named_entity_recognition
1.0.0
يحاول هذا المشروع حل مشكلة التعرف على كيان التسمية الصينية باستخدام مجموعة متنوعة من النماذج المختلفة (بما في ذلك HMM ، CRF ، BI-LSTM ، BI-LSTM+CRF). تستخدم مجموعة البيانات بيانات السيرة الذاتية التي تم جمعها في الورقة ACL 2018 الصينية NER باستخدام Lattice LSTM. شكل البيانات كما يلي. يتكون كل سطر منه من كلمة وشرح توضيحها المقابل. مجموعة التعليقات التوضيحية هي Bioes ويتم فصل الجمل بخط فارغ.
美 B-LOC
国 E-LOC
的 O
华 B-PER
莱 I-PER
士 E-PER
我 O
跟 O
他 O
谈 O
笑 O
风 O
生 O
تقع مجموعة البيانات هذه في مجلد ResumeNER في دليل المشروع.
فيما يلي أربعة نماذج مختلفة ودقة نتائج التنبؤ لهذه النماذج الأربعة (تأخذ الأفضل):
| همم | CRF | bilstm | BILSTM+CRF | فرقة | |
|---|---|---|---|---|---|
| استدعاء معدل | 91.22 ٪ | 95.43 ٪ | 95.32 ٪ | 95.72 ٪ | 95.65 ٪ |
| دقة | 91.49 ٪ | 95.43 ٪ | 95.37 ٪ | 95.74 ٪ | 95.69 ٪ |
| درجة F1 | 91.30 ٪ | 95.42 ٪ | 95.32 ٪ | 95.70 ٪ | 95.64 ٪ |
يجمع العمود الأخير من Ensemble بين نتائج التنبؤ لهذه النماذج الأربعة ويستخدم طريقة "التصويت" للحصول على نتائج التنبؤ النهائية.
(مؤشرات Ensemble الثلاثة ليست جيدة مثل BILSTM+CRF. يمكن القول أنه في عملية المجموعة ، كانت النماذج الثلاثة الأخرى هي التي جرت BILSTM+CRF)
لإخراج محدد ، يمكنك عرض ملف output.txt .
قم أولاً بتثبيت التبعيات:
pip3 install -r requirement.txt
بعد التثبيت ، استخدمه مباشرة
python3 main.py
يمكنك تدريب وتقييم النموذج. سيقوم نموذج التقييم بطباعة دقة النموذج ، واستدعاء ، وقيمة نقاط F1 ومصفوفة الارتباك. إذا كنت ترغب في تعديل معلمات النموذج ذات الصلة أو معلمات التدريب ، فيمكنك تعيينها في ملف ./models/config.py .
بعد التدريب ، إذا كنت ترغب في تحميل وتقييم النموذج ، قم بتشغيل الأمر التالي:
python3 test.pyفيما يلي مقدمة موجزة لهذه النماذج (Github Web Page لا تدعم الصيغ الرياضية بشكل جيد للغاية ، ولا يمكن عرض الأجزاء المشاركة في الصيغ بشكل طبيعي. مدونتي لديها مقدمة أكثر تفصيلاً لهذه النماذج والرمز):
يصف نموذج Markov المخفي عملية توليد تسلسل عشوائي لا يمكن ملاحظته بشكل غير قابل للملاحظة من سلسلة Markov المخفية ، ثم توليد ملاحظة من كل حالة لتوليد تسلسل عشوائي للمراقبة (LI طريقة التعلم الإحصائي المعلقة). يتم تحديد نموذج Markov المخفي من خلال توزيع الحالة الأولي ، ومصفوفة احتمال انتقال الحالة ، ومصفوفة الاحتمال المرصودة.
يمكن اعتبار تسمية التعرف على الكيان بشكل أساسي مشكلة في وصف تسلسل. عند استخدام HMM لحل مشكلة وضع العلامات التسلسلية الخاصة بالتعرف على الكيان المسماة ، فإن ما يمكن أن نلاحظه هو التسلسل المكون من الكلمات (تسلسل الملاحظة) ، وما لا يمكننا ملاحظته هو التسمية المقابلة لكل كلمة (تسلسل الحالة).
توزيع الحالة الأولي هو احتمال التهيئة لكل تسمية ، ومصفوفة احتمال انتقال الحالة هي احتمال الانتقال من تسمية معينة إلى الملصق التالي (أي إذا كانت تسمية الكلمة السابقة هي $ tag_i $ ، فإن احتمال تسمية الكلمة التالية هي $ tag_ $ $
تحت علامة معينة ، احتمال توليد كلمة معينة.
تتوافق عملية التدريب لنموذج HMM مع مشاكل التعلم لنموذج Markov المخفي (طريقة التعلم الإحصائي لـ Li Hang) ،
في الواقع ، هو تقدير العناصر الثلاثة للنموذج بناءً على بيانات التدريب بناءً على أقصى طريقة احتمال ، وهي توزيع الحالة الأولي ، ومصفوفة احتمال انتقال الحالة ومصفوفة احتمال المراقبة المذكورة أعلاه. بعد تدريب النموذج ، يتم استخدام النموذج لفك التشفير ، أي بالنسبة لتسلسل مراقبة معين ، فإنه هو العثور على تسلسل حالته المقابلة. فيما يلي العثور على التعليق التوضيحي المقابل لكل كلمة في الجملة لقمة معينة. لهذه المشكلة فك التشفير ، نستخدم خوارزمية Viterbi.
للحصول على تفاصيل محددة ، يرجى التحقق من ملف models/hmm.py
هناك افتراضان في نموذج HMM: الأول هو أن قيم مراقبة الإخراج مستقلة تمامًا ، والآخر هو أن الحالة الحالية مرتبطة فقط بالدولة السابقة أثناء انتقال الحالة. وهذا يعني ، في سيناريو التعرف على الكيانات ، يعتقد HMM أن كل كلمة في الجملة المرصودة مستقلة عن بعضها البعض ، وملصق اللحظة الحالية مرتبطة فقط بتسمية اللحظة السابقة. ولكن في الواقع ، غالبًا ما يتطلب التعرف على الكيانات المزيد من الميزات ، مثل جزء من الكلام ، سياق الكلمات ، إلخ. في نفس الوقت ، يجب أن ترتبط تسمية اللحظة الحالية بتسمية اللحظة السابقة واللحظة التالية. نظرًا لوجود هذين الافتراضين ، فمن الواضح أن نموذج HMM معيب في حل مشكلة التعرف على الكيان المسماة.
لا يمكن للحقول العشوائية الشرطية التعبير عن الاعتماد بين الملاحظات فحسب ، بل تمثل أيضًا الاعتماد المعقد بين الملاحظة الحالية والحالات السابقة واللاحقة ، والتي يمكن أن تتغلب بشكل فعال على المشكلات التي يواجهها نموذج HMM.
من أجل إنشاء حقل عشوائي مشروط ، نحتاج أولاً إلى تحديد مجموعة من وظائف الميزة ، وتأخذ كل وظيفة ميزة في المجموعة تسلسل التعليقات التوضيحية كمدخلات وميزات مستخرجة كإخراج. افترض أن مجموعة الوظائف هي:
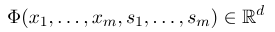
حيث يمثل $ x = (x_1 ، ... ، x_m) $ تسلسل المراقبة ، و $ s = (s_1 ، ...... ، s_m) $ يمثل تسلسل الحالة. يستخدم الحقل العشوائي الشرطي بعد ذلك نموذجًا خطيًا لوغاريتميًا لحساب الاحتمال الشرطي لتسلسل الحالة تحت تسلسل مراقبة معين:
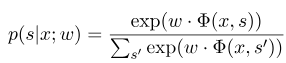
حيث $ s^{'} $ هو تسلسل جميع الحالات الممكنة ، و $ w $ هو معلمة نموذج الحقل العشوائي الشرطي ، والذي يمكن اعتباره وزن كل وظيفة ميزة. تدريب نموذج CRF هو في الواقع تقدير المعلمة $ w $. افترض أن لدينا $ n $ data $ {(x^i ، s^i)} _ {i = 1}^n $ ،
ثم يكون شكل تنظيم وظيفة احتمالية السجل الخاصة به كما يلي:
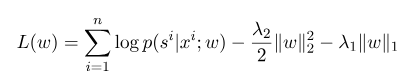
ثم ، المعلمة المثلى $ w^*$ هي:
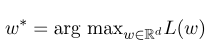
بعد اكتمال التدريب النموذجي ، لتسلسل المراقبة المعطى $ x $ ، يجب أن يكون تسلسل الحالة الأمثل المقابل:
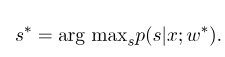
إنه مشابه لـ HMM عند فك التشفير ، ويمكن أيضًا استخدام خوارزمية Viterbi.
للحصول على تفاصيل محددة ، يرجى التحقق من ملف models/crf.py
بالإضافة إلى الطريقتين أعلاه القائمة على نماذج الرسم البياني الاحتمال ، غالبًا ما يتم استخدام LSTM لحل مشكلة وضع العلامات التسلسل. على عكس HMM و CRF ، يعتمد LSTM على القدرة القوية غير الخطية للشبكات العصبية. أثناء التدريب ، يتم تعلم العينات من خلال التحولات غير الخطية المعقدة في الفضاء العالي الأبعاد ، ثم استخدم هذه الوظيفة للتنبؤ بتعليق كل رمز للعينة المحددة. فيما يلي رسم تخطيطي لشرح التسلسل باستخدام LSTM ثنائية الاتجاه (يمكن أن يؤدي ثنائية الاتجاه إلى الحصول على التبعيات بين التسلسلات):
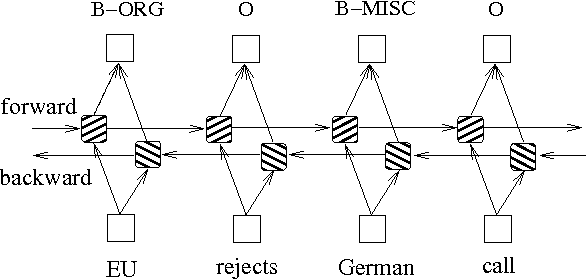
يمكن لتطبيق نموذج وضع العلامات التسلسل استنادًا إلى LSTM ثنائية الاتجاه عرض ملف models/bilstm.py .
ميزة LSTM هي أنه يمكن أن يتعلم الاعتماد بين تسلسل الملاحظة (كلمات الإدخال) من خلال الإعدادات ثنائية الاتجاه. أثناء عملية التدريب ، يمكن لـ LSTM تلقائيًا استخراج خصائص تسلسل المراقبة بناءً على الهدف (مثل تحديد الكيانات) ، ولكن العيب هو أنه لا يمكن أن يتعلم العلاقة بين تسلسل الحالة (ملصقات الإخراج). يجب أن تعلم أنه في مهمة التعرف على الكيان التسمية ، هناك علاقة معينة بين الملصقات. على سبيل المثال ، لن تتبع علامة B (التي تمثل بداية كيان) علامة B أخرى. لذلك ، عندما يحل LSTM مهام وضع العلامات التسلسل مثل NER ، على الرغم من أنه يمكن أن يلغي هندسة الميزات المعقدة ، فإنه لديه أيضًا عيوب عدم القدرة على تعلم سياق وضع العلامات.
على العكس من ذلك ، فإن ميزة CRF هي أنه يمكن أن يصمم حالات ضمنية وتعلم خصائص تسلسل الحالة ، ولكن عيوبها هي أنها تتطلب الاستخراج اليدوي لميزات التسلسل. لذلك فإن النهج العام هو إضافة طبقة أخرى من CRF خلف LSTM للحصول على مزايا كليهما.
للتنفيذ المحدد ، يرجى الاطلاع على models/bilstm_crf.py
يجب التعامل مع مشكلة OOV (خارج المفردات) في نموذج HMM ، أي أن بعض الكلمات في مجموعة الاختبار ليست في مجموعة التدريب. في هذا الوقت ، لا يمكن العثور على احتمال وجود حالات مختلفة المقابلة لـ OOV من خلال مصفوفة احتمال المراقبة. للتعامل مع هذه المشكلة ، يمكن ضبط توزيع احتمال الحالة المقابلة لـ OOV على توزيع موحد.
عندما يتم استخدام المعلمات الثلاثة لـ HMM (أي مصفوفة احتمال انتقال الحالة ، ومصفوفة احتمال المراقبة ومصفوفة احتمال الحالة الأولية) للتقدير باستخدام طريقة التعلم الخاضعة للإشراف ، إذا لم تظهر بعض المصطلحات أبدًا ، فإن الموضع المقابل للمصطلح هو 0. ثم إذا كانت هناك مصطلحات مع 0 ، فسيصبح احتمال المسار بأكمله 0. بالإضافة إلى ذلك ، من المحتمل أن يتسبب مضاعفات الاحتمالات المنخفضة المتعددة أثناء عملية فك التشفير. من أجل حل هاتين المشكلتين ، نقوم بتعيين عدد صغير جدًا لتلك المصطلحات التي لم تظهر أبدًا (مثل 0.00000001). في الوقت نفسه ، عند فك التشفير ، نقوم بتخطيط جميع المعلمات الثلاثة للنموذج إلى المساحة اللوغاريتمية ، والتي لا يمكن أن تجنب فقط التدفق ، ولكن أيضًا تبسيط عملية الضرب.
قبل استخدام بيانات التدريب وبيانات الاختبار كمدخلات للنموذج في CRF ، تحتاج إلى استخدام وظائف الميزة لاستخراج الميزات!
بالنسبة لنموذج Bi-LSTM+CRF ، يمكنك الرجوع إلى: البنى العصبية للتعرف على الكيان المسماة ، ويمكنك التركيز على تعريف وظيفة الخسارة فيه. يستخدم حساب وظائف الخسارة في الكود طريقة مشابهة للبرمجة الديناميكية ، والتي ليس من السهل فهمها. هنا نوصي بالنظر إلى المدونات التالية:


