a PyTorch Tutorial to Sequence Labeling
1.0.0
Este es un tutorial de Pytorch para el etiquetado de secuencia .
Este es el segundo de una serie de tutoriales que escribo sobre la implementación de modelos geniales por su cuenta con la increíble biblioteca de Pytorch.
Se supone que el conocimiento básico de las redes neuronales recurrentes, recurrentes.
Si eres nuevo en Pytorch, primero lea el aprendizaje profundo con Pytorch: un bombardeo de 60 minutos y aprendizaje de Pytorch con ejemplos.
Las preguntas, sugerencias o correcciones se pueden publicar como problemas.
Estoy usando PyTorch 0.4 en Python 3.6 .
27 de enero de 2020 : Se ha agregado código de trabajo para dos tutoriales nuevos: súper resolución y traducción automática
Objetivo
Conceptos
Descripción general
Implementación
Capacitación
Preguntas frecuentes
Para construir un modelo que pueda etiquetar cada palabra en una oración con entidades, partes del habla, etc.

Implementaremos el etiquetado de la secuencia Empower con el documento del modelo de lenguaje neural consciente de las tareas . Esto es más avanzado que la mayoría de los modelos de etiquetado de secuencia, pero aprenderá muchos conceptos útiles, y funciona extremadamente bien. La implementación original de los autores se puede encontrar aquí.
Este modelo es especial porque aumenta la tarea de etiquetado de secuencia al capacitarla simultáneamente con los modelos de idiomas.
Etiquetado de secuencia . duh.
Modelos de idiomas . El modelado de lenguaje es predecir la siguiente palabra o carácter en una secuencia de palabras o caracteres. Los modelos de lenguaje neuronal logran resultados impresionantes en una amplia variedad de tareas de PNL como generación de texto, traducción automática, subtitulación de imágenes, reconocimiento de caracteres ópticos y lo que tiene.
Personaje RNNS . Se sabe que los RNN que operan en caracteres individuales en un texto capturan el estilo y la estructura subyacentes. En una tarea de etiquetado de secuencia, son especialmente útiles ya que la información de sub-word a menudo puede producir pistas importantes a una entidad o etiqueta.
Aprendizaje de varias tareas . Los conjuntos de datos disponibles para entrenar un modelo son a menudo pequeños. Crear anotaciones o características artesanales para ayudar a su modelo no solo es engorroso, sino que con frecuencia no es adaptable a los diversos dominios o configuraciones en los que su modelo puede ser útil. El marcado de secuencia, desafortunadamente, es un excelente ejemplo. Hay una manera de mitigar este problema: capacitar conjuntamente múltiples modelos que se unen a la cadera maximizarán la información disponible para cada modelo, mejorando el rendimiento.
Campos aleatorios condicionales . Los clasificadores discretos predicen una clase o etiqueta en una palabra. Los campos aleatorios condicionales (CRF) pueden hacerle uno mejor: predicen etiquetas basadas no solo en la palabra, sino también en el vecindario. Lo que tiene sentido, porque hay patrones en una secuencia de entidades o etiquetas. Los CRF se usan ampliamente para modelar información ordenada, ya sea para el etiquetado de secuencias, la secuenciación génica o incluso la detección de objetos y la segmentación de imágenes en la visión por computadora.
Viterbi decodificación . Dado que estamos usando CRF, no estamos prediciendo tanto la etiqueta correcta en cada palabra, ya que estamos prediciendo la secuencia de la etiqueta correcta para una secuencia de palabras. La decodificación de Viterbi es una forma de hacer exactamente esto: encuentre la secuencia de etiqueta más óptima de las puntuaciones calculadas por un campo aleatorio condicional.
Redes de carreteras . Las capas totalmente conectadas son un elemento básico en cualquier red neuronal para transformar o extraer características en diferentes ubicaciones. Las redes de carreteras logran esto, pero también permiten que la información fluya sin obstáculos a través de las transformaciones. Esto hace que las redes profundas sean mucho más eficientes o factibles.
En esta sección, presentaré una descripción general de este modelo. Si ya está familiarizado con él, puede omitir directamente a la sección de implementación o al código comentado.
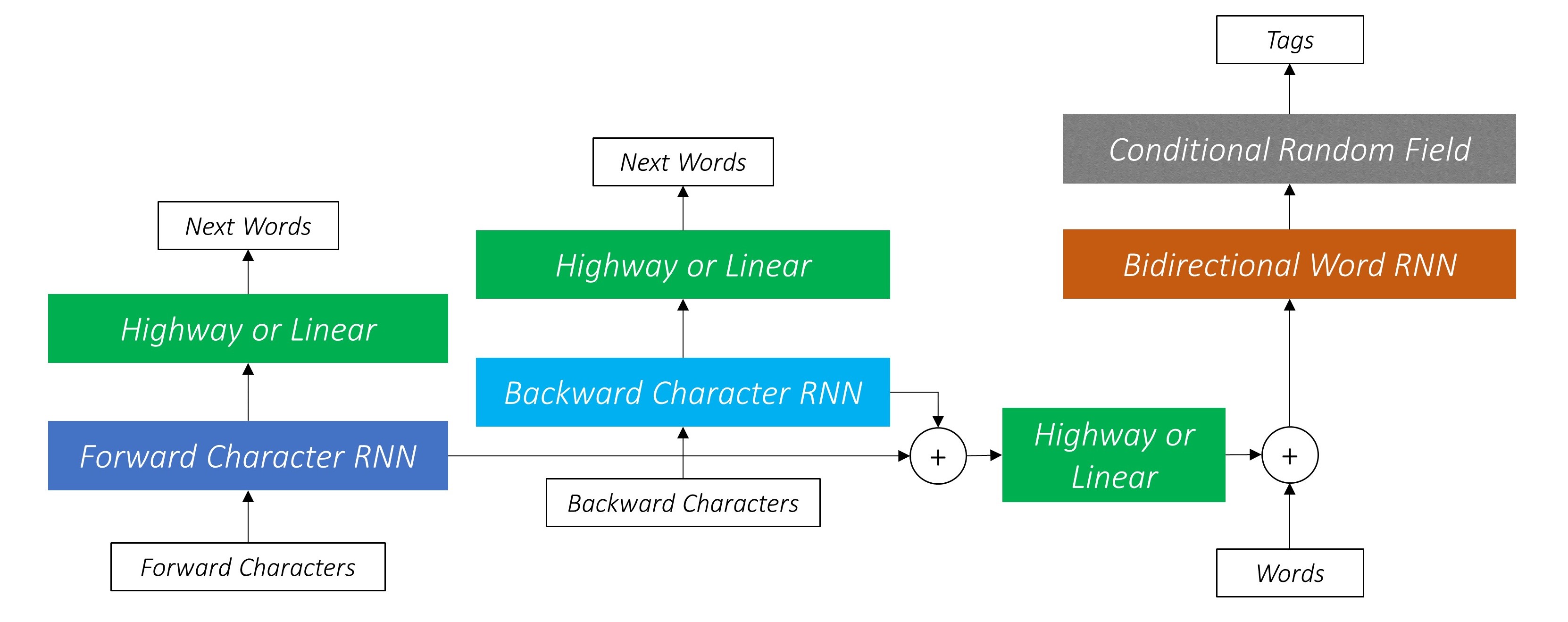
Los autores se refieren al modelo como el modelo de lenguaje: campo a largo plazo a corto plazo, un campo aleatorio condicional ya que implica modelos de lenguaje de entrenamiento con una combinación LSTM + CRF .
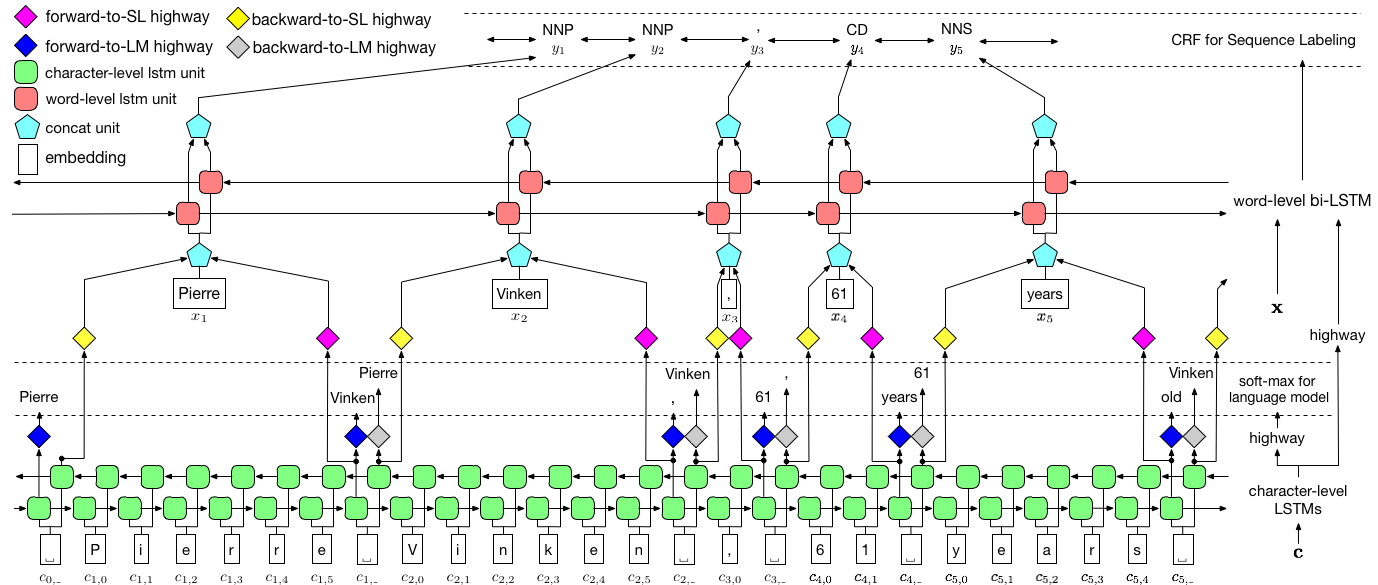
Esta imagen del papel representa a fondo todo el modelo, pero no se preocupe si parece demasiado compleja en este momento. Lo desglosaremos para echar un vistazo más de cerca a los componentes.
El aprendizaje de varias tareas es cuando simultáneamente entrena un modelo en dos o más tareas.
Por lo general, solo estamos interesados en una de estas tareas: en este caso, el etiquetado de la secuencia.
Pero cuando las capas en una red neuronal contribuyen a realizar múltiples funciones, aprenden más de lo que habrían si hubieran entrenado solo en la tarea principal. Esto se debe a que la información extraída en cada capa se amplía para acomodar todas las tareas. Cuando hay más información para trabajar, el rendimiento en la tarea principal se mejora .
Enriquecer las características existentes de esta manera elimina la necesidad de usar características artesanales para el etiquetado de secuencia.
La pérdida total durante el aprendizaje de varias tareas suele ser una combinación lineal de las pérdidas en las tareas individuales. Los parámetros de la combinación se pueden solucionar o aprender como pesos actualizables.

Dado que agregamos pérdidas individuales, puede ver cómo las capas aguas arriba compartidas por múltiples tareas recibirían actualizaciones de todas ellas durante el retroceso.
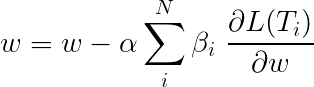
Los autores del documento simplemente agregan las pérdidas ( β=1 ), y haremos lo mismo.
Echemos un vistazo a las tareas que componen nuestro modelo.
Hay tres .

Esto aprovecha la información de la sub-palabras para predecir la siguiente palabra.
Hacemos lo mismo en la dirección hacia atrás. 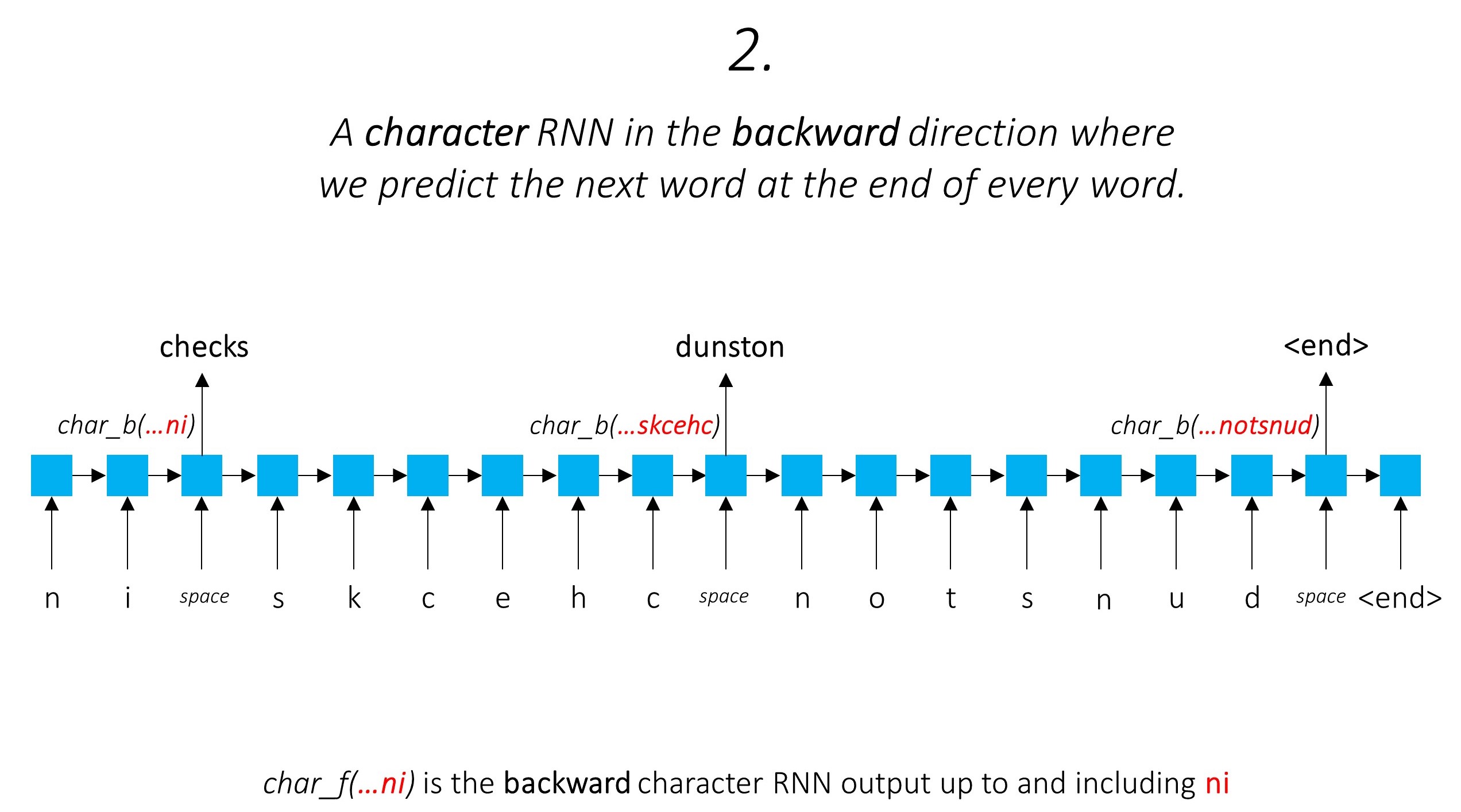
También usamos las salidas de estos dos rnns de caracteres como entradas a nuestro campo RNN y condicional (CRF) de Word-RNN (CRF) para realizar nuestra tarea principal de etiquetado de secuencia. 
Estamos utilizando información de sub-palabras en nuestra tarea de etiquetado porque puede ser un poderoso indicador de las etiquetas, ya sean partes del habla o las entidades. Por ejemplo, puede aprender que los adjetivos comúnmente terminan con "-y" o "-ul", o que los lugares a menudo terminan con "-land" o "-burg".
Pero nuestras características de sub-palabras, a saber. Las salidas de los RNN de caracteres también se enriquecen con información adicional : el conocimiento que necesita para predecir la siguiente palabra en direcciones hacia adelante y hacia atrás, debido a los modelos 1 y 2.
Por lo tanto, nuestro modelo de etiquetado de secuencia usa ambos
El LSTM/RNN bidireccional codifica estas características en nuevas características en cada palabra que contiene información sobre la palabra y su vecindario, tanto en el nivel de palabras como en el nivel de caracteres. Esto forma la entrada al campo aleatorio condicional.
Sin un CRF, simplemente habríamos usado una sola capa lineal para transformar la salida del LSTM bidireccional en puntajes para cada etiqueta. Estos se conocen como puntajes de emisión , que son una representación de la probabilidad de que la palabra sea una determinada etiqueta.
Un CRF calcula no solo los puntajes de emisión sino también los puntajes de transición , que son la probabilidad de que una palabra sea una determinada etiqueta considerando que la palabra anterior era una determinada etiqueta. Por lo tanto, los puntajes de transición miden la probabilidad de que la transición de una etiqueta a otra.
Si hay etiquetas m , los puntajes de transición se almacenan en una matriz de dimios m, m , donde las filas representan la etiqueta de la palabra anterior y las columnas representan la etiqueta de la palabra actual. Un valor en esta matriz en la posición i, j es la probabilidad de transición de la etiqueta i en la palabra anterior a la etiqueta j en la palabra actual . A diferencia de los puntajes de emisión, los puntajes de transición no se definen para cada palabra en la oración. Son globales.
En nuestro modelo, la capa CRF genera el agregado de los puntajes de emisión y transición en cada palabra .
Para una oración de longitud L , los puntajes de emisión serían un tensor L, m Dado que los puntajes de emisión en cada palabra no dependen de la etiqueta de la palabra anterior, creamos una nueva dimensión como L, _, m y transmitir (copiar) el tensor en esta dirección para obtener un tensor L, m, m
Los puntajes de transición son un tensor m, m Dado que los puntajes de transición son globales y no dependen de la palabra, creamos una nueva dimensión como _, m, m y transmitir (copiar) el tensor en esta dirección para obtener un tensor L, m, m
Ahora podemos agregarlos para obtener los puntajes totales que son un tensor L, m, m Un valor en la posición k, i, j es el agregado de la puntuación de emisión de la etiqueta j en la palabra k y la puntuación de transición de la etiqueta j en la palabra k que consideraba la palabra anterior era i etiqueta.
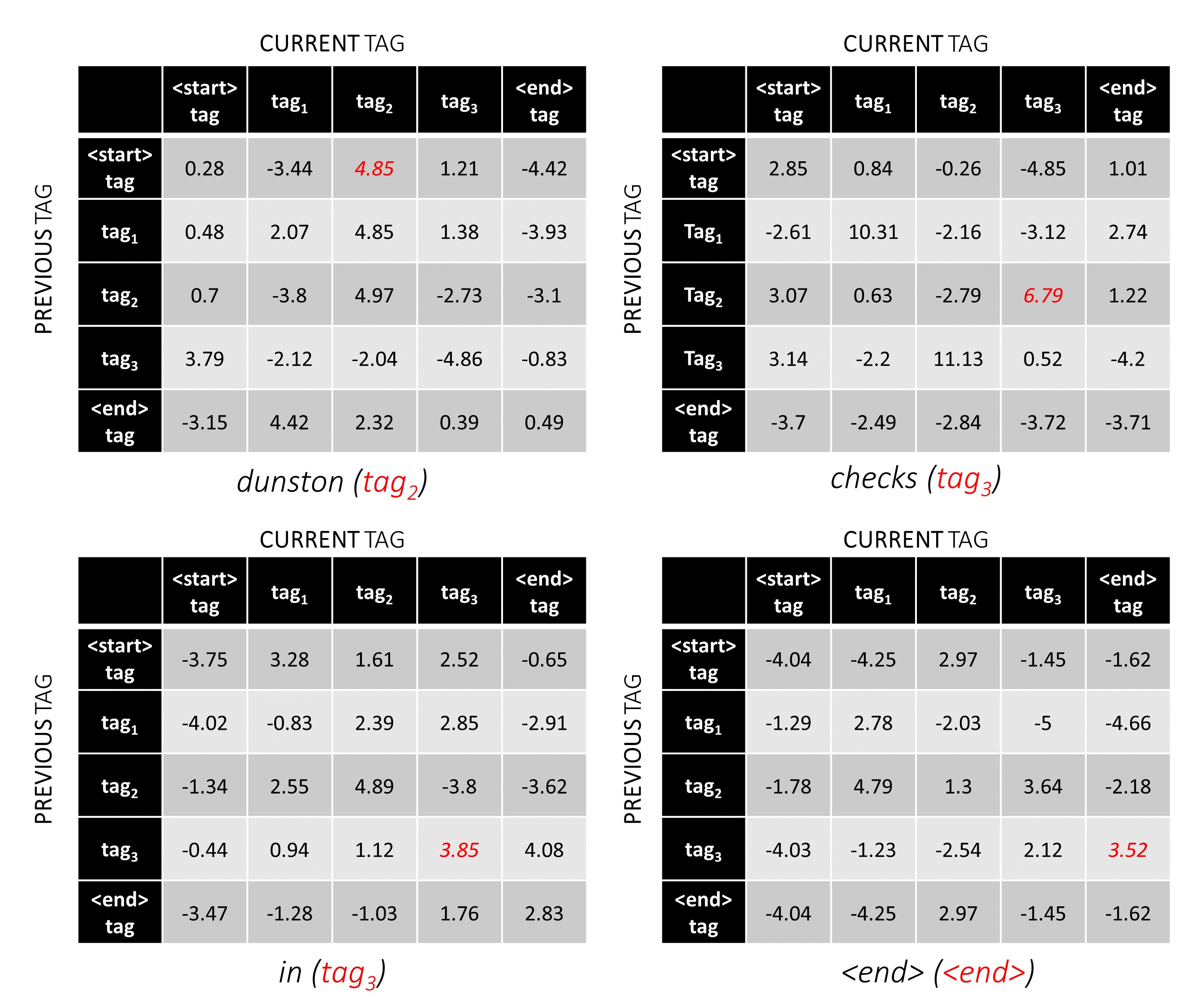
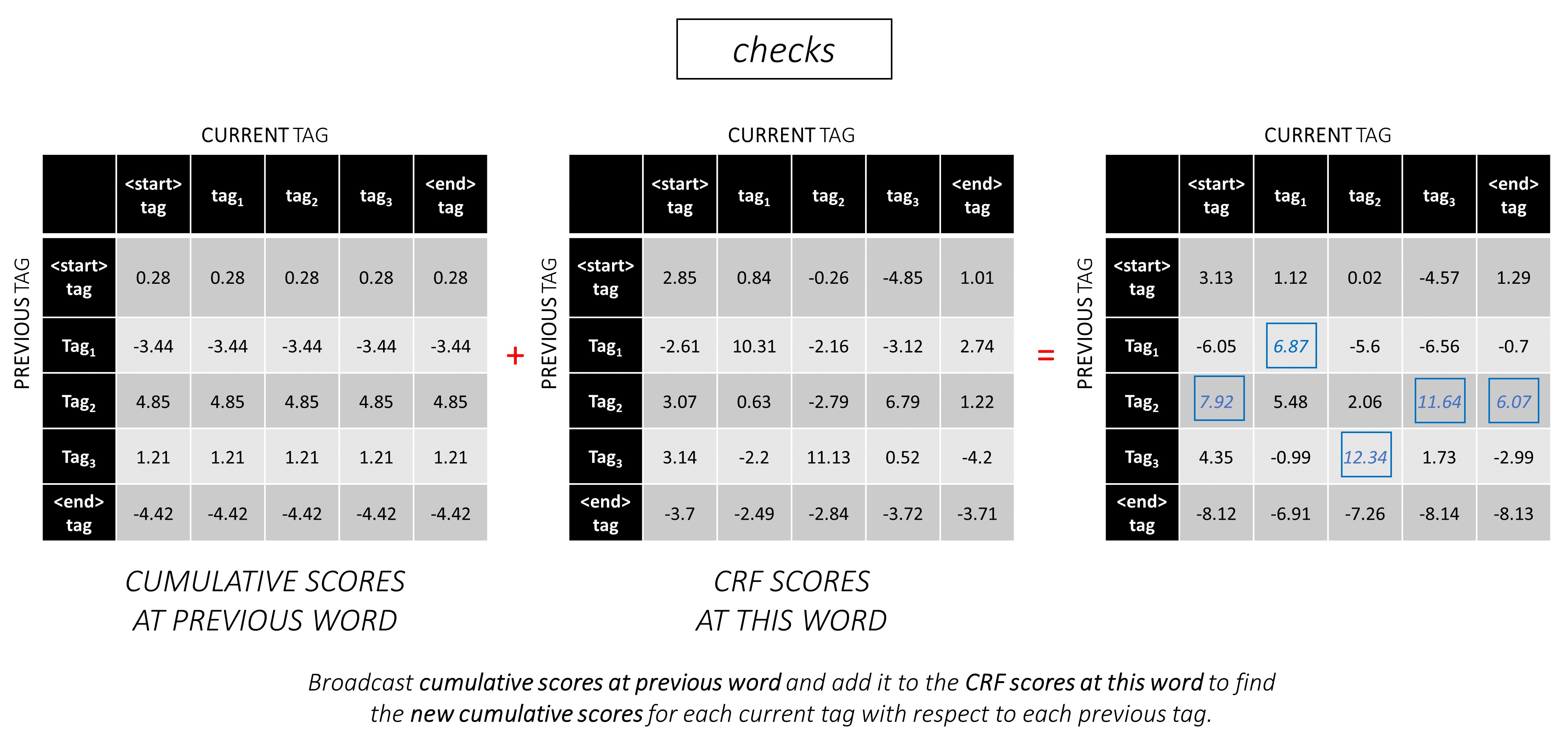
Para nuestra oración de ejemplo, dunston checks in <end> , si suponemos que hay 5 etiquetas en total, los puntajes totales se verían así,
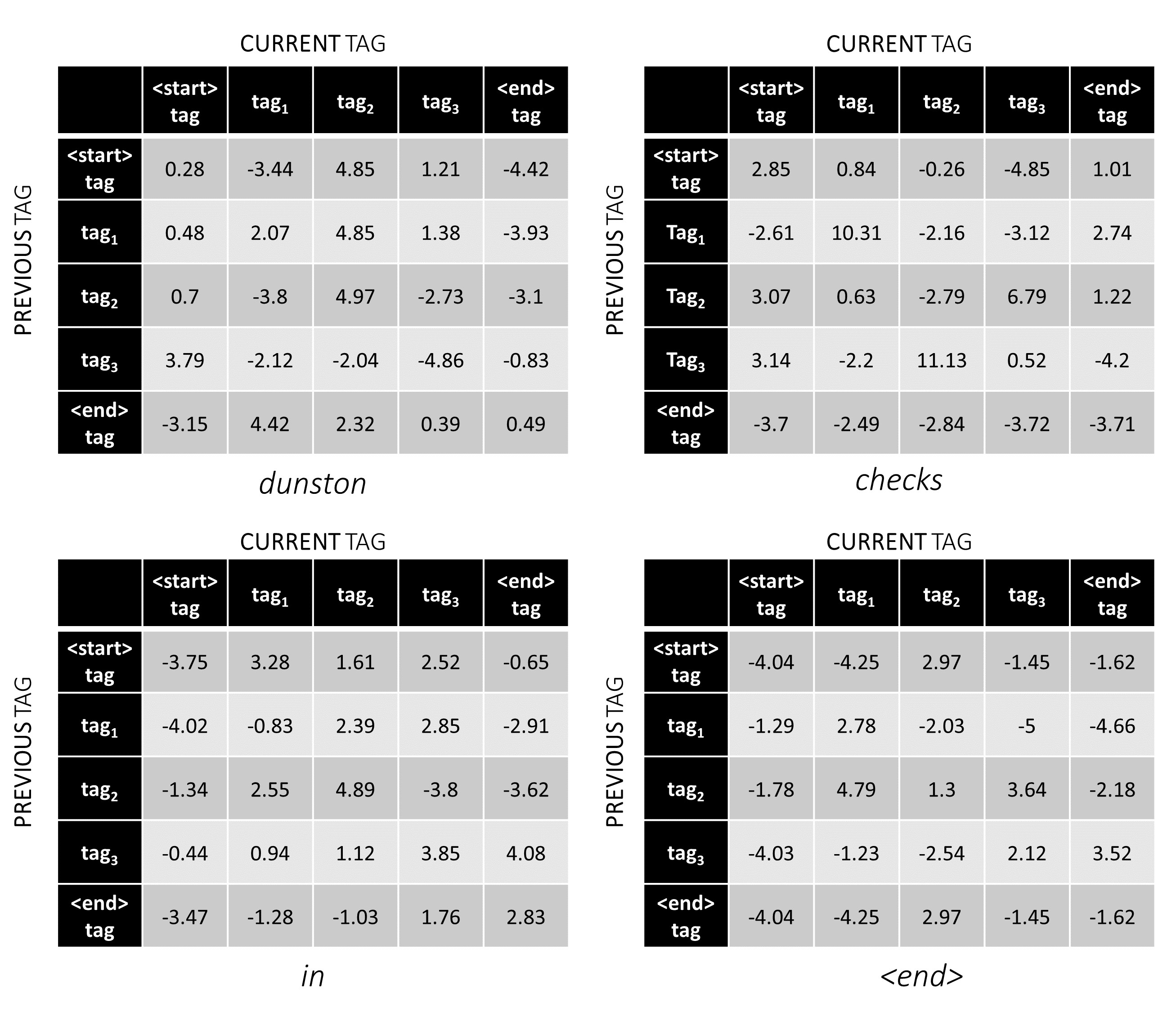
Pero espera un minuto, ¿por qué hay etiquetas <start> end <end> end>? Mientras lo hacemos, ¿por qué estamos usando un token <end> ?
<start> y <end> etiquetas, <start> y <end> tokens Dado que estamos modelando la probabilidad de transición entre etiquetas, también incluimos una etiqueta <start> y una etiqueta <end> en nuestro conjunto de etiquetas.
La puntuación de transición de una determinada etiqueta dado que la etiqueta anterior era una etiqueta <start> representa la probabilidad de que esta etiqueta sea la primera etiqueta en una oración . Por ejemplo, las oraciones generalmente comienzan con artículos (A, An, The) o sustantivos o pronombres.
El puntaje de transición de la etiqueta <end> considerando una determinada etiqueta anterior indica la probabilidad de que esta etiqueta anterior sea la última etiqueta en una oración .
Usaremos un token <end> en todas las oraciones y no un token <start> porque las puntuaciones totales de CRF en cada palabra se definen con respecto a la etiqueta de la palabra anterior , lo que no tendría sentido en un token <start> .
La etiqueta correcta del token <end> es siempre la etiqueta <end> . La "etiqueta anterior" de la primera palabra es siempre la etiqueta <start> .
Para ilustrar, si nuestra oración de ejemplo dunston checks in <end> tenía las etiquetas tag_2, tag_3, tag_3, <end> , los valores en rojo indican los puntajes de estas etiquetas.
Generalmente usamos capas lineales activadas para transformar y procesar salidas de un RNN/LSTM.
Si está familiarizado con las conexiones residuales, podemos agregar la entrada antes de la transformación a la salida transformada, creando una ruta para el flujo de datos alrededor de la transformación.
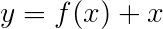
Este camino es un atajo para el flujo de gradientes durante la propagación de retroceso, y ayuda a la convergencia de redes profundas.
Una red de carreteras es similar a una red residual, pero utilizamos una puerta activada por sigmoide para determinar la relación en la que se combina la entrada y la salida transformada .
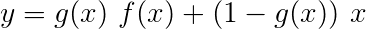
Dado que los RNN de caracteres contribuyen a múltiples tareas, las redes de carreteras se utilizan para extraer información específica de tareas de sus salidas.
Por lo tanto, utilizaremos redes de carreteras en tres ubicaciones en nuestro modelo combinado:
En una configuración ingenua de entrenamiento, donde usamos las salidas de los RNN de caracteres directamente para múltiples tareas, es decir, sin transformación, la discordancia entre la naturaleza de las tareas podría dañar el rendimiento.
Puede estar claro a estas alturas cómo se ve nuestra red combinada.
Eliminación progresiva de las partes de nuestra red los resultados en redes progresivamente más simples que se utilizan ampliamente para el etiquetado de secuencia.
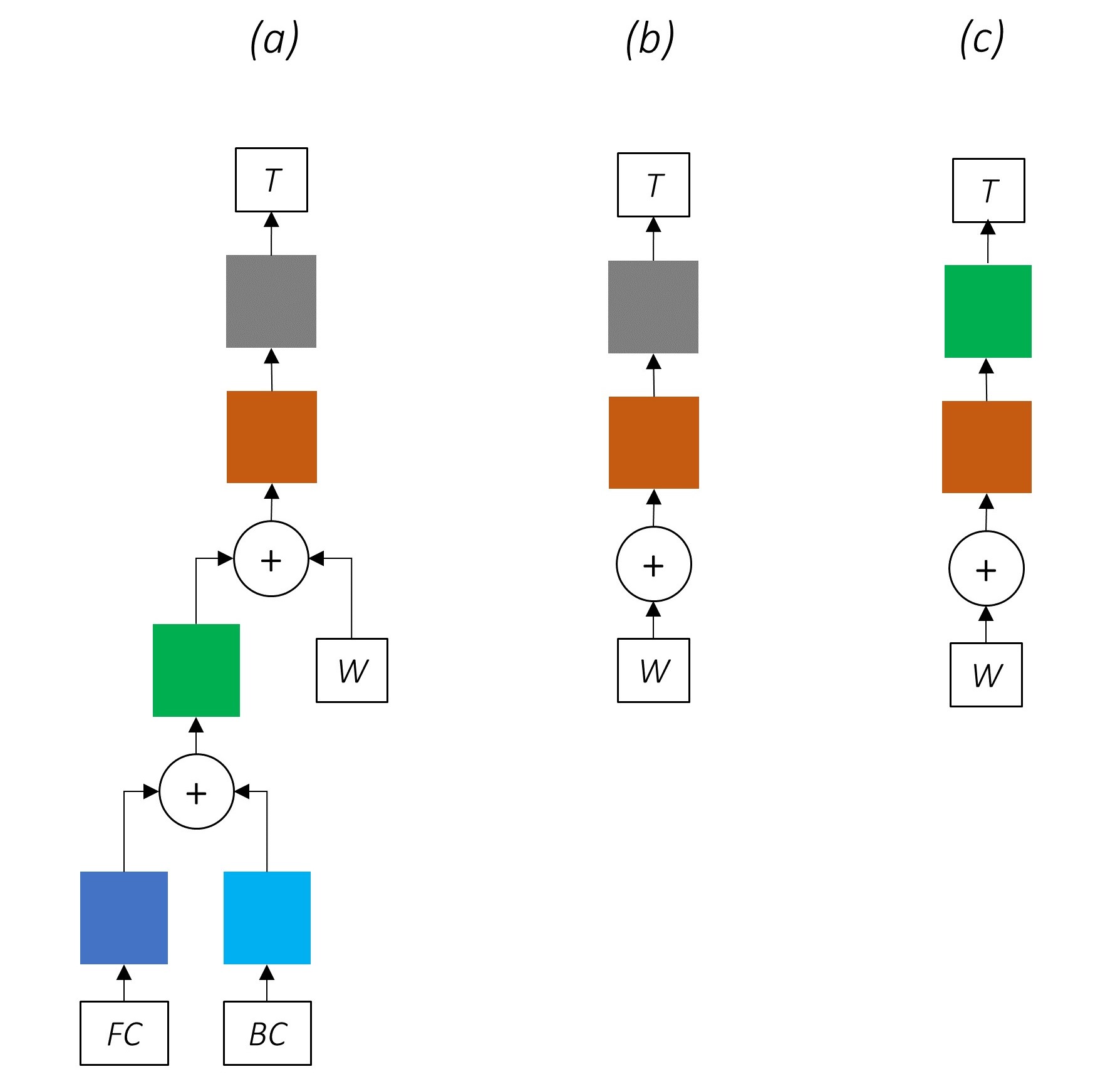
No hay aprendizaje de varias tareas.
El uso de información a nivel de personaje sin entrenamiento conjunto aún mejora el rendimiento.
No hay aprendizaje de varias tareas o procesamiento a nivel de carácter.
Esta configuración se usa con bastante frecuencia en la industria y funciona bien.
No hay aprendizaje de tareas múltiples, procesamiento a nivel de carácter o crfing. Tenga en cuenta que una capa lineal o de carretera reemplazaría a este último.
Esto podría funcionar razonablemente bien, pero un campo aleatorio condicional proporciona un impulso de rendimiento considerable.
Recuerde, no estamos usando una capa lineal que calcule solo los puntajes de emisión. La entropía cruzada no es una métrica de pérdida adecuada.
En su lugar, usaremos la pérdida de Viterbi que, como la entropía cruzada, es una "probabilidad de registro negativa". Pero aquí mediremos la probabilidad de la secuencia de la etiqueta de oro (verdadero), en lugar de la probabilidad de la etiqueta verdadera en cada palabra en la secuencia. Para encontrar la probabilidad, consideramos el Softmax sobre las puntuaciones de todas las secuencias de etiquetas.
La puntuación de una secuencia de etiqueta t se define como la suma de las puntuaciones de las etiquetas individuales.

Por ejemplo, considere los puntajes de CRF que observamos anteriormente -
La puntuación de la secuencia de etiqueta tag_2, tag_3, tag_3, <end> tag es la suma de los valores en rojo, 4.85 + 6.79 + 3.85 + 3.52 = 19.01 .
La pérdida de Viterbi se define como
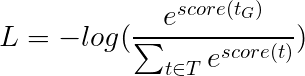
donde t_G es la secuencia de etiqueta de oro y T representa el espacio de todas las secuencias de etiqueta posibles.
Esto simplifica para -
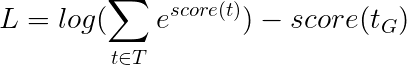
Por lo tanto, la pérdida de Viterbi es la diferencia entre el log-sum-Exp de las puntuaciones de todas las secuencias de etiquetas posibles y la puntuación de la secuencia de etiqueta de oro , es decir, log-sum-exp(all scores) - gold score .
La decodificación de Viterbi es una forma de construir la secuencia de etiqueta más óptima, considerando no solo la probabilidad de una etiqueta en una determinada palabra (puntajes de emisión), sino también la probabilidad de una etiqueta considerando las etiquetas anteriores y próximas (puntajes de transición).
Una vez que genera puntuaciones de CRF en una matriz L, m, m para una secuencia de longitud L , comenzamos a decodificar.
La decodificación de Viterbi se entiende mejor con un ejemplo. Considere nuevamente -
Para la primera palabra en la secuencia, el previous_tag solo puede ser <start> . Por lo tanto, solo considere esa fila.
Estos también son los puntajes acumulativos para cada current_tag en la primera palabra.
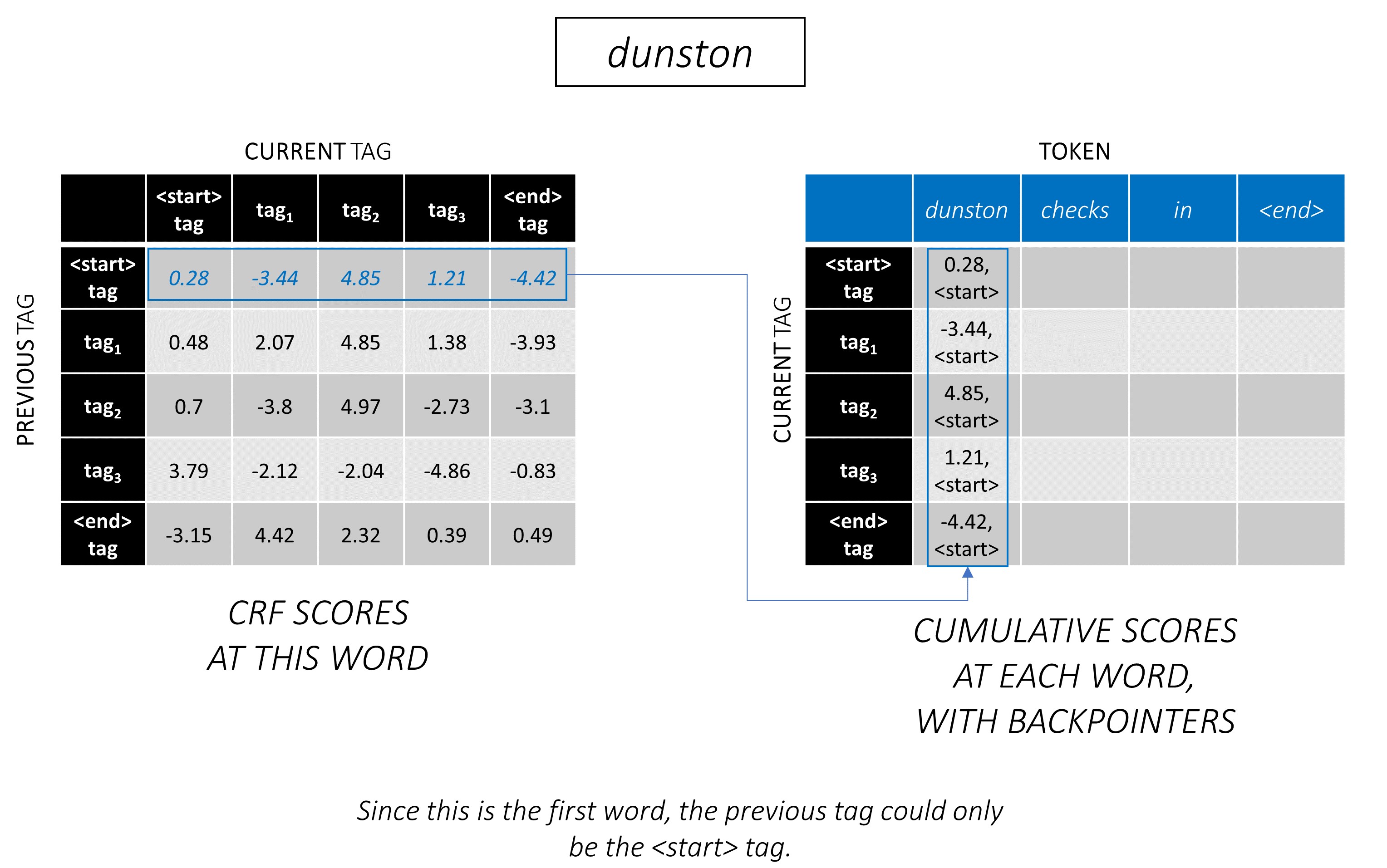
También realizaremos un seguimiento del previous_tag que corresponde a cada puntaje. Estos se conocen como backpointers . En la primera palabra, obviamente son todas las etiquetas <start> .
En la segunda palabra, agregue los puntajes acumulativos anteriores a las puntuaciones de CRF de esta palabra para generar nuevas puntuaciones acumulativas .
Tenga en cuenta que la primera palabra current_tag s es la segunda palabra previous_tag s. Por lo tanto, transmita la puntuación acumulativa de la primera palabra a lo largo de la dimensión current_tag .
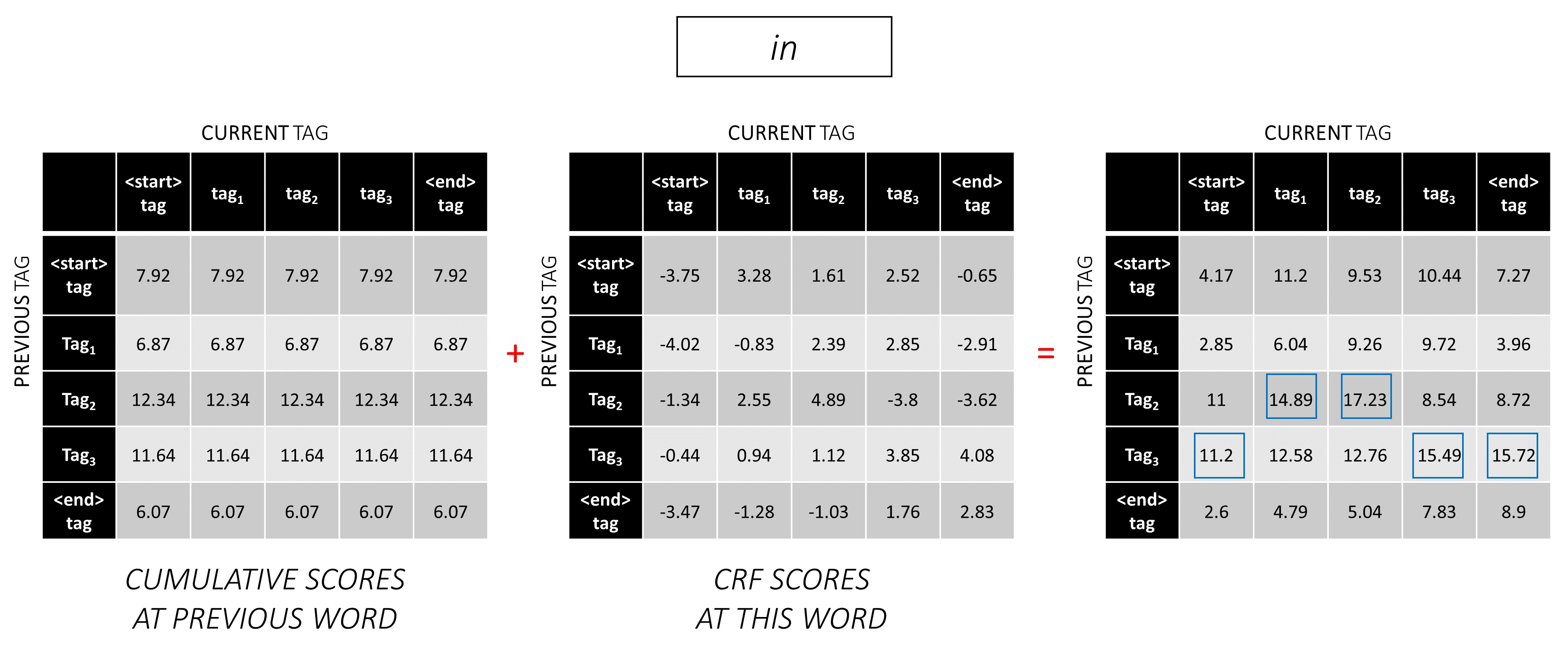
Para cada current_tag , considere solo el máximo de los puntajes de todos previous_tag s.
Almacene backpointers, es decir, las etiquetas anteriores que corresponden a estos puntajes máximos.

Repita este proceso en la tercera palabra.
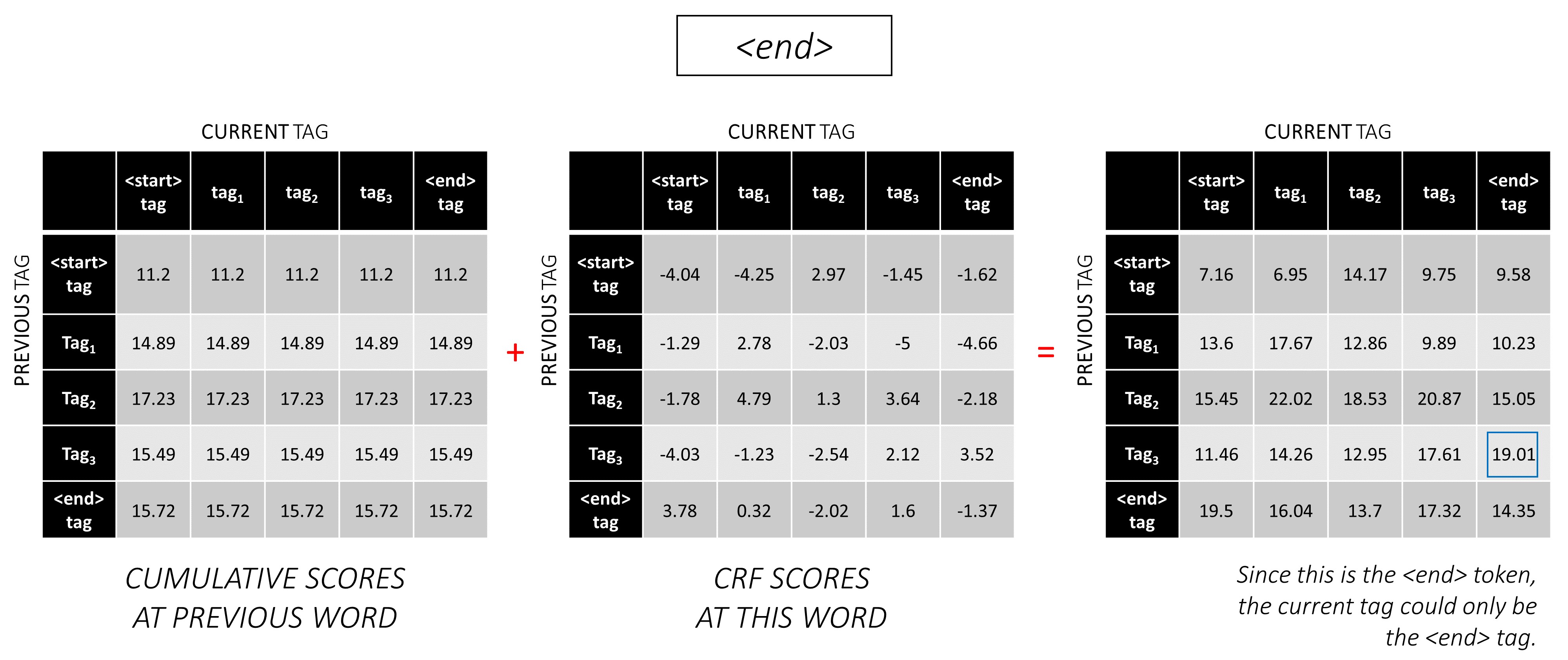
... y la última palabra, que es el token <end> .
Aquí, la única diferencia es que ya conoces la etiqueta correcta. Necesita la puntuación máxima y el mejor de los breve solo para la etiqueta <end> .
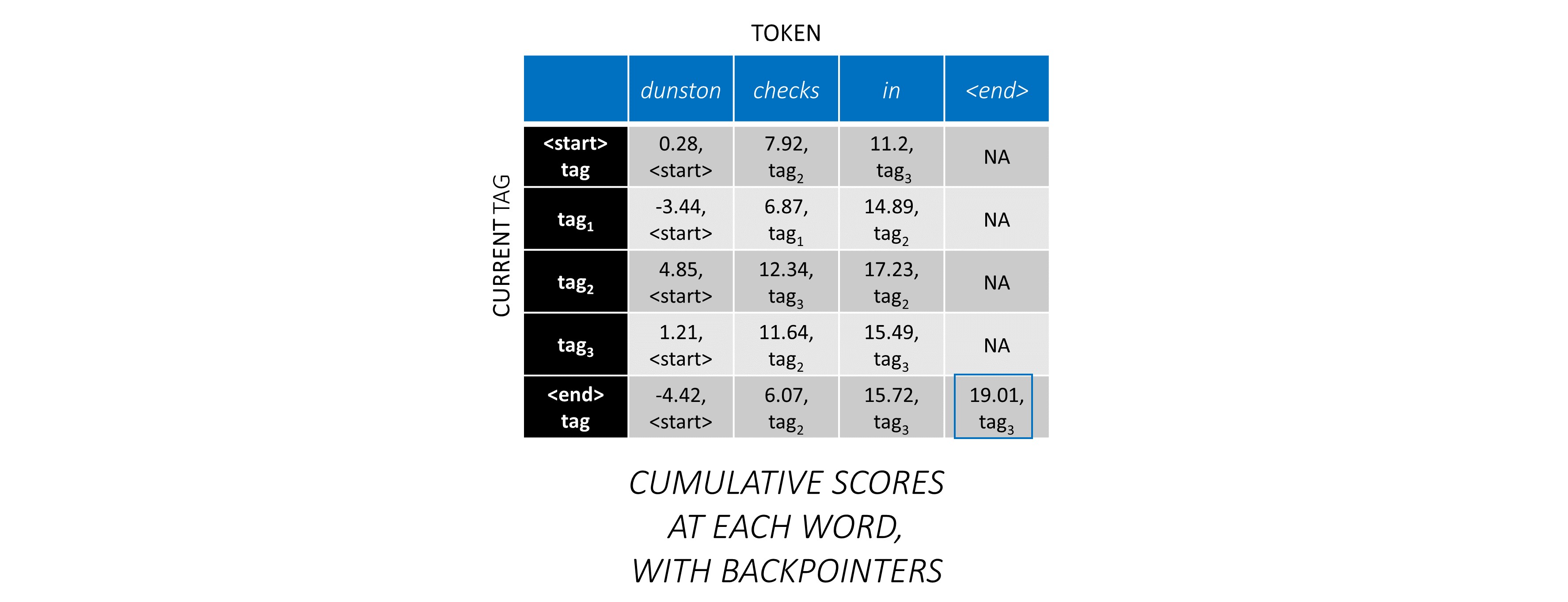
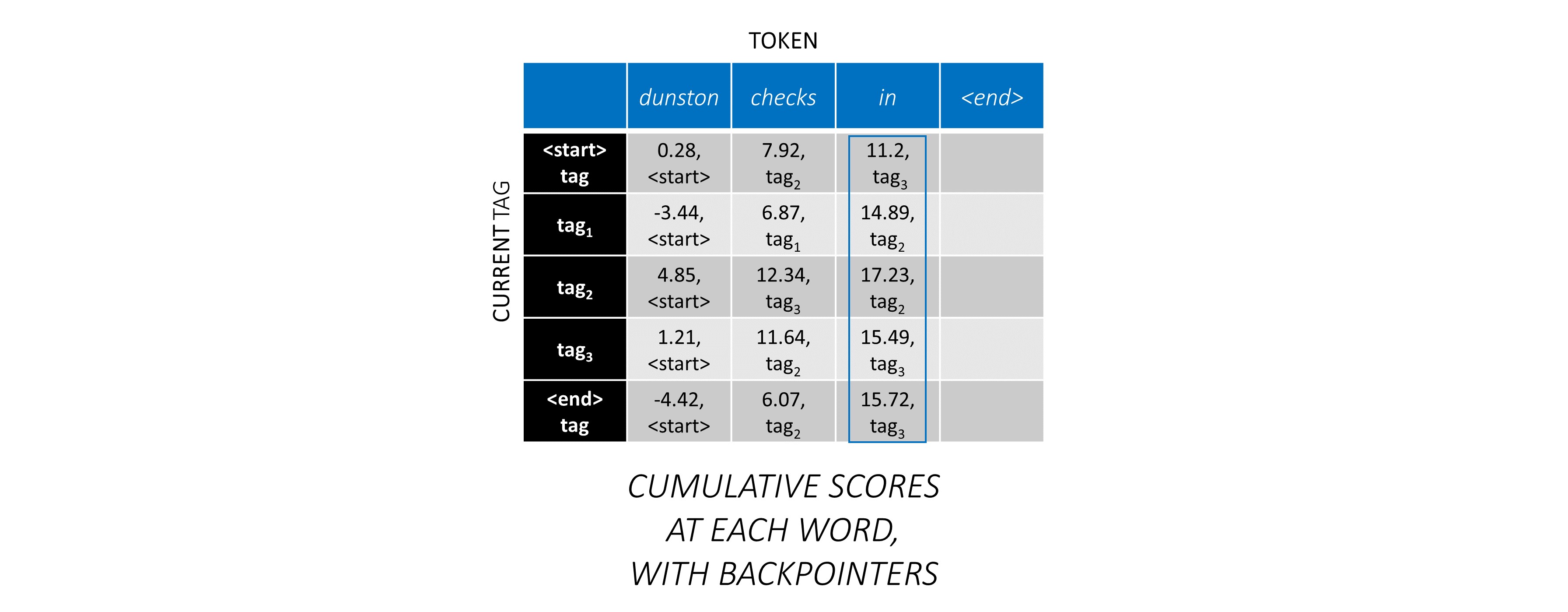
Ahora que acumuló los puntajes de CRF en toda la secuencia, trazas hacia atrás para revelar la secuencia de la etiqueta con la puntuación más alta posible .
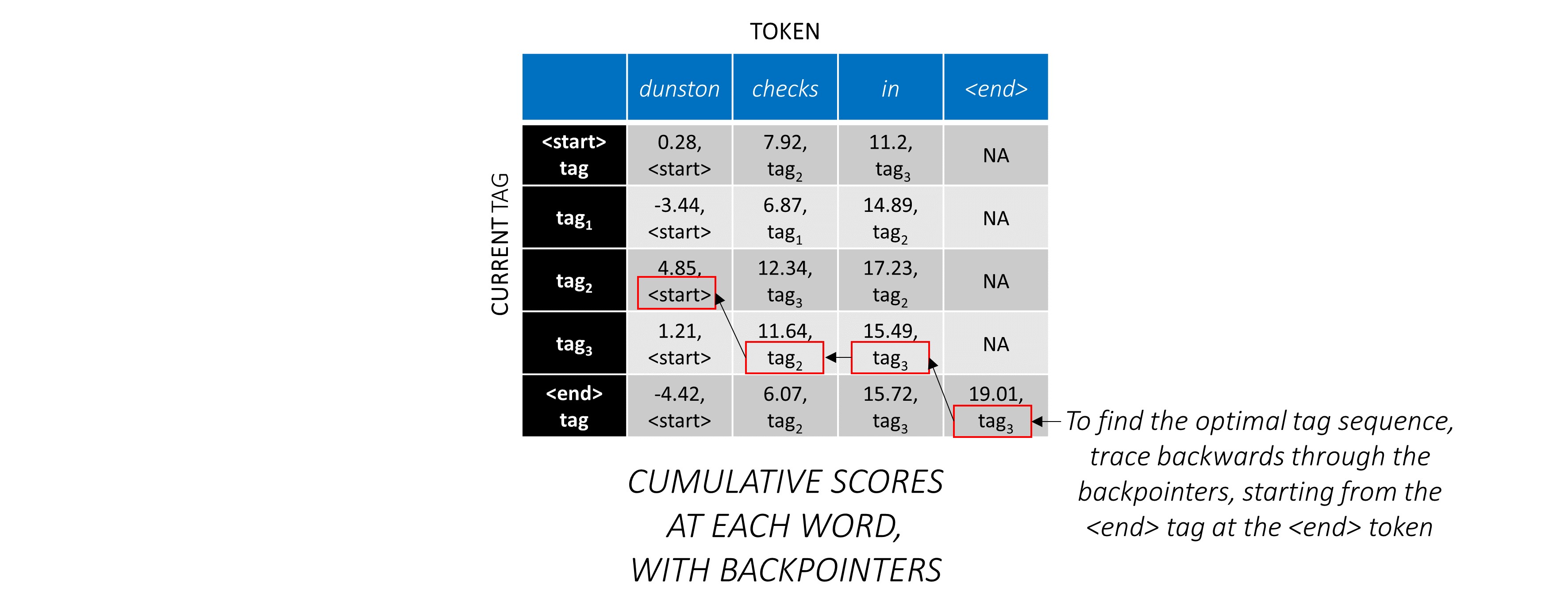
Encontramos que la secuencia de etiqueta más óptima para dunston checks in <end> es tag_2 tag_3 tag_3 <end> .
Las secciones a continuación describen brevemente la implementación.
Están destinados a proporcionar algún contexto, pero los detalles se entienden mejor directamente del código , que se comenta bastante.
Utilizo el conjunto de datos NER CONLL 2003 para comparar mis resultados con el documento.
Aquí hay un fragmento -
-DOCSTART- -X- O O
EU NNP I-NP I-ORG
rejects VBZ I-VP O
German JJ I-NP I-MISC
call NN I-NP O
to TO I-VP O
boycott VB I-VP O
British JJ I-NP I-MISC
lamb NN I-NP O
. . O O
Este conjunto de datos no está destinado a distribuirse públicamente, aunque puede encontrarlo en algún lugar en línea.
Hay varios conjuntos de datos públicos en línea que puede usar para capacitar al modelo. Es posible que no todos sean anotados al 100% humanos, pero son suficientes.
Para el etiquetado NER, puede usar el banco de significado Groningen.
Para el etiquetado POS, NLTK tiene un pequeño conjunto de datos disponible al que puede acceder con nltk.corpus.treebank.tagged_sents() .
Tendría que convertirlo en el formato de datos NER CONLL 2003 o modificar el código a la que se hace referencia en la sección de la tubería de datos.
Necesitaremos ocho entradas.
Estas son las secuencias de palabras que deben etiquetarse.
dunston checks in
Como se discutió anteriormente, no usaremos tokens <start> pero necesitaremos usar tokens <end> .
dunston, checks, in, <end>
Dado que pasamos las oraciones como tensores de tamaño fijo, necesitamos rellenar oraciones (que son naturalmente de longitud variable) a la misma longitud con tokens <pad> .
dunston, checks, in, <end>, <pad>, <pad>, <pad>, ...
Además, creamos un word_map que es una asignación de índice para cada palabra en el corpus, incluidas las tokens <end> y <pad> . Pytorch, como otras bibliotecas, necesita palabras codificadas como índices para buscar incrustaciones para ellos, o para identificar su lugar en las puntuaciones de palabras predichas.
4381, 448, 185, 4669, 0, 0, 0, ...
Por lo tanto, las secuencias de palabras alimentadas con el modelo deben ser un Int de dimensiones N, L_w donde N es el lote y L_w es la longitud acolchada de las secuencias de palabras (generalmente la longitud de la secuencia de palabras más larga).
Estas son las secuencias de caracteres en la dirección hacia adelante.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' '
Necesitamos <end> tokens en las secuencias de caracteres para que coincidan con el token <end> en las secuencias de palabras. Dado que vamos a usar características a nivel de personaje en cada palabra en la secuencia de la palabra, necesitamos características a nivel de personaje en <end> en la secuencia de la palabra.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>
También necesitamos rellenarlos.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>, <pad>, <pad>, <pad>, ...
Y codificarlos con un char_map .
29, 2, 12, 8, 7, 14, 12, 3, 6, 18, 1, 6, 21, 8, 3, 17, 12, 3, 60, 0, 0, 0, ...
Por lo tanto, las secuencias de caracteres delanteras alimentadas al modelo deben ser un Int de dimensiones N, L_c , donde L_c es la longitud acolchada de las secuencias de caracteres (generalmente la longitud de la secuencia de caracteres más larga).
Esto se procesaría igual que la secuencia hacia adelante, pero hacia atrás. (Los tokens <end> seguirían al final, naturalmente).
'n', 'i', ' ', 's', 'k', 'c', 'e', 'h', 'c', ' ', 'n', 'o', 't', 's', 'n', 'u', 'd', ' ', <end>, <pad>, <pad>, <pad>, ...
12, 17, 3, 8, 21, 6, 1, 18, 6, 3, 12, 14, 7, 8, 12, 2, 29, 3, 60, 0, 0, 0, ...
Por lo tanto, las secuencias de caracteres atrasadas alimentadas al modelo deben ser un Int de dimensiones N, L_c .
Estos marcadores son posiciones en las secuencias de caracteres donde extraemos características a -
Extraeremos características al final de cada espacio ' ' en la secuencia de caracteres, y en el token <end> .
Para la secuencia de personajes delanteros, extraemos en -
7, 14, 17, 18
Estos son puntos después de dunston , checks , in , <end> respectivamente. Por lo tanto, tenemos un marcador para cada palabra en la secuencia de la palabra , que tiene sentido. (Sin embargo, en los modelos de idiomas, dado que estamos prediciendo la siguiente palabra, no predeciremos en el marcador que corresponde a <end> .)
Papelamos estos con 0 s. No importa con qué se enfrentemos, siempre y cuando sean índices válidos. (Extraeremos características en las almohadillas, pero no las usaremos).
7, 14, 17, 18, 0, 0, 0, ...
Están acolchados a la longitud acolchada de las secuencias de las palabras, L_w .
Por lo tanto, los marcadores de caracteres delanteros alimentados al modelo deben ser un Int de dimensiones N, L_w .
Para los marcadores en las secuencias de caracteres hacia atrás, de manera similar encontramos las posiciones de cada espacio ' ' y el token <end> .
También nos aseguramos de que estas posiciones estén en el mismo orden de palabras que en los marcadores de avance . Esta alineación hace que sea más fácil concatenar las características extraídas de las secuencias de caracteres hacia adelante y hacia atrás, y también evita tener que reordenar los objetivos en los modelos de lenguaje.
17, 9, 2, 18
Estos son puntos después de notsnud , skcehc , ni , <end> respectivamente.
Paden con 0 s.
17, 9, 2, 18, 0, 0, 0, ...
Por lo tanto, los marcadores de caracteres atrasados alimentados al modelo deben ser un Int de dimensiones N, L_w .
Supongamos que las etiquetas correctas para dunston, checks, in, <end> son -
tag_2, tag_3, tag_3, <end>
Tenemos un tag_map (que contiene las etiquetas <start> , tag_1 , tag_2 , tag_3 , <end> ).
Normalmente, los codificaríamos directamente (antes del relleno) -
2, 3, 3, 5
Estas son codificaciones 1D , es decir, posiciones de etiqueta en un mapa de etiqueta 1D .
Pero las salidas de la capa CRF son tensores 2D m, m en cada palabra. Tendríamos que codificar las posiciones de la etiqueta en estas salidas 2D .
Las posiciones de etiqueta correctas están marcadas en rojo.
(0, 2), (2, 3), (3, 3), (3, 4)
Si desenrollamos estos puntajes en un tensor 1D m*m , entonces las posiciones de la etiqueta en el tensor desenrollado serían
tag_map [ previous_tag ] * len ( tag_map ) + tag_map [ current_tag ] Por lo tanto, codificamos tag_2, tag_3, tag_3, <end> AS
2, 13, 18, 19
Tenga en cuenta que puede recuperar los índices tag_map originales tomando el módulo
t % len ( tag_map ) Estarán acolchados a la longitud acolchada de las secuencias de las palabras, L_w .
Por lo tanto, las etiquetas alimentadas al modelo deben ser un Int de dimensiones N, L_w .
Estas son las longitudes reales de las secuencias de la palabra, incluidas las tokens <end> . Dado que Pytorch admite gráficos dinámicos, calcularemos solo sobre estas longitudes y no sobre los <pads> .
Por lo tanto, las longitudes de las palabras alimentadas al modelo deben ser un Int de dimensiones N .
Estas son las longitudes reales de las secuencias de caracteres, incluidos los tokens <end> . Dado que Pytorch admite gráficos dinámicos, calcularemos solo sobre estas longitudes y no sobre los <pads> .
Por lo tanto, las longitudes de los caracteres alimentadas al modelo deben ser un Int de dimensiones N .
Ver read_words_tags() en utils.py .
Esto lee los archivos de entrada en el formato Conll 2003 y extrae las secuencias de palabras y etiquetas.
Ver create_maps() en utils.py .
Aquí, creamos mapas de codificación para palabras, personajes y etiquetas. Genamos palabras y personajes raros como <unk> (incógnitas).
Ver create_input_tensors() en utils.py .
Generamos las ocho entradas detalladas en las entradas a la sección Modelo.
Ver load_embeddings() en utils.py .
Cargamos incrustaciones previamente capacitadas, con la opción de expandir el word_map para incluir palabras fuera de corpus presentes en el vocabulario de incrustación. Tenga en cuenta que esto también puede incluir palabras raras en el Corpus que fueron <unk> como s anteriores.
Ver WCDataset en datasets.py .
Esta es una subclase del Dataset Pytorch. Necesita un método __len__ definido, que devuelve el tamaño del conjunto de datos, y un método __getitem__ que devuelve i conjunto de ocho entradas al modelo.
El Dataset será utilizado por un Pytorch DataLoader en train.py para crear y alimentar lotes de datos al modelo para su entrenamiento o validación.
Ver Highway en models.py .
Una transformación es una transformación lineal activada por Relu de la entrada. Una puerta es una transformación lineal activada por sigmoide de la entrada. Tenga en cuenta que ambas transformaciones deben ser del mismo tamaño que la entrada , para permitir agregar la entrada en una conexión residual.
El atributo num_layers especifica cuántas operaciones de conexión transformada-residual realizamos en serie. Por lo general, solo uno es suficiente.
Almacenamos el número requerido de capas de transformación y puerta en ModuleList() S, y usamos un bucle for para realizar operaciones sucesivas.
Consulte LM_LSTM_CRF en models.py .
Al principio, ordenamos las secuencias de personajes hacia adelante y hacia atrás al disminuir las longitudes . Esto se requiere para usar pack_padded_sequence() para que el LSTM calcule solo sobre los times de tiempo válidos, es decir, la longitud verdadera de las secuencias.
Recuerde también ordenar todos los demás tensores en el mismo orden.
Consulte dynamic_rnn.py para una ilustración de cómo pack_padded_sequence() puede usarse para aprovechar las capacidades dinámicas de gráficos y lotes de Pytorch para que no procesemos las almohadillas. Aplana las secuencias ordenadas por tiempo de tiempo mientras ignora las almohadillas, y el LSTM se calcula solo sobre el tamaño de lote efectivo N_t en cada paso de tiempo .
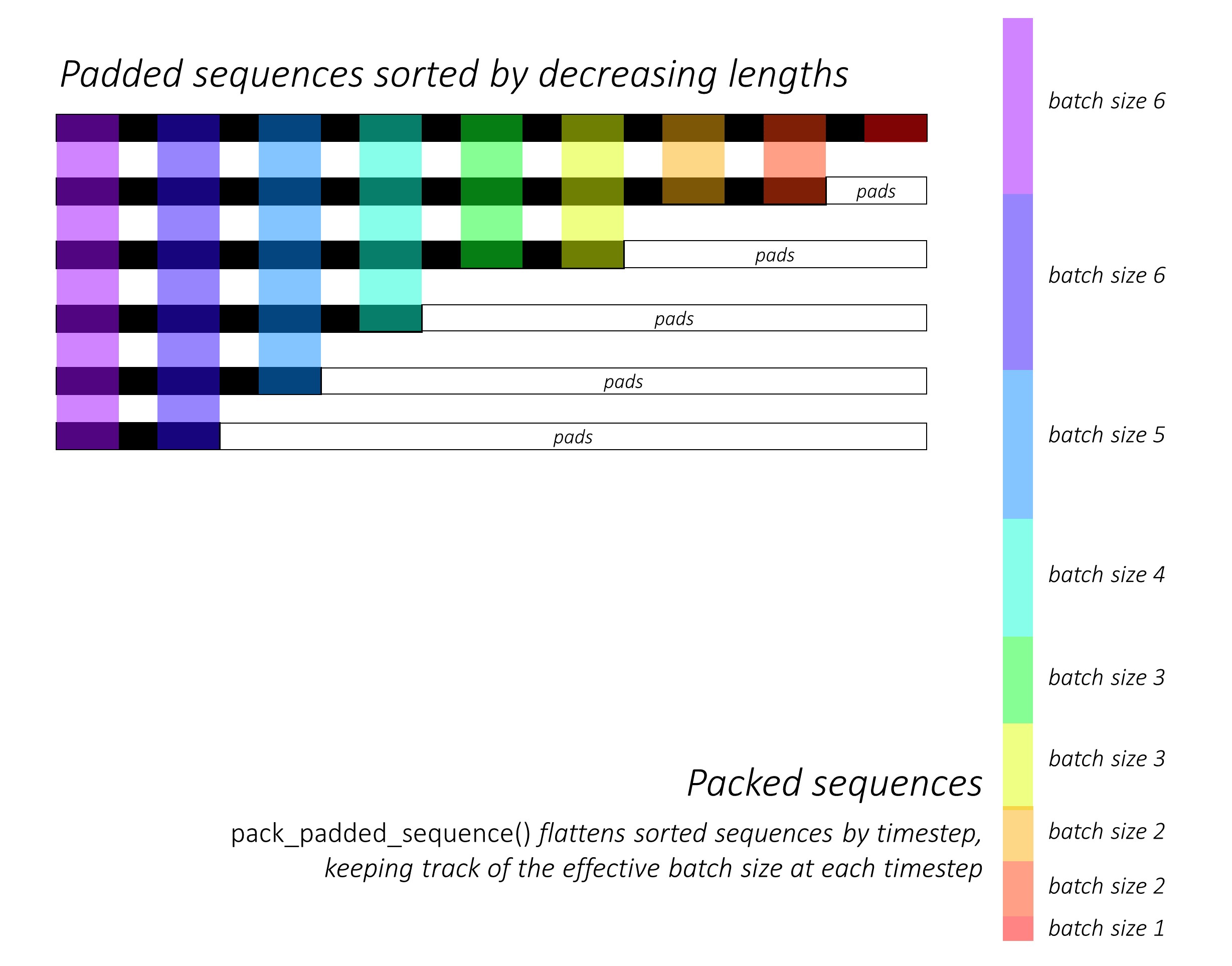
La clasificación permite que el N_t superior en cualquier paso de tiempo se alinee con las salidas del paso anterior . En el tercer tiempo de tiempo, por ejemplo, procesamos solo las 5 imágenes principales, utilizando las 5 salidas principales del paso anterior. Excepto por la clasificación, todo esto es manejado internamente por Pytorch, pero todavía es muy útil comprender qué pack_padded_sequence() para que podamos usarlo en otros escenarios para lograr fines similares. (Consulte la pregunta relacionada sobre el manejo de secuencias de longitud variable en la sección de preguntas frecuentes).
Al clasificar, aplicamos los LSTM hacia adelante y hacia atrás en el avanzado y hacia atrás, packed_sequences , respectivamente. Usamos pad_packed_sequence() para desactivar y volver a poner las salidas.
Extraemos solo las salidas en los marcadores de caracteres hacia adelante y hacia atrás con gather . Esta función es muy útil para extraer solo ciertos índices de un tensor que se especifica en un tensor separado.
Estas salidas extraídas son procesadas por las capas de la carretera hacia adelante y hacia atrás antes de aplicar una capa lineal para calcular las puntuaciones sobre el vocabulario para predecir la siguiente palabra en cada marcador. Hacemos esto solo durante la capacitación, ya que no tiene sentido realizar el modelado de idiomas para el aprendizaje de varias tareas durante la validación o la inferencia. El atributo training de cualquier modelo se establece con model.train() o model.eval() en train.py . (Tenga en cuenta que esto se usa principalmente para habilitar o deshabilitar las capas de deserción y norma por lotes en un modelo de Pytorch durante el entrenamiento y la inferencia, respectivamente).
Ver LM_LSTM_CRF en models.py (continuación).
También ordenamos las secuencias de la palabra al disminuir las longitudes , porque puede que no siempre haya una correlación entre las longitudes de las secuencias de las palabras y las secuencias de caracteres.
Recuerde también ordenar todos los demás tensores en el mismo orden.
Concatenamos las salidas LSTM del carácter hacia adelante y hacia atrás en los marcadores, y las ejecutamos a través de la tercera capa de carretera . Esto extraerá la información de sub-palabras en cada palabra que utilizaremos para el etiquetado de secuencia.
Concatenamos este resultado con la palabra incrustaciones y calculamos las salidas BLSTM sobre el packed_sequence .
Al volver a poner con pad_packed_sequence() , tenemos las características que necesitamos para alimentar a la capa CRF.
Ver CRF en models.py .
Puede encontrar que esta capa es sorprendentemente directa considerando el valor que agrega a nuestro modelo.
Se usa una capa lineal para transformar las salidas del BLSTM a puntajes para cada etiqueta, que son los puntajes de emisión .
Se usa un solo tensor para mantener los puntajes de transición . Este tensor es un Parameter del modelo, lo que significa que es actualizable durante la propagación backpropagación, al igual que los pesos de las otras capas.
Para encontrar los puntajes de CRF, calcule los puntajes de emisión en cada palabra y agréguelo a los puntajes de transición , después de la transmisión como se describe en la descripción general de CRF.
Ver ViterbiLoss en models.py .
Establecimos en la descripción general de la pérdida de Viterbi que queremos minimizar la diferencia entre el log-sum-Exp de las puntuaciones de todas las secuencias de etiquetas válidas posibles y la puntuación de la secuencia de etiqueta de oro , es decir, log-sum-exp(all scores) - gold score .
Sumamos los puntajes de CRF de cada etiqueta verdadera como se describió anteriormente para calcular la puntuación de oro .
¿Recuerdas cómo codificamos las secuencias de etiquetas con sus posiciones en los puntajes de CRF desactivados? Extraemos los puntajes en estas posiciones con gather() y eliminamos las almohadillas con pack_padded_sequences() antes de sumar.
Encontrar el log-sum-exp de las puntuaciones de todas las secuencias posibles es un poco más complicado. Usamos un bucle for para iterar sobre los times. En cada paso de tiempo, acumulamos puntajes para cada current_tag por -
current_tag para cada previous_tag . Hacemos esto solo en el tamaño de lote efectivo, es decir, para secuencias que aún no se han completado. (Nuestras secuencias todavía se clasifican disminuyendo la longitud de las palabras, del modelo LM-LSTM-CRF ).current_tag , calcule el registro-suM-Exp sobre el previous_tag s para encontrar las nuevas puntuaciones acumuladas en cada current_tag . Después de calcular las longitudes variables de todas las secuencias, nos queda un tensor de dimensiones N, m , donde m es el número de etiquetas (actuales). Estos son los puntajes acumulados log-sum-Exp en todas las secuencias posibles que terminan en cada una de las etiquetas m Sin embargo, dado que las secuencias válidas solo pueden terminar con la etiqueta <end> , suma solo la columna <end> para encontrar el registro de registro de los puntajes de todas las secuencias válidas posibles .
Encontramos la diferencia, log-sum-exp(all scores) - gold score .
Ver ViterbiDecoder en inference.py .
Esto implementa el proceso descrito en la descripción de decodificación de Viterbi.
Acumulamos puntajes en un bucle for de una manera similar a lo que hicimos en ViterbiLoss , excepto que aquí encontramos el máximo de las puntuaciones previous_tag para cada current_tag , en lugar de calcular el registro de registro-SUM-Exp. También realizamos un seguimiento del previous_tag que corresponde a esta puntuación máxima en un tensor de accesorios.
Papelamos el tensor de backpointer con etiquetas <end> porque esto nos permite rastrear hacia atrás sobre las almohadillas, llegando finalmente a la etiqueta <end> real , con lo cual comienza el retrato real .
Ver train.py .
Los parámetros para el modelo (y la capacitación) están al comienzo del archivo, por lo que puede verificarlos o modificarlos fácilmente si lo desea.
Para entrenar a su modelo desde cero , simplemente ejecute este archivo -
python train.py
Para reanudar la capacitación en un punto de control , apunte al archivo correspondiente con el parámetro de checkpoint al comienzo del código.
Tenga en cuenta que realizamos validación al final de cada época de entrenamiento.
Notará que recortamos las entradas en cada lote a las longitudes de secuencia máxima en ese lote . Esto es para que no tengamos más almohadillas en cada lote que realmente necesitamos.
¿Pero por qué? Aunque los RNN en nuestro modelo no calculan sobre las almohadillas, las capas lineales aún lo hacen . Es bastante directo cambiar esto: consulte la pregunta relacionada sobre el manejo de secuencias de longitud de variable en la sección Preguntas frecuentes.
Para este tutorial, pensé que un poco de cálculo adicional sobre algunas almohadillas valía la pena de no tener que realizar una serie de operaciones: carretera, CRF, otras capas lineales, concatenaciones) en una packed_sequence .
En el escenario de tareas múltiples, hemos elegido sumar las pérdidas de entropía cruzada de las dos tareas de modelado de idiomas y la pérdida de ViterBi de la tarea de etiquetado de secuencia.
Aunque estamos minimizando la suma de estas pérdidas , en realidad solo estamos interesados en minimizar la pérdida de Viterbi en virtud de minimizar la suma de estas pérdidas . Es la pérdida de Viterbi la que refleja el rendimiento en la tarea principal.
Usamos pack_padded_sequence() para eliminar las almohadillas siempre que sea necesario.
Al igual que en el documento, utilizamos el puntaje F1 macroverizado como el criterio para parar temprano . Naturalmente, calcular la puntuación F1 requiere que Viterbi decodifique las puntuaciones de CRF para generar nuestras secuencias de etiqueta óptimas.
Usamos pack_padded_sequence() para eliminar las almohadillas siempre que sea necesario.
He seguido los parámetros en la implementación de los autores lo más cerca posible.
Usé un tamaño de lote de 10 oraciones. Empleé descenso de gradiente estocástico con impulso. La tasa de aprendizaje fue decayada en cada época. Usé incrustaciones de guantes de guantes 100D sin ajustar.
Se necesitaron alrededor de los 80 para entrenar una época en un Titan X (Pascal).
La puntuación F1 en el conjunto de validación alcanzó 91% alrededor de la época 50, y alcanzó un máximo de 91.6% en la época 171. Lo ejecuté para un total de 200 épocas. Esto está bastante cerca de los resultados en el documento.
Puede descargar este modelo previo alado aquí.
¿Cómo decidimos si necesitamos <start> y <end> tokens para un modelo que usa secuencias?
Si esto parece confuso al principio, se resolverá fácilmente cuando piense en los requisitos del modelo que planea capacitar.
Para el etiquetado de secuencia con un CRF, necesita el token <end> ( o el token <start> ; ver la siguiente pregunta) debido a cómo se estructuran las puntuaciones de CRF.
En mi otro tutorial sobre subtítulos de imagen, utilicé tanto <start> y <end> tokens. El modelo necesitaba comenzar a decodificar en algún lugar y aprender a reconocer cuándo dejar de decodificar durante la inferencia.
Si está realizando una clasificación de texto, no necesitará.
¿Podemos hacer que el CRF genere current_word -> next_word puntajes en lugar de los puntajes previous_word -> current_word ?
Sí. En este caso, transmitiría los puntajes de emisión como L, m, _ , y tendría un token <start> en cada oración en lugar de un token <end> . La etiqueta correcta del token <start> siempre sería la etiqueta <start> . La "siguiente etiqueta" de la última palabra siempre sería la etiqueta <end> .
Creo que la previous word -> current word es ligeramente mejor porque hay modelos de lenguaje en la mezcla. It fits in quite nicely to be able to predict the <end> token at the last real word, and therefore learn to recognize when a sentence is complete.
Why are we using different vocabularies for the sequence tagger's inputs and language models' outputs?
The language models will learn to predict only those words it has seen during training. It's really unnecessary, and a huge waste of computation and memory, to use a linear-softmax layer with the extra ~400,000 out-of-corpus words from the embedding file it will never learn to predict.
But we can add these words to the input layer even if the model never sees them during training. This is because we're using pre-trained embeddings at the input. It doesn't need to see them because the meanings of words are encoded in these vectors. If it's encountered a chimpanzee before, it very likely knows what to do with an orangutan .
Is it a good idea to fine-tune the pre-trained word embeddings we use in this model?
I refrain from fine-tuning because most of the input vocabulary is not in-corpus. Most embeddings will remain the same while a few are fine-tuned. If fine-tuning changes these embeddings sufficiently, the model may not work well with the words that weren't fine-tuned. In the real world, we're bound to encounter many words that weren't present in a newspaper corpus from 2003.
What are some ways we can construct dynamic graphs in PyTorch to compute over only the true lengths of sequences?
If you're using an RNN, simply use pack_padded_sequence() . PyTorch will internally compute over only the true lengths. See dynamic_rnn.py for an example.
If you want to execute an operation (like a linear transformation) only on the true timesteps, pack_padded_sequences() is still the way to go. This flattens the tensor by timestep while removing the pads. You can perform your operation on this flattened tensor, and then use pad_packed_sequence() to unflatten it and re-pad it with 0 s.
Similarly, if you want to perform an aggregation operation, like computing the loss, use pack_padded_sequences() to eliminate the pads.
If you want to perform timestep-wise operations, you can take a leaf out of how pack_padded_sequences() works, and compute only on the effective batch size at each timestep with a for loop to iterate over the timesteps. We did this in the ViterbiLoss and ViterbiDecoder . I also used an LSTMCell() in this fashion in my image captioning tutorial.
Dunston Checks In ? ¿En realidad?
I had no memory of this movie for twenty years. I was trying to think of a short sentence that would be easier to visualize in this tutorial and it just popped into my mind riding a wave of 90s nostalgia.

I wish I hadn't googled it though. Damn, the critics were harsh, weren't they? This gem was overwhelmingly and universally panned. I'm not sure I'd disagree if I watched it now, but that just goes to show the world is so much more fun when you're a kid.
Didn't have to worry about LM-LSTM-CRFs or nuthin...


