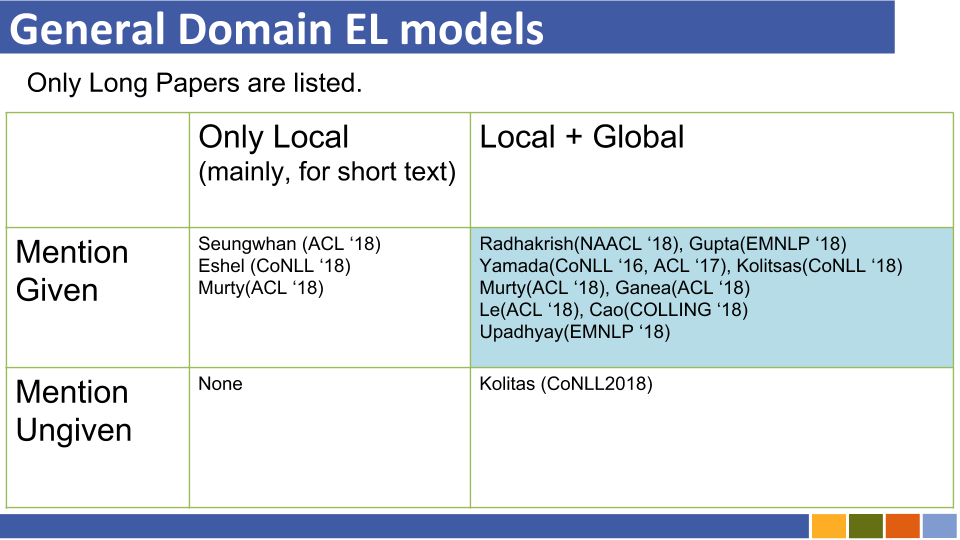
Entity Linking Recent Trends
1.0.0
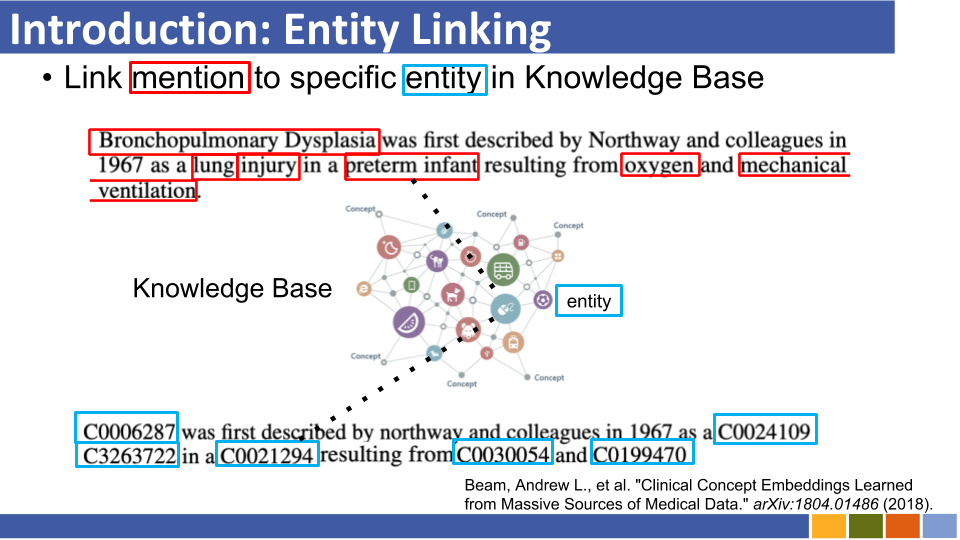
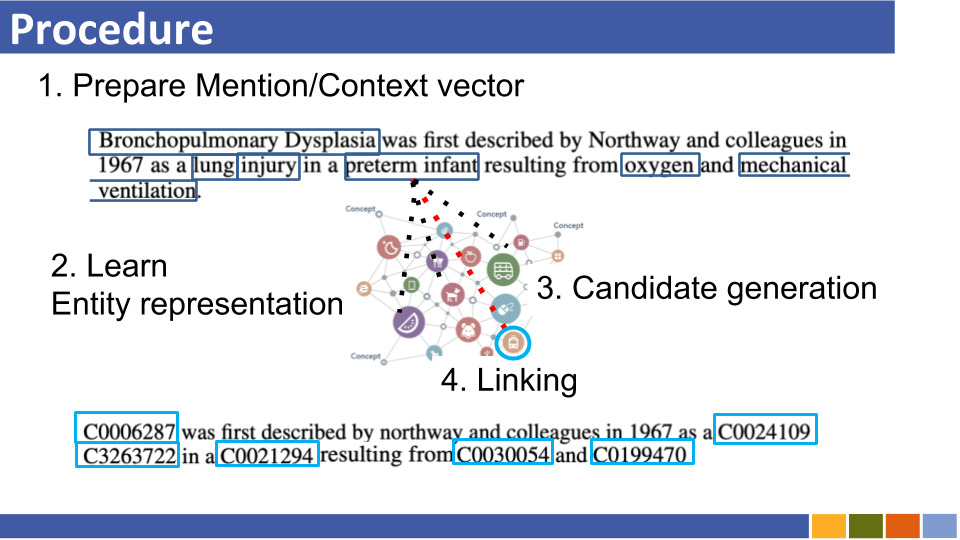
该存储库旨在跟踪实体链接的进度。还列出了如何准备实体表示形式的研究,因为实体表示与实体链接是强制性的。
自回家实体检索
由于知识库中的实体的事先编码,由于知识库中所有实体的比较而导致的计算资源成本以及冷启动问题,传统的实体链接系统遭受了记忆消耗的影响。
他们不是以前的体系结构,而是利用了一个序列序列,以在上下文中以自动回归方式生成实体名称。他们使用受约束的光束搜索,强迫仅解码有效的实体标识符。
将实体与任意模式联系在一起
传统实体连接系统假定将预测实体联系在一起的知识基础的模式是已知的。他们提出了一种新方法,将未知实体的模式转换为使用属性和辅助令牌嵌入BERT嵌入的方法。
同时,他们还提出了一种处理未知属性的培训方法。
在媒体中:用于评估命名实体与创意作品的语料库[论文] [代码]
路加福音:具有实体感知的自我注意力[link] [codes]的深层上下文化实体表示
他们提出了基于BERT的新预读任务,其中在Wikipedia的实体注销语料库中预测了随机掩盖的单词和实体。
同样在训练任务中,他们提出了变压器的扩展版本,该版本考虑实体觉醒的自我注意力以及计算注意力分数时的令牌(单词或实体)类型。
可扩展的零击实体与密集实体检索链接
实体链接100种语言[纸]
COMETA:社交媒体中链接的医学实体语料库[论文]
零拍摄实体与有效的远程序列建模链接[纸]
从零到英雄:在低资源域中链接的人类在线实体[链接]
改善通过语义增强实体嵌入链接的实体
预读的百科全书:弱监督的知识语语言模型(ICLR'20)[纸]
K-Audapter:将知识注入适配器的预训练模型[纸]
通过建模潜在实体类型信息(AAAI'20)论文来改善实体链接
零射击实体与密集实体检索链接(11月10日)论文
类似于[Logeswaran等,ACL'19]和[Gillick等,Conll'19]
幻灯片(非官方)
通过双重和跨注意编码链接的实体[ARXIV]
实体链接的细粒度评估(EMNLP'19)
全球实体链接的学习动态环境增强(EMNLP'19)
用于域独立实体链接的细粒度实体键入
通过简单的神经端到端实体链接(Conll '19)[纸]调查BERT中的实体知识
学习实体检索的密集表示(Conll '19)
纸,回购
他们提出了不使用别名表(基于Wikipedia统计或准备的),并通过蛮力/大约最近搜索搜索所有实体,以搜索所有实体。
Enteval:实体表示的整体评估基准(EMNLP '19)
Wikipedia类别重建的学习实体表示(ICLR '19)
知识增强上下文单词表示(EMNLP '19)[纸]
利用所有信息的趋势(例如,提到存在的类型,定义和文档等等等等)似乎正在消失。
尽管Wikipedia域可以使用其超链接(=提及 - 实用对,约7,500,000)进行训练链接模型,但是在某些特定领域的情况下,没有太多提及的实体对。
因此,现在有些论文挑战了遥远学习的实体链接学习和零射击学习。
遥远的学习
与自动噪声检测链接的实体的遥远学习
幻灯片(非官方)
他们提出将EL框架作为遥远的学习问题,其中没有标记的培训数据,并为此任务推迟了纳入模型。
通过利用未标记的文档来提高实体链接性能
零击链接
通过阅读实体说明链接零击实体链接
幻灯片(非官方)
他们提出了零照片EL,在训练过程中看不到测试。为了解决零拍摄的EL,他们提出了用于培训语言模型的领域自适应策略。另外,他们表明提及的描述对EL至关重要。
基于BERT的实体表示学习也出现了。
(评论 @ Nov,19')那时,改善实体链接模型本身的研究正在蓬勃发展。
粗体样式表示其特定数据集的SOTA分数。
| 基线模型 | 年 | 数据集 | 代码 | 跑步? | 代码地址 |
|---|---|---|---|---|---|
| 实体通过类型,描述和上下文的联合编码链接 | EMNLP2017 | Conll-Yago(82.9,ACC),ACE2004,ACE2005,Wiki( 89.0 ,F1) | 张量 | 仅上传火车模型 | 这里 |
| ┗(与上述非常相似)跨语义实体链接的联合多语言监督 | EMNLP2018 | TH-TEST,MCN检验,TAC2015 | Pytorch | 检查 | 这里 |
| 神经集体实体链接(NCEL) | CL2018 | Conll-Yago,ACE2004,Aquaint,TAC2010( 91.0 ,MIC-P),WW | Pytorch | 漏洞 | 这里 |
| 通过对提及之间的潜在关系建模来改善实体链接 | ACL2018 | Conll-Yago( 93.07 ,MIC-ACC),Aquaint,ACE2004,CWEB,Wiki(84.05,F1) | Pytorch | 评估完成 | 这里 |
| 埃尔登 | NAACL2018 | Conll-PPD(93.0,P-MIC),TAC2010(89.6,MIC-P) | Lua,火炬(LUA) | 漏洞 | 这里 |
| 深处联合实体歧义,局部神经关注 | EMNLP2017 | Conll-Yago(92.22,MIC-ACC),CWEB,WW,ACE2004,Aquaint,MSNBC | Lua,火炬(LUA) | 火车跑步(2019/01/15) | 这里 |
| 用于细粒实体的分层损失和新资源分型和链接 | ACL2018 | Medentions,Typenet | Pytorch | 漏洞 | 这里 |
| 联合学习命名实体歧义的单词和实体的嵌入(Yamada,Shindo) | Conll2016 | Conll-Yago(91.5,MIC-ACC),Conll-PPD(93.1,P-MIC),TAC2010(85.5,MIC-ACC) | pytorch/tensorflow(原始),, | 检查 | 基线原件 |
| 从知识库(Yamada,Shindo)学习文本和实体的分布式表示形式 | ACL2017 | Conll-PPD( 94.7 ,P-MIC),TAC2010(87.7,MIC-ACC) | Pytorch/keras(原始) | 检查 | 火炬,火炬,原始 |
注意:基准测试此任务的主要数据集在Blink存储库中列出。
mewsli-9数据集
生物医学
Medentions([Mohan and Li,AKBC '19])
Med Mentions是作为基准数据集创建的,用于在生物医学领域中命名的实体识别和链接的实体。
由于它包含了许多概念,这些概念太广泛而无法实际使用,因此ST21PV的构建是通过从饮食中滤除那些广泛的概念来构建的。
BC5CDR([Li等,'15'])
BC5CDR是为生物抗衡性V化学和疾病提及识别任务而创建的数据集。
它包含1,500篇文章,其中包含15,935种化学物质和12,852种疾病提及。
参考知识基础是网格,几乎所有提及在参考知识基础中都有一个黄金实体。
Wikimed和PubMedds([Shikhar等,'20])
Wikimed包括超过650,000个提及,将其标准化为UMLS的概念。 (引用)
此外,他们创建了带有超过500万个标准化的注释PubMedds。请注意,该数据集是由遥远的监督创建的,这导致引起一些嘈杂的注释。
零射
Wikia数据集([[Logeswaran等,'19])
从Wikia超链接及其相关主题中,他们创建了用于评估实体链接任务的域概括的数据集。
他们创建了16个世界数据集,这些数据集被分为火车 /开发 /测试的8/4/4,并且完全独立。
由于[Gillick等人,Conll'19]首先提出了用于实体链接的BI-(或双 - 双 - )编码系统,因此一些论文还利用了BERT。 [Gillick et al。,'18]也提出了基于生物编码器的检索系统的原始想法。
正如Wu等人,2020年所示,多型编码器也可以应用于实体链接。
基于变压器的编码器通常用于提及和实体编码。
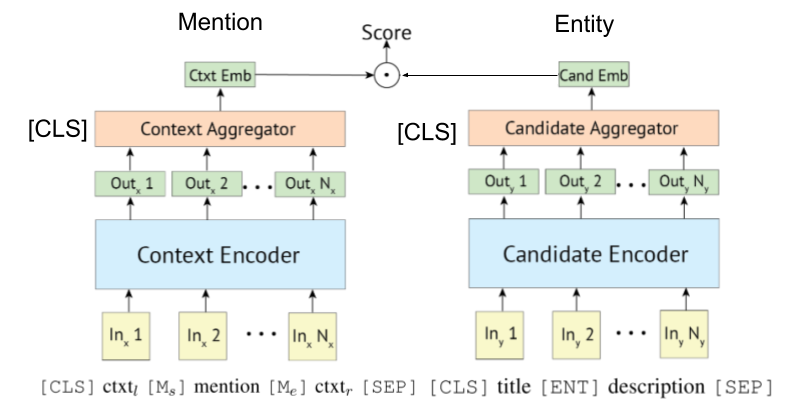
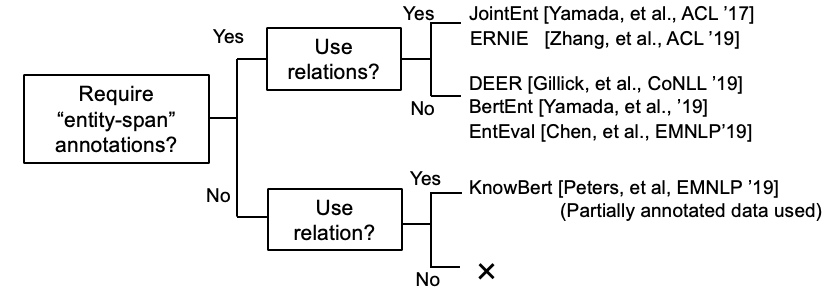
一些研究现在正在尝试将KB信息与Bert合并。
开普勒:一个统一的知识嵌入和预训练的语言表示模型(在19月119日,在进行中工作)
将图形上下文知识集成到预训练的语言模型中(在进行中工作 @ dec,'19)
K-Bert:通过知识图启用语言表示
[Petroni等,'19]检查了Bert本身是否具有事实知识。
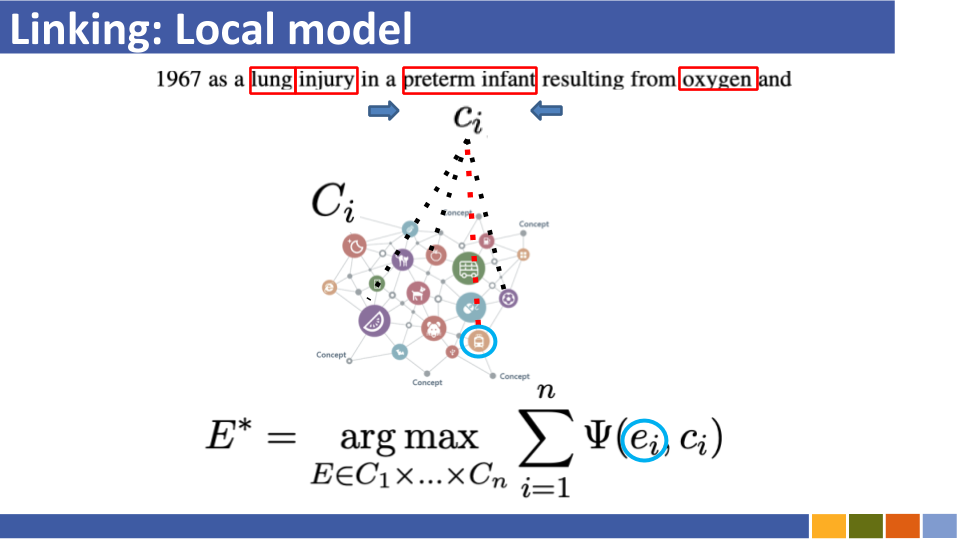
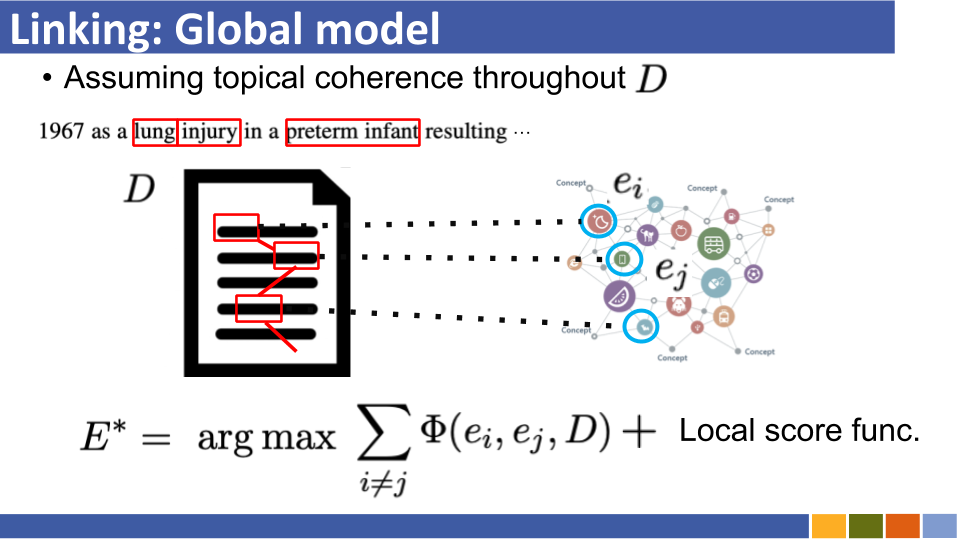
基于双重编码的实体将教程及其实施链接。 [关联]
已经出现了综合的实体链接调查文件。
(评论 @ 2020年3月)当前该存储库包括用于实体链接和实体LM的论文。前者需要编码实体表示以进行歧义,而后者则意味着在培训期间将实体知识注入LM。因此,它们完全不同,尽管某些实体LM的工作通过实体歧义评估了其模型。我们将在不久的将来将它们分开。
跨语言EL论文。
引用了Gupta等人。 (EMNLP '18)
跨语性实体链接(XEL)旨在以任何语言写入英语知识库(KB)(例如Wikipedia)的基础实体提及。
跨语性实体链接的联合多语言监督(EMNLP '18)
朝向零资源跨语言实体联系(Shuyan等人,EMNLP研讨会'19)
实体链接嘈杂/短文
短文本实体链接(ACL'18)[纸]的汇总语义匹配
在嘈杂的实体链接(EMNLP'18)[纸]中有效使用上下文
多模式实体链接
其他一些论文
仅清单实体链接纸
联合学习指定实体识别和链接纸的实体


