named_entity_recognition
1.0.0
Ce projet tente de résoudre le problème de la reconnaissance des entités de dénomination chinoise en utilisant une variété de modèles différents (y compris HMM, CRF, Bi-LSTM, BI-LSTM + CRF). L'ensemble de données utilise les données de curriculum vitae collectées dans le Paper ACL 2018 Chinois NER à l'aide de Lattice LSTM. Le format des données est le suivant. Chaque ligne est composée d'un mot et de son annotation correspondante. L'ensemble d'annotation est BIOES et les phrases sont séparées par une ligne vide.
美 B-LOC
国 E-LOC
的 O
华 B-PER
莱 I-PER
士 E-PER
我 O
跟 O
他 O
谈 O
笑 O
风 O
生 O
Cet ensemble de données est situé dans le dossier ResumeNER dans le répertoire du projet.
Voici quatre modèles différents et la précision des résultats de prédiction de ces quatre modèles (en prenant le meilleur):
| HMM | CRF | Bilstm | Bilstm + CRF | Ensemble | |
|---|---|---|---|---|---|
| Taux de rappel | 91,22% | 95,43% | 95,32% | 95,72% | 95,65% |
| Précision | 91,49% | 95,43% | 95,37% | 95,74% | 95,69% |
| Score F1 | 91,30% | 95,42% | 95,32% | 95,70% | 95,64% |
La dernière colonne d'Ensemble combine les résultats de prédiction de ces quatre modèles et utilise la méthode de "vote" pour obtenir les résultats de prédiction finaux.
(Les trois indicateurs de l'ensemble ne sont pas aussi bons que BILSTM + CRF. On peut dire que dans le processus d'ensemble, ce sont les trois autres modèles qui ont traîné Bilstm + CRF)
Pour une sortie spécifique, vous pouvez afficher le fichier output.txt .
Installez d'abord les dépendances:
pip3 install -r requirement.txt
Après l'installation, utilisez-le directement
python3 main.py
Vous pouvez vous entraîner et évaluer le modèle. Le modèle d'évaluation imprimera la précision, le rappel, la valeur du score F1 du modèle et la matrice de confusion. Si vous souhaitez modifier les paramètres du modèle ou les paramètres de formation pertinents, vous pouvez le définir dans le fichier ./models/config.py .
Après la formation, si vous souhaitez charger et évaluer le modèle, exécutez la commande suivante:
python3 test.pyVoici une brève introduction à ces modèles (la page Web GitHub ne prend pas très bien en charge les formules mathématiques, et les pièces impliquées dans les formules ne peuvent pas être affichées normalement. Mon blog a une introduction plus détaillée à ces modèles et code):
Le modèle de Markov caché décrit le processus de génération de séquences aléatoires à l'état non observable au hasard d'une chaîne de Markov cachée, puis de générer une observation à partir de chaque état pour générer une séquence aléatoire d'observation (méthode d'apprentissage statistique li hang). Le modèle de Markov caché est déterminé par la distribution initiale de l'état, la matrice de probabilité de transition de l'état et la matrice de probabilité observée.
La reconnaissance de l'entité de dénomination peut essentiellement être considérée comme un problème d'étiquetage de séquence. Lorsque vous utilisez HMM pour résoudre le problème de marquage de séquence de la reconnaissance des entités nommés, ce que nous pouvons observer, c'est la séquence composée de mots (séquence d'observation), et ce que nous ne pouvons pas observer, c'est l'étiquette correspondant à chaque mot (séquence d'état).
La distribution initiale de l'état est la probabilité d'initialisation de chaque étiquette, et la matrice de probabilité de transition d'état est la probabilité de transférer d'une certaine étiquette vers l'étiquette suivante (c'est-à-dire que si l'étiquette du mot précédent est $ tag_i $, la probabilité de l'étiquette du mot suivant étant $ tag_j $ est
Sous une certaine marque, la probabilité de générer un certain mot.
Le processus de formation du modèle HMM correspond aux problèmes d'apprentissage du modèle de Markov caché (la méthode d'apprentissage statistique de Li),
En fait, il s'agit d'estimer les trois éléments du modèle en fonction des données de formation basées sur la méthode du maximum de vraisemblance, à savoir la distribution initiale de l'état, la matrice de probabilité de transition d'état et la matrice de probabilité d'observation mentionnée ci-dessus. Une fois le modèle formé, le modèle est utilisé pour le décodage, c'est-à-dire pour une séquence d'observation donnée, c'est de trouver sa séquence d'état correspondante. Voici pour trouver l'annotation correspondante pour chaque mot de la phrase pour une phrase donnée. Pour ce problème de décodage, nous utilisons l'algorithme Viterbi.
Pour plus de détails, veuillez consulter le fichier models/hmm.py
Il y a deux hypothèses dans le modèle HMM: l'une est que les valeurs d'observation de sortie sont strictement indépendantes, et l'autre est que l'état actuel n'est lié qu'à l'état précédent pendant la transition de l'état. C'est-à-dire que dans le scénario de la reconnaissance des entités de dénomination, Hmm estime que chaque mot de la phrase observée est indépendant les uns des autres, et l'étiquette du moment actuel n'est liée qu'à l'étiquette du moment précédent. Mais en fait, la reconnaissance de l'entité de dénomination nécessite souvent plus de fonctionnalités, comme une partie de la parole, du contexte des mots, etc. En même temps, l'étiquette du moment actuel doit être associée à l'étiquette du moment précédent et au moment suivant. En raison de l'existence de ces deux hypothèses, il est évident que le modèle HMM est imparfait pour résoudre le problème de la reconnaissance des entités nommée.
Les champs aléatoires conditionnels peuvent non seulement exprimer la dépendance entre les observations, mais également représenter la dépendance complexe entre l'observation actuelle et les états précédents et suivants, qui peuvent efficacement surmonter les problèmes rencontrés par le modèle HMM.
Afin d'établir un champ aléatoire conditionnel, nous devons d'abord définir un ensemble de fonctions de fonctionnalité, chaque fonction de fonctionnalité de l'ensemble prend la séquence d'annotation en entrée et les fonctionnalités extraites sous forme de sortie. Supposons que l'ensemble de fonctions est:
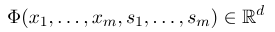
où $ x = (x_1, ..., x_m) $ représente la séquence d'observation, et $ s = (s_1, ......, s_m) $ représente la séquence d'état. Le champ aléatoire conditionnel utilise ensuite un modèle linéaire logarithmique pour calculer la probabilité conditionnelle de la séquence d'état sous une séquence d'observation donnée:
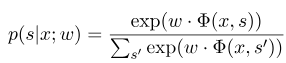
où $ s ^ {'} $ est la séquence de tous les états possibles, et $ w $ est le paramètre du modèle de champ aléatoire conditionnel, qui peut être considéré comme le poids de chaque fonction de fonctionnalité. La formation du modèle CRF est en fait l'estimation du paramètre $ w $. Supposons que nous ayons $ n $ de données marquées $ {(x ^ i, s ^ i)} _ {i = 1} ^ n $,
Ensuite, la forme de régularisation de sa fonction log-vraisemblance est la suivante:
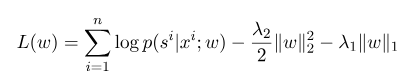
Ensuite, le paramètre optimal $ w ^ * $ est:
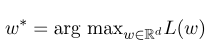
Une fois la formation modèle terminée, pour la séquence d'observation donnée $ x $, sa séquence d'état optimale correspondante devrait être:
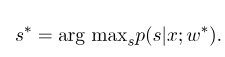
Il est similaire à HMM lors du décodage, et l'algorithme Viterbi peut également être utilisé.
Pour plus de détails, veuillez vérifier le fichier models/crf.py
En plus des deux méthodes ci-dessus basées sur des modèles de graphiques de probabilité, le LSTM est souvent utilisé pour résoudre le problème d'étiquetage des séquences. Contrairement à HMM et CRF, LSTM repose sur la forte capacité d'ajustement non linéaire des réseaux de neurones. Pendant l'entraînement, les échantillons sont appris par des transformations non linéaires complexes dans des espaces à haute dimension, puis utilisent cette fonction pour prédire l'annotation de chaque jeton pour l'échantillon spécifié. Vous trouverez ci-dessous un diagramme schématique de l'annotation des séquences à l'aide de LSTM bidirectionnelle (bidirectionnel peut mieux capturer les dépendances entre les séquences):
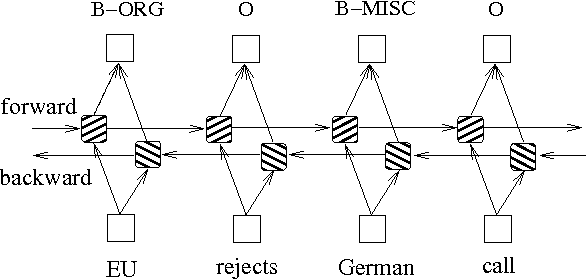
L'implémentation du modèle d'étiquetage de séquence basé sur le LSTM bidirectionnel peut afficher models/bilstm.py .
L'avantage de LSTM est qu'il peut apprendre la dépendance entre les séquences d'observation (mots d'entrée) via des paramètres bidirectionnels. Pendant le processus de formation, LSTM peut extraire automatiquement les caractéristiques de la séquence d'observation en fonction de la cible (comme les entités d'identification), mais l'inconvénient est qu'il ne peut pas apprendre la relation entre les séquences d'état (étiquettes de sortie). Vous devez savoir que dans la tâche de reconnaissance de l'entité de dénomination, il existe une certaine relation entre les étiquettes. Par exemple, une étiquette B (représentant le début d'une entité) ne sera pas suivie d'une autre étiquette B. Par conséquent, lorsque LSTM résout des tâches de marquage de séquence telles que NER, bien qu'elle puisse éliminer l'ingénierie des fonctionnalités complexes, il a également l'inconvénient de ne pas pouvoir apprendre le contexte d'étiquetage.
Au contraire, l'avantage du CRF est qu'il peut modéliser des états implicites et apprendre les caractéristiques des séquences d'État, mais son inconvénient est qu'il nécessite une extraction manuelle des caractéristiques de séquence. L'approche générale consiste donc à ajouter une autre couche de CRF derrière le LSTM pour obtenir les avantages des deux.
Pour une implémentation spécifique, veuillez consulter models/bilstm_crf.py
Le problème de l'OOV (hors du vocabulaire) doit être traité dans le modèle HMM, c'est-à-dire que certains mots dans l'ensemble de tests ne sont pas dans l'ensemble de formation. À l'heure actuelle, la probabilité de divers états correspondant à l'OOV ne peut être trouvée par la matrice de probabilité d'observation. Pour faire face à ce problème, la distribution de probabilité de l'état correspondant à l'OOV peut être définie sur une distribution uniforme.
Lorsque les trois paramètres de HMM (c'est-à-dire la matrice de probabilité de transition de l'état, la matrice de probabilité d'observation et la matrice de probabilité d'état initiale) sont utilisées pour l'estimation en utilisant la méthode d'apprentissage supervisée, si certains termes n'apparaissent jamais, alors la position correspondante du terme est de multiplier ces valeurs. Ensuite, s'il y a des termes avec 0, la probabilité de tout le chemin deviendra également 0. De plus, plusieurs multiplications de probabilité faibles pendant le processus de décodage sont susceptibles de provoquer un sous-flux. Afin de résoudre ces deux problèmes, nous attribuons un très petit nombre aux termes qui ne sont jamais apparus (comme 0,00000001). Dans le même temps, lors du décodage, nous cartographions les trois paramètres du modèle dans l'espace logarithmique, qui peut non seulement éviter le sous-flux, mais aussi simplifier l'opération de multiplication.
Avant d'utiliser les données de formation et les données de test comme entrée dans le modèle du CRF, vous devez utiliser les fonctions des fonctionnalités pour extraire les fonctionnalités!
Pour le modèle BI-LSTM + CRF, vous pouvez vous référer à: Architectures neuronales pour la reconnaissance des entités nommées, et vous pouvez vous concentrer sur la définition de la fonction de perte. Le calcul des fonctions de perte dans le code utilise une méthode similaire à la programmation dynamique, ce qui n'est pas facile à comprendre. Ici, nous vous recommandons de regarder les blogs suivants:


