a PyTorch Tutorial to Sequence Labeling
1.0.0
Это учебник Pytorch по маркировке последовательности .
Это вторая в серии учебных пособий, которые я пишу о реализации крутых моделей самостоятельно с удивительной библиотекой Pytorch.
Предполагается базовые знания о Pytorch, повторяющихся нейронных сетях.
Если вы новичок в Pytorch, сначала прочитайте Deep Learning с помощью Pytorch: 60 -минутный блиц и изучение питорха с примерами.
Вопросы, предложения или исправления могут быть опубликованы в качестве вопросов.
Я использую PyTorch 0.4 в Python 3.6 .
27 января 2020 года : был добавлен рабочий код для двух новых учебных пособий-супер-разрешение и машинный перевод
Цель
Концепции
Обзор
Выполнение
Обучение
Часто задаваемые вопросы
Чтобы построить модель, которая может пометить каждое слово в предложении с объектами, частями речи и т. Д.

Мы будем реализовать маркировку последовательности Empower с помощью модельного документа для нейронного языка с учетом задач . Это более продвинуто, чем большинство моделей тегов последовательности, но вы узнаете много полезных концепций - и это работает очень хорошо. Оригинальную реализацию авторов можно найти здесь.
Эта модель является особенной, потому что она увеличивает задачу маркировки последовательности, обучая ее одновременно с языковыми моделями.
Маркировка последовательности . дух
Языковые модели . Языковое моделирование - предсказать следующее слово или символ в последовательности слов или символов. Модели нейронного языка достигают впечатляющих результатов по широкому кругу задач NLP, таких как генерация текста, машинный перевод, подписание изображений, оптическое распознавание символов и то, что у вас есть.
Персонаж RNNS . Известно, что RNN, работающие на отдельных символах в тексте, отражают основной стиль и структуру. В задаче по маркировке последовательности они особенно полезны, поскольку информация о подлогах часто может дать важные подсказки для сущности или тега.
Многозадачное обучение . Наборы данных, доступные для обучения модели, часто невелики. Создание аннотаций или функций ручной работы, чтобы помочь вашей модели, не только громоздка, но и часто не адаптируется к разнообразным доменам или настройкам, в которых ваша модель может быть полезна. Маркировка последовательности, к сожалению, является ярким примером. Существует способ смягчить эту проблему - совместное обучение нескольких моделей, соединенных в бедре, максимизирует информацию, доступную для каждой модели, повышая производительность.
Условные случайные поля . Дискретные классификаторы предсказывают класс или метку на слове. Условные случайные поля (CRF) могут сделать вас лучше - они предсказывают этикетки на основе не только слова, но и на соседстве. Что имеет смысл, потому что в последовательности сущностей или метки есть шаблоны. CRF широко используются для моделирования упорядоченной информации, будь то для маркировки последовательности, секвенирования генов или даже обнаружения объектов и сегментации изображения в компьютерном зрении.
Витерби декодирование . Поскольку мы используем CRFS, мы не столько предсказываем правильную метку на каждом словом, сколько прогнозируем правильную последовательность метки для последовательности слов. Декодирование Viterbi - это способ сделать именно это - найти наиболее оптимальную последовательность тегов из баллов, рассчитанных по условному случайному полю.
Шоссе сети . Полностью подключенные слои являются основным продуктом в любой нейронной сети для преобразования или извлечения функций в разных местах. Шосовые сети достигают этого, но также позволяют информации течь, не предназначенная для преобразования. Это делает глубокие сети намного более эффективными или выполнимыми.
В этом разделе я представим обзор этой модели. Если вы уже знакомы с этим, вы можете пропустить прямо в раздел реализации или комментированный код.
Авторы называют модель как языковую модель - длинную кратковременную память - условное случайное поле, поскольку она включает в себя языковые модели совместного обучения с комбинацией LSTM + CRF .
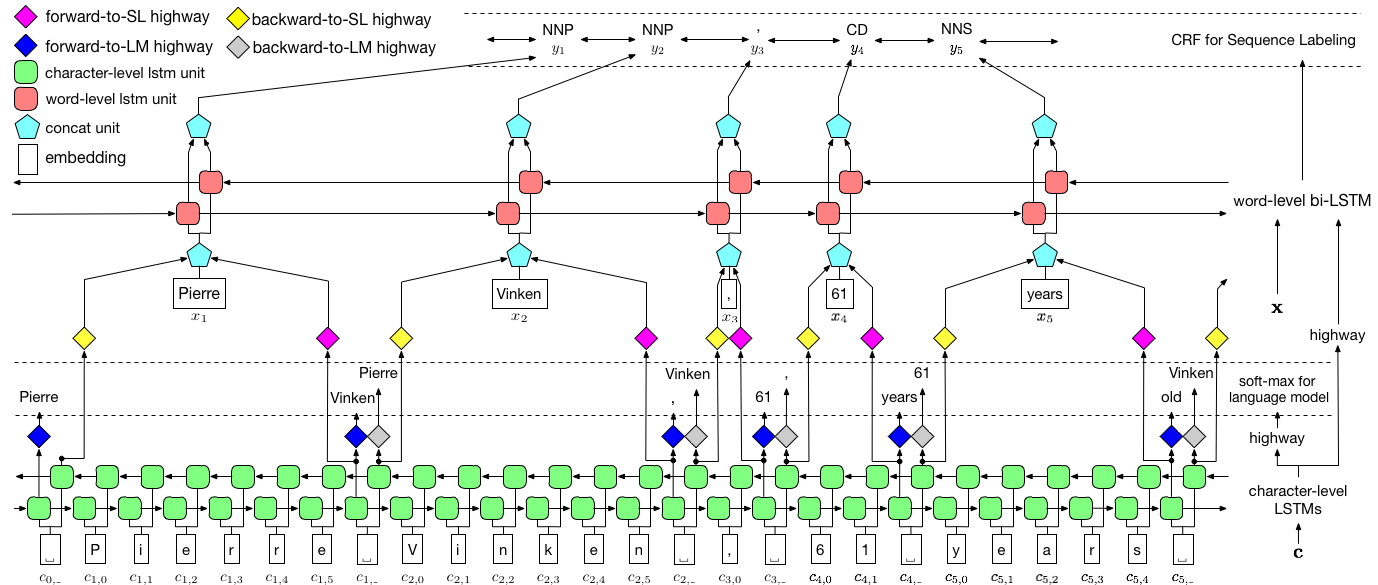
Это изображение из бумаги тщательно представляет всю модель, но не волнуйтесь, если в настоящее время оно кажется слишком сложным. Мы разбим его, чтобы поближе взглянуть на компоненты.
Многозадачное обучение-это когда вы одновременно тренируете модель на двух или более задачах.
Обычно нас интересует только одна из этих задач - в этом случае маркировка последовательности.
Но когда слои в нейронной сети способствуют выполнению нескольких функций, они изучают больше, чем они могли бы, если бы они обучались только на основной задаче. Это связано с тем, что информация, извлеченная на каждом уровне, расширяется для выполнения всех задач. Когда есть больше информации для работы, производительность по основной задаче улучшается .
Обогащение существующих функций таким образом устраняет необходимость использования функций ручной работы для маркировки последовательности.
Общая потеря во время многозадачного обучения, как правило, является линейной комбинацией потерь на отдельных задачах. Параметры комбинации могут быть фиксированы или изучены как обновляемые веса.

Поскольку мы собираем индивидуальные потери, вы можете увидеть, как вверх по течению слои, разделяемые несколькими задачами, получат обновления от всех из них во время обработки обработки.
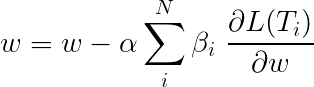
Авторы статьи просто добавляют потери ( β=1 ), и мы сделаем то же самое.
Давайте посмотрим на задачи, которые составляют нашу модель.
Есть три .

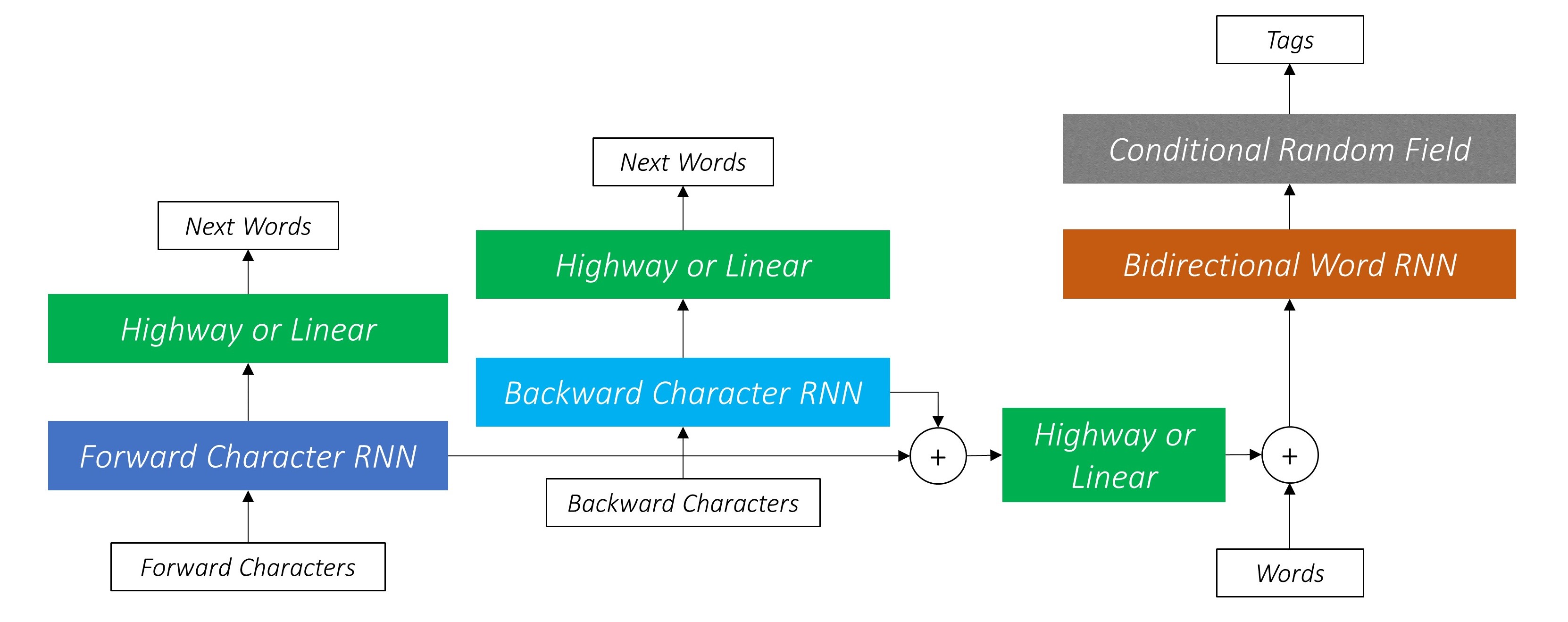
Это использует информацию о подносе, чтобы предсказать следующее слово.
Мы делаем то же самое в обратном направлении. 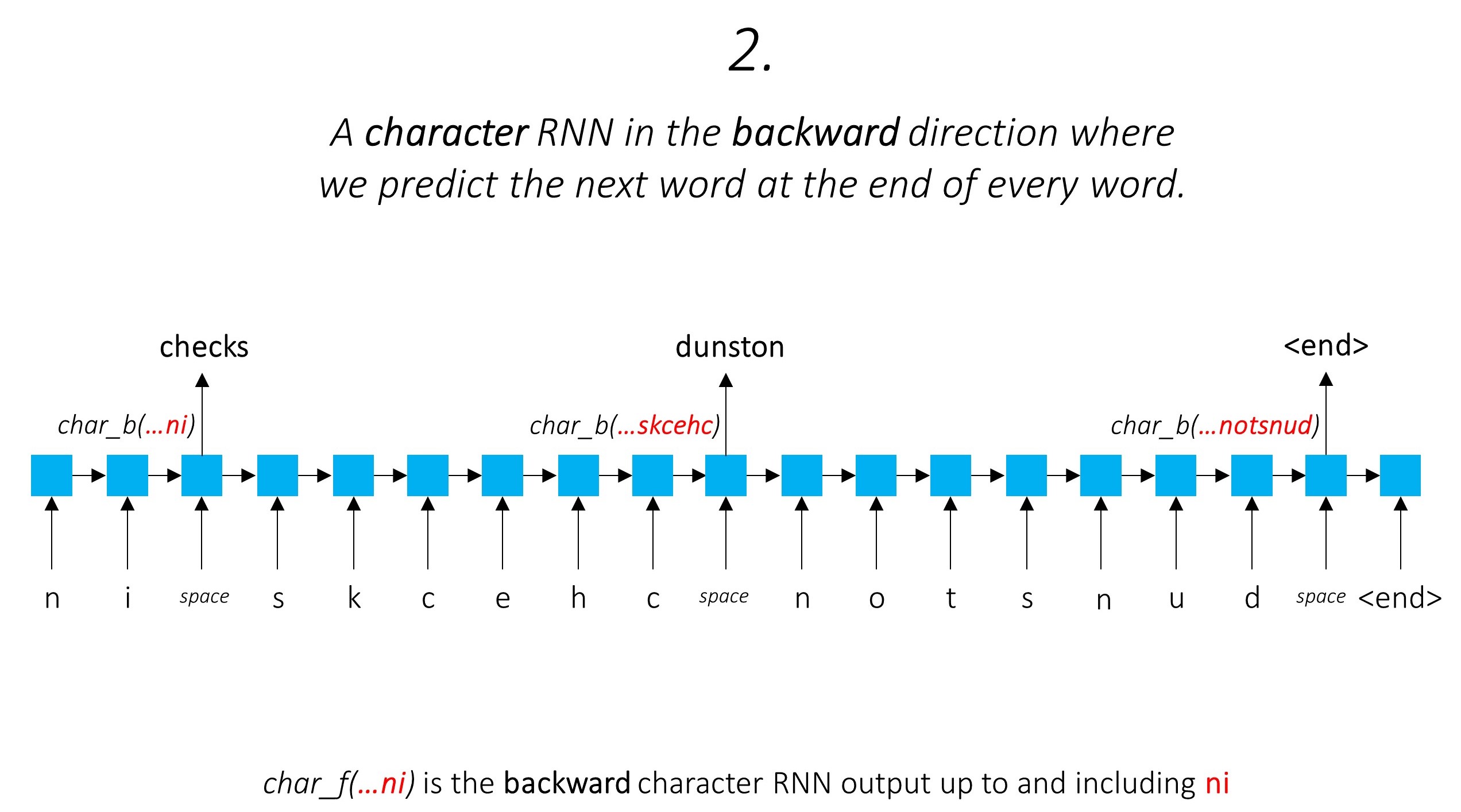
Мы также используем выходы этих двух символов-RNN в качестве входных данных для нашего Word-RNN и условного случайного поля (CRF) для выполнения нашей основной задачи маркировки последовательности. 
Мы используем информацию о подлоде в нашей задаче с тегом, потому что она может быть мощным показателем тегов, будь то части речи или сущностей. Например, он может узнать, что прилагательные обычно заканчиваются «-y» или «-ul», или что места часто заканчиваются «-land» или «-бургом».
Но наши функции подлонков, а именно. Выходы символов RNN также обогащены дополнительной информацией - знания, необходимые для прогнозирования следующего слова как в прямом, так и в обратном направлениях, из -за моделей 1 и 2.
Следовательно, наша модель тега последовательности использует оба
Двунаправленный LSTM/RNN кодирует эти функции в новые функции в каждом словом, содержащем информацию о словом и его соседстве, как на уровне слов, так и на уровне символов. Это образует вход в условное случайное поле.
Без CRF мы бы просто использовали один линейный слой для преобразования вывода двунаправленного LSTM в оценки для каждого тега. Они известны как оценки эмиссии , которые являются представлением о вероятности того, что слово является определенным тегом.
CRF рассчитывает не только оценки выбросов, но и оценки перехода , которые являются вероятностью слова, который будет определенным тегом, учитывая, что предыдущее слово было определенным тегом. Поэтому оценки перехода измеряют, насколько вероятно, что это переход от одного тега к другой.
Если есть m -теги, оценки перехода хранятся в матрице димедиций m, m , где ряды представляют тег предыдущего слова, а столбцы представляют тег текущего слова. Значение в этой матрице в положении i, j - вероятность перехода от i в предыдущем слова к тегу j на текущем словом . В отличие от результатов выбросов, оценки перехода не определены для каждого слова в предложении. Они глобальные.
В нашей модели слой CRF выводит совокупность показателей выбросов и перехода в каждом словом .
Для предложения длины L баллы выбросов будут L, m -тензором. Поскольку оценки выбросов в каждом словом не зависят от тега предыдущего слова, мы создаем новое измерение, например L, _, m и транслируют (копировать) тензор вдоль этого направления, чтобы получить тензор L, m, m
Оценки перехода - m, m Tensor. Поскольку оценки перехода являются глобальными и не зависят от слова, мы создаем новое измерение, например _, m, m и трансляция (копирование) тензора вдоль этого направления, чтобы получить тензор L, m, m
Теперь мы можем добавить их, чтобы получить общие оценки, которые являются тензором L, m, m Значение в позиции k, i, j - это совокупность оценки излучения j -метки на k th word и оценка перехода j -th в k th word, учитывая, что предыдущее слово было i th.
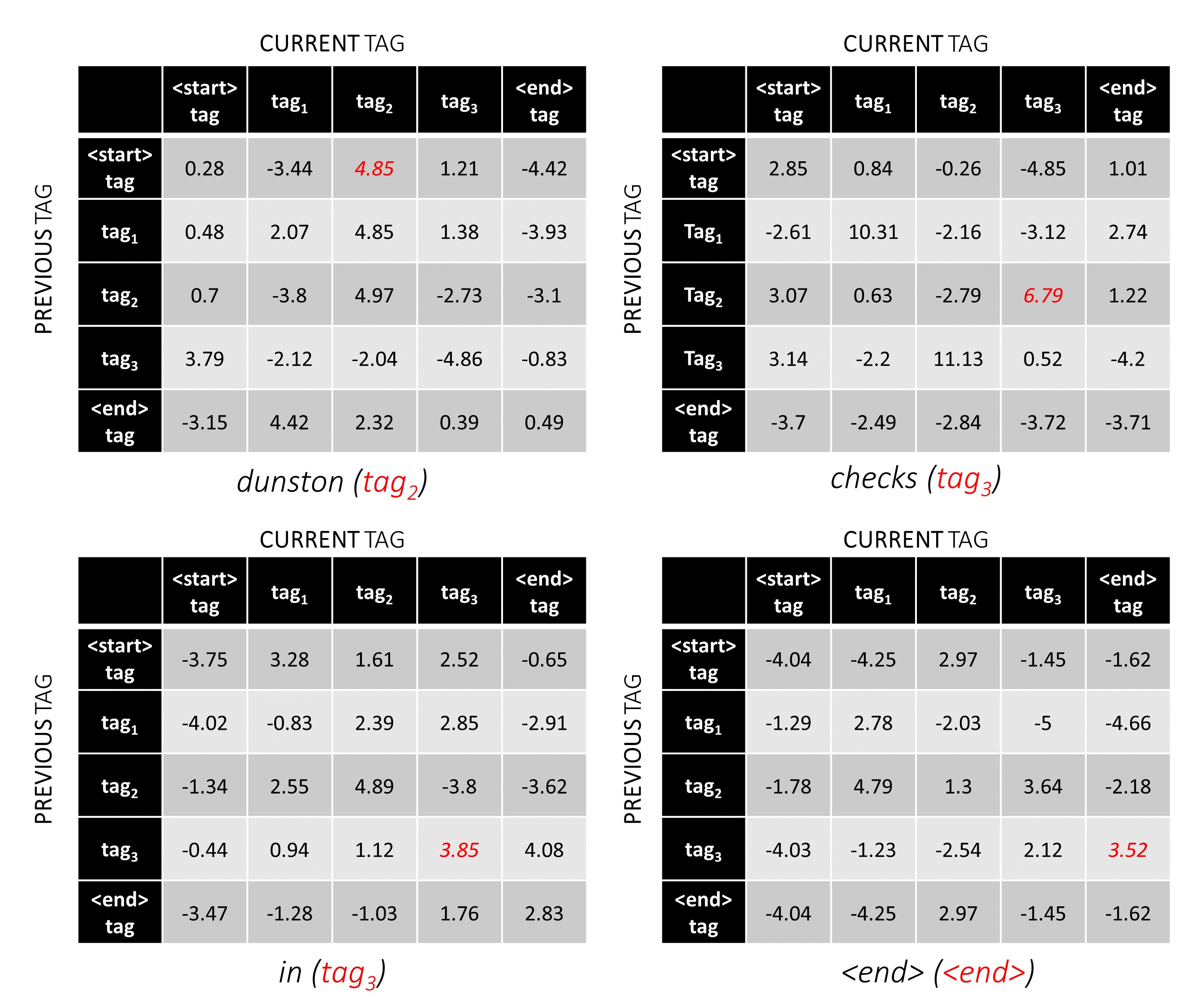
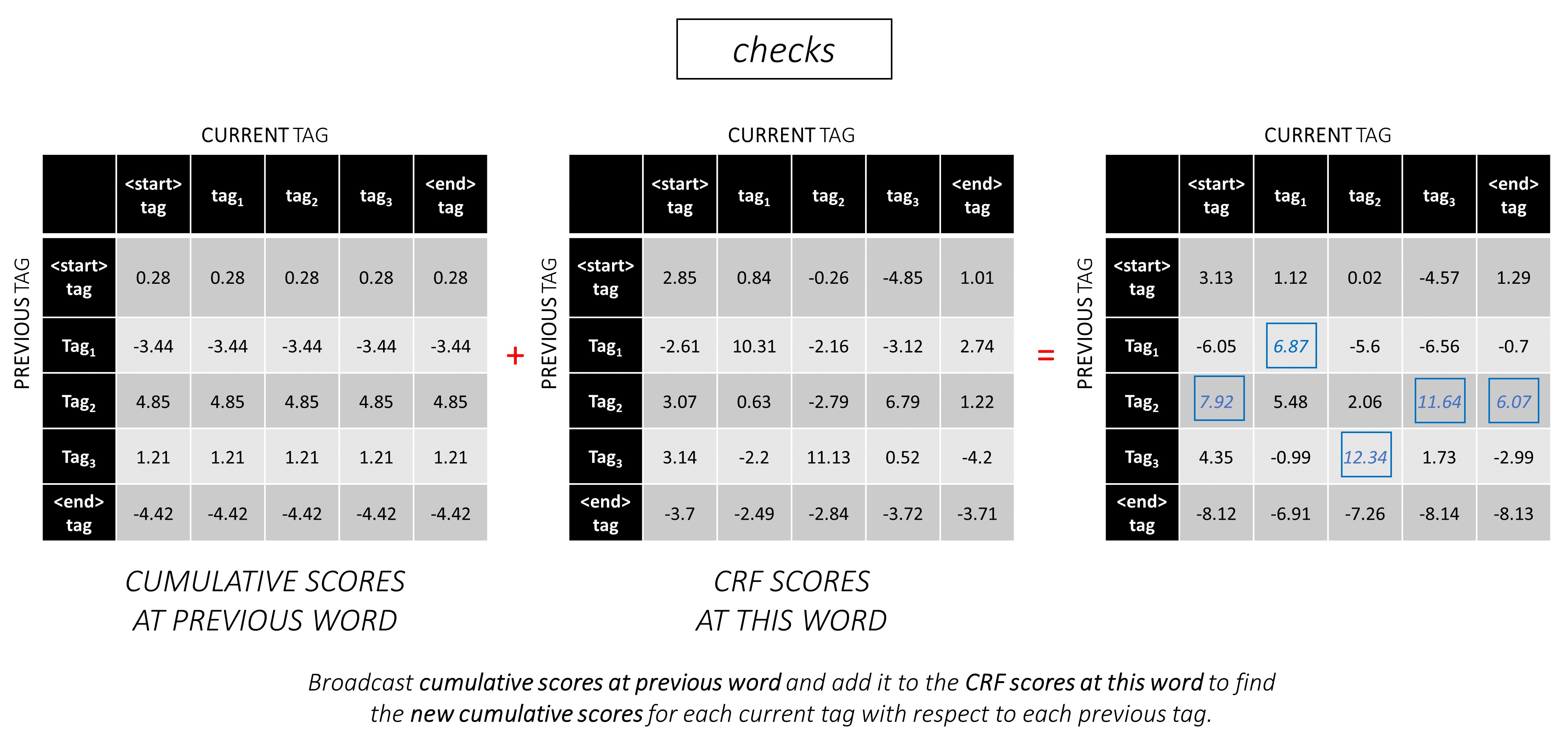
Для нашего примера предложения dunston checks in <end> , если мы предположим, что в общей сложности 5 тегов, общие оценки будут выглядеть так -
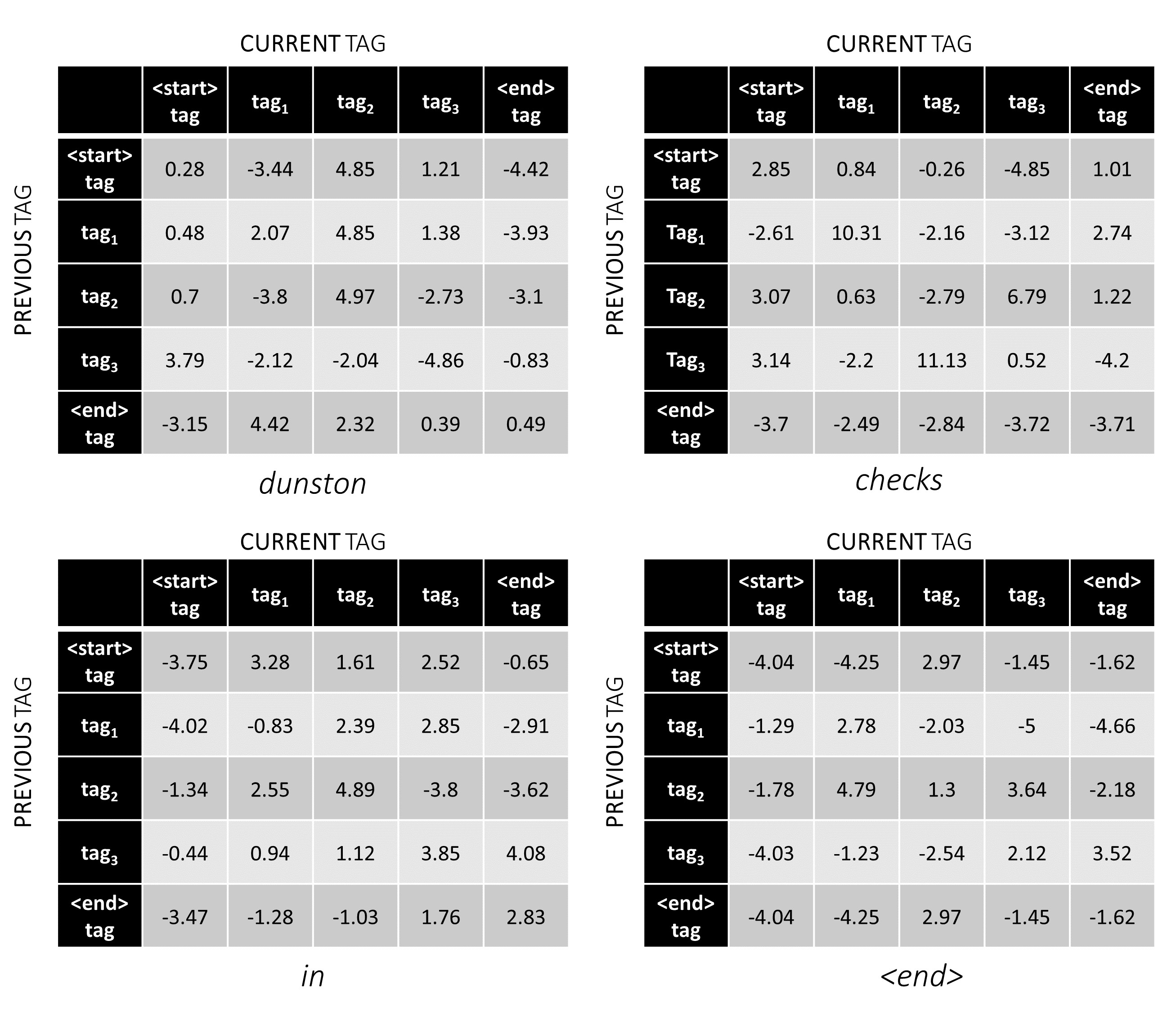
Но подождите минуту, почему есть теги <start> End <end> ? Пока мы в этом, почему мы используем токен <end> ?
<start> и <end> тегах, <start> и <end> Токены Поскольку мы моделируем вероятность перехода между тегами, мы также включаем тег <start> и тег <end> в наш набор тегов.
Оценка перехода определенного тега, учитывая, что предыдущий тег был тегом <start> , представляет вероятность того, что этот тег является первым тегом в предложении . Например, предложения обычно начинаются со статей (a, an, the) или существительных или местоимений.
Оценка перехода тега <end> с учетом определенного предыдущего тега указывает на вероятность того, что этот предыдущий тег является последним тегом в предложении .
Мы будем использовать токен <end> во всех предложениях, а не токен <start> , потому что общие оценки CRF в каждом словом определены в отношении тега предыдущего слова, что не имеет смысла в токене <start> .
Правильный тег токена <end> всегда является тегом <end> . «Предыдущий тег» первого слова - это всегда тег <start> .
Чтобы проиллюстрировать, если в нашем примере предложения dunston checks in <end> имел теги tag_2, tag_3, tag_3, <end> , значения в красном указывают оценки этих тегов.
Как правило, мы используем активированные линейные слои для преобразования и обработки выходов RNN/LSTM.
Если вы знакомы с остаточными соединениями, мы можем добавить вход перед преобразованием в преобразованный выход, создав путь для потока данных вокруг преобразования.
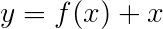
Этот путь является ярлыком для потока градиентов во время обратного распространения и помогает сближению глубоких сетей.
Сеть дорожных дорог аналогична остаточной сети, но мы используем активированный сигмоид затвор, чтобы определить отношение, в котором объединяется вход и преобразованный выход .
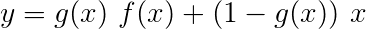
Поскольку символ-RNN вносят свой вклад в множество задач, шоссе сети используются для извлечения информации о конкретной задаче из ее выходов.
Поэтому мы будем использовать сети на шоссе в трех местах в нашей комбинированной модели -
В наивном настройке совместного обучения, где мы используем выходы символов-RNN непосредственно для нескольких задач, т. Е. Без преобразования, разногласия между природой задач может повредить производительности.
Теперь может быть ясно, как выглядит наша комбинированная сеть.
Посказательное удаление частей нашей сети приводит к постепенно более простым сетям, которые широко используются для маркировки последовательностей.
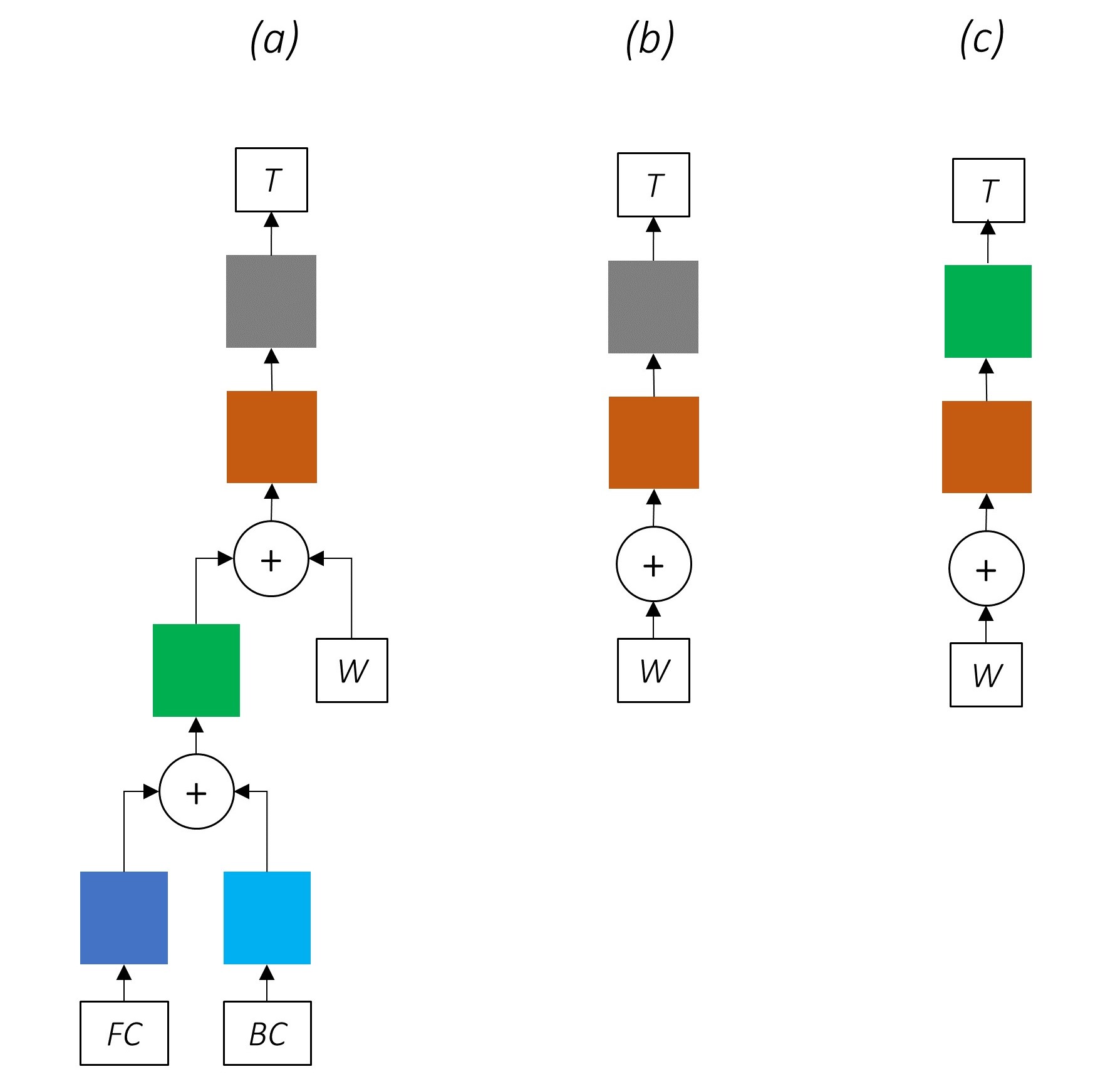
Там нет многозадачного обучения.
Использование информации на уровне символов без совместного обучения по-прежнему повышает производительность.
Там нет многозадачного обучения или обработки на уровне символов.
Эта конфигурация довольно часто используется в отрасли и работает хорошо.
Там нет многозадачного обучения, обработки на уровне символов или Crfing. Обратите внимание, что линейный или шоссе слой заменит последний.
Это может работать достаточно хорошо, но условное случайное поле обеспечивает значительный повышение производительности.
Помните, что мы не используем линейный слой, который вычисляет только оценки выбросов. Поперечная энтропия не является подходящей метрикой потерь.
Вместо этого мы будем использовать потерю Viterbi , которая, как и поперечная энтропия, является «отрицательной вероятностью журнала». Но здесь мы измеряем вероятность последовательности тегов золота (истина), а не вероятность истинного тега в каждом словом в последовательности. Чтобы найти вероятность, мы рассмотрим Softmax по оценкам всех последовательностей тегов.
Оценка последовательности TAG t определяется как сумма баллов отдельных тегов.

Например, рассмотрите оценки CRF, на которые мы смотрели ранее -
Оценка последовательности тегов tag_2, tag_3, tag_3, <end> tag - это сумма значений красного цвета, 4.85 + 6.79 + 3.85 + 3.52 = 19.01 .
Потеря Витерби затем определяется как
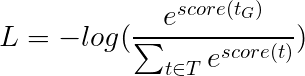
где t_G - последовательность золотой тега, а T представляет пространство всех возможных последовательностей тегов.
Это упрощает -
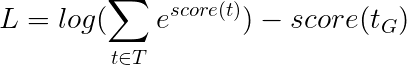
Следовательно, потеря viterbi-это разница между логарифмическим эксплуатацией баллов всех возможных последовательностей тегов и оценкой последовательности золотых тегов , т.е. log-sum-exp(all scores) - gold score .
Декодирование Viterbi - это способ построить наиболее оптимальную последовательность тегов, учитывая не только вероятность тега в определенном слове (оценки излучения), но и вероятность тега с учетом предыдущих и следующих тегов (оценки перехода).
Как только вы генерируете оценки CRF в матрице L, m, m для последовательности длины L , мы начинаем декодировать.
Декодирование Витерби лучше всего понимается с примером. Рассмотрим еще раз -
Для первого слова в последовательности previous_tag может быть только <start> . Поэтому считайте только один ряд.
Это также кумулятивные оценки для каждого current_tag на первом словом.
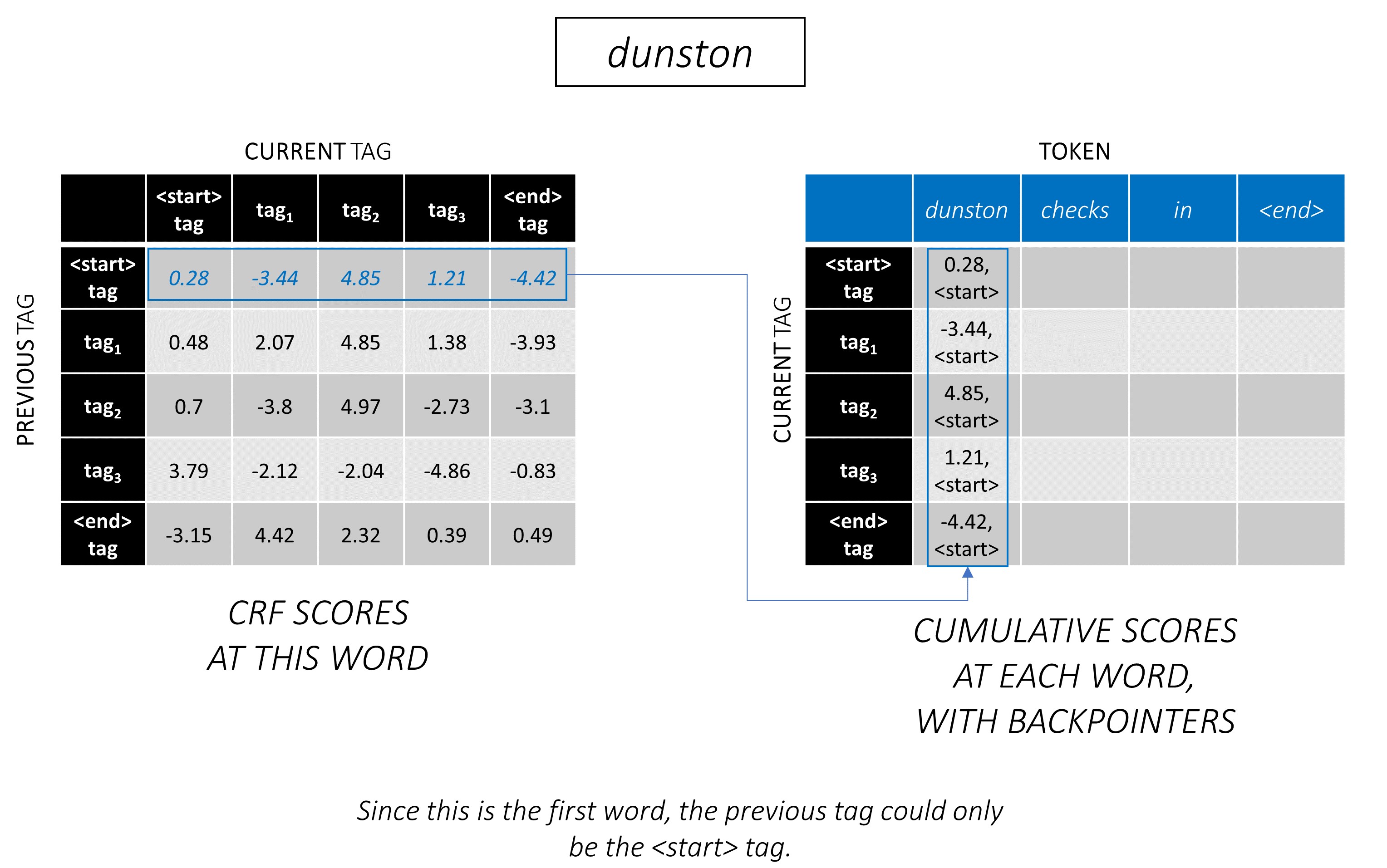
Мы также отслеживаем previous_tag , который соответствует каждому баллу. Они известны как бакульницы . При первом словом они, очевидно, все теги <start> .
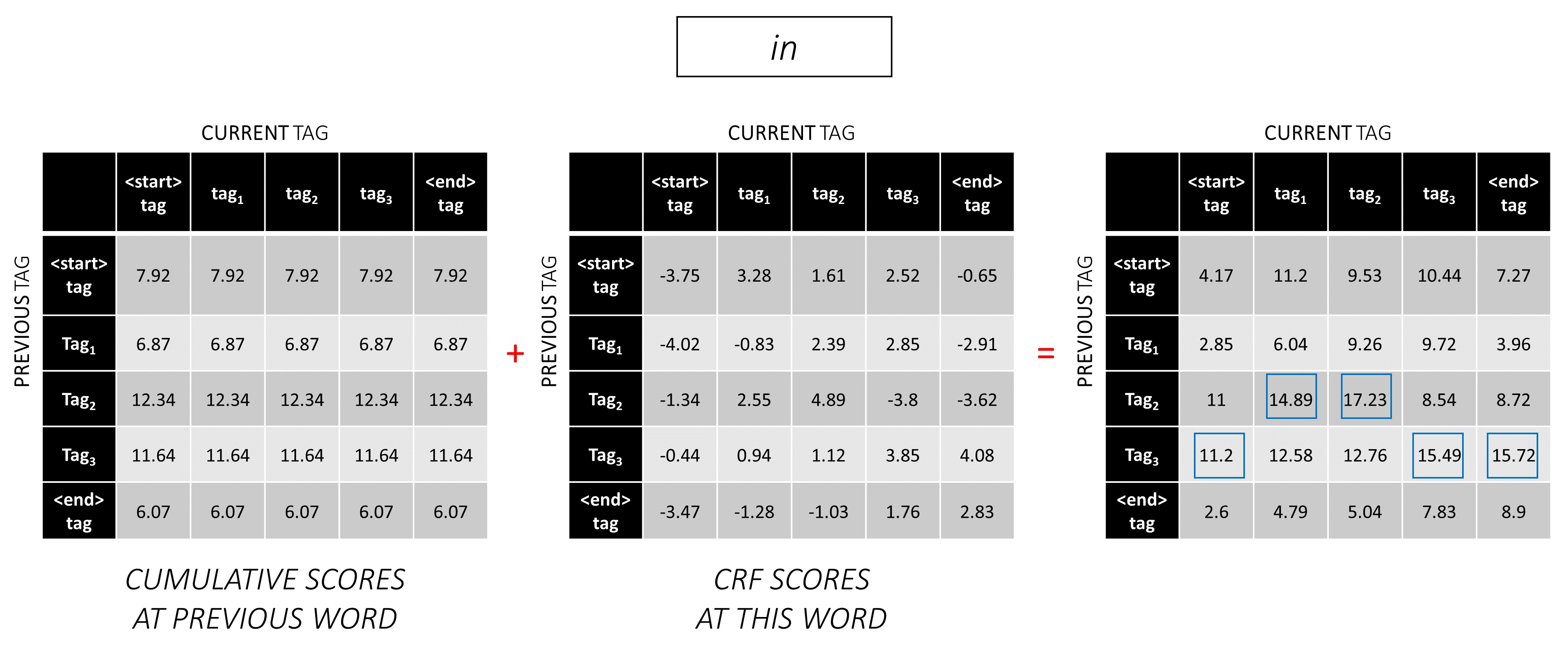
Во втором словом добавьте предыдущие кумулятивные оценки в результаты CRF этого слова, чтобы генерировать новые кумулятивные оценки .
Обратите внимание, что первое слово « current_tag » - это previous_tag слово второго слова. Поэтому транслируйте совокупную оценку первого слова по измерению current_tag .
Для каждого current_tag рассмотрите только максимум результатов от всех previous_tag s.
Храните бэки -точки, то есть предыдущие теги, которые соответствуют этим максимальным оценкам.

Повторите этот процесс на третьем словом.
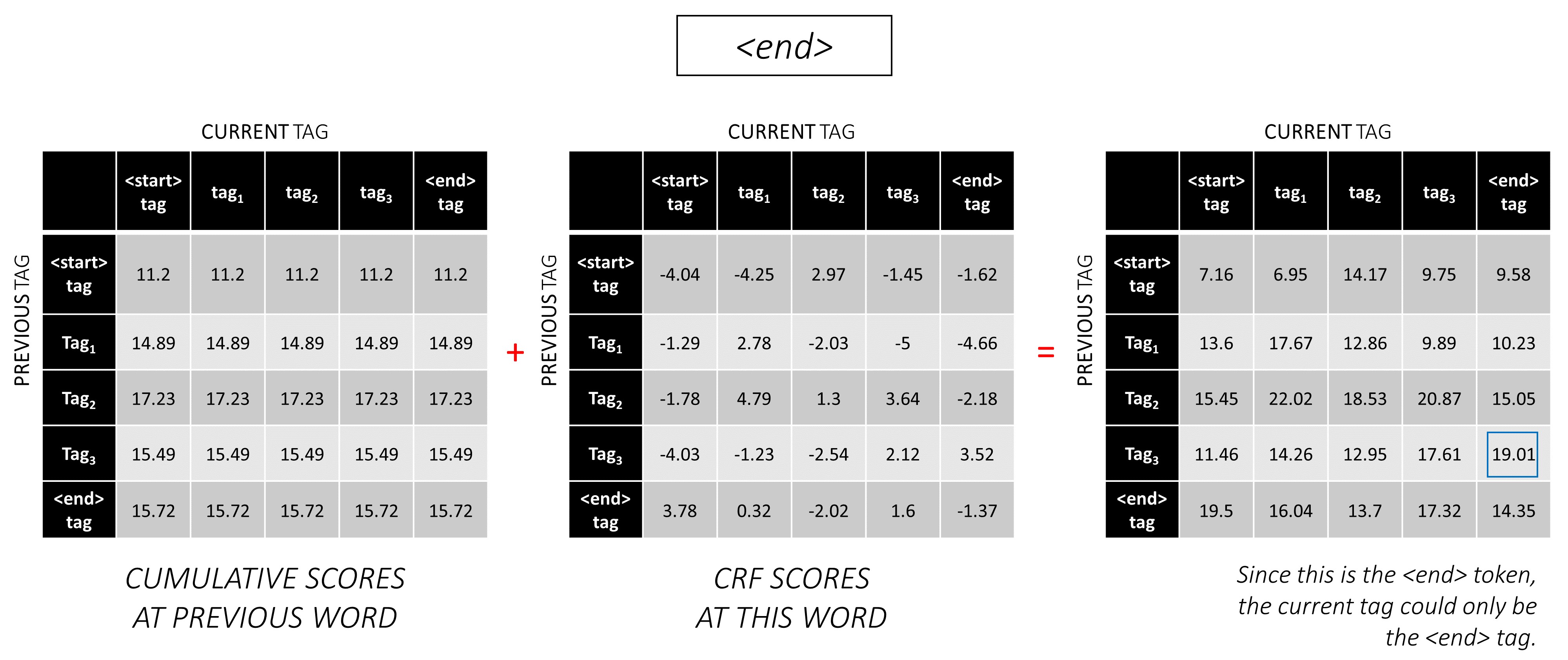
... и последнее слово, которое является токеном <end> .
Здесь единственная разница в том, что вы уже знаете правильный тег. Вам нужен максимальная оценка и бакла только для тега <end> .
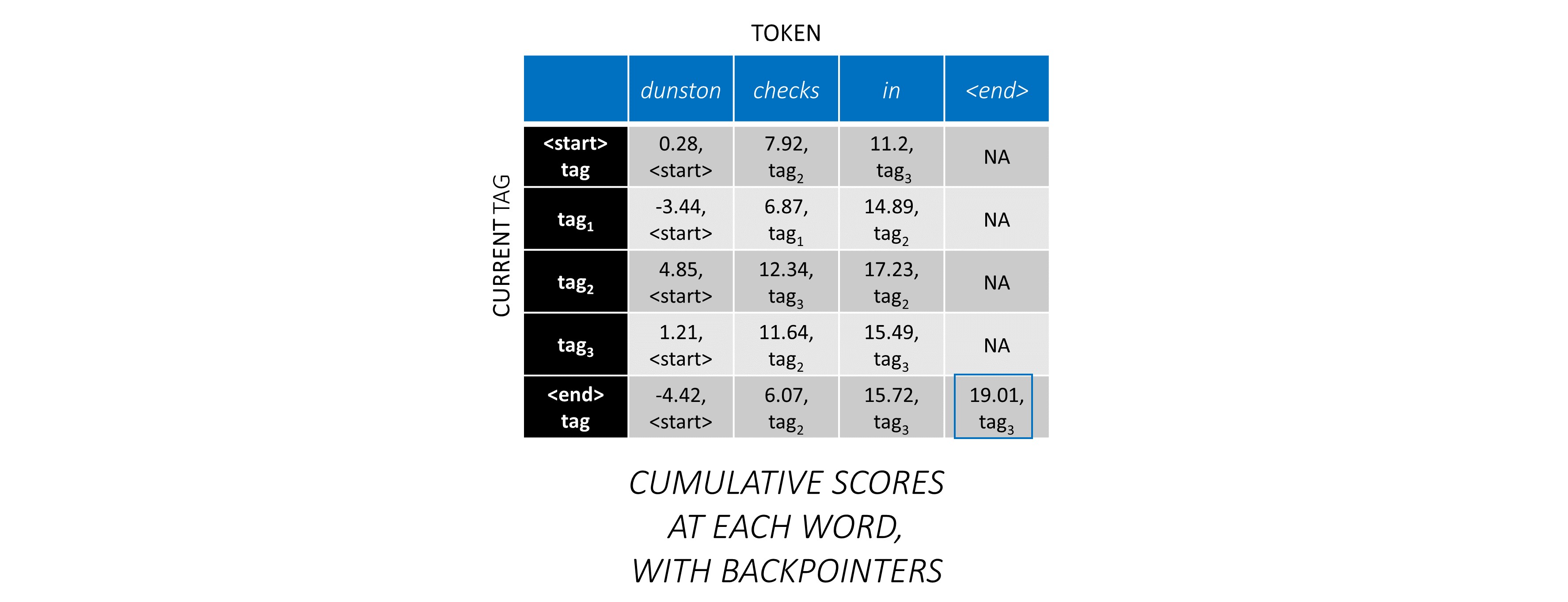
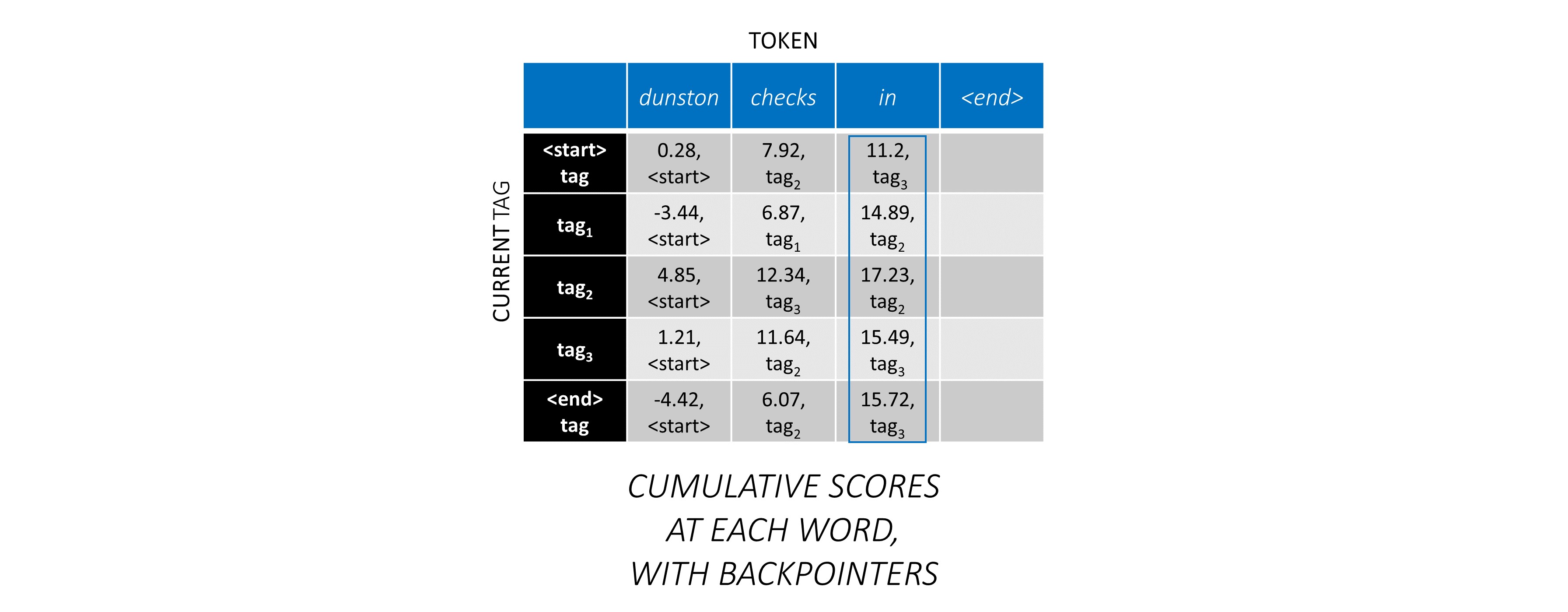
Теперь, когда вы накопили оценки CRF по всей последовательности, вы отслеживаете назад, чтобы раскрыть последовательность TAG с максимально возможной оценкой .
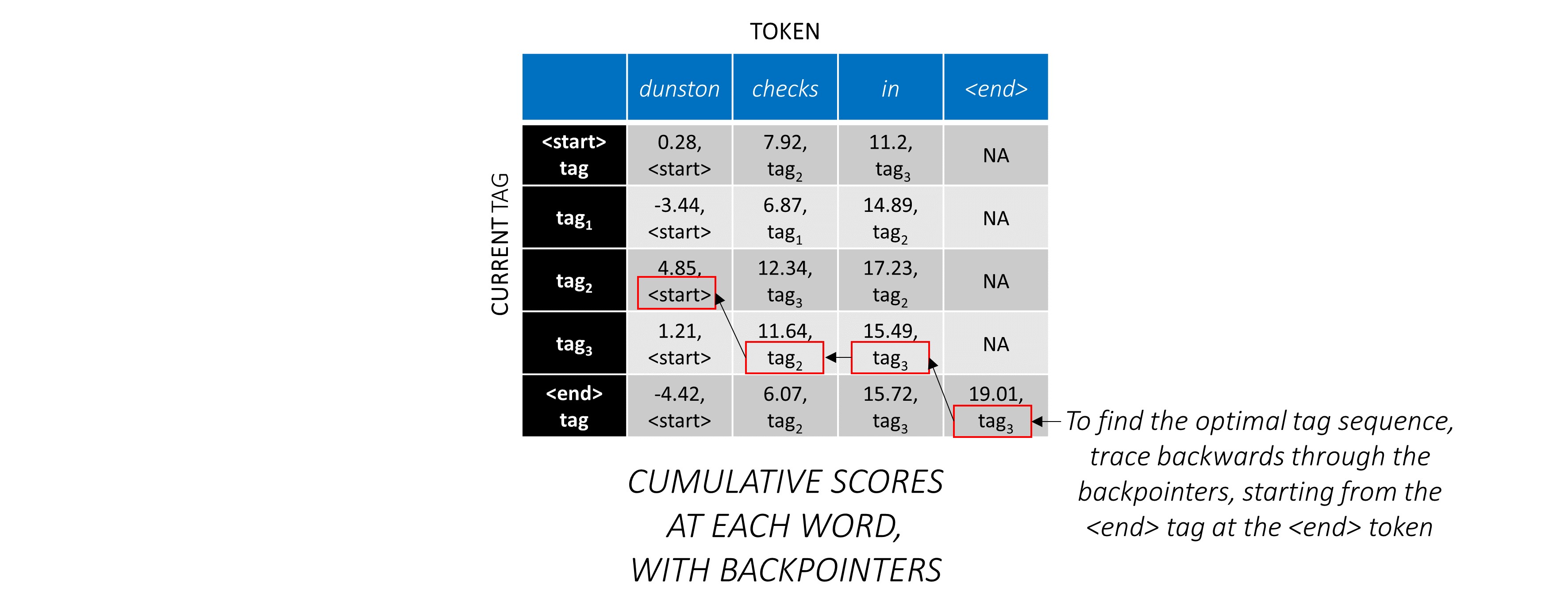
Мы находим, что наиболее оптимальная последовательность тегов для dunston checks in <end> IS tag_2 tag_3 tag_3 <end> .
В разделах ниже кратко описываются реализация.
Они предназначены для предоставления некоторого контекста, но детали лучше всего понимаются непосредственно из кода , что довольно много прокомментировано.
Я использую набор данных Conll 2003 NER для сравнения моих результатов с статьей.
Вот фрагмент -
-DOCSTART- -X- O O
EU NNP I-NP I-ORG
rejects VBZ I-VP O
German JJ I-NP I-MISC
call NN I-NP O
to TO I-VP O
boycott VB I-VP O
British JJ I-NP I-MISC
lamb NN I-NP O
. . O O
Этот набор данных не предназначен для публичного распределения, хотя вы можете найти его где -то в Интернете.
Есть несколько общедоступных наборов данных, которые вы можете использовать для обучения модели. Это не может быть на 100% человеческим аннотированным, но их достаточно.
Для метки NER вы можете использовать банк Groningen, означающий.
Для тега POS NLTK имеет небольшой набор данных, который вы можете получить с помощью nltk.corpus.treebank.tagged_sents() .
Вам придется либо преобразовать его в формат данных Conll 2003 NER, либо изменить код, упомянутый в разделе Data Pipeline.
Нам понадобится восемь входов.
Это слова последовательности, которые должны быть помечены.
dunston checks in
Как обсуждалось ранее, мы не будем использовать токены <start> , но нам нужно будет использовать <end> токены.
dunston, checks, in, <end>
Поскольку мы передаем предложения в виде тензоров фиксированного размера, нам нужно накладываться предложения (которые естественно имеют различную длину) до той же длины с токенами <pad> .
dunston, checks, in, <end>, <pad>, <pad>, <pad>, ...
Кроме того, мы создаем word_map , который является индексным отображением для каждого слова в корпусе, включая токены <end> и <pad> . Pytorch, как и другие библиотеки, нуждаются в словах, закодированных как индексы, чтобы искать для них внедрения или определить их место в прогнозируемых оценках слов.
4381, 448, 185, 4669, 0, 0, 0, ...
Следовательно, последовательности слов, подаваемые на модель, должны быть Int тензором размеров N, L_w где N - batch_size, а L_w - это мягкая длина последовательностей слов (обычно длина самой длинной последовательности слов).
Это последовательности символов в прямом направлении.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' '
Нам нужны токены <end> в последовательностях символов, чтобы соответствовать токену <end> в последовательностях слова. Поскольку мы собираемся использовать функции на уровне символов в каждом словом в последовательности слова, нам нужны функции уровня символов в <end> в последовательности слова.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>
Нам также нужно подумать о них.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>, <pad>, <pad>, <pad>, ...
И кодировать их с помощью char_map .
29, 2, 12, 8, 7, 14, 12, 3, 6, 18, 1, 6, 21, 8, 3, 17, 12, 3, 60, 0, 0, 0, ...
Следовательно, последовательности формированных символов, подаваемые на модель, должны быть Int измерений N, L_c , где L_c - это мягкая длина последовательностей символов (обычно длина самой длинной последовательности символов).
Это будет обработано так же, как и прямая последовательность, но назад. (Токены <end> все еще будут в конце, естественно.)
'n', 'i', ' ', 's', 'k', 'c', 'e', 'h', 'c', ' ', 'n', 'o', 't', 's', 'n', 'u', 'd', ' ', <end>, <pad>, <pad>, <pad>, ...
12, 17, 3, 8, 21, 6, 1, 18, 6, 3, 12, 14, 7, 8, 12, 2, 29, 3, 60, 0, 0, 0, ...
Следовательно, обратные последовательности символов, подаваемые на модель, должны быть Int измерений N, L_c .
Эти маркеры являются позициями в последовательностях символов , где мы извлекаем функции -
Мы будем извлекать функции в конце каждого пространства ' ' в последовательности символов и в токене <end> .
Для прямой последовательности символов мы извлекаем в -
7, 14, 17, 18
Это точки после dunston , checks , in , <end> соответственно. Таким образом, у нас есть маркер для каждого слова в последовательности слова , что имеет смысл. (Однако в языковых моделях, поскольку мы предсказываем следующее слово, мы не будем предсказать на маркере, который соответствует <end> ).)
Мы накладываем это с 0 с. Неважно, с чем мы продумываем до тех пор, пока они действительны. (Мы будем извлекать функции на прокладках, но мы не будем их использовать.)
7, 14, 17, 18, 0, 0, 0, ...
Они пролажены до полной длины словесных последовательностей, L_w .
Следовательно, форвардные маркеры персонажа, поданные на модель, должны быть Int измерений N, L_w .
Для маркеров в обратных последовательностях символов мы также находим позиции каждого пространства ' ' и токен <end> .
Мы также гарантируем, что эти позиции находятся в том же порядке слова , что и в прямом маркерах . Это выравнивание облегчает сознание функций, извлеченных из прямых и обратных последовательностей символов, а также предотвращает повторное заказ целей в языковых моделях.
17, 9, 2, 18
Это точки после notsnud , skcehc , ni , <end> соответственно.
Мы продушьем с 0 с.
17, 9, 2, 18, 0, 0, 0, ...
Следовательно, обратные маркеры символов, подаваемые на модель, должны быть Int измерений N, L_w .
Давайте предположим, что правильные теги для dunston, checks, in, <end>
tag_2, tag_3, tag_3, <end>
У нас есть tag_map (содержащий теги <start> , tag_1 , tag_2 , tag_3 , <end> ).
Обычно мы просто кодируем их напрямую (перед набивкой) -
2, 3, 3, 5
Это 1D -кодировки, т.е. позиции тегов в 1D -карте.
Но выходы слоя CRF составляют 2D m, m Tensors в каждом словом. Нам нужно будет кодировать позиции тегов в этих 2D выходах.
Правильные позиции метки отмечены красным.
(0, 2), (2, 3), (3, 3), (3, 4)
Если мы развернем эти оценки в тензоре 1D m*m , то положения тега в развернутом тензоре будут
tag_map [ previous_tag ] * len ( tag_map ) + tag_map [ current_tag ] Поэтому мы кодируем tag_2, tag_3, tag_3, <end>
2, 13, 18, 19
Обратите внимание, что вы можете получить исходные индексы tag_map , взяв модуль
t % len ( tag_map ) Они будут подкреплены до полной длины словесных последовательностей, L_w .
Следовательно, теги, подаваемые на модель, должны быть Int измерений N, L_w .
Это фактическая длина последовательностей слов, включая токены <end> . Поскольку Pytorch поддерживает динамические графики, мы будем вычислять только на эти длины, а не через <pads> .
Следовательно, длина слова, подаваемая на модель, должна быть Int измерений N .
Это фактические длины последовательностей символов, включая токены <end> . Поскольку Pytorch поддерживает динамические графики, мы будем вычислять только на эти длины, а не через <pads> .
Следовательно, длина символов, подаваемая на модель, должна быть Int измерений N .
См. read_words_tags() в utils.py .
Это считывает входные файлы в формате Conll 2003 и извлекает последовательности слова и теги.
См. create_maps() в utils.py .
Здесь мы создаем карты кодирования для слов, символов и тегов. We bin rare words and characters as <unk> s (unknowns).
См. create_input_tensors() в utils.py .
Мы генерируем восемь входов, подробно описанные в разделе «Входы в модель».
См. load_embeddings() в utils.py .
Мы загружаем предварительно обученные встраивания, с возможностью расширения word_map , чтобы включить вне качества слова, присутствующие в словарном заряде. Note that this may also include rare in-corpus words that were binned as <unk> s earlier.
См. WCDataset в datasets.py .
Это подкласс Dataset Pytorch. Ему нужен определенный метод __len__ , который возвращает размер набора данных, и метод __getitem__ , который возвращает набор i входов в модель.
Dataset будет использоваться Pytorch DataLoader в train.py для создания и подачи партий данных в модель для обучения или проверки.
Смотрите Highway в models.py .
Преобразование представляет собой рельсоактивированное линейное преобразование ввода. Вторник представляет собой линейное преобразование ввода, активируемое сигмоидами. Обратите внимание, что оба преобразования должны быть такого же размера, что и вход , чтобы позволить добавлять вход в остаточное соединение.
num_layers Атрибут специфично, сколько операций преобразования-ворота-резидуального соединения мы выполняем последовательно. Обычно только одного достаточно.
Мы храним необходимое количество слоев преобразования и затвора в отдельных ModuleList() s и используем for цикла для выполнения последовательных операций.
См. LM_LSTM_CRF в models.py .
В самом начале мы сортируем первые и обратные последовательности символов, уменьшая длину . Это необходимо для использования pack_padded_sequence() , чтобы LSTM вычислил только только действительные временные рамки, т.е. истинная длина последовательностей.
Не забудьте также сортировать все другие тензоры в одном порядке.
См. dynamic_rnn.py для иллюстрации того, как pack_padded_sequence() может использоваться для использования преимуществ динамического графика и партии Pytorch, чтобы мы не обрабатывали прокладки. Он выравнивает отсортированные последовательности путем временного тома, игнорируя прокладки, а LSTM вычисляет только эффективный размер партии N_t в каждом временном разделе .
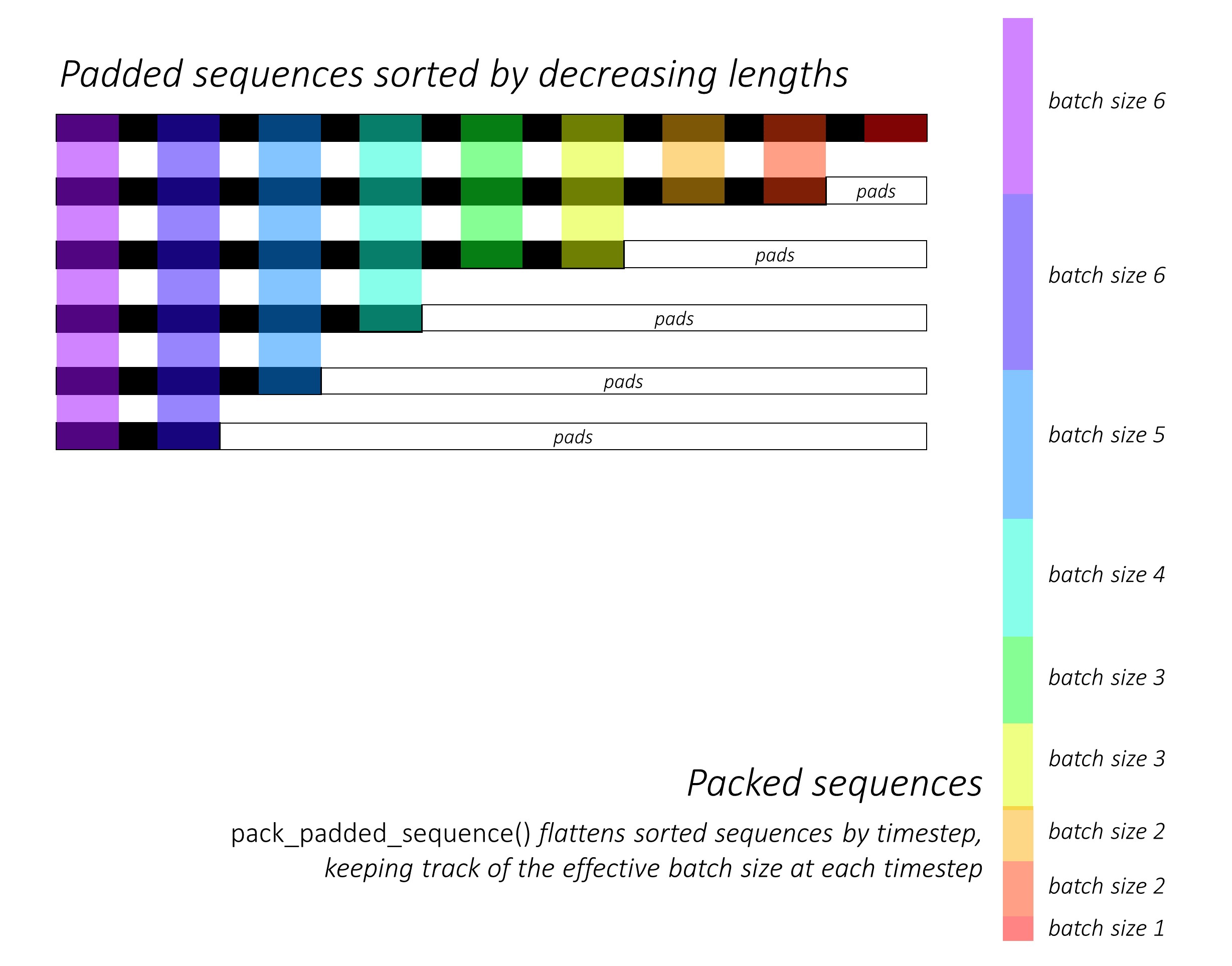
Сортировка позволяет верхнему N_t при любом временном шаге соответствовать выходам с предыдущего шага . Например, в третьем времени мы обрабатываем только 5 лучших изображений, используя 5 лучших выходов с предыдущего шага. За исключением сортировки, все это обрабатывается внутри Pytorch, но все еще очень полезно понять, что делает pack_padded_sequence() , чтобы мы могли использовать его в других сценариях для достижения аналогичных целей. (См. Связанный вопрос об обработке последовательностей переменной длины в разделе часто задаваемых вопросов.)
После сортировки мы применяем форвардные и обратные LSTM на прямой и обратной packed_sequences соответственно. Мы используем pad_packed_sequence() для нерадосения и повторно выпускайте выходы.
Мы извлекаем только выходы на передовые и обратные маркеры символов с gather . Эта функция очень полезна для извлечения только определенных индексов из тензора, которые указаны в отдельном тензоре.
Эти извлеченные выходы обрабатываются переходными и обратными уровнями шоссе, прежде чем применять линейный слой для вычисления баллов по словарному запасу для прогнозирования следующего слова на каждом маркере. Мы делаем это только во время обучения, поскольку не имеет смысла выполнять языковое моделирование для многозадачного обучения во время проверки или вывода. training атрибут любой модели установлен с помощью model.train() или model.eval() в train.py . (Обратите внимание, что это в первую очередь используется для включения или отключения слоев отсева и партии в модели Pytorch во время обучения и вывода соответственно.)
См. LM_LSTM_CRF в models.py (продолжение).
Мы также сортируем последовательности слов путем уменьшения длины , потому что не всегда может быть корреляция между длиной последовательностей слова и последовательностями символов.
Не забудьте также сортировать все другие тензоры в одном порядке.
Мы объединяем выходы LSTM вперед и назад на маркерах и запускаем его через третий слой шоссе . Это извлечет информацию о подлоде в каждом словом, которое мы будем использовать для маркировки последовательности.
Мы объединяем этот результат со словом «Встроены» и вычисляем выходы BLSTM через packed_sequence .
После повторной прохождения с помощью pad_packed_sequence() у нас есть функции, которые нам необходимы для подачи на слой CRF.
См. CRF в models.py .
Вы можете обнаружить, что этот слой удивительно прост, учитывая значение, которое он добавляет к нашей модели.
Линейный слой используется для преобразования выходов из BLSTM в оценки для каждого тега, которые являются оценками выбросов .
Один тензор используется для хранения баллов перехода . Этот тензор является Parameter модели, что означает, что он обновляется во время обработки, как и веса других слоев.
Чтобы найти результаты CRF, вычислите результаты выбросов в каждом словом и добавьте их к оценкам перехода , после трансляции оба, как описано в обзоре CRF.
См. ViterbiLoss в models.py .
В обзоре потерь Витерби мы установили, что мы хотим минимизировать разницу между логарифмическим эксплуатацией показателей всех возможных допустимых последовательностей тегов и оценкой последовательности золотых тегов , т.е. log-sum-exp(all scores) - gold score .
Мы суммируем оценки CRF каждого истинного тега, как описано ранее, чтобы рассчитать оценку золота .
Помните, как мы закодировали последовательности тегов с их позициями в распущенных результатах CRF? Мы извлекаем баллы на этих позициях с помощью gather() и устраняем прокладки с помощью pack_padded_sequences() перед суммированием.
Поиск логарифмического эксплуатации показателей всех возможных последовательностей немного сложнее. Мы используем for цикла, чтобы итерация над временными точками. В каждом временномме мы накапливаем оценки для каждого current_tag с помощью -
current_tag для каждого previous_tag . Мы делаем это только при эффективном размере партии, т.е. для последовательностей, которые еще не завершены. (Наши последовательности по-прежнему отсортированы по уменьшению длины слов, по модели LM-LSTM-CRF .)current_tag вычислите журнал SUM-EXP по previous_tag , чтобы найти новые накопленные оценки на каждом current_tag . После вычисления по переменной длине всех последовательностей у нас остается тензор измерений N, m , где m - количество (текущих) тегов. Это накопленные оценки log-sum-exp по всем возможным последовательностям, заканчивающимися в каждом из m метров. Однако, поскольку допустимые последовательности могут заканчиваться только с тегом <end> , суммируйте только столбец <end> , чтобы найти логарифм-sum-exp из баллов всех возможных допустимых последовательностей .
Мы находим разницу, log-sum-exp(all scores) - gold score .
См. ViterbiDecoder в inference.py .
Это реализует процесс, описанный в обзоре декодирования Viterbi.
Мы накапливаем баллы в цикле for цикла аналогично тому, что мы делали в ViterbiLoss , за исключением того, что здесь мы находим максимум previous_tag баллов_tag для каждого current_tag , вместо того, чтобы вычислять логарифмический EXP. Мы также отслеживаем previous_tag , который соответствует этому максимальному баллу в тензоре Backpointer.
Мы накладываем тенсор Backpointer с тегами <end> , потому что это позволяет нам проследить назад по прокладкам, в конечном итоге достигая фактического тега <end> , после чего начинается фактическая обратная передача .
Смотрите train.py .
Параметры для модели (и обучения ее) находятся в начале файла, поэтому вы можете легко проверить или изменить их, если хотите.
Чтобы обучить свою модель с нуля , просто запустите этот файл -
python train.py
Чтобы возобновить обучение на контрольно -пропускной пункте , укажите на соответствующий файл с параметром checkpoint в начале кода.
Обратите внимание, что мы выполняем проверку в конце каждой эпохи обучения.
Вы заметите, что мы обрезаем входы в каждой партии до максимальной длины последовательности в этой партии . Это так, что у нас нет больше прокладок в каждой партии, которая нам действительно нужна.
Но почему? Хотя RNN в нашей модели не вычисляют на прокладки, линейные слои все еще делают . Это довольно прямо, чтобы изменить это - см. Связанный вопрос об обработке последовательностей переменной длины в разделе часто задаваемых вопросов.
Для этого урока я подумал, что немного дополнительных вычислений по некоторым прокладкам стоило простой необходимости не выполнять множество операций - шоссе, CRF, другие линейные слои, конкатенации - на packed_sequence . Sequence.
В сценарии с несколькими задачами мы решили суммировать потери поперечной энтропии из двух задач по моделированию языка и потери витерби из задачи маркировки последовательности.
Несмотря на то, что мы минимизируем сумму этих потерь , мы на самом деле заинтересованы только в минимизации потери Витерби в силу минимизации суммы этих потерь . Это потеря Витерби, которая отражает производительность на основной задаче.
Мы используем pack_padded_sequence() для устранения прокладки, где бы это ни было необходимо.
Как и в газете, мы используем средний макрос, в качестве критерия для раннего перерыва . Естественно, вычисление показателя F1 требует декодирования Viterbi оценки CRF для генерации наших оптимальных последовательностей тегов.
Мы используем pack_padded_sequence() для устранения прокладки, где бы это ни было необходимо.
Я как можно ближе следовал параметрам в реализации авторов.
Я использовал размеры партии 10 предложений. Я использовал стохастический градиент спуск с импульсом. Скорость обучения была распадана каждую эпоху. Я использовал 100D перчатки, предварительно подготовленные без точной настройки.
Потребовалось около 80 -х годов, чтобы тренировать одну эпоху на титане X (Паскаль).
Оценка F1 по набору валидации достигла 91% вокруг Epoch 50 и достиг пика на уровне 91.6% в эпох 171. Я запустил его в общей сложности 200 эпох. Это довольно близко к результатам в статье.
Вы можете скачать эту предварительную модель здесь.
Как мы решаем, нужны ли нам токены <start> и <end> для модели, которая использует последовательности?
Если это кажется сбивающим с толку, это будет легко, это будет легко разрешить себя, когда вы думаете о требованиях модели, которую вы планируете обучить.
Для маркировки последовательности с помощью CRF вам нужен токен <end> ( или токен <start> ; см. Следующий вопрос) из -за того, как структурированы оценки CRF.
В моем другом уроке по подписанию изображения я использовал токены <start> и <end> . Модель должна была где -то начать декодировать и научиться распознавать, когда прекратить декодирование во время вывода.
Если вы выполняете классификацию текста, вам не нужно ни того, ни другого.
Можем ли мы иметь CRF генерировать current_word -> next_word -результаты вместо previous_word -> current_word
Да. В этом случае вы будете транслировать результаты выбросов, такие как L, m, _ , и у вас будет токен <start> в каждом предложении вместо токена <end> . Правильным тегом токена <start> всегда будет тегом <start> . «Следующим тегом» последнего слова всегда будет тег <end> .
Я думаю, что previous word -> current word немного лучше, потому что в миксе есть языковые модели. It fits in quite nicely to be able to predict the <end> token at the last real word, and therefore learn to recognize when a sentence is complete.
Why are we using different vocabularies for the sequence tagger's inputs and language models' outputs?
The language models will learn to predict only those words it has seen during training. It's really unnecessary, and a huge waste of computation and memory, to use a linear-softmax layer with the extra ~400,000 out-of-corpus words from the embedding file it will never learn to predict.
But we can add these words to the input layer even if the model never sees them during training. This is because we're using pre-trained embeddings at the input. It doesn't need to see them because the meanings of words are encoded in these vectors. If it's encountered a chimpanzee before, it very likely knows what to do with an orangutan .
Is it a good idea to fine-tune the pre-trained word embeddings we use in this model?
I refrain from fine-tuning because most of the input vocabulary is not in-corpus. Most embeddings will remain the same while a few are fine-tuned. If fine-tuning changes these embeddings sufficiently, the model may not work well with the words that weren't fine-tuned. In the real world, we're bound to encounter many words that weren't present in a newspaper corpus from 2003.
What are some ways we can construct dynamic graphs in PyTorch to compute over only the true lengths of sequences?
If you're using an RNN, simply use pack_padded_sequence() . PyTorch will internally compute over only the true lengths. See dynamic_rnn.py for an example.
If you want to execute an operation (like a linear transformation) only on the true timesteps, pack_padded_sequences() is still the way to go. This flattens the tensor by timestep while removing the pads. You can perform your operation on this flattened tensor, and then use pad_packed_sequence() to unflatten it and re-pad it with 0 s.
Similarly, if you want to perform an aggregation operation, like computing the loss, use pack_padded_sequences() to eliminate the pads.
If you want to perform timestep-wise operations, you can take a leaf out of how pack_padded_sequences() works, and compute only on the effective batch size at each timestep with a for loop to iterate over the timesteps. We did this in the ViterbiLoss and ViterbiDecoder . I also used an LSTMCell() in this fashion in my image captioning tutorial.
Dunston Checks In ? Действительно?
I had no memory of this movie for twenty years. I was trying to think of a short sentence that would be easier to visualize in this tutorial and it just popped into my mind riding a wave of 90s nostalgia.

I wish I hadn't googled it though. Damn, the critics were harsh, weren't they? This gem was overwhelmingly and universally panned. I'm not sure I'd disagree if I watched it now, but that just goes to show the world is so much more fun when you're a kid.
Didn't have to worry about LM-LSTM-CRFs or nuthin...


