Entity Linking Recent Trends
1.0.0
このリポジトリは、エンティティリンクの進捗状況を追跡することを目的としています。エンティティの表現はエンティティのリンクで必須であるため、エンティティの表現を準備する方法に関する研究もリストされています。
自己回帰エンティティ検索
従来のエンティティリンクシステムは、知識ベースのエンティティの事前のエンコード、知識ベースのすべてのエンティティの比較による計算リソースコスト、およびコールドスタートの問題により、メモリ消費に悩まされています。
以前のアーキテクチャの代わりに、彼らはシーケンスからシーケンスまでのものを活用して、コンテキストに条件付けられた自動回復的なファッションでエンティティ名を生成します。彼らは制約付きのビーム検索を使用し、有効なエンティティ識別子のみをデコードするように強制しました。
エンティティを目に見えない知識ベースに任意のスキーマにリンクします
システムをリンクする従来のエンティティは、予測されたエンティティを結び付ける知識ベースのスキーマが既知であると想定しています。彼らは、不明なエンティティのスキーマを属性と補助トークンを使用してBERT Embeddingに変換する新しい方法を提案しました。
同時に、彼らはまた、未知の属性に対処するためのトレーニング方法を提案しました。
メディアのres:クリエイティブワークスとリンクする名前の名前のエンティティを評価するためのコーパス[紙] [コード]
ルーク:エンティティを意識した自己attentionを使用した深い文脈化されたエンティティ表現[リンク] [コード]
彼らは、Wikipediaのエンティティが発表したコーパスでランダムにマスクされた単語とエンティティが予測されるBertに基づいて新しい事前削除タスクを提案しました。
また、事前に登録されたタスクでは、エンティティを意識した自己触たちと注意スコアを計算する際にエンティティを意識した自己触媒とトークン(単語またはエンティティ)の種類を考慮したトランスの拡張バージョンを提案しました。
密集したエンティティの検索とリンクするスケーラブルゼロショットエンティティ
100の言語でリンクするエンティティ[紙]
cometa:ソーシャルメディアにリンクする医療団体のためのコーパス[論文]
効率的な長距離シーケンスモデリングとリンクするゼロショットエンティティ[Paper]
ゼロからヒーローへ:低リソースドメインでリンクするループインエンティティ[リンク]
セマンティック強化エンティティの埋め込みを介してリンクするエンティティの改善
前処理された百科事典:監視された知識に基づいた言語モデル(ICLR'20)[論文]
K-アダプター:アダプターを使用して事前に訓練されたモデルに知識を注入する[紙]
潜在エンティティタイプ情報(AAAI'20)ペーパーのモデリングによるリンクの改善エンティティ
密集したエンティティ検索(10日、11月)とリンクするゼロショットエンティティ
[Logeswaran、et al。、acl'19]および[Gillick、et al。、conll'19]に似ています。
スライド(非公式)
デュアルおよびクロスアテンションエンコーダーを介してリンクするエンティティ[arxiv]
リンクリンクのエンティティの微調整された評価(emnlp'19)
グローバルエンティティリンクの動的コンテキスト増強(EMNLP'19)
ドメイン独立エンティティのリンクのための微調整されたエンティティタイピング
バートのエンティティの知識の調査シンプルなニューラルエンドツーエンティティリンク(Conll '19)[Paper]
エンティティ検索の密な表現を学ぶ(Conll '19)
紙、レポ
彼らは、エイリアステーブル(ウィキペディア統計に基づいたものまたは準備されたもの)の使用を提案し、言及あたりのリンクエンティティのリンクエンティティの近くで最も近い検索ですべてのエンティティを検索しました。
Enteval:エンティティ表現の全体的な評価ベンチマーク(EMNLP '19)
ウィキペディアカテゴリの少数のショット再構築の学習エンティティ表現(ICLR '19)
知識強化されたコンテキストワード表現(EMNLP '19)[Paper]
すべての情報を活用する傾向(たとえば、言及のタイプと定義、および言及が存在するなどの文書など)は消滅しているようです。
Wikipediaドメインは、トレーニングリンクモデルにハイパーリンク(=言及エンティティペア、約7,500,000)を使用できますが、一部のドメイン固有の状況では、言及されたペアはそれほど多くありません。
したがって、いくつかの論文は、エンティティリンクの遠隔学習とゼロショット学習に挑戦しています。
遠い学習
自動ノイズ検出とリンクするエンティティの遠い学習
スライド(非公式)
彼らは、ELを遠い学習問題としてフレーミングすることを提案しました。この問題は、ラベル付きトレーニングデータが利用できないこと、およびこのタスクのモデルを除外しました。
非標識ドキュメントを活用することにより、パフォーマンスをリンクするエンティティを後押しします
ゼロショットリンク
エンティティの説明を読み取ることでリンクするゼロショットエンティティ
スライド(非公式)
彼らはゼロショットELを提案しましたが、その下ではトレーニング中にテストの言及は見られません。ゼロショットELに取り組むために、彼らはトレーニング前の言語モデルのドメイン適応戦略を提案しました。また、彼らは、言及と専門性の説明の相互出絶対がELにとって重要であることを示しました。
Bertベースのエンティティ表現学習も登場しました。
(コメント @ nov、19 ')当時、モデル自体をリンクするエンティティを改善するための研究は繁栄していました。
Boldスタイルは、特定のデータセットのSOTAスコアを示しています。
| ベースラインモデル | 年 | データセット | コード | 走る? | コードアドレス |
|---|---|---|---|---|---|
| タイプ、説明、およびコンテキストの共同エンコードを介してリンクするエンティティ | EMNLP2017 | conll-yago(82.9、acc)、ACE2004、ACE2005、Wiki( 89.0 、F1) | Tensorflow | Traindモデルのみがアップロードされます | ここ |
| ┗(上記に非常によく似ている)横断的エンティティのリンクのための共同多言語監督 | EMNLP2018 | Thtest、MCN-TEST、TAC2015 | Pytorch | チェック中 | ここ |
| ニューラル集団エンティティリンク(NCEL) | CL2018 | Conll-Yago、ACE2004、Aquent、TAC2010( 91.0 、MIC-P)、ww | Pytorch | バグ | ここ |
| 言及間の潜在的な関係をモデル化することによってリンクするエンティティの改善 | ACL2018 | conll-yago( 93.07 、mic-acc)、aquaint、ace2004、cweb、wiki(84.05、f1) | Pytorch | 評価が行われました | ここ |
| エルデン | NAACL2018 | Conll-PPD(93.0、P-MIC)、TAC2010(89.6、MIC-P) | ルア、トーチ(ルア) | バグ | ここ |
| 局所的な神経の注意を伴う深い共同エンティティは曖昧性を乱します | EMNLP2017 | conll-yago(92.22、MIC-ACC)、CWEB、WW、ACE2004、Aquaint、MSNBC | ルア、トーチ(ルア) | トレインランニング(2019/01/15) | ここ |
| 細かい穀物エンティティのタイピングとリンクのための階層的損失と新しいリソース | ACL2018 | メドメント、TypeNet | Pytorch | バグ | ここ |
| 指名されたエンティティの単語とエンティティの埋め込みの共同学習曖昧性除去(山田、シンド) | conll2016 | conll-yago(91.5、mic-acc)、conll-ppd(93.1、p-mic)、tac2010(85.5、mic-acc) | pytorch/tensorflow(オリジナル)、 | チェック中 | ベースラインオリジナル |
| 知識ベースからテキストとエンティティの分散表現を学習する(ヤマダ、シンド) | ACL2017 | Conll-PPD( 94.7 、P-MIC)、TAC2010(87.7、MIC-ACC) | Pytorch/Keras(オリジナル) | チェック中 | トーチ、トーチ、オリジナル |
注:このタスクをベンチマークするための主要なデータセットは、Blinkリポジトリにリストされています。
mewsli-9データセット
生物医学
メドメント([Mohan and Li、Akbc '19])
Medmentionsは、名前付きエンティティ認識と生物医学的領域にリンクするエンティティのベンチマークデータセットとして作成されました。
幅が広すぎて実用的ではない多くの概念が含まれているため、ST21PVは、これらの広範な概念をメドメントから除外することで構築されました。
bc5cdr([li et al。、 '15'])
BC5CDRは、BioCREative V Chemical and Diseaseの認識タスクのために作成されたデータセットです。
15,935個の化学物質と12,852個の疾患の言及を含む1,500個の記事で構成されています。
参照ナレッジベースはメッシュであり、ほとんどすべての言及には、参照ナレッジベースに金の実体があります。
WikimedおよびPubMedds([Shikhar et al。、'20])
Wikimedには、UMLSの概念に正規化された650,000を超える言及が含まれています。 (引用)
また、彼らは500万件以上の正規化された言及で注釈付きコーパスPubMeddsを作成しました。このデータセットは遠い監督によって作成されたことに注意してください。
ゼロショット
ウィキアデータセット([logeswaran et al。、'19])
Wikia HyperLinksとその関連テーマから、タスクをリンクするエンティティのドメイン一般化を評価するためのデータセットを作成しました。
彼らは16のWorldsデータセットを作成しました。これは、電車 /開発 /テストのために8/4/4に分割され、互いに完全に独立しています。
[Gillick et al。、conll'19]は、リンクするエンティティ用のbi-(またはdual-)エンコーダー検索システムを最初に提案して以来、一部の論文もそれらにBertを活用しています。 Biencoderベースの検索システムのオリジナルアイデアは、[Gillick et al。、'18]によっても提案されています。
Poly-Encoderは、Wu et al。、2020が示したように、エンティティリンクにも適用できます。
トランスベースのエンコーダーは、多くの場合、言及とエンティティエンコードのために採用されます。
