named_entity_recognition
1.0.0
Proyek ini berupaya memecahkan masalah pengenalan entitas penamaan Cina menggunakan berbagai model yang berbeda (termasuk HMM, CRF, BI-LSTM, BI-LSTM+CRF). Kumpulan data menggunakan data resume yang dikumpulkan dalam kertas ACL 2018 China Ner menggunakan Lattice LSTM. Format data adalah sebagai berikut. Setiap baris terdiri dari sebuah kata dan anotasi yang sesuai. Set anotasi adalah bioes dan kalimat dipisahkan oleh garis kosong.
美 B-LOC
国 E-LOC
的 O
华 B-PER
莱 I-PER
士 E-PER
我 O
跟 O
他 O
谈 O
笑 O
风 O
生 O
Dataset ini terletak di folder ResumeNER di direktori proyek.
Berikut adalah empat model yang berbeda dan keakuratan hasil prediksi dari empat model ini (mengambil yang terbaik):
| HMM | CRF | Bilstm | BILSTM+CRF | Ansambel | |
|---|---|---|---|---|---|
| Tarif penarikan | 91,22% | 95,43% | 95,32% | 95,72% | 95,65% |
| Ketepatan | 91,49% | 95,43% | 95,37% | 95,74% | 95,69% |
| Skor F1 | 91,30% | 95,42% | 95,32% | 95,70% | 95,64% |
Kolom terakhir dari Ensemble menggabungkan hasil prediksi dari keempat model ini dan menggunakan metode "pemungutan suara" untuk mendapatkan hasil prediksi akhir.
(Tiga indikator Ensemble tidak sebagus BILSTM+CRF. Dapat dikatakan bahwa dalam proses ensembel, itu adalah tiga model lainnya yang menyeret BILSTM+CRF)
Untuk output tertentu, Anda dapat melihat file output.txt .
Pertama instal dependensi:
pip3 install -r requirement.txt
Setelah instalasi, gunakan secara langsung
python3 main.py
Anda dapat melatih dan mengevaluasi model. Model evaluasi akan mencetak akurasi model, penarikan, nilai skor F1 dan matriks kebingungan. Jika Anda ingin memodifikasi parameter model yang relevan atau parameter pelatihan, Anda dapat mengaturnya di file ./models/config.py .
Setelah pelatihan, jika Anda ingin memuat dan mengevaluasi model, jalankan perintah berikut:
python3 test.pyBerikut adalah pengantar singkat untuk model -model ini (halaman web GitHub tidak mendukung rumus matematika dengan sangat baik, dan bagian -bagian yang terlibat dalam rumus tidak dapat ditampilkan secara normal. Blog saya memiliki pengantar yang lebih rinci untuk model dan kode ini):
Model Markov tersembunyi menjelaskan proses menghasilkan urutan acak keadaan yang tidak dapat diamati secara acak dari rantai Markov tersembunyi, dan kemudian menghasilkan pengamatan dari masing -masing negara untuk menghasilkan urutan acak pengamatan (metode pembelajaran statistik Li hang). Model Markov tersembunyi ditentukan oleh distribusi keadaan awal, matriks probabilitas transisi keadaan, dan matriks probabilitas yang diamati.
Pengenalan entitas penamaan pada dasarnya dapat dianggap sebagai masalah pelabelan urutan. Saat menggunakan HMM untuk menyelesaikan masalah pelabelan urutan pengenalan entitas yang disebutkan, yang dapat kita amati adalah urutan yang terdiri dari kata -kata (urutan pengamatan), dan yang tidak dapat kita amati adalah label yang sesuai dengan setiap kata (urutan keadaan).
Distribusi keadaan awal adalah probabilitas inisialisasi dari masing -masing label, dan matriks probabilitas transisi keadaan adalah probabilitas transfer dari label tertentu ke label berikutnya (yaitu, jika label kata sebelumnya adalah $ tag_i $, probabilitas label dari kata berikutnya adalah $ tag_j $
Di bawah tanda tertentu, probabilitas menghasilkan kata tertentu.
Proses pelatihan model HMM sesuai dengan masalah pembelajaran model Markov yang tersembunyi (metode pembelajaran statistik Li Hang),
Faktanya, ini adalah untuk memperkirakan tiga elemen model berdasarkan data pelatihan berdasarkan metode kemungkinan maksimum, yaitu distribusi keadaan awal, matriks probabilitas transisi keadaan dan matriks probabilitas pengamatan yang disebutkan di atas. Setelah model dilatih, model digunakan untuk decoding, yaitu, untuk urutan pengamatan yang diberikan, ia menemukan urutan keadaan yang sesuai. Berikut ini untuk menemukan anotasi yang sesuai untuk setiap kata dalam kalimat untuk kalimat yang diberikan. Untuk masalah decoding ini, kami menggunakan algoritma Viterbi.
Untuk detail tertentu, silakan periksa file models/hmm.py .
Ada dua asumsi dalam model HMM: satu adalah bahwa nilai pengamatan output sangat independen, dan yang lainnya adalah bahwa keadaan saat ini hanya terkait dengan keadaan sebelumnya selama transisi negara. Dengan kata lain, dalam skenario pengakuan entitas penamaan, HMM percaya bahwa setiap kata dalam kalimat yang diamati tidak tergantung satu sama lain, dan label momen saat ini hanya terkait dengan label momen sebelumnya. Tetapi pada kenyataannya, pengenalan entitas penamaan seringkali membutuhkan lebih banyak fitur, seperti bagian dari bicara, konteks kata, dll. Pada saat yang sama, label momen saat ini harus dikaitkan dengan label momen sebelumnya dan momen berikutnya. Karena adanya dua asumsi ini, jelas bahwa model HMM cacat dalam memecahkan masalah pengakuan entitas yang disebutkan.
Bidang acak bersyarat tidak hanya dapat mengekspresikan ketergantungan antara pengamatan, tetapi juga mewakili ketergantungan kompleks antara pengamatan saat ini dan keadaan sebelumnya dan selanjutnya, yang secara efektif dapat mengatasi masalah yang dihadapi oleh model HMM.
Untuk menetapkan bidang acak bersyarat, pertama -tama kita perlu menentukan satu set fungsi fitur, setiap fungsi fitur dalam set mengambil urutan anotasi sebagai input dan fitur yang diekstraksi sebagai output. Asumsikan bahwa set fungsi adalah:
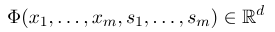
di mana $ x = (x_1, ..., x_m) $ mewakili urutan pengamatan, dan $ s = (s_1, ......, s_m) $ mewakili urutan keadaan. Bidang acak bersyarat kemudian menggunakan model linier logaritmik untuk menghitung probabilitas kondisional dari urutan keadaan di bawah urutan pengamatan yang diberikan:
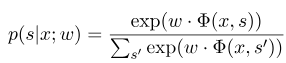
Di mana $ S^{'} $ adalah urutan dari semua status yang mungkin, dan $ W $ adalah parameter model bidang acak bersyarat, yang dapat dianggap sebagai bobot setiap fungsi fitur. Pelatihan model CRF sebenarnya adalah estimasi parameter $ W $. Misalkan kita memiliki $ n $ Data yang ditandai $ {(x^i, s^i)} _ {i = 1}^n $,
Kemudian bentuk regularisasi dari fungsi log-likelihood-nya adalah sebagai berikut:
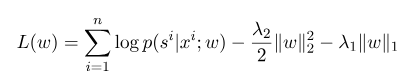
Kemudian, parameter optimal $ w^*$ adalah:
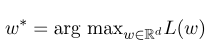
Setelah pelatihan model selesai, untuk urutan pengamatan yang diberikan $ x $, urutan keadaan optimal yang sesuai harus:
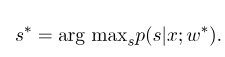
Ini mirip dengan HMM saat decoding, dan algoritma Viterbi juga dapat digunakan.
Untuk detail tertentu, silakan periksa file models/crf.py .
Selain dua metode di atas berdasarkan model grafik probabilitas, LSTM sering digunakan untuk menyelesaikan masalah pelabelan urutan. Tidak seperti HMM dan CRF, LSTM bergantung pada kemampuan pemasangan nonlinier yang kuat dari jaringan saraf. Selama pelatihan, sampel dipelajari melalui transformasi nonlinier yang kompleks dalam ruang dimensi tinggi, dan kemudian menggunakan fungsi ini untuk memprediksi anotasi masing-masing token untuk sampel yang ditentukan. Di bawah ini adalah diagram skematis dari anotasi urutan menggunakan LSTM dua arah (dua arah dapat lebih baik menangkap ketergantungan antara urutan):
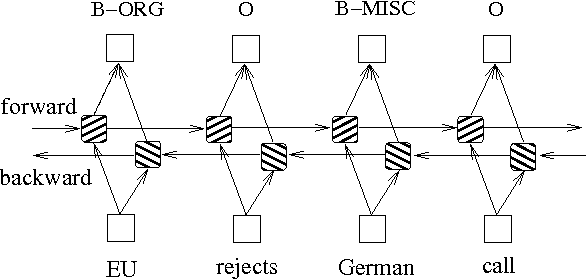
Implementasi model pelabelan urutan berdasarkan BIDIRECTIONAL LSTM dapat melihat file models/bilstm.py .
Keuntungan LSTM adalah bahwa ia dapat mempelajari ketergantungan antara urutan pengamatan (kata -kata input) melalui pengaturan dua arah. Selama proses pelatihan, LSTM dapat secara otomatis mengekstraksi karakteristik urutan pengamatan berdasarkan target (seperti mengidentifikasi entitas), tetapi kerugiannya adalah bahwa ia tidak dapat mempelajari hubungan antara urutan keadaan (label output). Anda harus tahu bahwa dalam tugas pengenalan entitas penamaan, ada hubungan tertentu antara label. Misalnya, label B (mewakili awal suatu entitas) tidak akan diikuti oleh label B lain. Oleh karena itu, ketika LSTM memecahkan tugas pelabelan urutan seperti NER, meskipun dapat menghilangkan rekayasa fitur yang rumit, ia juga memiliki kelemahan karena tidak dapat mempelajari konteks pelabelan.
Sebaliknya, keuntungan CRF adalah bahwa ia dapat memodelkan keadaan implisit dan mempelajari karakteristik urutan keadaan, tetapi kerugiannya adalah bahwa ia membutuhkan ekstraksi manual fitur urutan. Jadi pendekatan umum adalah menambahkan lapisan CRF lain di belakang LSTM untuk mendapatkan keuntungan dari keduanya.
Untuk implementasi tertentu, silakan lihat models/bilstm_crf.py
Masalah OOV (keluar dari kosakata) perlu ditangani dalam model HMM, yaitu, beberapa kata dalam set tes tidak ada dalam set pelatihan. Pada saat ini, probabilitas berbagai negara yang sesuai dengan OOV tidak dapat ditemukan melalui matriks probabilitas pengamatan. Untuk menangani masalah ini, distribusi probabilitas negara yang sesuai dengan OOV dapat diatur ke distribusi yang seragam.
Ketika tiga parameter HMM (mis., Matriks probabilitas transisi keadaan, matriks probabilitas pengamatan dan matriks probabilitas keadaan awal) digunakan untuk estimasi menggunakan metode pembelajaran yang diawasi, jika beberapa istilah tidak pernah muncul, maka posisi yang sesuai dari istilah ini adalah 0. Ketika decoding menggunakan viterbi algoritma, proses perhitungan yang diperlukan untuk mengalikan nilai -nilai ini. Kemudian jika ada istilah dengan 0, probabilitas seluruh jalur juga akan menjadi 0. Selain itu, beberapa multiplikasi probabilitas rendah selama proses decoding cenderung menyebabkan aliran bawah. Untuk menyelesaikan dua masalah ini, kami menetapkan jumlah yang sangat kecil untuk istilah -istilah yang tidak pernah muncul (seperti 0,00000001). Pada saat yang sama, ketika decoding, kami memetakan ketiga parameter model ke ruang logaritmik, yang tidak hanya dapat menghindari underflow, tetapi juga menyederhanakan operasi multiplikasi.
Sebelum menggunakan data pelatihan dan data uji sebagai input ke model dalam CRF, Anda perlu menggunakan fungsi fitur untuk mengekstrak fitur!
Untuk model BI-LSTM+CRF, Anda dapat merujuk pada: Arsitektur saraf untuk pengenalan entitas yang disebutkan, dan Anda dapat fokus pada definisi fungsi kerugian di dalamnya. Perhitungan fungsi kerugian dalam kode menggunakan metode yang mirip dengan pemrograman dinamis, yang tidak mudah dimengerti. Di sini kami sarankan melihat blog berikut:


