named_entity_recognition
1.0.0
本項目嘗試使用了多種不同的模型(包括HMM,CRF,Bi-LSTM,Bi-LSTM+CRF)來解決中文命名實體識別問題,數據集用的是論文ACL 2018Chinese NER using Lattice LSTM中收集的簡歷數據,數據的格式如下,它的每一行由一個字及其對應的標註組成,標註集採用BIOES,句子之間用一個空行隔開。
美 B-LOC
国 E-LOC
的 O
华 B-PER
莱 I-PER
士 E-PER
我 O
跟 O
他 O
谈 O
笑 O
风 O
生 O
該數據集就位於項目目錄下的ResumeNER文件夾裡。
下面是四種不同的模型以及這Ensemble這四個模型預測結果的準確率(取最好):
| HMM | CRF | BiLSTM | BiLSTM+CRF | Ensemble | |
|---|---|---|---|---|---|
| 召回率 | 91.22% | 95.43% | 95.32% | 95.72% | 95.65% |
| 準確率 | 91.49% | 95.43% | 95.37% | 95.74% | 95.69% |
| F1分數 | 91.30% | 95.42% | 95.32% | 95.70% | 95.64% |
最後一列Ensemble是將這四個模型的預測結果結合起來,使用“投票表決”的方法得出最後的預測結果。
(Ensemble的三個指標均不如BiLSTM+CRF,可以認為在Ensemble過程中,是其他三個模型拖累了BiLSTM+CRF)
具體的輸出可以查看output.txt文件。
首先安裝依賴項:
pip3 install -r requirement.txt
安裝完畢之後,直接使用
python3 main.py
即可訓練以及評估模型,評估模型將會打印出模型的精確率、召回率、F1分數值以及混淆矩陣,如果想要修改相關模型參數或者是訓練參數,可以在./models/config.py文件中進行設置。
訓練完畢之後,如果想要加載並評估模型,運行如下命令:
python3 test.py下面是這些模型的簡單介紹(github網頁對數學公式的支持不太好,涉及公式的部分無法正常顯示,我的博客有對這些模型以及代碼更加詳細的介紹):
隱馬爾可夫模型描述由一個隱藏的馬爾科夫鏈隨機生成不可觀測的狀態隨機序列,再由各個狀態生成一個觀測而產生觀測隨機序列的過程(李航統計學習方法)。隱馬爾可夫模型由初始狀態分佈,狀態轉移概率矩陣以及觀測概率矩陣所確定。
命名實體識別本質上可以看成是一種序列標註問題,在使用HMM解決命名實體識別這種序列標註問題的時候,我們所能觀測到的是字組成的序列(觀測序列),觀測不到的是每個字對應的標註(狀態序列)。
初始狀態分佈就是每一個標註的初始化概率,狀態轉移概率矩陣就是由某一個標註轉移到下一個標註的概率(就是若前一個詞的標註為$tag_i$ ,則下一個詞的標註為$tag_j$的概率為
某個標註下,生成某個詞的概率。
HMM模型的訓練過程對應隱馬爾可夫模型的學習問題(李航統計學習方法),
實際上就是根據訓練數據根據最大似然的方法估計模型的三個要素,即上文提到的初始狀態分佈、狀態轉移概率矩陣以及觀測概率矩陣,模型訓練完畢之後,利用模型進行解碼,即對給定觀測序列,求它對應的狀態序列,這裡就是對給定的句子,求句子中的每個字對應的標註,針對這個解碼問題,我們使用的是維特比(viterbi)算法。
具體的細節可以查看models/hmm.py文件。
HMM模型中存在兩個假設,一是輸出觀察值之間嚴格獨立,二是狀態轉移過程中當前狀態只與前一狀態有關。也就是說,在命名實體識別的場景下,HMM認為觀測到的句子中的每個字都是相互獨立的,而且當前時刻的標註只與前一時刻的標註相關。但實際上,命名實體識別往往需要更多的特徵,比如詞性,詞的上下文等等,同時當前時刻的標註應該與前一時刻以及後一時刻的標註都相關聯。由於這兩個假設的存在,顯然HMM模型在解決命名實體識別的問題上是存在缺陷的。
條件隨機場通過引入自定義的特徵函數,不僅可以表達觀測之間的依賴,還可表示當前觀測與前後多個狀態之間的複雜依賴,可以有效克服HMM模型面臨的問題。
為了建立一個條件隨機場,我們首先要定義一個特徵函數集,該函數集內的每個特徵函數都以標註序列作為輸入,提取的特徵作為輸出。假設該函數集為:
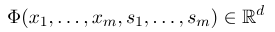
其中$x=(x_1, ..., x_m)$表示觀測序列,$s = (s_1, ...., s_m)$表示狀態序列。然後,條件隨機場使用對數線性模型來計算給定觀測序列下狀態序列的條件概率:
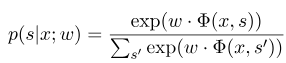
其中$s^{'}$是是所有可能的狀態序列,$w$是條件隨機場模型的參數,可以把它看成是每個特徵函數的權重。 CRF模型的訓練其實就是對參數$w$的估計。假設我們有$n$個已經標註好的數據${(x^i, s^i)}_{i=1}^n$,
則其對數似然函數的正則化形式如下:
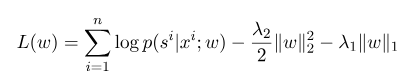
那麼,最優參數$w^*$就是:
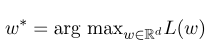
模型訓練結束之後,對給定的觀測序列$x$,它對應的最優狀態序列應該是:
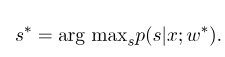
解碼的時候與HMM類似,也可以採用維特比算法。
具體的細節可以查看models/crf.py文件。
除了以上兩種基於概率圖模型的方法,LSTM也常常被用來解決序列標註問題。和HMM、CRF不同的是,LSTM是依靠神經網絡超強的非線性擬合能力,在訓練時將樣本通過高維空間中的複雜非線性變換,學習到從樣本到標註的函數,之後使用這個函數為指定的樣本預測每個token的標註。下方就是使用雙向LSTM(雙向能夠更好的捕捉序列之間的依賴關係)進行序列標註的示意圖:
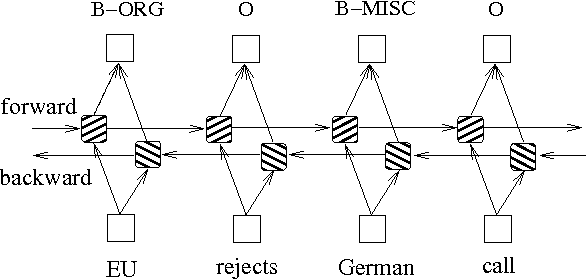
基於雙向LSTM的序列標註模型實現可以查看models/bilstm.py文件。
LSTM的優點是能夠通過雙向的設置學習到觀測序列(輸入的字)之間的依賴,在訓練過程中,LSTM能夠根據目標(比如識別實體)自動提取觀測序列的特徵,但是缺點是無法學習到狀態序列(輸出的標註)之間的關係,要知道,在命名實體識別任務中,標註之間是有一定的關係的,比如B類標註(表示某實體的開頭)後面不會再接一個B類標註,所以LSTM在解決NER這類序列標註任務時,雖然可以省去很繁雜的特徵工程,但是也存在無法學習到標註上下文的缺點。
相反,CRF的優點就是能對隱含狀態建模,學習狀態序列的特點,但它的缺點是需要手動提取序列特徵。所以一般的做法是,在LSTM後面再加一層CRF,以獲得兩者的優點。
具體的實現請查看models/bilstm_crf.py
HMM模型中要處理OOV(Out of vocabulary)的問題,就是測試集裡面有些字是不在訓練集裡面的, 這個時候通過觀測概率矩陣是無法查詢到OOV對應的各種狀態的概率的,處理這個問題可以將OOV對應的狀態的概率分佈設為均勻分佈。
HMM的三個參數(即狀態轉移概率矩陣、觀測概率矩陣以及初始狀態概率矩陣)在使用監督學習方法進行估計的過程中,如果有些項從未出現,那麼該項對應的位置就為0,而在使用維特比算法進行解碼的時候,計算過程需要將這些值相乘,那麼如果其中有為0的項,那麼整條路徑的概率也變成0了。此外,解碼過程中多個小概率相乘很可能出現下溢的情況,為了解決這兩個問題,我們給那些從未出現過的項賦予一個很小的數(如0.00000001),同時在進行解碼的時候將模型的三個參數都映射到對數空間,這樣既可以避免下溢,又可以簡化乘法運算。
CRF中將訓練數據以及測試數據作為模型的輸入之前,都需要先用特徵函數提取特徵!
Bi-LSTM+CRF模型可以參考:Neural Architectures for Named Entity Recognition,可以重點看一下里面的損失函數的定義。代碼裡面關於損失函數的計算採用的是類似動態規劃的方法,不是很好理解,這裡推薦看一下以下這些博客:


