Entity Linking Recent Trends
1.0.0
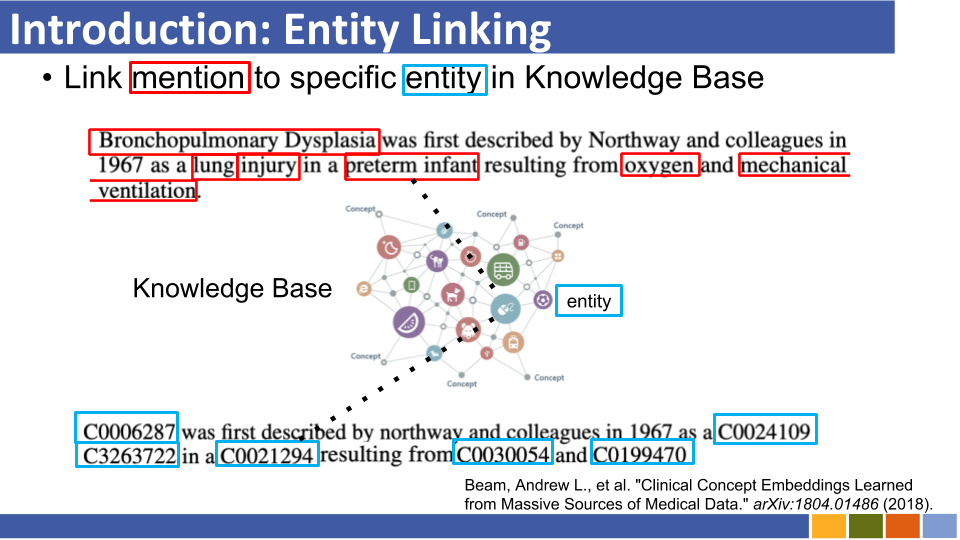
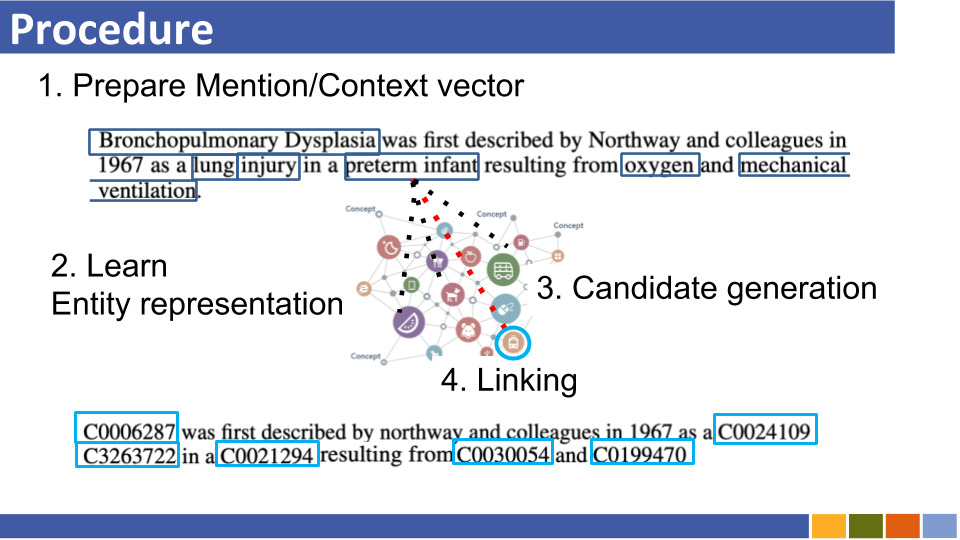
이 저장소는 엔티티 링크의 진행 상황을 추적하는 것을 목표로합니다. 엔티티 표현을 엔터티 링크와 함께 필수적이므로 엔티티 표현을 준비하는 방법에 대한 연구도 나열됩니다.
자동 회귀 실체 검색
기존 엔티티 링크 시스템은 지식 기반의 실체를 이전에 인코딩하여 메모리 소비, 지식 기반의 모든 엔티티의 비교로 인한 계산 자원 비용 및 냉장 문제로 인해 메모리 소비가 발생합니다.
이전 아키텍처 대신, 그들은 컨텍스트에 따라 조절 된 자동 회귀 방식으로 엔터티 이름을 생성하기 위해 시퀀스 간의 시퀀스를 이용합니다. 그들은 제한된 빔 검색을 사용하여 유효한 엔티티 식별자 만 디코딩하도록 강요했습니다.
엔티티를 임의의 스키마로 보이지 않는 지식 기반에 연결합니다
전통적인 엔티티 연결 시스템은 예측 된 엔티티를 하나로 묶는 지식 기반의 스키마가 알려져 있다고 가정합니다. 그들은 알 수없는 엔티티의 스키마를 속성 및 보조 토큰을 사용하여 Bert 임베딩으로 변환하는 새로운 방법을 제안했습니다.
동시에, 그들은 알려지지 않은 속성을 다루는 훈련 방법을 제안했습니다.
미디어 해상도 : 창의적 작품과 연결되는 이름 지정된 엔티티를 평가하기위한 코퍼스 [논문] [코드]
LUKE : 엔티티 인식 자체 변환과의 깊은 맥락화 된 엔티티 표현 [링크] [코드]
그들은 Bert를 기반으로 한 새로운 사전 조정 과제를 제안했는데, 여기서 Wikipedia의 엔티티 공유 코퍼스에서 무작위로 가려진 단어와 엔티티가 예측됩니다.
또한 사전 배치 작업에서, 그들은 확장 된 버전의 변압기를 제안했는데, 이는주의 점수를 계산할 때 엔티티 인식 자체 변환과 토큰 (단어 또는 엔티티)의 유형을 고려한 변압기를 제안했습니다.
밀집된 엔티티 검색과 연결되는 확장 가능한 제로 샷 엔티티
100 언어로 연결되는 엔티티 링크 [종이]
COCTA : 소셜 미디어에 연결하는 의료 기관을위한 코퍼스 [논문]
효율적인 장거리 시퀀스 모델링과 연결되는 제로 샷 엔터티 [용지]
0에서 영웅으로 : 낮은 리소스 도메인에서 링크 인 Human-in-Loop Entity [Link]
시맨틱 강화 엔터티 임베딩을 통한 엔터티 개선
사전 예방 백과 사전 : 약하게 감독 된 지식이없는 언어 모델 (ICLR'20) [논문]
K- 어택터 : 어댑터가있는 미리 훈련 된 모델에 지식을 주입 [종이]
잠재 엔티티 유형 정보 모델링을 통한 엔터티 링크 향상 (AAAI'20) 논문
밀집된 엔티티 검색 (10, 11 월)과 연결되는 제로 샷 엔터티
[Logeswaran, et al., ACL'19] 및 [Gillick, et al., Conll'19와 유사합니다.
슬라이드 (비공식)
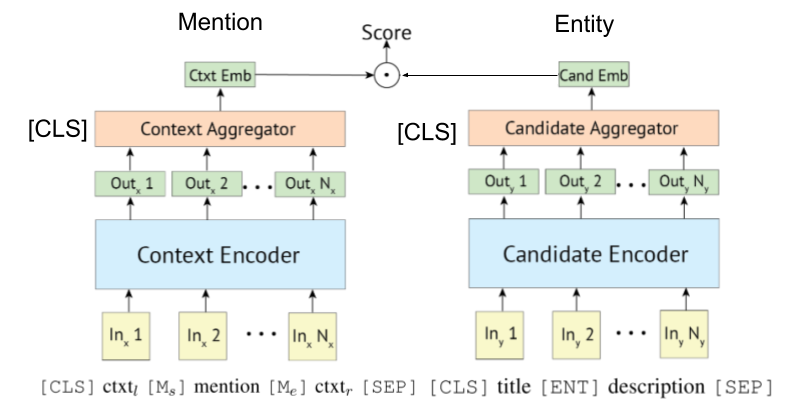
듀얼 및 교차 내역 인코더를 통한 엔터티 링크 [ARXIV]
엔티티 링크에 대한 세밀한 평가 (EMNLP'19)
글로벌 엔티티 링크에 대한 동적 상황 증강 학습 (EMNLP'19)
도메인 독립 엔티티 링크에 대한 세밀한 엔티티 타이핑
간단한 신경 종단 단체 연결 (Conll '19) [논문]으로 Bert에 대한 실체 지식 조사
엔티티 검색에 대한 조밀 한 표현 학습 (Conll '19)
종이, repo
그들은 별칭 테이블 (Wikipedia 통계 또는 준비된 하나를 기반으로 한)을 사용하지 않았으며 언급 당 링크 엔터티에 대한 Brute-Force/대략적인 검색으로 모든 엔티티를 검색했습니다.
Enteval : 엔티티 표현에 대한 전체적인 평가 벤치 마크 (EMNLP '19)
Wikipedia 카테고리의 소수의 재건에 대한 학습 기관 표현 (ICLR '19)
지식 향상된 맥락 단어 표현 (EMNLP '19) [논문]
모든 정보를 활용하는 트렌드 (예 : 언급의 유형 및 정의 및 언급이 존재하는 문서 등)는 반대되는 것으로 보입니다.
Wikipedia 도메인은 연결 모델을 훈련시키기 위해 하이퍼 링크 (= 언급-엔티티 쌍, 약 7,500,000)를 사용할 수 있지만, 일부 도메인 별 상황에서는 언급 쌍이 많지 않습니다.
따라서 일부 논문은 이제 법인 연결에 대한 먼 학습 및 제로 샷 학습에 도전하고 있습니다.
먼 학습
자동 노이즈 감지와 연결되는 실체에 대한 먼 학습
슬라이드 (비공식)
그들은 엘을 먼 학습 문제로 프레임을 제안했으며,이 작업에 대한 라벨이 붙은 교육 데이터가 없고이 작업에 대한 모델을 제거했습니다.
표지되지 않은 문서를 활용하여 성능을 연결하는 엔티티 강화
제로 샷 링크
독서 엔터티 설명을 통한 제로 쇼트 엔티티 링크
슬라이드 (비공식)
그들은 훈련 중에 테스트 언급을 볼 수없는 Zero-Shot EL을 제안했습니다. Zero-Shot EL을 다루기 위해 그들은 사전 훈련 언어 모델에 대한 도메인 적응 전략을 제안했습니다. 또한, 그들은 언급-엔티티 설명 교차 적분이 EL에게 중요하다는 것을 보여 주었다.
버트 기반 기업 표현 학습도 등장했습니다.
(Nov @ Nov, 19 ') 당시에는 모델 자체를 연결하는 엔티티를 개선하기위한 연구가 번성했습니다.
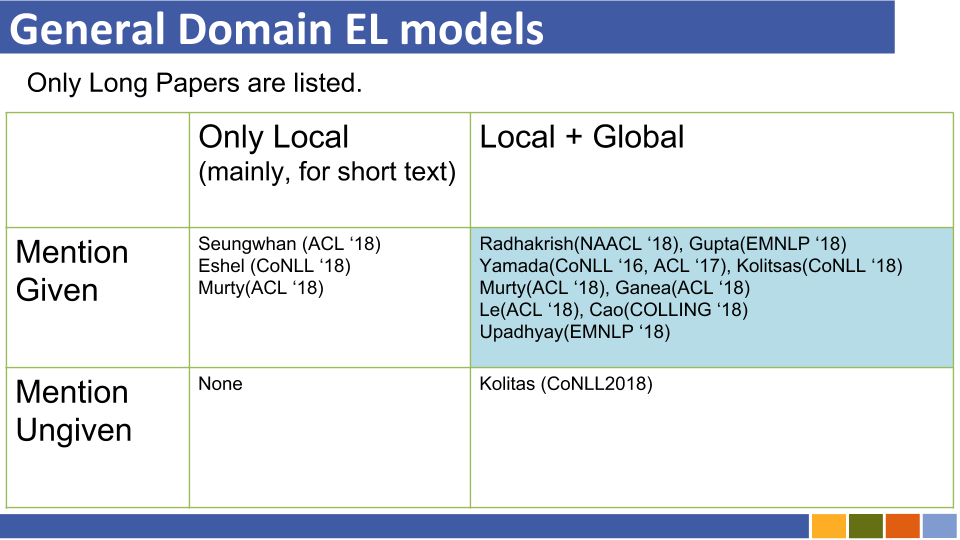
굵은 스타일은 특정 데이터 세트의 SOTA 점수를 나타냅니다.
| 기준선 모델 | 년도 | 데이터 세트 | 암호 | 달리다? | 코드 주소 |
|---|---|---|---|---|---|
| 유형, 설명 및 컨텍스트의 공동 인코딩을 통한 엔터티 연결 | EMNLP2017 | Conll-Yago (82.9, ACC), ACE2004, ACE2005, Wiki ( 89.0 , F1) | 텐서 플로 | Traind 모델 만 업로드됩니다 | 여기 |
| 짐 | EMNLP2018 | TH-TEST, MCN-TEST, TAC2015 | Pytorch | 확인 | 여기 |
| 신경 집단 단체 링크 (NCEL) | CL2018 | Conll-Yago, ACE2004, Aquaint, TAC2010 ( 91.0 , MIC-P), ww | Pytorch | 벌레 | 여기 |
| 언급 사이의 잠재 관계를 모델링하여 엔터티 연결 개선 | ACL2018 | Conll-Yago ( 93.07 , MIC-ACC), Aquaint, ACE2004, CWEB, Wiki (84.05, F1) | Pytorch | 평가 완료 | 여기 |
| 엘든 | NAACL2018 | Conll-PPD (93.0, P-MIC), TAC2010 (89.6, MIC-P) | 루아, 토치 (루아) | 벌레 | 여기 |
| 지역 신경의 관심으로 깊은 공동 실체 명확성 | EMNLP2017 | Conll-Yago (92.22, MIC-ACC), CWEB, WW, ACE2004, Aquaint, MSNBC | 루아, 토치 (루아) | 기차 달리기 (2019/01/15) | 여기 |
| 세밀한 기업 타이핑 및 연결을위한 계층 적 손실 및 새로운 리소스 | ACL2018 | 약점, typenet | Pytorch | 벌레 | 여기 |
| 명명 된 엔티티 명단에 대한 단어와 엔티티의 임베딩에 대한 공동 학습 (Yamada, Shindo) | Conll2016 | Conll-Yago (91.5, MIC-ACC), Conll-PPD (93.1, P-MIC), TAC2010 (85.5, MIC-ACC) | Pytorch/Tensorflow (원본), | 확인 | 기준선 원본 |
| 지식 기반의 텍스트 및 엔티티의 분산 표현 학습 (Yamada, Shindo) | ACL2017 | Conll-PPD ( 94.7 , P-MIC), TAC2010 (87.7, MIC-ACC) | Pytorch/Keras (원본) | 확인 | 토치, 토치, 원본 |
참고 :이 작업을 벤치마킹하기위한 주요 데이터 세트는 Blink 저장소에 나열되어 있습니다.
Mewsli-9 데이터 세트
생물 의학
약물 ([Mohan and Li, AKBC '19])
중재는 지명 된 엔티티 인식 및 생체 의학 영역에서 링크를위한 벤치 마크 데이터 세트로 만들어졌습니다.
실용적으로 사용하기에는 너무 광범위한 개념이 포함되어 있기 때문에, ST21PV는 이러한 광범위한 개념을 약물로부터 필터링함으로써 구성되었습니다.
BC5CDR ([Li et al., '15'])
BC5CDR은 Biocreative V 화학 및 질병 언급 인식 작업을 위해 생성 된 데이터 세트입니다.
15,935 개의 화학 물질과 12,852 개의 질병 언급이 포함 된 1,500 개의 기사로 구성됩니다.
참조 지식 기반은 메쉬이며, 거의 모든 언급에는 참조 지식 기반에 금 실체가 있습니다.
Wikimed 및 PubMedds ([Shikhar et al., '20])
Wikimed는 UML의 개념에 정규화 된 650,000 개 이상의 언급을 포함합니다. (인용)
또한 그들은 5 백만 개 이상의 정규화 된 언급을 가진 주석이 달린 코퍼스 PubMedds를 만들었습니다. 이 데이터 세트는 먼 감독에 의해 만들어졌으며, 이로 인해 시끄러운 주석이 유발됩니다.
제로 샷
Wikia 데이터 세트 ([Logeswaran et al., '19])
Wikia Hyperlinks 및 관련 테마에서 엔티티 링크 작업의 도메인 일반화를 평가하기위한 데이터 세트를 만들었습니다.
그들은 16 Worlds DataSet을 만들었습니다.이 데이터 세트는 기차 / 개발 / 테스트를 위해 8 / 4 / 4로 분할되었고 서로 독립적으로 독립했습니다.
[Gillick et al., Conll'19]는 먼저 엔티티 링크를위한 Bi- (또는 이중) 인코더 검색 시스템을 제안했기 때문에 일부 논문은 Bert를 활용합니다. Biencoder 기반 검색 시스템에 대한 원래 아이디어는 또한 [Gillick et al., '18]에 의해 제안된다.
Wu et al., 2020이 보여준 바와 같이, 폴리-인코더는 또한 엔티티 링크에 적용될 수있다.
변압기 기반 인코더는 종종 언급 및 엔티티 인코딩을 위해 채택됩니다.
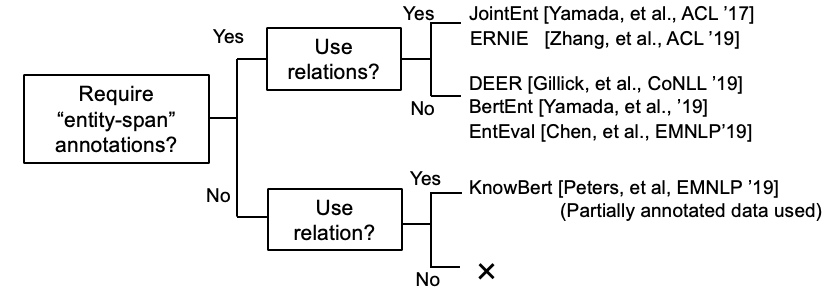
일부 연구는 현재 KB 정보를 BERT에 통합하려고 노력하고 있습니다.
KEPLER : 지식 임베딩 및 미리 훈련 된 언어 표현을위한 통일 된 모델 (11 월, '19)
그래프 맥락화 된 지식을 미리 훈련 된 언어 모델에 통합 (Dec @ Dec, '19)
K-Bert : 지식 그래프로 언어 표현 활성화
[Petroni, et al., '19]는 Bert 자체가 사실 지식을 가지고 있는지 확인했다.
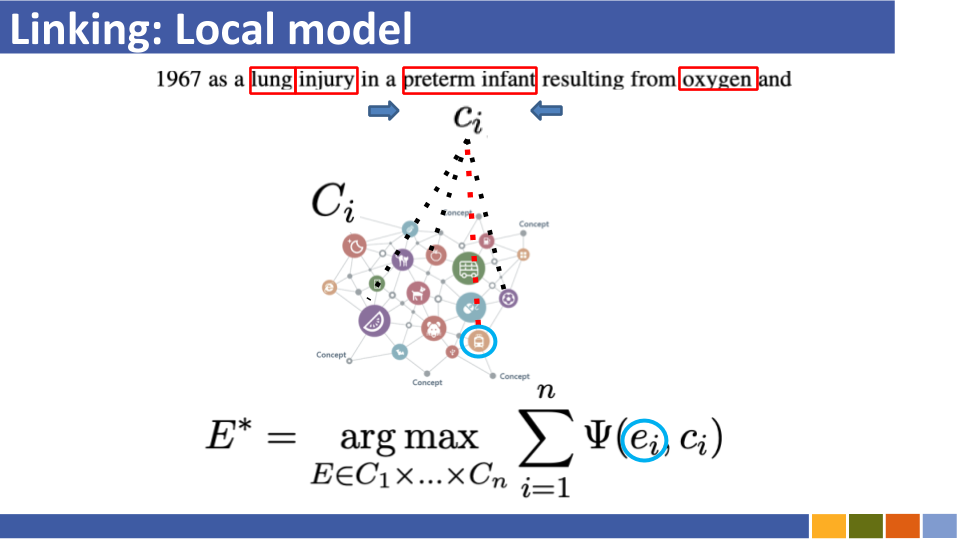
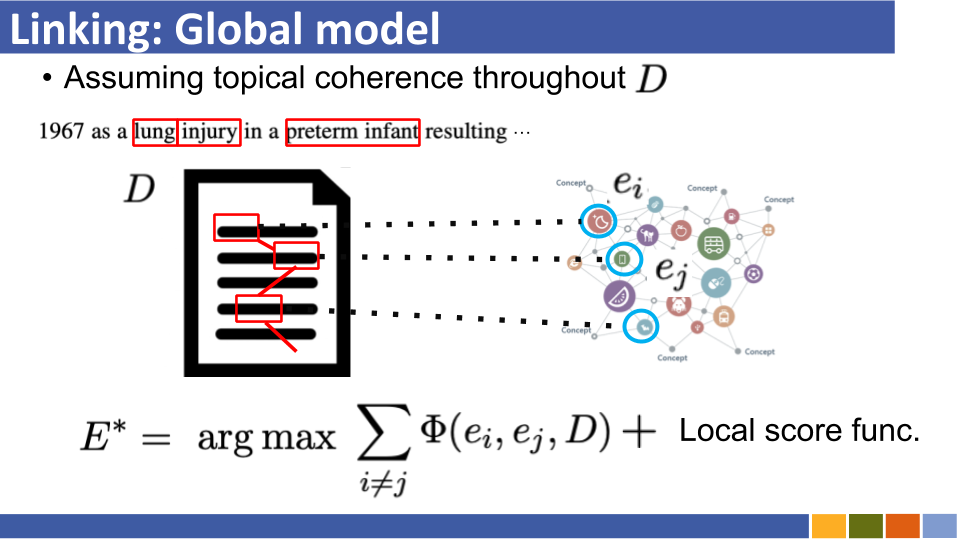
바이 코더 기반 엔터티 링크 튜토리얼 및 구현. [링크]
Entity Linking의 포괄적 인 설문 조사 논문이 나타났습니다.
(2020 년 3 월 @ 댓글) 현재이 저장소에는 엔터티 링크와 엔터티 LM의 논문이 포함되어 있습니다. 전자는 명확성을 위해 엔티티 표현을 인코딩 해야하는 반면, 후자는 훈련 중에 엔티티 지식을 LM에 주입하는 것을 의미합니다. 따라서 일부 엔티티 LM의 작품은 엔티티 명단으로 모델을 평가했지만 완전히 상이합니다. 우리는 가까운 장래 에이 저장소에서 그것들을 분리 할 것입니다.
교차 언어 EL 논문.
Gupta et al. (emnlp '18)
XEL (Cross-Lirenual Entity Linking)은 Wikipedia와 같은 영어 지식 기반 (KB)에 모든 언어로 작성된 지상 엔티티 언급을 목표로합니다.
교차 언어 엔티티 링크에 대한 공동 다국어 감독 (EMNLP '18)
제로 소스 자원 간 교차 실체 연결 (Shuyan et al., EMNLP Workshop '19)
시끄러운/짧은 텍스트에 대한 엔티티 링크
짧은 텍스트 엔티티 링크 (ACL'18)에 대한 집계 시맨틱 매칭 [논문]
시끄러운 엔티티 링크에서 컨텍스트의 효과적인 사용 (EMNLP'18) [논문]
멀티 모달 엔티티 링크
다른 논문
목록 전용 엔터티 링크 용지
지명 된 기업 인식 및 엔티티 연결 용지의 공동 학습


