a PyTorch Tutorial to Sequence Labeling
1.0.0
Ini adalah tutorial Pytorch untuk mengurutkan pelabelan .
Ini adalah yang kedua dari serangkaian tutorial yang saya tulis tentang menerapkan model keren sendiri dengan perpustakaan Pytorch yang menakjubkan.
Pengetahuan dasar Pytorch, jaringan saraf berulang diasumsikan.
Jika Anda baru mengenal Pytorch, pertama -tama baca pembelajaran mendalam dengan Pytorch: Blitz 60 menit dan belajar Pytorch dengan contoh.
Pertanyaan, saran, atau koreksi dapat diposting sebagai masalah.
Saya menggunakan PyTorch 0.4 di Python 3.6 .
27 Jan 2020 : Kode kerja untuk dua tutorial baru telah ditambahkan-super-resolusi dan terjemahan mesin
Tujuan
Konsep
Ringkasan
Pelaksanaan
Pelatihan
Pertanyaan yang sering diajukan
Untuk membangun model yang dapat menandai setiap kata dalam kalimat dengan entitas, bagian ucapan, dll.

Kami akan mengimplementasikan pelabelan urutan Empower dengan kertas model bahasa saraf yang sadar tugas . Ini lebih canggih daripada kebanyakan model penandaan urutan, tetapi Anda akan belajar banyak konsep yang berguna - dan bekerja dengan sangat baik. Implementasi asli penulis dapat ditemukan di sini.
Model ini istimewa karena menambah tugas pelabelan urutan dengan melatihnya secara bersamaan dengan model bahasa.
Pelabelan urutan . duh.
Model bahasa . Pemodelan bahasa adalah untuk memprediksi kata atau karakter berikutnya dalam urutan kata atau karakter. Model bahasa saraf mencapai hasil yang mengesankan di berbagai tugas NLP seperti pembuatan teks, terjemahan mesin, teks gambar, pengenalan karakter optik, dan apa yang Anda miliki.
Karakter rnns . RNN yang beroperasi pada karakter individu dalam teks diketahui menangkap gaya dan struktur yang mendasarinya. Dalam tugas pelabelan urutan, mereka sangat berguna karena informasi sub-kata seringkali dapat menghasilkan petunjuk penting untuk entitas atau tag.
Pembelajaran multi-tugas . Dataset yang tersedia untuk melatih model seringkali kecil. Membuat anotasi atau fitur buatan tangan untuk membantu model Anda tidak hanya rumit, tetapi juga sering tidak dapat disesuaikan dengan beragam domain atau pengaturan di mana model Anda mungkin berguna. Labeling urutan, sayangnya, adalah contoh utama. Ada cara untuk mengurangi masalah ini - bersama -sama melatih beberapa model yang bergabung di pinggul akan memaksimalkan informasi yang tersedia untuk setiap model, meningkatkan kinerja.
Bidang acak bersyarat . Klasifikasi diskrit memprediksi kelas atau label pada satu kata. Bidang acak bersyarat (CRF) dapat membuat Anda lebih baik - mereka memprediksi label berdasarkan tidak hanya kata, tetapi juga lingkungan. Yang masuk akal, karena ada pola dalam urutan entitas atau label. CRF banyak digunakan untuk memodelkan informasi yang dipesan, baik untuk pelabelan urutan, sekuensing gen, atau bahkan deteksi objek dan segmentasi gambar dalam penglihatan komputer.
Decoding viterbi . Karena kami menggunakan CRF, kami tidak terlalu memprediksi label yang tepat pada setiap kata karena kami memprediksi urutan label yang tepat untuk urutan kata. Decoding Viterbi adalah cara untuk melakukan hal ini - temukan urutan tag paling optimal dari skor yang dihitung oleh bidang acak bersyarat.
Jaringan Jalan Raya . Lapisan yang sepenuhnya terhubung adalah bahan pokok dalam jaringan saraf apa pun untuk mengubah atau mengekstrak fitur di lokasi yang berbeda. Jaringan jalan raya mencapai hal ini, tetapi juga memungkinkan informasi mengalir tanpa hambatan melintasi transformasi. Ini membuat jaringan yang dalam jauh lebih efisien atau layak.
Di bagian ini, saya akan menyajikan ikhtisar model ini. Jika Anda sudah terbiasa dengan itu, Anda dapat melewatkan langsung ke bagian implementasi atau kode yang dikomentari.
Para penulis merujuk pada model sebagai model bahasa - memori jangka pendek yang panjang - bidang acak bersyarat karena melibatkan model bahasa pelatihan bersama dengan kombinasi LSTM + CRF .
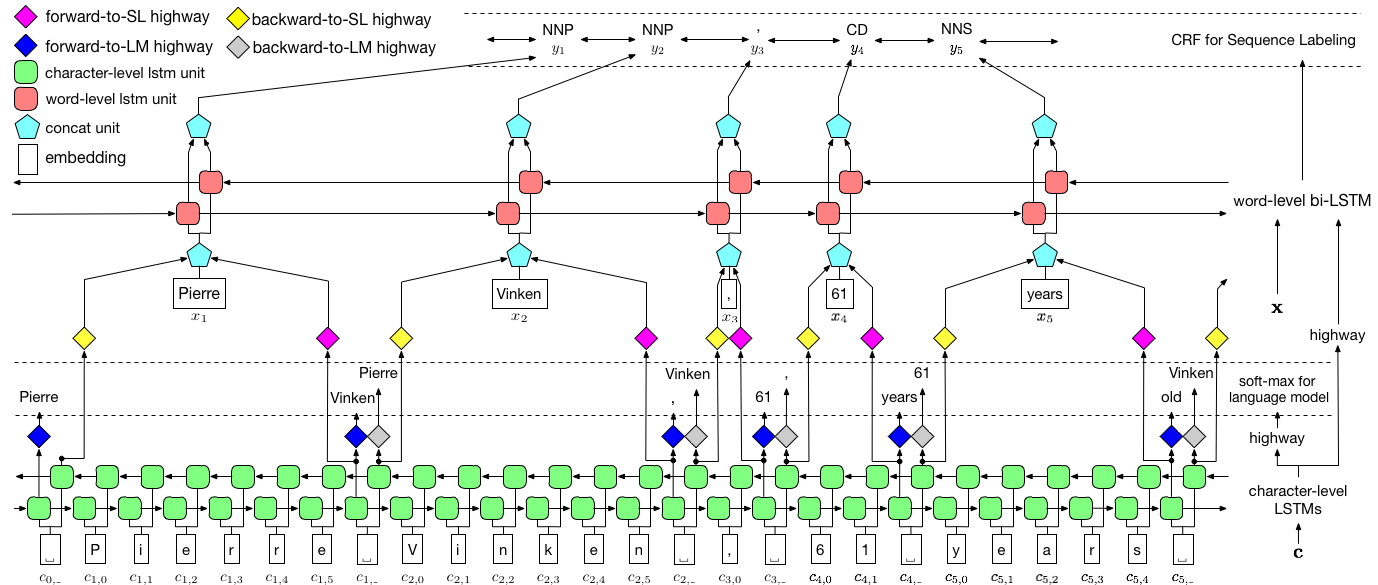
Gambar ini dari kertas ini benar -benar mewakili seluruh model, tetapi jangan khawatir jika tampaknya terlalu rumit saat ini. Kami akan memecahnya untuk melihat lebih dekat pada komponen.
Pembelajaran multi-tugas adalah ketika Anda secara bersamaan melatih model pada dua atau lebih tugas.
Biasanya kami hanya tertarik pada salah satu tugas ini - dalam hal ini, pelabelan urutan.
Tetapi ketika lapisan dalam jaringan saraf berkontribusi untuk melakukan beberapa fungsi, mereka belajar lebih banyak daripada yang mereka miliki jika mereka hanya berlatih pada tugas utama. Ini karena informasi yang diekstraksi pada setiap lapisan diperluas untuk mengakomodasi semua tugas. Ketika ada lebih banyak informasi untuk dikerjakan, kinerja pada tugas utama ditingkatkan .
Memperkaya fitur yang ada dengan cara ini menghilangkan kebutuhan untuk menggunakan fitur buatan tangan untuk pelabelan urutan.
Kerugian total selama pembelajaran multi-tugas biasanya merupakan kombinasi linier dari kerugian pada tugas individu. Parameter kombinasi dapat diperbaiki atau dipelajari sebagai bobot yang dapat diperbarui.

Karena kami mengumpulkan kerugian individu, Anda dapat melihat bagaimana lapisan hulu dibagikan oleh banyak tugas akan menerima pembaruan dari semuanya selama backpropagation.
