named_entity_recognition
1.0.0
このプロジェクトは、さまざまな異なるモデル(HMM、CRF、BI-LSTM、BI-LSTM+CRFを含む)を使用して、中国の命名エンティティ認識の問題を解決しようとします。データセットは、格子LSTMを使用してPaper ACL 2018中国NERで収集された履歴書データを使用します。データの形式は次のとおりです。それの各行は、単語とそれに対応する注釈で構成されています。注釈セットはバイオエであり、文は空白線で区切られています。
美 B-LOC
国 E-LOC
的 O
华 B-PER
莱 I-PER
士 E-PER
我 O
跟 O
他 O
谈 O
笑 O
风 O
生 O
このデータセットは、プロジェクトディレクトリのResumeNERフォルダーにあります。
ここに4つの異なるモデルと、これら4つのモデルの予測結果の精度があります(最善を尽くします):
| ふーむ | CRF | bilstm | bilstm+crf | アンサンブル | |
|---|---|---|---|---|---|
| リコール率 | 91.22% | 95.43% | 95.32% | 95.72% | 95.65% |
| 正確さ | 91.49% | 95.43% | 95.37% | 95.74% | 95.69% |
| F1スコア | 91.30% | 95.42% | 95.32% | 95.70% | 95.64% |
アンサンブルの最後の列は、これらの4つのモデルの予測結果を組み合わせて、「投票」方法を使用して最終的な予測結果を取得します。
(アンサンブルの3つのインジケーターは、Bilstm+CRFほど良くありません。アンサンブルプロセスでは、Bilstm+CRFをドラッグしたのは他の3つのモデルだったと言えます)
特定の出力については、 output.txtファイルを表示できます。
最初に依存関係をインストールします。
pip3 install -r requirement.txt
インストール後、直接使用してください
python3 main.py
モデルをトレーニングおよび評価できます。評価モデルは、モデルの精度、Recall、F1スコア値、および混乱マトリックスを印刷します。関連するモデルパラメーターまたはトレーニングパラメーターを変更する場合は、 ./models/config.py config.pyファイルに設定できます。
トレーニング後、モデルをロードして評価する場合は、次のコマンドを実行します。
python3 test.pyこれらのモデルの簡単な紹介を次に示します(Github Webページは数学の公式をあまりサポートしておらず、式に関係する部分を正常に表示することはできません。私のブログにはこれらのモデルとコードのより詳細な紹介があります):
隠されたマルコフモデルは、隠されたマルコフ連鎖から観測不能な状態のランダムシーケンスをランダムに生成し、各状態から観察を生成して観測ランダムシーケンスを生成するプロセスを説明します(LIハング統計学習方法)。隠されたマルコフモデルは、初期状態分布、状態遷移確率マトリックス、および観測された確率マトリックスによって決定されます。
ネーミングエンティティの認識は、本質的にシーケンスラベル付けの問題と見なすことができます。 HMMを使用して名前付きエンティティ認識のシーケンスラベルの問題を解決する場合、観察できるのは単語(観測シーケンス)で構成されるシーケンスであり、観察できないのは各単語(状態シーケンス)に対応するラベルです。
初期状態分布は各ラベルの初期化確率であり、状態遷移確率マトリックスは特定のラベルから次のラベルに転送する確率です(つまり、前の単語のラベルが$ tag_i $の場合、次の単語のラベルの確率は$ tag_j $です
特定のマークの下で、特定の単語を生成する確率。
HMMモデルのトレーニングプロセスは、Hidden Markovモデルの学習問題に対応しています(Li Hangの統計学習方法)、
実際、最尤法、つまり初期状態分布、状態遷移確率マトリックス、および観測確率マトリックスに基づいて、トレーニングデータに基づいてモデルの3つの要素を推定することです。モデルがトレーニングされた後、モデルはデコードに使用されます。つまり、特定の観察シーケンスでは、対応する状態シーケンスを見つけることです。特定の文の文の各単語の対応する注釈を見つけることです。このデコードの問題では、ViterBiアルゴリズムを使用します。
特定の詳細については、 models/hmm.pyファイルを確認してください。
HMMモデルには2つの仮定があります。1つは、出力観測値が厳密に独立していることであり、もう1つは現在の状態が州の移行中の以前の状態にのみ関連していることです。つまり、エンティティ認識の命名のシナリオでは、HMMは、観察された文の各単語は互いに独立しており、現在の瞬間のラベルは前の瞬間のラベルにのみ関連していると考えています。しかし、実際には、エンティティの認識を命名するには、スピーチ、単語の文脈などの一部など、より多くの機能が必要になることがよくあります。同時に、現在の瞬間のラベルは、前の瞬間と次の瞬間のラベルに関連付けられる必要があります。これら2つの仮定が存在するため、HMMモデルが名前付きエンティティ認識の問題を解決することに欠陥があることは明らかです。
条件付きランダムフィールドは、観測間の依存性を表現するだけでなく、現在の観測と以前およびその後の状態との間の複雑な依存性を表し、HMMモデルが直面する問題を効果的に克服できます。
条件付きランダムフィールドを確立するには、まず機能関数のセットを定義する必要があります。セットの各機能関数は、アノテーションシーケンスを入力として、抽出された特徴を出力として使用する必要があります。関数セットは次のとおりです。
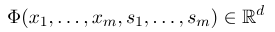
ここで、$ x =(x_1、...、x_m)$は観測シーケンスを表し、$ s =(s_1、......、s_m)$は状態シーケンスを表します。条件付きランダムフィールドは、対数線形モデルを使用して、特定の観測シーケンスの下で状態シーケンスの条件付き確率を計算します。
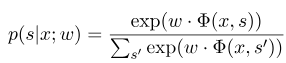
ここで、$ s^{'} $はすべての可能な状態のシーケンスであり、$ w $は条件付きランダムフィールドモデルのパラメーターであり、各機能関数の重みと見なすことができます。 CRFモデルのトレーニングは、実際にはパラメーター$ w $の推定です。 $ n $マークデータ$ {(x^i、s^i)} _ {i = 1}^n $、
次に、その対数尤度関数の正規化形式は次のとおりです。
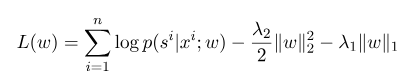
次に、最適なパラメーター$ w^*$は次のとおりです。
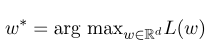
モデルトレーニングが完了した後、指定された観察シーケンス$ x $の場合、対応する最適な状態シーケンスは次のとおりです。
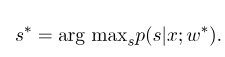
デコード時のうーんに似ており、ViterBiアルゴリズムも使用できます。
特定の詳細については、 models/crf.pyファイルを確認してください。
確率グラフモデルに基づいた上記の2つの方法に加えて、LSTMはシーケンスラベルの問題を解決するためによく使用されます。 HMMやCRFとは異なり、LSTMはニューラルネットワークの強力な非線形フィッティング能力に依存しています。トレーニング中、サンプルは高次元空間での複雑な非線形変換を通じて学習され、この関数を使用して、指定されたサンプルの各トークンの注釈を予測します。以下は、双方向LSTMを使用したシーケンス注釈の概略図です(双方向は、シーケンス間の依存関係をよりよくキャプチャできます):
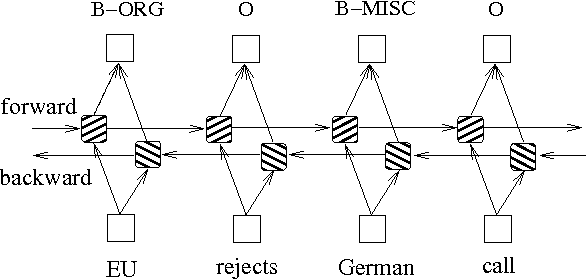
双方向LSTMに基づくシーケンスラベル付けモデルの実装は、 models/bilstm.pyファイルを表示できます。
LSTMの利点は、双方向設定を介して観測シーケンス(入力単語)間の依存性を学習できることです。トレーニングプロセス中、LSTMはターゲット(エンティティの識別など)に基づいて観測シーケンスの特性を自動的に抽出できますが、不利な点は、状態シーケンス間の関係(出力ラベル)間の関係を学習できないことです。ネーミングエンティティ認識タスクでは、ラベル間に特定の関係があることを知っておく必要があります。たとえば、Bラベル(エンティティの開始を表す)には、別のBラベルが続きません。したがって、LSTMがNERなどのシーケンスラベルのタスクを解決すると、複雑な機能エンジニアリングを排除できますが、ラベル付けのコンテキストを学習できないという不利な点もあります。
それどころか、CRFの利点は、暗黙の状態をモデル化し、状態シーケンスの特性を学習できることですが、その欠点は、シーケンス機能の手動抽出が必要であることです。したがって、一般的なアプローチは、LSTMの背後にあるCRFの別の層を追加して、両方の利点を得ることです。
特定の実装については、 models/bilstm_crf.pyを参照してください
OOV(語彙から)の問題は、HMMモデルで処理する必要があります。つまり、テストセットのいくつかの単語はトレーニングセットにはありません。現時点では、OOVに対応するさまざまな状態の確率は、観測確率マトリックスを介して見つけることができません。この問題に対処するために、OOVに対応する状態の確率分布は、均一な分布に設定できます。
HMMの3つのパラメーター(つまり、状態遷移確率マトリックス、観測確率マトリックス、および初期状態確率マトリックス)が監視された学習方法を使用した推定に使用される場合、項の対応する位置は0です。次に、0に項がある場合、パス全体の確率も0になります。さらに、デコードプロセス中の複数の低確率乗算は、アンダーフローを引き起こす可能性があります。これらの2つの問題を解決するために、現れたことのない用語(0.00000001など)に非常に少ない数を割り当てます。同時に、デコードするときに、モデルの3つのパラメーターすべてを対数空間にマッピングします。これにより、アンダーフローを避けるだけでなく、乗算操作も簡素化できます。
トレーニングデータとテストデータをCRFのモデルへの入力として使用する前に、機能関数を使用して機能を抽出する必要があります。
Bi-LSTM+CRFモデルについては、次のように参照できます。名前付きエンティティ認識のニューラルアーキテクチャ、およびITの損失関数の定義に焦点を当てることができます。コード内の損失関数の計算では、動的プログラミングと同様のメソッドを使用しますが、これは簡単に理解できません。ここでは、次のブログを見ることをお勧めします。


