named_entity_recognition
1.0.0
Dieses Projekt versucht, das Problem der Erkennung chinesischer Namensentität unter Verwendung einer Vielzahl verschiedener Modelle (einschließlich HMM, CRF, BI-LSTM, BI-LSTM+CRF) zu lösen. Der Datensatz verwendet die im Papier ACL 2018 Chinese Ner mit Gitter -LSTM gesammelten Lebenslaufdaten. Das Format der Daten lautet wie folgt. Jede Zeile besteht aus einem Wort und seiner entsprechenden Annotation. Der Annotationssatz ist Bioes und die Sätze werden durch eine leere Linie getrennt.
美 B-LOC
国 E-LOC
的 O
华 B-PER
莱 I-PER
士 E-PER
我 O
跟 O
他 O
谈 O
笑 O
风 O
生 O
Dieser Datensatz befindet sich im Ordner ResumeNER im Projektverzeichnis.
Hier sind vier verschiedene Modelle und die Genauigkeit der Vorhersageergebnisse dieser vier Modelle (das Beste):
| HMM | CRF | Bilstm | BILSTM+CRF | Ensemble | |
|---|---|---|---|---|---|
| Rückrufrate | 91,22% | 95,43% | 95,32% | 95,72% | 95,65% |
| Genauigkeit | 91,49% | 95,43% | 95,37% | 95,74% | 95,69% |
| F1 -Punktzahl | 91,30% | 95,42% | 95,32% | 95,70% | 95,64% |
Die letzte Spalte des Ensemble kombiniert die Vorhersageergebnisse dieser vier Modelle und verwendet die "Abstimmungs" -Methode, um die endgültigen Vorhersageergebnisse zu erhalten.
(Die drei Indikatoren von Ensemble sind nicht so gut wie Bilstm+CRF. Es kann gesagt werden, dass im Ensemble -Prozess die anderen drei Modelle waren, die Bilstm+CRF schleppten)
Für eine bestimmte Ausgabe können Sie die Datei output.txt -Datei anzeigen.
Installieren Sie zuerst die Abhängigkeiten:
pip3 install -r requirement.txt
Verwenden Sie es nach der Installation direkt
python3 main.py
Sie können das Modell trainieren und bewerten. Das Bewertungsmodell druckt die Genauigkeit, den Rückruf, die F1 -Bewertungswert und die Verwirrungsmatrix des Modells aus. Wenn Sie die relevanten Modellparameter oder Trainingsparameter ändern möchten, können Sie diese in der Datei ./models/config.py festlegen.
Wenn Sie das Modell nach dem Training laden und bewerten möchten, führen Sie den folgenden Befehl aus:
python3 test.pyHier ist eine kurze Einführung in diese Modelle (die GitHub -Webseite unterstützt mathematische Formeln nicht sehr gut, und die Teile, die an Formeln beteiligt sind, können nicht normal angezeigt werden. Mein Blog hat eine detailliertere Einführung in diese Modelle und Code):
Das versteckte Markov -Modell beschreibt den Prozess der zufällig erzeugenden zufälligen Zufallssequenzen von nicht beobachtbarem Zustand aus einer versteckten Markov -Kette und dann eine Beobachtung aus jedem Zustand, um eine Zufallsequenz von Beobachtungen zu erzeugen (li -Hang -statistische Lernmethode). Das versteckte Markov -Modell wird durch die Ausgangszustandsverteilung, die staatliche Übergangswahrscheinlichkeitsmatrix und die beobachtete Wahrscheinlichkeitsmatrix bestimmt.
Die Benennungserkennung von Unternehmen kann im Wesentlichen als Problem mit Sequenzmarkierung angesehen werden. Wenn Sie HMM verwenden, um das Problem der Sequenzmarkierung der benannten Entitätserkennung zu lösen, können wir die Sequenz beobachten, die aus Wörtern (Beobachtungssequenz) besteht, und was wir nicht beobachten können, ist die Etikett, die jedem Wort entspricht (Zustandssequenz).
Die Ausbreitungsverteilung der Ausgangszustand ist die Initialisierungswahrscheinlichkeit jeder Etikett, und die Wahrscheinlichkeit der Statusübergangswahrscheinlichkeit ist die Wahrscheinlichkeit, von einer bestimmten Etikett auf das nächste Etikett zu überweisen (dh wenn das Etikett des vorherigen Wortes $ tag_i $ ist, ist die Wahrscheinlichkeit, dass das nächste Wort $ tag_j $ ist
Unter einer bestimmten Marke die Wahrscheinlichkeit, ein bestimmtes Wort zu erzeugen.
Der Trainingsprozess des HMM -Modells entspricht den Lernproblemen des versteckten Markov -Modells (li Hangs statistische Lernmethode).
In der Tat soll die drei Elemente des Modells basierend auf den Trainingsdaten basierend auf der maximalen Wahrscheinlichkeitsmethode, nämlich der oben genannten Ausgangszustandsverteilung, staatlichen Übergangswahrscheinlichkeitsmatrix und Beobachtungswahrscheinlichkeitsmatrix, geschätzt werden. Nach dem Training des Modells wird das Modell zur Dekodierung verwendet, dh für eine bestimmte Beobachtungssequenz soll seine entsprechende Zustandssequenz ermittelt werden. Hier finden Sie die entsprechende Annotation für jedes Wort im Satz für einen bestimmten Satz. Für dieses Dekodierungsproblem verwenden wir den Viterbi -Algorithmus.
Für spezifische Details finden Sie bitte die models/hmm.py -Datei.
Es gibt zwei Annahmen im HMM -Modell: Eine ist, dass die Ausgangsbeobachtungswerte streng unabhängig sind und der andere ist, dass der aktuelle Zustand nur mit dem vorherigen Zustand während des Zustandsübergangs zusammenhängt. Das heißt, in dem Szenario der Namenserkennung von Entitäten glaubt HMM, dass jedes Wort im beobachteten Satz unabhängig voneinander ist und das Etikett des aktuellen Moments nur mit dem Etikett des vorherigen Moments zusammenhängt. Tatsächlich erfordert die Namenserkennung von Entitäten häufig mehr Merkmale wie ein Teil der Sprache, des Wortkontexts usw. Gleichzeitig sollte das Etikett des aktuellen Moments mit dem Etikett des vorherigen Moments und des nächsten Moments in Verbindung gebracht werden. Aufgrund der Existenz dieser beiden Annahmen ist es offensichtlich, dass das HMM -Modell bei der Lösung des Problems der genannten Entitätserkennung fehlerhaft ist.
Bedingte Zufallsfelder können nicht nur die Abhängigkeit zwischen Beobachtungen ausdrücken, sondern auch die komplexe Abhängigkeit zwischen der aktuellen Beobachtung und den vorherigen und den nachfolgenden Zuständen darstellen, die die Probleme des HMM -Modells effektiv überwinden können.
Um ein bedingtes Zufallsfeld festzulegen, müssen wir zunächst eine Reihe von Feature -Funktionen definieren. Jede Funktionsfunktion im Set nimmt die Annotationssequenz als Eingabe und die extrahierten Merkmale als Ausgabe an. Angenommen, der Funktionssatz lautet:
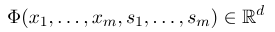
wobei $ x = (x_1, ..., x_m) $ die Beobachtungssequenz repräsentiert, und $ s = (s_1, ......, s_m) $ repräsentiert die Statussequenz. Das bedingte Zufallsfeld verwendet dann ein logarithmisches lineares Modell, um die bedingte Wahrscheinlichkeit der Zustandssequenz unter einer gegebenen Beobachtungssequenz zu berechnen:
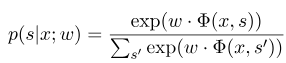
wobei $ s^{'} $ die Abfolge aller möglichen Zustände ist und $ W $ der Parameter des bedingten Zufallsfeldmodells ist, das als Gewicht jeder Merkmalsfunktion angesehen werden kann. Das Training des CRF -Modells ist tatsächlich die Schätzung des Parameters $ W $. Angenommen, wir haben $ n $ markierte Daten $ {(x^i, s^i)} _ {i = 1}^n $,,
Dann lautet die Regularisierungsform seiner Log-Likelihood-Funktion wie folgt:
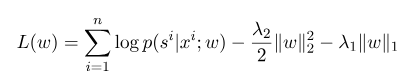
Dann ist der optimale Parameter $ w^*$:
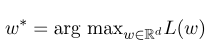
Nach Abschluss des Modelltrainings sollte die entsprechende optimale Zustandssequenz für die angegebene Beobachtungssequenz $ x $ sein:
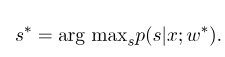
Es ähnelt HMM beim Dekodieren, und der Viterbi -Algorithmus kann auch verwendet werden.
Für spezifische Details finden Sie bitte die models/crf.py -Datei.
Zusätzlich zu den oben genannten zwei Methoden, die auf Wahrscheinlichkeitsgraphenmodellen basieren, wird LSTM häufig verwendet, um das Problem der Sequenzmarkierung zu lösen. Im Gegensatz zu HMM und CRF basiert LSTM auf die starke nichtlineare Anpassungsfähigkeit neuronaler Netzwerke. Während des Trainings werden die Proben durch komplexe nichtlineare Transformationen im hochdimensionalen Raum gelernt und verwenden diese Funktion dann, um die Annotation jedes Tokens für die angegebene Stichprobe vorherzusagen. Im Folgenden finden Sie ein schematisches Diagramm der Sequenzannotation unter Verwendung bidirektionaler LSTM (bidirektional kann die Abhängigkeiten zwischen Sequenzen besser erfassen):
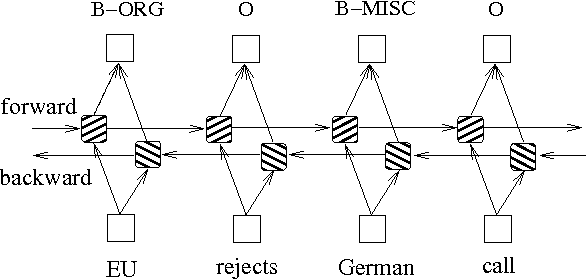
Die auf bidirektionale LSTM basierende Implementierung des Sequenzmarkierungsmodells kann models/bilstm.py -Datei anzeigen.
Der Vorteil von LSTM besteht darin, dass die Abhängigkeit zwischen Beobachtungssequenzen (Eingabewörter) durch bidirektionale Einstellungen lernen kann. Während des Schulungsprozesses kann LSTM die Eigenschaften der Beobachtungssequenz automatisch basierend auf dem Ziel (z. B. Identifizierungen) extrahieren, aber der Nachteil besteht darin, dass die Beziehung zwischen Zustandssequenzen (Ausgangsbezeichnungen) nicht lernen kann. Sie sollten wissen, dass bei der Aufgabe der Namenserkennungsaufgabe eine bestimmte Beziehung zwischen den Etiketten besteht. Zum Beispiel wird ein B -Etikett (der den Beginn einer Entität darstellt) nicht von einem anderen B -Etikett folgt. Wenn LSTM Sequenzmarkierungsaufgaben wie NER löst, obwohl es komplizierte Feature -Engineering beseitigen kann, hat es auch den Nachteil, den Kennzeichnungskontext nicht zu lernen.
Im Gegenteil, der Vorteil von CRF besteht darin, dass es implizite Zustände modellieren und die Eigenschaften von Zustandssequenzen lernen kann. Der Nachteil ist jedoch, dass es eine manuelle Extraktion von Sequenzfunktionen erfordert. Der allgemeine Ansatz besteht also darin, eine weitere CRF -Schicht hinter dem LSTM hinzuzufügen, um die Vorteile beider zu erhalten.
Für eine bestimmte Implementierung finden Sie in models/bilstm_crf.py
Das Problem von OOV (aus dem Vokabular) muss im HMM -Modell behandelt werden, dh einige Wörter im Testsatz befinden sich nicht im Trainingssatz. Zu diesem Zeitpunkt kann die Wahrscheinlichkeit verschiedener Zustände, die OOV entsprechen, nicht durch die Beobachtungswahrscheinlichkeitsmatrix gefunden werden. Um dieses Problem zu lösen, kann die Wahrscheinlichkeitsverteilung des Staates, der OOV entspricht, auf eine einheitliche Verteilung eingestellt werden.
Wenn die drei Parameter von HMM (d. H. Die Statusübergangswahrscheinlichkeitsmatrix, die Beobachtungswahrscheinlichkeitsmatrix und die Ausgangszustandswahrscheinlichkeitsmatrix) zur Schätzung unter Verwendung der überwachten Lernmethode verwendet werden, wenn einige Begriffe niemals erscheinen, erscheint der entsprechende Position des Begriffs 0. Wenn das Dekodieren der Viterbi -Algorithmus verwendet wird, benötigt der Berechnungsvorgang diese Werte, diese Werte, diese Werte. Wenn es dann Begriffe mit 0 gibt, wird die Wahrscheinlichkeit des gesamten Pfades ebenfalls zu 0. Zusätzlich führen mehrere Wahrscheinlichkeitsmultiplikationen während des Dekodierungsprozesses wahrscheinlich zu Unterströmungen. Um diese beiden Probleme zu lösen, weisen wir diesen Begriffen, die noch nie aufgetreten sind (wie 0,00000001), eine sehr kleine Zahl zu. Gleichzeitig zeichnen wir beim Dekodieren alle drei Parameter des Modells dem logarithmischen Raum ab, der nicht nur Unterströmung vermeiden kann, sondern auch den Multiplikationsvorgang vereinfacht.
Bevor Sie Trainingsdaten und Testdaten als Eingabe für das Modell in CRF verwenden, müssen Sie Funktionenfunktionen verwenden, um Funktionen zu extrahieren!
Für das BI-LSTM+CRF-Modell können Sie sich beziehen: Neuronale Architekturen für die Erkennung der genannten Entität, und Sie können sich auf die Definition der Verlustfunktion konzentrieren. Die Berechnung von Verlustfunktionen im Code verwendet eine Methode, die der dynamischen Programmierung ähnelt, was nicht leicht zu verstehen ist. Hier empfehlen wir uns, sich die folgenden Blogs anzusehen:


