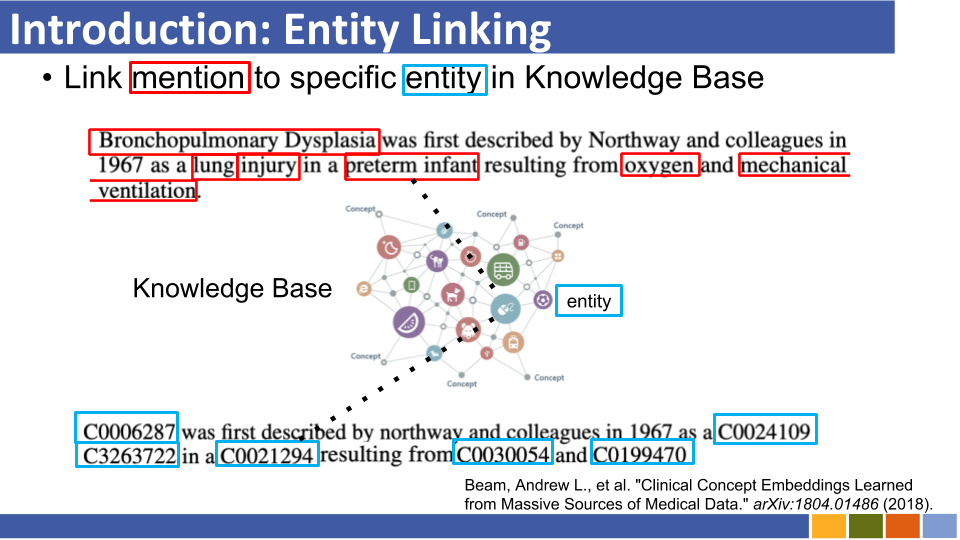
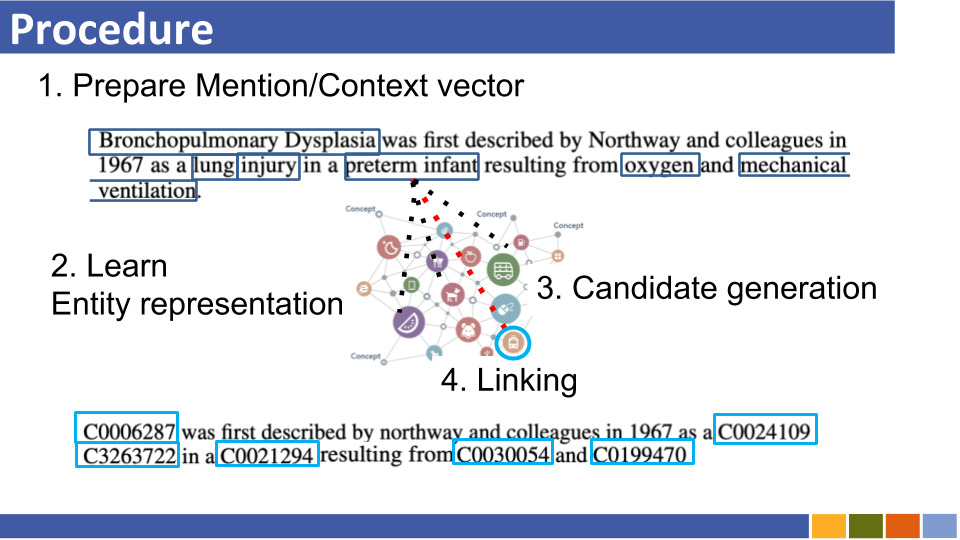
Entity Linking Recent Trends
1.0.0
ที่เก็บนี้มีวัตถุประสงค์เพื่อติดตามความคืบหน้าในการเชื่อมโยงเอนทิตี การศึกษาเกี่ยวกับวิธีการเตรียมการเป็นตัวแทนของเอนทิตีนั้นมีการระบุไว้เช่นกันเนื่องจากการเป็นตัวแทนของเอนทิตีนั้นมีผลบังคับใช้กับการเชื่อมโยงเอนทิตี
การดึงเอนทิตีอัตโนมัติ
ระบบการเชื่อมโยงเอนทิตีแบบดั้งเดิมได้รับผลกระทบจากการใช้หน่วยความจำเนื่องจากการเข้ารหัสเอนทิตีก่อนหน้าในฐานความรู้ต้นทุนทรัพยากรการคำนวณเนื่องจากการเปรียบเทียบเอนทิตีทั้งหมดในฐานความรู้และปัญหาการเริ่มต้นเย็น
แทนที่จะเป็นสถาปัตยกรรมก่อนหน้านี้พวกเขาใช้ประโยชน์จากลำดับต่อลำดับเพื่อสร้างชื่อเอนทิตีในแฟชั่นอัตโนมัติที่มีเงื่อนไขในบริบท พวกเขาใช้การค้นหาลำแสงแบบ จำกัด บังคับให้ถอดรหัสตัวระบุเอนทิตีที่ถูกต้องเท่านั้น
การเชื่อมโยงหน่วยงานกับฐานความรู้ที่มองไม่เห็นด้วยแผนการโดยพลการ
ระบบการเชื่อมโยงเอนทิตีแบบดั้งเดิมสันนิษฐานว่าสคีมาของฐานความรู้ที่เชื่อมโยงหน่วยงานที่คาดการณ์ไว้ด้วยกัน พวกเขาเสนอวิธีการใหม่ในการแปลงสคีมาของเอนทิตีที่ไม่รู้จักเป็นการฝังเบิร์ตโดยใช้แอตทริบิวต์และโทเค็นเสริม
ในเวลาเดียวกันพวกเขายังเสนอวิธีการฝึกอบรมเพื่อจัดการกับคุณลักษณะที่ไม่รู้จัก
ในสื่อ Res: คลังข้อมูลสำหรับการประเมินชื่อการเชื่อมโยงเอนทิตีกับงานสร้างสรรค์ [กระดาษ] [รหัส]
ลุค: การเป็นตัวแทนของนิติบุคคลที่มีบริบทอย่างลึก
พวกเขาเสนองานการเตรียมการใหม่โดยใช้เบิร์ตซึ่งมีการทำนายคำและนิติบุคคลที่สวมหน้ากากแบบสุ่มในคลังข้อมูลที่มีข้ออ้างในเอนทิตีจากวิกิพีเดีย
นอกจากนี้ในภารกิจการเตรียมการพวกเขาเสนอเวอร์ชันขยายของหม้อแปลงซึ่งพิจารณาถึงการใช้ตัวเองที่ตระหนักถึงเอนทิตีและประเภทของโทเค็น (คำหรือเอนทิตี) เมื่อคำนวณคะแนนความสนใจ
การเชื่อมโยงเอนทิตีศูนย์การยิงที่ปรับขนาดได้กับการดึงเอนทิตีหนาแน่น
เอนทิตีเชื่อมโยงใน 100 ภาษา [กระดาษ]
Cometa: คลังข้อมูลการแพทย์ที่เชื่อมโยงในโซเชียลมีเดีย [กระดาษ]
zero-shot entity เชื่อมโยงกับการสร้างแบบจำลองลำดับระยะยาวที่มีประสิทธิภาพ [กระดาษ]
จากศูนย์ถึงฮีโร่: การเชื่อมโยงเอนทิตีของมนุษย์ในลูปในโดเมนทรัพยากรต่ำ [ลิงก์]
การปรับปรุงเอนทิตีที่เชื่อมโยงผ่านการฝังเอนทิตีเสริมความหมาย
สารานุกรมที่ได้รับการฝึกฝนมาก่อน: แบบจำลองภาษาที่มีความรู้ที่มีความรู้อย่างอ่อน (ICLR'20) [PAPER]
K-Adapter: ผสมผสานความรู้เข้ากับโมเดลที่ผ่านการฝึกอบรมมาก่อนด้วยอะแดปเตอร์ [กระดาษ]
การปรับปรุงการเชื่อมโยงเอนทิตีโดยการสร้างแบบจำลองข้อมูลประเภทเอนทิตีแฝง (aaai'20) กระดาษ
zero-shot entity เชื่อมโยงกับกระดาษการดึงเอนทิตีหนาแน่น (10, พฤศจิกายน)
คล้ายกับ [Logeswaran, et al., Acl'19] และ [Gillick, et al., Conll'19]
สไลด์ (ไม่เป็นทางการ)
การเชื่อมโยงเอนทิตีผ่านตัวเข้ารหัสแบบคู่และข้ามความสนใจ [arxiv]
การประเมินผลอย่างละเอียดสำหรับการเชื่อมโยงเอนทิตี (EMNLP'19)
การเรียนรู้การเพิ่มบริบทแบบไดนามิกสำหรับการเชื่อมโยงเอนทิตีระดับโลก (EMNLP'19)
การพิมพ์เอนทิตีที่ละเอียดสำหรับการเชื่อมโยงเอนทิตีอิสระของโดเมน
การตรวจสอบความรู้ของเอนทิตีในเบิร์ตด้วยการเชื่อมโยงเอนทิตีแบบ end-to-end อย่างง่าย (Conll '19) [กระดาษ]
การเรียนรู้การเป็นตัวแทนหนาแน่นสำหรับการดึงเอนทิตี (Conll '19)
กระดาษ repo
พวกเขาเสนอว่าไม่มีการใช้งานตารางนามแฝง (ซึ่งใช้สถิติวิกิพีเดียหรือเตรียมหนึ่ง) และค้นหาเอนทิตีทั้งหมดโดยการค้นหาเดรัจฉาน/การค้นหาที่ใกล้ที่สุดโดยประมาณสำหรับการเชื่อมโยงเอนทิตีต่อการกล่าวถึง
ENTEVAL: มาตรฐานการประเมินแบบองค์รวมสำหรับการเป็นตัวแทนเอนทิตี (EMNLP '19)
การเป็นตัวแทนเอนทิตีการเรียนรู้สำหรับการสร้างหมวดหมู่วิกิพีเดียไม่กี่ครั้ง (ICLR '19)
ความรู้ที่เพิ่มขึ้นการแสดงคำบริบท (EMNLP '19) [กระดาษ]
แนวโน้มของการใช้ประโยชน์จากข้อมูลทั้งหมด (เช่นประเภทและคำจำกัดความและเอกสารที่กล่าวถึงมีอยู่ ฯลฯ ... ) ดูเหมือนว่าจะไม่พอใจ
แม้ว่าโดเมน Wikipedia สามารถใช้การเชื่อมโยงหลายมิติ (= คู่ที่กล่าวถึง-ประมาณ 7,500,000) สำหรับรูปแบบการเชื่อมโยงการฝึกอบรมภายใต้สถานการณ์เฉพาะโดเมนบางอย่างมีคู่ที่กล่าวถึงไม่มากนัก
ดังนั้นเอกสารบางฉบับจึงท้าทายการเรียนรู้ระยะไกลและการเรียนรู้แบบไม่ยิงแบบไม่มีการเชื่อมโยงเอนทิตี
การเรียนรู้ที่ห่างไกล
การเรียนรู้ระยะไกลสำหรับการเชื่อมโยงเอนทิตีกับการตรวจจับเสียงอัตโนมัติ
สไลด์ (ไม่เป็นทางการ)
พวกเขาเสนอให้ Framing EL เป็นปัญหาการเรียนรู้ที่ห่างไกลซึ่งไม่มีข้อมูลการฝึกอบรมที่มีป้ายกำกับและรูปแบบการยกเลิกการทำเสียงสำหรับงานนี้
การเพิ่มประสิทธิภาพการเชื่อมโยงเอนทิตีโดยใช้ประโยชน์จากเอกสารที่ไม่มีป้ายกำกับ
การเชื่อมโยงแบบไม่มีการยิง
การเชื่อมโยงเอนทิตี zero-shot โดยการอ่านคำอธิบายเอนทิตี
สไลด์ (ไม่เป็นทางการ)
พวกเขาเสนอ zero-shot el ซึ่งไม่มีการกล่าวถึงการทดสอบในระหว่างการฝึกอบรม สำหรับการจัดการกับศูนย์ EL พวกเขาเสนอกลยุทธ์การปรับโดเมนสำหรับแบบจำลองภาษาก่อนการฝึกอบรม นอกจากนี้พวกเขายังแสดงให้เห็นว่าคำอธิบายการพูดคุยเกี่ยวกับความสนใจเป็นสิ่งสำคัญสำหรับเอล
การเรียนรู้การเป็นตัวแทนของเอนทิตีที่ใช้เบิร์ตก็เกิดขึ้นเช่นกัน
(แสดงความคิดเห็น @ nov, 19 ') ในสมัยนั้นงานวิจัยเพื่อปรับปรุง โมเดล การเชื่อมโยงเอนทิตีของตัวเองกำลังเฟื่องฟู
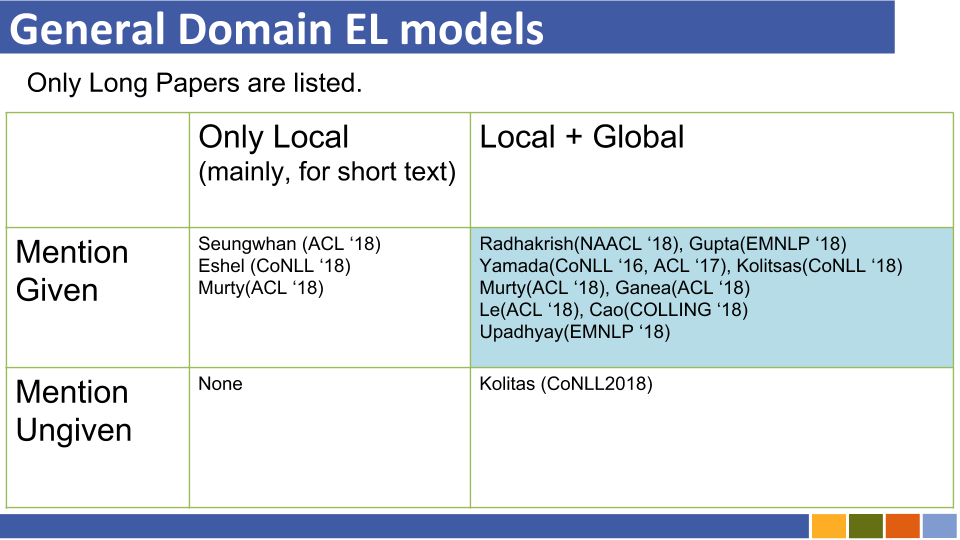
สไตล์ตัวหนา แสดงคะแนน SOTA ของชุดข้อมูลที่เฉพาะเจาะจง
| รุ่นพื้นฐาน | ปี | ชุดข้อมูล | รหัส | วิ่ง? | ที่อยู่รหัส |
|---|---|---|---|---|---|
| การเชื่อมโยงเอนทิตีผ่านการเข้ารหัสแบบร่วมของประเภทคำอธิบายและบริบท | EMNLP2017 | Conll-Yago (82.9, ACC), ACE2004, ACE2005, Wiki ( 89.0 , F1) | เทนเซอร์โฟลว์ | อัปโหลดรุ่นรถไฟเท่านั้น | ที่นี่ |
| ┗ (คล้ายกับข้างต้น) การกำกับดูแลหลายภาษาร่วมกันสำหรับการเชื่อมโยงเอนทิตีข้ามภาษา | EMNLP2018 | th-test, MCN-test, TAC2015 | pytorch | การตรวจสอบ | ที่นี่ |
| การเชื่อมโยงเอนทิตี้ของกลุ่มประสาท (NCEL) | CL2018 | Conll-Yago, Ace2004, Aquaint, TAC2010 ( 91.0 , MIC-P), WW | pytorch | ข้อผิดพลาด | ที่นี่ |
| การปรับปรุงการเชื่อมโยงเอนทิตีโดยการสร้างแบบจำลองความสัมพันธ์แฝงระหว่างการกล่าวถึง | ACL2018 | Conll-Yago ( 93.07 , MIC-ACC), Aquaint, Ace2004, CWEB, Wiki (84.05, F1) | pytorch | ประเมินผล | ที่นี่ |
| เอลเดน | NAACL2018 | Conll-PPD (93.0, P-MIC), TAC2010 (89.6, MIC-P) | Lua, Torch (Lua) | ข้อผิดพลาด | ที่นี่ |
| ความไม่ลงรอยกันของกิจการร่วมกัน | EMNLP2017 | Conll-Yago (92.22, MIC-ACC), CWEB, WW, ACE2004, Aquaint, MSNBC | Lua, Torch (Lua) | รถไฟวิ่ง (2019/01/15) | ที่นี่ |
| การสูญเสียลำดับชั้นและทรัพยากรใหม่สำหรับการพิมพ์และเชื่อมโยงเอนทิตี้ | ACL2018 | Medmentions, Typenet | pytorch | ข้อผิดพลาด | ที่นี่ |
| การเรียนรู้ร่วมกันเกี่ยวกับการฝังคำและเอนทิตีสำหรับความไม่ลงรอยกันของเอนทิตี (ยามาดะ, ชินโด) | Conll2016 | Conll-Yago (91.5, MIC-ACC), Conll-PPD (93.1, P-MIC), TAC2010 (85.5, MIC-ACC) | Pytorch/Tensorflow (ต้นฉบับ) | การตรวจสอบ | ต้นฉบับพื้นฐาน |
| การเรียนรู้การเป็นตัวแทนของตำราและนิติบุคคลจากฐานความรู้ (ยามาดะ, ชินโด) | ACL2017 | Conll-PPD ( 94.7 , P-MIC), TAC2010 (87.7, MIC-ACC) | Pytorch/Keras (ต้นฉบับ) | การตรวจสอบ | คบเพลิงคบเพลิงต้นฉบับ |
หมายเหตุ: ชุดข้อมูลหลักสำหรับการเปรียบเทียบงานนี้มีการระบุไว้ที่พื้นที่เก็บข้อมูลกะพริบ
ชุดข้อมูล mewsli-9
เกี่ยวกับชีวการแพทย์
Medmentions ([Mohan and Li, Akbc '19])
Medmentions ถูกสร้างขึ้นเป็นชุดข้อมูลมาตรฐานสำหรับการรับรู้เอนทิตีที่มีชื่อและการเชื่อมโยงเอนทิตีในโดเมนชีวการแพทย์
เนื่องจากมีแนวคิดมากมายที่กว้างเกินไปที่จะใช้งานจริง ST21PV ถูกสร้างขึ้นโดยการกรองแนวคิดที่กว้างเหล่านั้นออกจากการรับประทานอาหาร
BC5CDR ([Li et al., '15'])
BC5CDR เป็นชุดข้อมูลที่สร้างขึ้นสำหรับงาน Biocreative V Chemical and Disease กล่าวถึงงานการรับรู้
ประกอบด้วย 1,500 บทความที่มีสารเคมี 15,935 และ 12,852 กล่าวถึงโรค
ฐานความรู้อ้างอิงคือตาข่ายและเกือบทั้งหมดกล่าวถึงมีเอนทิตีทองคำในฐานความรู้อ้างอิง
Wikimed และ PubMedds ([Shikhar et al., '20])
Wikimed มีมากกว่า 650,000 กล่าวถึงแนวคิดในแนวคิดใน UMLS (อ้างถึง)
นอกจากนี้พวกเขายังสร้างคลังข้อมูลที่มีคำอธิบายประกอบ PubMedds ด้วยการกล่าวถึงปกติมากกว่า 5 ล้านครั้ง โปรดทราบว่าชุดข้อมูลนี้ถูกสร้างขึ้นโดยการกำกับดูแลที่ห่างไกลซึ่งนำไปสู่การสร้างคำอธิบายประกอบที่มีเสียงดัง
เป็นศูนย์
ชุดข้อมูล Wikia ([Logeswaran et al., '19])
จากการเชื่อมโยงหลายมิติของ Wikia และธีมที่เกี่ยวข้องพวกเขาสร้างชุดข้อมูลสำหรับการประเมินการวางนัยทั่วไปของงานการเชื่อมโยงเอนทิตี
พวกเขาสร้างชุดข้อมูล 16 Worlds ซึ่งแบ่งออกเป็น 8/4/4 สำหรับรถไฟ / dev / test และเป็นอิสระอย่างสมบูรณ์ซึ่งกันและกัน
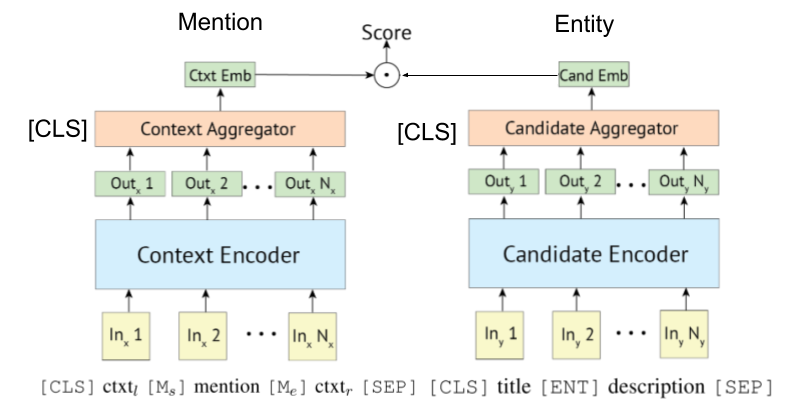
เนื่องจาก [Gillick et al., Conll'19] ครั้งแรกที่เสนอระบบการดึงตัวเข้ารหัส bi- (หรือ dual-) ครั้งแรกสำหรับการเชื่อมโยงเอนทิตีเอกสารบางฉบับยังใช้ประโยชน์จากเบิร์ตสำหรับพวกเขา แนวคิดดั้งเดิมสำหรับระบบดึงข้อมูลที่ใช้ biencoder ยังเสนอโดย [Gillick et al., '18]
โพลี-เข้ารหัสยังสามารถนำไปใช้กับการเชื่อมโยงเอนทิตีเช่น Wu et al., 2020 แสดงให้เห็น
เครื่องเข้ารหัสที่ใช้หม้อแปลงมักจะถูกนำมาใช้เพื่อการกล่าวถึงและการเข้ารหัสเอนทิตี
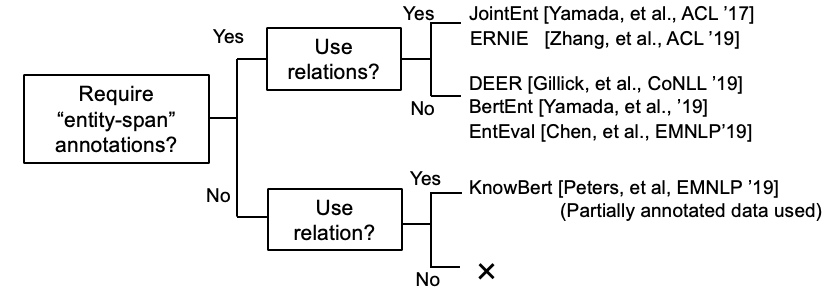
งานวิจัยบางอย่างกำลังพยายามรวมข้อมูล KB กับ Bert
Kepler: รูปแบบแบบครบวงจรสำหรับการฝังความรู้และการเป็นตัวแทนภาษาที่ผ่านการฝึกอบรมมาก่อน (ทำงานระหว่างดำเนินการ @ nov, '19)
การบูรณาการความรู้เชิงบริบทของกราฟเข้ากับแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อน (ทำงานอยู่ระหว่างดำเนินการ @ ธ.ค. '19)
K-Bert: เปิดใช้งานการเป็นตัวแทนภาษาด้วยกราฟความรู้
[Petroni, et al., '19] ตรวจสอบว่าเบิ ร์ ตมีความรู้จริงหรือไม่
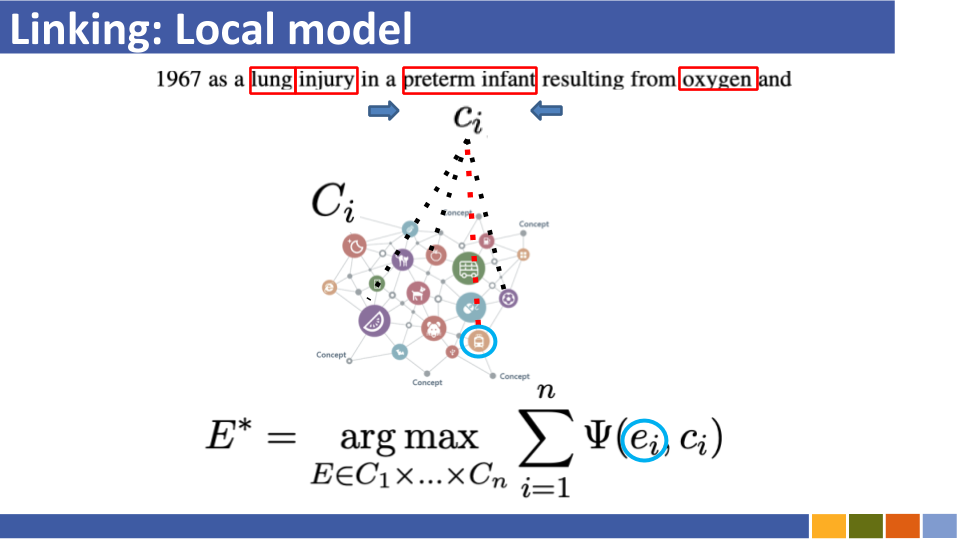
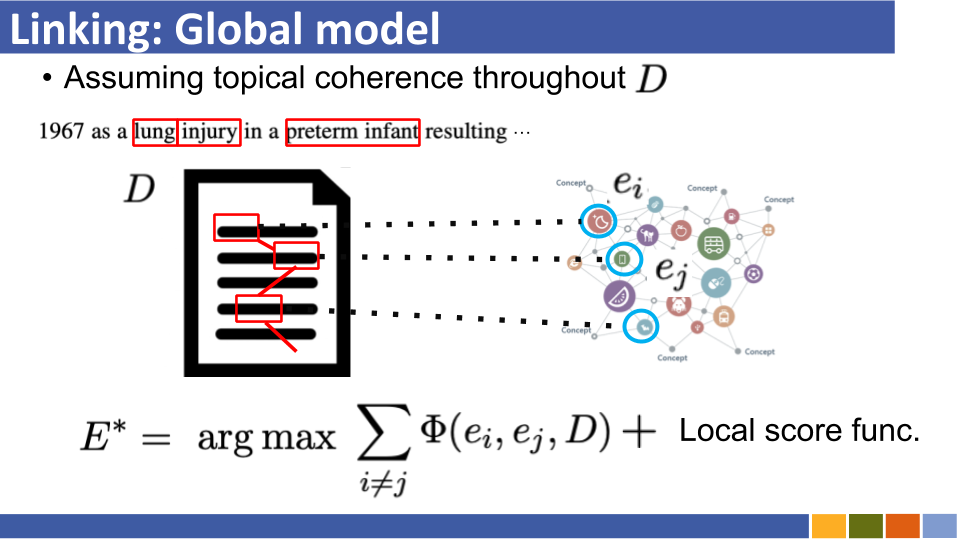
การเชื่อมโยงเอนทิตีที่ใช้การเข้ารหัสแบบ Bi-encoder และการใช้งาน [ลิงก์]
กระดาษสำรวจที่ครอบคลุมของการเชื่อมโยงเอนทิตีปรากฏขึ้น
(แสดงความคิดเห็น @ March, 2020) ปัจจุบันที่เก็บนี้มีเอกสารสำหรับการเชื่อมโยงทั้งเอนทิตีและเอนทิตี LM อดีตต้องการการเข้ารหัสนิติบุคคลสำหรับการสร้างความไม่ลงรอยกันในขณะที่หลังหมายถึงการฉีดความรู้เอนทิตีลงใน LM ในระหว่างการฝึกอบรม ดังนั้นพวกเขาจึงแตกต่างกันอย่างสมบูรณ์แม้ว่างานของเอนทิตี LM จะประเมินแบบจำลองด้วยความไม่ลงรอยกันของเอนทิตี เราจะแยกพวกเขาที่ที่เก็บนี้ในอนาคตอันใกล้
เอกสาร EL แบบข้ามภาษา
อ้างถึงจาก Gupta และคณะ (emnlp '18)
การเชื่อมโยงเอนทิตี้ข้ามภาษา (XEL) มีจุดมุ่งหมายเพื่อกล่าวถึงสิ่งที่เขียนไว้ในภาษาใด ๆ กับฐานความรู้ภาษาอังกฤษ (KB) เช่น Wikipedia
การกำกับดูแลหลายภาษาร่วมกันสำหรับการเชื่อมโยงเอนทิตีข้ามภาษา (EMNLP '18)
ไปสู่การเชื่อมโยงเอนทิตีข้ามภาษาที่เป็นศูนย์ (Shuyan et al., EMNLP Workshop '19)
การเชื่อมโยงเอนทิตีสำหรับข้อความที่มีเสียงดัง/สั้น
การจับคู่ความหมายแบบรวมสำหรับการเชื่อมโยงเอนทิตีข้อความสั้น ๆ (ACL'18) [กระดาษ]
การใช้บริบทอย่างมีประสิทธิภาพในการเชื่อมโยงเอนทิตีที่มีเสียงดัง (EMNLP'18) [กระดาษ]
การเชื่อมโยงเอนทิตีหลายรูปแบบ
เอกสารอื่น ๆ
เอกสารเชื่อมโยงเอนทิตีรายการเท่านั้น
การเรียนรู้ร่วมกันของการรับรู้เอนทิตีที่มีชื่อและกระดาษเชื่อมโยงเอนทิตี


