named_entity_recognition
1.0.0
โครงการนี้พยายามที่จะแก้ปัญหาการจดจำเอนทิตีการตั้งชื่อจีนโดยใช้โมเดลที่หลากหลาย (รวมถึง HMM, CRF, BI-LSTM, BI-LSTM+CRF) ชุดข้อมูลใช้ข้อมูลเรซูเม่ที่รวบรวมไว้ในกระดาษ ACL 2018 ภาษาจีนโดยใช้ Lattice LSTM รูปแบบของข้อมูลมีดังนี้ แต่ละบรรทัดของมันประกอบด้วยคำและคำอธิบายประกอบที่สอดคล้องกัน ชุดคำอธิบายประกอบคือชีวภาพและประโยคจะถูกคั่นด้วยเส้นเปล่า
美 B-LOC
国 E-LOC
的 O
华 B-PER
莱 I-PER
士 E-PER
我 O
跟 O
他 O
谈 O
笑 O
风 O
生 O
ชุดข้อมูลนี้ตั้งอยู่ในโฟลเดอร์ ResumeNER ในไดเรกทอรีโครงการ
นี่คือสี่รุ่นที่แตกต่างกันและความถูกต้องของผลการทำนายของทั้งสี่รุ่น (ใช้สิ่งที่ดีที่สุด):
| อืม | CRF | bilstm | bilstm+crf | วงดนตรี | |
|---|---|---|---|---|---|
| อัตราการเรียกคืน | 91.22% | 95.43% | 95.32% | 95.72% | 95.65% |
| ความแม่นยำ | 91.49% | 95.43% | 95.37% | 95.74% | 95.69% |
| คะแนน F1 | 91.30% | 95.42% | 95.32% | 95.70% | 95.64% |
คอลัมน์สุดท้ายของวงดนตรีรวมผลการทำนายของทั้งสี่รุ่นนี้และใช้วิธีการ "ลงคะแนน" เพื่อให้ได้ผลลัพธ์การทำนายขั้นสุดท้าย
(ตัวชี้วัดทั้งสามของ Ensemble ไม่ดีเท่า Bilstm+CRF อาจกล่าวได้ว่าในกระบวนการทั้งมวลมันเป็นอีกสามรุ่นที่ลาก Bilstm+CRF)
สำหรับเอาต์พุตเฉพาะคุณสามารถดูไฟล์ output.txt
ก่อนอื่นติดตั้งการพึ่งพา:
pip3 install -r requirement.txt
หลังจากการติดตั้งใช้โดยตรง
python3 main.py
คุณสามารถฝึกอบรมและประเมินแบบจำลอง รูปแบบการประเมินผลจะพิมพ์ความแม่นยำของโมเดลการเรียกคืนค่าคะแนน F1 และเมทริกซ์ความสับสน หากคุณต้องการแก้ไขพารามิเตอร์โมเดลที่เกี่ยวข้องหรือพารามิเตอร์การฝึกอบรมคุณสามารถตั้งค่าได้ในไฟล์ ./models/config.py
หลังจากการฝึกอบรมหากคุณต้องการโหลดและประเมินโมเดลให้เรียกใช้คำสั่งต่อไปนี้:
python3 test.pyนี่คือการแนะนำสั้น ๆ เกี่ยวกับโมเดลเหล่านี้ (หน้าเว็บ GitHub ไม่สนับสนุนสูตรทางคณิตศาสตร์เป็นอย่างดีและชิ้นส่วนที่เกี่ยวข้องในสูตรไม่สามารถแสดงได้ตามปกติบล็อกของฉันมีรายละเอียดเพิ่มเติมเกี่ยวกับโมเดลและรหัสเหล่านี้):
โมเดล Markov ที่ซ่อนอยู่จะอธิบายกระบวนการของการสร้างลำดับสุ่มสถานะที่ไม่สามารถสังเกตได้จากห่วงโซ่ Markov ที่ซ่อนอยู่จากนั้นสร้างการสังเกตจากแต่ละรัฐเพื่อสร้างลำดับการสุ่มสังเกต (วิธีการเรียนรู้ทางสถิติของ Li Hang) โมเดล Markov ที่ซ่อนอยู่นั้นถูกกำหนดโดยการกระจายสถานะเริ่มต้นเมทริกซ์ความน่าจะเป็นของการเปลี่ยนสถานะและเมทริกซ์ความน่าจะเป็นที่สังเกตได้
