a PyTorch Tutorial to Sequence Labeling
1.0.0
Este é um tutorial de Pytorch para a rotulagem de sequência .
Este é o segundo de uma série de tutoriais que estou escrevendo sobre como implementar modelos legais por conta própria com a incrível biblioteca Pytorch.
Conhecimento básico de pytorch, é assumida redes neurais recorrentes.
Se você é novo no Pytorch, primeiro leia o Deep Learning com Pytorch: uma blitz de 60 minutos e aprendendo Pytorch com exemplos.
Perguntas, sugestões ou correções podem ser publicadas como questões.
Estou usando PyTorch 0.4 no Python 3.6 .
27 de janeiro de 2020 : Código de trabalho para dois novos tutoriais foi adicionado-Super-resolução e tradução para a máquina
Objetivo
Conceitos
Visão geral
Implementação
Treinamento
Perguntas frequentes
Para construir um modelo que possa marcar cada palavra em uma frase com entidades, partes da fala, etc.

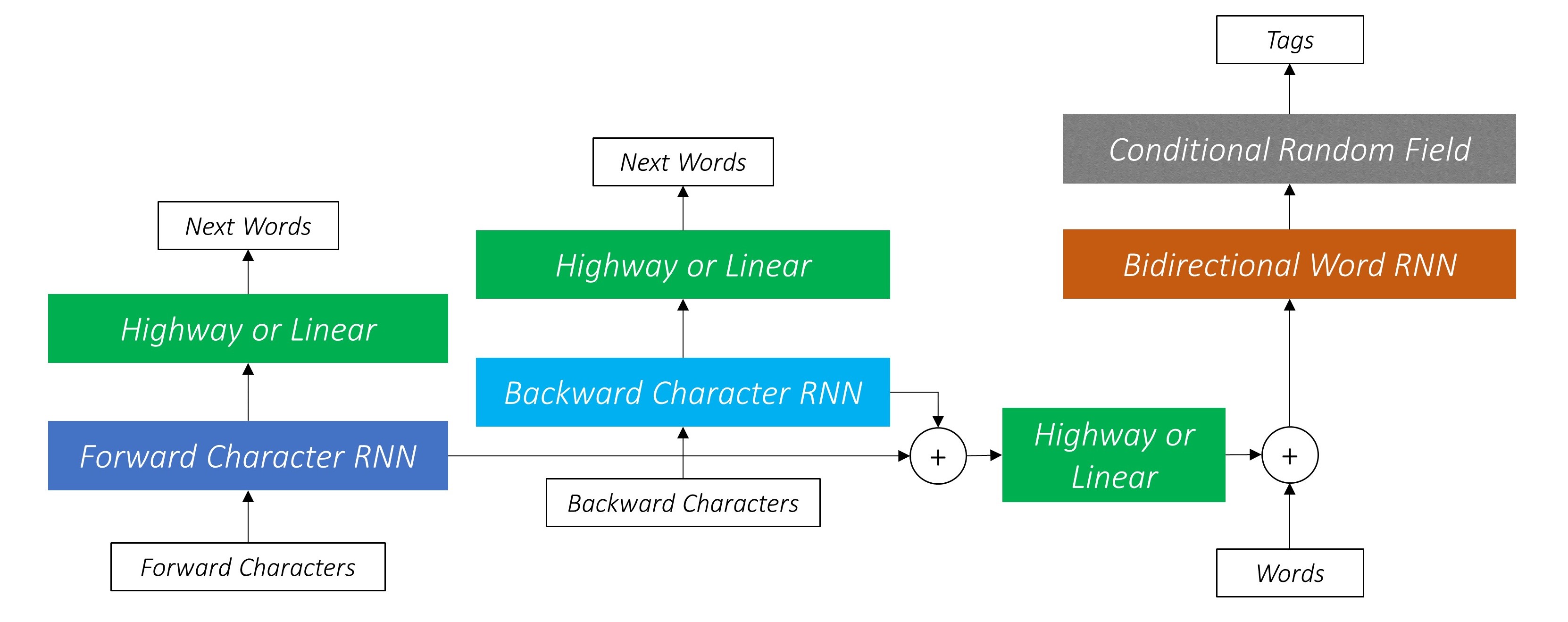
Estaremos implementando a rotulagem de sequência do Empower com papel de modelo de linguagem neural com conhecimento de tarefas . Isso é mais avançado do que a maioria dos modelos de marcação de seqüências, mas você aprenderá muitos conceitos úteis - e funciona extremamente bem. A implementação original dos autores pode ser encontrada aqui.
Este modelo é especial porque aumenta a tarefa de rotulagem de sequência treinando -o simultaneamente com modelos de idiomas.
Marcação de sequência . duh.
Modelos de idiomas . A modelagem de idiomas é prever a próxima palavra ou personagem em uma sequência de palavras ou caracteres. Os modelos de linguagem neural alcançam resultados impressionantes em uma ampla variedade de tarefas de PNL, como geração de texto, tradução de máquinas, legenda da imagem, reconhecimento de caracteres ópticos e o que você tem.
Personagem rnns . Os RNNs que operam em caracteres individuais em um texto são conhecidos por capturar o estilo e a estrutura subjacentes. Em uma tarefa de rotulagem de sequência, eles são especialmente úteis, pois as informações da sub-palavra geralmente podem produzir pistas importantes para uma entidade ou tag.
Aprendizado de várias tarefas . Os conjuntos de dados disponíveis para treinar um modelo geralmente são pequenos. Criar anotações ou recursos artesanais para ajudar seu modelo não é apenas complicado, mas também frequentemente não adaptável aos diversos domínios ou configurações em que seu modelo pode ser útil. A rotulagem de sequência, infelizmente, é um excelente exemplo. Existe uma maneira de mitigar esse problema - treinando em conjunto vários modelos que são unidos no quadril maximizarão as informações disponíveis para cada modelo, melhorando o desempenho.
Campos aleatórios condicionais . Classificadores discretos prevêem uma classe ou rótulo em uma palavra. Os campos aleatórios condicionais (CRFs) podem fazer um melhor - eles prevêem rótulos com base não apenas na palavra, mas também no bairro. O que faz sentido, porque existem padrões em uma sequência de entidades ou rótulos. Os CRFs são amplamente utilizados para modelar informações ordenadas, seja para marcação de sequência, sequenciamento de genes ou até detecção de objetos e segmentação de imagem na visão computacional.
Decodificação de Viterbi . Como estamos usando CRFs, não estamos prevendo tanto o rótulo certo em cada palavra quanto prevemos a sequência de etiqueta correta para uma sequência de palavras. A decodificação do Viterbi é uma maneira de fazer exatamente isso - encontre a sequência de tags mais ideal das pontuações calculadas por um campo aleatório condicional.
Redes de rodovias . As camadas totalmente conectadas são um grampo em qualquer rede neural para transformar ou extrair recursos em diferentes locais. As redes de rodovias conseguem isso, mas também permitem que as informações fluam sem impedimentos entre as transformações. Isso torna as redes profundas muito mais eficientes ou viáveis.
Nesta seção, apresentarei uma visão geral deste modelo. Se você já está familiarizado com isso, pode pular direto para a seção de implementação ou o código comentado.
Os autores se referem ao modelo como modelo de idioma - memória de curto prazo - campo aleatório condicional, pois envolve modelos de linguagem de co -treinamento com uma combinação LSTM + CRF .
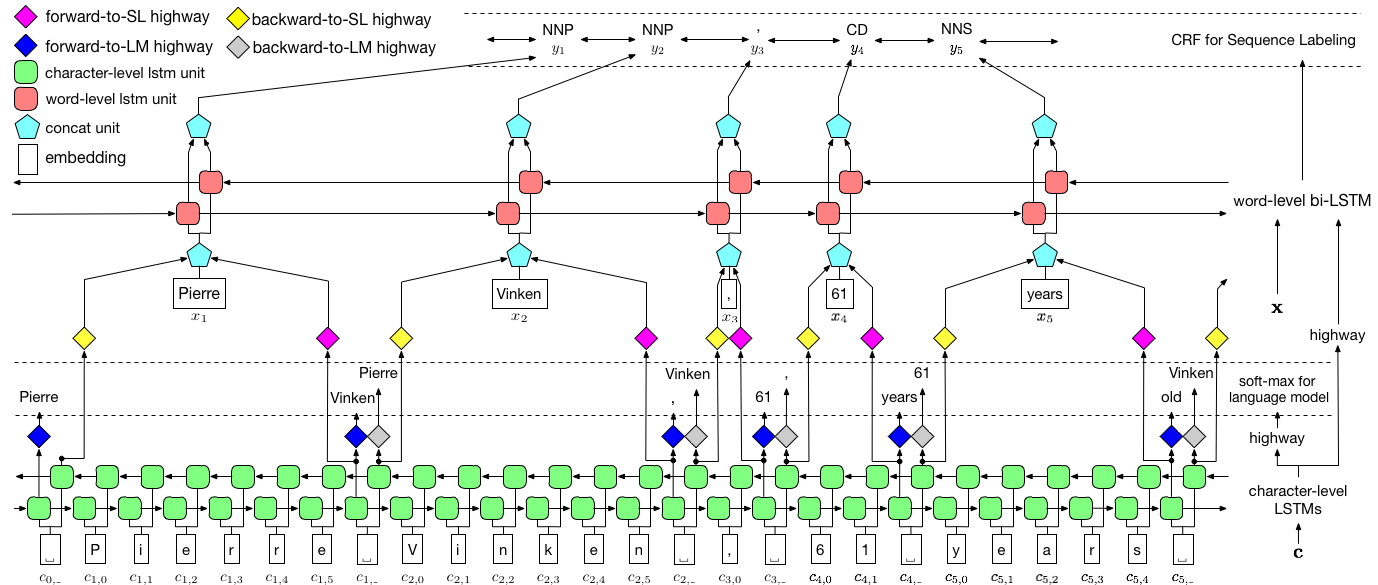
Esta imagem do artigo representa completamente o modelo inteiro, mas não se preocupe se parecer muito complexo neste momento. Vamos dividi -lo para dar uma olhada nos componentes.
A aprendizagem de várias tarefas é quando você treina simultaneamente um modelo em duas ou mais tarefas.
Normalmente, estamos interessados apenas em uma dessas tarefas - neste caso, a rotulagem de sequência.
Mas quando as camadas de uma rede neural contribuem para a execução de várias funções, elas aprendem mais do que teriam se tivessem treinado apenas na tarefa principal. Isso ocorre porque as informações extraídas em cada camada são expandidas para acomodar todas as tarefas. Quando há mais informações para trabalhar, o desempenho na tarefa principal é aprimorado .
Enriquecer os recursos existentes dessa maneira remove a necessidade de usar recursos artesanais para marcação de sequência.
A perda total durante o aprendizado de várias tarefas é geralmente uma combinação linear das perdas nas tarefas individuais. Os parâmetros da combinação podem ser fixados ou aprendidos como pesos atualizáveis.

Como estamos agregando perdas individuais, você pode ver como as camadas upstream compartilhadas por várias tarefas receberiam atualizações de todas elas durante a retropropagação.
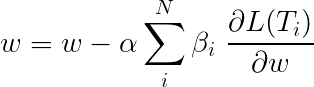
Os autores do artigo simplesmente adicionam as perdas ( β=1 ) e faremos o mesmo.
Vamos dar uma olhada nas tarefas que compõem nosso modelo.
Existem três .

Isso aproveita as informações da sub-palavra para prever a próxima palavra.
Fazemos o mesmo na direção para trás. 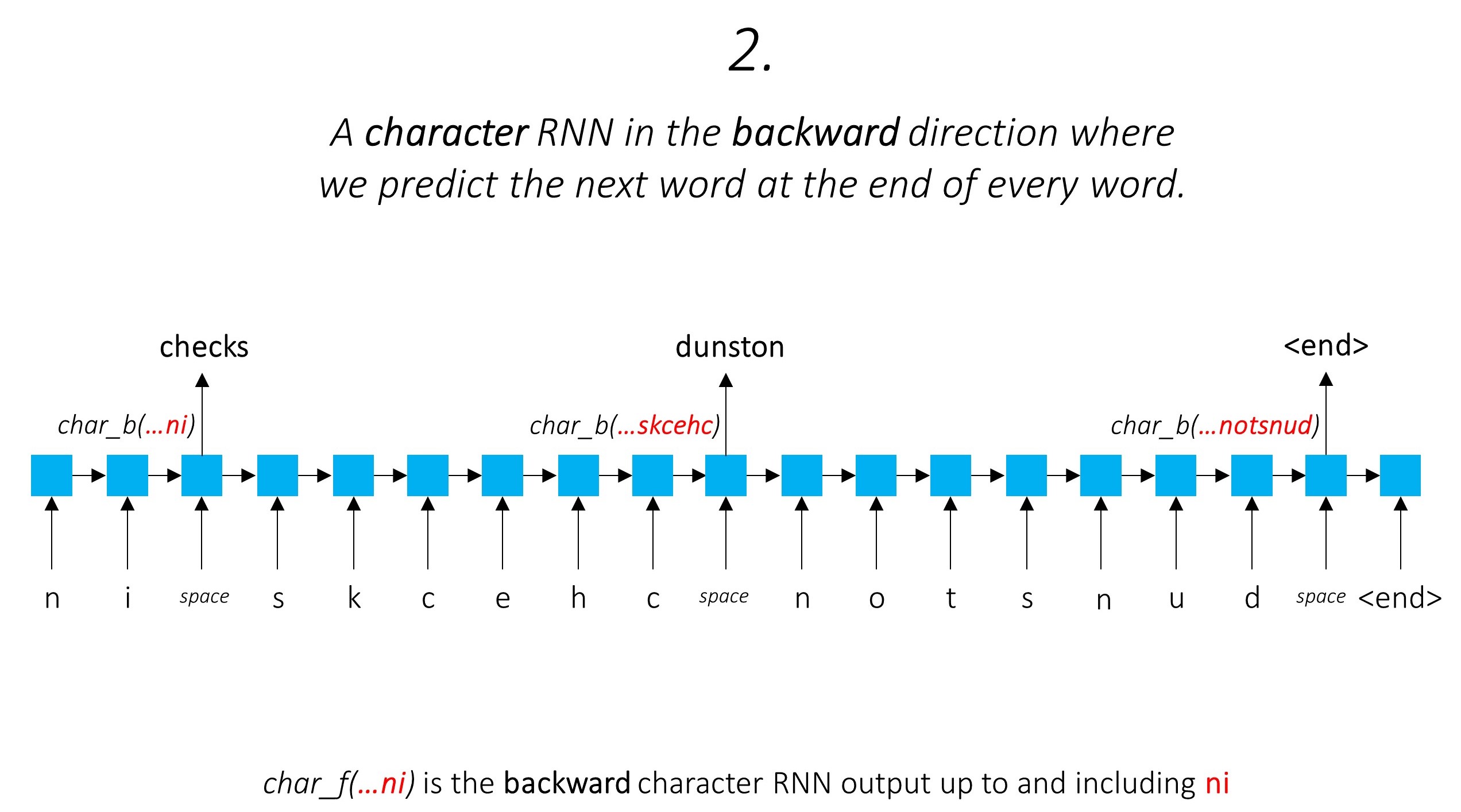
Também usamos as saídas desses dois RNNs de caracteres como entradas em nosso Word-RNN e CIDENTO ALEMANO CONDIGIAL (CRF) para executar nossa tarefa principal de marcação de sequência. 
Estamos usando informações sobre sub-palavras em nossa tarefa de marcação, pois pode ser um indicador poderoso das tags, sejam partes da fala ou entidades. Por exemplo, pode aprender que os adjetivos geralmente terminam com "-y" ou "-ul", ou que os lugares geralmente terminam com "-land" ou "-burg".
Mas nossos recursos da sub-palavra, viz. As saídas dos RNNs de caracteres também são enriquecidas com informações adicionais - o conhecimento necessário para prever a próxima palavra nas direções para a frente e para trás, devido aos modelos 1 e 2.
Portanto, nosso modelo de marcação de sequência usa os dois
O LSTM/RNN bidirecional codifica esses recursos em novos recursos em cada palavra que contém informações sobre a palavra e sua vizinhança, tanto no nível da palavra quanto no nível do caractere. Isso forma a entrada para o campo aleatório condicional.
Sem um CRF, teríamos simplesmente usado uma única camada linear para transformar a saída do LSTM bidirecional em pontuações para cada tag. Eles são conhecidos como pontuações de emissão , que são uma representação da probabilidade de a palavra ser uma certa etiqueta.
Um CRF calcula não apenas as pontuações de emissão, mas também as pontuações de transição , que são a probabilidade de uma palavra ser uma certa tag, considerando que a palavra anterior era uma certa tag. Portanto, as pontuações de transição medem a probabilidade de fazer a transição de uma etiqueta para outra.
Se houver tags m , as pontuações de transição serão armazenadas em uma matriz de dimesões m, m , onde as linhas representam a etiqueta da palavra anterior e as colunas representam a tag da palavra atual. Um valor nesta matriz na posição i, j é a probabilidade de fazer a transição da tag i th that na palavra anterior para a tag j th na palavra atual . Ao contrário das pontuações de emissão, as pontuações de transição não são definidas para cada palavra na frase. Eles são globais.
Em nosso modelo, a camada CRF produz o agregado das pontuações de emissão e transição em cada palavra .
Para uma frase de comprimento L , as pontuações de emissão seriam um tensor L, m Como as pontuações de emissão em cada palavra não dependem da tag da palavra anterior, criamos uma nova dimensão como L, _, m e Broadcast (Copy) o tensor nessa direção para obter um tensor L, m, m
As pontuações de transição são um tensor m, m Como as pontuações de transição são globais e não dependem da palavra, criamos uma nova dimensão como _, m, m e Broadcast (Copy) o tensor nessa direção para obter um tensor L, m, m
Agora podemos adicioná -los para obter as pontuações totais que são um tensor L, m, m Um valor na posição k, i, j é o agregado da pontuação de emissão da tag j th na k th Word e a pontuação de transição da tag j th na k th Word, considerando que a palavra anterior era i tag.
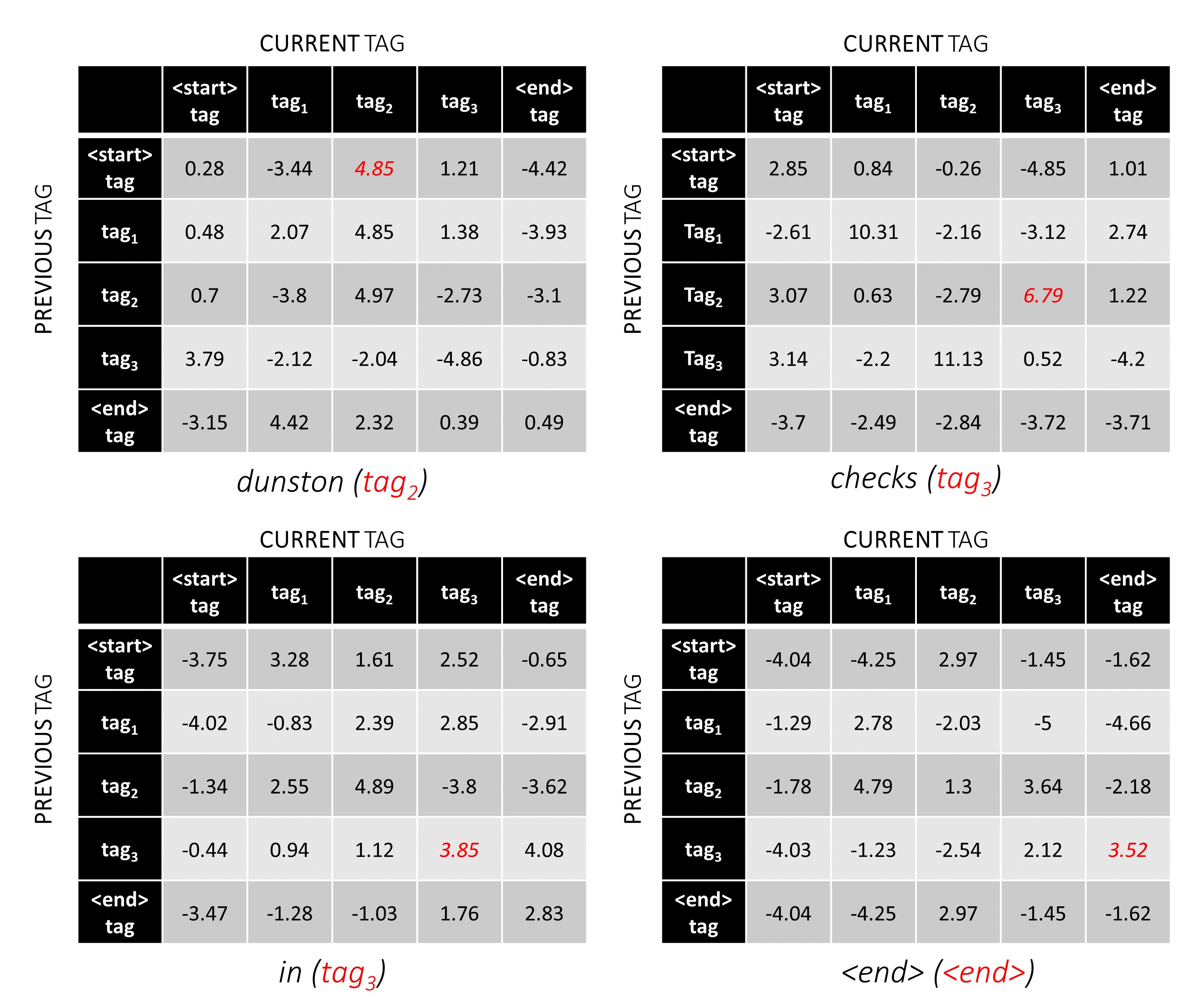
Para nossa frase de exemplo, dunston checks in <end> , se assumirmos que existem 5 tags no total, as pontuações totais seriam assim -
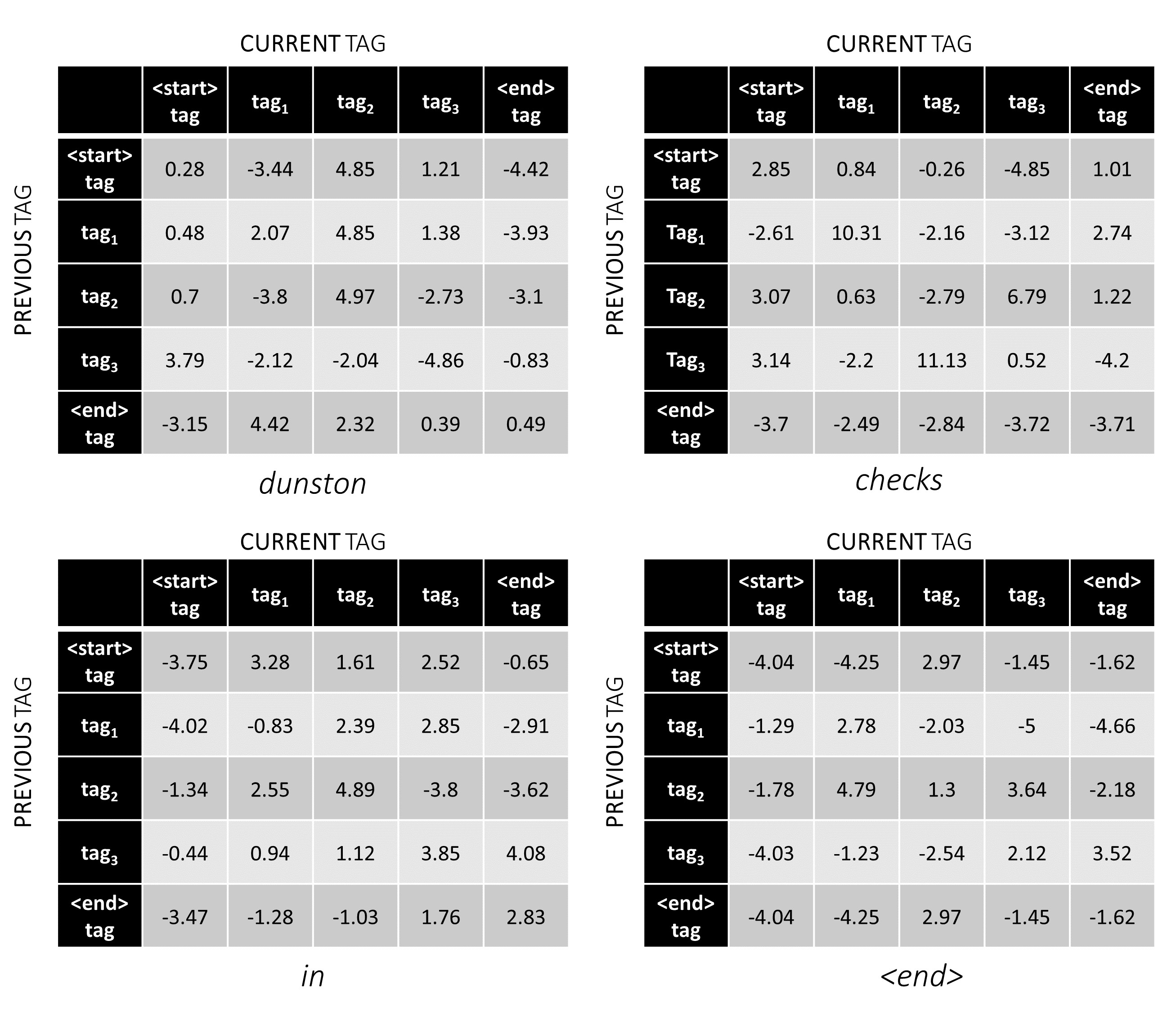
Mas espere um minuto, por que há tags <start> End <end> ? Enquanto estamos nisso, por que estamos usando um token <end> ?
<start> e <end> , <start> e <end> tokens Como estamos modelando a probabilidade de fazer a transição entre as tags, também incluímos uma tag <start> e uma tag <end> em nosso conjunto de tags.
A pontuação de transição de uma determinada tag, uma vez que a tag anterior era uma tag <start> representa a probabilidade de essa tag ser a primeira tag em uma frase . Por exemplo, frases geralmente começam com artigos (A, An, The) ou substantivos ou pronomes.
A pontuação de transição da tag <end> , considerando uma certa tag anterior, indica que a probabilidade desta tag anterior ser a última tag em uma frase .
Usaremos um token <end> em todas as frases e não um token <start> porque as pontuações totais de CRF em cada palavra são definidas em relação à tag da palavra anterior , o que não faria sentido em um token <start> .
A tag correta do token <end> é sempre a tag <end> . A "tag anterior" da primeira palavra é sempre a tag <start> .
Para ilustrar, se nossa frase de exemplo dunston checks in <end> tivesse as tags tag_2, tag_3, tag_3, <end> , os valores em vermelho indicam as pontuações dessas tags.
Geralmente usamos camadas lineares ativadas para transformar e processar saídas de um RNN/LSTM.
Se você estiver familiarizado com as conexões residuais, podemos adicionar a entrada antes da transformação à saída transformada, criando um caminho para o fluxo de dados em torno da transformação.
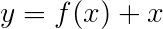
Esse caminho é um atalho para o fluxo de gradientes durante a retropacagação e ajuda na convergência de redes profundas.
Uma rede de rodovias é semelhante a uma rede residual, mas usamos um portão ativado por sigmóide para determinar a relação na qual a entrada e a saída transformada são combinadas .
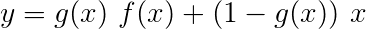
Como os RNNs de caracteres contribuem para várias tarefas, as redes de rodovias são usadas para extrair informações específicas da tarefa de suas saídas.
Portanto, usaremos redes de rodovias em três locais em nosso modelo combinado -
Em uma configuração ingênua de co-treinamento, onde usamos as saídas dos RNNs de caracteres diretamente para várias tarefas, ou seja, sem transformação, a discordância entre a natureza das tarefas pode prejudicar o desempenho.
Pode ficar claro agora como é a nossa rede combinada.
A remoção progressiva de partes de nossa rede resulta em redes progressivamente mais simples que são amplamente utilizadas para a marcação de sequência.
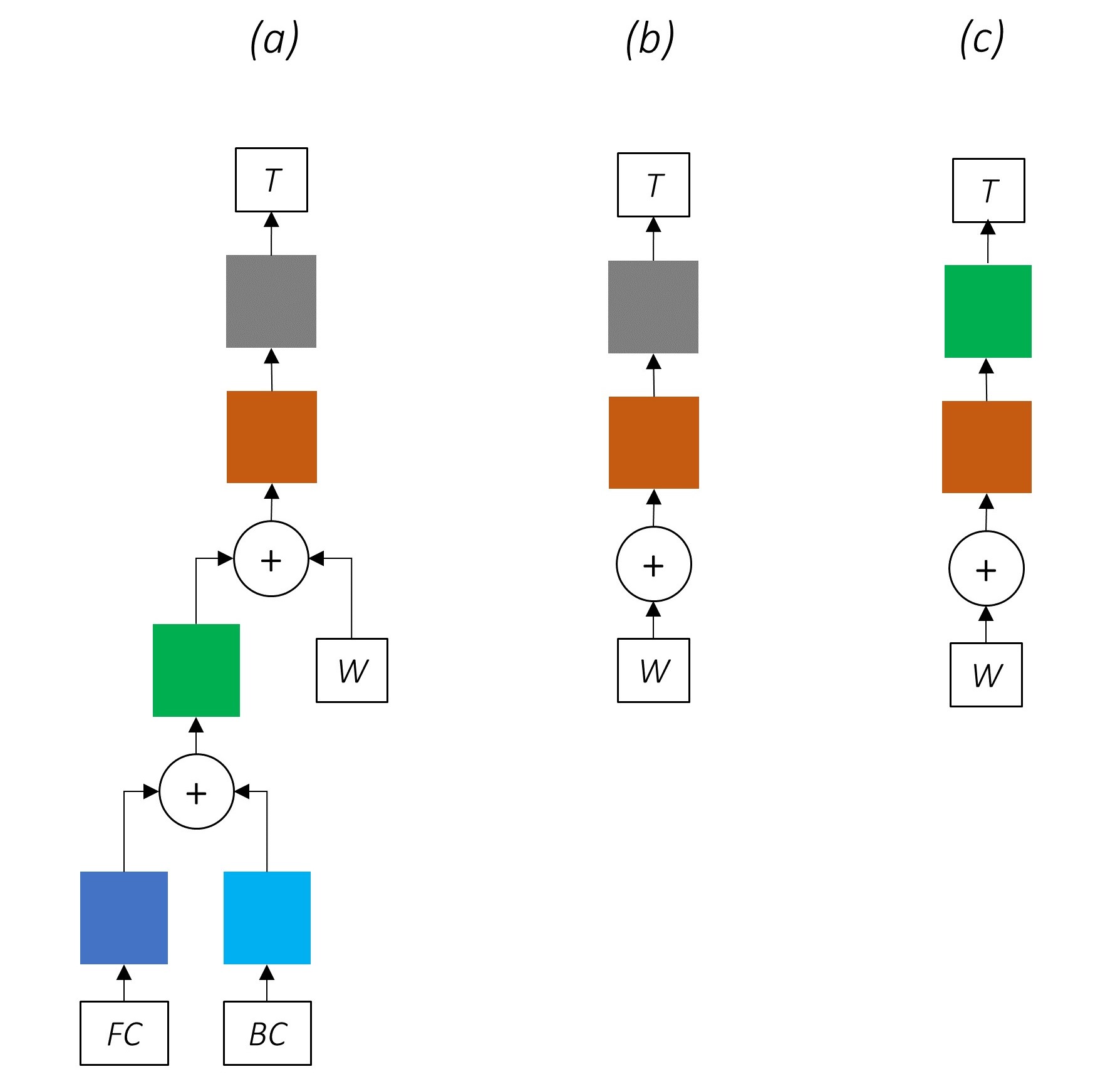
Não há aprendizado de várias tarefas.
O uso de informações no nível do caractere sem co-treinamento ainda melhora o desempenho.
Não há aprendizado de várias tarefas ou processamento no nível do caractere.
Essa configuração é usada com bastante frequência no setor e funciona bem.
Não há aprendizado de várias tarefas, processamento no nível do personagem ou CRFing. Observe que uma camada linear ou rodovia substituiria o último.
Isso pode funcionar razoavelmente bem, mas um campo aleatório condicional fornece um aumento considerável de desempenho.
Lembre -se, não estamos usando uma camada linear que calcule apenas as pontuações de emissão. A entropia cruzada não é uma métrica de perda adequada.
Em vez disso, usaremos a perda Viterbi que, como entropia cruzada, é uma "probabilidade negativa de log". Mas aqui vamos medir a probabilidade da sequência de tags de ouro (verdadeira), em vez da probabilidade da tag verdadeira em cada palavra na sequência. Para encontrar a probabilidade, consideramos o softmax sobre as pontuações de todas as seqüências de tags.
A pontuação de uma sequência de tags t definida como a soma das pontuações das tags individuais.

Por exemplo, considere as pontuações da CRF que analisamos mais cedo -
A pontuação da sequência de tags tag_2, tag_3, tag_3, <end> tag é a soma dos valores em vermelho, 4.85 + 6.79 + 3.85 + 3.52 = 19.01 .
A perda de Viterbi é então definida como
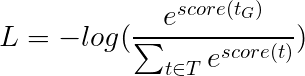
onde t_G é a sequência de tags de ouro e T representa o espaço de todas as sequências de tags possíveis.
Isso simplifica para -
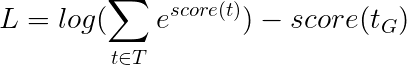
Portanto, a perda do Viterbi é a diferença entre o log-sum-exp das pontuações de todas as sequências de tags possíveis e a pontuação da sequência de tags de ouro , ou seja, log-sum-exp(all scores) - gold score .
A decodificação do Viterbi é uma maneira de construir a sequência de tags mais ideal, considerando não apenas a probabilidade de uma tag em uma determinada palavra (pontuações de emissão), mas também a probabilidade de uma tag, considerando as tags anteriores e as próximas tags (pontuações de transição).
Depois de gerar pontuações de CRF em matriz L, m, m para uma sequência de comprimento L , começamos a decodificar.
A decodificação do Viterbi é melhor compreendida com um exemplo. Considere novamente -
Para a primeira palavra na sequência, o previous_tag só pode ser <start> . Portanto, considere apenas essa linha.
Essas também são as pontuações cumulativas para cada current_tag na primeira palavra.
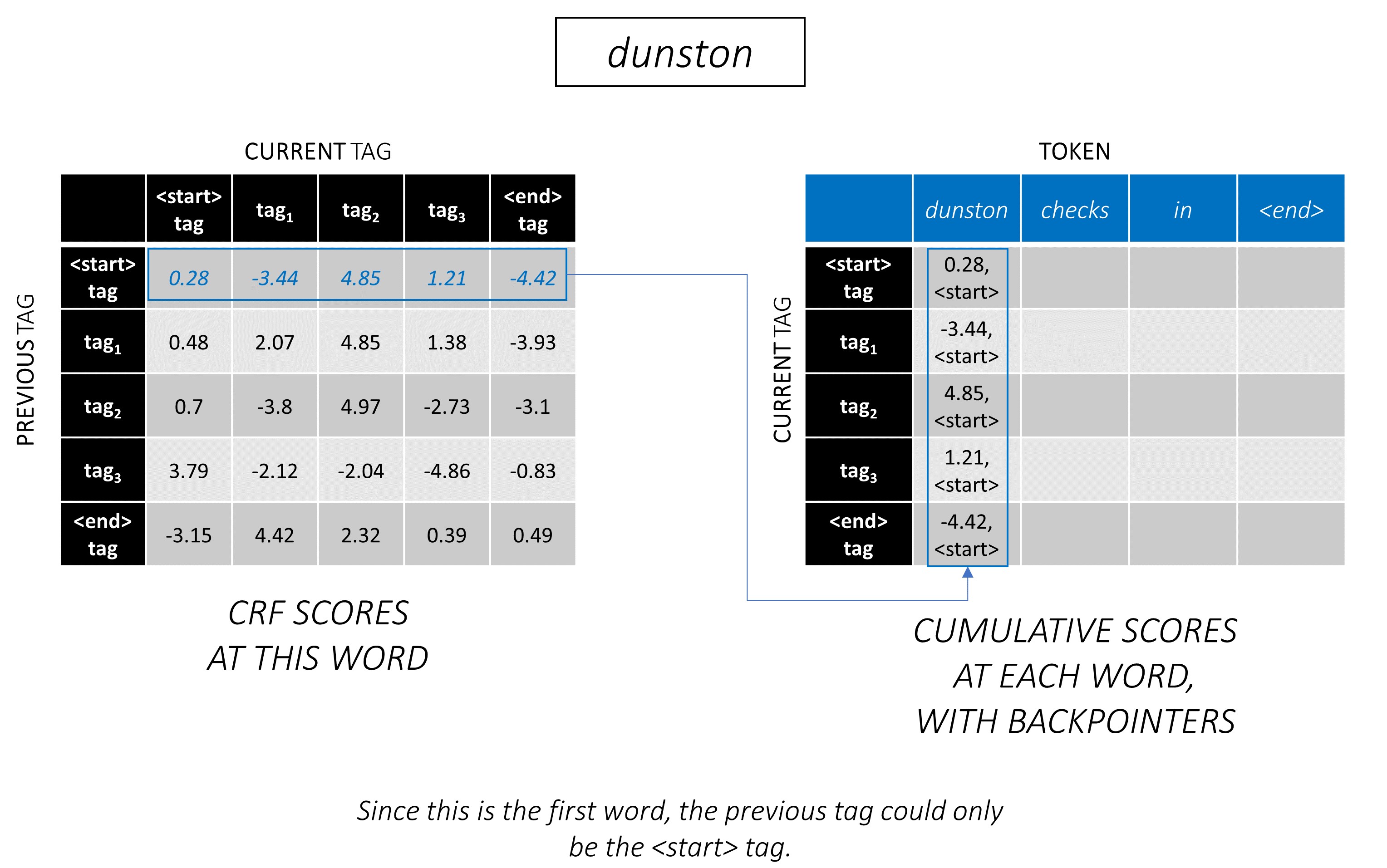
Também acompanharemos o previous_tag que corresponde a cada pontuação. Estes são conhecidos como Backpointers . Na primeira palavra, elas são obviamente todas as tags <start> .
Na segunda palavra, adicione as pontuações cumulativas anteriores às pontuações da CRF desta palavra para gerar novas pontuações cumulativas .
Observe que os current_tag s da primeira palavra são os previous_tag da segunda palavra. Portanto, transmita a pontuação cumulativa da primeira palavra ao longo da dimensão current_tag .
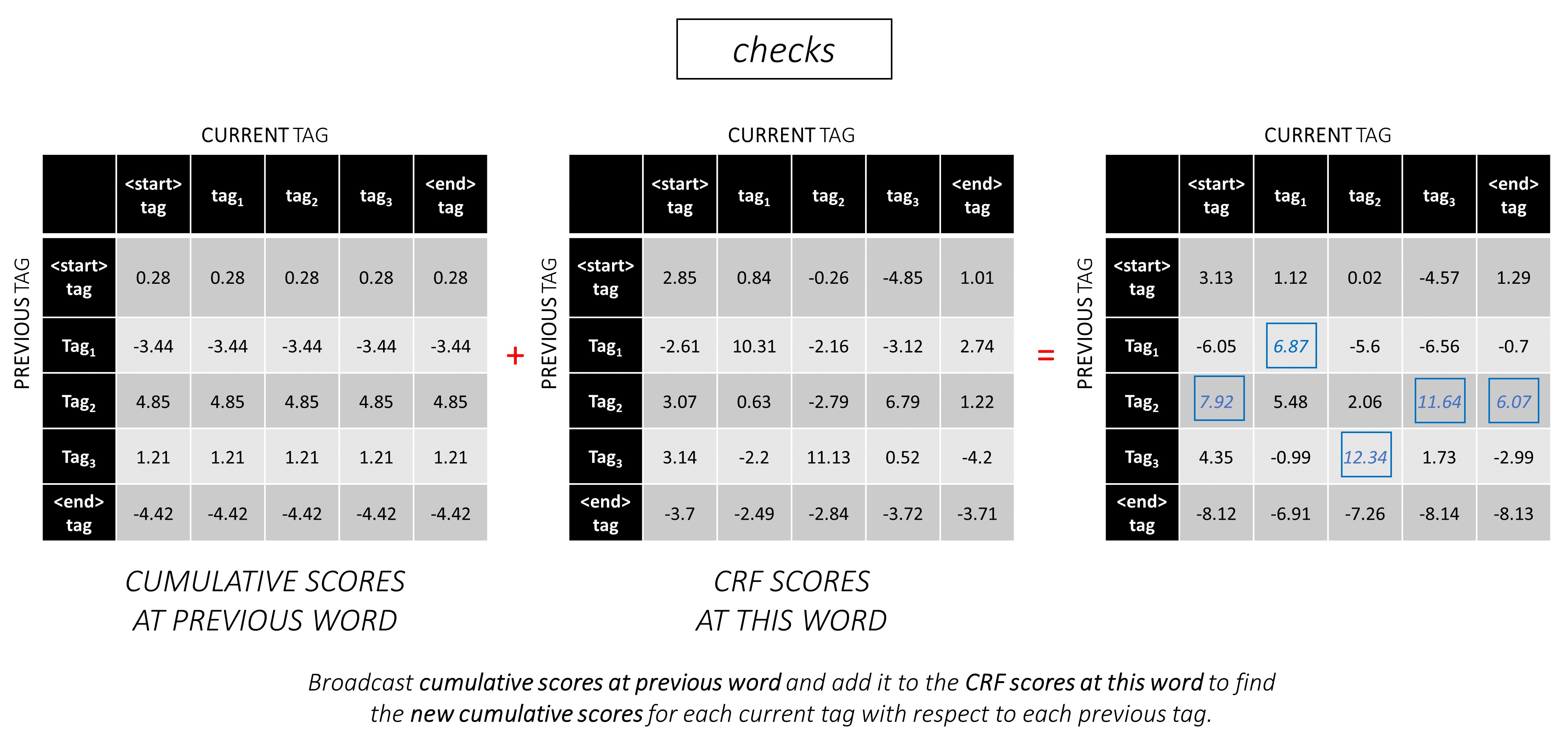
Para cada current_tag , considere apenas o máximo das pontuações de todos os previous_tag s.
Armazene backpoíteres, ou seja, as tags anteriores que correspondem a essas pontuações máximas.

Repita esse processo na terceira palavra.
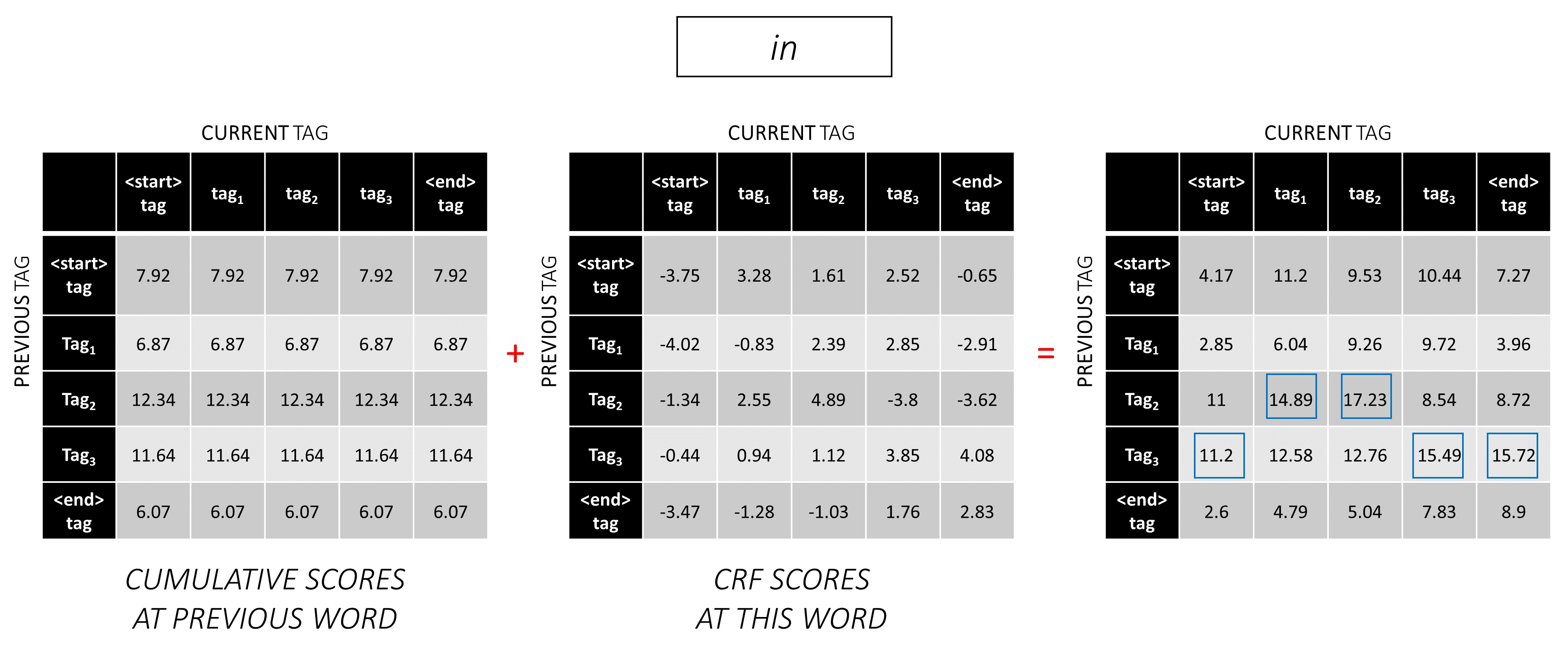
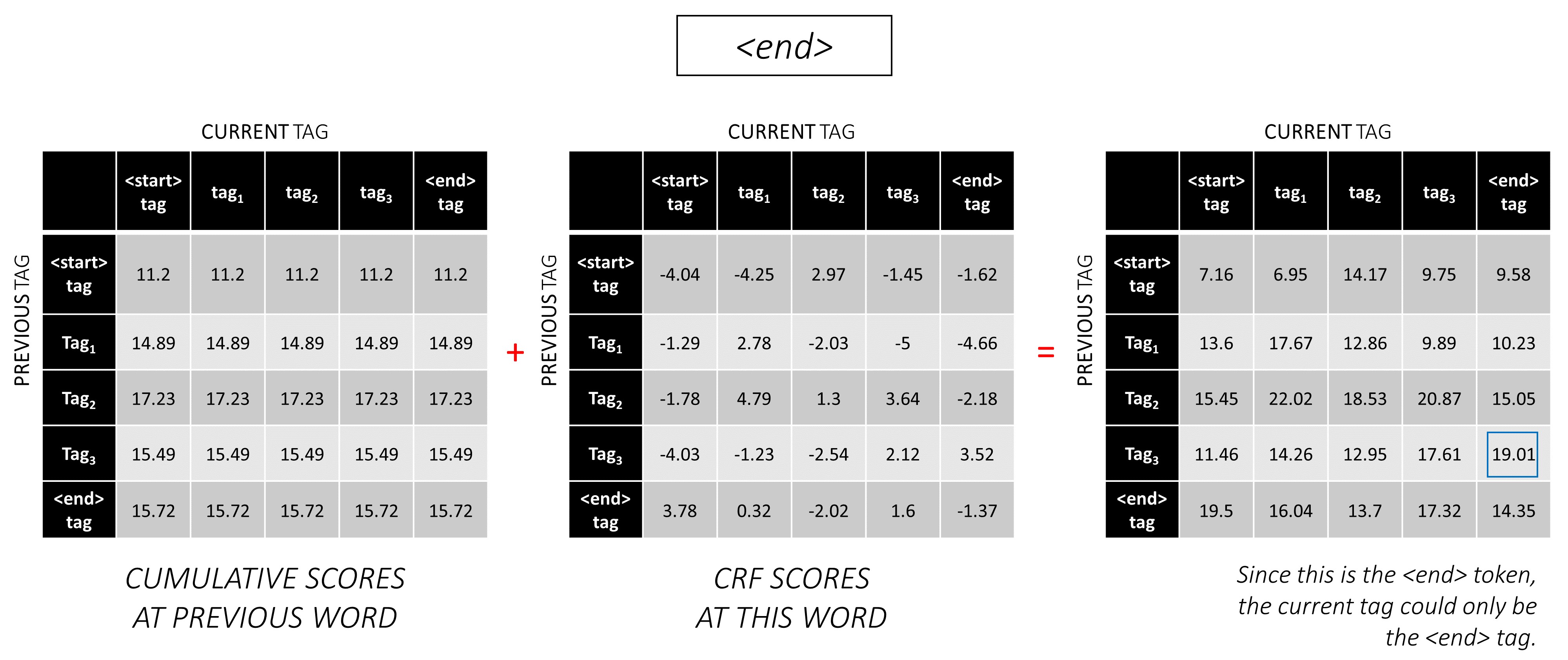
... e a última palavra, que é o token <end> .
Aqui, a única diferença é que você já conhece a tag correta. Você precisa da pontuação máxima e da backpointer apenas para a tag <end> .
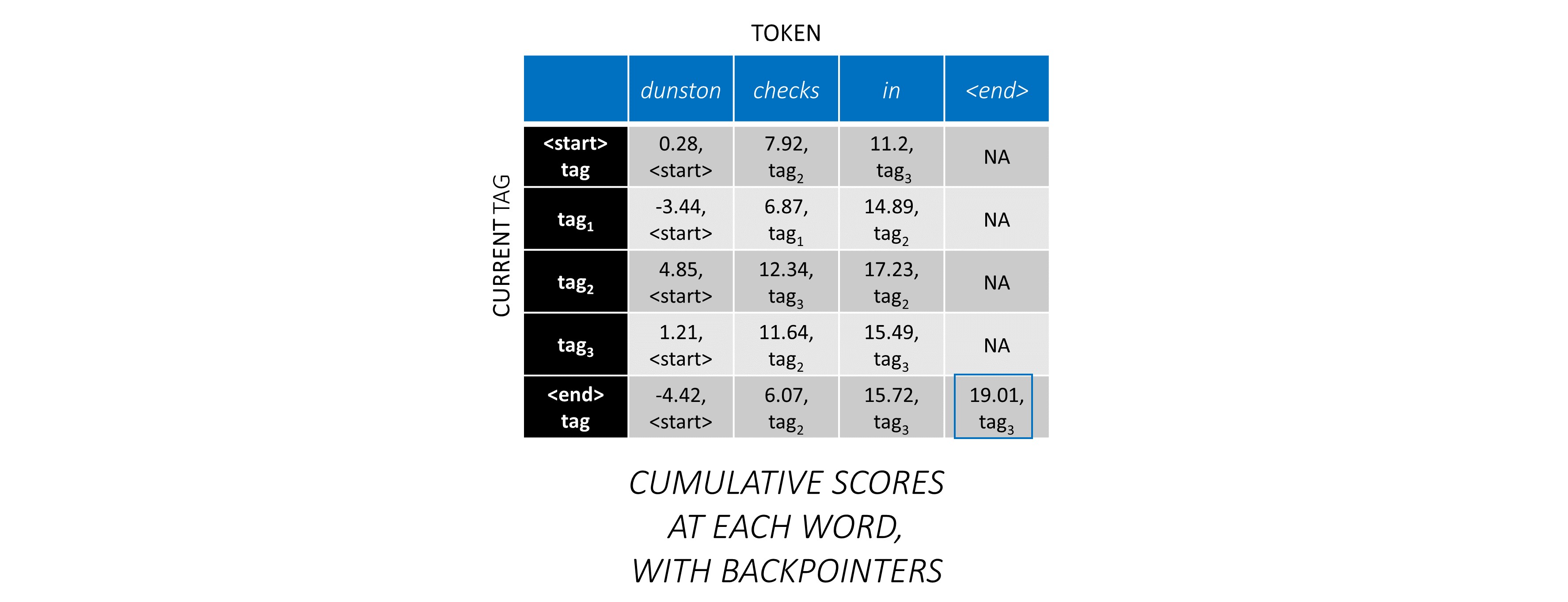
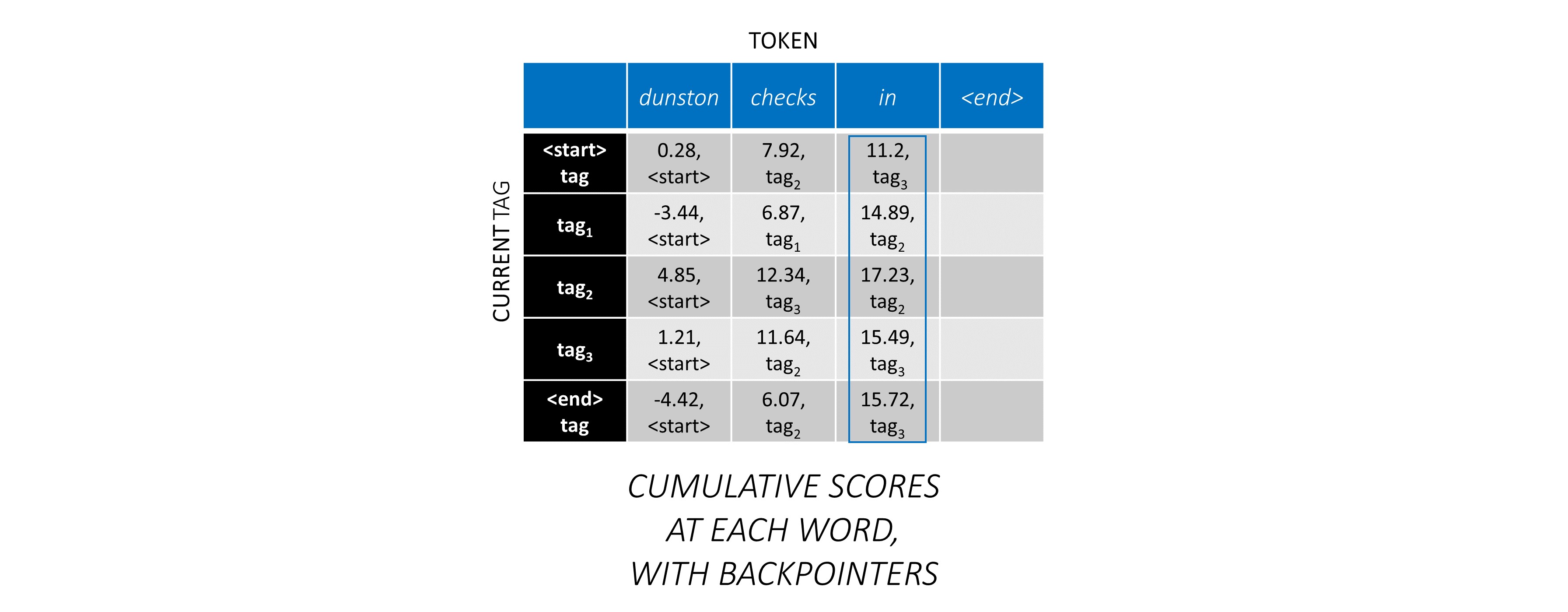
Agora que você acumulou as pontuações do CRF em toda a sequência, você rastreia para trás para revelar a sequência de tags com a maior pontuação possível .
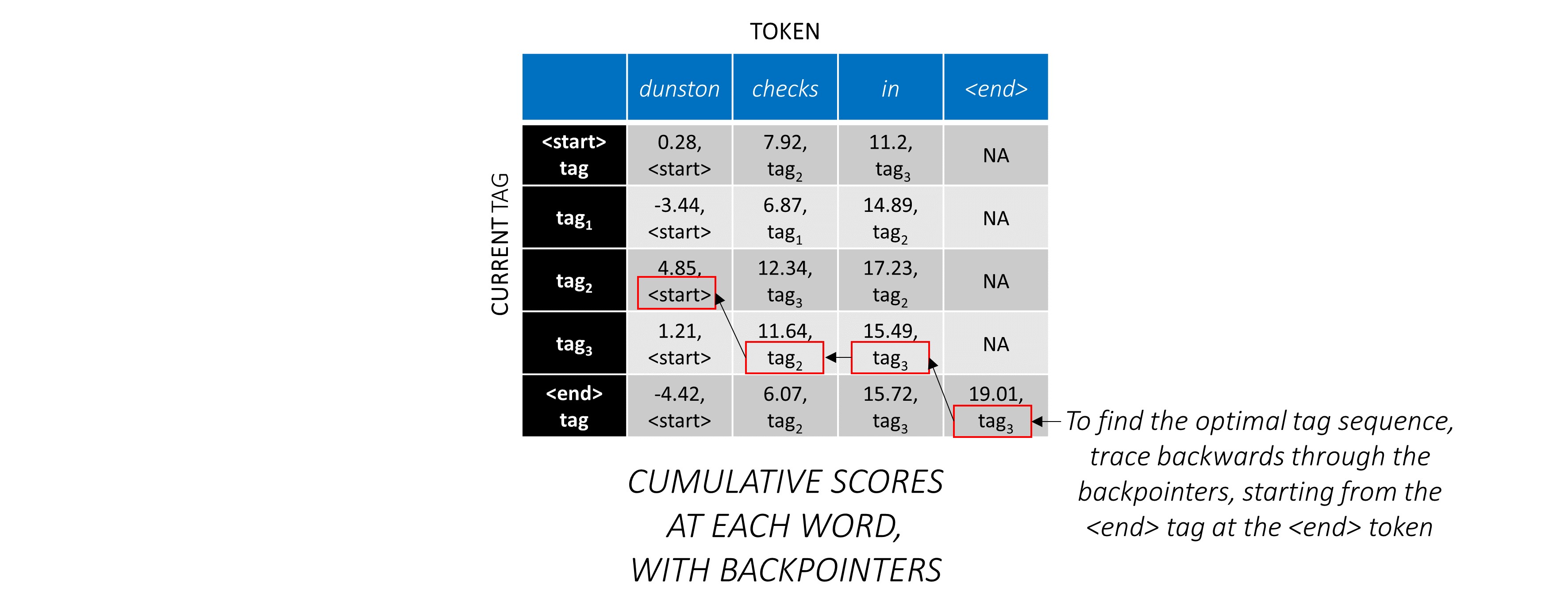
Descobrimos que a sequência de tags mais ideal para dunston checks in <end> é tag_2 tag_3 tag_3 <end> .
As seções abaixo descrevem brevemente a implementação.
Eles são feitos para fornecer algum contexto, mas os detalhes são melhor compreendidos diretamente do código , o que é bastante comentado.
Eu uso o conjunto de dados NER da Conll 2003 para comparar meus resultados com o artigo.
Aqui está um trecho -
-DOCSTART- -X- O O
EU NNP I-NP I-ORG
rejects VBZ I-VP O
German JJ I-NP I-MISC
call NN I-NP O
to TO I-VP O
boycott VB I-VP O
British JJ I-NP I-MISC
lamb NN I-NP O
. . O O
Esse conjunto de dados não deve ser distribuído publicamente, embora você possa encontrá -lo em algum lugar online.
Existem vários conjuntos de dados públicos on -line que você pode usar para treinar o modelo. Isso não pode ser 100% anotado humano, mas são suficientes.
Para marcação de NER, você pode usar o Groningen Significado Bank.
Para marcação de POS, o NLTK possui um pequeno conjunto de dados disponível que você pode acessar com nltk.corpus.treebank.tagged_sents() .
Você teria que convertê -lo no formato de dados NER do CONLL 2003 ou modificar o código referenciado na seção Data Pipeline.
Precisamos de oito insumos.
Essas são as seqüências de palavras que devem ser marcadas.
dunston checks in
Conforme discutido anteriormente, não usaremos tokens <start> , mas precisaremos usar tokens <end> .
dunston, checks, in, <end>
Como passamos as frases como tensores de tamanho fixo, precisamos fazer frases para encaixar (que são naturalmente de comprimento variável) ao mesmo comprimento com os tokens <pad> .
dunston, checks, in, <end>, <pad>, <pad>, <pad>, ...
Além disso, criamos um word_map que é um mapeamento de índice para cada palavra no corpus, incluindo os tokens <end> e <pad> . Pytorch, como outras bibliotecas, precisa de palavras codificadas como índices para procurar incorporações para elas ou para identificar seu lugar nas pontuações previstas das palavras.
4381, 448, 185, 4669, 0, 0, 0, ...
Portanto, as seqüências de palavras alimentadas ao modelo devem ser um Int de dimensões N, L_w onde N é o lote_size e L_w é o comprimento acolchoado das seqüências de palavras (geralmente o comprimento da sequência de palavras mais longa).
Estas são as seqüências de caracteres na direção direta.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' '
Precisamos de tokens <end> nas seqüências de caracteres para corresponder ao token <end> nas seqüências de palavras. Como usaremos os recursos no nível do caractere em cada palavra na sequência da palavra, precisamos de recursos no nível do caractere em <end> na sequência da palavra.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>
Também precisamos prendê -los.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>, <pad>, <pad>, <pad>, ...
E codificá -los com um char_map .
29, 2, 12, 8, 7, 14, 12, 3, 6, 18, 1, 6, 21, 8, 3, 17, 12, 3, 60, 0, 0, 0, ...
Portanto, as sequências de caracteres avançadas alimentadas ao modelo devem ser um Int de dimensões N, L_c , onde L_c é o comprimento acolchoado das seqüências de caracteres (geralmente o comprimento da sequência de caracteres mais longa).
Isso seria processado da mesma forma que a sequência avançada, mas para trás. (Os tokens <end> ainda estariam no final, naturalmente.)
'n', 'i', ' ', 's', 'k', 'c', 'e', 'h', 'c', ' ', 'n', 'o', 't', 's', 'n', 'u', 'd', ' ', <end>, <pad>, <pad>, <pad>, ...
12, 17, 3, 8, 21, 6, 1, 18, 6, 3, 12, 14, 7, 8, 12, 2, 29, 3, 60, 0, 0, 0, ...
Portanto, as seqüências de caracteres atrasadas alimentadas ao modelo devem ser um Int de dimensões N, L_c .
Esses marcadores são posições nas seqüências de caracteres nas quais extraímos recursos para -
Extrairemos recursos no final de todos os espaço ' ' na sequência do personagem e no token <end> .
Para a sequência de personagens avançados, extraímos em -
7, 14, 17, 18
Estes são pontos após dunston , checks , in , <end> , respectivamente. Assim, temos um marcador para cada palavra na sequência da palavra , o que faz sentido. (Nos modelos de idiomas, no entanto, como estamos prevendo a próxima palavra, não prevemos no marcador que corresponde a <end> >.)
Nós os encaixamos com 0 s. Não importa com o que prendemos, desde que sejam índices válidos. (Vamos extrair recursos nas almofadas, mas não os usaremos.)
7, 14, 17, 18, 0, 0, 0, ...
Eles são acolchoados para o comprimento acolchoado das seqüências de palavras, L_w .
Portanto, os marcadores de caracteres avançados alimentados ao modelo devem ser um Int de dimensões N, L_w .
Para os marcadores nas seqüências de caracteres para trás, também encontramos as posições de todo espaço ' ' e o token <end> .
Também garantimos que essas posições estejam na mesma ordem de palavra que nos marcadores avançados . Esse alinhamento facilita a concatenação de recursos extraídos das seqüências de caracteres para frente e para trás e também impede a ter que reordenar os alvos nos modelos de idiomas.
17, 9, 2, 18
Estes são pontos após notsnud , skcehc , ni , <end> respectivamente.
Padamos com 0 s.
17, 9, 2, 18, 0, 0, 0, ...
Portanto, os marcadores de caracteres atrasados alimentados ao modelo devem ser um Int de dimensões N, L_w .
Vamos supor que as tags corretas para dunston, checks, in, <end> são -
tag_2, tag_3, tag_3, <end>
Temos um tag_map (contendo as tags <start> , tag_1 , tag_2 , tag_3 , <end> ).
Normalmente, nós apenas os codificávamos diretamente (antes de preenchimento) -
2, 3, 3, 5
Estas são as codificações 1D , ou seja, posições de tag em um mapa de tag 1D .
Mas as saídas da camada CRF são 2D m, m tensores em cada palavra. Precisamos codificar posições de tag nessas saídas 2D .
As posições de tag corretas são marcadas em vermelho.
(0, 2), (2, 3), (3, 3), (3, 4)
Se desenrolarmos essas pontuações em um tensor 1D m*m , então as posições da tag no tensor desenroladas seria
tag_map [ previous_tag ] * len ( tag_map ) + tag_map [ current_tag ] Portanto, codificamos tag_2, tag_3, tag_3, <end> AS
2, 13, 18, 19
Observe que você pode recuperar os índices tag_map originais, tomando o módulo
t % len ( tag_map ) Eles serão acolchoados para o comprimento acolchoado das seqüências de palavras, L_w .
Portanto, as tags alimentadas com o modelo devem ser um Int de dimensões N, L_w .
Estes são os comprimentos reais das seqüências de palavras, incluindo os tokens <end> . Como o Pytorch suporta gráficos dinâmicos, calcularemos apenas esses comprimentos e não sobre os <pads> .
Portanto, os comprimentos das palavras alimentados ao modelo devem ser um Int de dimensões N .
Estes são os comprimentos reais das seqüências de caracteres, incluindo os tokens <end> . Como o Pytorch suporta gráficos dinâmicos, calcularemos apenas esses comprimentos e não sobre os <pads> .
Portanto, os comprimentos dos caracteres alimentados ao modelo devem ser um Int de dimensões N .
Consulte read_words_tags() em utils.py .
Isso lê os arquivos de entrada no formato Conll 2003 e extrai as seqüências de palavras e tags.
Consulte create_maps() em utils.py .
Aqui, criamos mapas de codificação para palavras, caracteres e tags. Nós binamos palavras e personagens raros como <unk> s (desconhecidos).
Consulte create_input_tensors() em utils.py .
Geramos as oito entradas detalhadas nas entradas na seção Modelo.
Consulte load_embeddings() em utils.py .
Carregamos incorporações pré-treinadas, com a opção de expandir o word_map para incluir palavras fora do corpus presentes no vocabulário de incorporação. Observe que isso também pode incluir palavras raras no corpus que foram <unk> como antes.
Consulte WCDataset em datasets.py .
Esta é uma subclasse do Dataset Pytorch. Ele precisa de um método __len__ definido, que retorna o tamanho do conjunto de dados e um método __getitem__ que retorna i conjunto de oito entradas para o modelo.
O Dataset será usado por um Pytorch DataLoader em train.py para criar e alimentar lotes de dados ao modelo para treinamento ou validação.
Veja Highway em models.py .
Uma transformação é uma transformação linear relativa ativada da entrada. Um portão é uma transformação linear ativada por sigmóide da entrada. Observe que ambas as transformações devem ter o mesmo tamanho da entrada , para permitir a adição da entrada em uma conexão residual.
Os num_layers atribuem especifica quantas operações de conexão residual de transformação por gate-portas que realizamos em série. Geralmente apenas um é suficiente.
Armazenamos o número necessário de camadas de transformação e portão em ModuleList() s separado e usamos for loop para executar operações sucessivas.
Consulte LM_LSTM_CRF em models.py .
No início, classificamos as seqüências de caracteres para frente e para trás diminuindo os comprimentos . Isso é necessário para usar pack_padded_sequence() para que o LSTM calcule apenas o timesteps válido, ou seja, o comprimento verdadeiro das seqüências.
Lembre -se de também classificar todos os outros tensores na mesma ordem.
Consulte dynamic_rnn.py para obter uma ilustração de como pack_padded_sequence() pode ser usado para aproveitar os recursos dinâmicos de gráficos e lotes dinâmicos da Pytorch para que não processemos as almofadas. Ele achata as seqüências classificadas pelo Timestep enquanto ignora as almofadas, e o LSTM calcula apenas o tamanho eficaz do lotes N_t em cada timestep .
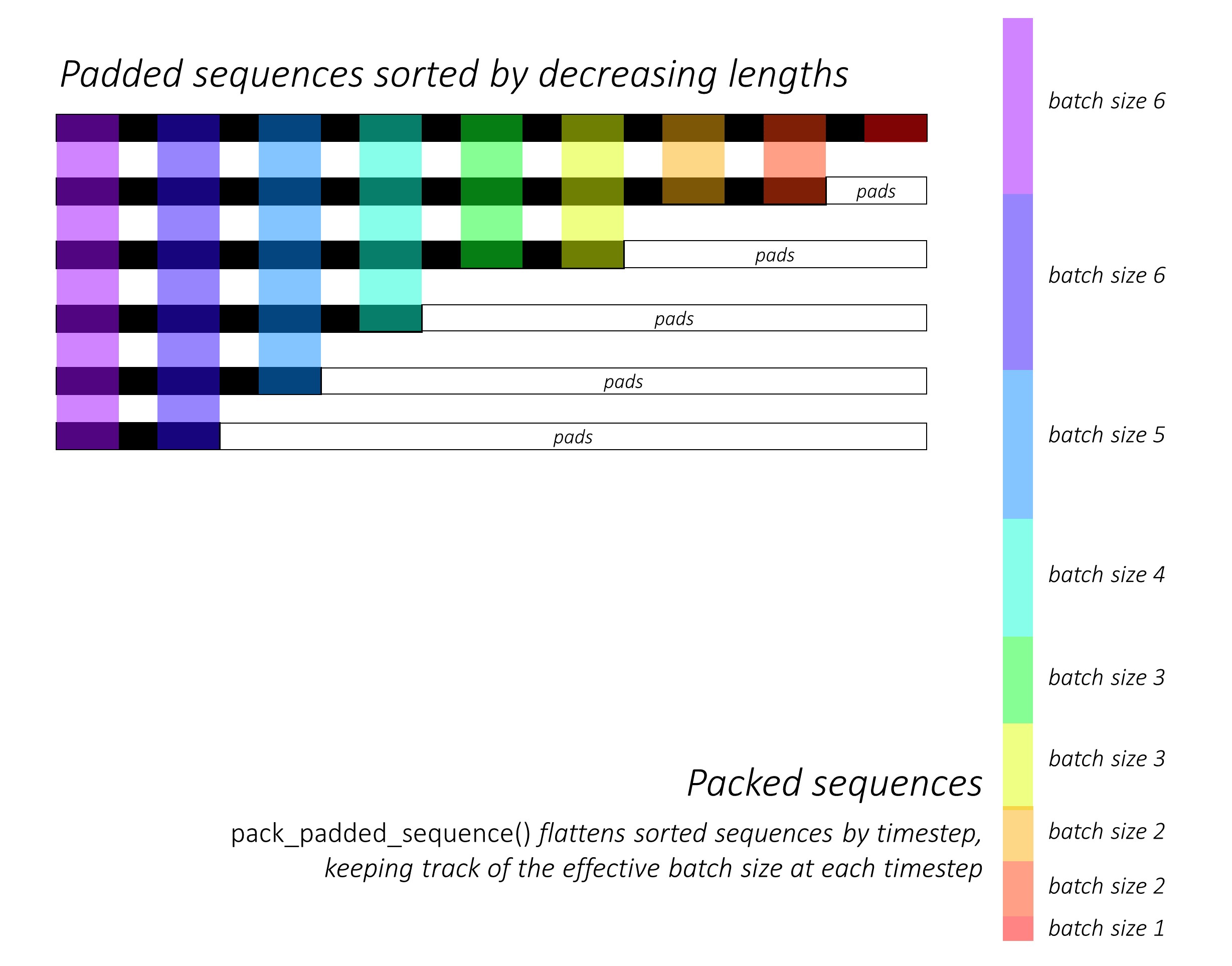
A classificação permite que o Top N_t em qualquer timestep alinhe com as saídas da etapa anterior . No terceiro timestep, por exemplo, processamos apenas as 5 principais imagens, usando as 5 principais saídas da etapa anterior. Exceto pela classificação, tudo isso é tratado internamente pela Pytorch, mas ainda é muito útil entender o que pack_padded_sequence() faz, para que possamos usá -lo em outros cenários para obter fins semelhantes. (Veja a pergunta relacionada sobre o manuseio de sequências de comprimento variável na seção Perguntas frequentes.)
Após a classificação, aplicamos os LSTMs para frente e para trás nas packed_sequences para frente e para trás, respectivamente. Usamos pad_packed_sequence() para desbloquear e re-padar as saídas.
Extraímos apenas as saídas nos marcadores de caracteres para a frente e para trás com gather . Esta função é muito útil para extrair apenas certos índices de um tensor que são especificados em um tensor separado.
Essas saídas extraídas são processadas pelas camadas de rodovias para frente e para trás antes de aplicar uma camada linear para calcular as pontuações sobre o vocabulário para prever a próxima palavra em cada marcador. Fazemos isso apenas durante o treinamento, pois não faz sentido realizar modelagem de idiomas para o aprendizado de várias tarefas durante a validação ou inferência. O atributo training de qualquer modelo é definido com model.train() ou model.eval() em train.py . (Observe que isso é usado principalmente para ativar ou desativar as camadas de abandono e norma em lote em um modelo Pytorch durante o treinamento e a inferência, respectivamente.)
Consulte LM_LSTM_CRF em models.py (continuação).
Também classificamos as seqüências de palavras diminuindo os comprimentos , porque nem sempre pode haver uma correlação entre os comprimentos das sequências de palavras e as seqüências de caracteres.
Lembre -se de também classificar todos os outros tensores na mesma ordem.
Concatenamos as saídas LSTM de caracteres para a frente e para trás nos marcadores e o percorrer pela terceira camada de rodovia . Isso extrairá as informações da sub-palavra em cada palavra que usaremos para rotulagem de sequência.
Concatenamos esse resultado com a palavra incorporação e calculamos as saídas BLSTM sobre o packed_sequence .
Ao re-acalmar com pad_packed_sequence() , temos os recursos que precisamos alimentar para a camada CRF.
Veja CRF em models.py .
Você pode achar que essa camada é surpreendentemente direta, considerando o valor que agrega ao nosso modelo.
Uma camada linear é usada para transformar as saídas do BLSTM em pontuações para cada tag, que são as pontuações de emissão .
Um único tensor é usado para manter as pontuações de transição . Esse tensor é um Parameter do modelo, o que significa que é atualizável durante a retropropagação, assim como os pesos das outras camadas.
Para encontrar as pontuações do CRF, calcule as pontuações de emissão em cada palavra e adicione -as às pontuações de transição , depois de transmitir ambas conforme descrito na visão geral da CRF.
Veja ViterbiLoss em models.py .
Estabelecemos na visão geral da perda do Viterbi que queremos minimizar a diferença entre o log-soma-EXP das pontuações de todas as sequências de tags válidas possíveis e a pontuação da sequência de tags de ouro , ou seja, log-sum-exp(all scores) - gold score .
Summos as pontuações da CRF de cada tag verdadeira, conforme descrito anteriormente para calcular a pontuação do ouro .
Lembre -se de como codificamos sequências de tags com suas posições nas pontuações de CRF não controladas? Extraímos as pontuações nessas posições com gather() e eliminamos as almofadas com pack_padded_sequences() antes de soma.
Encontrar o log-soma das pontuações de todas as seqüências possíveis é um pouco mais complicado. Usamos um loop for para iterar sobre os timesteps. Em cada timestep, acumulamos escores para cada current_tag por -
current_tag para cada previous_tag . Fazemos isso apenas no tamanho eficaz do lote, ou seja, para sequências que ainda não foram concluídas. (Nossas seqüências ainda são classificadas diminuindo o comprimento das palavras, do modelo LM-LSTM-CRF .)current_tag , calcule o log-sum-exp sobre os previous_tag s para encontrar as novas pontuações acumuladas em cada current_tag . Após calcular os comprimentos variáveis de todas as seqüências, ficamos com um tensor de dimensões N, m , onde m é o número de tags (atuais). Estas são as pontuações acumuladas de log-soma-EXP em todas as seqüências possíveis que terminam em cada uma das tags m No entanto, como as seqüências válidas podem terminar apenas com a tag <end> , soma apenas a coluna <end> para encontrar o log-sum-exp das pontuações de todas as seqüências válidas possíveis .
Encontramos a diferença, log-sum-exp(all scores) - gold score .
Veja ViterbiDecoder in inference.py .
Isso implementa o processo descrito na visão geral de decodificação do Viterbi.
Acumulamos as pontuações em um for for de maneira semelhante à que fizemos em ViterbiLoss , exceto aqui que encontramos o máximo das pontuações previous_tag para cada current_tag , em vez de calcular o log-sum-exp. Também acompanhamos o previous_tag que corresponde a essa pontuação máxima em um tensor de backpointer.
Pontamos o tensor de backpointer com tags <end> , porque isso nos permite rastrear para trás sobre as almofadas, chegando à tag <end> real , e depois que o retorno real começa.
Veja train.py .
Os parâmetros do modelo (e treinando -o) estão no início do arquivo, para que você possa verificá -los ou modificá -los facilmente, caso deseje.
Para treinar seu modelo do zero , basta executar este arquivo -
python train.py
Para retomar o treinamento em um ponto de verificação , aponte para o arquivo correspondente com o parâmetro de checkpoint no início do código.
Observe que realizamos a validação no final de todas as épocas de treinamento.
Você notará que reduzimos as entradas em cada lote para os comprimentos máximos da sequência nesse lote . Isso é para que não tenhamos mais almofadas em cada lote que realmente precisamos.
Mas por que? Embora os RNNs em nosso modelo não calculem as almofadas, as camadas lineares ainda o fazem . É bastante direto mudar isso - veja a pergunta relacionada sobre o manuseio de sequências de comprimento variável na seção Perguntas frequentes.
Para este tutorial, imaginei que um pouco de computação extra sobre algumas almofadas valia a direita de não ter que realizar uma série de operações - rodovia, CRF, outras camadas lineares, concatenações - em uma packed_sequence .
No cenário de várias tarefas, optamos por somar as perdas de entropia cruzada das duas tarefas de modelagem de idiomas e a perda do Viterbi da tarefa de rotulagem de sequência.
Embora estejamos minimizando a soma dessas perdas , estamos realmente interessados em minimizar a perda do Viterbi em virtude de minimizar a soma dessas perdas . É a perda do Viterbi que reflete o desempenho na tarefa principal.
Usamos pack_padded_sequence() para eliminar as almofadas sempre que necessário.
Como no artigo, usamos a pontuação de F1 com média macro como critério para parar cedo . Naturalmente, a computação da pontuação F1 requer decodificar o Viterbi as pontuações do CRF para gerar nossas sequências de tags ideais.
Usamos pack_padded_sequence() para eliminar as almofadas sempre que necessário.
Eu segui os parâmetros na implementação dos autores o mais próximo possível.
Eu usei um tamanho de lote de 10 frases. Empreguei descida de gradiente estocástico com impulso. A taxa de aprendizado foi deteriorada em todas as épocas. Eu usei incorporações pré-tenhadas de luva 100D sem ajuste fino.
Demorou cerca de 80s para treinar uma época em um Titan X (Pascal).
A pontuação de F1 no conjunto de validação atingiu 91% em torno da Epoch 50 e atingiu o pico de 91.6% na época 171. Eu o executei para um total de 200 épocas. Isso é bem próximo dos resultados no artigo.
Você pode baixar este modelo pré -traido aqui.
Como decidimos se precisamos de <start> e <end> Tokens para um modelo que usa sequências?
Se isso parecer confuso no início, ele se resolverá facilmente quando você pensar nos requisitos do modelo que planeja treinar.
Para rotulagem de sequência com um CRF, você precisa do token <end> ( ou o token <start> ; veja a próxima pergunta) por causa de como as pontuações da CRF estão estruturadas.
No meu outro tutorial sobre legendas de imagem, usei tokens <start> e <end> . O modelo precisava começar a decodificar em algum lugar e aprender a reconhecer quando parar de decodificar durante a inferência.
Se você estiver executando a classificação de texto, você não precisaria.
Podemos ter o CRF gerar current_word -> next_word em vez de previous_word -> current_word ?
Sim. Nesse caso, você transmitia as pontuações de emissão como L, m, _ , e você teria um token <start> em todas as frases em vez de um token <end> . A etiqueta correta do token <start> sempre seria a tag <start> . A "próxima tag" da última palavra sempre seria a tag <end> .
Eu acho que a previous word -> current word é um pouco melhor porque existem modelos de idiomas no mix. Ele se encaixa muito bem para poder prever o token <end> na última palavra real e, portanto, aprender a reconhecer quando uma frase está concluída.
Por que estamos usando vocabulários diferentes para as entradas e saídas dos modelos de idiomas da sequência?
Os modelos de idiomas aprenderão a prever apenas as palavras que viu durante o treinamento. É realmente desnecessário, e um enorme desperdício de computação e memória, usar uma camada linear-softmax com ~ 400.000 palavras fora do corpus do arquivo de incorporação que nunca aprenderá a prever.
Mas podemos adicionar essas palavras à camada de entrada, mesmo que o modelo nunca as veja durante o treinamento. Isso ocorre porque estamos usando incorporações pré-treinadas na entrada. Não precisa vê -los porque os significados das palavras são codificados nesses vetores. Se já encontrou um chimpanzee antes, provavelmente sabe o que fazer com um orangutan .
É uma boa ideia ajustar as incorporações de palavras pré-treinadas que usamos neste modelo?
Abstro-me de ajustar fino, porque a maior parte do vocabulário de entrada não está no espaço. Most embeddings will remain the same while a few are fine-tuned. If fine-tuning changes these embeddings sufficiently, the model may not work well with the words that weren't fine-tuned. In the real world, we're bound to encounter many words that weren't present in a newspaper corpus from 2003.
What are some ways we can construct dynamic graphs in PyTorch to compute over only the true lengths of sequences?
If you're using an RNN, simply use pack_padded_sequence() . PyTorch will internally compute over only the true lengths. See dynamic_rnn.py for an example.
If you want to execute an operation (like a linear transformation) only on the true timesteps, pack_padded_sequences() is still the way to go. This flattens the tensor by timestep while removing the pads. You can perform your operation on this flattened tensor, and then use pad_packed_sequence() to unflatten it and re-pad it with 0 s.
Similarly, if you want to perform an aggregation operation, like computing the loss, use pack_padded_sequences() to eliminate the pads.
If you want to perform timestep-wise operations, you can take a leaf out of how pack_padded_sequences() works, and compute only on the effective batch size at each timestep with a for loop to iterate over the timesteps. We did this in the ViterbiLoss and ViterbiDecoder . I also used an LSTMCell() in this fashion in my image captioning tutorial.
Dunston Checks In ? Realmente?
I had no memory of this movie for twenty years. I was trying to think of a short sentence that would be easier to visualize in this tutorial and it just popped into my mind riding a wave of 90s nostalgia.

I wish I hadn't googled it though. Damn, the critics were harsh, weren't they? This gem was overwhelmingly and universally panned. I'm not sure I'd disagree if I watched it now, but that just goes to show the world is so much more fun when you're a kid.
Didn't have to worry about LM-LSTM-CRFs or nuthin...


