named_entity_recognition
1.0.0
Этот проект пытается решить проблему распознавания китайских именованных сущностей с использованием различных различных моделей (включая HMM, CRF, BI-LSTM, BI-LSTM+CRF). Набор данных использует данные резюме, собранные в бумажном ACL 2018 китайского NER с использованием LSTM Lattice LSTM. Формат данных заключается в следующем. Каждая его строка состоит из слова и соответствующей его аннотации. Набор аннотаций - биоэты, а предложения разделены пустой линией.
美 B-LOC
国 E-LOC
的 O
华 B-PER
莱 I-PER
士 E-PER
我 O
跟 O
他 O
谈 O
笑 O
风 O
生 O
Этот набор данных расположен в папке ResumeNER в каталоге проекта.
Вот четыре различных моделя и точность результатов прогнозирования этих четырех моделей (взяв лучшие):
| ХМ | CRF | Bilstm | Bilstm+CRF | Ансамбль | |
|---|---|---|---|---|---|
| Частота отзыва | 91,22% | 95,43% | 95,32% | 95,72% | 95,65% |
| Точность | 91,49% | 95,43% | 95,37% | 95,74% | 95,69% |
| F1 Оценка | 91,30% | 95,42% | 95,32% | 95,70% | 95,64% |
Последний столбец ансамбля объединяет результаты прогнозирования этих четырех моделей и использует метод «голосования» для получения окончательных результатов прогнозирования.
(Три индикатора ансамбля не так хороши, как Bilstm+CRF. Можно сказать, что в ансамбле -процессе это были три других моделя, которые перетаскивали Bilstm+CRF)
Для конкретного вывода вы можете просмотреть файл output.txt .
Сначала установите зависимости:
pip3 install -r requirement.txt
После установки используйте его напрямую
python3 main.py
Вы можете тренировать и оценить модель. Модель оценки распечатает точность, отзыв, значение F1 и матрица путаницы. Если вы хотите изменить соответствующие параметры модели или параметры обучения, вы можете установить ее в файле ./models/config.py .
После обучения, если вы хотите загрузить и оценить модель, запустите следующую команду:
python3 test.pyВот краткое введение в эти модели (веб -страница Github не очень хорошо поддерживает математические формулы, и части, участвующие в формулах, не могут быть отображены нормально. Мой блог имеет более подробное введение в эти модели и код):
Скрытая модель Маркова описывает процесс случайного генерирования ненаблюдаемого состояния случайных последовательностей из скрытой цепи марковки, а затем генерирования наблюдения из каждого состояния для генерации случайной последовательности наблюдения (метод статистического обучения Li Hang). Скрытая модель Маркова определяется начальным распределением состояния, матрицей вероятности перехода состояния и наблюдаемой матрицей вероятности.
Признание имен сущностей можно по существу рассматриваться как проблема маркировки последовательности. При использовании HMM для решения задачи маркировки последовательности, названной именованной энтерий, мы можем наблюдать последовательность, состоящую из слов (последовательность наблюдения), и то, что мы не можем наблюдать, является меткой, соответствующей каждому слову (последовательность состояния).
Первоначальное распределение состояний - это вероятность инициализации каждой метки, а матрица вероятности перехода состояния - это вероятность передачи с определенной метки на следующую метку (то есть, если метка предыдущего слова - $ TAG_I $, вероятность метки следующего слова - $ Tag_J $
Под определенной отметки вероятность генерации определенного слова.
Процесс обучения модели HMM соответствует задачам обучения скрытой модели Маркова (метод статистического обучения Li Hang),
Фактически, для оценки трех элементов модели на основе учебных данных, основанных на методе максимального правдоподобия, а именно, а именно на начальном распределении состояния, матрице вероятности перехода состояния и матрице вероятности наблюдения. После обучения модели модель используется для декодирования, то есть для данной последовательности наблюдения, она должна найти соответствующую последовательность состояний. Здесь нужно найти соответствующую аннотацию для каждого слова в предложении для данного предложения. Для этой проблемы декодирования мы используем алгоритм Viterbi.
Для получения конкретной информации, пожалуйста, проверьте файл models/hmm.py .
В модели HMM есть два предположения: одно состоит в том, что значения выходного наблюдения строго независимы, а другое заключается в том, что текущее состояние связано только с предыдущим состоянием во время перехода состояния. То есть, в сценарии признания именования сущностей, HMM считает, что каждое слово в наблюдаемом предложении не зависит друг от друга, и метка текущего момента связан только с меткой предыдущего момента. Но на самом деле, распознавание сущностей часто требуется больше функций, таких как часть речи, контекст слов и т. Д. В то же время, этикетка текущего момента должна быть связана с этикеткой предыдущего момента и следующим моментом. Из -за наличия этих двух предположений очевидно, что модель HMM ошибочна в решении проблемы распознавания именованных объектов.
Условные случайные поля могут не только экспрессировать зависимость между наблюдениями, но также представлять сложную зависимость между текущим наблюдением и предыдущими и последующими состояниями, что может эффективно преодолеть проблемы, с которыми сталкиваются модель HMM.
Чтобы установить условное случайное поле, нам сначала необходимо определить набор функций функций, каждая функция функции в наборе принимает последовательность аннотации в качестве входных и извлеченных функций в качестве вывода. Предположим, что набор функций:
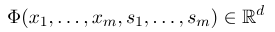
где $ x = (x_1, ..., x_m) $ представляет последовательность наблюдения, а $ s = (s_1, ......, s_m) $ представляет последовательность состояния. Условное случайное поле затем использует логарифмическую линейную модель для расчета условной вероятности последовательности состояния в данной последовательности наблюдения:
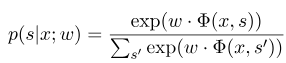
где $ s^{'} $ - последовательность всех возможных состояний, а $ w $ является параметром условной модели случайного поля, которую можно рассматривать как вес каждой функции. Обучение модели CRF на самом деле является оценкой параметра $ W $. Предположим, что у нас есть $ n $, отмеченные данные $ {(x^i, s^i)} _ {i = 1}^n $,
Тогда форма регуляризации его функции логарифмического правдоподобия следующая:
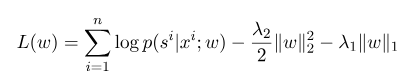
Затем оптимальный параметр $ W^*$ - это:
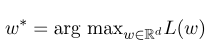
После завершения модельной обучения для данной последовательности наблюдения $ x $ ее соответствующая оптимальная последовательность состояния должна быть:
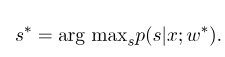
Это похоже на HMM при декодировании, и алгоритм Viterbi также можно использовать.
Для получения конкретной информации, пожалуйста, проверьте файл models/crf.py .
В дополнение к двум вышеуказанным методам, основанным на моделях графика вероятности, LSTM часто используется для решения проблемы маркировки последовательности. В отличие от HMM и CRF, LSTM опирается на сильную нелинейную способность нейронных сетей. Во время тренировки образцы изучаются с помощью сложных нелинейных преобразований в высокомерном пространстве, а затем используют эту функцию для прогнозирования аннотации каждого токена для указанного образца. Ниже приведена схематическая схема аннотации последовательности с использованием двунаправленного LSTM (двунаправленный может лучше захватить зависимости между последовательностями):
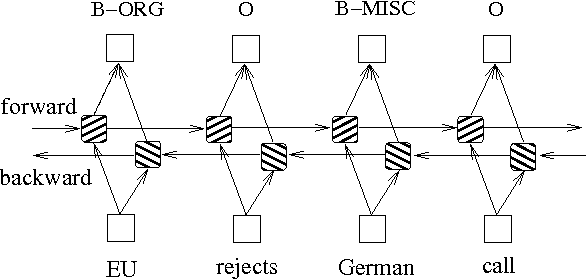
Реализация модели маркировки последовательности, основанная на двунаправленной LSTM, может просматривать файл models/bilstm.py .
Преимущество LSTM заключается в том, что он может изучить зависимость между последовательностями наблюдений (входные слова) посредством двунаправленных настроек. Во время учебного процесса LSTM может автоматически извлекать характеристики последовательности наблюдения на основе цели (например, идентификации сущностей), но недостаток заключается в том, что он не может изучить взаимосвязь между последовательностями состояний (выходные метки). Вы должны знать, что в задаче по признанию именования существует определенная связь между этикетками. Например, на метке B (представляющий начало сущности) не будет следовать другой метку B. Следовательно, когда LSTM решает задачи маркировки последовательности, такие как NER, хотя он может устранить сложную инженерию функций, он также имеет недостаток в том, что он не способен выучить контекст маркировки.
Напротив, преимущество CRF заключается в том, что он может моделировать неявные состояния и изучать характеристики последовательностей состояний, но его недостаток заключается в том, что он требует ручной извлечения особенностей последовательности. Таким образом, общий подход состоит в том, чтобы добавить еще один слой CRF за LSTM, чтобы получить преимущества обоих.
Для конкретной реализации см. models/bilstm_crf.py
Проблема OOV (из словарного запаса) должна быть решена в модели HMM, то есть некоторые слова в тестовом наборе не находятся в тренировочном наборе. В это время вероятность различных состояний, соответствующих OOV, не может быть найдена через матрицу вероятности наблюдения. Чтобы решить эту проблему, распределение вероятности состояния, соответствующее OOV, может быть установлено на равномерное распределение.
Когда три параметра HMM (то есть, матрица вероятности перехода состояния, матрица вероятности наблюдения и матрица вероятности начального состояния) используются для оценки с использованием метода контролируемого обучения, если некоторые термины никогда не появляются, то соответствующее положение термина составляет 0. При расширении с использованием алгоритма Viterbi процесс расчета необходимо увеличивать эти значения. Затем, если есть термины с 0, вероятность всего пути также станет 0. Кроме того, множественные умножения с низкой вероятностью в процессе декодирования, вероятно, вызывают недостаточность. Чтобы решить эти две проблемы, мы назначаем очень небольшое число на те условия, которые никогда не появились (например, 0,00000001). В то же время, при декодировании, мы сопоставляем все три параметра модели в логарифмическое пространство, что может не только избегать недостаточности, но и упростить операцию умножения.
Перед использованием учебных данных и тестовых данных в качестве входных данных в модель в CRF вам необходимо использовать функции функций для извлечения функций!
Для модели BI-LSTM+CRF вы можете ссылаться на: нейронные архитектуры для распознавания именованных объектов, и вы можете сосредоточиться на определении функции потери в нем. Расчет функций потерь в коде использует метод, аналогичный динамическому программированию, который нелегко понять. Здесь мы рекомендуем посмотреть на следующие блоги:


