a PyTorch Tutorial to Sequence Labeling
1.0.0
Dies ist ein Pytorch -Tutorial zur Sequenzmarkierung .
Dies ist der zweite in einer Reihe von Tutorials, die ich über die Implementierung von coolen Modellen mit der erstaunlichen Pytorch -Bibliothek selbst schreibe.
Grundkenntnisse über Pytorch, wiederkehrende neuronale Netze werden angenommen.
Wenn Sie neu in Pytorch sind, lesen Sie zuerst Deep Learning mit Pytorch: A 60 -minütiges Blitz und Lernen von Pytorch mit Beispielen.
Fragen, Vorschläge oder Korrekturen können als Probleme veröffentlicht werden.
Ich verwende PyTorch 0.4 in Python 3.6 .
27. Januar 2020 : Der Arbeitscode für zwei neue Tutorials wurde hinzugefügt-Superauflösung und maschinelle Übersetzung
Objektiv
Konzepte
Überblick
Durchführung
Ausbildung
Häufig gestellte Fragen
Um ein Modell zu erstellen, das jedes Wort in einem Satz mit Entitäten, Teilen der Sprache usw. markieren kann, usw.

Wir werden die Empower-Sequenz-Kennzeichnung mit aufgabenbewusster neuronaler Sprachmodellpapier implementieren. Dies ist fortgeschrittener als die meisten Sequenz -Tagging -Modelle, aber Sie werden viele nützliche Konzepte lernen - und es funktioniert sehr gut. Die ursprüngliche Implementierung der Autoren finden Sie hier.
Dieses Modell ist etwas Besonderes, da es die Aufgabe der Sequenzmarkierung durch das Training mit Sprachmodellen erhöht.
Sequenzmarkierung . Duh.
Sprachmodelle . Die Sprachmodellierung besteht darin, das nächste Wort oder Zeichen in einer Abfolge von Wörtern oder Zeichen vorherzusagen. Neuronale Sprachmodelle erzielen beeindruckende Ergebnisse in einer Vielzahl von NLP -Aufgaben wie Textgenerierung, maschineller Übersetzung, Bildunterschrift, optischer Charaktererkennung und was Sie haben.
Charakter RNNs . Es ist bekannt, dass RNNs, die auf einzelnen Zeichen in einem Text arbeiten, den zugrunde liegenden Stil und die zugrunde liegende Struktur erfassen. In einer Sequenz-Kennzeichnungsaufgabe sind sie besonders nützlich, da Unterwortinformationen häufig wichtige Hinweise auf eine Entität oder ein Tag liefern können.
Multi-Task-Lernen . Datensätze, die zum Training eines Modells verfügbar sind, sind oft klein. Das Erstellen von Annotationen oder handgefertigten Funktionen, die Ihr Modell dabei unterstützen, ist nicht nur umständlich, sondern auch häufig nicht an die verschiedenen Domänen oder Einstellungen, in denen Ihr Modell nützlich sein kann. Die Sequenzmarkierung ist leider ein Paradebeispiel. Es gibt eine Möglichkeit, dieses Problem zu mildern. Das gemeinsame Training mehrerer Modelle, die an der Hüfte verbunden sind, maximiert die für jedes Modell verfügbaren Informationen und verbessert die Leistung.
Bedingte Zufallsfelder . Diskrete Klassifizierer sagen eine Klasse oder ein Etikett für ein Wort vor. Bedingte Zufallsfelder (CRFs) können Sie besser machen - sie prognostizieren Etiketten nicht nur auf dem Wort, sondern auch auf der Nachbarschaft. Was sinnvoll ist, weil es Muster in einer Abfolge von Entitäten oder Etiketten gibt . CRFs werden häufig verwendet, um geordnete Informationen zu modellieren, sei es für die Sequenzmarkierung, die Gensequenzierung oder sogar die Objekterkennung und die Bildsegmentierung im Computer Vision.
Viterbi -Dekodierung . Da wir CRFs verwenden, werden wir bei jedem Wort nicht so sehr das richtige Etikett vorhersagen, da wir die richtige Label -Sequenz für eine Wortsequenz vorhersagen. Viterbi -Dekodierung ist eine Möglichkeit, genau dies zu tun - die optimalste Tag -Sequenz aus den von einem bedingten Zufallsfeld berechneten Bewertungen zu finden.
Autobahnnetzwerke . Vollständige Schichten sind in jedem neuronalen Netzwerk ein Grundnahrungsmittel, um Merkmale an verschiedenen Stellen zu transformieren oder zu extrahieren. Autobahnnetzwerke ermöglichen dies, ermöglichen jedoch auch, dass Informationen über Transformationen hinweg ungehindert fließen. Dies macht tiefe Netzwerke viel effizienter oder machbarer.
In diesem Abschnitt werde ich einen Überblick über dieses Modell geben. Wenn Sie bereits vertraut sind, können Sie direkt zum Implementierungsabschnitt oder zum Kommentarcode überspringen.
Die Autoren bezeichnen das Modell als Sprachmodell - langfristiges Kurzzeitgedächtnis - bedingte Zufallsfeld, da es sich um Co -Training -Sprachmodelle mit einer LSTM + CRF -Kombination handelt.
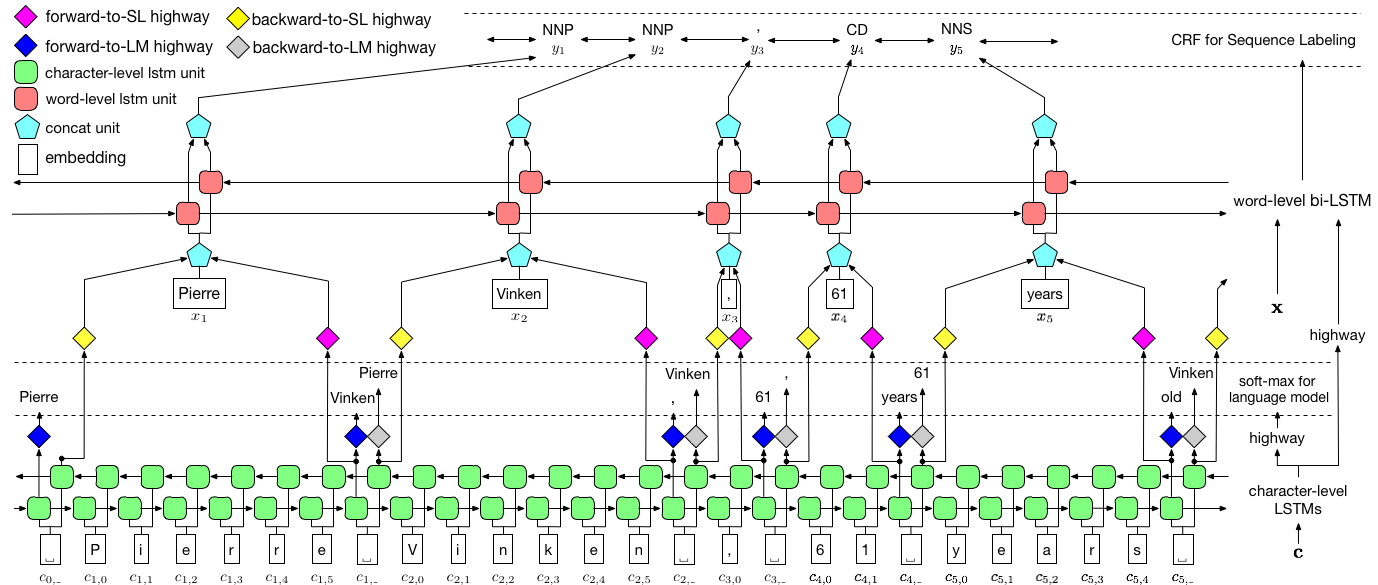
Dieses Bild aus dem Papier repräsentiert gründlich das gesamte Modell, aber mach dir keine Sorgen, wenn es zu diesem Zeitpunkt zu komplex erscheint. Wir werden es zerlegen, um die Komponenten genauer zu betrachten.
Das Lernen von Multitaskieren ist, wenn Sie gleichzeitig ein Modell für zwei oder mehr Aufgaben trainieren.
Normalerweise interessieren wir uns nur für eine dieser Aufgaben - in diesem Fall die Sequenzmarkierung.
Aber wenn Schichten in einem neuronalen Netzwerk dazu beitragen, mehrere Funktionen auszuführen, lernen sie mehr als sie, wenn sie nur über die Hauptaufgabe trainiert hätten. Dies liegt daran, dass die in jeder Schicht extrahierten Informationen erweitert werden, um alle Aufgaben zu erfassen. Wenn weitere Informationen zu arbeiten sind, wird die Leistung der Hauptaufgabe verbessert .
Die Anreicherung vorhandener Funktionen auf diese Weise beseitigt die Notwendigkeit, handgefertigte Funktionen für die Sequenzmarkierung zu verwenden.
Der Gesamtverlust während des Lernens von mehreren Aufgaben ist normalerweise eine lineare Kombination der Verluste bei den einzelnen Aufgaben. Die Parameter der Kombination können als aktualisierbare Gewichte behoben oder gelernt werden.

Da wir individuelle Verluste aggregieren, können Sie sehen, wie vorgelagerte Ebenen, die durch mehrere Aufgaben geteilt werden, während der Rückpropagation Aktualisierungen von allen erhalten.
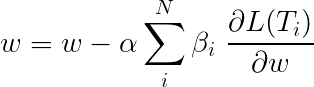
Die Autoren des Papiers fügen einfach die Verluste hinzu ( β=1 ), und wir werden dasselbe tun.
Schauen wir uns die Aufgaben an, die unser Modell ausmachen.
Es gibt drei .

Dies nutzt die Unterwortinformationen, um das nächste Wort vorherzusagen.
Wir tun das Gleiche in rückwärts gerichteter Richtung. 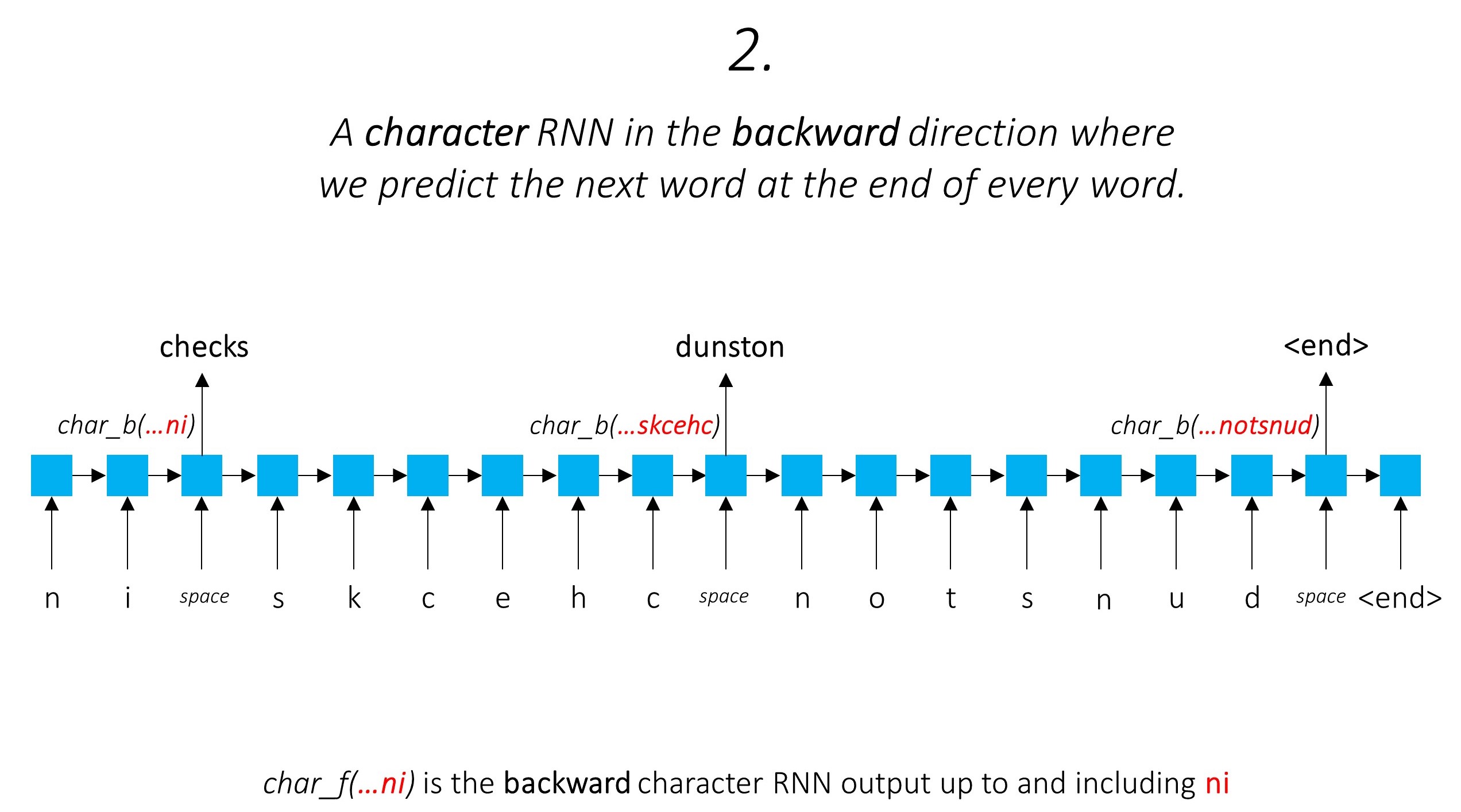
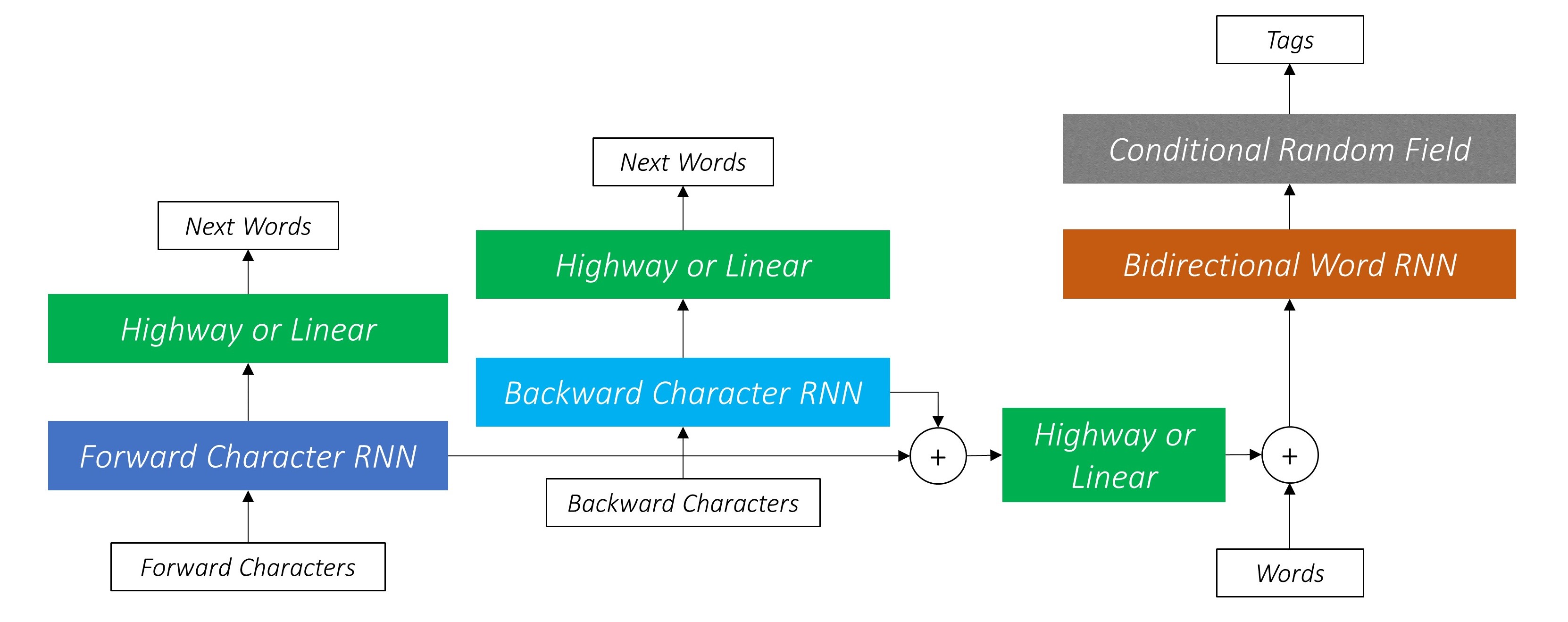
Wir verwenden auch die Ausgänge dieser beiden Charakter-RNNs als Eingaben für unser Word-RNN und Conditional Random Field (CRF), um unsere primäre Aufgabe der Sequenzmarkierung durchzuführen. 
Wir verwenden Sub-Word-Informationen in unserer Tagging-Aufgabe, da dies ein leistungsstarker Indikator für die Tags sein kann, unabhängig davon, ob es sich um Teile von Sprache oder Entitäten handelt. Zum Beispiel kann es lernen, dass Adjektive üblicherweise mit "-y" oder "-ul" enden oder dass Orte oft mit "Land" oder "-burg" enden.
Aber unsere Unterwortmerkmale, nämlich. Die Ausgänge der Charakter -RNNs sind auch mit zusätzlichen Informationen angereichert - das Wissen, das es benötigt, um das nächste Wort sowohl in Vorwärts- als auch in Rückwärtsrichtungen vorhersagen, aufgrund der Modelle 1 und 2.
Daher verwendet unser Sequenz -Tagging -Modell beide
Das bidirektionale LSTM/RNN codiert diese Merkmale in jedem Wort, das Informationen über das Wort und seine Nachbarschaft enthält, sowohl auf der Wortebene als auch auf der Charakterebene. Dies bildet die Eingabe zum bedingten Zufallsfeld.
Ohne CRF hätten wir einfach eine einzelne lineare Schicht verwendet, um die Ausgabe des bidirektionalen LSTM für jedes Tag in die Punktzahlen zu verwandeln. Diese sind als Emissionswerte bekannt, die eine Darstellung der Wahrscheinlichkeit darstellen, dass das Wort ein bestimmtes Tag ist.
Ein CRF berechnet nicht nur die Emissionswerte, sondern auch die Übergangswerte , die die Wahrscheinlichkeit eines Wortes sind, ein bestimmtes Tag zu sein, wenn man bedenkt, dass das vorherige Wort ein bestimmtes Tag war. Daher messen die Übergangsbewertungen, wie wahrscheinlich es ist, dass er von einem Tag zum anderen übergeht.
Wenn es m -Tags gibt, werden die Übergangsbewertungen in einer Matrix von Dimsions m, m , gespeichert, wobei die Zeilen das Tag des vorherigen Wortes und die Spalten das Tag des aktuellen Wortes darstellen. Ein Wert in dieser Matrix an Position i, j ist die Wahrscheinlichkeit, vom i -th -Tag am vorherigen Wort zum j -Tag -Tag des aktuellen Wortes zu wechseln . Im Gegensatz zu Emissionswerten werden die Übergangswerte für jedes Wort im Satz nicht definiert. Sie sind global.
In unserem Modell gibt die CRF -Schicht das Aggregat der Emissions- und Übergangswerte bei jedem Wort aus.
Für einen Satz der Länge L wären Emissionswerte ein L, m -Tensor. Da die Emissionswerte bei jedem Wort nicht vom Tag des vorherigen Wortes abhängen, erstellen wir eine neue Dimension wie L, _, m und senden den Tensor entlang dieser Richtung, um einen L, m, m -Tensor zu erhalten.
Die Übergangswerte sind ein m, m -Tensor. Da die Übergangswerte global sind und nicht vom Wort abhängen, erstellen wir eine neue Dimension wie _, m, m und Sendung (kopieren) den Tensor entlang dieser Richtung, um einen L, m, m -Tensor zu erhalten.
Wir können sie jetzt hinzufügen, um die Gesamtwerte zu erhalten, die ein L, m, m -Tensor sind . Ein Wert an Position k, i, j ist das Aggregat des Emissionswerts des j -Th -Tags am k k -Wort und die Übergangsbewertung des j i
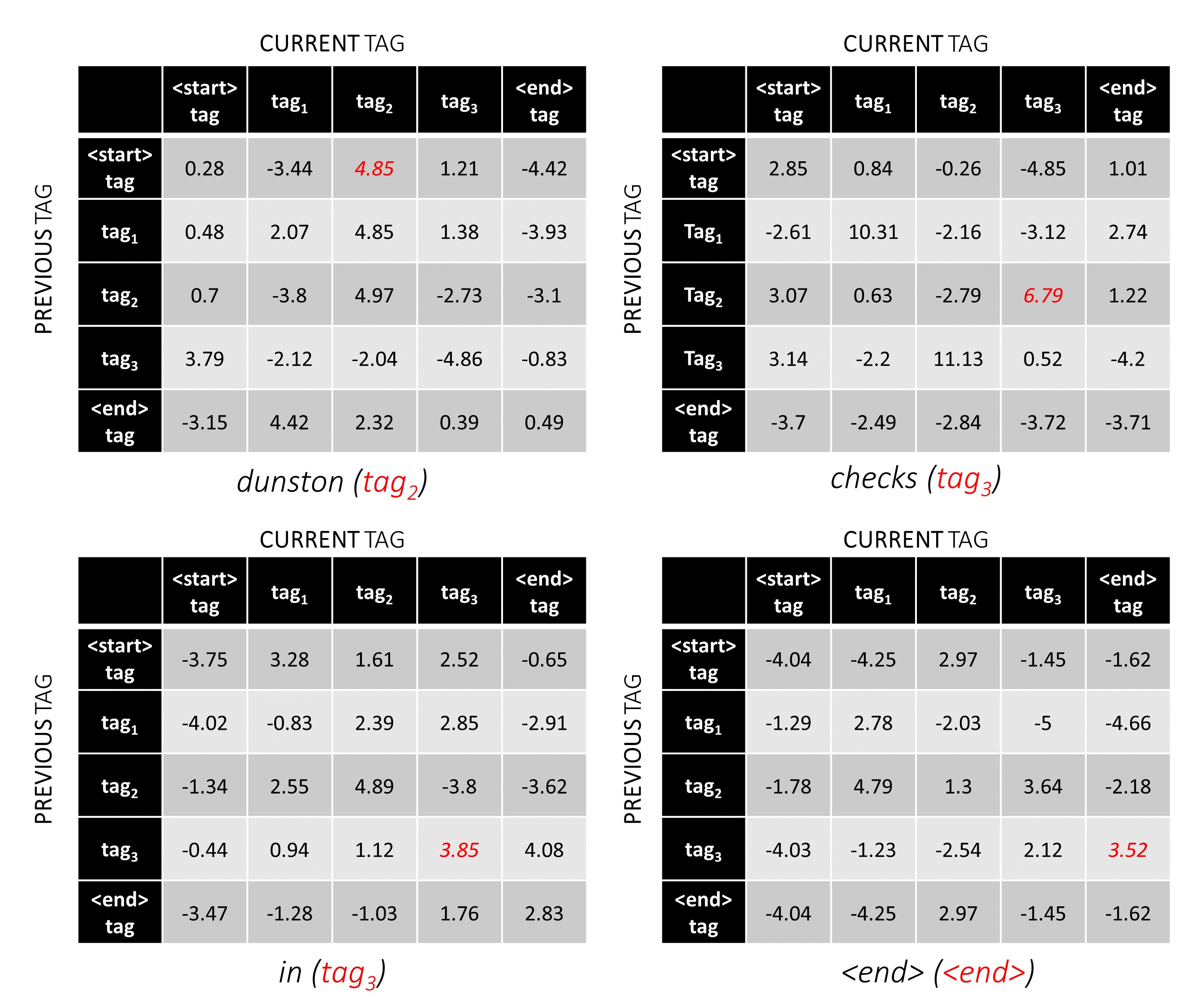
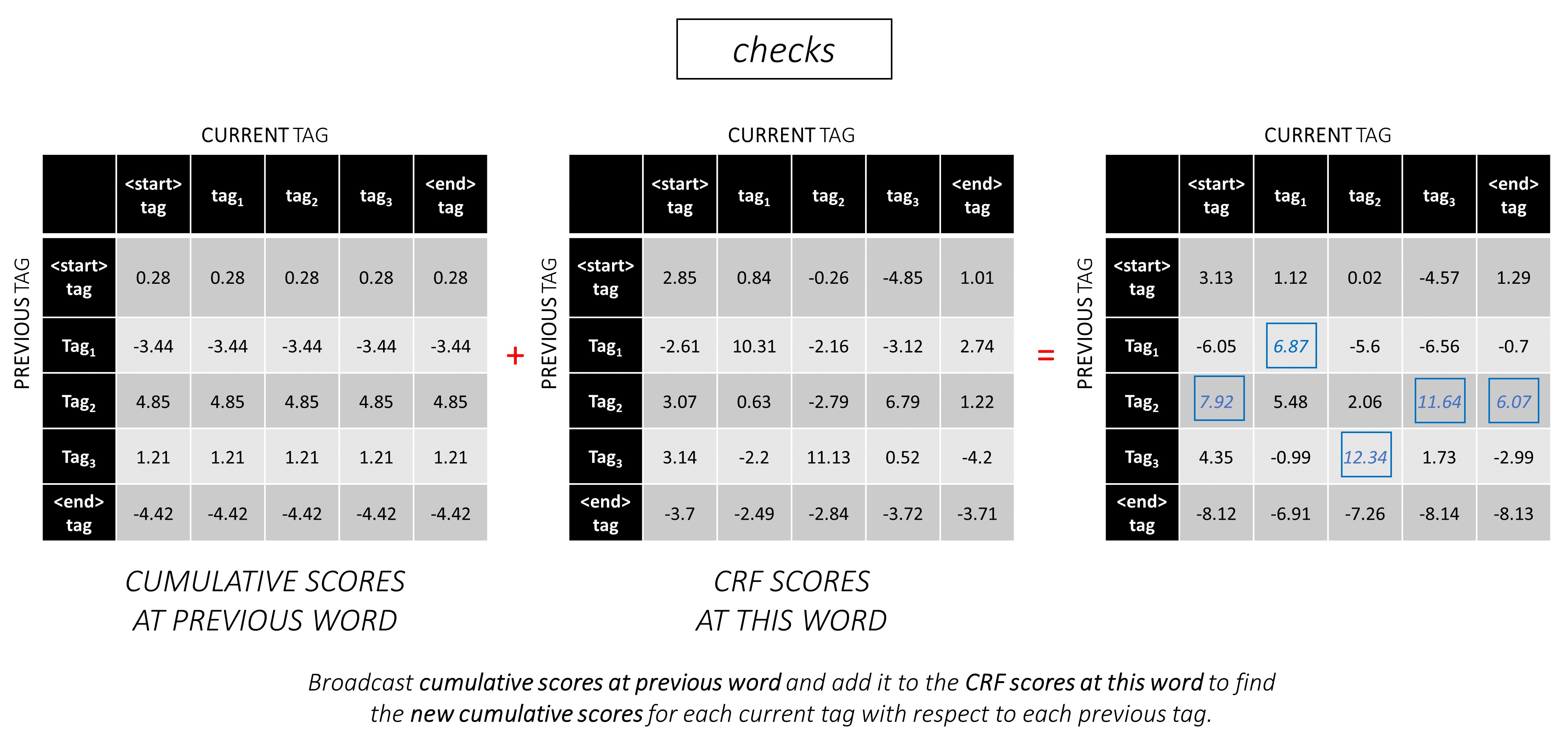
In unserem Beispiel -Satz dunston checks in <end> , wenn wir davon ausgehen, dass es insgesamt 5 Tags gibt, würden die Gesamtwerte so aussehen -
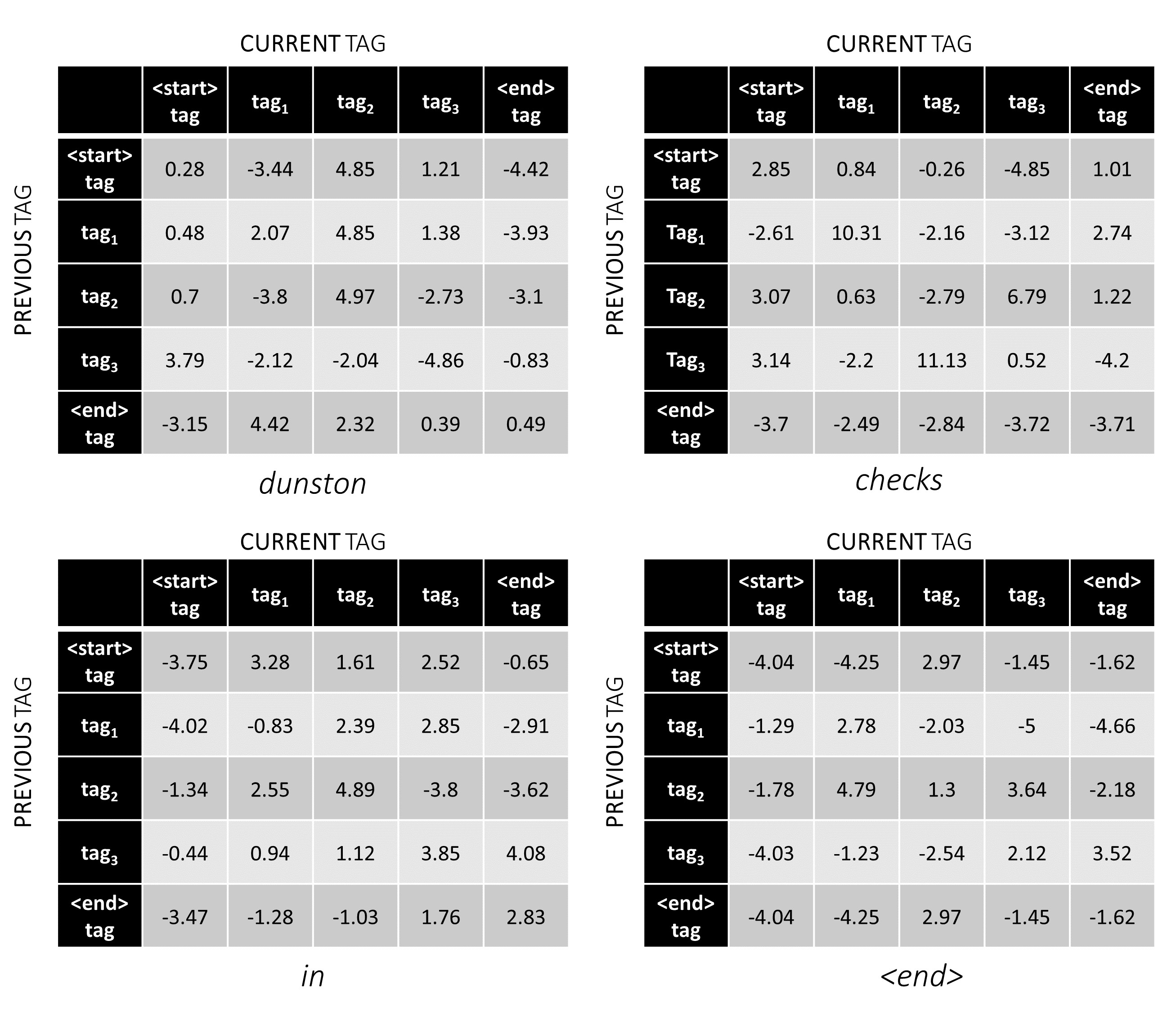
Aber warte eine Minute, warum gibt es <start> Ende <end> Tags? Warum verwenden wir ein <end> Token, während wir dabei sind?
<start> und <end> Tags, <start> und <end> Tokens Da wir die Wahrscheinlichkeit eines Übergangs zwischen Tags modellieren, fügen wir auch ein <start> -Tag und ein <end> -Tag in unser Tag-Set ein.
Die Übergangsbewertung eines bestimmten Tags, da das vorherige Tag ein <start> -Tag ausgeht, repräsentiert die Wahrscheinlichkeit, dass dieses Tag das erste Tag in einem Satz ist . Beispielsweise beginnen Sätze normalerweise mit Artikeln (a, an) oder Substantiven oder Pronomen.
Die Übergangsbewertung des <end> -Tags unter Berücksichtigung eines bestimmten vorherigen Tags gibt an, dass die Wahrscheinlichkeit, dass dieses vorherige Tag das letzte Tag in einem Satz ist .
Wir werden in allen Sätzen ein <end> -Token und nicht in einem <start> -Token verwenden, da die Gesamt -CRF -Bewertungen bei jedem Wort in Bezug auf das vorherige Word -Tag definiert sind, was bei einem <start> -Token keinen Sinn ergibt.
Das richtige Tag des <end> -Tokens ist immer das <end> -Tag. Das "vorherige Tag" des ersten Wortes ist immer das <start> -Tag.
Um zu veranschaulichen, dass in unserem Beispiel -Satz dunston checks in <end> die Tags tag_2, tag_3, tag_3, <end> hatte, geben die Werte in Rot die Bewertungen dieser Tags an.
Wir verwenden im Allgemeinen aktivierte lineare Schichten, um Ausgänge eines RNN/LSTM zu transformieren und zu verarbeiten.
Wenn Sie mit verbleibenden Verbindungen vertraut sind, können wir die Eingabe vor der Transformation zur transformierten Ausgabe hinzufügen und einen Pfad für den Datenfluss um die Transformation erstellen.
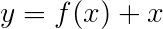
Dieser Pfad ist eine Abkürzung für den Gradientenfluss während der Backpropagation und hilft bei der Konvergenz von tiefen Netzwerken.
Ein Autobahnnetz ähnelt einem Restnetzwerk, aber wir verwenden ein Sigmoid-aktiviertes Gate, um das Verhältnis zu bestimmen, in dem die Eingabe und der transformierte Ausgang kombiniert werden .
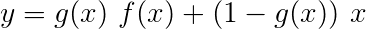
Da die Character-RNNs zu mehreren Aufgaben beitragen, werden Autobahnnetzwerke zum Extrahieren von aufgabenspezifischen Informationen aus ihren Ausgaben verwendet .
Daher werden wir Autobahnnetzwerke an drei Standorten in unserem kombinierten Modell verwenden -
In einer naiven Co-Training-Umgebung, in der wir die Ausgänge der Charakter-RNNs direkt für mehrere Aufgaben verwenden, könnte die Diskordanz zwischen der Natur der Aufgaben die Leistung beeinträchtigen.
Es könnte inzwischen klar sein, wie unser kombiniertes Netzwerk aussieht.
Das zunehmende Entfernen von Teilen unseres Netzwerks führt zu zunehmend einfacheren Netzwerken, die häufig zur Sequenzmarkierung verwendet werden.
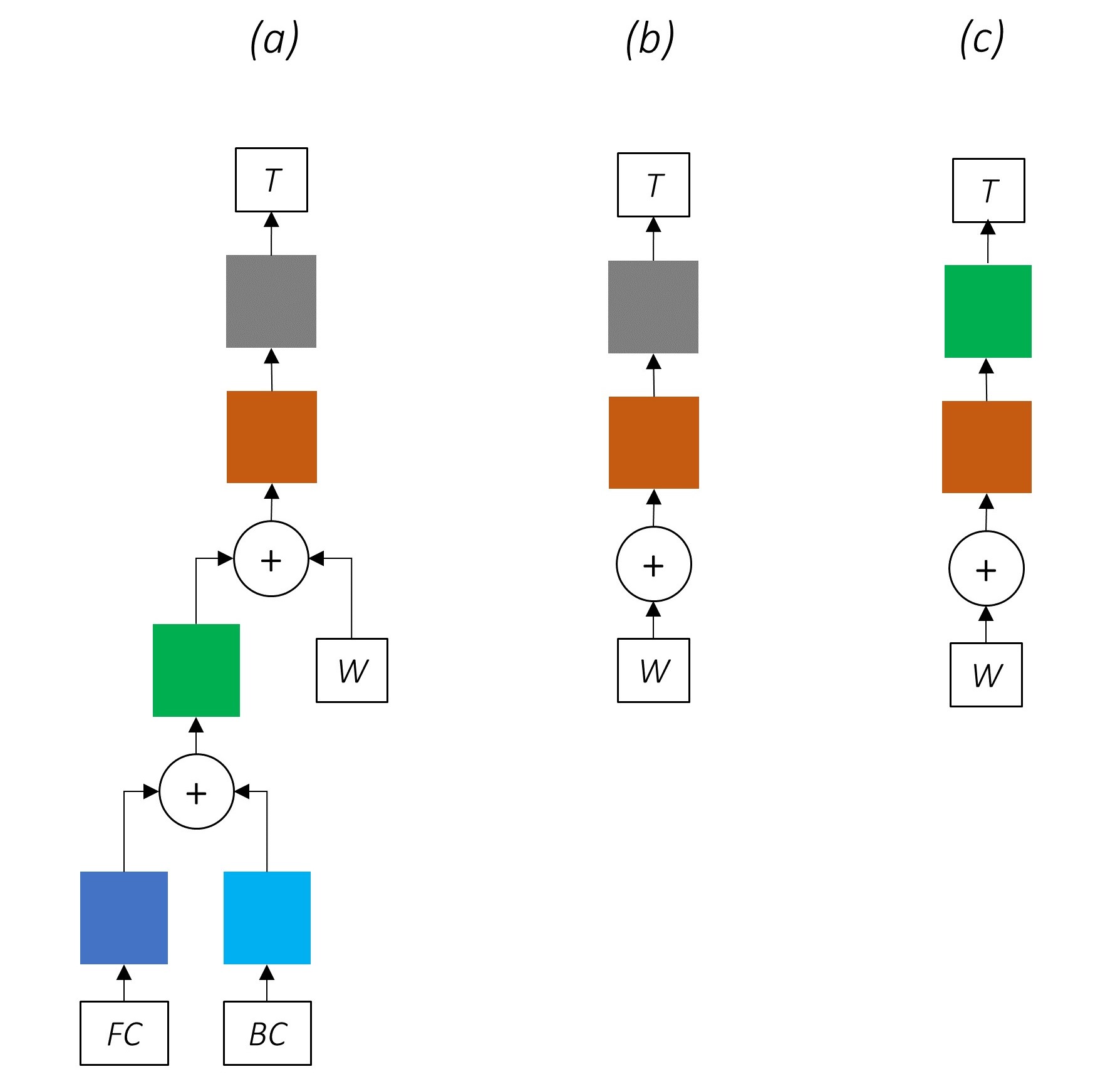
Es gibt kein Multi-Task-Lernen.
Die Verwendung von Informationen auf Zeichenebene ohne Co-Training verbessert die Leistung weiter.
Es gibt keine Multi-Task-Lern- oder Charakterebene-Verarbeitung.
Diese Konfiguration wird in der Branche häufig verwendet und funktioniert gut.
Es gibt kein Multi-Task-Lernen, keine Verarbeitung von Charakterebene oder CRFing. Beachten Sie, dass eine lineare oder Autobahnschicht das letztere ersetzen würde.
Dies könnte einigermaßen gut funktionieren, aber ein bedingter Zufallsfeld bietet einen beträchtlichen Leistungsschub.
Denken Sie daran, dass wir keine lineare Schicht verwenden, die nur die Emissionswerte berechnet. Cross -Entropie ist keine geeignete Verlustmetrik.
Stattdessen werden wir den Viterbi -Verlust verwenden, der wie Kreuzentropie eine "negative Log -Wahrscheinlichkeit" ist. Aber hier werden wir die Wahrscheinlichkeit der Gold -Tag -Sequenz anstelle der Wahrscheinlichkeit des wahren Tags bei jedem Wort in der Sequenz messen. Um die Wahrscheinlichkeit zu finden, betrachten wir die Softmax über die Punktzahlen aller Tag -Sequenzen.
Die Punktzahl einer Tag -Sequenz t ist definiert als die Summe der Punkte der einzelnen Tags.

Betrachten Sie zum Beispiel die CRF -Werte, die wir uns zuvor angesehen haben -
Die Punktzahl des Tag -Sequenz tag_2, tag_3, tag_3, <end> tag ist die Summe der Werte in rot, 4.85 + 6.79 + 3.85 + 3.52 = 19.01 .
Der Viterbi -Verlust wird dann als definiert als
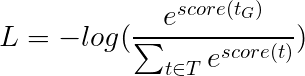
wobei t_G die Gold -Tag -Sequenz ist und T den Raum aller möglichen Tag -Sequenzen darstellt.
Dies vereinfacht zu -
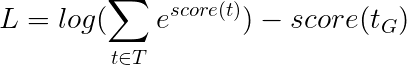
Daher ist der Viterbi-Verlust der Unterschied zwischen dem Protokoll-Sum-EXP der Bewertungen aller möglichen Tag-Sequenzen und der Punktzahl der Gold-Tag-Sequenz , dh log-sum-exp(all scores) - gold score .
Das Dekodieren von Viterbi ist eine Möglichkeit, die optimalste Tag -Sequenz zu konstruieren, da nicht nur die Wahrscheinlichkeit eines Tags bei einem bestimmten Wort (Emissionswerte), sondern auch die Wahrscheinlichkeit eines Tags unter Berücksichtigung der vorherigen und nächsten Tags (Übergangswerte) berücksichtigt wird.
Sobald Sie CRF -Scores in einer L, m, m -Matrix für eine Abfolge von Länge L generiert haben, beginnen wir zu dekodieren.
Viterbi -Dekodierung wird am besten mit einem Beispiel verstanden. Noch einmal überlegen -
Für das erste Wort in der Sequenz kann der previous_tag nur <start> sein. Betrachten Sie daher nur diese eine Reihe.
Dies sind auch die kumulativen Bewertungen für jeden current_tag beim ersten Wort.
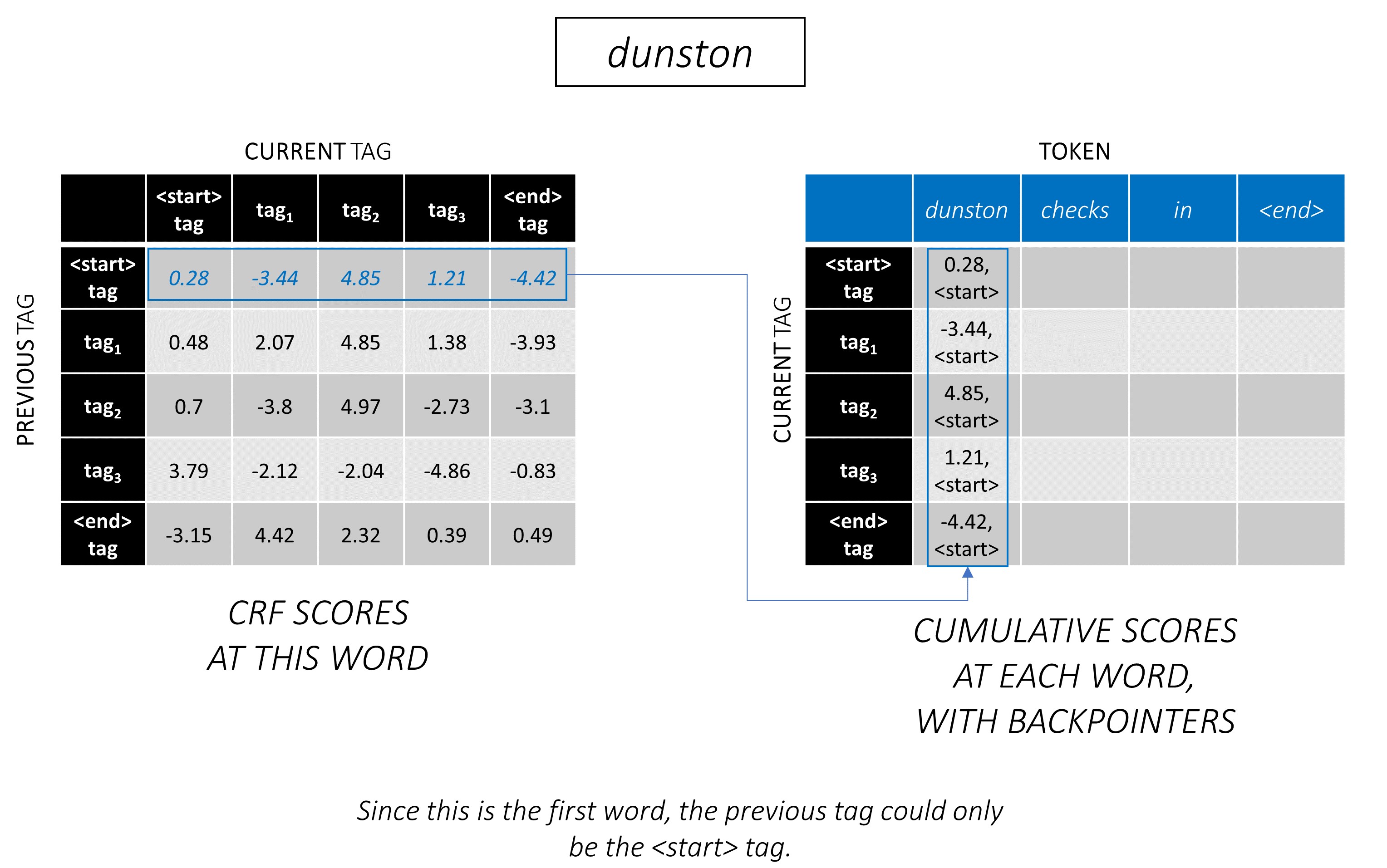
Wir werden auch den previous_tag verfolgen, der jeder Punktzahl entspricht. Diese sind als Backpolter bekannt. Beim ersten Wort sind sie offensichtlich alle <start> Tags.
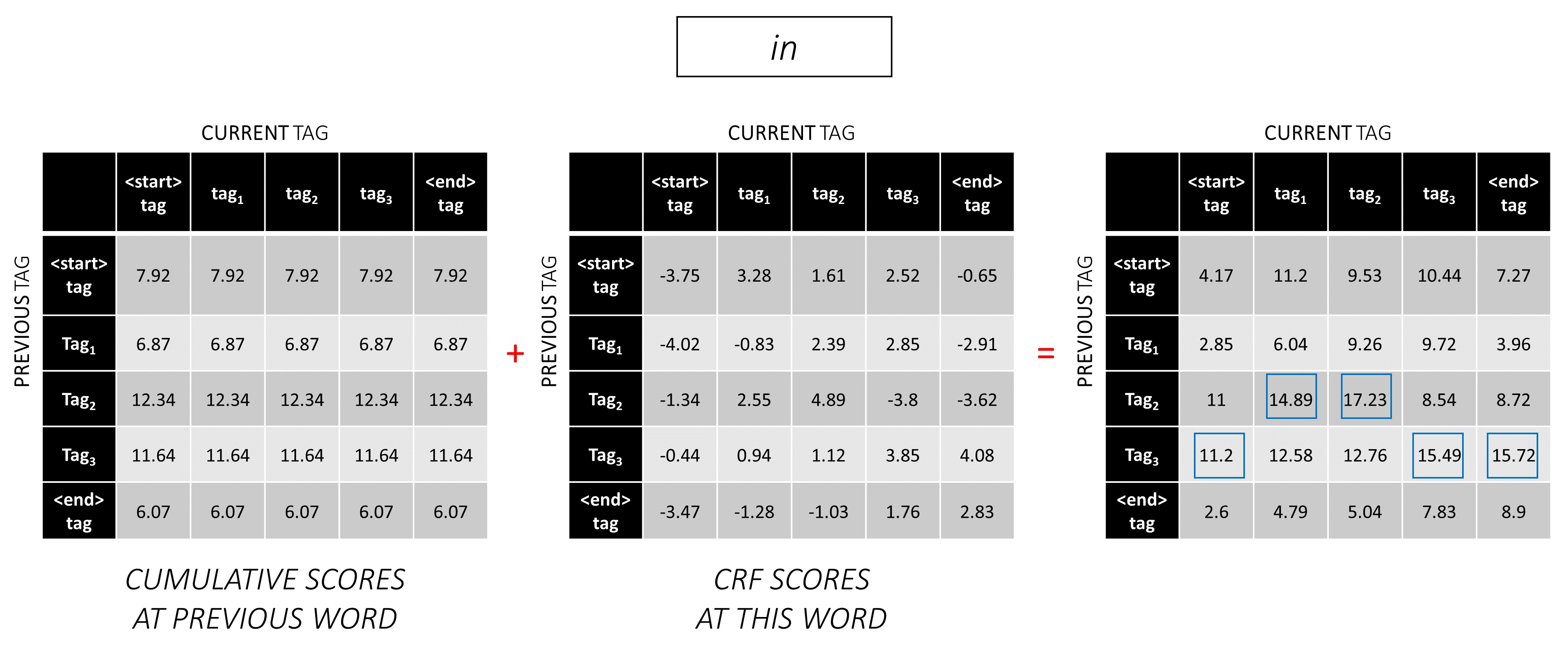
Fügen Sie beim zweiten Wort die vorherigen kumulativen Bewertungen zu den CRF -Werten dieses Wortes hinzu, um neue kumulative Bewertungen zu generieren .
Beachten Sie, dass das erste Wort current_tag s das zweite Wort des previous_tag ist. Senden Sie daher die kumulative Punktzahl des ersten Wortes entlang der Dimension current_tag .
Betrachten Sie für jeden current_tag nur das Maximum der Ergebnisse aller previous_tag .
Speichern Sie Backpointers, dh die vorherigen Tags, die diesen maximalen Bewertungen entsprechen.

Wiederholen Sie diesen Vorgang beim dritten Wort.
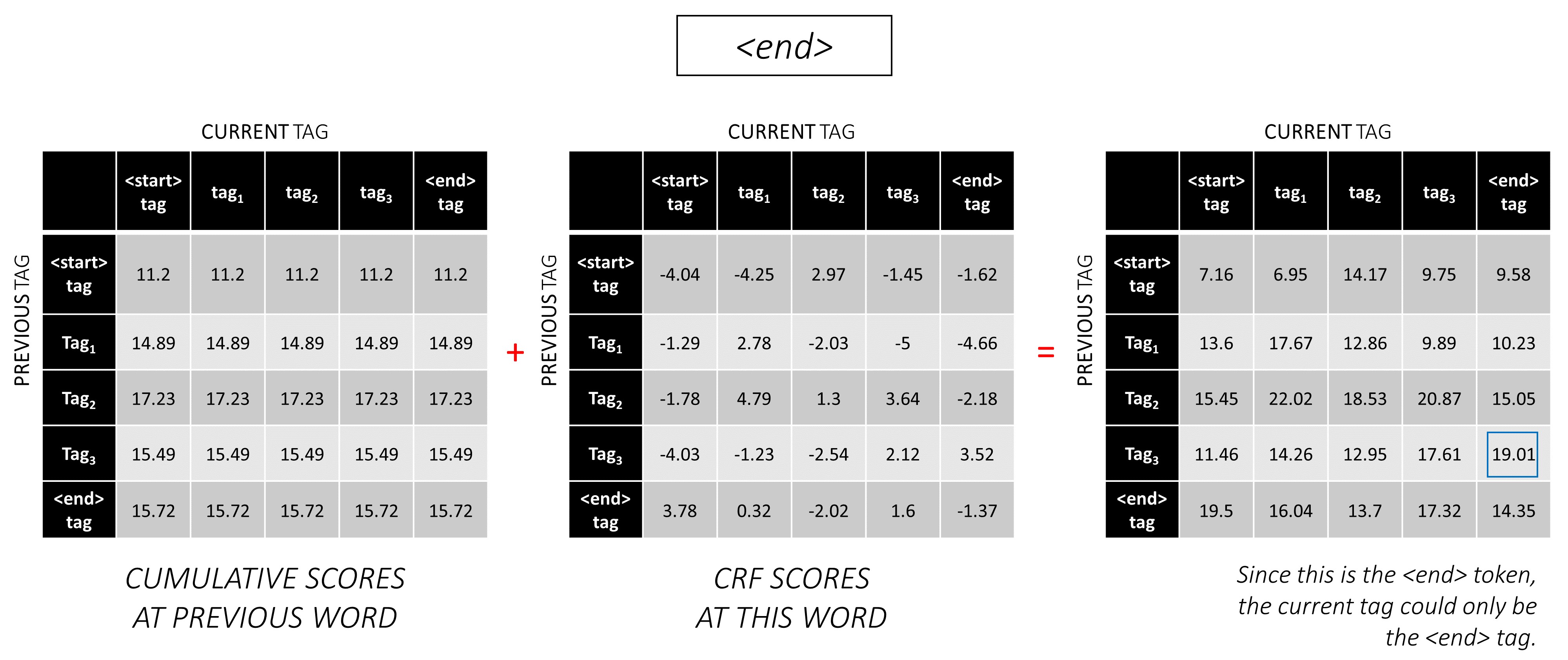
... und das letzte Wort, das ist das <end> -Token.
Der einzige Unterschied ist, dass Sie bereits das richtige Tag kennen . Sie benötigen die maximale Punktzahl und den Rucksort nur für das <end> -Tag .
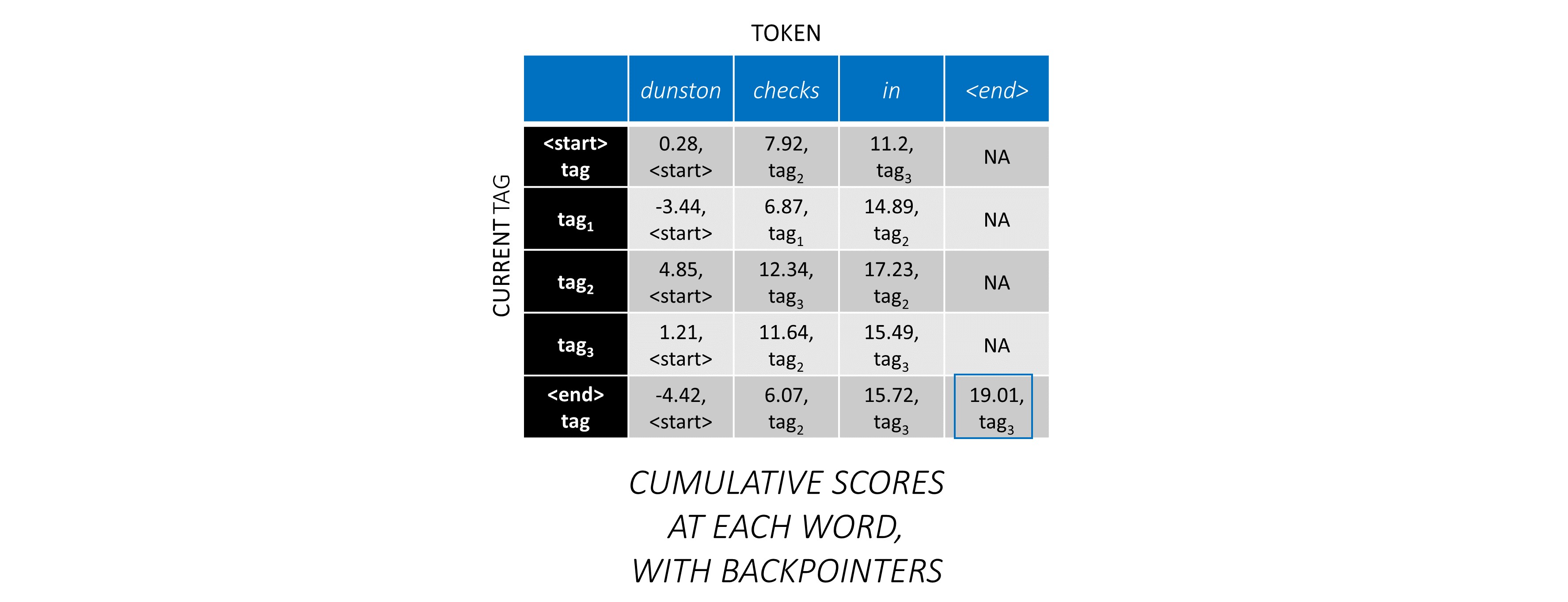
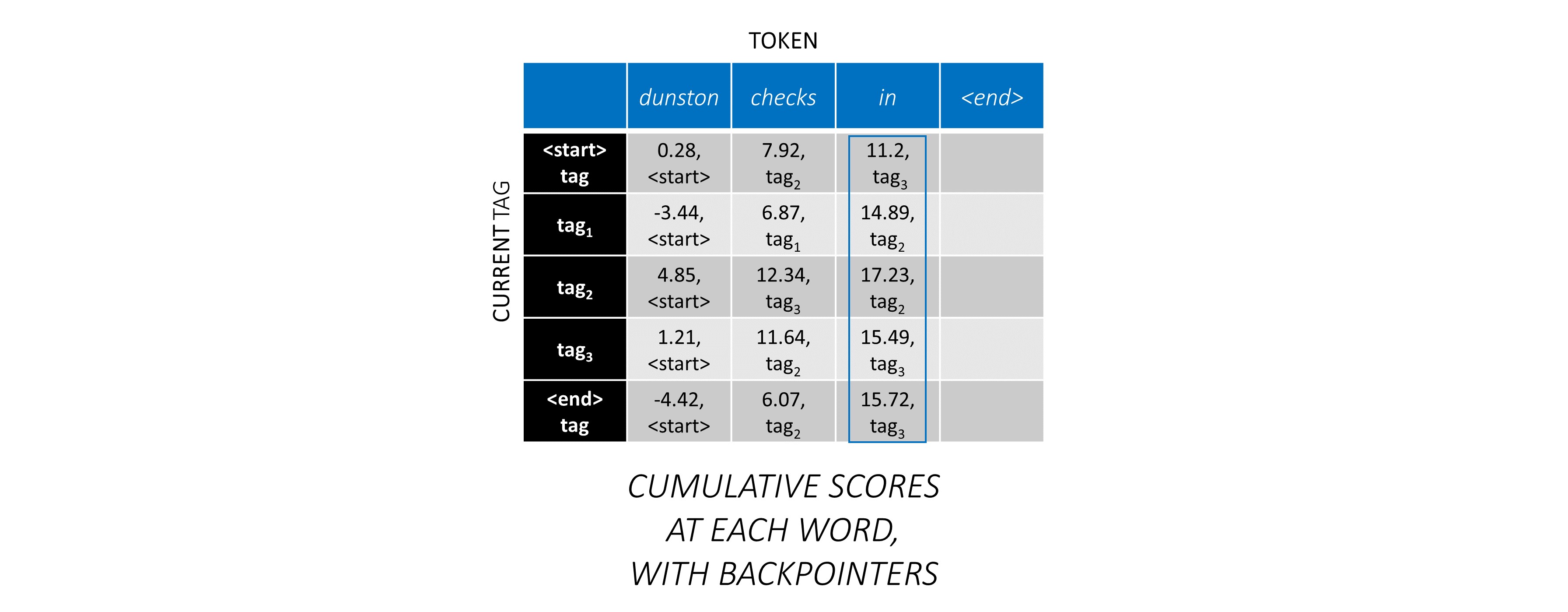
Nachdem Sie die CRF -Bewertungen in der gesamten Sequenz angesammelt haben, verfolgen Sie nach hinten, um die Tag -Sequenz mit der höchstmöglichen Punktzahl zu enthüllen .
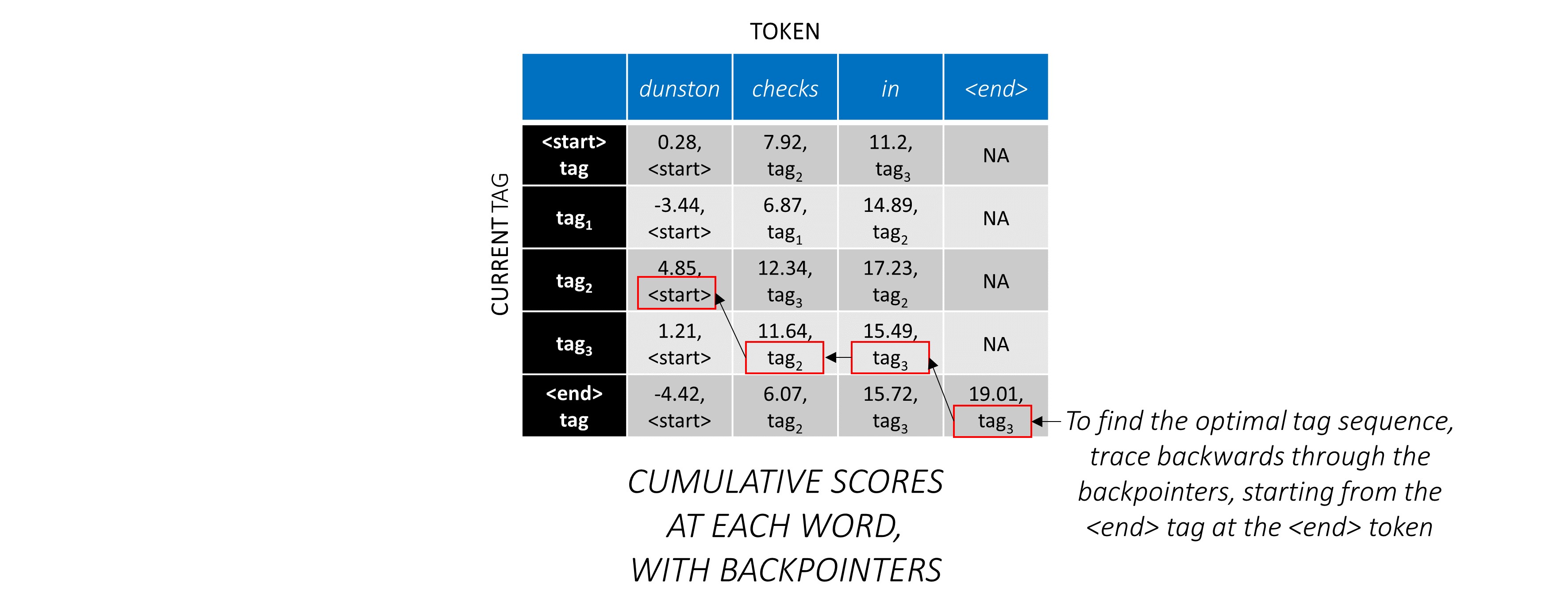
Wir finden, dass die optimalste Tag -Sequenz für dunston checks in <end> tag_2 tag_3 tag_3 <end> ist.
Die folgenden Abschnitte beschreiben kurz die Implementierung.
Sie sollen einen gewissen Kontext liefern, aber Details werden am besten direkt aus dem Code verstanden , was ziemlich stark kommentiert wird.
Ich benutze den CONLL 2003 NER -Datensatz, um meine Ergebnisse mit dem Papier zu vergleichen.
Hier ist ein Snippet -
-DOCSTART- -X- O O
EU NNP I-NP I-ORG
rejects VBZ I-VP O
German JJ I-NP I-MISC
call NN I-NP O
to TO I-VP O
boycott VB I-VP O
British JJ I-NP I-MISC
lamb NN I-NP O
. . O O
Dieser Datensatz soll nicht öffentlich verteilt sein, obwohl Sie ihn vielleicht irgendwo online finden.
Es gibt mehrere öffentliche Datensätze online, mit denen Sie das Modell trainieren können. Diese sind möglicherweise nicht alle 100% menschliche Annotierungen, aber sie sind ausreichend.
Für das NER -Tagging können Sie die Groningen Bedeutung Bank verwenden.
Für POS -Tagging verfügt NLTK über einen kleinen Datensatz, den Sie mit nltk.corpus.treebank.tagged_sents() zugreifen können.
Sie müssten es entweder in das NER -Datenformat von Conll 2003 umwandeln oder den im Abschnitt Data Pipeline verwiesenen Code ändern.
Wir brauchen acht Eingänge.
Dies sind die Wortsequenzen, die markiert werden müssen.
dunston checks in
Wie bereits erwähnt, werden wir <start> Token nicht verwenden, aber wir müssen <end> Token verwenden.
dunston, checks, in, <end>
Da wir die Sätze als Tensoren der festen Größe übergeben, müssen wir Sätze (die natürlich unterschiedliche Länge haben) auf die gleiche Länge mit <pad> -Token padeln.
dunston, checks, in, <end>, <pad>, <pad>, <pad>, ...
Darüber hinaus erstellen wir eine word_map , die für jedes Wort im Korpus, einschließlich des <end> und <pad> -Tokens, eine Indexzuordnung ist. Pytorch braucht wie andere Bibliotheken Wörter, die als Indizes kodiert werden, um Einbettungen für sie nachzuschlagen oder ihren Platz in den vorhergesagten Wortwerten zu identifizieren.
4381, 448, 185, 4669, 0, 0, 0, ...
Daher müssen Wortsequenzen, die dem Modell gefüttert werden, ein Int -Tensor der Abmessungen N, L_w sein, wobei N das batch_size und L_w die gepolsterte Länge der Wortsequenzen ist (normalerweise die Länge der längsten Wortsequenz).
Dies sind die Zeichensequenzen in Vorwärtsrichtung.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' '
Wir brauchen <end> Token in den Zeichensequenzen, um dem <end> -Token in den Wortsequenzen zu entsprechen. Da wir bei jedem Wort in der Wortsequenz Merkmale auf <end> verwenden, benötigen wir in der Wortsequenz Charakter-Ebenen-Features.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>
Wir müssen sie auch padeln.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>, <pad>, <pad>, <pad>, ...
Und codieren sie mit einem char_map .
29, 2, 12, 8, 7, 14, 12, 3, 6, 18, 1, 6, 21, 8, 3, 17, 12, 3, 60, 0, 0, 0, ...
Daher müssen Vorwärtszeichensequenzen, die dem Modell gefüttert werden, ein Int -Tensor der Abmessungen N, L_c sein , wobei L_c die gepolsterte Länge der Zeichensequenzen ist (normalerweise die Länge der längsten Zeichensequenz).
Dies würde genauso wie die Vorwärtssequenz verarbeitet, aber rückwärts. (Die <end> -Token wären natürlich noch am Ende.)
'n', 'i', ' ', 's', 'k', 'c', 'e', 'h', 'c', ' ', 'n', 'o', 't', 's', 'n', 'u', 'd', ' ', <end>, <pad>, <pad>, <pad>, ...
12, 17, 3, 8, 21, 6, 1, 18, 6, 3, 12, 14, 7, 8, 12, 2, 29, 3, 60, 0, 0, 0, ...
Daher müssen rückwärts -Zeichensequenzen, die dem Modell gespeist werden, ein Int -Tensor der Abmessungen N, L_c sein .
Diese Marker sind Positionen in den Zeichensequenzen, in denen wir Merkmale extrahieren, zu -
Wir werden Merkmale am Ende jedes ' ' in der Zeichensequenz und am <end> -Token extrahieren.
Für die Vorwärtszeichensequenz extrahieren wir bei -
7, 14, 17, 18
Dies sind Punkte nach dunston , checks in <end> . Somit haben wir einen Marker für jedes Wort in der Wortsequenz , was Sinn macht. (In den Sprachmodellen werden wir jedoch nicht vorhersagen, da wir das nächste Wort vorhersagen, der den Marker, der <end> entspricht, nicht vorhersagen wird.)
Wir padeln diese mit 0 s. Es spielt keine Rolle, was wir polieren, solange sie gültige Indizes sind. (Wir werden Merkmale auf den Pads extrahieren, aber wir werden sie nicht verwenden.)
7, 14, 17, 18, 0, 0, 0, ...
Sie sind auf die gepolsterte Länge der Wortsequenzen L_w gepolstert.
Daher müssen Vorwärtscharaktermarker, die dem Modell gespeist werden, ein Int -Tensor der Abmessungen N, L_w sein .
Für die Marker in den Rückwärts -Zeichensequenzen finden wir in ähnlicher Weise die Positionen jedes ' ' und des <end> -Tokens.
Wir stellen auch sicher, dass diese Positionen in derselben Wortreihenfolge wie in den Vorwärtsmarkierungen sind . Diese Ausrichtung erleichtert die Verkettung von Merkmalen, die aus den vorwärts- und rückwärts gerichteten Zeichensequenzen extrahiert wurden, und verhindert auch, dass die Ziele in den Sprachmodellen nachbestellen müssen.
17, 9, 2, 18
Dies sind Punkte nach notsnud , skcehc , ni , <end> .
Wir packen mit 0 s.
17, 9, 2, 18, 0, 0, 0, ...
Daher müssen rückwärts -Zeichenmarkierungen, die dem Modell gespeist werden, ein Int -Tensor der Abmessungen N, L_w sein .
Nehmen wir die richtigen Tags für dunston, checks, in, <end> sind - -
tag_2, tag_3, tag_3, <end>
Wir haben einen tag_map (mit Tags <start> , tag_1 , tag_2 , tag_3 , <end> ).
Normalerweise würden wir sie einfach direkt (vor dem Polsterung) codieren -
2, 3, 3, 5
Dies sind 1D -Codierungen, dh Tag -Positionen in einer 1D -Tag -Karte.
Die Ausgänge der CRF -Schicht sind jedoch 2D m, m -Tensoren bei jedem Wort. Wir müssten Tag -Positionen in diesen 2D -Ausgängen codieren.
Die richtigen Tag -Positionen sind rot markiert.
(0, 2), (2, 3), (3, 3), (3, 4)
Wenn wir diese Ergebnisse in einen 1D m*m -Tensor ausrollen, dann wäre die Tag -Positionen im ungereinten Tensor
tag_map [ previous_tag ] * len ( tag_map ) + tag_map [ current_tag ] Daher codieren wir tag_2, tag_3, tag_3, <end> AS
2, 13, 18, 19
Beachten Sie, dass Sie die ursprünglichen tag_map -Indizes abrufen können, indem Sie den Modul einnehmen
t % len ( tag_map ) Sie werden auf die gepolsterte Länge der Wortsequenzen L_w gepolstert.
Daher müssen Tags, die dem Modell gefüttert werden, ein Int -Tensor der Abmessungen N, L_w sein .
Dies sind die tatsächlichen Längen der Wortsequenzen, einschließlich der <end> -Token. Da Pytorch dynamische Graphen unterstützt, werden wir nur über diese Längen berechnen und nicht über den <pads> .
Daher müssen Wortlängen, die dem Modell gespeist werden, ein Int -Tensor der Abmessungen N sein .
Dies sind die tatsächlichen Längen der Zeichensequenzen, einschließlich der <end> -Token. Da Pytorch dynamische Graphen unterstützt, werden wir nur über diese Längen berechnen und nicht über den <pads> .
Daher müssen Charakterlängen, die dem Modell gespeist werden, ein Int -Tensor der Abmessungen N sein .
Siehe read_words_tags() in utils.py .
Dies liest die Eingabedateien im Conll 2003 -Format und extrahiert die Wort- und Tag -Sequenzen.
Siehe create_maps() in utils.py .
Hier erstellen wir Codierungskarten für Wörter, Zeichen und Tags. Wir sind seltene Wörter und Zeichen als <unk> (Unbekannte).
Siehe create_input_tensors() in utils.py .
Wir generieren die acht Eingänge, die in den Eingängen zum Modellabschnitt beschrieben sind.
Siehe load_embeddings() in utils.py .
Wir laden vorgeborene Einbettungen mit der Option, die word_map um Out-of-Corpus-Wörter zu erweitern, die in das Einbettungsvokabular vorhanden sind. Note that this may also include rare in-corpus words that were binned as <unk> s earlier.
Siehe WCDataset in datasets.py .
Dies ist eine Unterklasse von Pytorch Dataset . Es benötigt eine __len__ -Methode definiert, die die Größe des Datensatzes zurückgibt, und eine __getitem__ -Methode, die den i -Set der acht Eingänge an das Modell zurückgibt.
Der Dataset wird von einem Pytorch DataLoader in train.py verwendet, um Datenstapel von Daten für Schulungen oder Validierung zu erstellen und zu füttern.
Siehe Highway in models.py .
Eine Transformation ist eine reluaktivierte lineare Transformation der Eingabe. Ein Tor ist eine sigmoid-aktivierte lineare Transformation des Eingangs. Beachten Sie, dass beide Transformationen die gleiche Größe wie die Eingabe haben müssen , um das Hinzufügen der Eingabe in einer Restverbindung zu ermöglichen.
Die num_layers schreibt spezifiziert, wie viele Transformations-Gate-Residual-Connection-Operationen wir in Serien ausführen. Normalerweise ist nur einer ausreichend.
Wir speichern die erforderliche Anzahl von Transformations- und Gate -Ebenen in separaten ModuleList() s und verwenden eine for Schleife, um aufeinanderfolgende Operationen durchzuführen.
Siehe LM_LSTM_CRF in models.py .
Zu Beginn sortieren wir die Vorwärts- und Rückwärts -Zeichensequenzen, indem wir die Längen verringern . Dies ist erforderlich, um pack_padded_sequence() zu verwenden, damit der LSTM nur über die gültigen Zeitschritte berechnet wird, dh die wahre Länge der Sequenzen.
Denken Sie daran, auch alle anderen Tensoren in der gleichen Reihenfolge zu sortieren.
In dynamic_rnn.py finden Sie eine Abbildung, wie pack_padded_sequence() verwendet werden kann, um die dynamischen Grafik- und Batching -Funktionen von Pytorch zu nutzen, damit wir die Pads nicht verarbeiten. Es flacht die sortierten Sequenzen nach dem Zeitschritt, während die Pads ignoriert werden, und das LSTM berechnet nur die effektive Stapelgröße N_t an jedem Zeitschritt .
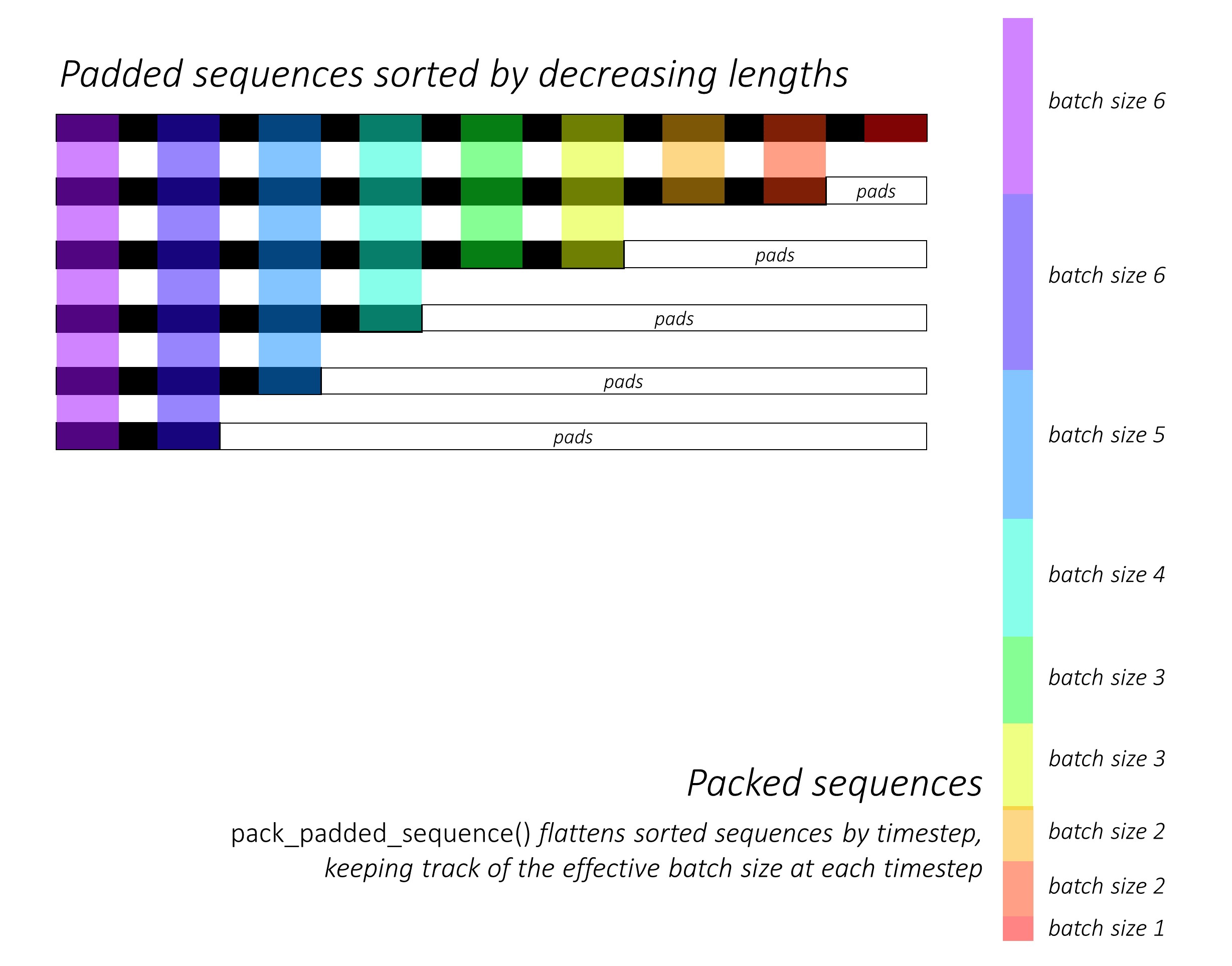
Die Sortierung ermöglicht es dem oberen N_t an jedem Zeitschritt, sich mit den Ausgängen aus dem vorherigen Schritt auszurichten . Zum dritten Zeitschritt verarbeiten wir beispielsweise nur die Top 5 Bilder mit den Top 5 Ausgängen aus dem vorherigen Schritt. Abgesehen von der Sortierung wird all dies von Pytorch intern behandelt, aber es ist immer noch sehr nützlich zu verstehen, was pack_padded_sequence() tut, damit wir es in anderen Szenarien verwenden können, um ähnliche Ziele zu erreichen. (Siehe die zugehörige Frage zum Umgang mit variablen Längensequenzen im FAQS -Abschnitt.)
Bei der Sortierung wenden wir die Vorwärts- und Rückwärts -LSTMs auf die vorwärts bzw. rückwärts packed_sequences an. Wir verwenden pad_packed_sequence() um die Ausgänge zu fäuellen und neu zu streichen.
Wir extrahieren nur die Ausgänge am Vorwärts- und Rückwärtscharaktermarkierungen mit gather . Diese Funktion ist sehr nützlich, um nur bestimmte Indizes aus einem Tensor zu extrahieren, die in einem separaten Tensor angegeben sind.
Diese extrahierten Ausgänge werden von den Vorwärts- und Rückwärts -Autobahnschichten verarbeitet, bevor eine lineare Schicht angewendet wird, um die Bewertungen über dem Wortschatz für die Vorhersage des nächsten Wortes an jedem Marker zu berechnen . Wir tun dies nur während des Trainings, da es keinen Sinn macht, eine Sprachmodellierung für das Lernen von Multitaskieren während der Validierung oder Inferenz durchzuführen. Das training eines beliebigen Modells wird mit model.train() oder model.eval() in train.py festgelegt. (Beachten Sie, dass dies in erster Linie verwendet wird, um den Ausfall- und Batch-Norm-Schichten in einem Pytorch-Modell während des Trainings und der Inferenz zu aktivieren oder zu deaktivieren.)
Siehe LM_LSTM_CRF in models.py (Fortsetzung).
Wir sortieren auch die Wortsequenzen, indem wir Längen verringern , da es möglicherweise nicht immer eine Korrelation zwischen den Längen der Wortsequenzen und den Zeichensequenzen gibt.
Denken Sie daran, auch alle anderen Tensoren in der gleichen Reihenfolge zu sortieren.
Wir verkettet die LSTM -Ausgänge für die Vorwärts- und Rückwärtscharakter an den Markierungen und laufen ihn durch die dritte Autobahnschicht . Dadurch wird die Unterwortinformationen bei jedem Wort extrahiert, die wir für die Sequenzmarkierung verwenden werden.
Wir verkettet dieses Ergebnis mit dem Wort Einbettung und berechnen Blstm Ausgänge über die packed_sequence .
Beim erneuten Padding mit pad_packed_sequence() haben wir die Funktionen, die wir für die CRF-Schicht benötigen.
Siehe CRF in models.py .
Sie können feststellen, dass diese Schicht unter Berücksichtigung des Wertes, den sie zu unserem Modell hinzufügt, überraschend einfach ist.
Eine lineare Schicht wird verwendet, um die Ausgänge von der Blstm in die Punktzahlen für jedes Tag zu verwandeln, bei denen es sich um die Emissionsbewertungen handelt.
Ein einzelner Tensor wird verwendet, um die Übergangswerte zu halten. Dieser Tensor ist ein Parameter des Modells, was bedeutet, dass er während der Backpropagation genau wie die Gewichte der anderen Schichten aktualisierbar ist.
Um die CRF -Bewertungen zu finden, berechnen Sie die Emissionswerte bei jedem Wort und fügen Sie sie den Übergangswerten hinzu , nachdem Sie beide wie im CRF -Überblick beschrieben gesendet wurden.
Siehe ViterbiLoss in models.py .
Wir haben im Viterbi-Verlustüberblick festgestellt, dass wir den Unterschied zwischen dem Protokoll-Sum-Exp der Bewertungen aller möglichen gültigen Tag-Sequenzen und der Punktzahl der Gold-Tag-Sequenz , dh log-sum-exp(all scores) - gold score .
Wir summieren die CRF -Bewertungen jedes wahren Tags, wie zuvor beschrieben, um die Goldbewertung zu berechnen.
Erinnern Sie sich, wie wir Tag -Sequenzen mit ihren Positionen in den ungehörten CRF -Werten codiert haben? Wir extrahieren die Bewertungen an diesen Positionen mit gather() und eliminieren die Pads vor dem Summieren mit pack_padded_sequences() .
Das Finden des Protokolls-Sum-EXP der Bewertungen aller möglichen Sequenzen ist etwas schwieriger. Wir verwenden eine for Schleife, um die Zeitschritte zu iterieren. Bei jedem Zeitschritt sammeln wir Punkte für jeden current_tag von -
current_tag für jeden previous_tag zu finden. Wir tun dies nur bei der effektiven Chargengröße, dh für Sequenzen, die noch nicht abgeschlossen sind. (Unsere Sequenzen werden immer noch sortiert, indem die Wortlängen aus dem LM-LSTM-CRF Modell verringert werden.)current_tag den Protokoll-Sum-Exp über die previous_tag s, um die neuen akkumulierten Bewertungen an jedem current_tag zu finden. Nach dem Berechnen der variablen Längen aller Sequenzen haben wir einen Tensor der Abmessungen N, m , wobei m die Anzahl der (aktuellen) Tags ist. Dies sind die akkumulierten Log-Sum-EXP-Scores über alle möglichen Sequenzen, die in jedem der m Tags enden. Da jedoch gültige Sequenzen nur mit dem <end> -Tag enden können, summe nur über die Spalte <end> , um den Protokoll-Sum-Exp der Bewertungen aller möglichen gültigen Sequenzen zu ermitteln .
Wir finden den Unterschied, log-sum-exp(all scores) - gold score .
Siehe ViterbiDecoder in inference.py .
Dies implementiert den im Viterbi -Dekodierungsüberblick beschriebenen Prozess.
Wir sammeln Scores in A for Loop in ähnlicher Weise wie in ViterbiLoss , außer hier finden wir das Maximum der previous_tag -Ergebnisse für jeden current_tag , anstatt das Protokoll-Sum-Exp zu berechnen. Wir verfolgen auch den previous_tag , der dieser maximalen Punktzahl in einem Backpointer -Tensor entspricht .
Wir padeln den Backpointer -Tensor mit <end> -Tags, da wir dies ermöglicht, nach hinten über die Pads nachzuverfolgen und schließlich am tatsächlichen <end> -Tag anzukommen, woraufhin die tatsächliche Back -Treat -Strecke beginnt.
Siehe train.py .
Die Parameter für das Modell (und das Training) liegen am Anfang der Datei, sodass Sie diese problemlos überprüfen oder ändern können, wenn Sie dies wünschen.
Um Ihr Modell von Grund auf neu zu trainieren , führen Sie einfach diese Datei aus - aus.
python train.py
Um das Training an einem Kontrollpunkt wieder aufzunehmen , verweisen Sie auf die entsprechende Datei mit dem checkpoint -Parameter am Anfang des Codes.
Beachten Sie, dass wir am Ende jeder Trainingspoche die Validierung durchführen.
Sie werden feststellen, dass wir die Eingänge an jeder Stapel auf die maximalen Sequenzlängen in dieser Stapel abschneiden . Dies ist so, dass wir nicht mehr Pads in jeder Charge haben, die wir tatsächlich brauchen.
Aber warum? Obwohl die RNNs in unserem Modell nicht über die Pads berechnet werden, tun es die linearen Schichten immer noch . Es ist ziemlich geradlinig, dies zu ändern - siehe die damit verbundene Frage zum Umgang mit variablen Längensequenzen im FAQS -Abschnitt.
Für dieses Tutorial dachte ich, dass ein wenig zusätzliche Berechnung über einige Pads die Unkomplizierung wert war, nicht eine Reihe von Operationen - Autobahn, CRF, andere lineare Schichten, Verkettungen - in einer packed_sequence ausführen zu müssen.
Im Multi-Task-Szenario haben wir uns entschieden, die Cross-Entropy-Verluste aus den beiden Sprachmodellierungsaufgaben und den Viterbi-Verlust aus der Sequenzmarkierungsaufgabe zusammenzufassen.
Obwohl wir die Summe dieser Verluste minimieren , sind wir tatsächlich nur daran interessiert, den Viterbi -Verlust zu minimieren , weil wir die Summe dieser Verluste minimieren . Es ist der Viterbi -Verlust, der die Leistung bei der Hauptaufgabe widerspiegelt.
Wir verwenden pack_padded_sequence() um Pads zu beseitigen, wo immer dies erforderlich ist.
Wie in der Zeitung verwenden wir den makroverkiganten F1-Score als Kriterium für frühstöckige . Das Berechnen des F1 -Scores erfordert natürlich, dass Viterbi die CRF -Bewertungen entschlüsselt, um unsere optimalen Tag -Sequenzen zu erzeugen.
Wir verwenden pack_padded_sequence() um Pads zu beseitigen, wo immer dies erforderlich ist.
Ich habe die Parameter in der Implementierung der Autoren so genau wie möglich befolgt.
Ich habe eine Chargengröße von 10 Sätzen verwendet. Ich verwendete stochastische Gradientenabstieg mit Impuls. Die Lernrate wurde in jeder Epoche verfallen. Ich habe 100D-Handschuhe ohne Feinabstimmung verwendet.
Es dauerte ungefähr 80er Jahre, um eine Epoche auf einem Titan X (Pascal) zu trainieren.
Der F1 -Score für den Validierungssatz erreichte 91% um Epoch 50 und erreichte bei Epoch 171 einen Höhepunkt bei 91.6% Ich leitete ihn für insgesamt 200 Epochen. Dies ist ziemlich nahe an den Ergebnissen des Papiers.
Sie können dieses vorbereitete Modell hier herunterladen.
Wie entscheiden wir, ob wir <start> und <end> Token für ein Modell benötigen, das Sequenzen verwendet?
Wenn dies zunächst verwirrend erscheint, wird es sich leicht selbst lösen, wenn Sie über die Anforderungen des Modells nachdenken, das Sie trainieren.
Für die Sequenzmarkierung mit einem CRF benötigen Sie das <end> -Token ( oder das <start> -Token; siehe nächste Frage), weil die CRF -Scores strukturiert sind.
In meinem anderen Tutorial über Bildunterschriften habe ich sowohl <start> als auch <end> Token verwendet. Das Modell musste irgendwo dekodieren und lernen, zu erkennen, wann die Dekodierung während der Inferenz eingestellt werden muss.
Wenn Sie eine Textklassifizierung durchführen, müssen Sie auch nicht benötigen.
Können wir das CRF current_word -> next_word generieren lassen previous_word -> current_word
Ja. In diesem Fall würden Sie die Emissionswerte wie L, m, _ übertragen, und Sie hätten ein <start> -Token in jedem Satz anstelle eines <end> -Tokens. Das richtige Tag des <start> Token wäre immer das <start> -Tag. Das "Nächste Tag" des letzten Wortes wäre immer das <end> -Tag.
Ich denke, das previous word -> current word Wortkonvention ist etwas besser, da es Sprachmodelle im Mix gibt. Es passt ziemlich gut dazu, das <end> -Token beim letzten wirklichen Wort vorherzusagen und daher zu erkennen, wann ein Satz vollständig ist.
Warum verwenden wir verschiedene Vokabulare für die Eingänge und Sprachmodelle des Sequenz -Taggers?
Die Sprachmodelle lernen, nur die Wörter vorherzusagen, die sie während des Trainings gesehen haben. Es ist wirklich unnötig und eine enorme Verschwendung von Berechnungs- und Speicher, eine lineare Softmax-Ebene mit den zusätzlichen ~ 400.000 Out-of-Corpus-Wörtern aus der Einbettungsdatei zu verwenden, die niemals vorhersagen wird.
Aber wir können diese Wörter der Eingabebereich hinzufügen, auch wenn das Modell sie während des Trainings nie sieht. Dies liegt daran, dass wir beim Eingang vorgebreitete Einbettungen verwenden. Es muss sie nicht sehen, weil die Bedeutungen von Wörtern in diesen Vektoren codiert sind. Wenn es zuvor auf einen chimpanzee gestoßen ist, weiß es sehr wahrscheinlich, was mit einem orangutan zu tun ist.
Ist es eine gute Idee, die in diesem Modell verwendeten vorgeschriebenen Wort-Einbettungen zu optimieren?
Ich verzichte auf die Feinabstimmung, da der größte Teil des Eingangsvokabulars nicht im Korpus ist. Most embeddings will remain the same while a few are fine-tuned. If fine-tuning changes these embeddings sufficiently, the model may not work well with the words that weren't fine-tuned. In the real world, we're bound to encounter many words that weren't present in a newspaper corpus from 2003.
What are some ways we can construct dynamic graphs in PyTorch to compute over only the true lengths of sequences?
If you're using an RNN, simply use pack_padded_sequence() . PyTorch will internally compute over only the true lengths. See dynamic_rnn.py for an example.
If you want to execute an operation (like a linear transformation) only on the true timesteps, pack_padded_sequences() is still the way to go. This flattens the tensor by timestep while removing the pads. You can perform your operation on this flattened tensor, and then use pad_packed_sequence() to unflatten it and re-pad it with 0 s.
Similarly, if you want to perform an aggregation operation, like computing the loss, use pack_padded_sequences() to eliminate the pads.
If you want to perform timestep-wise operations, you can take a leaf out of how pack_padded_sequences() works, and compute only on the effective batch size at each timestep with a for loop to iterate over the timesteps. We did this in the ViterbiLoss and ViterbiDecoder . I also used an LSTMCell() in this fashion in my image captioning tutorial.
Dunston Checks In ? Wirklich?
I had no memory of this movie for twenty years. I was trying to think of a short sentence that would be easier to visualize in this tutorial and it just popped into my mind riding a wave of 90s nostalgia.

I wish I hadn't googled it though. Damn, the critics were harsh, weren't they? This gem was overwhelmingly and universally panned. I'm not sure I'd disagree if I watched it now, but that just goes to show the world is so much more fun when you're a kid.
Didn't have to worry about LM-LSTM-CRFs or nuthin...