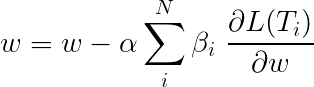
Para penulis makalah cukup menambahkan kerugian ( β=1 ), dan kami akan melakukan hal yang sama.
Mari kita lihat tugas yang membentuk model kita.
Ada tiga .

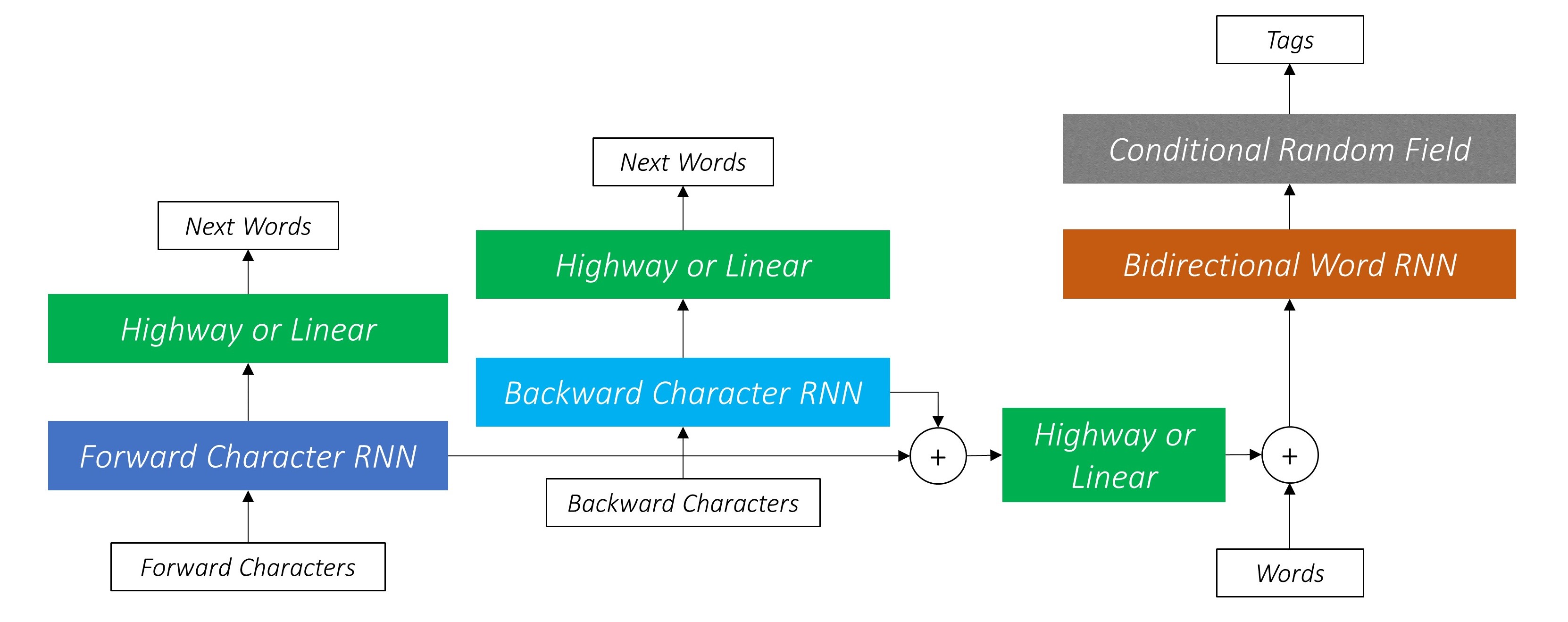
Ini memanfaatkan informasi sub-kata untuk memprediksi kata berikutnya.
Kami melakukan hal yang sama di arah mundur. 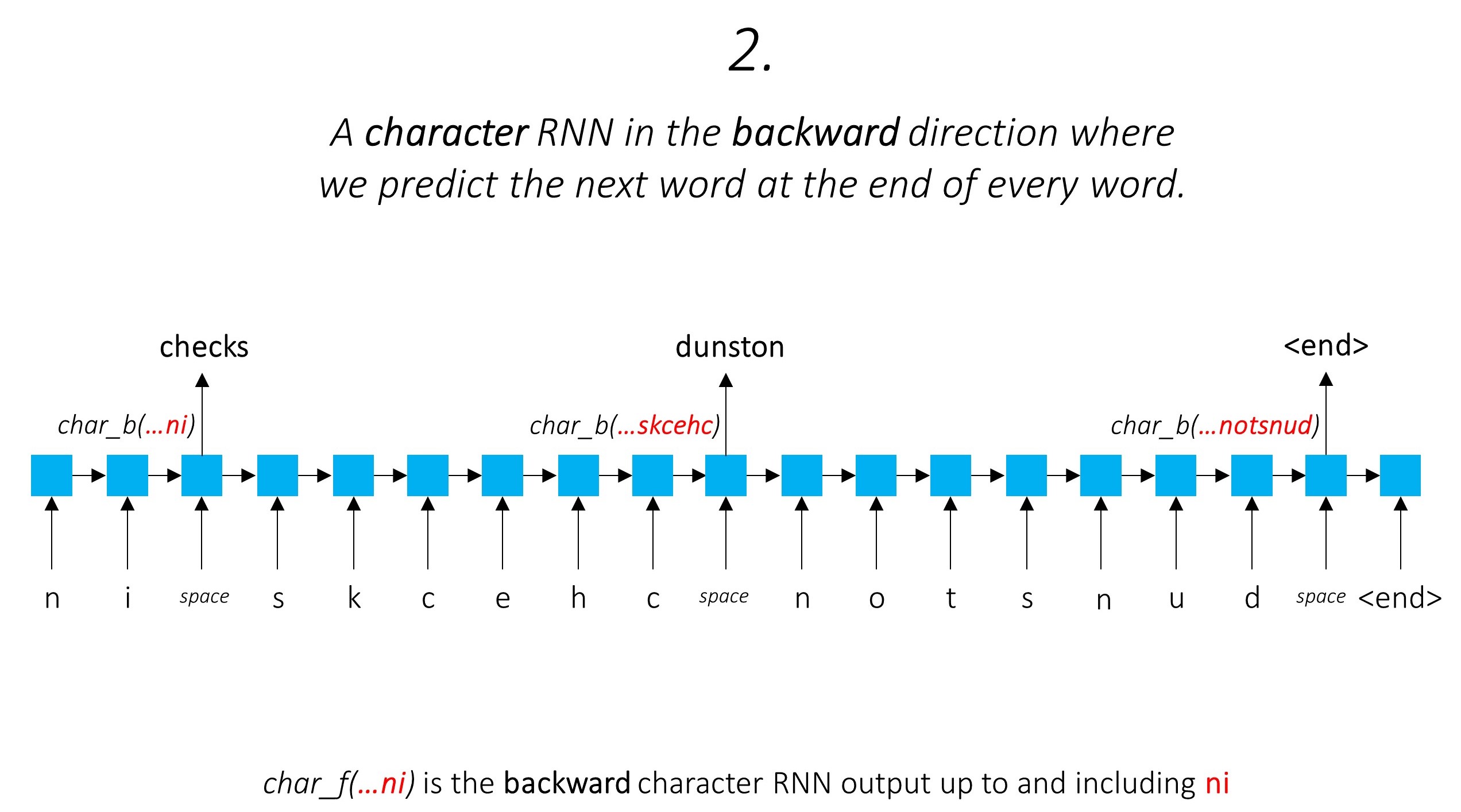
Kami juga menggunakan output dari dua karakter-RNN ini sebagai input ke Word-RNN kami dan bidang acak bersyarat (CRF) untuk melakukan tugas utama pelabelan urutan kami. 
Kami menggunakan informasi sub-kata dalam tugas penandaan kami karena dapat menjadi indikator tag yang kuat, apakah itu bagian dari ucapan atau entitas. Misalnya, dapat belajar bahwa kata sifat yang umumnya berakhir dengan "-y" atau "-ul", atau tempat-tempat itu sering berakhir dengan "-land" atau "-burg".
Tapi fitur sub-kata kami, yaitu. Output dari karakter RNNs, juga diperkaya dengan informasi tambahan - pengetahuan yang dibutuhkan untuk memprediksi kata berikutnya di arah maju dan mundur, karena model 1 dan 2.
Oleh karena itu, model penandaan urutan kami menggunakan keduanya
LSTM/RNN dua arah menyandikan fitur-fitur ini menjadi fitur-fitur baru pada setiap kata yang berisi informasi tentang kata dan lingkungannya, baik pada tingkat kata dan tingkat karakter. Ini membentuk input ke bidang acak bersyarat.
Tanpa CRF, kami hanya akan menggunakan lapisan linier tunggal untuk mengubah output LSTM dua arah menjadi skor untuk setiap tag. Ini dikenal sebagai skor emisi , yang merupakan representasi dari kemungkinan kata menjadi tag tertentu.
CRF menghitung tidak hanya skor emisi tetapi juga skor transisi , yang merupakan kemungkinan kata menjadi tag tertentu mengingat kata sebelumnya adalah tag tertentu. Oleh karena itu skor transisi mengukur seberapa besar kemungkinan transisi dari satu tag ke tag lainnya.
Jika ada m tag, skor transisi disimpan dalam matriks dime m, m , di mana baris mewakili tag kata sebelumnya dan kolom mewakili tag dari kata saat ini. Nilai dalam matriks ini pada posisi i, j adalah kemungkinan transisi dari tag ke i pada kata sebelumnya ke j pada kata saat ini . Tidak seperti skor emisi, skor transisi tidak didefinisikan untuk setiap kata dalam kalimat. Mereka global.
Dalam model kami, lapisan CRF mengeluarkan agregat skor emisi dan transisi pada setiap kata .
Untuk kalimat panjang L , skor emisi akan menjadi tensor L, m Karena skor emisi pada setiap kata tidak tergantung pada tag kata sebelumnya, kami membuat dimensi baru seperti L, _, m dan menyiarkan (salin) tensor di sepanjang arah ini untuk mendapatkan tensor L, m, m .
Skor transisi adalah m, m tensor. Karena skor transisi bersifat global dan tidak bergantung pada kata, kami membuat dimensi baru seperti _, m, m dan siaran (salin) tensor di sepanjang arah ini untuk mendapatkan tensor L, m, m
Kami sekarang dapat menambahkannya untuk mendapatkan skor total yang merupakan tensor L, m, m Nilai pada posisi k, i, j adalah agregat dari skor emisi dari tag ke j pada kata k dan skor transisi dari tag ke j pada kata k th mengingat kata sebelumnya adalah tag ke i .
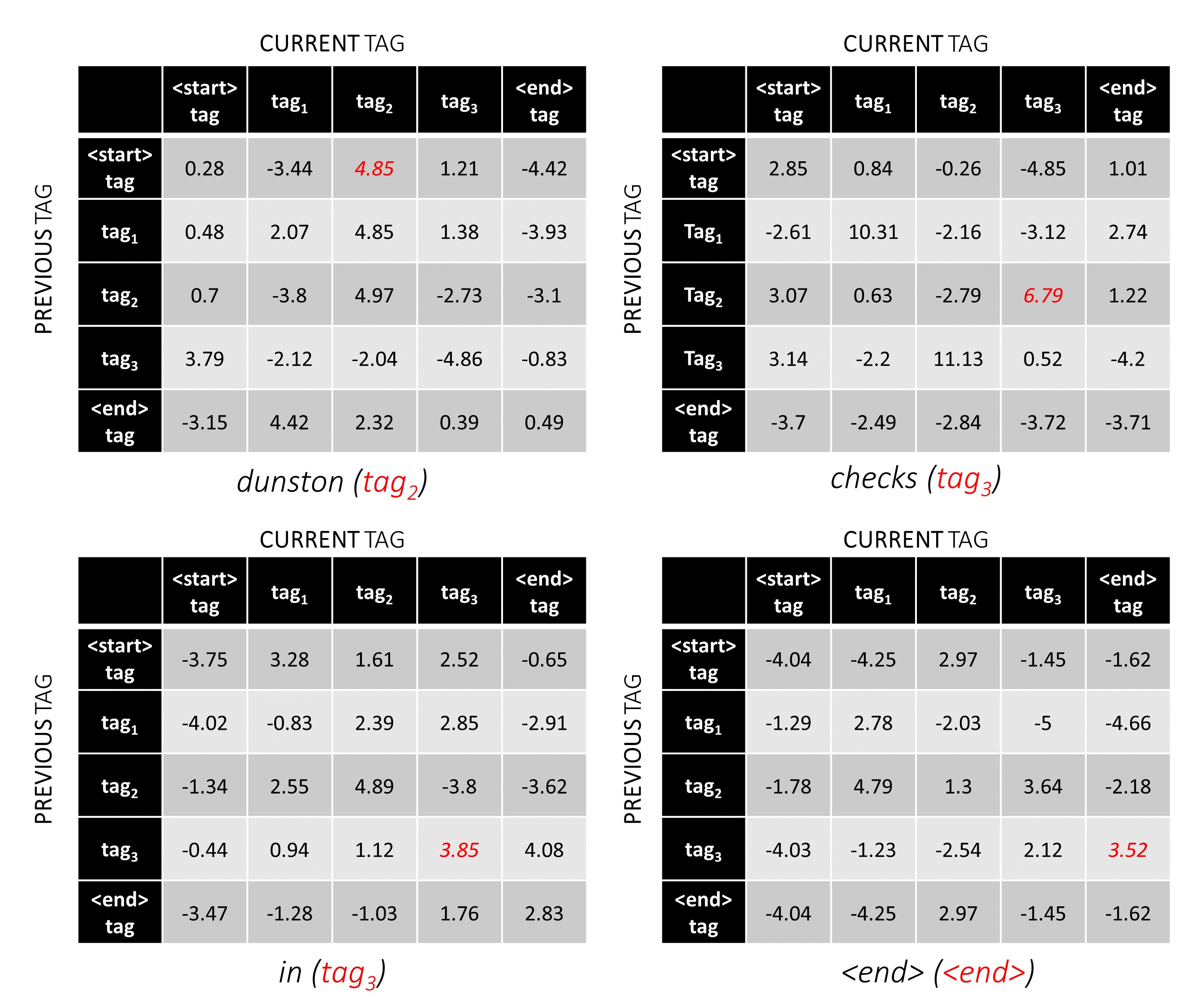
Untuk contoh kalimat kami, dunston checks in <end> , jika kami menganggap ada 5 tag secara total, total skor akan terlihat seperti ini -
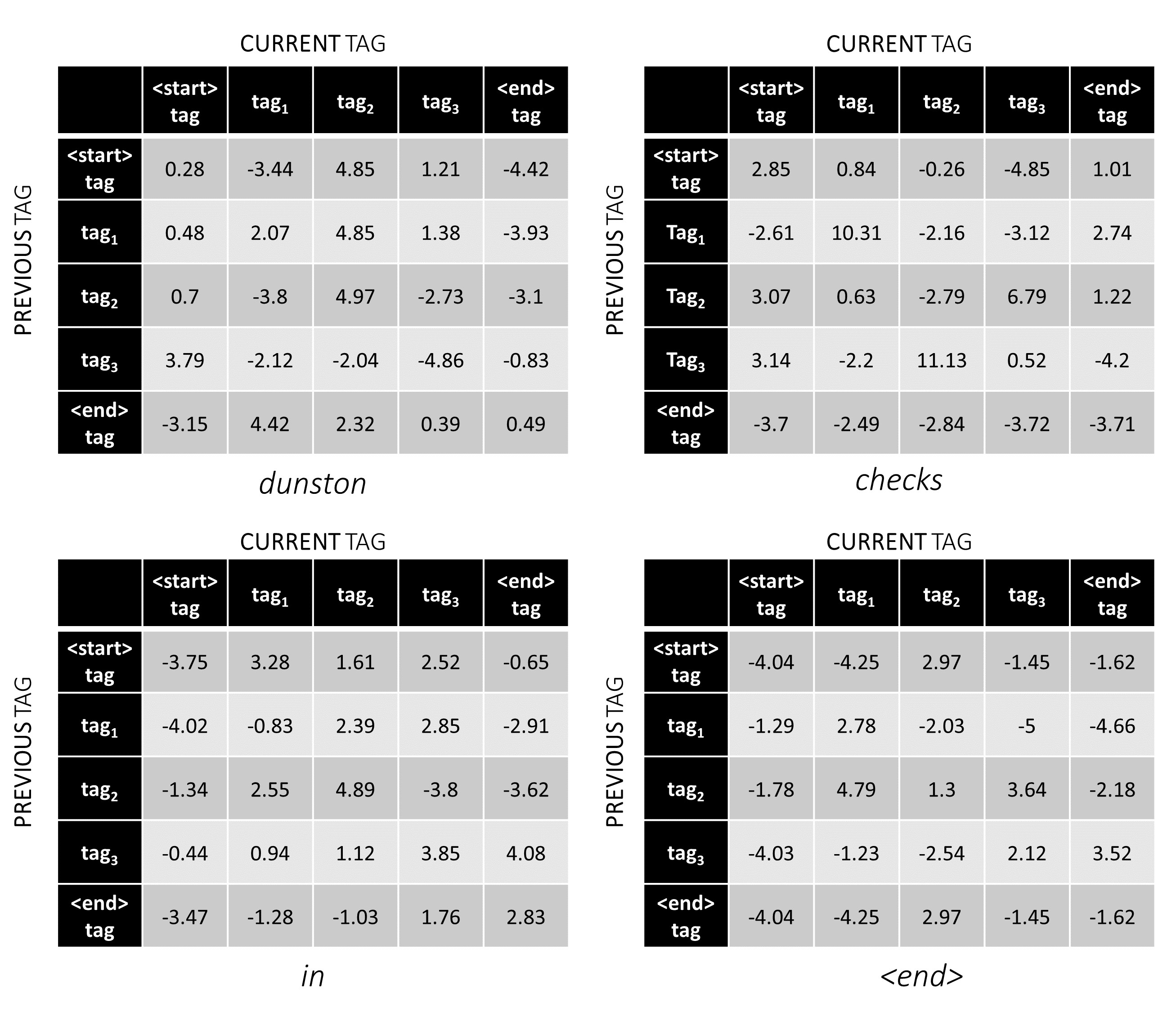
Tapi tunggu sebentar, mengapa ada tag <start> akhir <end> ? Sementara kita berada di sana, mengapa kita menggunakan token <end> ?
<start> dan <end> tag, <start> dan <end> token Karena kami memodelkan kemungkinan transisi antar tag, kami juga menyertakan tag <start> dan tag <end> dalam tag-set kami.
Skor transisi dari tag tertentu yang mengingat bahwa tag sebelumnya adalah tag <start> mewakili kemungkinan tag ini menjadi tag pertama dalam sebuah kalimat . Misalnya, kalimat biasanya dimulai dengan artikel (a, an,) atau kata benda atau kata ganti.
Skor transisi dari tag <end> yang mempertimbangkan tag sebelumnya menunjukkan kemungkinan tag sebelumnya menjadi tag terakhir dalam sebuah kalimat .
Kami akan menggunakan token <end> di semua kalimat dan bukan token <start> karena skor CRF total pada setiap kata didefinisikan sehubungan dengan tag kata sebelumnya , yang tidak masuk akal di token <start> .
Tag yang benar dari token <end> selalu menjadi tag <end> . "Tag sebelumnya" dari kata pertama selalu menjadi tag <start> .
