named_entity_recognition
1.0.0
Este projeto tenta resolver o problema do reconhecimento de entidade de nomeação chinesa usando uma variedade de modelos diferentes (incluindo HMM, CRF, BI-LSTM, BI-LSTM+CRF). O conjunto de dados usa os dados de currículo coletados no papel chinês ACL 2018 usando LSTM LSTM. O formato dos dados é o seguinte. Cada linha é composta por uma palavra e sua anotação correspondente. O conjunto de anotações é biológico e as frases são separadas por uma linha em branco.
美 B-LOC
国 E-LOC
的 O
华 B-PER
莱 I-PER
士 E-PER
我 O
跟 O
他 O
谈 O
笑 O
风 O
生 O
Este conjunto de dados está localizado na pasta ResumeNER no diretório do projeto.
Aqui estão quatro modelos diferentes e a precisão dos resultados da previsão desses quatro modelos (tomando o melhor):
| HUM | CRF | Bilstm | Bilstm+CRF | Conjunto | |
|---|---|---|---|---|---|
| Taxa de recall | 91,22% | 95,43% | 95,32% | 95,72% | 95,65% |
| Precisão | 91,49% | 95,43% | 95,37% | 95,74% | 95,69% |
| Pontuação F1 | 91,30% | 95,42% | 95,32% | 95,70% | 95,64% |
A última coluna do conjunto combina os resultados da previsão desses quatro modelos e usa o método de "votação" para obter os resultados finais da previsão.
(Os três indicadores do Ensemble não são tão bons quanto o bilstm+CRF. Pode -se dizer que, no processo do conjunto, foram os outros três modelos que arrastaram bilstm+CRF)
Para saída específica, você pode visualizar o arquivo output.txt .
Primeiro instale as dependências:
pip3 install -r requirement.txt
Após a instalação, use -o diretamente
python3 main.py
Você pode treinar e avaliar o modelo. O modelo de avaliação imprimirá a precisão, recall, valor da pontuação F1 e matriz de confusão da F1. Se você deseja modificar os parâmetros do modelo relevante ou os parâmetros de treinamento, poderá defini -lo no arquivo ./models/config.py .
Após o treinamento, se você deseja carregar e avaliar o modelo, execute o seguinte comando:
python3 test.pyAqui está uma breve introdução a esses modelos (a página da web do Github não suporta muito bem as fórmulas matemáticas, e as peças envolvidas nas fórmulas não podem ser exibidas normalmente. Meu blog tem uma introdução mais detalhada a esses modelos e código):
O modelo oculto de Markov descreve o processo de geração aleatória de sequências aleatórias de estado não observável a partir de uma cadeia oculta de Markov e, em seguida, gerando uma observação de cada estado para gerar uma sequência aleatória de observação (método de aprendizado estatístico de li). O modelo oculto de Markov é determinado pela distribuição inicial do estado, pela matriz de probabilidade de transição do estado e pela matriz de probabilidade observada.
O reconhecimento de entidade de nomeação pode ser essencialmente considerado como um problema de rotulagem de sequência. Ao usar o HMM para resolver o problema de marcação de sequência do reconhecimento de entidade nomeado, o que podemos observar é a sequência composta por palavras (sequência de observação) e o que não podemos observar é o rótulo correspondente a cada palavra (sequência de estado).
A distribuição inicial do estado é a probabilidade de inicialização de cada rótulo, e a matriz de probabilidade de transição do estado é a probabilidade de transferir de um determinado rótulo para o próximo rótulo (ou seja, se o rótulo da palavra anterior for $ tag_i $, a probabilidade do rótulo da próxima palavra sendo $ tag_j $ for
Sob uma certa marca, a probabilidade de gerar uma certa palavra.
O processo de treinamento do modelo HMM corresponde aos problemas de aprendizagem do modelo oculto de Markov (método de aprendizado estatístico de Li Hang),
De fato, é estimar os três elementos do modelo com base nos dados de treinamento com base no método de máxima verossimilhança, a saber, a distribuição inicial do estado, a matriz de probabilidade de transição de estado e a matriz de probabilidade de observação mencionada acima. Depois que o modelo é treinado, o modelo é usado para decodificar, ou seja, para uma determinada sequência de observação, é encontrar sua sequência de estado correspondente. Aqui está para encontrar a anotação correspondente para cada palavra na frase para uma determinada frase. Para esse problema de decodificação, usamos o algoritmo Viterbi.
Para detalhes específicos, verifique o arquivo models/hmm.py .
Existem duas suposições no modelo HMM: uma é que os valores de observação de saída são estritamente independentes e a outra é que o estado atual está relacionado apenas ao estado anterior durante a transição do estado. Ou seja, no cenário de nomear reconhecimento de entidades, o HMM acredita que cada palavra na frase observada é independente uma da outra, e o rótulo do momento atual está relacionado apenas ao rótulo do momento anterior. Mas, de fato, nomear o reconhecimento de entidade geralmente requer mais recursos, como parte da fala, contexto de palavras etc. ao mesmo tempo, o rótulo do momento atual deve estar associado ao rótulo do momento anterior e do próximo momento. Devido à existência dessas duas suposições, é óbvio que o modelo HMM é falho na solução do problema do reconhecimento de entidade nomeado.
Os campos aleatórios condicionais podem não apenas expressar a dependência entre as observações, mas também representam a dependência complexa entre a observação atual e os estados anteriores e subsequentes, que podem superar efetivamente os problemas enfrentados pelo modelo HMM.
Para estabelecer um campo aleatório condicional, primeiro precisamos definir um conjunto de funções de recurso, cada função de recurso no conjunto toma a sequência de anotação como entrada e os recursos extraídos como saída. Suponha que o conjunto de funções seja:
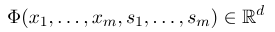
onde $ x = (x_1, ..., x_m) $ representa a sequência de observação e $ s = (s_1, ......, s_m) $ representa a sequência do estado. O campo aleatório condicional usa então um modelo linear logarítmico para calcular a probabilidade condicional da sequência de estado sob uma determinada sequência de observação:
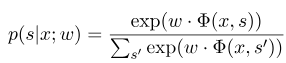
onde $ s^{'} $ é a sequência de todos os estados possíveis, e $ w $ é o parâmetro do modelo de campo aleatório condicional, que pode ser considerado como o peso de cada função de recurso. O treinamento do modelo CRF é na verdade a estimativa do parâmetro $ W $. Suponha que tenhamos $ n $ dados marcados $ {(x^i, s^i)} _ {i = 1}^n $,
Então a forma de regularização de sua função de probabilidade de log é a seguinte:
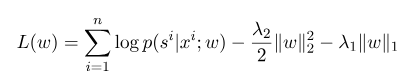
Então, o parâmetro ideal $ w^*$ é:
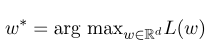
Após a conclusão do treinamento do modelo, para a sequência de observação fornecida $ x $, sua sequência ideal de estado correspondente deve ser:
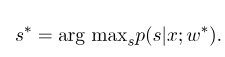
É semelhante ao HMM quando decodificação, e o algoritmo Viterbi também pode ser usado.
Para detalhes específicos, verifique o arquivo models/crf.py .
Além dos dois métodos acima baseados em modelos de gráficos de probabilidade, o LSTM é frequentemente usado para resolver o problema de marcação de sequência. Ao contrário do HMM e CRF, o LSTM depende da forte capacidade de ajuste não linear das redes neurais. Durante o treinamento, as amostras são aprendidas por meio de transformações não lineares complexas no espaço de alta dimensão e, em seguida, usam essa função para prever a anotação de cada token para a amostra especificada. Abaixo está um diagrama esquemático da anotação de sequência usando o LSTM bidirecional (bidirecional pode capturar melhor as dependências entre sequências):
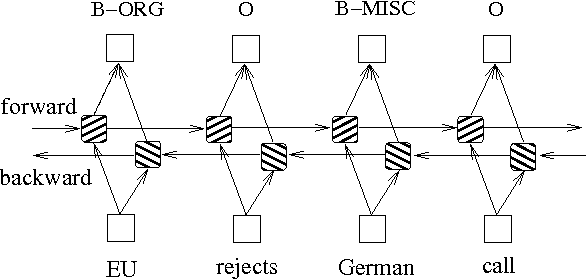
A implementação do modelo de marcação de sequência com base no LSTM bidirecional pode visualizar models/bilstm.py .
A vantagem do LSTM é que ele pode aprender a dependência entre sequências de observação (palavras de entrada) através de configurações bidirecionais. Durante o processo de treinamento, o LSTM pode extrair automaticamente as características da sequência de observação com base no alvo (como a identificação de entidades), mas a desvantagem é que ele não pode aprender a relação entre sequências de estado (rótulos de saída). Você deve saber que, na tarefa de reconhecimento de entidades de nomenclatura, há uma certa relação entre os rótulos. Por exemplo, um rótulo B (representando o início de uma entidade) não será seguido por outro rótulo B. Portanto, quando o LSTM resolve tarefas de rotulagem de sequência como o NER, embora possa eliminar a engenharia de recursos complicada, também tem a desvantagem de não ser capaz de aprender o contexto de rotulagem.
Pelo contrário, a vantagem do CRF é que ela pode modelar estados implícitos e aprender as características das seqüências de estado, mas sua desvantagem é que ela requer extração manual de recursos de sequência. Portanto, a abordagem geral é adicionar outra camada de CRF atrás do LSTM para obter as vantagens de ambos.
Para implementação específica, consulte models/bilstm_crf.py
O problema do Oov (fora do vocabulário) precisa ser tratado no modelo HMM, ou seja, algumas palavras no conjunto de testes não estão no conjunto de treinamento. Neste momento, a probabilidade de vários estados correspondentes a Oov não pode ser encontrada através da matriz de probabilidade de observação. Para lidar com esse problema, a distribuição de probabilidade do estado correspondente ao OOV pode ser definida como uma distribuição uniforme.
Quando os três parâmetros do HMM (isto é, a matriz de probabilidade de transição de estado, a matriz de probabilidade de observação e a matriz de probabilidade de estado inicial) são usadas para estimativa usando o método de aprendizado supervisionado, se alguns termos nunca aparecerem, a posição correspondente do termo é 0. Então, se houver termos com 0, a probabilidade de todo o caminho também se tornará 0. Além disso, é provável que múltiplas multiplicações de baixa probabilidade durante o processo de decodificação causem subfluxo. Para resolver esses dois problemas, atribuímos um número muito pequeno aos termos que nunca apareceram (como 0,00000001). Ao mesmo tempo, ao decodificar, mapeamos todos os três parâmetros do modelo para o espaço logarítmico, que pode não apenas evitar o fluxo, mas também simplificar a operação de multiplicação.
Antes de usar os dados de treinamento e os dados de teste como entrada para o modelo na CRF, você precisa usar funções de recursos para extrair recursos!
Para o modelo BI-LSTM+CRF, você pode consultar: arquiteturas neurais para reconhecimento de entidade nomeadas e pode se concentrar na definição da função de perda. O cálculo das funções de perda no código usa um método semelhante à programação dinâmica, o que não é fácil de entender. Aqui, recomendamos olhar para os seguintes blogs:


