a PyTorch Tutorial to Sequence Labeling
1.0.0
这是序列标记的Pytorch教程。
这是我正在写的一系列教程中的第二个,内容涉及出色的Pytorch图书馆独自实施酷模型。
假定Pytorch,复发性神经网络的基础知识。
如果您是Pytorch的新手,请首先使用Pytorch阅读深度学习:60分钟的闪电战和学习示例的Pytorch。
问题,建议或更正可以作为问题发布。
我在Python 3.6中使用PyTorch 0.4 。
2020年1月27日:添加了两个新教程的工作代码 - 超分辨率和机器翻译
客观的
概念
概述
执行
训练
常见问题
构建一个可以在句子中标记每个单词的模型,其中包括实体,一部分语音等。

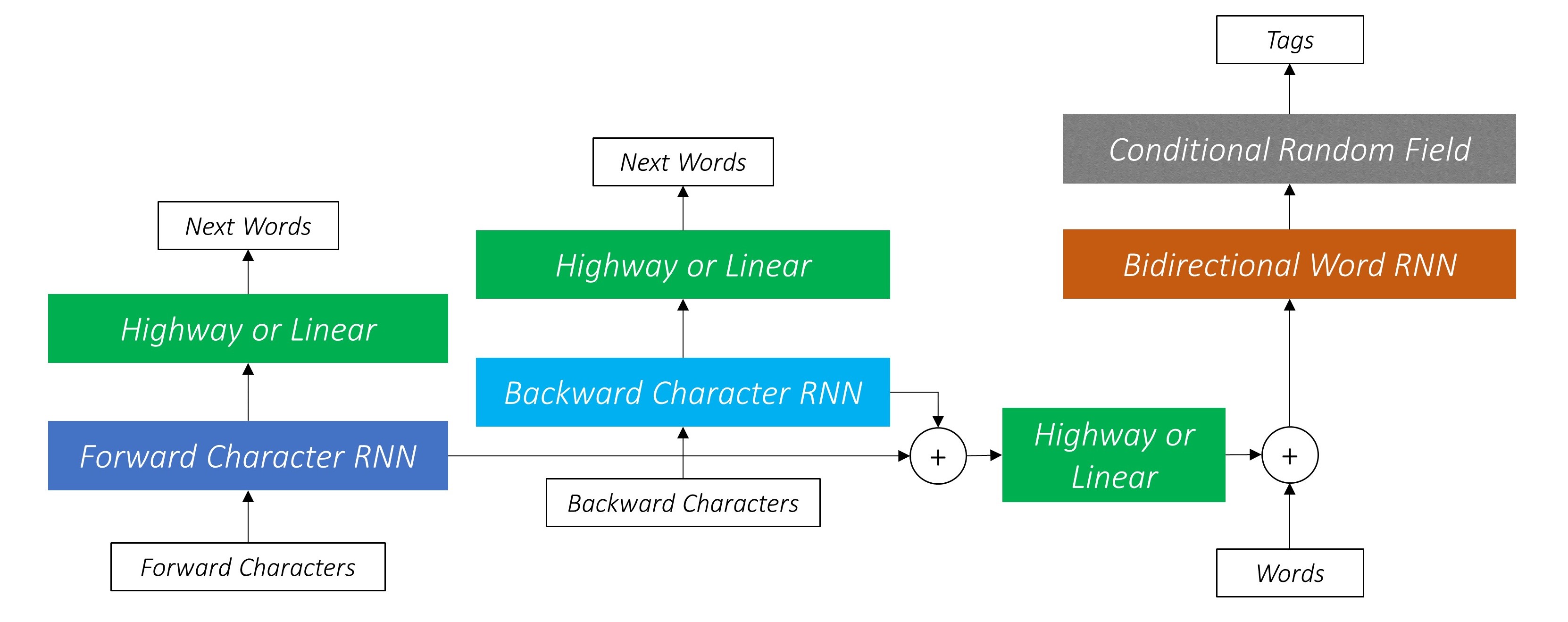
我们将使用任务感知的神经语言模型论文实施授权序列标签。这比大多数序列标记模型更为先进,但是您将学到许多有用的概念 - 而且效果很好。作者的原始实现可以在此处找到。
该模型很特别,因为它通过与语言模型同时训练它来增强序列标记任务。
序列标记。 du。
语言模型。语言建模是通过一系列单词或字符预测下一个单词或字符。神经语言模型在各种NLP任务中取得了令人印象深刻的结果,例如文本生成,机器翻译,图像字幕,光学字符识别以及您的工作。
角色rnns 。已知在文本中的单个字符上操作的RNN可以捕获基本样式和结构。在序列标记任务中,它们特别有用,因为子字通常可以为实体或标签产生重要的线索。
多任务学习。可用于训练模型的数据集通常很小。创建注释或手工制作的功能来帮助您的模型不仅繁琐,而且通常不适合您模型可能有用的不同域或设置。不幸的是,序列标记是一个很好的例子。有一种减轻此问题的方法 - 共同训练以臀部连接的多个模型将最大化每个模型可用的信息,从而提高性能。
有条件的随机字段。离散分类器在单词上预测类或标签。有条件的随机字段(CRF)可以更好地为您提供一个 - 他们不仅基于单词,而且还基于邻居预测标签。这是有道理的,因为一系列实体或标签中存在模式。 CRF被广泛用于建模有序信息,无论是用于序列标记,基因测序还是在计算机视觉中的对象检测和图像分割。
Viterbi解码。由于我们使用的是CRF,因此我们并没有在每个单词上预测正确的标签,而是我们预测单词序列的正确标签序列。 Viterbi解码是一种准确做到这一点的方法 - 从条件随机场计算出的分数中找到最佳的标签序列。
公路网络。完全连接的层是任何神经网络中的主食,可以在不同位置转换或提取特征。高速公路网络实现了这一目标,但也允许信息在转换中不受阻碍。这使深层网络效率更高或可行。
在本节中,我将介绍此模型。如果您已经熟悉它,则可以直接跳到实施部分或注释代码。
作者将模型称为语言模型 - 长期短期内存 - 条件随机字段,因为它涉及与LSTM + CRF组合的共同培训语言模型。
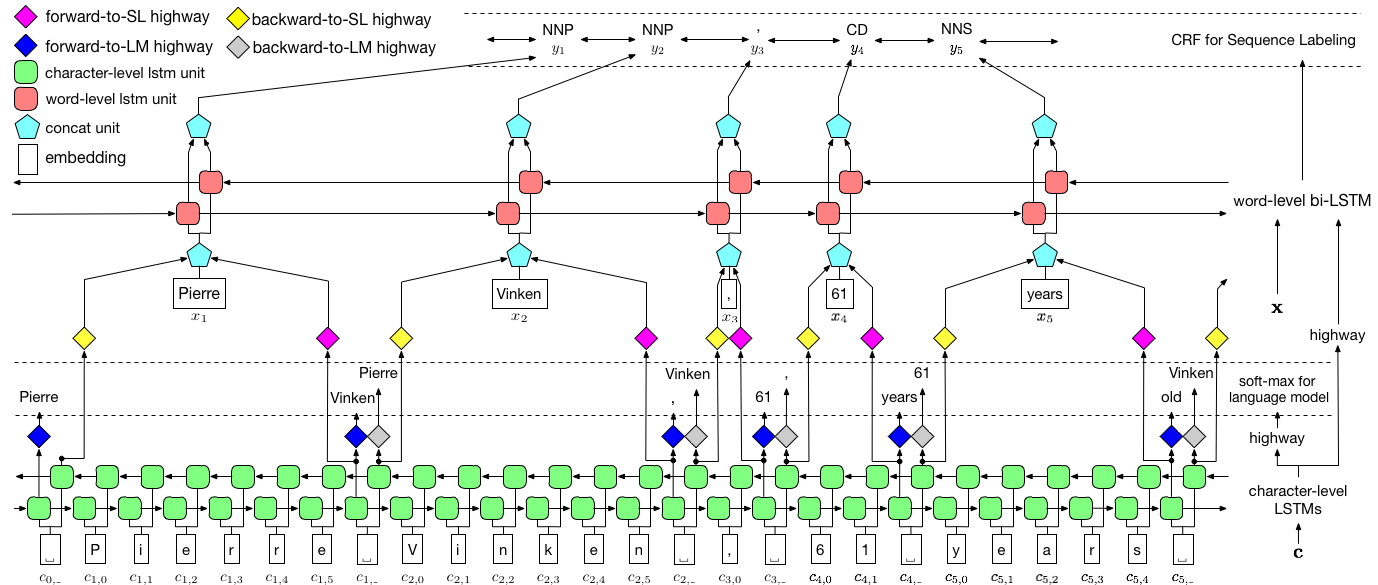
纸上的图像完全代表了整个模型,但是不必担心目前看起来是否太复杂。我们将其分解,仔细研究组件。
多任务学习是当您同时在两个或多个任务上训练模型。
通常,我们只对其中一项任务感兴趣 - 在这种情况下是序列标签。
但是,当神经网络中的层次有助于执行多个功能时,他们学到的比仅在主要任务上培训的情况要多。这是因为扩展了每一层中提取的信息以适应所有任务。当有更多信息可以使用时,主要任务的性能就会增强。
以这种方式丰富现有功能可以消除使用手工制作的功能进行序列标签的需求。
多任务学习期间的总损失通常是单个任务上损失的线性组合。组合的参数可以作为可更新的权重固定或学习。

由于我们正在汇总个人损失,因此您可以看到多个任务共享的上游层如何在反向传播期间从所有任务中收到所有更新。
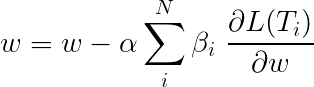
本文的作者只需添加损失( β=1 ),我们将做同样的事情。
让我们看一下组成我们模型的任务。
有三个。

这利用子字预测下一个单词。
我们在向后做同样的事情。 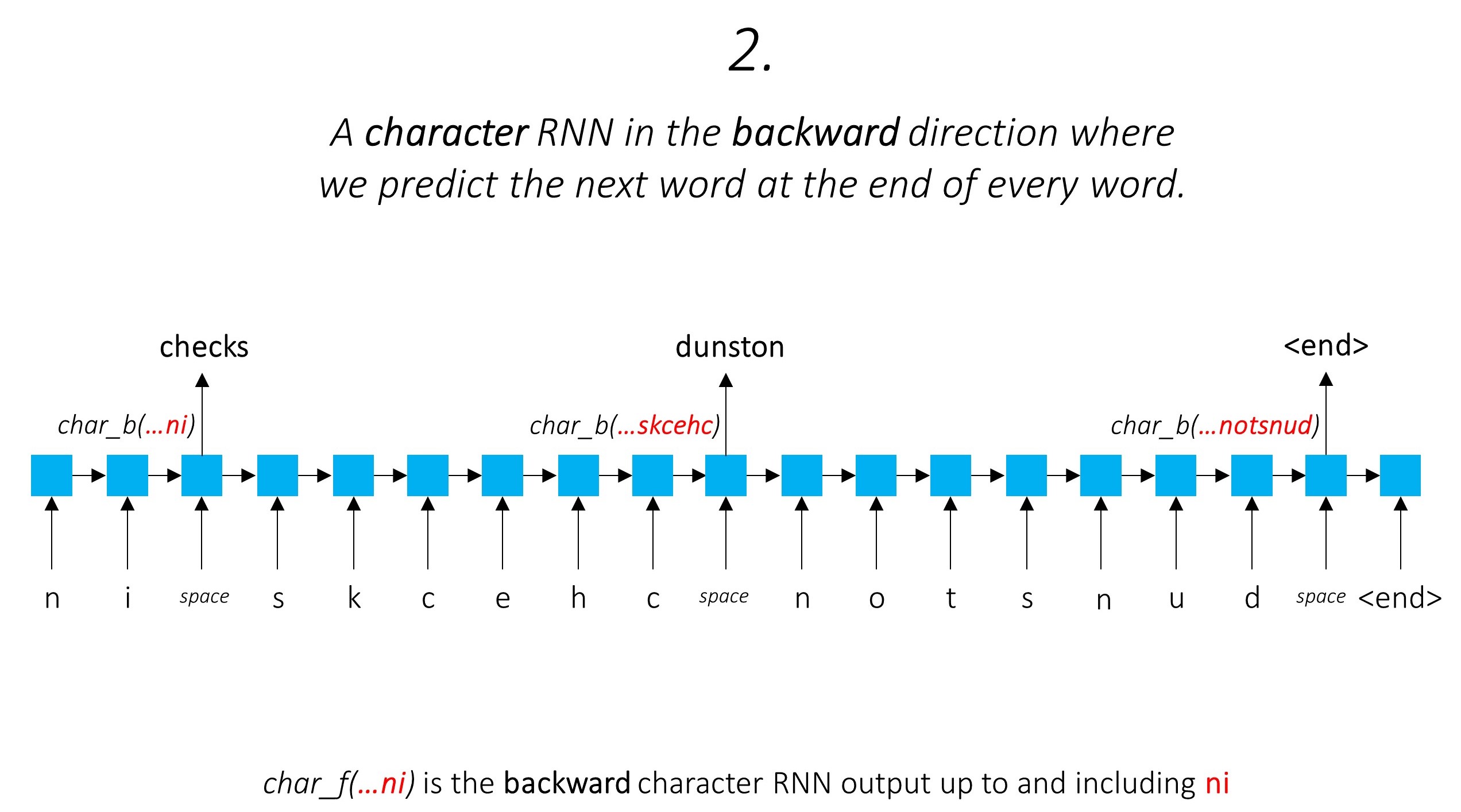
我们还将这两个字符RNN的输出用作我们单词rnn和条件随机字段(CRF)的输入,以执行我们的序列标记的主要任务。 
我们在标记任务中使用子字信息,因为它可以是标签的有力指标,无论是语音的一部分还是实体。例如,它可能会学会形容词通常以“ -y”或“ -ul”结尾,或者通常以“ -land”或“ -burg”结尾。
但是我们的子字特征,即。字符rnns的输出也充满了其他信息 - 由于模型1和2,它需要在向前和向后预测下一个单词所需的知识。
因此,我们的序列标记模型都使用
双向LSTM/RNN将这些功能编码为每个单词的新功能,其中包含有关单词及其邻居的信息,无论是单词级别还是字符级别。这形成了条件随机场的输入。
如果没有CRF,我们只会使用单个线性层将双向LSTM的输出转换为每个标签的分数。这些被称为排放分数,这是单词为某个标签的可能性的表示。
CRF不仅计算排放得分,而且还计算过渡分数,这是一个单词是一个标签的可能性,因为上一个单词是某个标签。因此,过渡分数衡量从一个标签过渡到另一个标签的可能性。
如果有m标签,则将过渡分数存储在一个钻机m, m的矩阵中,其中行代表上一个单词的标签,列代表当前单词的标签。该矩阵中的一个值在i, j是从上一个单词上的i th标签过渡到当前单词的j th标签的可能性。与排放分数不同,句子中的每个单词都没有定义过渡分数。他们是全球的。
在我们的模型中,CRF层在每个单词上输出发射和过渡分数的汇总。
对于长度为L的句子,排放得分将是L, m张量。由于每个单词的发射分数不取决于上一个单词的标签,因此我们创建了一个新的维度,例如L, _, m和广播(复制)沿这个方向的张量,以获取L, m, m Tensor。
过渡分数是m, m张量。由于过渡分数是全局的,并且不依赖于单词,因此我们创建一个新的维度,例如_, m, m和广播(复制)沿这个方向张量,以获得L, m, m张量。
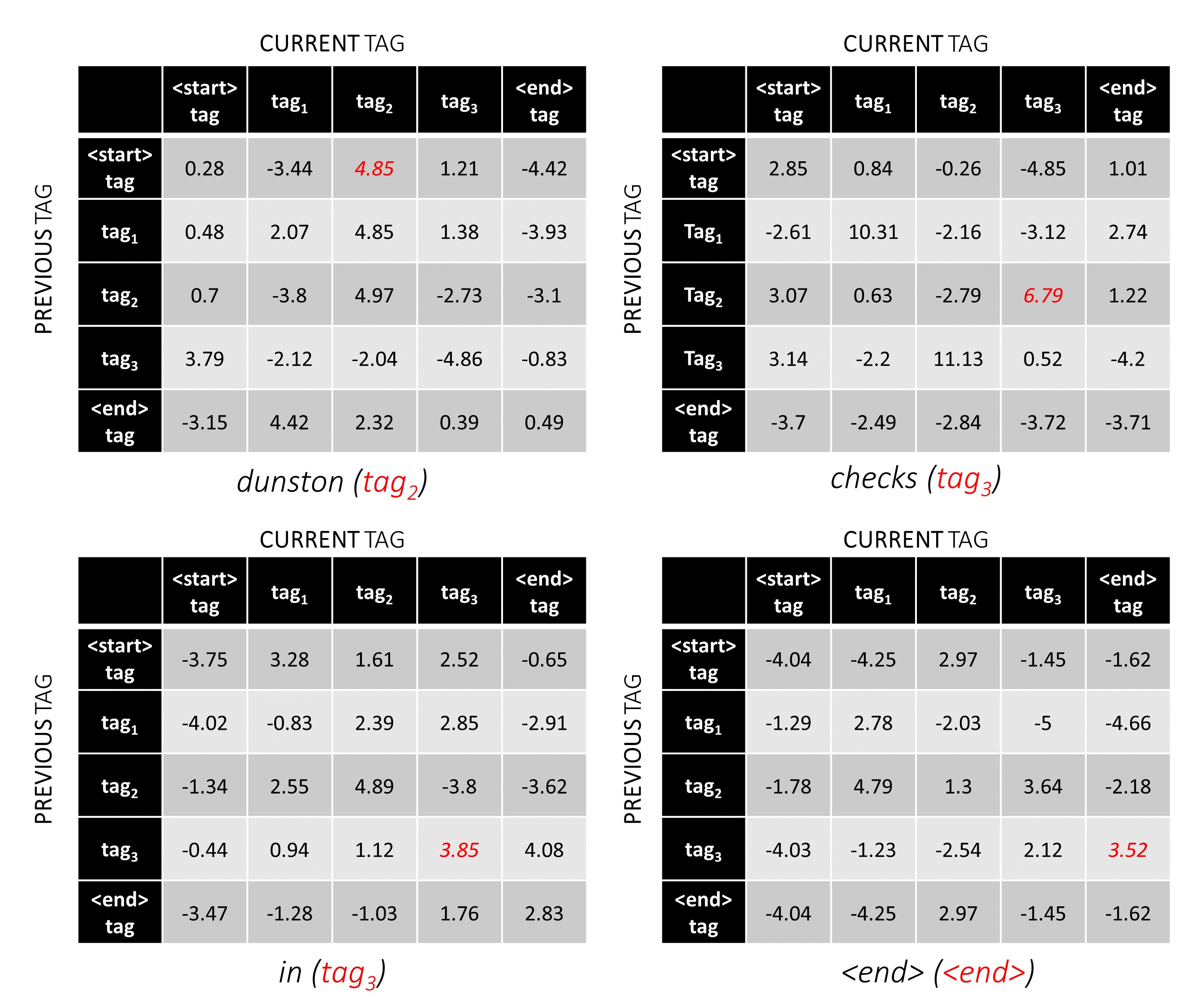
现在,我们可以添加它们以获得L, m, m张量的总得分。位置k, i, j处的值是k th单词的j th标签的发射分数的总和,考虑到上一个单词的k th单词的j th标签的过渡得分是i th标签。
对于我们的示例句子, dunston checks in <end> ,如果我们假设总共有5个标签,那么总得分将看起来像这样 -
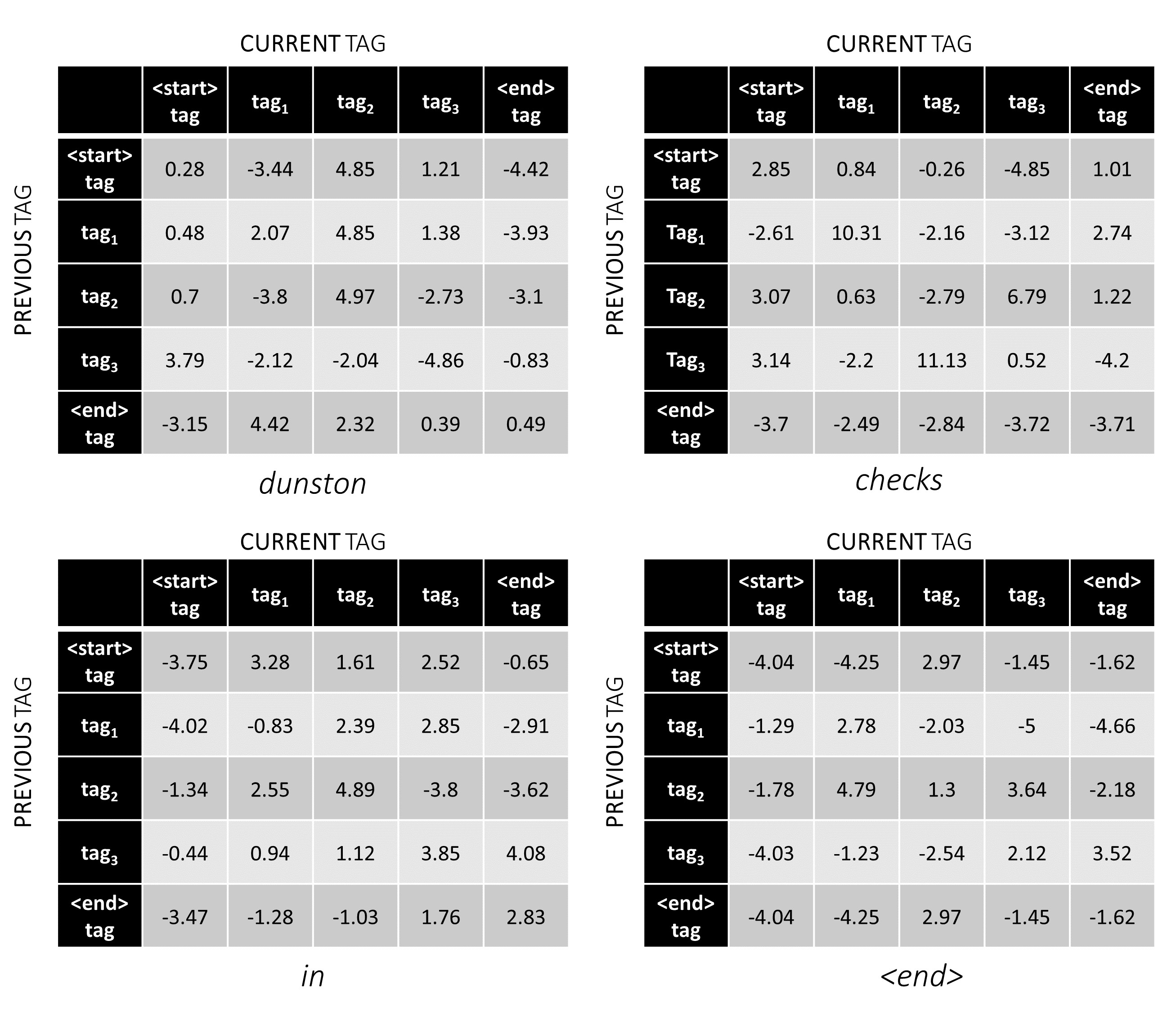
但是请等一下,为什么<start> end <end>标签?当我们使用时,为什么要使用<end>令牌?
<start>和<end>标签, <start>和<end>令牌由于我们正在对标签之间过渡的可能性进行建模,因此我们还将<start>和<end>标签包括在标签中。
鉴于先前的标签是<start>标签,该标签的过渡得分表示该标签的可能性是句子中的第一个标签。例如,句子通常以文章(A,AN,THE)或名词或代词开头。
考虑到某个上一个标签的<end>标签的过渡分数表明,先前标签的可能性是句子中的最后一个标签。
我们将在所有句子中使用<end>令牌,而不是<start>令牌,因为每个单词的总CRF分数是针对上一个单词的标签定义的,这在<start>令牌上是没有意义的。
<end>令牌的正确标签始终是<end>标签。第一个单词的“先前标签”始终是<start>标签。
为了说明,如果我们的示例句子dunston checks in <end>标签tag_2, tag_3, tag_3, <end> ,红色的值表示这些标签的分数。
我们通常使用激活的线性层来转换和处理RNN/LSTM的输出。
如果您熟悉剩余连接,我们可以在转换之前将输入添加到转换后的输出,从而为转换周围的数据流提供了一条路径。
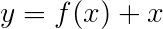
该路径是反向传播过程中梯度流的捷径,有助于深网的收敛。
高速公路网络类似于残差网络,但是我们使用Sigmoid激活的门来确定输入和转换后输出的比率。
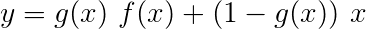
由于字符RNN有助于多个任务,因此使用高速公路网络来从其输出中提取特定于任务的信息。
因此,我们将在合并模型的三个位置使用高速公路网络 -
在天真的共同训练环境中,我们将角色RNN的输出直接用于多个任务,即没有转换,任务性质之间的不一致可能会损害性能。
到目前为止,我们的组合网络的外观可能很清楚。
逐渐删除网络的一部分会导致逐渐简单的网络,这些网络被广泛用于序列标记。
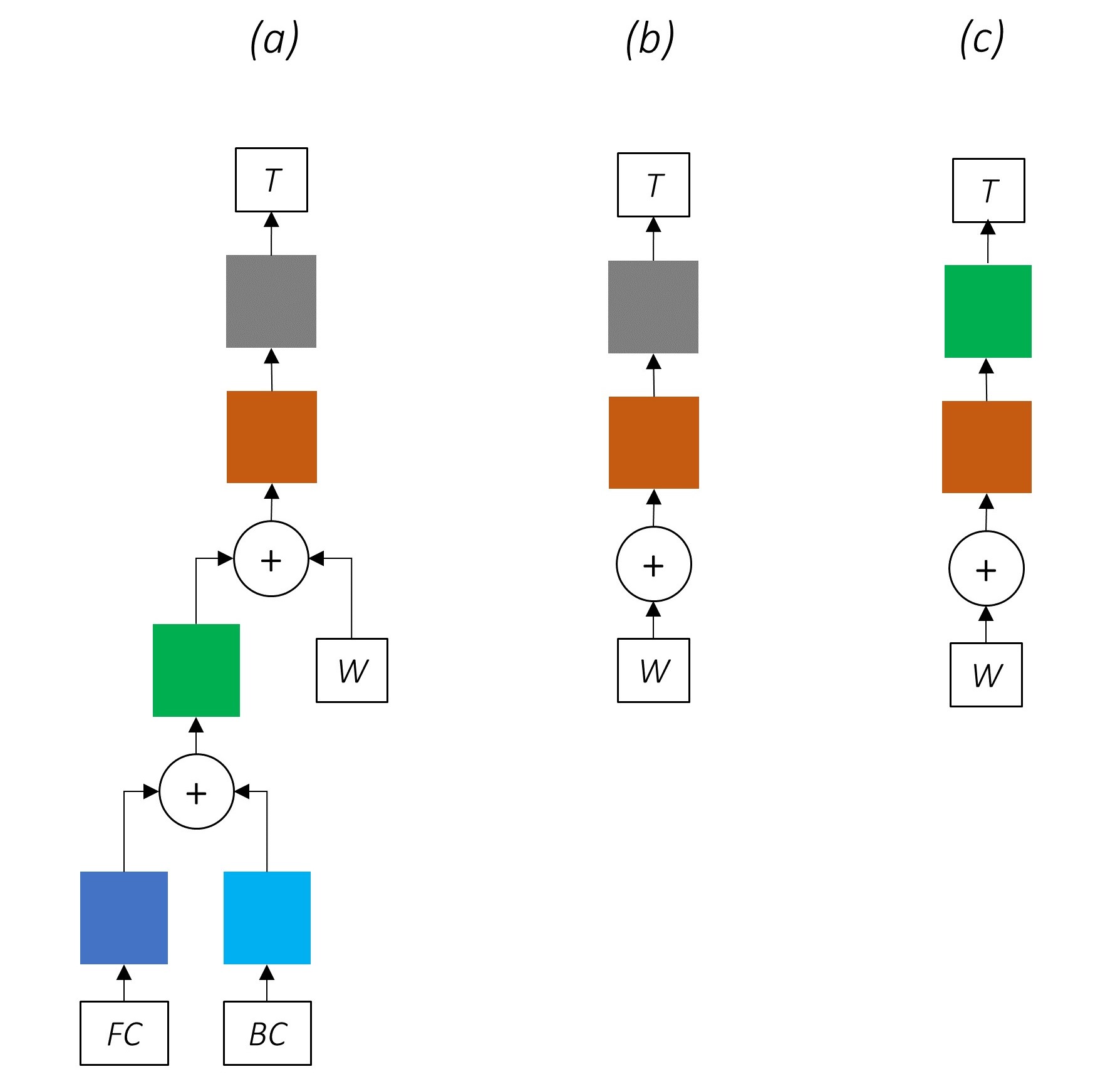
没有多任务学习。
使用角色级信息而无需共同训练仍然可以提高性能。
没有多任务学习或角色级处理。
这种配置通常在行业中使用,并且运行良好。
没有多任务学习,角色级处理或CRFing。请注意,线性或高速公路层将替换后者。
这可以很好地工作,但是有条件的随机字段可提高性能。
请记住,我们不使用仅计算发射分数的线性层。交叉熵不是合适的损失度量。
取而代之的是,我们将使用Viterbi损失,就像交叉熵一样,它是“负模可能性”。但是在这里,我们将测量黄金(真)标签序列的可能性,而不是序列中每个单词的真实标签的可能性。为了找到可能性,我们在所有标签序列的得分上考虑了SoftMax。
标签序列t的得分定义为单个标签得分的总和。

例如,考虑我们之前查看的CRF分数 -
标签序列tag_2, tag_3, tag_3, <end> tag的分数是红色值的总和, 4.85 + 6.79 + 3.85 + 3.52 = 19.01 。
然后将Viterbi损失定义为
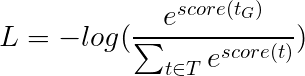
其中t_G是金标签序列, T表示所有可能的标签序列的空间。
这简化为 -
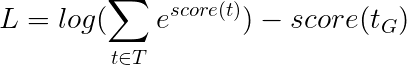
因此,viterbi损失是所有可能的标签序列的分数的log-sum-exp与金标签序列的得分,即log-sum-exp(all scores) - gold score 。
Viterbi解码是一种构建最佳标签序列的方式,不仅考虑到某个单词(发射得分)的标签的可能性,而且考虑到标签的可能性考虑到上一个和下一个标签(过渡得分)。
一旦您以L, m, m矩阵生成CRF分数,以一系列长度L的序列L ,我们就开始解码。
通过一个示例,最好理解Viterbi解码。再次考虑 -
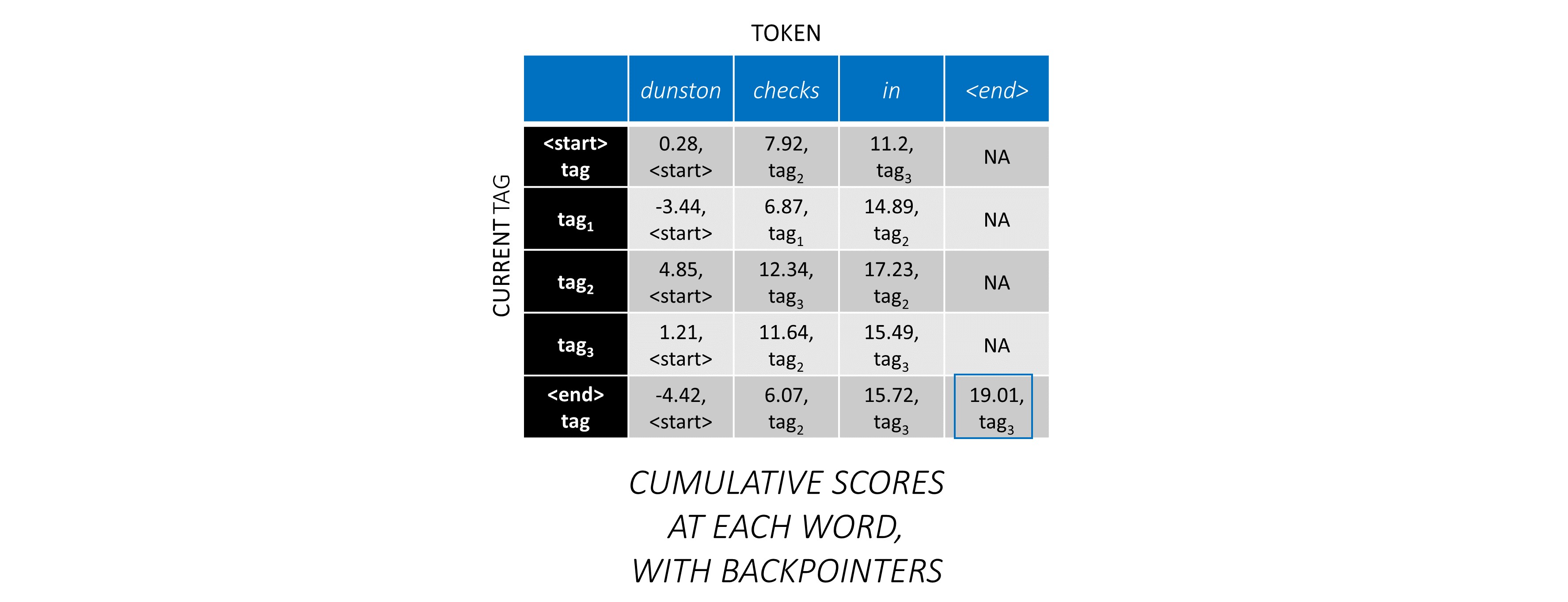
对于序列中的第一个单词, previous_tag只能是<start> 。因此,仅考虑一行。
这些也是第一个单词上每个current_tag的累积分数。
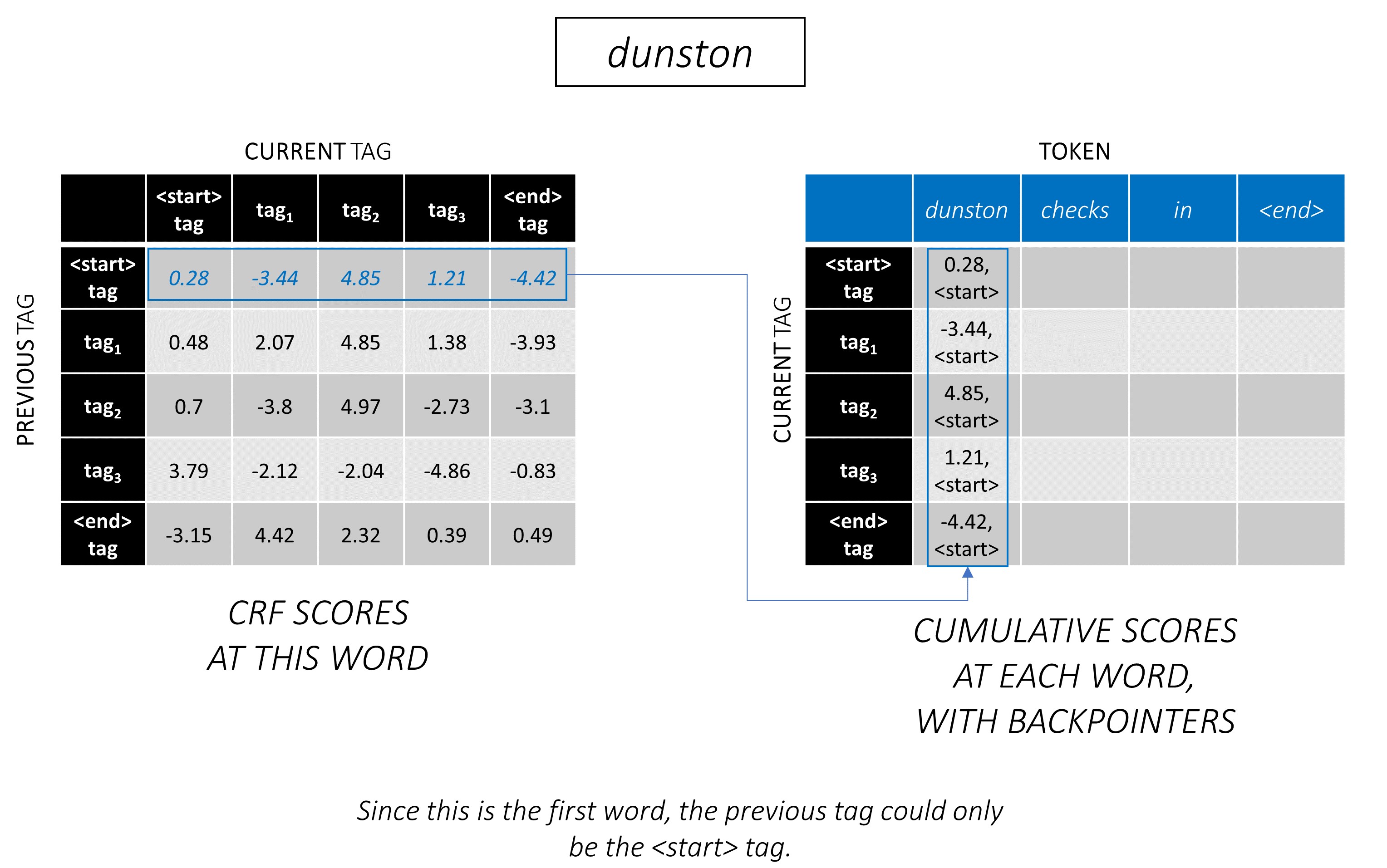
我们还将跟踪与每个分数相对应的previous_tag _tag。这些被称为反点击量。在第一个单词上,它们显然都是<start>标签。
在第二个单词上,将先前的累积分数添加到该单词的CRF分数中,以生成新的累积分数。
请注意,第一个单词的current_tag s是第二个单词的previous_tag s。因此,沿current_tag维度广播第一个单词的累积分数。
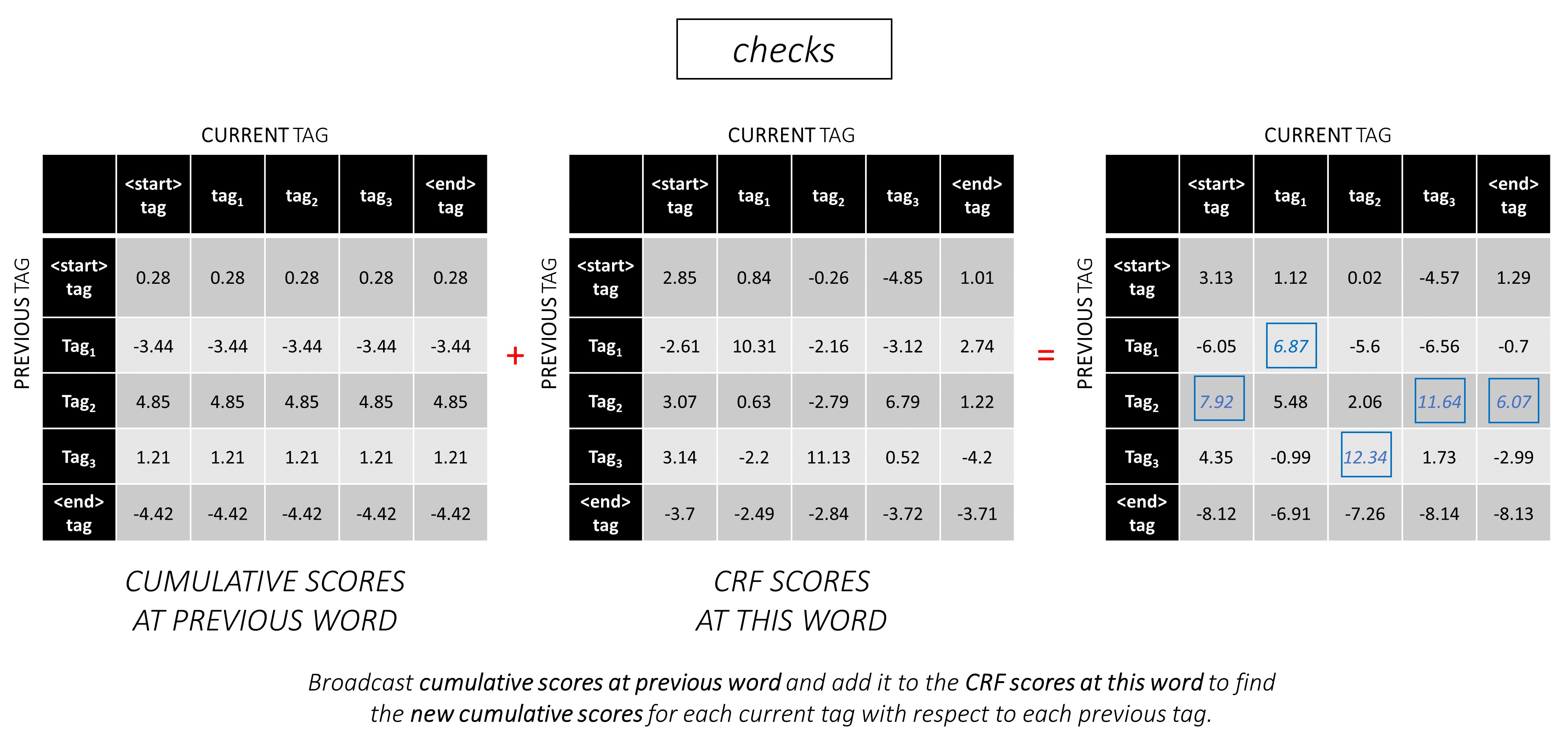
对于每个current_tag ,仅考虑从所有previous_tag s中的得分的最大值。
存储反点击量,即与这些最大分数相对应的先前标签。

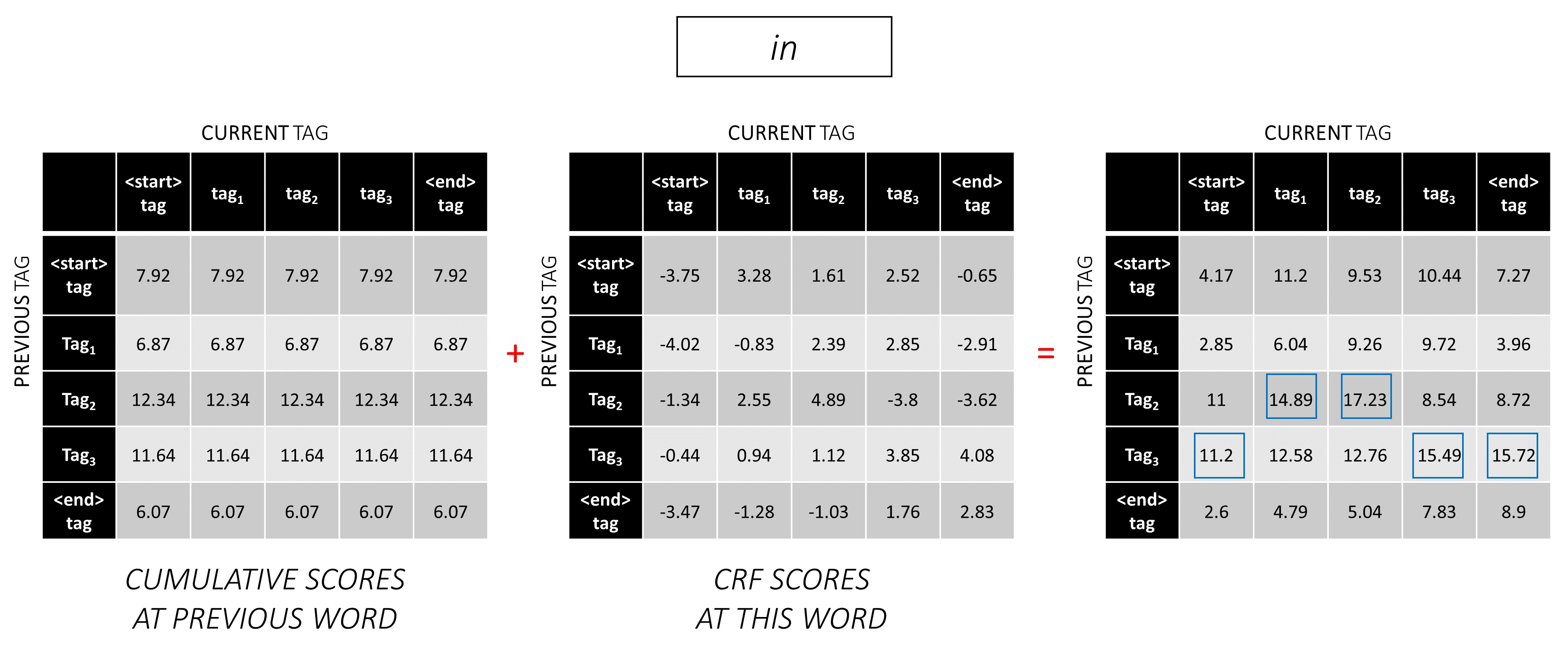
在第三个单词上重复此过程。
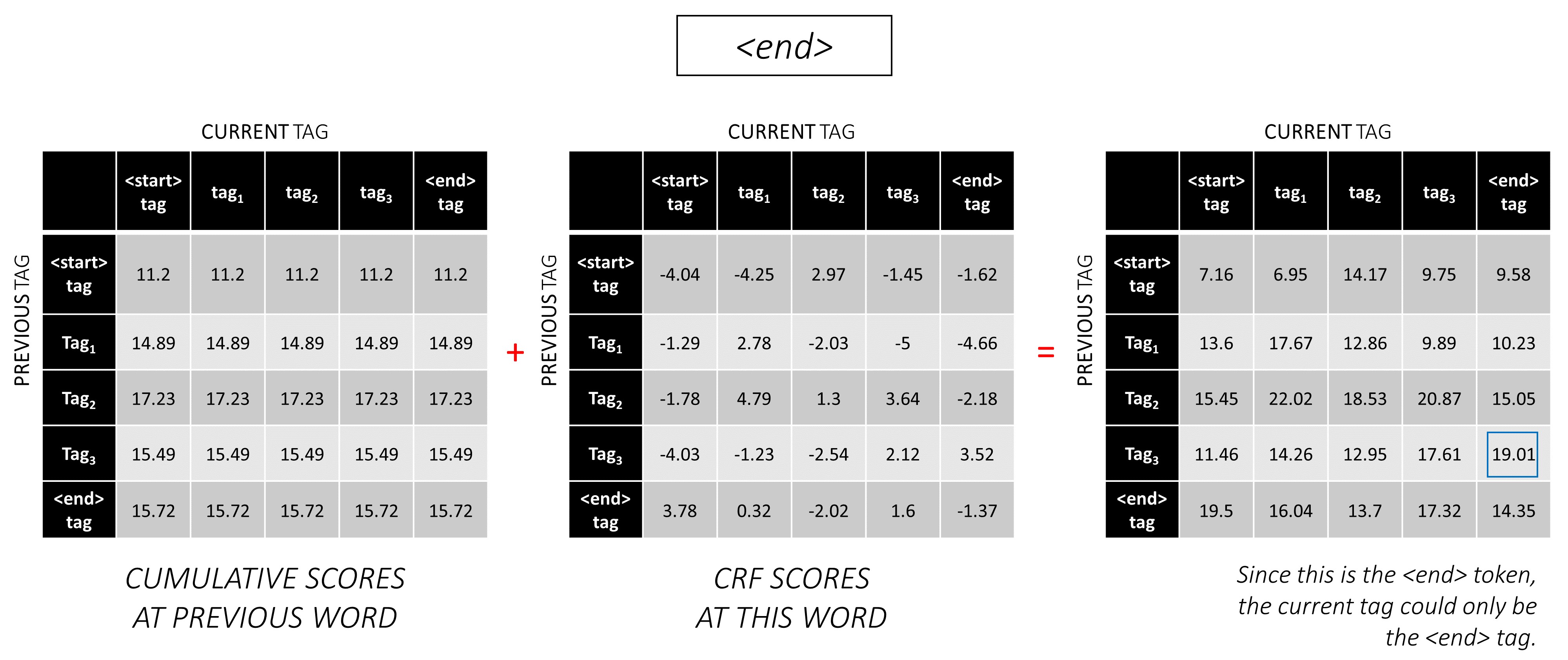
...和最后一个单词,即<end>令牌。
在这里,唯一的区别是您已经知道正确的标签。您仅需要<end>标签的最高分数和反销子。
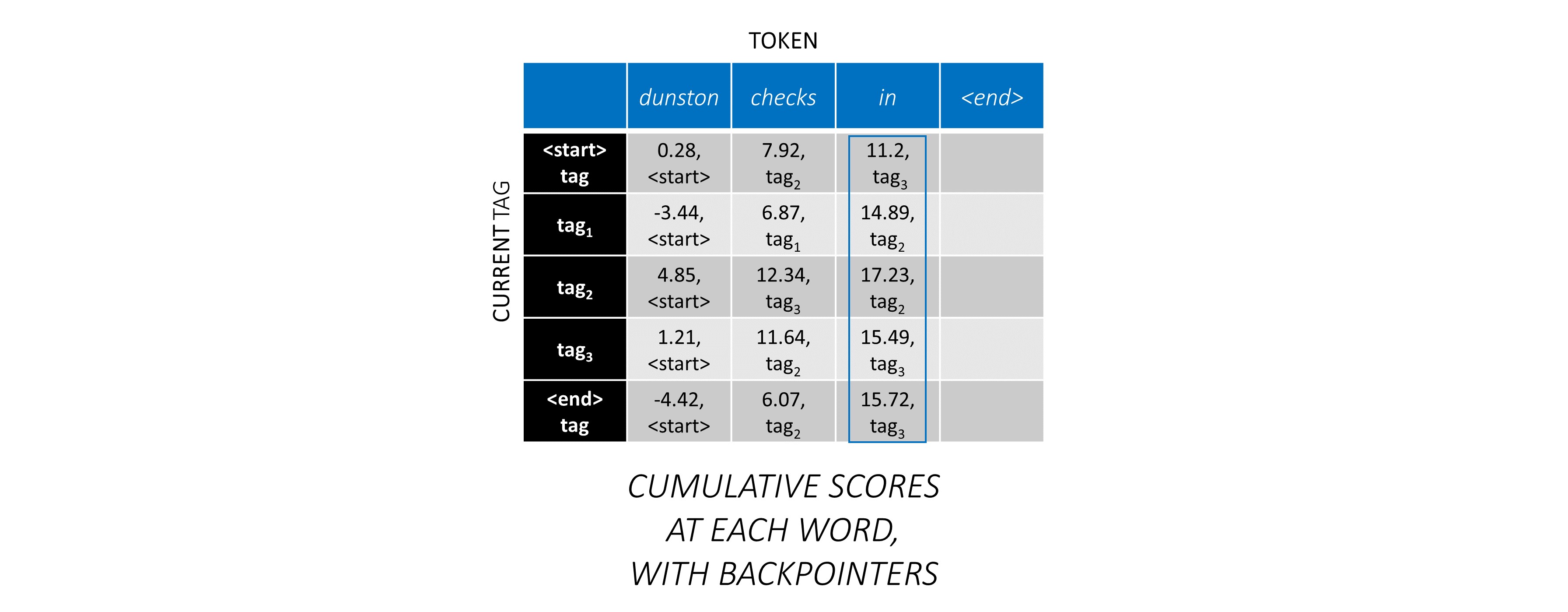
现在,您在整个序列中积累了CRF分数,您可以向后追踪以显示最高得分的标签序列。
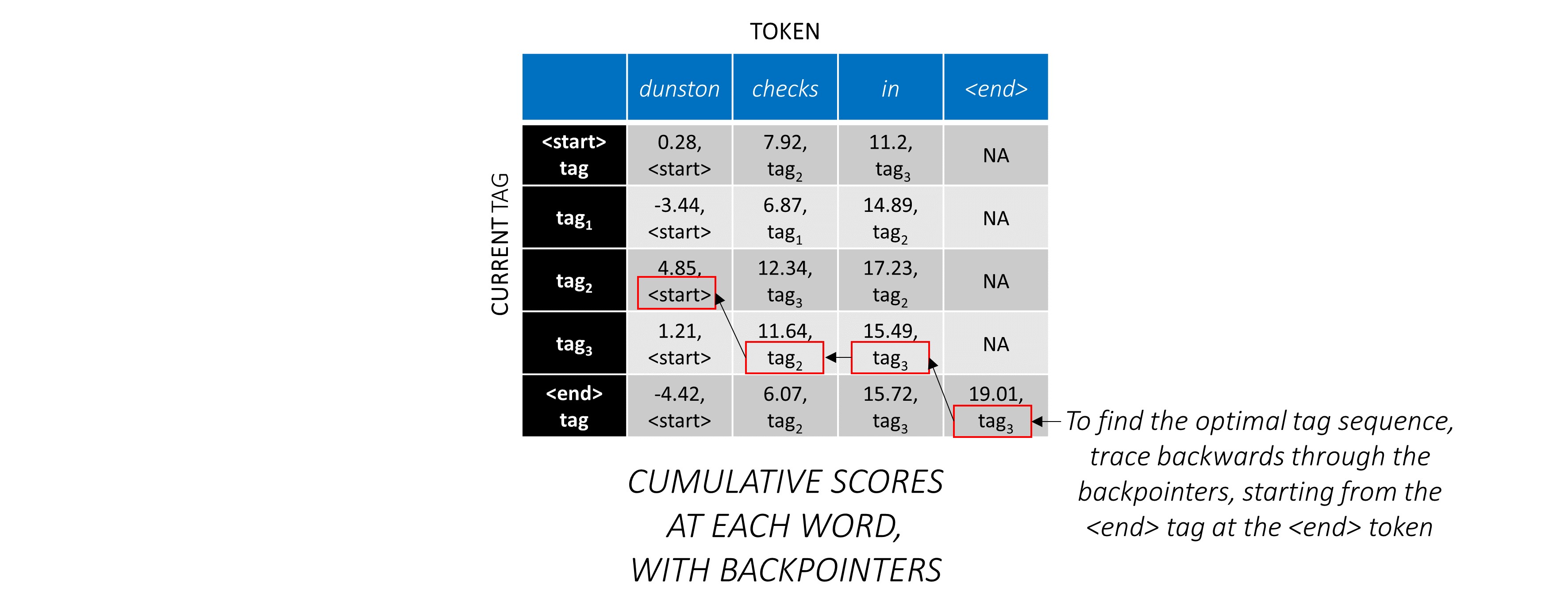
我们发现, dunston checks in <end> IS tag_2 tag_3 tag_3 <end>中Dunston检查的最佳标签序列。
以下各节简要描述了实现。
它们的目的是提供一些背景,但是最好直接从代码中理解细节,这是非常重大评论的。
我使用Conll 2003 NER数据集将我的结果与论文进行比较。
这是一个片段 -
-DOCSTART- -X- O O
EU NNP I-NP I-ORG
rejects VBZ I-VP O
German JJ I-NP I-MISC
call NN I-NP O
to TO I-VP O
boycott VB I-VP O
British JJ I-NP I-MISC
lamb NN I-NP O
. . O O
尽管您可能会在网上找到该数据集,但该数据集并不是要公开分发的。
在线有几个公共数据集,您可以用来培训该模型。这些可能并非全部是100%的注释,但它们足够了。
对于NER标记,您可以使用Groningen含义银行。
对于POS标记,NLTK有一个小数据集,您可以使用nltk.corpus.treebank.tagged_sents()访问。
您要么必须将其转换为Conll 2003 NER数据格式,要么修改数据管道部分中引用的代码。
我们将需要八个输入。
这些是必须标记的单词序列。
dunston checks in
如前所述,我们将不使用<start>令牌,但是我们需要使用<end>令牌。
dunston, checks, in, <end>
由于我们将句子作为固定尺寸张量传递,因此我们需要使用<pad>令牌将句子(自然的长度变化)添加到相同的长度。
dunston, checks, in, <end>, <pad>, <pad>, <pad>, ...
此外,我们创建一个word_map ,它是语料库中每个单词的索引映射,包括<end>和<pad>令牌。与其他库一样,Pytorch需要编码单词作为索引来查找它们的嵌入,或者在预测的单词分数中识别其位置。
4381, 448, 185, 4669, 0, 0, 0, ...
因此,馈送到模型的单词序列必须是尺寸N, L_w的Int张量,其中N是batch_size, L_w是单词序列的填充长度(通常是最长的单词序列的长度)。
这些是向前方向的字符序列。
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' '
我们需要字符序列中的<end>令牌,以匹配单词序列中的<end>令牌。由于我们将在单词序列中的每个单词上使用字符级特征,因此我们在单词sequence中需要<end>的字符级特征。
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>
我们还需要垫子。
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>, <pad>, <pad>, <pad>, ...
并用char_map编码它们。
29, 2, 12, 8, 7, 14, 12, 3, 6, 18, 1, 6, 21, 8, 3, 17, 12, 3, 60, 0, 0, 0, ...
因此,馈送到模型的正向字符序列必须是尺寸N, L_c的Int张量,其中L_c是字符序列的填充长度(通常是最长字符序列的长度)。
这将与前向序列相同,但向后进行处理。 ( <end>令牌仍然自然而然。)
'n', 'i', ' ', 's', 'k', 'c', 'e', 'h', 'c', ' ', 'n', 'o', 't', 's', 'n', 'u', 'd', ' ', <end>, <pad>, <pad>, <pad>, ...
12, 17, 3, 8, 21, 6, 1, 18, 6, 3, 12, 14, 7, 8, 12, 2, 29, 3, 60, 0, 0, 0, ...
因此,馈送到模型的向后字符序列必须是尺寸N, L_c的Int张量。
这些标记是字符序列中的位置,我们将特征提取到 -
我们将在字符序列和<end>令牌中的每个' '的末端提取特征。
对于正向字符序列,我们提取 -
7, 14, 17, 18
这些是dunston之后的点, in checks , <end> 。因此,我们为单词序列中的每个单词都有一个标记,这很有意义。 (但是,在语言模型中,由于我们正在预测下一个单词,因此我们不会在标记中预测与<end>相对应的标记。)
我们用0 s垫板。只要它们有效索引,我们都可以使用什么。 (我们将在垫子上提取功能,但我们不会使用它们。)
7, 14, 17, 18, 0, 0, 0, ...
它们被填充到单词序列的填充长度L_w 。
因此,馈送到模型的正向字符标记必须是尺寸N, L_w的Int张量。
对于向后字符序列中的标记,我们同样找到了每个空间的位置' '和<end>令牌。
我们还确保这些位置与前向标记中的单词顺序相同。这种对齐使从前向和向后字符序列提取的连接特征变得更加容易,并且还可以防止在语言模型中重新订购目标。
17, 9, 2, 18
这些是notsnud , skcehc , ni , <end>之后的点。
我们用0 s垫。
17, 9, 2, 18, 0, 0, 0, ...
因此,向后馈送到模型的向后字符标记必须是尺寸N, L_w的Int张量。
让我们假设dunston, checks, in, <end>是 -
tag_2, tag_3, tag_3, <end>
我们有一个tag_map (包含标签<start> , tag_1 , tag_2 , tag_3 , <end> )。
通常,我们只会直接编码它们(填充之前) -
2, 3, 3, 5
这些是1D编码,即1D标签图中的标签位置。
但是CRF层的输出为2D m, m每个单词的张量。我们需要在这些2D输出中编码标签位置。
正确的标签位置标记为红色。
(0, 2), (2, 3), (3, 3), (3, 4)
如果我们将这些分数展开为1D m*m张量,则在展开的张量中的标签位置为
tag_map [ previous_tag ] * len ( tag_map ) + tag_map [ current_tag ]因此,我们编码tag_2, tag_3, tag_3, <end> as
2, 13, 18, 19
请注意,您可以通过模量来检索原始的tag_map索引
t % len ( tag_map )它们将被填充到单词序列的填充长度L_w 。
因此,馈送到模型的标签必须是尺寸N, L_w的Int张量。
这些是单词序列的实际长度,包括<end>令牌。由于Pytorch支持动态图,因此我们将仅在这些长度上计算,而不是在<pads>上计算。
因此,馈送到模型的单词长度必须是尺寸N的Int张量。
这些是字符序列的实际长度,包括<end>令牌。由于Pytorch支持动态图,因此我们将仅在这些长度上计算,而不是在<pads>上计算。
因此,馈送到模型的字符长度必须是尺寸N的Int张量。
请参阅utils.py中的read_words_tags() 。
这以Conll 2003格式读取输入文件,并提取单词和标签序列。
请参阅utils.py中的create_maps() 。
在这里,我们为单词,字符和标签创建编码地图。我们将稀有的单词和字符<unk> s(未知)。
请参阅utils.py中的create_input_tensors() 。
我们生成了“模型”部分输入中详述的八个输入。
请参见utils.py中的load_embeddings() 。
我们加载了预训练的嵌入式,可以选择将word_map扩展到包含嵌入词汇中存在的corpus词。请注意,这也可能包括稀有的词内单词,这些<unk>被归为s之前。
请参阅datasets.py中的WCDataset 。
这是Pytorch Dataset集的子类。它需要定义的__len__方法,该方法返回数据集的大小和__getitem__方法,该方法将八个输入的i返回到模型。
该Dataset将在train.py中的pytorch DataLoader器使用,以创建和将数据批量馈送到模型中以进行培训或验证。
请参阅models.py中的Highway 。
转换是输入的恢复激活的线性变换。门是输入的乙状体激活线性变换。请注意,这两种转换都必须与输入相同,以允许在残差连接中添加输入。
num_layers属性属性我们串联执行多少个转换网状遗传连接操作。通常只有一个就足够了。
我们将必要数量的变换和门层存储在单独的ModuleList() s中,并使用for loop执行连续的操作。
请参阅models.py中的LM_LSTM_CRF 。
从一开始,我们通过降低长度来对前向和向后的字符序列进行分类。为了使LSTM仅计算有效的时间段,即序列的真实长度,就需要使用pack_padded_sequence()来使用Pack_padded_seperence()。
请记住还要按照相同的顺序对所有其他张量进行排序。
有关如何使用pack_padded_sequence()的说明,请参见dynamic_rnn.py以利用Pytorch的动态图形和批处理功能,以便我们不处理垫子。它通过时间到忽略垫子时通过时间步段来平移分类的序列,而LSTM仅在每个时间步上计算有效的批次尺寸N_t 。
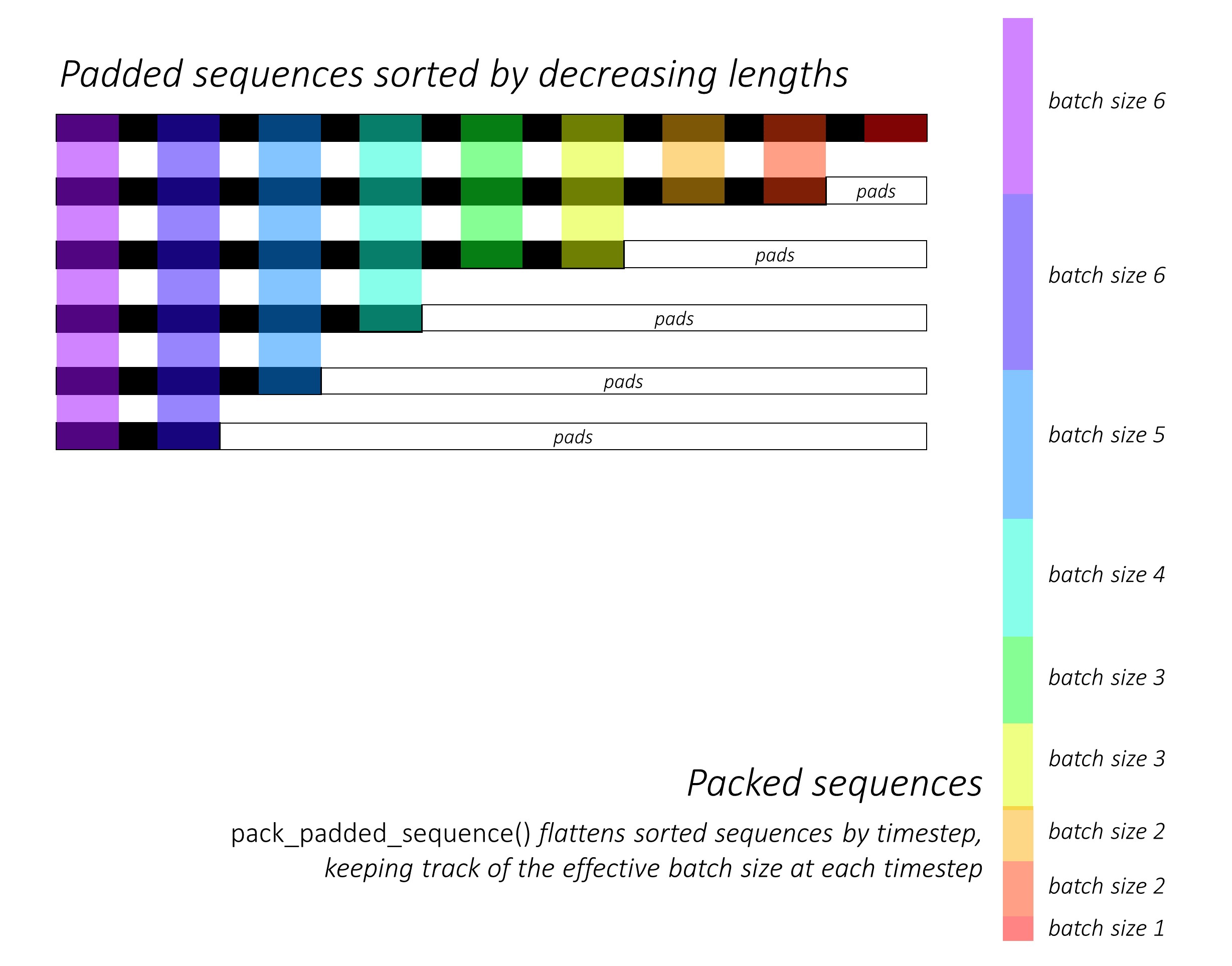
排序允许在任何时间步上的顶部N_t与上一步的输出对齐。例如,在第三个时间步中,我们仅使用上一步的前5个输出来处理前5个图像。除了分类外,所有这些都是由Pytorch内部处理的,但是了解pack_padded_sequence()做什么仍然非常有用,因此我们可以在其他情况下使用它来实现相似的目的。 (请参阅有关处理常见问题解答部分中的可变长度序列的相关问题。)
排序后,我们分别在前进和向后packed_sequences上应用前向和向后的LSTM 。我们使用pad_packed_sequence()取消贴上输出并重新填充输出。
我们仅在gather前方和向后字符标记处提取输出。此函数对于仅在单独张量中指定的张量中提取某些索引非常有用。
这些提取的输出由前向和向后的高速公路层处理,然后应用线性层来计算词汇上的分数,以预测每个标记处的下一个单词。我们仅在培训期间这样做,因为在验证或推理期间为多任务学习进行语言建模没有意义。任何模型的training属性均由model.train()或model.eval()在train.py中设置。 (请注意,这主要用于在训练和推理期间分别在Pytorch模型中启用或禁用辍学和批处理层。)
请参阅models.py中的LM_LSTM_CRF (续)。
我们还通过减小长度来对单词序列进行排序,因为单词序列的长度与字符序列之间可能并不总是存在相关性。
请记住还要按照相同的顺序对所有其他张量进行排序。
我们在标记处加入前后字符LSTM输出,并通过第三个高速公路层运行。这将在每个单词上提取我们将用于序列标签的每个单词。
我们将此结果与单词嵌入式相结合,并在packed_sequence中计算BLSTM输出。
使用pad_packed_sequence()重新涂片后,我们具有进送到CRF层所需的功能。
请参阅models.py中的CRF 。
考虑到它添加到我们的模型中的值,您可能会发现这一层非常简单。
线性层用于将输出从BLSTM转换为每个标签的分数,即发射分数。
单个张量用于保持过渡分数。该张量是模型的一个Parameter ,这意味着它在反向传播过程中可以更新,就像其他层的权重一样。
要查找CRF分数,请在按照CRF概述中所述进行广播之后,计算每个单词的发射分数并将其添加到过渡分数中。
请参阅models.py中的ViterbiLoss 。
我们在Viterbi损失概述中建立了,我们希望最大程度地减少所有可能有效的标签序列的分数和金牌序列的得分,即IE log-sum-exp(all scores) - gold score之间的差异。
如前所述,我们将每个真实标签的CRF得分列为计算金评分。
还记得我们如何在展开的CRF分数中编码标签序列及其位置吗?我们使用gather()在这些位置上提取分数,并在求和之前用pack_padded_sequences()消除垫子。
找到所有可能序列的分数的log-sum-exp稍微棘手。我们使用用于循环for时间来迭代时间段。在每个时间步中,我们为每个current_tag积累得分。
previous_tag的每个current_tag的累积分数。我们仅以有效的批量大小进行此操作,即尚未完成的序列。 (我们的序列仍然是通过从LM-LSTM-CRF模型中减小单词长度来分类的。)current_tag ,在上previous_tag s上计算log-sum-exp,以在每个current_tag处找到新的累积分数。在计算所有序列的可变长度之后,我们将留下张张量N, m ,其中m是(当前)标签的数量。这些是在每个m标签中结束的所有可能序列上的log-sum-exp分数。但是,由于有效序列只能以<end>标签结尾,因此仅在<end>列上汇总以找到所有可能有效序列的分数的log-sum-exp 。
我们发现差异, log-sum-exp(all scores) - gold score 。
请参阅inference.py中的ViterbiDecoder 。
这实现了Viterbi解码概述中描述的过程。
我们以类似于我们在ViterbiLoss中所做的方式累积的for分数,除非我们找到每个current_tag的上previous_tag得分的最大值,而不是计算log-sum-exp。我们还跟踪与反向量张量中此最大分数相对应的previous_tag 。
我们使用<end>标签的背对量张量,因为这使我们能够向后追踪垫子,最终到达实际的<end>标签,然后开始实际的回溯。
参见train.py 。
模型的参数(和培训)在文件的开头,因此您可以在愿意的情况下轻松检查或修改它们。
要从头开始训练您的模型,只需运行此文件 -
python train.py
要在检查点恢复培训,请指向代码开头的checkpoint参数的相应文件。
请注意,我们在每个培训时期结束时执行验证。
您会注意到,我们将每批的输入调整为该批次的最大序列长度。这是这样,我们实际上没有更多的垫子。
但为什么?尽管我们的模型中的RNN不会在垫子上计算,但线性层仍然可以。改变这一点是很直接的 - 请参阅有关处理常见问题解答部分中的可变长度序列的相关问题。
在本教程中,我认为在某些垫子上进行了一些额外的计算值得直接的计算,即不必在packed_sequence上执行一系列操作 - 高速公路,CRF,其他线性层,串联,串联。
在多任务场景中,我们选择了两个语言建模任务中的交叉熵损失以及序列标记任务中的Viterbi损失。
即使我们正在最大程度地减少这些损失的总和,我们实际上只对通过最小化这些损失的总和来最大程度地减少Viterbi损失感兴趣。 Viterbi损失反映了主要任务的性能。
我们使用pack_padded_sequence()在必要时消除垫子。
像论文中一样,我们将宏观平均的F1得分作为早期漫步的标准。自然,计算F1分数需要Viterbi解码CRF分数以生成我们的最佳标签序列。
我们使用pack_padded_sequence()在必要时消除垫子。
我尽可能地遵循作者实现中的参数。
我使用了10句子的批次大小。我用动量使用随机梯度下降。每个时代都腐烂了学习率。我在没有微调的情况下使用了100D手套预处理的嵌入。
在泰坦X(Pascal)上训练一个时代大约花了大约80年代。
验证集的F1分数在50时期左右达到91% ,在171时期达到91.6%的峰值。这非常接近论文中的结果。
您可以在此处下载此验证的模型。
我们如何决定使用序列的模型是否需要<start>和<end>令牌?
如果一开始似乎令人困惑,那么当您考虑计划训练的模型的要求时,它将很容易解决。
对于使用CRF标记的序列标记,您需要<end>令牌(或<start>令牌;请参见下一个问题),因为CRF分数的结构如何。
在我的图像字幕上的另一个教程中,我同时使用了<start>和<end>令牌。该模型需要开始在某个地方解码,并学会识别何时在推理过程中停止解码。
如果您执行文本分类,则无需。
我们可以让CRF生成current_word -> next_word分数,而不是上previous_word -> current_word分数吗?
是的。在这种情况下,您将播放诸如L, m, _类的排放分数,并且您将在每个句子中都有一个<start>令牌,而不是<end>令牌。 <start>令牌的正确标签始终是<start>标签。最后一个单词的“下一个标签”始终是<end>标签。
我认为previous word -> current word惯例稍好一些,因为混音中有语言模型。 It fits in quite nicely to be able to predict the <end> token at the last real word, and therefore learn to recognize when a sentence is complete.
Why are we using different vocabularies for the sequence tagger's inputs and language models' outputs?
The language models will learn to predict only those words it has seen during training. It's really unnecessary, and a huge waste of computation and memory, to use a linear-softmax layer with the extra ~400,000 out-of-corpus words from the embedding file it will never learn to predict.
But we can add these words to the input layer even if the model never sees them during training. This is because we're using pre-trained embeddings at the input. It doesn't need to see them because the meanings of words are encoded in these vectors. If it's encountered a chimpanzee before, it very likely knows what to do with an orangutan .
Is it a good idea to fine-tune the pre-trained word embeddings we use in this model?
I refrain from fine-tuning because most of the input vocabulary is not in-corpus. Most embeddings will remain the same while a few are fine-tuned. If fine-tuning changes these embeddings sufficiently, the model may not work well with the words that weren't fine-tuned. In the real world, we're bound to encounter many words that weren't present in a newspaper corpus from 2003.
What are some ways we can construct dynamic graphs in PyTorch to compute over only the true lengths of sequences?
If you're using an RNN, simply use pack_padded_sequence() . PyTorch will internally compute over only the true lengths. See dynamic_rnn.py for an example.
If you want to execute an operation (like a linear transformation) only on the true timesteps, pack_padded_sequences() is still the way to go. This flattens the tensor by timestep while removing the pads. You can perform your operation on this flattened tensor, and then use pad_packed_sequence() to unflatten it and re-pad it with 0 s.
Similarly, if you want to perform an aggregation operation, like computing the loss, use pack_padded_sequences() to eliminate the pads.
If you want to perform timestep-wise operations, you can take a leaf out of how pack_padded_sequences() works, and compute only on the effective batch size at each timestep with a for loop to iterate over the timesteps. We did this in the ViterbiLoss and ViterbiDecoder . I also used an LSTMCell() in this fashion in my image captioning tutorial.
Dunston Checks In ?真的吗?
I had no memory of this movie for twenty years. I was trying to think of a short sentence that would be easier to visualize in this tutorial and it just popped into my mind riding a wave of 90s nostalgia.

I wish I hadn't googled it though. Damn, the critics were harsh, weren't they? This gem was overwhelmingly and universally panned. I'm not sure I'd disagree if I watched it now, but that just goes to show the world is so much more fun when you're a kid.
Didn't have to worry about LM-LSTM-CRFs or nuthin...


