a PyTorch Tutorial to Sequence Labeling
1.0.0
這是序列標記的Pytorch教程。
這是我正在寫的一系列教程中的第二個,內容涉及出色的Pytorch圖書館獨自實施酷模型。
假定Pytorch,復發性神經網絡的基礎知識。
如果您是Pytorch的新手,請首先使用Pytorch閱讀深度學習:60分鐘的閃電戰和學習示例的Pytorch。
問題,建議或更正可以作為問題發布。
我在Python 3.6中使用PyTorch 0.4 。
2020年1月27日:添加了兩個新教程的工作代碼 - 超分辨率和機器翻譯
客觀的
概念
概述
執行
訓練
常見問題
構建一個可以在句子中標記每個單詞的模型,其中包括實體,一部分語音等。

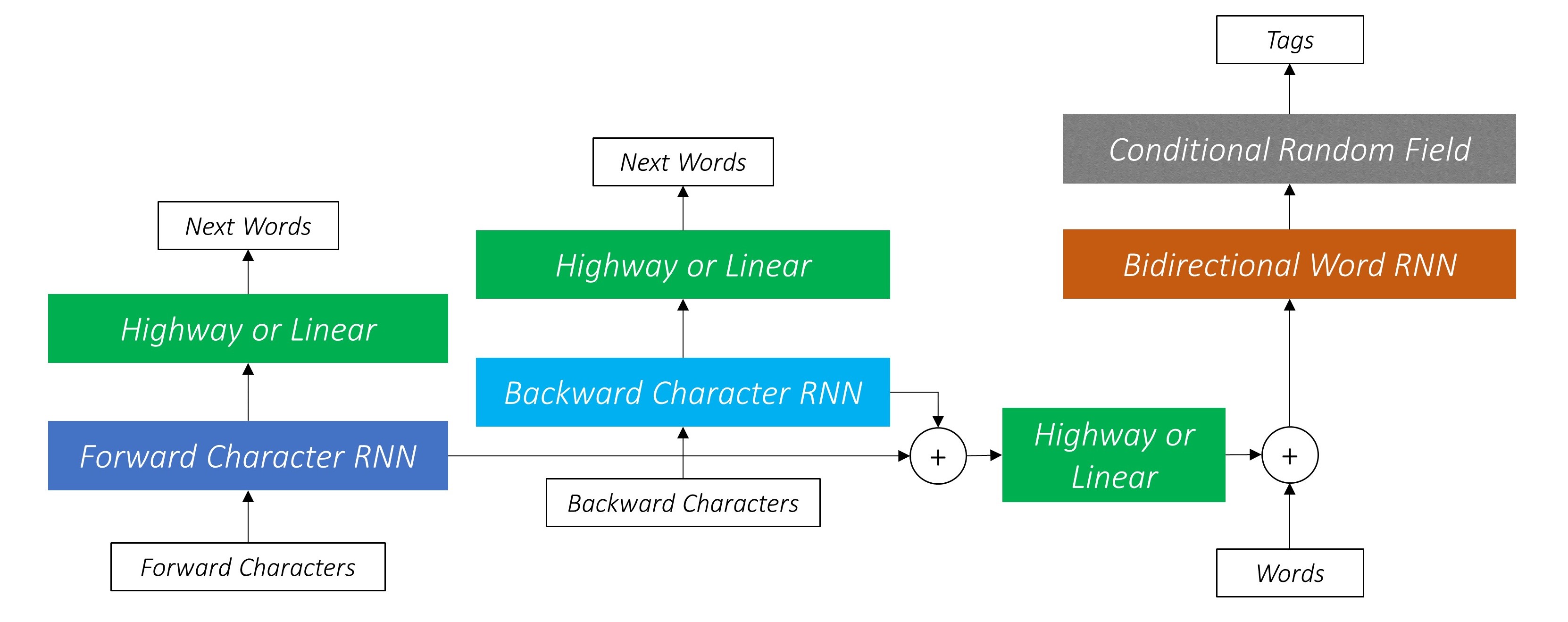
我們將使用任務感知的神經語言模型論文實施授權序列標籤。這比大多數序列標記模型更為先進,但是您將學到許多有用的概念 - 而且效果很好。作者的原始實現可以在此處找到。
該模型很特別,因為它通過與語言模型同時訓練它來增強序列標記任務。
序列標記。 du。
語言模型。語言建模是通過一系列單詞或字符來預測下一個單詞或字符。神經語言模型在各種NLP任務中取得了令人印象深刻的結果,例如文本生成,機器翻譯,圖像字幕,光學字符識別以及您的工作。
角色rnns 。已知在文本中的單個字符上操作的RNN可以捕獲基本樣式和結構。在序列標記任務中,它們特別有用,因為子字通常可以為實體或標籤產生重要的線索。
多任務學習。可用於訓練模型的數據集通常很小。創建註釋或手工製作的功能來幫助您的模型不僅繁瑣,而且通常不適合您模型可能有用的不同域或設置。不幸的是,序列標記是一個很好的例子。有一種減輕此問題的方法 - 共同訓練以臀部連接的多個模型將最大化每個模型可用的信息,從而提高性能。
有條件的隨機字段。離散分類器在單詞上預測類或標籤。有條件的隨機字段(CRF)可以更好地為您提供一個 - 他們不僅基於單詞,而且還基於鄰居預測標籤。這是有道理的,因為一系列實體或標籤中存在模式。 CRF被廣泛用於建模有序信息,無論是用於序列標記,基因測序還是在計算機視覺中的對象檢測和圖像分割。
Viterbi解碼。由於我們使用的是CRF,因此我們並沒有在每個單詞上預測正確的標籤,而是我們預測單詞序列的正確標籤序列。 Viterbi解碼是一種準確做到這一點的方法 - 從條件隨機場計算出的分數中找到最佳的標籤序列。
公路網絡。完全連接的層是任何神經網絡中的主食,可以在不同位置轉換或提取特徵。高速公路網絡實現了這一目標,但也允許信息在轉換中不受阻礙。這使深層網絡效率更高或可行。
在本節中,我將介紹此模型。如果您已經熟悉它,則可以直接跳到實施部分或註釋代碼。
作者將模型稱為語言模型 - 長期短期內存 - 條件隨機字段,因為它涉及與LSTM + CRF組合的共同培訓語言模型。
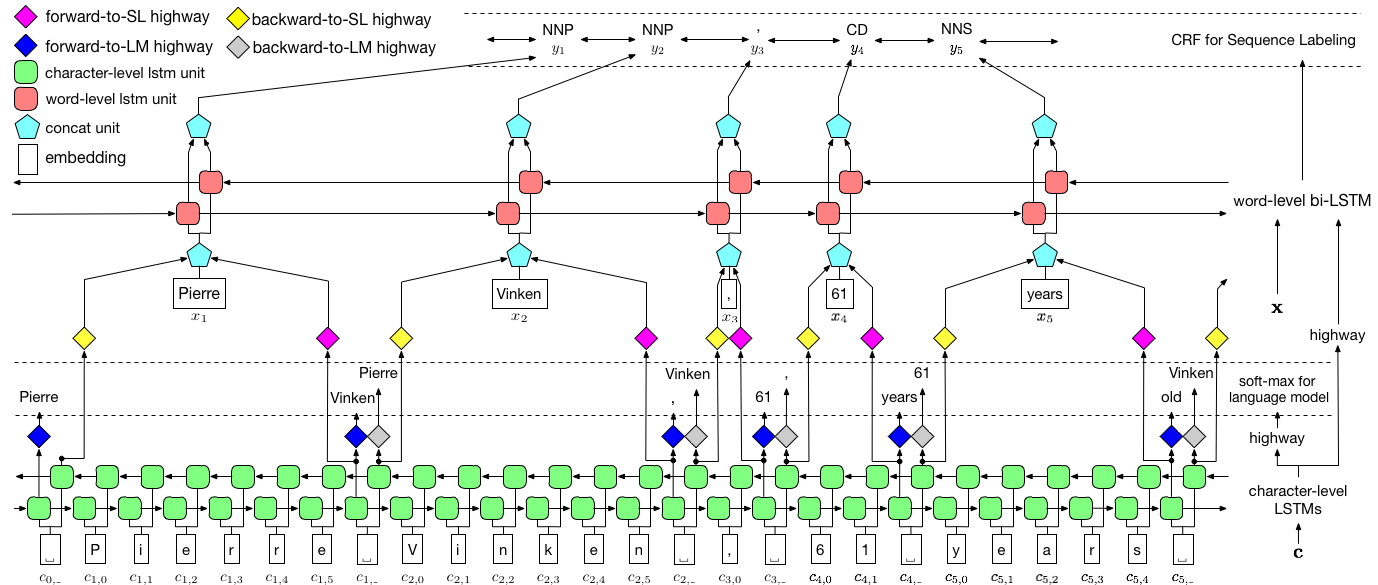
紙上的圖像完全代表了整個模型,但是不必擔心目前看起來是否太複雜。我們將其分解,仔細研究組件。
多任務學習是當您同時在兩個或多個任務上訓練模型。
通常,我們只對其中一項任務感興趣 - 在這種情況下是序列標籤。
但是,當神經網絡中的層次有助於執行多個功能時,他們學到的比僅在主要任務上培訓的情況要多。這是因為擴展了每一層中提取的信息以適應所有任務。當有更多信息可以使用時,主要任務的性能就會增強。
以這種方式豐富現有功能可以消除使用手工製作的功能進行序列標籤的需求。
多任務學習期間的總損失通常是單個任務上損失的線性組合。組合的參數可以作為可更新的權重固定或學習。

由於我們正在匯總個人損失,因此您可以看到多個任務共享的上游層如何在反向傳播期間從所有任務中收到所有更新。
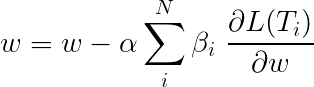
本文的作者只需添加損失( β=1 ),我們將做同樣的事情。
讓我們看一下組成我們模型的任務。
有三個。

這利用子字預測下一個單詞。
我們在向後做同樣的事情。 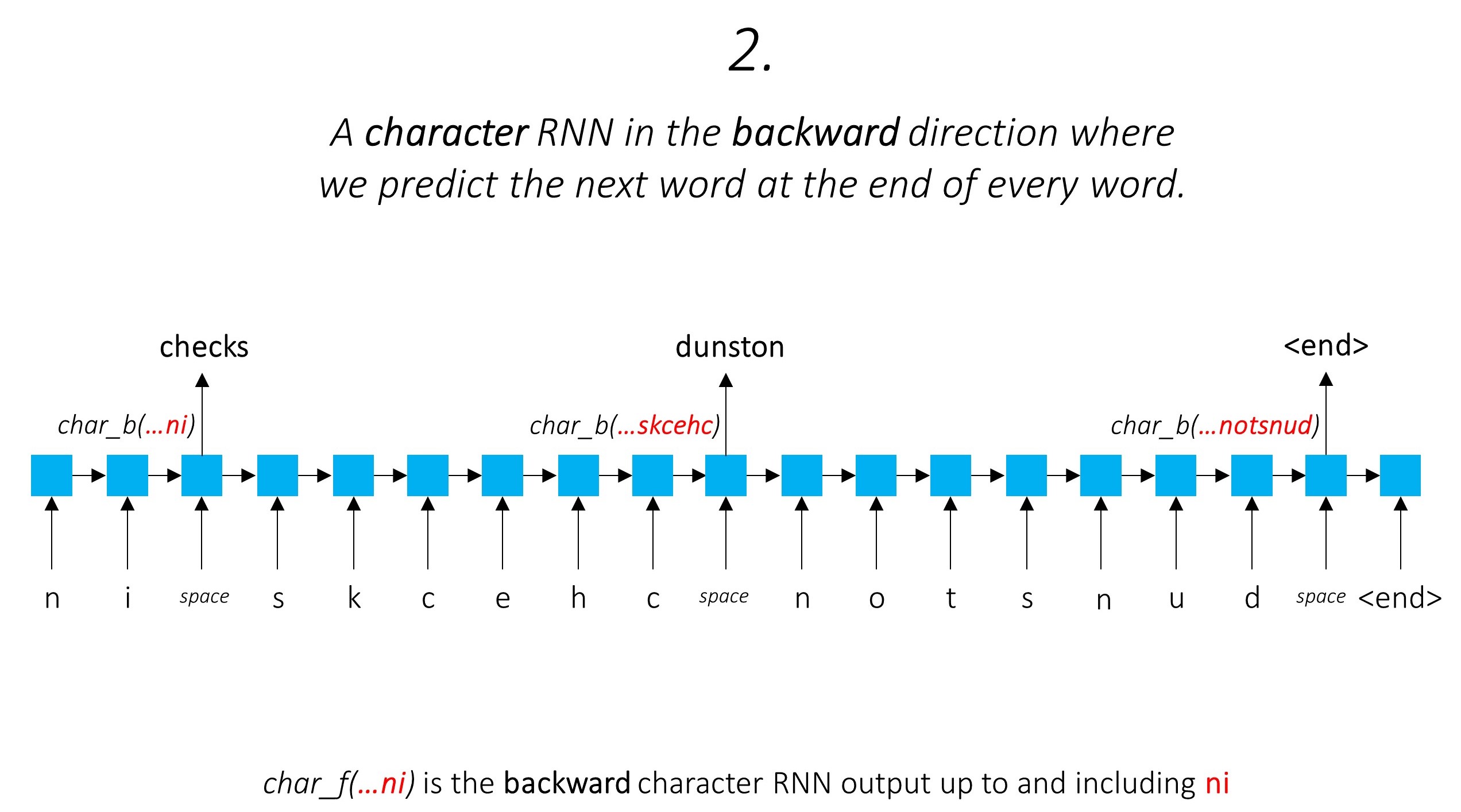
我們還將這兩個字符RNN的輸出用作我們單詞rnn和條件隨機字段(CRF)的輸入,以執行我們的序列標記的主要任務。 
我們在標記任務中使用子字信息,因為它可以是標籤的有力指標,無論是語音的一部分還是實體。例如,它可能會學會形容詞通常以“ -y”或“ -ul”結尾,或者通常以“ -land”或“ -burg”結尾。
但是我們的子字特徵,即。字符rnns的輸出也充滿了其他信息 - 由於模型1和2,它需要在向前和向後預測下一個單詞所需的知識。
因此,我們的序列標記模型都使用
雙向LSTM/RNN將這些功能編碼為每個單詞的新功能,其中包含有關單詞及其鄰居的信息,無論是單詞級別還是字符級別。這形成了條件隨機場的輸入。
如果沒有CRF,我們只會使用單個線性層將雙向LSTM的輸出轉換為每個標籤的分數。這些被稱為排放分數,這是單詞為某個標籤的可能性的表示。
CRF不僅計算排放得分,而且還計算過渡分數,這是一個單詞是一個標籤的可能性,因為上一個單詞是某個標籤。因此,過渡分數衡量從一個標籤過渡到另一個標籤的可能性。
如果有m標籤,則將過渡分數存儲在一個鑽機m, m的矩陣中,其中行代表上一個單詞的標籤,列代表當前單詞的標籤。該矩陣中的一個值在i, j是從上一個單詞上的i th標籤過渡到當前單詞的j th標籤的可能性。與排放分數不同,句子中的每個單詞都沒有定義過渡分數。他們是全球的。
在我們的模型中,CRF層在每個單詞上輸出發射和過渡分數的匯總。
對於長度為L的句子,排放得分將是L, m張量。由於每個單詞的發射分數不取決於上一個單詞的標籤,因此我們創建了一個新的維度,例如L, _, m和廣播(複製)沿這個方向的張量,以獲取L, m, m Tensor。
過渡分數是m, m張量。由於過渡分數是全局的,並且不依賴於單詞,因此我們創建一個新的維度,例如_, m, m和廣播(複製)沿這個方向張量,以獲得L, m, m張量。
現在,我們可以添加它們以獲得L, m, m張量的總得分。位置k, i, j處的值是k th單詞的j th標籤的發射分數的總和,考慮到上一個單詞的k th單詞的j th標籤的過渡得分是i th標籤。
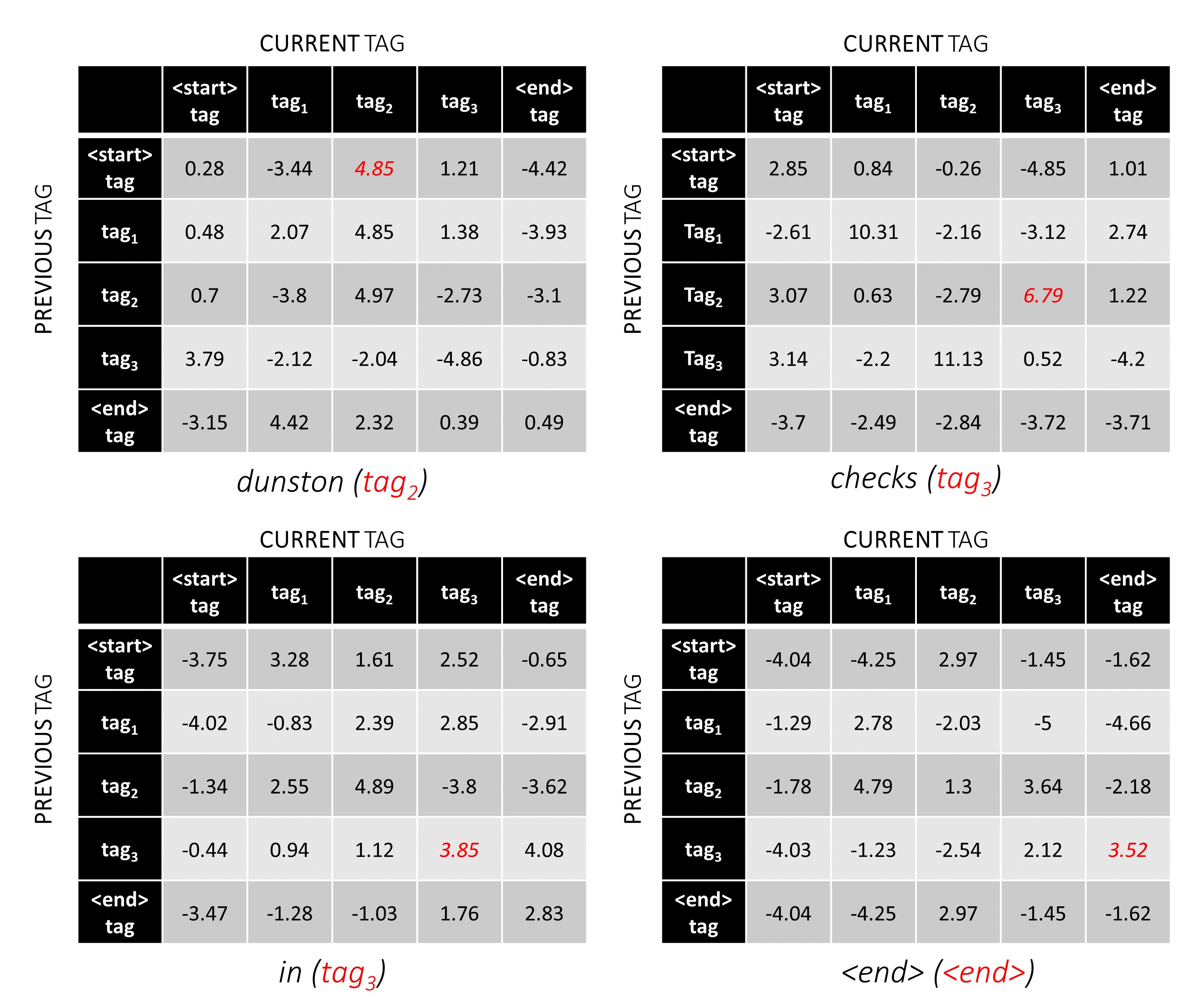
對於我們的示例句子, dunston checks in <end> ,如果我們假設總共有5個標籤,那麼總得分將看起來像這樣 -
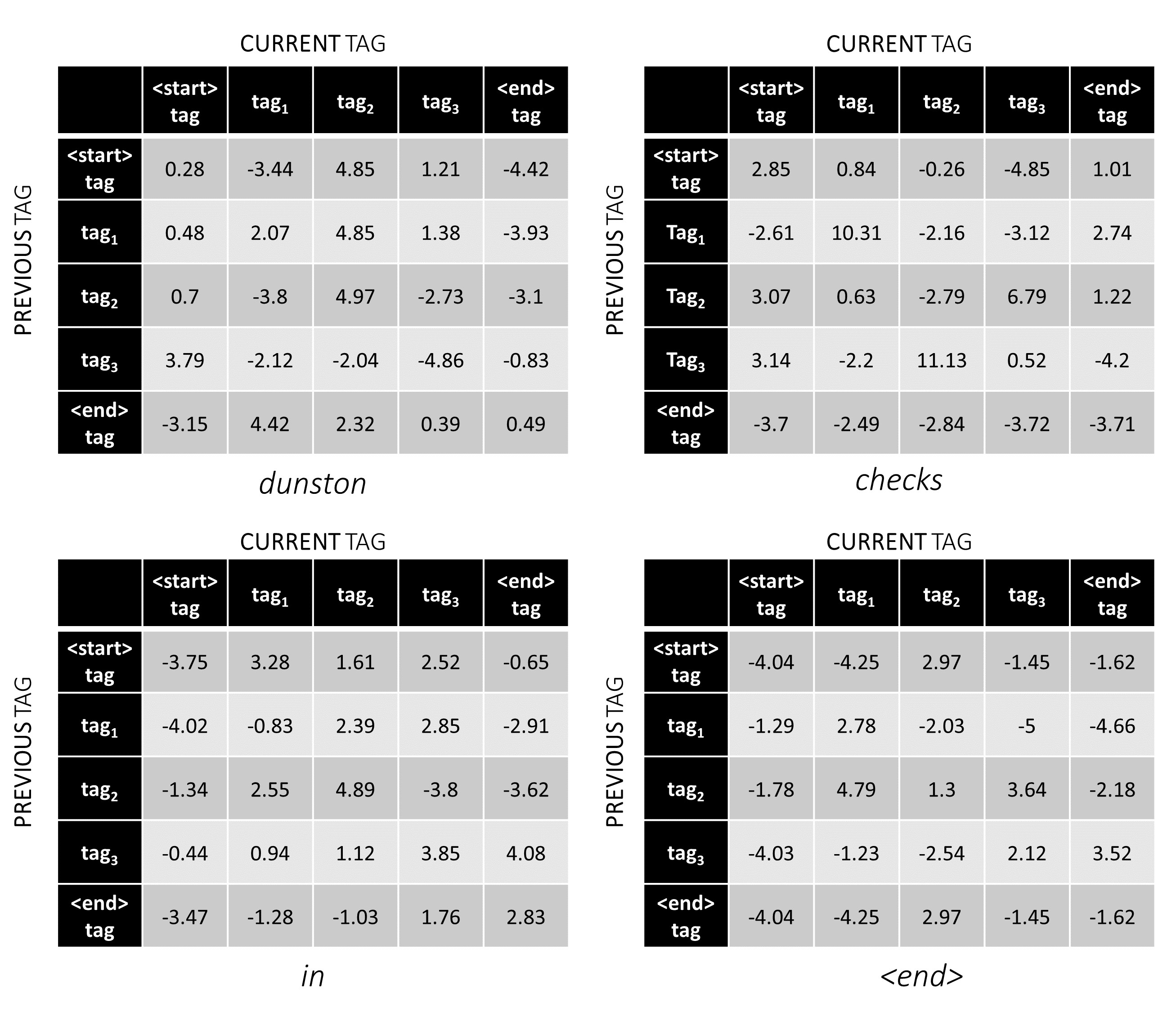
但是請等一下,為什麼<start> end <end>標籤?當我們使用時,為什麼要使用<end>令牌?
<start>和<end>標籤, <start>和<end>令牌由於我們正在對標籤之間過渡的可能性進行建模,因此我們還將<start>和<end>標籤包括在標籤中。
鑑於先前的標籤是<start>標籤,該標籤的過渡得分錶示該標籤的可能性是句子中的第一個標籤。例如,句子通常以文章(A,AN,THE)或名詞或代詞開頭。
考慮到某個上一個標籤的<end>標籤的過渡分數表明,先前標籤的可能性是句子中的最後一個標籤。
我們將在所有句子中使用<end>令牌,而不是<start>令牌,因為每個單詞的總CRF分數是針對上一個單詞的標籤定義的,這在<start>令牌上是沒有意義的。
<end>令牌的正確標籤始終是<end>標籤。第一個單詞的“先前標籤”始終是<start>標籤。
為了說明,如果我們的示例句子dunston checks in <end>標籤tag_2, tag_3, tag_3, <end> ,紅色的值表示這些標籤的分數。
我們通常使用激活的線性層來轉換和處理RNN/LSTM的輸出。
如果您熟悉剩餘連接,我們可以在轉換之前將輸入添加到轉換後的輸出,從而為轉換周圍的數據流提供了一條路徑。
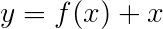
該路徑是反向傳播過程中梯度流的捷徑,有助於深網的收斂。
高速公路網絡類似於殘差網絡,但是我們使用Sigmoid激活的門來確定輸入和轉換後輸出的比率。
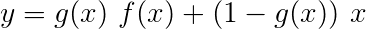
由於字符RNN有助於多個任務,因此使用高速公路網絡來從其輸出中提取特定於任務的信息。
因此,我們將在合併模型的三個位置使用高速公路網絡 -
在天真的共同訓練環境中,我們將角色RNN的輸出直接用於多個任務,即沒有轉換,任務性質之間的不一致可能會損害性能。
到目前為止,我們的組合網絡的外觀可能很清楚。
逐漸刪除網絡的一部分會導致逐漸簡單的網絡,這些網絡被廣泛用於序列標記。
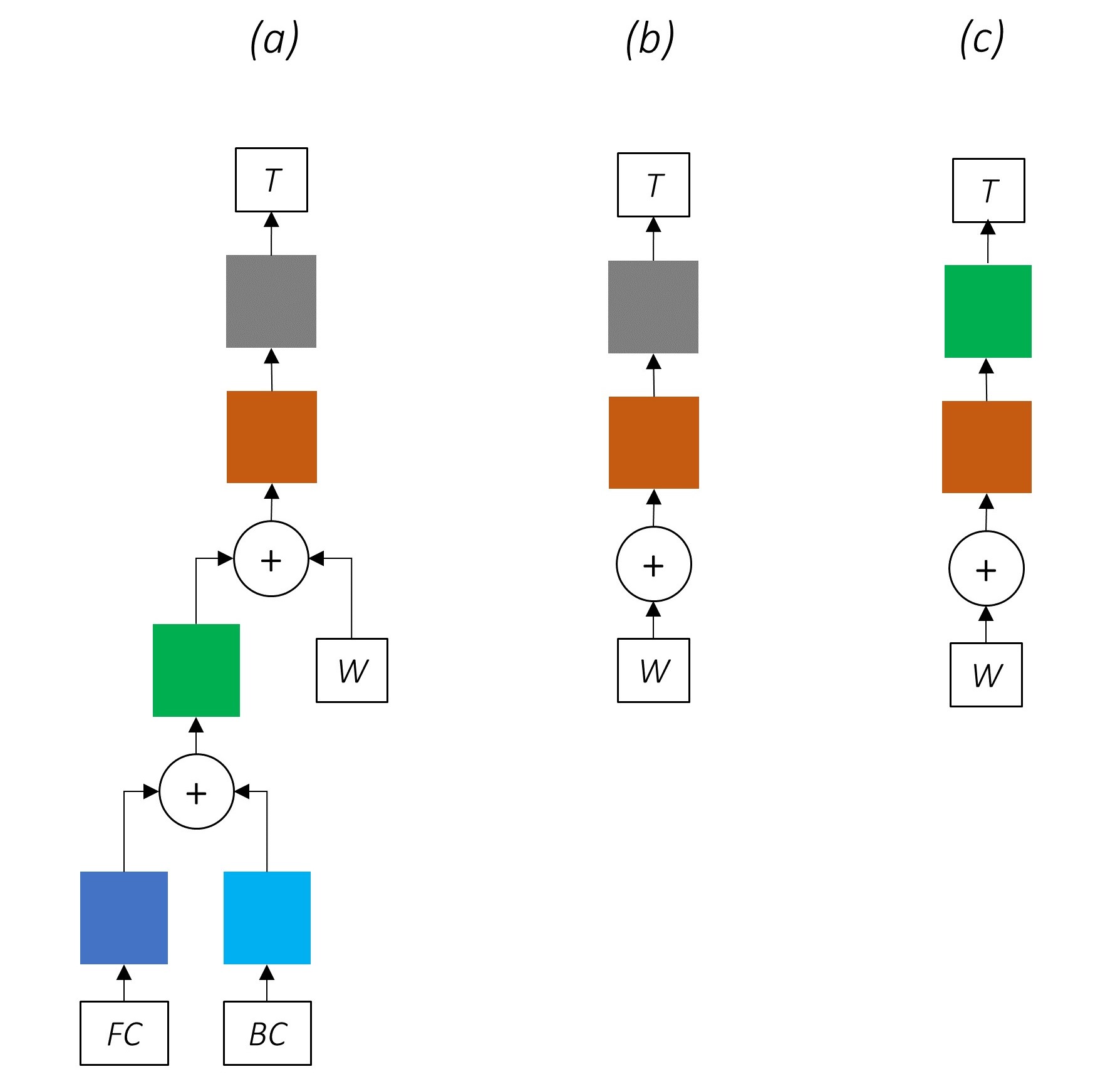
沒有多任務學習。
使用角色級信息而無需共同訓練仍然可以提高性能。
沒有多任務學習或角色級處理。
這種配置通常在行業中使用,並且運行良好。
沒有多任務學習,角色級處理或CRFing。請注意,線性或高速公路層將替換後者。
這可以很好地工作,但是有條件的隨機字段可提高性能。
請記住,我們不使用僅計算發射分數的線性層。交叉熵不是合適的損失度量。
取而代之的是,我們將使用Viterbi損失,就像交叉熵一樣,它是“負模可能性”。但是在這裡,我們將測量黃金(真)標籤序列的可能性,而不是序列中每個單詞的真實標籤的可能性。為了找到可能性,我們在所有標籤序列的得分上考慮了SoftMax。
標籤序列t的得分定義為單個標籤得分的總和。

例如,考慮我們之前查看的CRF分數 -
標籤序列tag_2, tag_3, tag_3, <end> tag的分數是紅色值的總和, 4.85 + 6.79 + 3.85 + 3.52 = 19.01 。
然後將Viterbi損失定義為
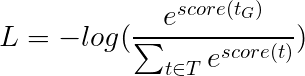
其中t_G是金標籤序列, T表示所有可能的標籤序列的空間。
這簡化為 -
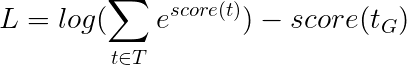
因此,viterbi損失是所有可能的標籤序列的分數的log-sum-exp與金標籤序列的得分,即log-sum-exp(all scores) - gold score 。
Viterbi解碼是一種構建最佳標籤序列的方式,不僅考慮到某個單詞(發射得分)的標籤的可能性,而且考慮到標籤的可能性考慮到上一個和下一個標籤(過渡得分)。
一旦您以L, m, m矩陣生成CRF分數,以一系列長度L的序列L ,我們就開始解碼。
通過一個示例,最好理解Viterbi解碼。再次考慮 -
對於序列中的第一個單詞, previous_tag只能是<start> 。因此,僅考慮一行。
這些也是第一個單詞上每個current_tag的累積分數。
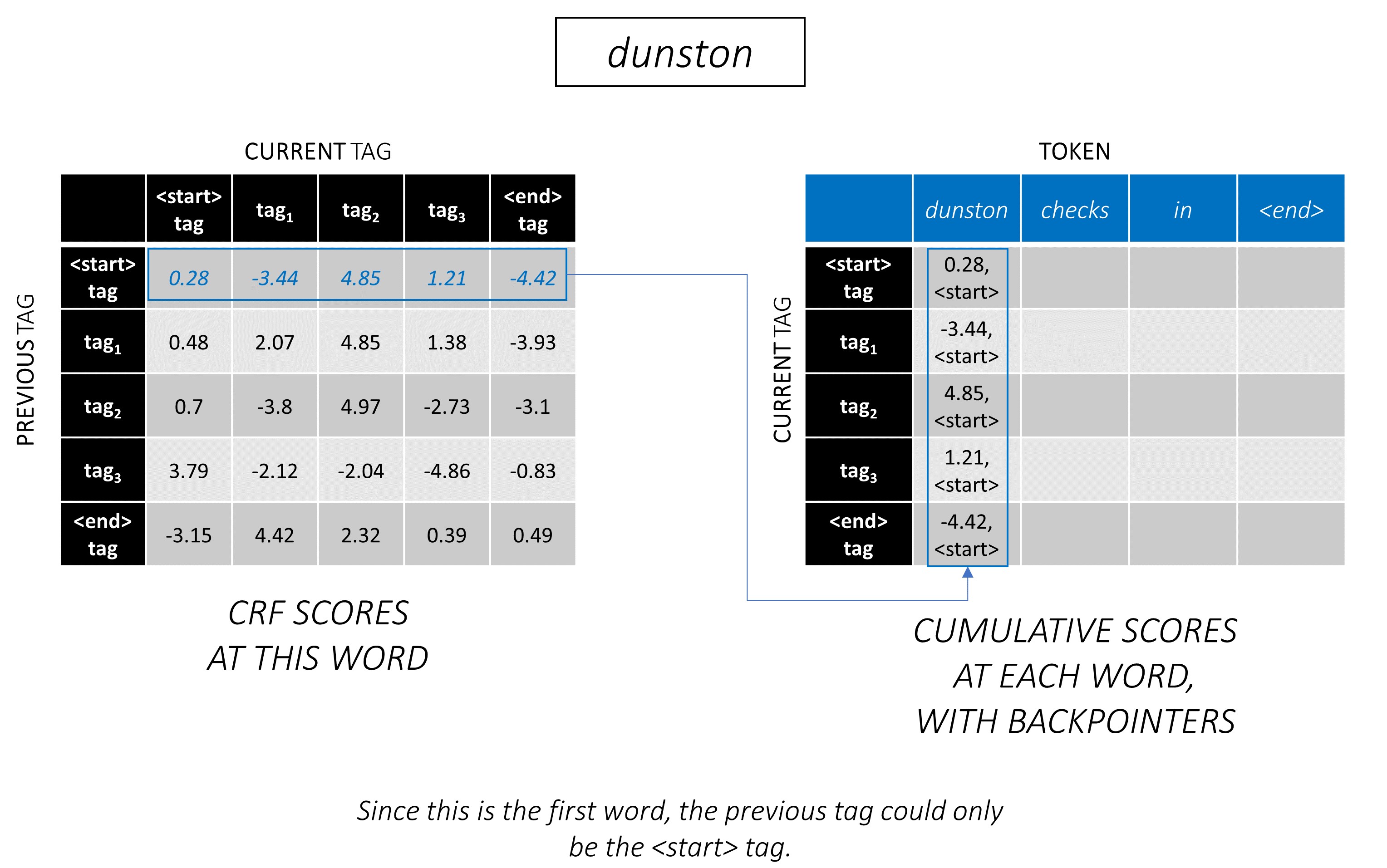
我們還將跟踪與每個分數相對應的previous_tag _tag。這些被稱為反點擊量。在第一個單詞上,它們顯然都是<start>標籤。
在第二個單詞上,將先前的累積分數添加到該單詞的CRF分數中,以生成新的累積分數。
請注意,第一個單詞的current_tag s是第二個單詞的previous_tag s。因此,沿current_tag維度廣播第一個單詞的累積分數。
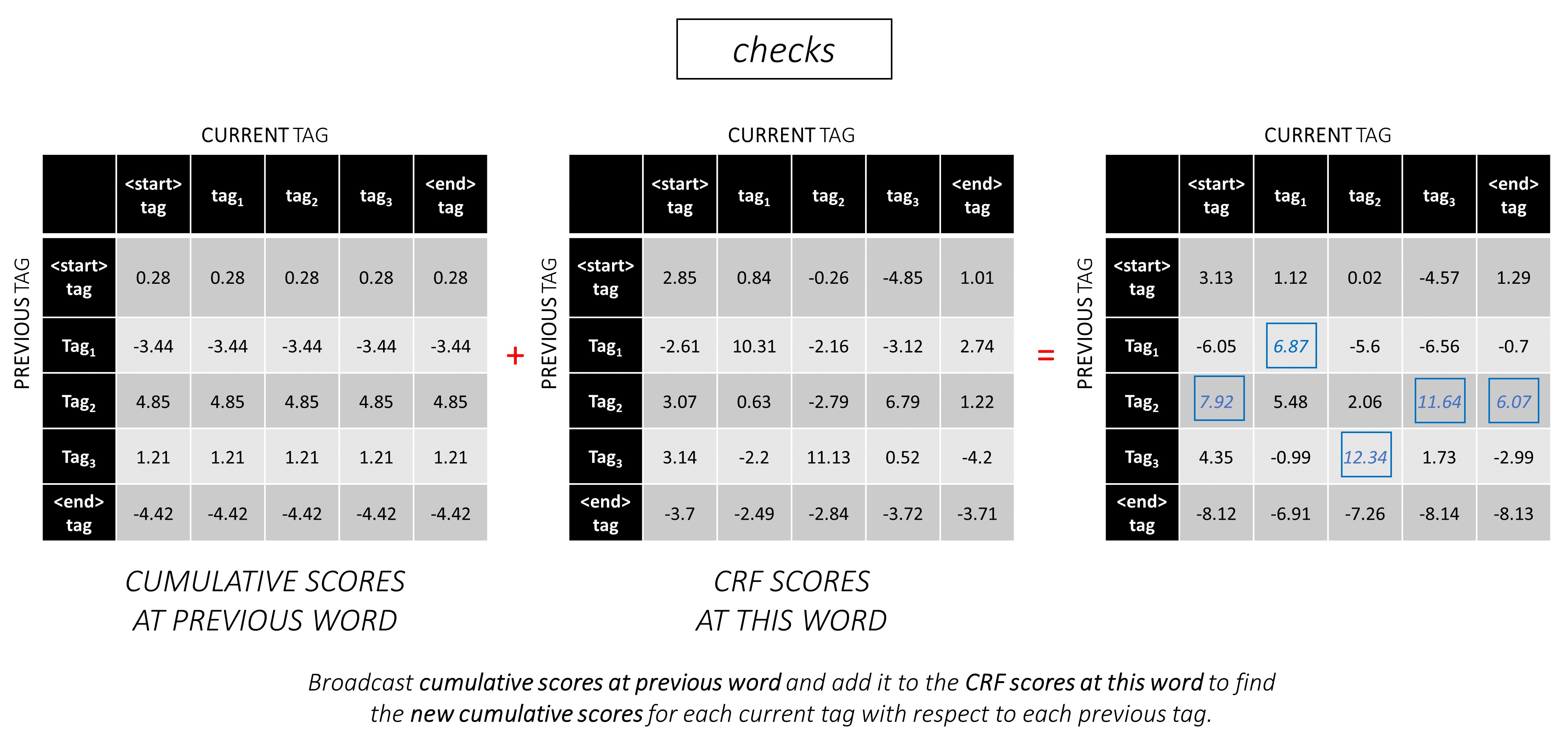
對於每個current_tag ,僅考慮從所有previous_tag s中的得分的最大值。
存儲反點擊量,即與這些最大分數相對應的先前標籤。

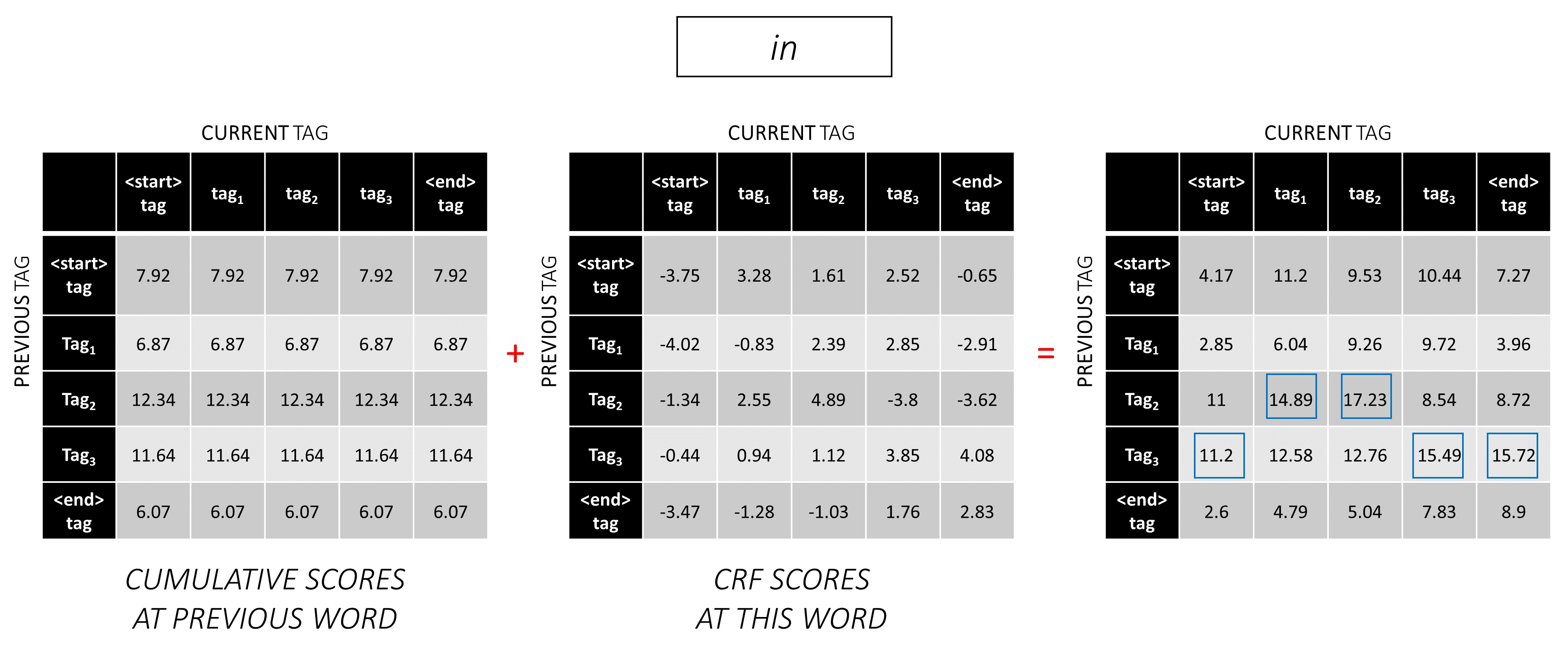
在第三個單詞上重複此過程。
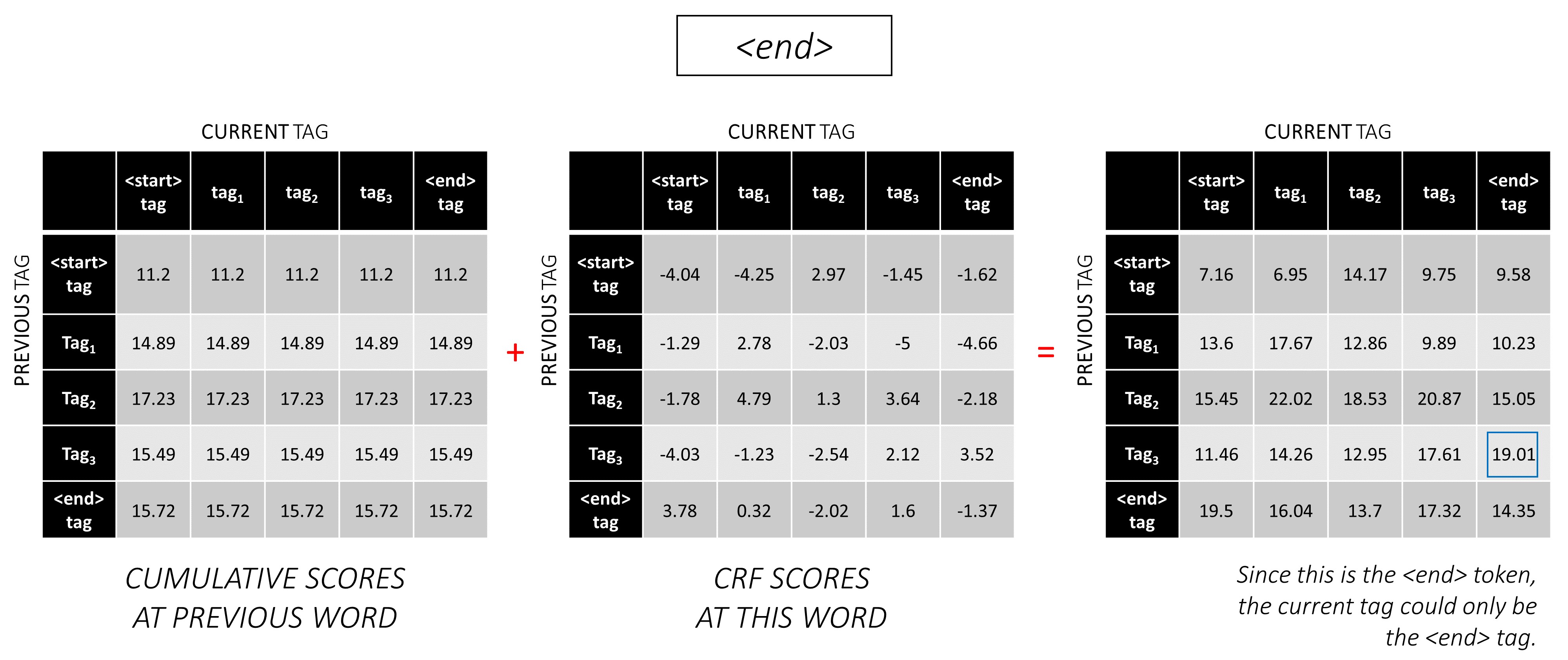
...和最後一個單詞,即<end>令牌。
在這裡,唯一的區別是您已經知道正確的標籤。您僅需要<end>標籤的最高分數和反銷子。
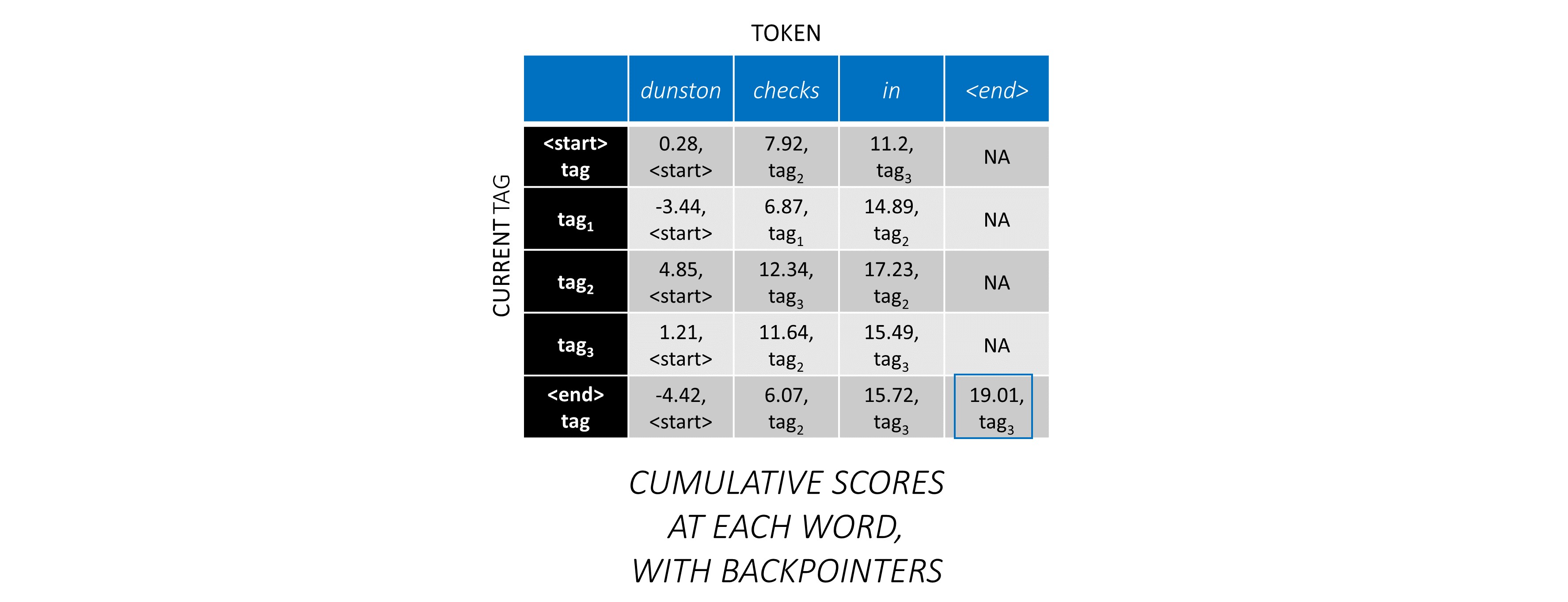
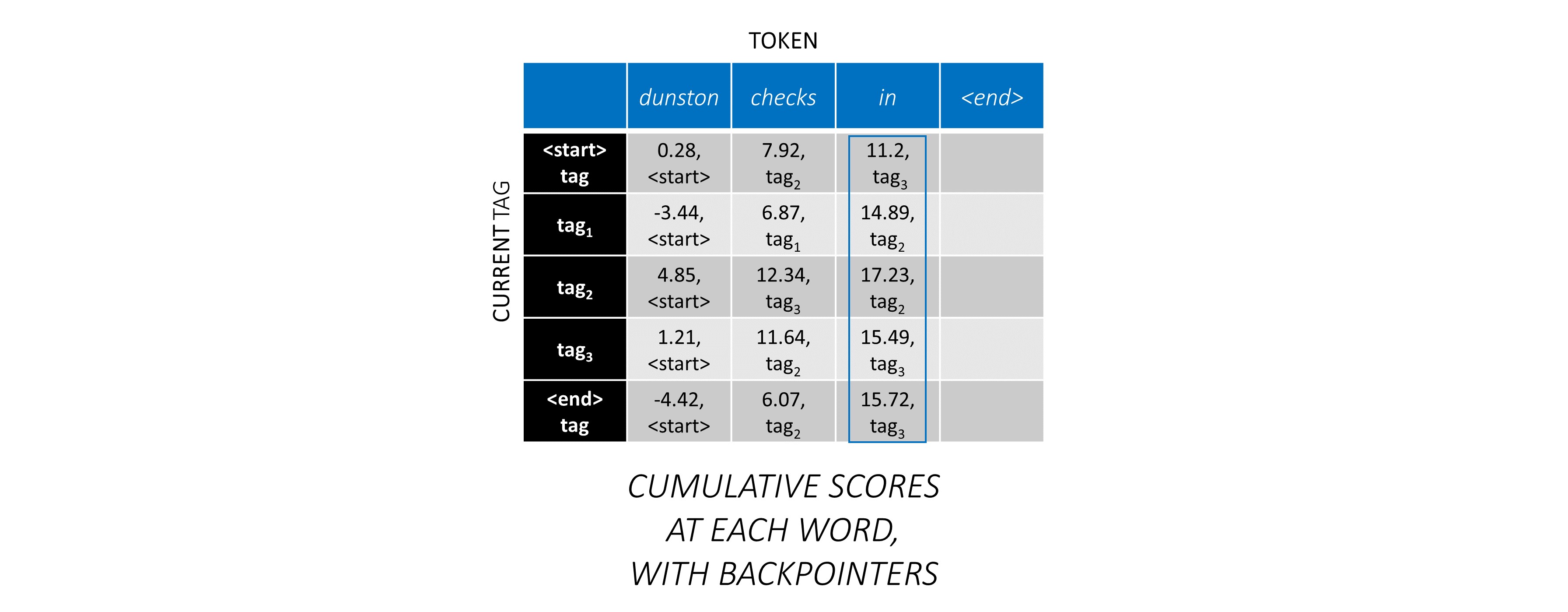
現在,您在整個序列中積累了CRF分數,您可以向後追踪以顯示最高得分的標籤序列。
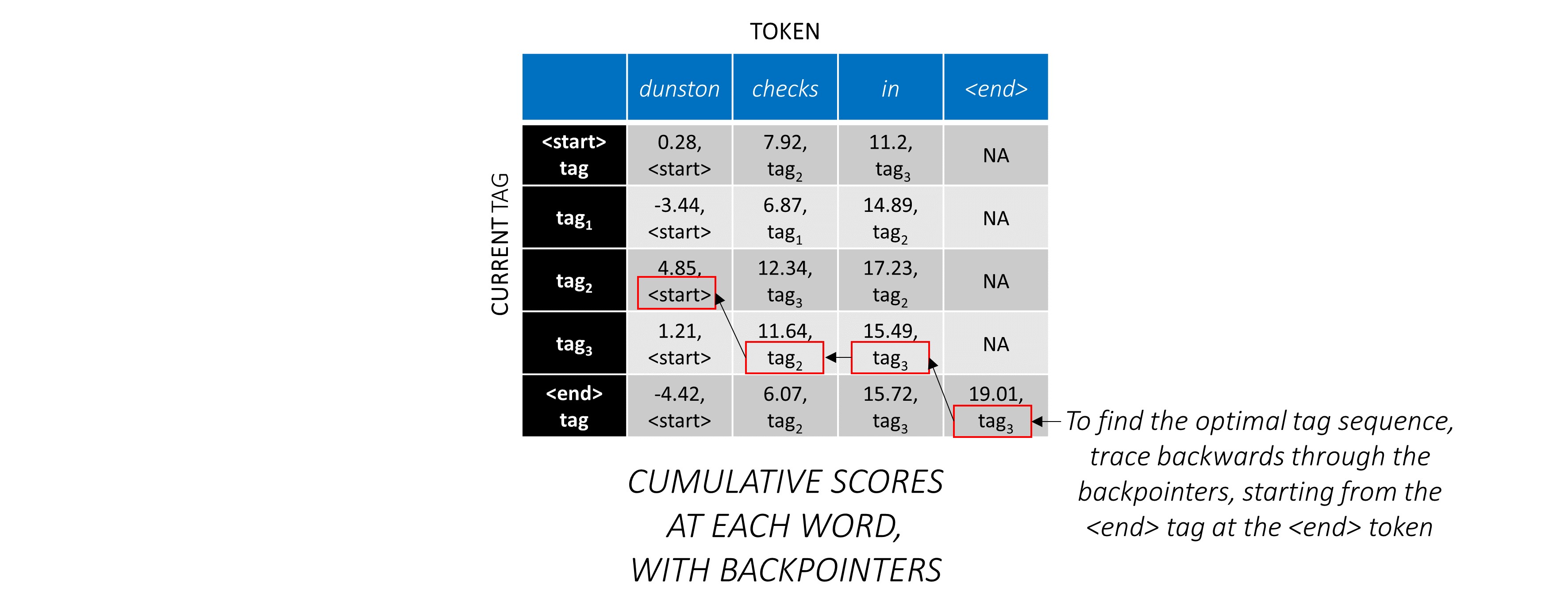
我們發現, dunston checks in <end> IS tag_2 tag_3 tag_3 <end>中Dunston檢查的最佳標籤序列。
以下各節簡要描述了實現。
它們的目的是提供一些背景,但是最好直接從代碼中理解細節,這是非常重大評論的。
我使用Conll 2003 NER數據集將我的結果與論文進行比較。
這是一個片段 -
-DOCSTART- -X- O O
EU NNP I-NP I-ORG
rejects VBZ I-VP O
German JJ I-NP I-MISC
call NN I-NP O
to TO I-VP O
boycott VB I-VP O
British JJ I-NP I-MISC
lamb NN I-NP O
. . O O
儘管您可能會在網上找到該數據集,但該數據集並不是要公開分發的。
在線有幾個公共數據集,您可以用來培訓該模型。這些可能並非全部是100%的註釋,但它們足夠了。
對於NER標記,您可以使用Groningen含義銀行。
對於POS標記,NLTK有一個小數據集,您可以使用nltk.corpus.treebank.tagged_sents()訪問。
您要么必須將其轉換為Conll 2003 NER數據格式,要么修改數據管道部分中引用的代碼。
我們將需要八個輸入。
這些是必須標記的單詞序列。
dunston checks in
如前所述,我們將不使用<start>令牌,但是我們需要使用<end>令牌。
dunston, checks, in, <end>
由於我們將句子作為固定尺寸張量傳遞,因此我們需要使用<pad>令牌將句子(自然的長度變化)添加到相同的長度。
dunston, checks, in, <end>, <pad>, <pad>, <pad>, ...
此外,我們創建一個word_map ,它是語料庫中每個單詞的索引映射,包括<end>和<pad>令牌。與其他庫一樣,Pytorch需要編碼單詞作為索引來查找它們的嵌入,或者在預測的單詞分數中識別其位置。
4381, 448, 185, 4669, 0, 0, 0, ...
因此,饋送到模型的單詞序列必須是尺寸N, L_w的Int張量,其中N是batch_size, L_w是單詞序列的填充長度(通常是最長的單詞序列的長度)。
這些是向前方向的字符序列。
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' '
我們需要字符序列中的<end>令牌,以匹配單詞序列中的<end>令牌。由於我們將在單詞序列中的每個單詞上使用字符級特徵,因此我們在單詞sequence中需要<end>的字符級特徵。
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>
我們還需要墊子。
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>, <pad>, <pad>, <pad>, ...
並用char_map編碼它們。
29, 2, 12, 8, 7, 14, 12, 3, 6, 18, 1, 6, 21, 8, 3, 17, 12, 3, 60, 0, 0, 0, ...
因此,饋送到模型的正向字符序列必須是尺寸N, L_c的Int張量,其中L_c是字符序列的填充長度(通常是最長字符序列的長度)。
這將與前向序列相同,但向後進行處理。 ( <end>令牌仍然自然而然。)
'n', 'i', ' ', 's', 'k', 'c', 'e', 'h', 'c', ' ', 'n', 'o', 't', 's', 'n', 'u', 'd', ' ', <end>, <pad>, <pad>, <pad>, ...
12, 17, 3, 8, 21, 6, 1, 18, 6, 3, 12, 14, 7, 8, 12, 2, 29, 3, 60, 0, 0, 0, ...
因此,饋送到模型的向後字符序列必須是尺寸N, L_c的Int張量。
這些標記是字符序列中的位置,我們將特徵提取到 -
我們將在字符序列和<end>令牌中的每個' '的末端提取特徵。
對於正向字符序列,我們提取 -
7, 14, 17, 18
這些是dunston之後的點, in checks , <end> 。因此,我們為單詞序列中的每個單詞都有一個標記,這很有意義。 (但是,在語言模型中,由於我們正在預測下一個單詞,因此我們不會在標記中預測與<end>相對應的標記。)
我們用0 s墊板。只要它們有效索引,我們都可以使用什麼。 (我們將在墊子上提取功能,但我們不會使用它們。)
7, 14, 17, 18, 0, 0, 0, ...
它們被填充到單詞序列的填充長度L_w 。
因此,饋送到模型的正向字符標記必須是尺寸N, L_w的Int張量。
對於向後字符序列中的標記,我們同樣找到了每個空間的位置' '和<end>令牌。
我們還確保這些位置與前向標記中的單詞順序相同。這種對齊使從前向和向後字符序列提取的連接特徵變得更加容易,並且還可以防止在語言模型中重新訂購目標。
17, 9, 2, 18
這些是notsnud , skcehc , ni , <end>之後的點。
我們用0 s墊。
17, 9, 2, 18, 0, 0, 0, ...
因此,向後饋送到模型的向後字符標記必須是尺寸N, L_w的Int張量。
讓我們假設dunston, checks, in, <end>是 -
tag_2, tag_3, tag_3, <end>
我們有一個tag_map (包含標籤<start> , tag_1 , tag_2 , tag_3 , <end> )。
通常,我們只會直接編碼它們(填充之前) -
2, 3, 3, 5
這些是1D編碼,即1D標籤圖中的標籤位置。
但是CRF層的輸出為2D m, m每個單詞的張量。我們需要在這些2D輸出中編碼標籤位置。
正確的標籤位置標記為紅色。
(0, 2), (2, 3), (3, 3), (3, 4)
如果我們將這些分數展開為1D m*m張量,則在展開的張量中的標籤位置為
tag_map [ previous_tag ] * len ( tag_map ) + tag_map [ current_tag ]因此,我們編碼tag_2, tag_3, tag_3, <end> as
2, 13, 18, 19
請注意,您可以通過模量來檢索原始的tag_map索引
t % len ( tag_map )它們將被填充到單詞序列的填充長度L_w 。
因此,饋送到模型的標籤必須是尺寸N, L_w的Int張量。
這些是單詞序列的實際長度,包括<end>令牌。由於Pytorch支持動態圖,因此我們將僅在這些長度上計算,而不是在<pads>上計算。
因此,饋送到模型的單詞長度必須是尺寸N的Int張量。
這些是字符序列的實際長度,包括<end>令牌。由於Pytorch支持動態圖,因此我們將僅在這些長度上計算,而不是在<pads>上計算。
因此,饋送到模型的字符長度必須是尺寸N的Int張量。
請參閱utils.py中的read_words_tags() 。
這以Conll 2003格式讀取輸入文件,並提取單詞和標籤序列。
請參閱utils.py中的create_maps() 。
在這裡,我們為單詞,字符和標籤創建編碼地圖。我們將稀有的單詞和字符<unk> s(未知)。
請參閱utils.py中的create_input_tensors() 。
我們生成了“模型”部分輸入中詳述的八個輸入。
請參見utils.py中的load_embeddings() 。
我們加載了預訓練的嵌入式,可以選擇將word_map擴展到包含嵌入詞彙中存在的corpus詞。請注意,這也可能包括稀有的詞內單詞,這些<unk>被歸為s之前。
請參閱datasets.py中的WCDataset 。
這是Pytorch Dataset集的子類。它需要定義的__len__方法,該方法返回數據集的大小和__getitem__方法,該方法將八個輸入的i返回到模型。
該Dataset將在train.py中的pytorch DataLoader器使用,以創建和將數據批量饋送到模型中以進行培訓或驗證。
請參閱models.py中的Highway 。
轉換是輸入的恢復激活的線性變換。門是輸入的乙狀體激活線性變換。請注意,這兩種轉換都必須與輸入相同,以允許在殘差連接中添加輸入。
num_layers屬性屬性我們串聯執行多少個轉換網狀遺傳連接操作。通常只有一個就足夠了。
我們將必要數量的變換和門層存儲在單獨的ModuleList() s中,並使用for loop執行連續的操作。
請參閱models.py中的LM_LSTM_CRF 。
從一開始,我們通過降低長度來對前向和向後的字符序列進行分類。為了使LSTM僅計算有效的時間段,即序列的真實長度,就需要使用pack_padded_sequence()來使用Pack_padded_seperence()。
請記住還要按照相同的順序對所有其他張量進行排序。
有關如何使用pack_padded_sequence()的說明,請參見dynamic_rnn.py以利用Pytorch的動態圖形和批處理功能,以便我們不處理墊子。它通過時間到忽略墊子時通過時間步段來平移分類的序列,而LSTM僅在每個時間步上計算有效的批次尺寸N_t 。
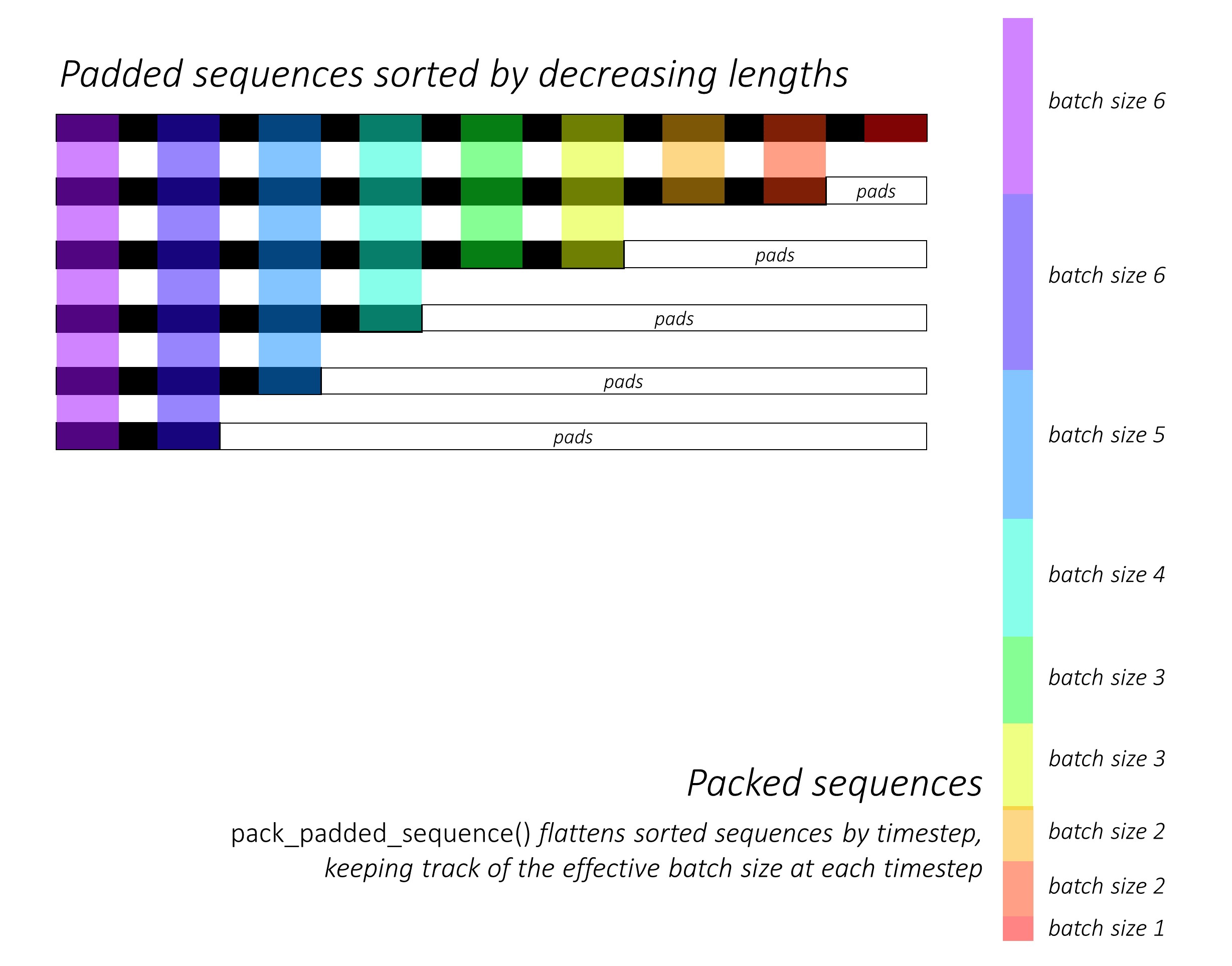
排序允許在任何時間步上的頂部N_t與上一步的輸出對齊。例如,在第三個時間步中,我們僅使用上一步的前5個輸出來處理前5個圖像。除了分類外,所有這些都是由Pytorch內部處理的,但是了解pack_padded_sequence()做什麼仍然非常有用,因此我們可以在其他情況下使用它來實現相似的目的。 (請參閱有關處理常見問題解答部分中的可變長度序列的相關問題。)
排序後,我們分別在前進和向後packed_sequences上應用前向和向後的LSTM 。我們使用pad_packed_sequence()取消貼上輸出並重新填充輸出。
我們僅在gather前方和向後字符標記處提取輸出。此函數對於僅在單獨張量中指定的張量中提取某些索引非常有用。
這些提取的輸出由前向和向後的高速公路層處理,然後應用線性層來計算詞彙上的分數,以預測每個標記處的下一個單詞。我們僅在培訓期間這樣做,因為在驗證或推理期間為多任務學習進行語言建模沒有意義。任何模型的training屬性均由model.train()或model.eval()在train.py中設置。 (請注意,這主要用於在訓練和推理期間分別在Pytorch模型中啟用或禁用輟學和批處理層。)
請參閱models.py中的LM_LSTM_CRF (續)。
我們還通過減小長度來對單詞序列進行排序,因為單詞序列的長度與字符序列之間可能並不總是存在相關性。
請記住還要按照相同的順序對所有其他張量進行排序。
我們在標記處加入前後字符LSTM輸出,並通過第三個高速公路層運行。這將在每個單詞上提取我們將用於序列標籤的每個單詞。
我們將此結果與單詞嵌入式相結合,並在packed_sequence中計算BLSTM輸出。
使用pad_packed_sequence()重新塗片後,我們具有進送到CRF層所需的功能。
請參閱models.py中的CRF 。
考慮到它添加到我們的模型中的值,您可能會發現這一層非常簡單。
線性層用於將輸出從BLSTM轉換為每個標籤的分數,即發射分數。
單個張量用於保持過渡分數。該張量是模型的一個Parameter ,這意味著它在反向傳播過程中可以更新,就像其他層的權重一樣。
要查找CRF分數,請在按照CRF概述中所述進行廣播之後,計算每個單詞的發射分數並將其添加到過渡分數中。
請參閱models.py中的ViterbiLoss 。
我們在Viterbi損失概述中建立了,我們希望最大程度地減少所有可能有效的標籤序列的分數和金牌序列的得分,即IE log-sum-exp(all scores) - gold score之間的差異。
如前所述,我們將每個真實標籤的CRF得分列為計算金評分。
還記得我們如何在展開的CRF分數中編碼標籤序列及其位置嗎?我們使用gather()在這些位置上提取分數,並在求和之前用pack_padded_sequences()消除墊子。
找到所有可能序列的分數的log-sum-exp稍微棘手。我們使用用於循環for時間來迭代時間段。在每個時間步中,我們為每個current_tag積累得分。
previous_tag的每個current_tag的累積分數。我們僅以有效的批量大小進行此操作,即尚未完成的序列。 (我們的序列仍然是通過從LM-LSTM-CRF模型中減小單詞長度來分類的。)current_tag ,在上previous_tag s上計算log-sum-exp,以在每個current_tag處找到新的累積分數。在計算所有序列的可變長度之後,我們將留下張張量N, m ,其中m是(當前)標籤的數量。這些是在每個m標籤中結束的所有可能序列上的log-sum-exp分數。但是,由於有效序列只能以<end>標籤結尾,因此僅在<end>列上匯總以找到所有可能有效序列的分數的log-sum-exp 。
我們發現差異, log-sum-exp(all scores) - gold score 。
請參閱inference.py中的ViterbiDecoder 。
這實現了Viterbi解碼概述中描述的過程。
我們以類似於我們在ViterbiLoss中所做的方式累積的for分數,除非我們找到每個current_tag的上previous_tag得分的最大值,而不是計算log-sum-exp。我們還跟踪與反向量張量中此最大分數相對應的previous_tag 。
我們使用<end>標籤的背對量張量,因為這使我們能夠向後追踪墊子,最終到達實際的<end>標籤,然後開始實際的回溯。
參見train.py 。
模型的參數(和培訓)在文件的開頭,因此您可以在願意的情況下輕鬆檢查或修改它們。
要從頭開始訓練您的模型,只需運行此文件 -
python train.py
要在檢查點恢復培訓,請指向代碼開頭的checkpoint參數的相應文件。
請注意,我們在每個培訓時期結束時執行驗證。
您會注意到,我們將每批的輸入調整為該批次的最大序列長度。這是這樣,我們實際上沒有更多的墊子。
但為什麼?儘管我們的模型中的RNN不會在墊子上計算,但線性層仍然可以。改變這一點是很直接的 - 請參閱有關處理常見問題解答部分中的可變長度序列的相關問題。
在本教程中,我認為在某些墊子上進行了一些額外的計算值得直接的計算,即不必在packed_sequence上執行一系列操作 - 高速公路,CRF,其他線性層,串聯,串聯。
在多任務場景中,我們選擇了兩個語言建模任務中的交叉熵損失以及序列標記任務中的Viterbi損失。
即使我們正在最大程度地減少這些損失的總和,我們實際上只對通過最小化這些損失的總和來最大程度地減少Viterbi損失感興趣。 Viterbi損失反映了主要任務的性能。
我們使用pack_padded_sequence()在必要時消除墊子。
像論文中一樣,我們將宏觀平均的F1得分作為早期漫步的標準。自然,計算F1分數需要Viterbi解碼CRF分數以生成我們的最佳標籤序列。
我們使用pack_padded_sequence()在必要時消除墊子。
我盡可能地遵循作者實現中的參數。
我使用了10句子的批次大小。我用動量使用隨機梯度下降。每個時代都腐爛了學習率。我在沒有微調的情況下使用了100D手套預處理的嵌入。
在泰坦X(Pascal)上訓練一個時代大約花了大約80年代。
驗證集的F1分數在50時期左右達到91% ,在171時期達到91.6%的峰值。這非常接近論文中的結果。
您可以在此處下載此驗證的模型。
我們如何決定使用序列的模型是否需要<start>和<end>令牌?
如果一開始似乎令人困惑,那麼當您考慮計劃訓練的模型的要求時,它將很容易解決。
對於使用CRF標記的序列標記,您需要<end>令牌(或<start>令牌;請參見下一個問題),因為CRF分數的結構如何。
在我的圖像字幕上的另一個教程中,我同時使用了<start>和<end>令牌。該模型需要開始在某個地方解碼,並學會識別何時在推理過程中停止解碼。
如果您執行文本分類,則無需。
我們可以讓CRF生成current_word -> next_word分數,而不是上previous_word -> current_word分數嗎?
是的。在這種情況下,您將播放諸如L, m, _類的排放分數,並且您將在每個句子中都有一個<start>令牌,而不是<end>令牌。 <start>令牌的正確標籤始終是<start>標籤。最後一個單詞的“下一個標籤”始終是<end>標籤。
我認為previous word -> current word慣例稍好一些,因為混音中有語言模型。能夠在最後一個真實的單詞上預測<end>令牌,因此學會識別句子何時完成。
為什麼我們為序列標記器的輸入和語言模型的輸出使用不同的詞彙?
語言模型將學會僅預測培訓期間看到的那些單詞。使用線性柔軟的層和額外的約400,000個嵌入式文件中的額外的單詞,這確實是不必要的,並且浪費了計算和內存,這是不必要的。
但是,即使模型在訓練過程中永遠不會看到它們,我們也可以將這些單詞添加到輸入層中。這是因為我們在輸入處使用了預訓練的嵌入。它不需要看到它們,因為單詞的含義是在這些向量中編碼的。如果以前遇到過chimpanzee ,很可能知道該如何處理orangutan 。
微調我們在此模型中使用的預訓練的單詞嵌入是一個好主意嗎?
我避免了微調,因為大多數輸入詞彙不是內部的。大多數嵌入將保持不變,而一些嵌入方式進行了微調。 If fine-tuning changes these embeddings sufficiently, the model may not work well with the words that weren't fine-tuned. In the real world, we're bound to encounter many words that weren't present in a newspaper corpus from 2003.
What are some ways we can construct dynamic graphs in PyTorch to compute over only the true lengths of sequences?
If you're using an RNN, simply use pack_padded_sequence() . PyTorch will internally compute over only the true lengths. See dynamic_rnn.py for an example.
If you want to execute an operation (like a linear transformation) only on the true timesteps, pack_padded_sequences() is still the way to go. This flattens the tensor by timestep while removing the pads. You can perform your operation on this flattened tensor, and then use pad_packed_sequence() to unflatten it and re-pad it with 0 s.
Similarly, if you want to perform an aggregation operation, like computing the loss, use pack_padded_sequences() to eliminate the pads.
If you want to perform timestep-wise operations, you can take a leaf out of how pack_padded_sequences() works, and compute only on the effective batch size at each timestep with a for loop to iterate over the timesteps. We did this in the ViterbiLoss and ViterbiDecoder . I also used an LSTMCell() in this fashion in my image captioning tutorial.
Dunston Checks In ?真的嗎?
I had no memory of this movie for twenty years. I was trying to think of a short sentence that would be easier to visualize in this tutorial and it just popped into my mind riding a wave of 90s nostalgia.

I wish I hadn't googled it though. Damn, the critics were harsh, weren't they? This gem was overwhelmingly and universally panned. I'm not sure I'd disagree if I watched it now, but that just goes to show the world is so much more fun when you're a kid.
Didn't have to worry about LM-LSTM-CRFs or nuthin...