การจดจำเอนทิตีการตั้งชื่อนั้นถือได้ว่าเป็นปัญหาการติดฉลากลำดับ เมื่อใช้ HMM เพื่อแก้ปัญหาการติดฉลากลำดับของการจดจำเอนทิตีที่มีชื่อสิ่งที่เราสามารถสังเกตได้คือลำดับที่ประกอบด้วยคำ (ลำดับการสังเกต) และสิ่งที่เราไม่สามารถสังเกตได้คือฉลากที่สอดคล้องกับแต่ละคำ (ลำดับสถานะ)
การแจกแจงสถานะเริ่มต้น คือความน่าจะเป็นแบบเริ่มต้นของแต่ละฉลาก และเมทริกซ์ความน่าจะเป็นของการเปลี่ยนสถานะ คือความน่าจะเป็นของการถ่ายโอนจากฉลากที่แน่นอนไปยังป้ายกำกับถัดไป (นั่นคือถ้าฉลากของคำก่อนหน้าคือ $ tag_i $ ความน่าจะเป็นของฉลากของคำถัดไปคือ $ tag_j $ คือคือ
ภายใต้เครื่องหมายที่แน่นอนความน่าจะเป็นของการสร้างคำที่แน่นอน
กระบวนการฝึกอบรมของโมเดล HMM สอดคล้องกับปัญหาการเรียนรู้ของโมเดล Markov ที่ซ่อนอยู่ (วิธีการเรียนรู้ทางสถิติของ Li Hang)
ในความเป็นจริงมันคือการประเมินองค์ประกอบทั้งสามของโมเดลตามข้อมูลการฝึกอบรมตามวิธีความน่าจะเป็นสูงสุดคือการกระจายสถานะเริ่มต้นเมทริกซ์ความน่าจะเป็นของการเปลี่ยนสถานะและเมทริกซ์ความน่าจะเป็นของการสังเกตที่กล่าวถึงข้างต้น หลังจากได้รับการฝึกอบรมแบบจำลองแล้วโมเดลจะใช้สำหรับการถอดรหัสนั่นคือสำหรับลำดับการสังเกตที่กำหนดมันคือการค้นหาลำดับสถานะที่สอดคล้องกัน นี่คือการค้นหาคำอธิบายประกอบที่สอดคล้องกันสำหรับแต่ละคำในประโยคสำหรับประโยคที่กำหนด สำหรับปัญหาการถอดรหัสนี้เราใช้อัลกอริทึม Viterbi
สำหรับรายละเอียดเฉพาะโปรดตรวจสอบไฟล์ models/hmm.py
มีสมมติฐานสองข้อในโมเดล HMM: หนึ่งคือค่าการสังเกตเอาท์พุทนั้นมีความเป็นอิสระอย่างเคร่งครัดและอีกอย่างคือสถานะปัจจุบันเกี่ยวข้องกับสถานะก่อนหน้าในระหว่างการเปลี่ยนแปลงของรัฐเท่านั้น กล่าวคือในสถานการณ์ของการจดจำเอนทิตีการตั้งชื่อ HMM เชื่อว่าแต่ละคำในประโยคที่สังเกตนั้นเป็นอิสระจากกันและฉลากของช่วงเวลาปัจจุบันนั้นเกี่ยวข้องกับฉลากของช่วงเวลาก่อนหน้าเท่านั้น แต่ในความเป็นจริงการจดจำเอนทิตีการตั้งชื่อมักจะต้องใช้คุณสมบัติมากขึ้นเช่นส่วนหนึ่งของคำพูดบริบทของคำ ฯลฯ ในเวลาเดียวกันฉลากของช่วงเวลาปัจจุบันควรเชื่อมโยงกับฉลากของช่วงเวลาก่อนหน้าและช่วงเวลาต่อไป เนื่องจากการมีอยู่ของสมมติฐานทั้งสองนี้เป็นที่ชัดเจนว่าโมเดล HMM มีข้อบกพร่องในการแก้ปัญหาการจดจำเอนทิตีที่มีชื่อ
เขตข้อมูลแบบสุ่มแบบมีเงื่อนไขไม่เพียง แต่สามารถแสดงการพึ่งพาระหว่างการสังเกตได้ แต่ยังแสดงถึงการพึ่งพาที่ซับซ้อนระหว่างการสังเกตในปัจจุบันและสถานะก่อนหน้าและต่อมาซึ่งสามารถเอาชนะปัญหาที่เผชิญกับแบบจำลอง HMM ได้อย่างมีประสิทธิภาพ
ในการสร้างฟิลด์แบบสุ่มแบบมีเงื่อนไขก่อนอื่นเราต้องกำหนดชุดของฟังก์ชั่นคุณลักษณะแต่ละฟังก์ชั่นคุณสมบัติในชุดจะต้องใช้ลำดับความหมายรวมเป็นอินพุตและคุณสมบัติที่แยกออกมาเป็นเอาต์พุต สมมติว่าชุดฟังก์ชันคือ:
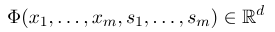
โดยที่ $ x = (x_1, ... , x_m) $ หมายถึงลำดับการสังเกตและ $ s = (s_1, ...... , s_m) $ หมายถึงลำดับสถานะ จากนั้นฟิลด์แบบสุ่มแบบมีเงื่อนไขจะใช้แบบจำลองเชิงเส้นลอการิทึมเพื่อคำนวณความน่าจะเป็นตามเงื่อนไขของลำดับสถานะภายใต้ลำดับการสังเกตที่กำหนด:
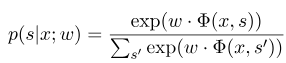
โดยที่ $ s^{'} $ เป็นลำดับของสถานะที่เป็นไปได้ทั้งหมดและ $ w $ เป็นพารามิเตอร์ของแบบจำลองฟิลด์แบบสุ่มแบบมีเงื่อนไขซึ่งถือได้ว่าเป็นน้ำหนักของฟังก์ชันคุณลักษณะแต่ละอย่าง การฝึกอบรมของโมเดล CRF นั้นเป็นการประมาณค่าพารามิเตอร์ $ W $ สมมติว่าเรามี $ n $ data ที่ทำเครื่องหมาย $ {(x^i, s^i)} _ {i = 1}^n $,
จากนั้นรูปแบบการทำให้เป็นมาตรฐานของฟังก์ชั่นความน่าจะเป็นบันทึกของมันมีดังนี้:
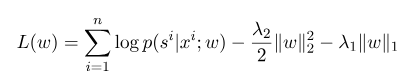
จากนั้นพารามิเตอร์ที่ดีที่สุด $ w^*$ คือ:
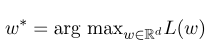
หลังจากการฝึกอบรมแบบจำลองเสร็จสมบูรณ์สำหรับลำดับการสังเกตที่กำหนด $ x $ ลำดับสถานะที่ดีที่สุดที่สอดคล้องกันควรเป็น:
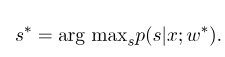
มันคล้ายกับ HMM เมื่อถอดรหัสและสามารถใช้อัลกอริทึม Viterbi ได้
สำหรับรายละเอียดเฉพาะโปรดตรวจสอบไฟล์ models/crf.py
นอกเหนือจากสองวิธีข้างต้นตามแบบจำลองกราฟความน่าจะเป็นแล้ว LSTM มักจะใช้ในการแก้ปัญหาการติดฉลากลำดับ ซึ่งแตกต่างจาก HMM และ CRF, LSTM ขึ้นอยู่กับความสามารถในการติดตั้งแบบไม่เชิงเส้นที่แข็งแกร่งของเครือข่ายประสาท ในระหว่างการฝึกอบรมตัวอย่างจะได้รับการเรียนรู้ผ่านการแปลงแบบไม่เชิงเส้นที่ซับซ้อนในพื้นที่มิติสูงจากนั้นใช้ฟังก์ชั่นนี้เพื่อทำนายคำอธิบายประกอบของโทเค็นแต่ละตัวสำหรับตัวอย่างที่ระบุ ด้านล่างนี้เป็นแผนผังแผนผังของคำอธิบายประกอบลำดับโดยใช้ LSTM แบบสองทิศทาง (สองทิศทางสามารถจับการพึ่งพาระหว่างลำดับได้ดีขึ้น):
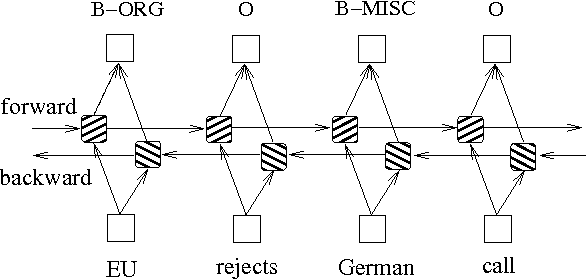
การใช้งานรูปแบบการติดฉลากลำดับตาม LSTM แบบสองทิศทางสามารถดูไฟล์ models/bilstm.py
ข้อได้เปรียบของ LSTM คือมันสามารถเรียนรู้การพึ่งพาระหว่างลำดับการสังเกต (คำพูด) ผ่านการตั้งค่าแบบสองทิศทาง ในระหว่างกระบวนการฝึกอบรม LSTM สามารถแยกลักษณะของลำดับการสังเกตได้โดยอัตโนมัติตามเป้าหมาย (เช่นการระบุเอนทิตี) แต่ข้อเสียคือมันไม่สามารถเรียนรู้ความสัมพันธ์ระหว่างลำดับสถานะ (ฉลากเอาต์พุต) คุณควรรู้ว่าในงานการจดจำเอนทิตีการตั้งชื่อมีความสัมพันธ์บางอย่างระหว่างฉลาก ตัวอย่างเช่นฉลาก B (แสดงถึงจุดเริ่มต้นของเอนทิตี) จะไม่ถูกติดตามด้วยฉลาก B อื่น ดังนั้นเมื่อ LSTM แก้ปัญหาการติดฉลากลำดับเช่น NER แม้ว่ามันจะสามารถกำจัดวิศวกรรมคุณลักษณะที่ซับซ้อนได้ แต่ก็มีข้อเสียที่จะไม่สามารถเรียนรู้บริบทการติดฉลากได้
ในทางตรงกันข้ามข้อได้เปรียบของ CRF คือมันสามารถสร้างแบบจำลองสถานะโดยนัยและเรียนรู้ลักษณะของลำดับสถานะ แต่ข้อเสียของมันคือมันต้องมีการสกัดด้วยตนเองของคุณสมบัติลำดับ ดังนั้นวิธีการทั่วไปคือการเพิ่มเลเยอร์อีกชั้นของ CRF ที่อยู่ด้านหลัง LSTM เพื่อให้ได้ข้อได้เปรียบของทั้งคู่
สำหรับการใช้งานเฉพาะโปรดดู models/bilstm_crf.py
ปัญหาของ OOV (ออกจากคำศัพท์) จำเป็นต้องได้รับการจัดการในโมเดล HMM นั่นคือคำบางคำในชุดทดสอบไม่ได้อยู่ในชุดการฝึกอบรม ในเวลานี้ความน่าจะเป็นของรัฐต่าง ๆ ที่สอดคล้องกับ OOV ไม่สามารถพบได้ผ่านเมทริกซ์ความน่าจะเป็นของการสังเกต ในการจัดการกับปัญหานี้การกระจายความน่าจะเป็นของสถานะที่สอดคล้องกับ OOV สามารถตั้งค่าเป็นการแจกแจงแบบสม่ำเสมอ
เมื่อพารามิเตอร์สามพารามิเตอร์ของ HMM (เช่นเมทริกซ์ความน่าจะเป็นของการเปลี่ยนสถานะเมทริกซ์ความน่าจะเป็นของการสังเกตและเมทริกซ์ความน่าจะเป็นสถานะเริ่มต้น) จะใช้สำหรับการประมาณค่าโดยใช้วิธีการเรียนรู้ภายใต้การดูแลหากคำบางคำไม่ปรากฏขึ้น จากนั้นหากมีคำศัพท์ที่มี 0 ความน่าจะเป็นของเส้นทางทั้งหมดจะกลายเป็น 0 นอกจากนี้การคูณความน่าจะเป็นต่ำหลายครั้งในระหว่างกระบวนการถอดรหัสมีแนวโน้มที่จะทำให้เกิดการไหลออกมา เพื่อแก้ปัญหาทั้งสองนี้เรากำหนดจำนวนน้อยมากให้กับข้อกำหนดเหล่านั้นที่ไม่เคยปรากฏ (เช่น 0.00000001) ในเวลาเดียวกันเมื่อถอดรหัสเราแมปพารามิเตอร์ทั้งสามของโมเดลไปยังพื้นที่ลอการิทึมซึ่งไม่เพียง แต่หลีกเลี่ยงใต้การไหล แต่ยังช่วยลดความซับซ้อนของการคูณการคูณ
ก่อนที่จะใช้ข้อมูลการฝึกอบรมและการทดสอบข้อมูลเป็นอินพุตไปยังโมเดลใน CRF คุณต้องใช้ฟังก์ชั่นคุณสมบัติเพื่อแยกคุณสมบัติ!
สำหรับโมเดล BI-LSTM+CRF คุณสามารถอ้างถึง: สถาปัตยกรรมระบบประสาทสำหรับการจดจำเอนทิตีที่มีชื่อและคุณสามารถมุ่งเน้นไปที่คำจำกัดความของฟังก์ชั่นการสูญเสียในนั้น การคำนวณฟังก์ชั่นการสูญเสียในรหัสใช้วิธีการที่คล้ายกับการเขียนโปรแกรมแบบไดนามิกซึ่งไม่ง่ายที่จะเข้าใจ ที่นี่เราขอแนะนำให้ดูบล็อกต่อไปนี้:


