Entity Linking Recent Trends
1.0.0
Dieses Repository zielt darauf ab, die Fortschritte bei der Entitätsverbindung zu verfolgen. Studien zur Erstellung von Unternehmensdarstellungen werden ebenfalls aufgeführt, da Entitätsdarstellungen bei der Verknüpfung der Entität obligatorisch sind.
Autoregressive Entität Abruf
Traditionelle Entitätsverbinden von Systemen leiden unter dem Speicherverbrauch aufgrund der vorherigen Kodierung von Entitäten in der Wissensbasis, den Rechenressourcenkosten aufgrund des Vergleichs aller Einheiten in der Wissensbasis und kaltem Startproblemen.
Anstelle einer früheren Architektur nutzen sie eine Sequenz zu Sequenz, um Entitätsnamen autoregressiv zu generieren, die auf den Kontext konditioniert sind. Sie verwendeten eine beengte Strahlsuche, um nur die gültige Entitätskennung zu entschlüsseln.
Verknüpfung von Einheiten mit unsichtbaren Wissensbasis mit willkürlichen Schemata
Traditionelle Entitätsverbindungssysteme gehen davon aus, dass das Schema der Wissensbasis, das die vorhergesagten Entitäten zusammenbringt, bekannt ist. Sie schlugen eine neue Methode vor, um das Schema unbekannter Entitäten in Bert -Einbettung unter Verwendung von Attributen und Hilfs -Token umzuwandeln.
Gleichzeitig schlugen sie auch eine Trainingsmethode vor, um mit unbekannten Attributen umzugehen.
In Media Res: Ein Korpus zur Bewertung der benannten Entität, die mit kreativen Werken verknüpft wird [Papier] [Codes]
Lukas: Deep Contextualisierte Entitätsdarstellungen mit Entitätsbewusstsein [Link] [Codes]
Sie schlugen eine neue Aufgabe vor der Basis von Bert vor, bei der zufällig maskierte Wörter und Entitäten im von Wikipedia entitätsanannten Korpus vorhergesagt werden.
Auch bei der Vorbereitungsaufgabe schlugen sie eine erweiterte Version des Transformators vor, die eine Entitätsbewusstsein und die Arten von Token (Wörter oder Entitäten) bei der Berechnung von Aufmerksamkeitswerten berücksichtigt.
Skalierbares Zero-Shot-Entität, das mit einer dichten Entitätsabnahme verbindet
Entitätsverbinden in 100 Sprachen [Papier]
COMETA: Ein Korpus für die medizinische Einheit, die in den sozialen Medien verbindet [Papier]
Null-Shot-Entität, die mit einer effizienten Langstreckensequenzmodellierung verknüpft ist [Papier]
Von Null zum Helden: Menschen in der Schleife, die in Domänen mit niedrigen Ressourcen verlinkt [Link]
Verbesserung der Einheit, die durch semantische verstärkte Einbettung verbunden ist
Vorbereitete Enzyklopädie: schwach überwachtes kenntnisgefälliges Sprachmodell (ICLR'20) [Papier]
K-Adapter: Wissen in vorgeborene Modelle mit Adaptern [Papier] in vorgebrachte Modelle einfließen lassen.
Verbesserung der Entitätsverbindung durch Modellierung von Latent Entity -Informationen (AAAI'20) Papier
Zero-Shot-Entität, die sich mit einer dichten Entitätsabnahme (10., Nov.) Papier verknüpfen
Ähnlich wie [Logeswaran et al., ACL'19] und [Gillick, et al., Conll'19]
Folien (inoffiziell)
Entität, die über Dual- und Cross-Tentention-Encoder verknüpft [ARXIV]
Feinkörnige Bewertung für die Entitätsverbindung (EMNLP'19)
Lerndynamische Kontextvergrößerung für die globale Entitätsverknüpfung (EMNLP'19)
Feinkörnige Entität Typisierung für domänenunabhängige Entitätsverbinden
Untersuchung von Unternehmen Kenntnissen in Bert mit einfacher neuronaler End-to-End-Entitätsverknüpfung (conll '19) [Papier]
Dense Repräsentationen für die Entitätsabnahme (Conll '19)
Papier, Repo
Sie schlugen keine Verwendung der Alias-Tabelle (die auf Wikipedia-Statistiken oder vorbereiteten verwendet wurde) und durchsuchten alle Entitäten nach Brute-Force/Unen-nächstgelegener Suche nach Verknüpfungsentität pro Erwähnung.
Enteval: Ein ganzheitlicher Bewertungs -Benchmark für Entitätsdarstellungen (EMNLP '19)
Repräsentationen für Lernentität für wenige Schussrekonstruktion von Wikipedia-Kategorien (ICLR '19)
Wissen verstärkte kontextbezogene Wortrepräsentationen (EMNLP '19) [Papier]
Trends zur Nutzung aller Informationen (z. B. die Art und Definition von Erwähnung und Dokumente, in denen erwähnt wird, usw.) scheinen zu enttäuschten.
Obwohl die Wikipedia-Domäne seinen Hyperlink (= Erwähnungspaare, etwa 7.500.000) für das Trainingsverbindenmodell verwenden kann, gibt es unter einigen domänenspezifischen Situationen nicht so viele Paare für Erwähnung von Zeugen.
Daher sind einige Papiere jetzt herausfordern, dass das Lernen von Fernlosen und Null-Shot-Lernen einer Entitätsverbindung gelernt wird.
Fernerkenntnis
Fernerkenntnis für Entität, die mit automatischer Rauscherkennung verknüpft ist
Folien (inoffiziell)
Sie schlugen das Rahmung von EL als fernes Lernproblem vor, bei dem keine beschrifteten Trainingsdaten verfügbar sind, und das De-Noising-Modell für diese Aufgabe.
Steigerung der Entität, die die Leistung verbindet, indem unmarkierte Dokumente eingesetzt werden
Null-Shot-Verknüpfung
Null-Shot-Entität, die durch Lesen von Entitätsbeschreibungen verlinkt wird
Folien (inoffiziell)
Sie schlugen Null-Shot El vor, unter denen während des Trainings keine Test erwähnt werden können. Für die Bekämpfung von Null-Shot EL schlugen sie eine Domänenanpassungsstrategie für das Voraussetzungsmodell vor. Außerdem zeigten sie, dass die Beschreibung der Erwähnung der Entfernung von EL von entscheidender Bedeutung ist.
Das Lernen von Bert-basierten Entitäten Repräsentation entstand ebenfalls.
(Kommentierte @ Nov, 19 ') In jenen Tagen blühten die Forschungen zur Verbesserung der Verbindungsverbindung des Unternehmens auf.
Fetthaltiger Stil zeigt den SOTA -Score eines bestimmten Datensatzes an.
| Basismodelle | Jahr | Datensatz | Code | Laufen? | Codeadresse |
|---|---|---|---|---|---|
| Entität, die durch gemeinsame Codierung von Typen, Beschreibungen und Kontext verlinkt wird | EMNLP2017 | Conll-Yago (82,9, ACC), ACE2004, ACE2005, Wiki ( 89,0 , F1) | Tensorflow | Nur das Traindmodell wird hochgeladen | Hier |
| ┗ (sehr ähnlich wie die oben genannte) Gelenk mehrsprachige Überwachung für die bringliche Entitätsverbindung | EMNLP2018 | TH-Test, McN-Test, TAC2015 | Pytorch | Überprüfung | Hier |
| Neuronale kollektive Einheit (NCEL) | CL2018 | Conll-Yago, ACE2004, Aquaint, TAC2010 ( 91,0 , MIC-P), WW | Pytorch | Insekt | Hier |
| Verbesserung der Entitätsverbindung durch Modellierung latenter Beziehungen zwischen Erwähnungen | ACL2018 | Conll-Yago ( 93.07 , MIC-ACC), Aquaint, Ace2004, CWeb, Wiki (84,05, F1) | Pytorch | Bewertung durchgeführt | Hier |
| Elden | NAACL2018 | Conll-PPD (93,0, P-MIC), TAC2010 (89,6, MIC-P) | Lua, Fackel (Lua) | Insekt | Hier |
| Disambiguation der tiefen gemeinsamen Einheit mit lokaler neuronaler Aufmerksamkeit | EMNLP2017 | Conll-Yago (92.22, MIC-ACC), CWEB, WW, ACE2004, Aquaint, MSNBC | Lua, Fackel (Lua) | Zug Running (2019/01/15) | Hier |
| Hierarchische Verluste und neue Ressourcen für die typische und Verknüpfung von feinkörniger Entität | ACL2018 | Mediens, Typenet | Pytorch | Insekt | Hier |
| Gemeinsames Lernen der Einbettung von Wörtern und Entitäten für die namens Disambiguation (Yamada, Shindo) | Conll2016 | Conll-Yago (91,5, MIC-ACC), Conll-PPD (93,1, P-MIC), TAC2010 (85,5, MIC-ACC) | Pytorch/Tensorflow (Original), | Überprüfung | Basis -Original |
| Lernen verteilte Darstellungen von Texten und Entitäten aus der Wissensbasis (Yamada, Shindo) | ACL2017 | Conll-PPD ( 94,7 , P-MIC), TAC2010 (87,7, MIC-ACC) | Pytorch/Keras (Original) | Überprüfung | Fackel, Taschenlampe, original |
Hinweis: Hauptdatensätze zum Benchmarking Diese Aufgabe sind im Blink Repository aufgeführt.
MEWSLI-9-Datensatz
Biomedizinisch
Mediens ([Mohan und Li, AKBC '19])
Medmentions wurde als Benchmark -Datensatz für die genannte Entitätserkennung und Entität erstellt, die in der biomedizinischen Domäne verlinkt.
Da es viele Konzepte enthält, die zu breit sind, um praktisch zu nutzen, wurde ST21PV durch Filtern dieser breiten Konzepte von Meditionen konstruiert.
BC5CDR ([Li et al., '15'])
BC5CDR ist ein Datensatz, der für die Aufgabe der biokreativen V -Chemikalie und der Krankheitserkennungsbekannung erstellt wurde.
Es umfasst 1.500 Artikel, die 15.935 chemische und 12.852 Krankheiten enthalten.
Die Referenzwissenbasis ist ein Mesh, und fast alle Erwähnungen haben eine Goldentität in der Referenzwissenbasis.
Wikimed und PubMedds ([Shikhar et al., '20])
Wikimed umfasst über 650.000 Erwähnungen, die auf Konzepte in UMLS normalisiert wurden. (Zitiert)
Außerdem erstellten sie kommentierte Corpus PubMedds mit mehr als 5 Millionen normalisierten Erwähnungen. Beachten Sie, dass dieser Datensatz durch entfernte Überwachung erstellt wurde, was zu lauten Annotationen führt.
Null-Shot
Wikia -Datensätze ([Logeswaran et al., '19])
Aus Wikia Hyperlinks und seinen damit verbundenen Themen erstellten sie einen Datensatz zur Bewertung der Domänenverallgemeinerung der Entitätsverbindungsaufgabe.
Sie erstellten 16 Welten -Datensatz, die für Zug / Dev / Test auf 8/4/4 geteilt wurden und für einander völlig unabhängig waren.
Da [Gillick et al., Conll'19] vorgeschlagen wurde, nutzen einige Papiere auch Bert für sie. Die ursprüngliche Idee für das Abrufsystem von Biencoder-basiertem Abruf wird ebenfalls von [Gillick et al., '18] vorgeschlagen.
Der Poly-Coder kann auch auf eine Entitätsverbindung angewendet werden, wie Wu et al., 2020 gezeigt.
Transformator-basierter Encoder wird häufig zur Erwähnung und Entitätskodierung übernommen.
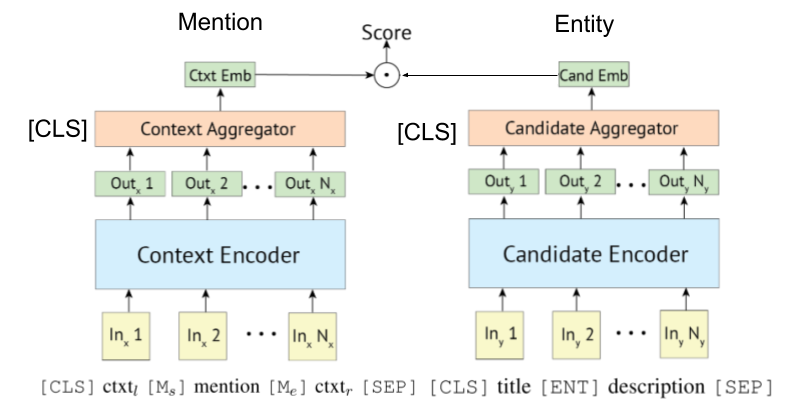
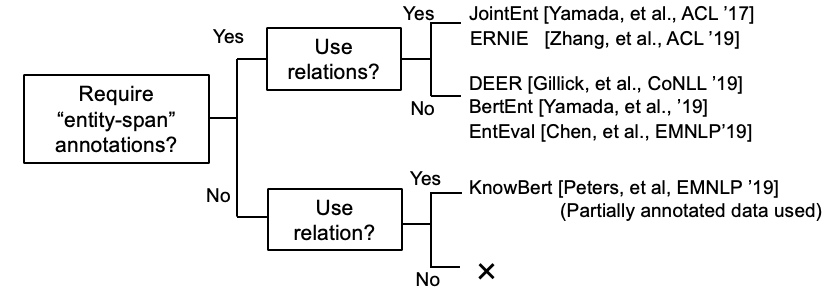
Einige Forschungen versuchen nun, KB -Informationen in Bert einzubeziehen.
Kepler: Ein einheitliches Modell für die Einbettung von Wissen und eine vorgebrachte Sprachdarstellung (Arbeit in Bearbeitung @ Nov. '19)
Integration von Graphen kontextualisiertem Wissen in vorgeborene Sprachmodelle (Arbeit in Fortschritt @ dec, '19)
K-Tbert: Ermöglicht die Sprachdarstellung mit Wissensgrafik
[Petroni et al., '19] überprüfte, ob Bert selbst sachlich kennt.
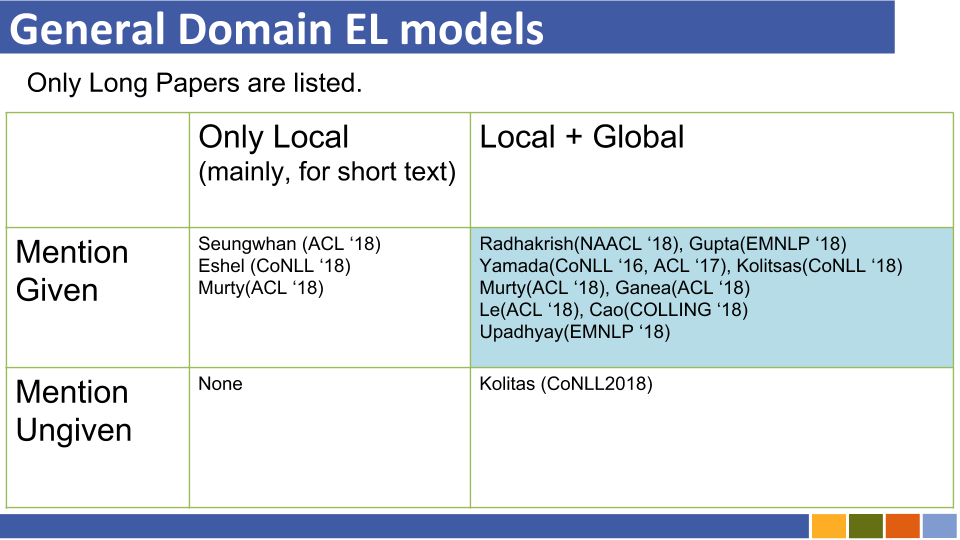
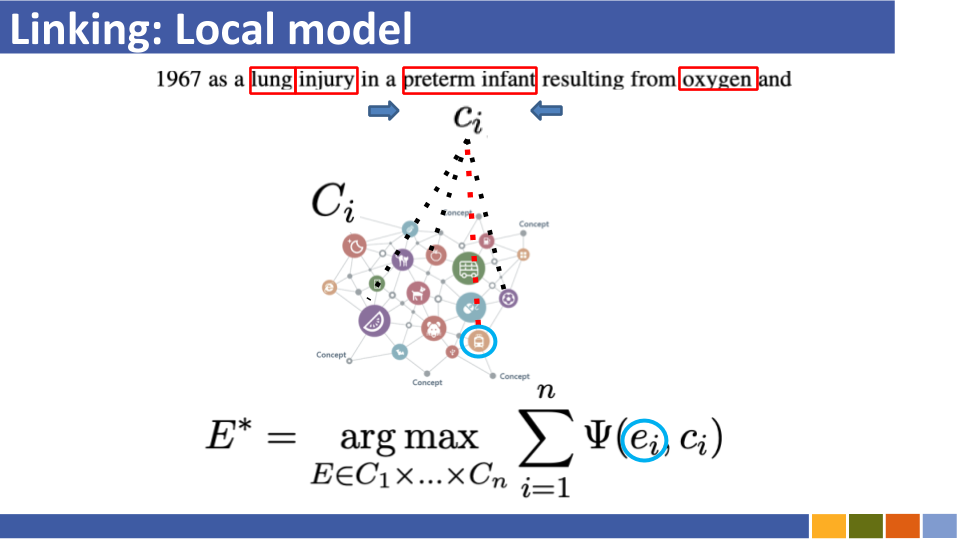
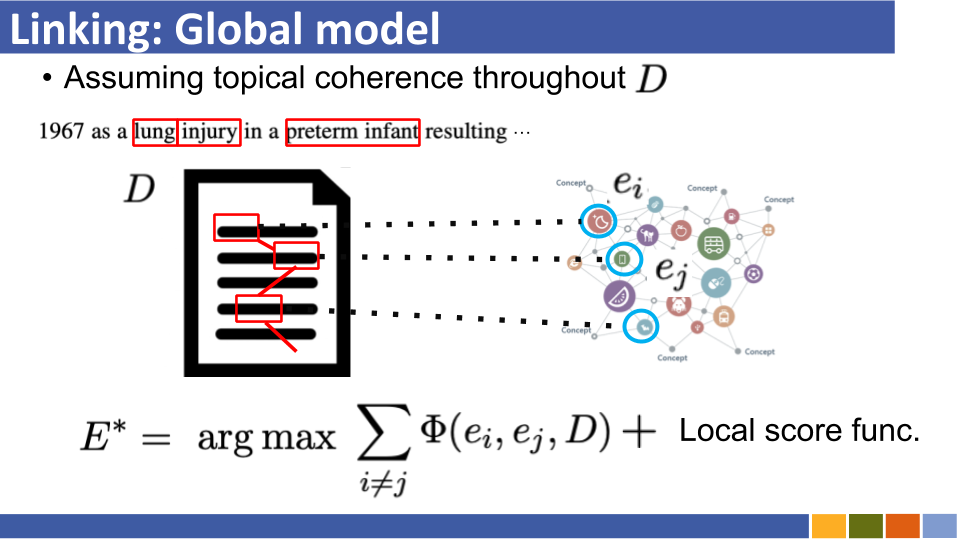
BI-CODER-Basis-Einheit, das Tutorial und deren Implementierung verbindet. [Link]
Umfassende Erhebungspapier der Entitätsverknüpfung ist erschienen.
(Kommentiert @ März 2020) Derzeit enthält dieses Repository Papiere für die Entitätsverbindung und die Entität LM. Ersteres erfordert eine codierende Entitätsdarstellung für die Disambiguierung, während letzteres bedeutet, dass ein Unternehmen während des Trainings ein Wissen in LM injiziert. Sie sind also völlig unterschiedlich, obwohl einige Arbeiten der Entität LM sein Modell mit einer Entitäts -Disambiguation bewerteten. Wir werden sie in naher Zukunft in diesem Repository trennen.
Kreuzsprachige El Papiere.
Zitiert von Gupta et al. (EMNLP '18)
Cross-Lingual Entity Linking (XEL) zielt darauf ab, eine in jeder Sprache an eine englische Wissensbasis (KB) wie Wikipedia geschriebene Einheit zu ergeben.
Gemeinsame mehrsprachige Überwachung für die bringliche Entitätsverbindung (EMNLP '18)
In Richtung Null-Ressource-Kreuzungs-Entitätsverbindung (Shuyan et al., EMNLP Workshop '19)
Entität, die nach lauten/kurzen Texten verlinkt
Aggregierte semantische Übereinstimmung für eine kurze Textentität (ACL'18) [Papier]
Effektive Verwendung des Kontextes in der lauten Entitätsverbindung (EMNLP'18) [Papier]
Multimodale Entitätsverbindung
Einige andere Papiere
Nur Listenentität Verknüpfungspapier
Gemeinsames Lernen der genannten Entitätserkennung und Entitätsverbindenpapier


