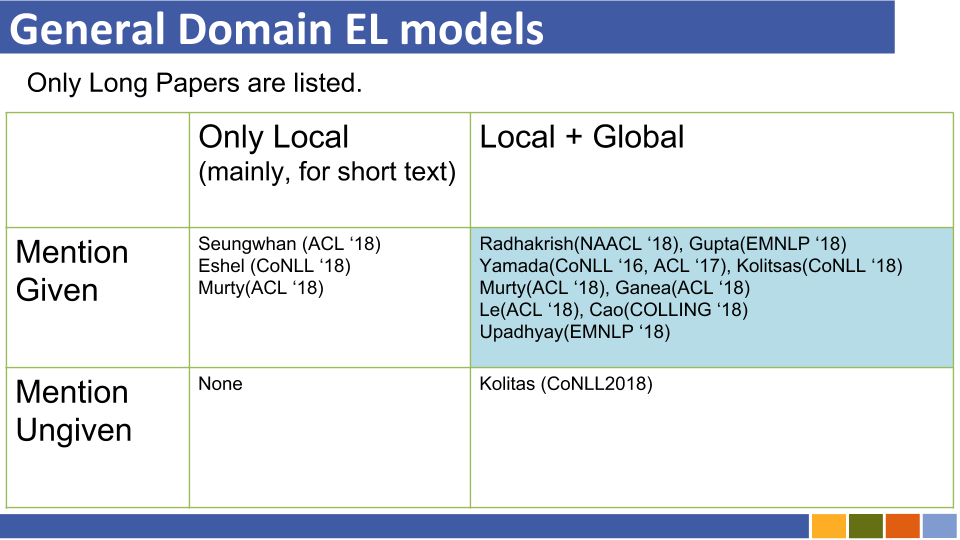
| Entité liant le codage conjoint des types, des descriptions et du contexte | EMNLP2017 | Conll-Yago (82,9, ACC), ACE2004, ACE2005, Wiki ( 89,0 , F1) | Tensorflow | Seul le modèle Traind est téléchargé | ici |
| ┗ (très similaire à ce qui précède) Supervision multilingue conjointe pour un lien entre entités croisées | EMNLP2018 | TEST TH, TEST MCN, TAC2015 | Pytorch | Vérification | ici |
| Entité collective neuronale liant (NCEL) | CL2018 | Conll-yago, ACE2004, Aquaint, TAC2010 ( 91.0 , MIC-P), WW | pytorch | Bogue | ici |
| Améliorer les liens en entités en modélisant les relations latentes entre les mentions | ACL2018 | Conll-Yago ( 93,07 , Mic-ACC), Aquaint, ACE2004, CWEB, Wiki (84,05, F1) | pytorch | Évaluation effectuée | ici |
| Elden | NAACL2018 | CONLL-PPD (93,0, P-MIC), TAC2010 (89,6, MIC-P) | Lua, torche (Lua) | Bogue | ici |
| Disambigation de l'entité conjointe profonde avec une attention neuronale locale | EMNLP2017 | Conll-Yago (92.22, Mic-ACC), CWEB, WW, ACE2004, Aquaint, MSNBC | Lua, torche (Lua) | Train Running (2019/01/15) | ici |
| Pertes hiérarchiques et nouvelles ressources pour la saisie et la liaison des entités grainides fines | ACL2018 | Medmentions, Typenet | pytorch | Bogue | ici |
| Apprentissage conjoint de l'incorporation de mots et d'entités pour la désambiguïsation des entités nommés (Yamada, Shindo) | Conll2016 | Conll-yago (91,5, Mic-ACC), Conll-PPD (93.1, P-MIC), TAC2010 (85,5, MIC-ACC) | pytorch / tensorflow (original), | vérification | Original de base |
| Apprentissage des représentations distribuées des textes et entités de la base de connaissances (Yamada, Shindo) | ACL2017 | CONLL-PPD ( 94,7 , P-MIC), TAC2010 (87.7, MIC-ACC) | pytorch / keras (original) | vérification | Torche, torche, original |
Remarque: les principaux ensembles de données pour l'analyse comparative de cette tâche sont répertoriés au référentiel Blink.
Ensemble de données mewsli-9
Biomédical
Medmentions ([Mohan et Li, AKBC '19])
Medmesions a été créée en tant que jeu de données de référence pour la reconnaissance des entités et la liaison des entités nommées dans le domaine biomédical.
Comme il contient de nombreux concepts trop larges pour être utiles, ST21PV a été construit en filtrant ces larges concepts de Medmentions.
BC5CDR ([Li et al., '15'])
BC5CDR est un ensemble de données créé pour la tâche de reconnaissance de la chimie et de la maladie biocréative V.
Il comprend 1 500 articles, contenant 15 935 chimiques et 12 852 mentions de maladie.
La base de connaissances de référence est maillée et presque toutes les mentions ont une entité d'or dans la base de connaissances de référence.
Wikimed et PubMedds ([Shikhar et al., '20])
Wikimed comprend plus de 650 000 mentions normalisées en concepts dans les UML. (Cité)
En outre, ils ont créé des Corpus PubMedds annotés avec plus de 5 millions de mentions normalisées. Notez que cet ensemble de données a été créé par une supervision lointaine, ce qui conduit à provoquer des annotations bruyantes.
Zéro
Ensembles de données Wikia ([Logeswaran et al., '19])
À partir des hyperliens de Wikia et de ses thèmes connexes, ils ont créé un ensemble de données pour évaluer la généralisation du domaine de la tâche de liaison des entités.
Ils ont créé 16 ensembles de données Worlds , qui ont été divisés à 8/4/4 pour Train / Dev / Test et complètement indépendants les uns pour les autres.
Étant donné que [Gillick et al., Conll'19] a d'abord proposé des systèmes de récupération de l'encodeur bi- (ou, double) pour la liaison des entités, certains articles exploitent également Bert pour eux. L'idée originale du système de récupération basé sur Bieencoder est également proposée par [Gillick et al., '18]
Le poly-encodeur peut également être appliqué à la liaison des entités, comme l'a montré Wu et al., 2020.
L'encodeur basé sur le transformateur est souvent adopté pour mention et encodage d'entité.
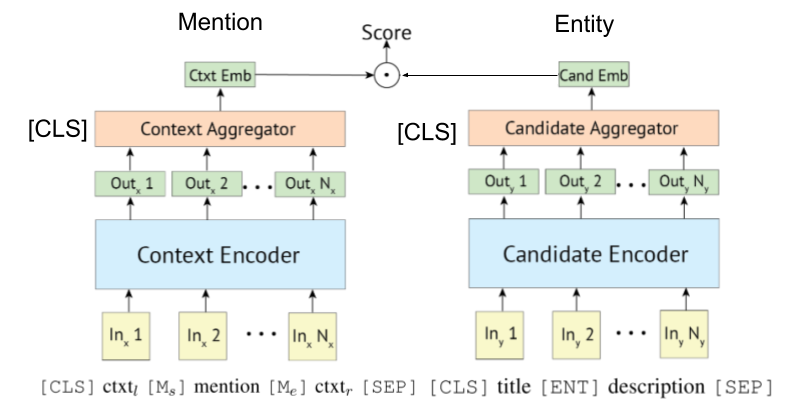
Certaines recherches tentent maintenant d'incorporer des informations KB avec Bert.
Kepler: un modèle unifié pour l'intégration des connaissances et la représentation du langage pré-formé (travail en cours @ nov, 19)
Intégrer les connaissances contextualisées du graphique dans les modèles de langage pré-formés (travail en cours @ dec, '19)
K-Bert: Permettre une représentation du langage avec un graphique de connaissances
[Petroni, et al., '19] a vérifié si Bert lui-même a des connaissances factuelles.
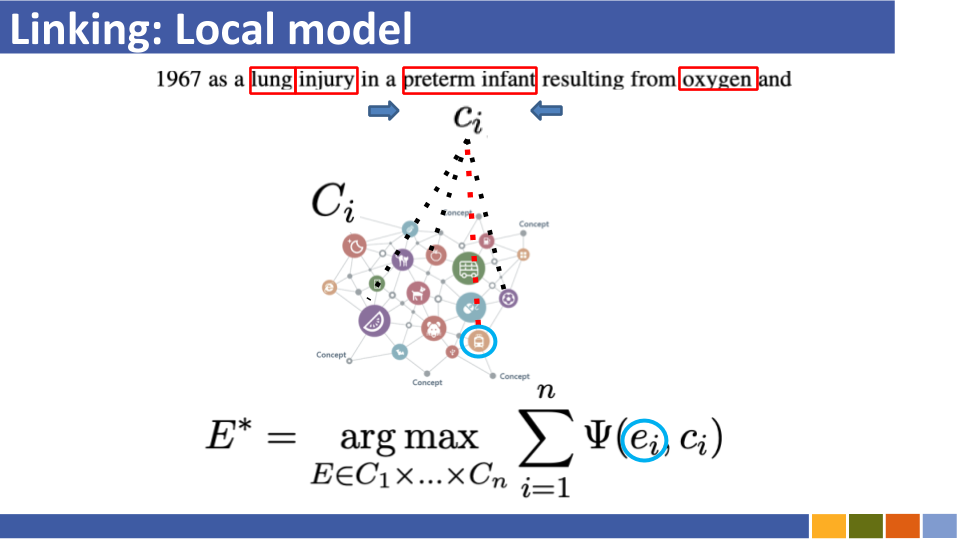
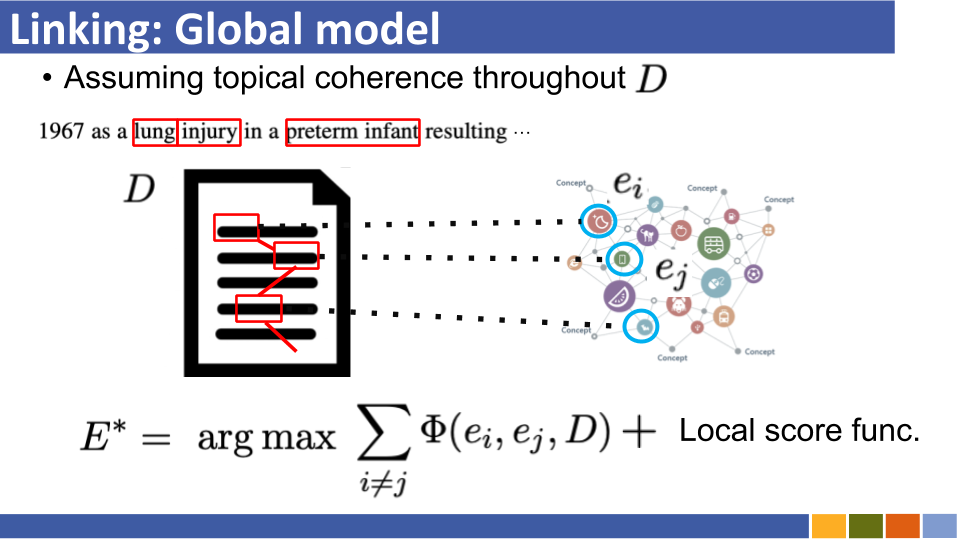
Tutoriel de liaison entités basé sur le bi-encodeur et sa mise en œuvre. [lien]
Un document d'enquête complet de liaison d'entités est apparu.
(Commenté @ mars 2020) Actuellement, ce référentiel comprend des articles pour la liaison entités et l'entité LM. Le premier nécessite une représentation d'entité d'encodage pour la désambiguïsation, tandis que le second signifie injecter des connaissances entités dans LM pendant la formation. Ils sont donc complètement différents, bien que certains travaux d'entité LM aient évalué son modèle avec une désambiguïsation des entités. Nous les séparerons dans ce référentiel, dans un avenir proche.
Documents EL interdictionnels.
Cité de Gupta et al. (EMNLP '18)
La liaison de l'entité inter-greatrice (XEL) vise des mentions d'entité à la terre écrites dans n'importe quelle langue à une base de connaissances en anglais (KB), comme Wikipedia.
Supervision multilingue conjointe pour la liaison des entités croisées (EMNLP '18)
Vers la liaison de l'entité inter-linguale à ressources zéro (Shuyan et al., EMNLP Workshop '19)
Entité liée à des textes bruyants / courts
Correspondance sémantique agrégée pour lien en entités de texte court (acl'18) [papier]
Utilisation efficace du contexte dans une liaison en entités bruyantes (EMNLP'18) [papier]
Liaison d'entité multimodale
Quelques autres papiers
Liste uniquement du papier de liaison
Apprentissage conjoint de la reconnaissance et du document de liaison des entités nommées nommées