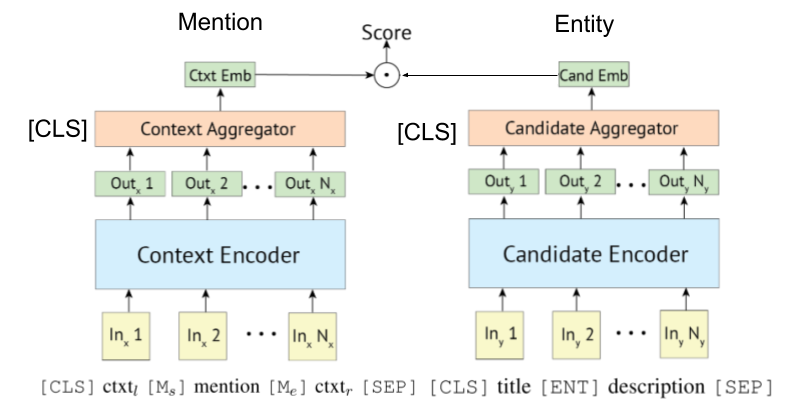
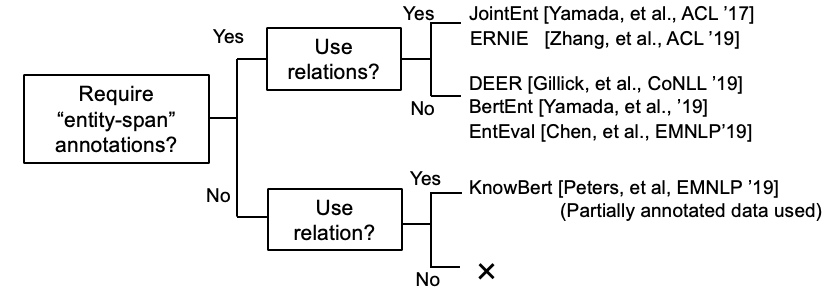
いくつかの研究は現在、KB情報をBERTに組み込もうとしています。
ケプラー:知識の埋め込みと事前に訓練された言語表現のための統一されたモデル(作業中の作業 @ nov、'19)
グラフのコンテキスト化された知識を事前に訓練された言語モデルに統合する(作業中の作業 @ Dec、'19)
K-Bert:知識グラフで言語表現を有効にします
[Petroni、et al。、'19]は、Bert自体が事実の知識を持っているかどうかを確認しました。
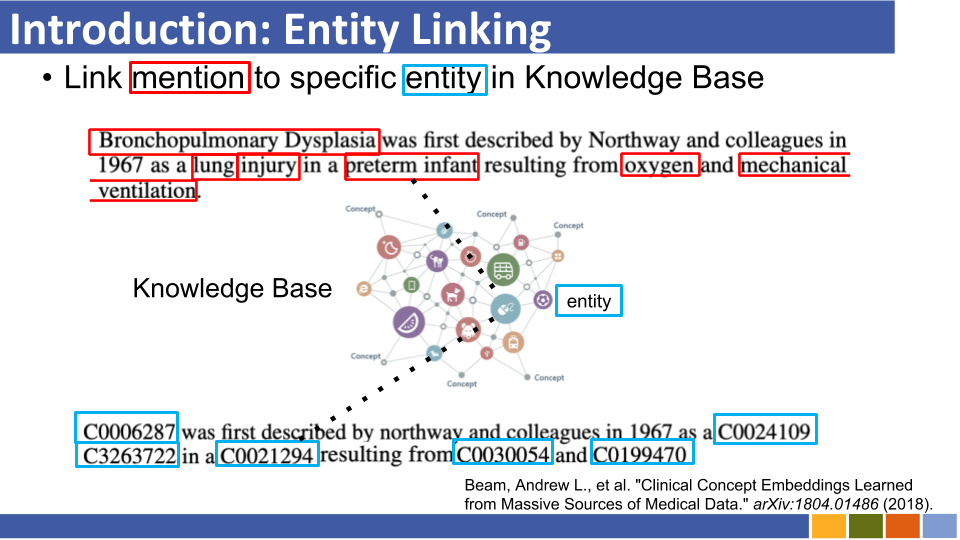
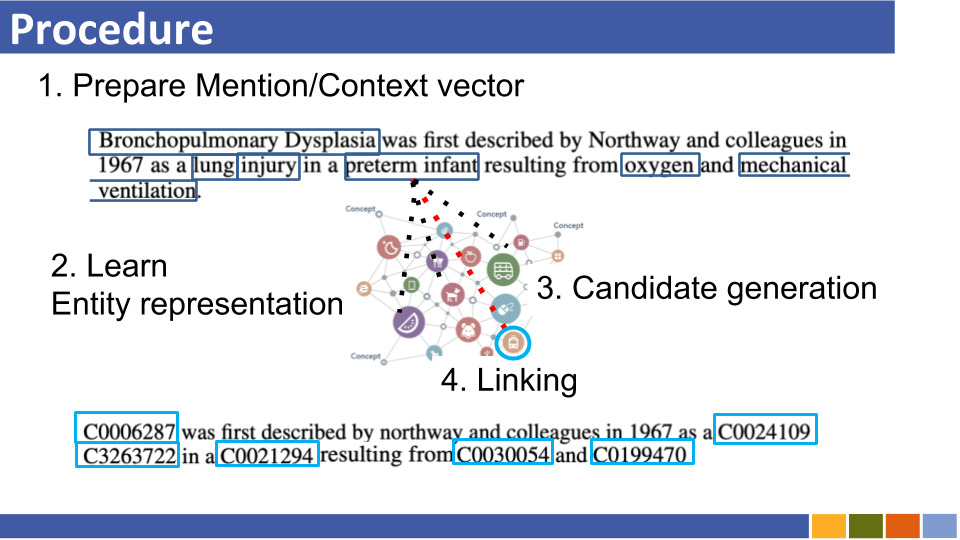
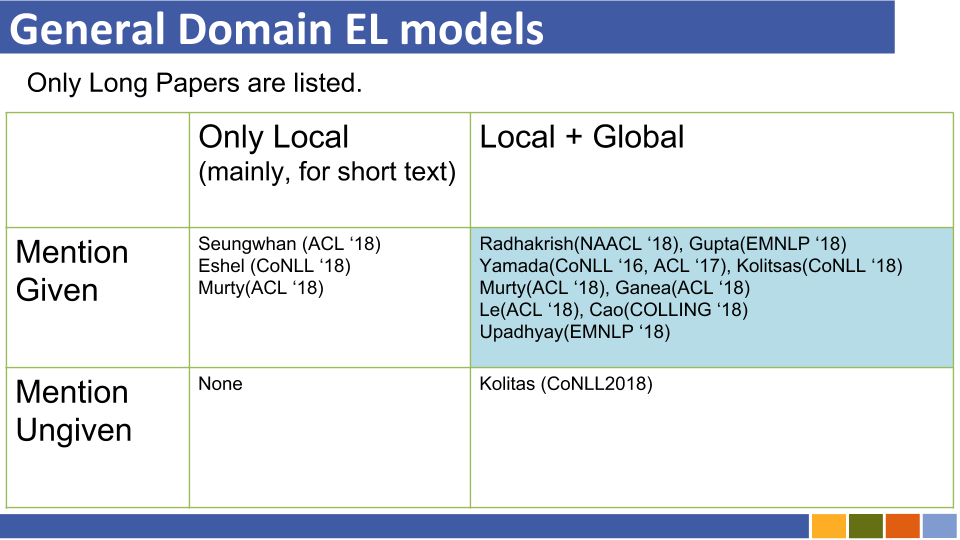
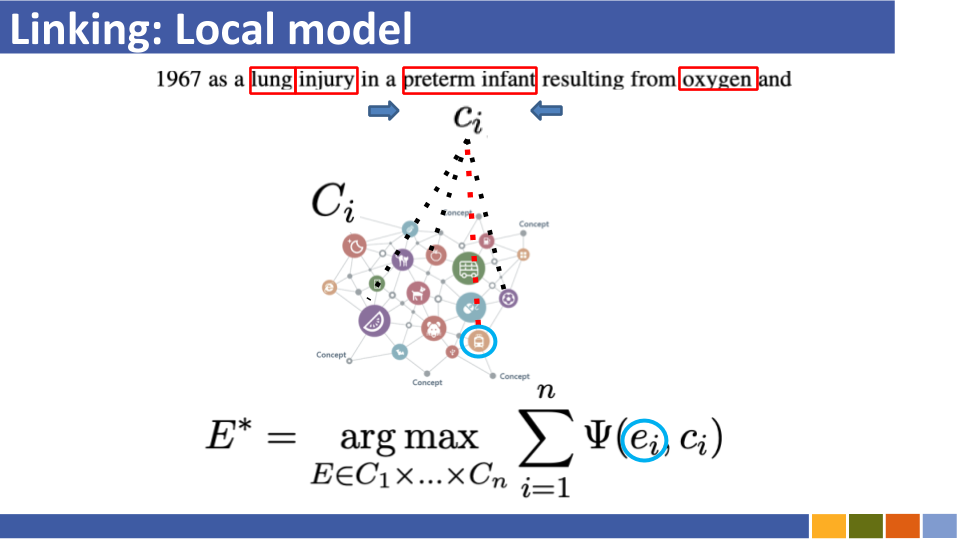
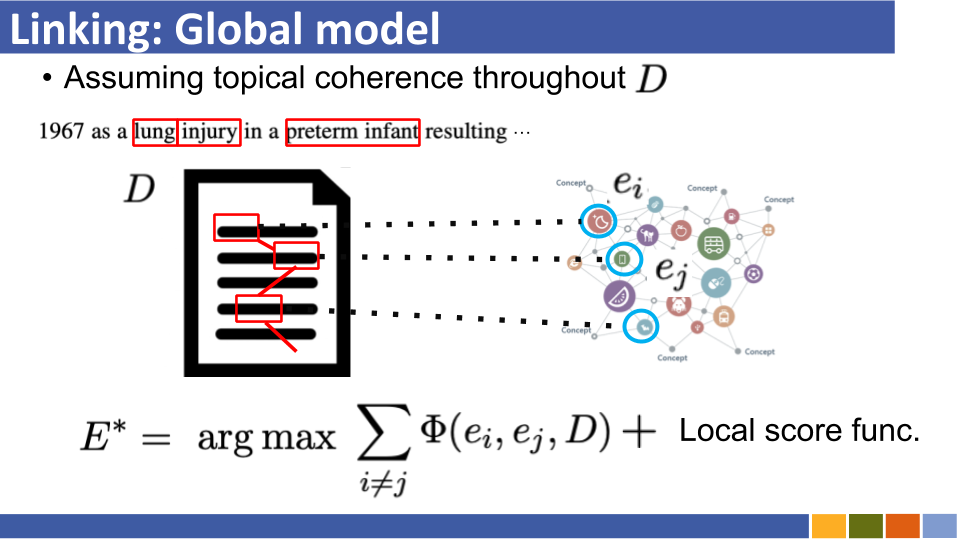
チュートリアルとその実装をリンクするBi-Encoderベースのエンティティ。 [リンク]
エンティティリンクの包括的な調査論文が登場しました。
(2020年3月 @コメントされた)現在、このリポジトリには、エンティティリンクとエンティティLMの両方の論文が含まれています。前者は、曖昧性を除去するためにエンティティの代表をエンコードすることを要求しますが、後者はトレーニング中にエンティティの知識をLMに注入することを意味します。したがって、それらは完全に異なりますが、エンティティLMのいくつかの作業は、エンティティの曖昧性を除去してそのモデルを評価しました。近い将来、このリポジトリでそれらを分離します。
言語間のエルペーパー。
Gupta et alから引用。 (emnlp '18)
横断的存在リンク(XEL)は、ウィキペディアなどの英語の知識ベース(KB)に任意の言語で書かれた存在の言語を粉砕することを目的としています。
横断的存在のリンクのための共同多言語監督(EMNLP '18)
ゼロリソースの横断的エンティティリンクに向けて(Shuyan et al。、EMNLP Workshop '19)
騒々しい/短いテキストにリンクするエンティティ
短いテキストエンティティリンクのための集約されたセマンティックマッチング(ACL'18)[Paper]
騒々しいエンティティリンクにおけるコンテキストの効果的な使用(EMNLP'18)[論文]
マルチモーダルエンティティリンク
他のいくつかの論文
リストのみのエンティティリンクペーパー
指定されたエンティティ認識とエンティティのリンクペーパーの共同学習