Untuk mengilustrasikan, jika contoh kami dunston checks in <end> memiliki tag tag_2, tag_3, tag_3, <end> , nilai -nilai merah menunjukkan skor tag ini.
Kami biasanya menggunakan lapisan linier yang diaktifkan untuk mengubah dan memproses output RNN/LSTM.
Jika Anda terbiasa dengan koneksi residual, kami dapat menambahkan input sebelum transformasi ke output yang diubah, membuat jalur untuk aliran data di sekitar transformasi.
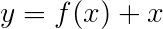
Jalur ini adalah jalan pintas untuk aliran gradien selama backpropagation, dan AIDS dalam konvergensi jaringan yang dalam.
Jaringan jalan raya mirip dengan jaringan residual, tetapi kami menggunakan gerbang yang diaktifkan sigmoid untuk menentukan rasio di mana input dan output yang diubah digabungkan .
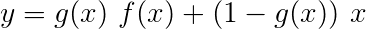
Karena karakter-RNN berkontribusi terhadap beberapa tugas, jaringan jalan raya digunakan untuk mengekstraksi informasi khusus tugas dari outputnya.
Oleh karena itu, kami akan menggunakan jaringan jalan raya di tiga lokasi dalam model gabungan kami -
Dalam pengaturan pelatihan bersama yang naif, di mana kami menggunakan output karakter-RNNs secara langsung untuk beberapa tugas, yaitu tanpa transformasi, ketidaksesuaian antara sifat tugas dapat merusak kinerja.
Mungkin sekarang seperti apa jaringan gabungan kami.
Menghapus bagian -bagian jaringan kami secara progresif dalam jaringan yang semakin sederhana yang digunakan secara luas untuk pelabelan urutan.
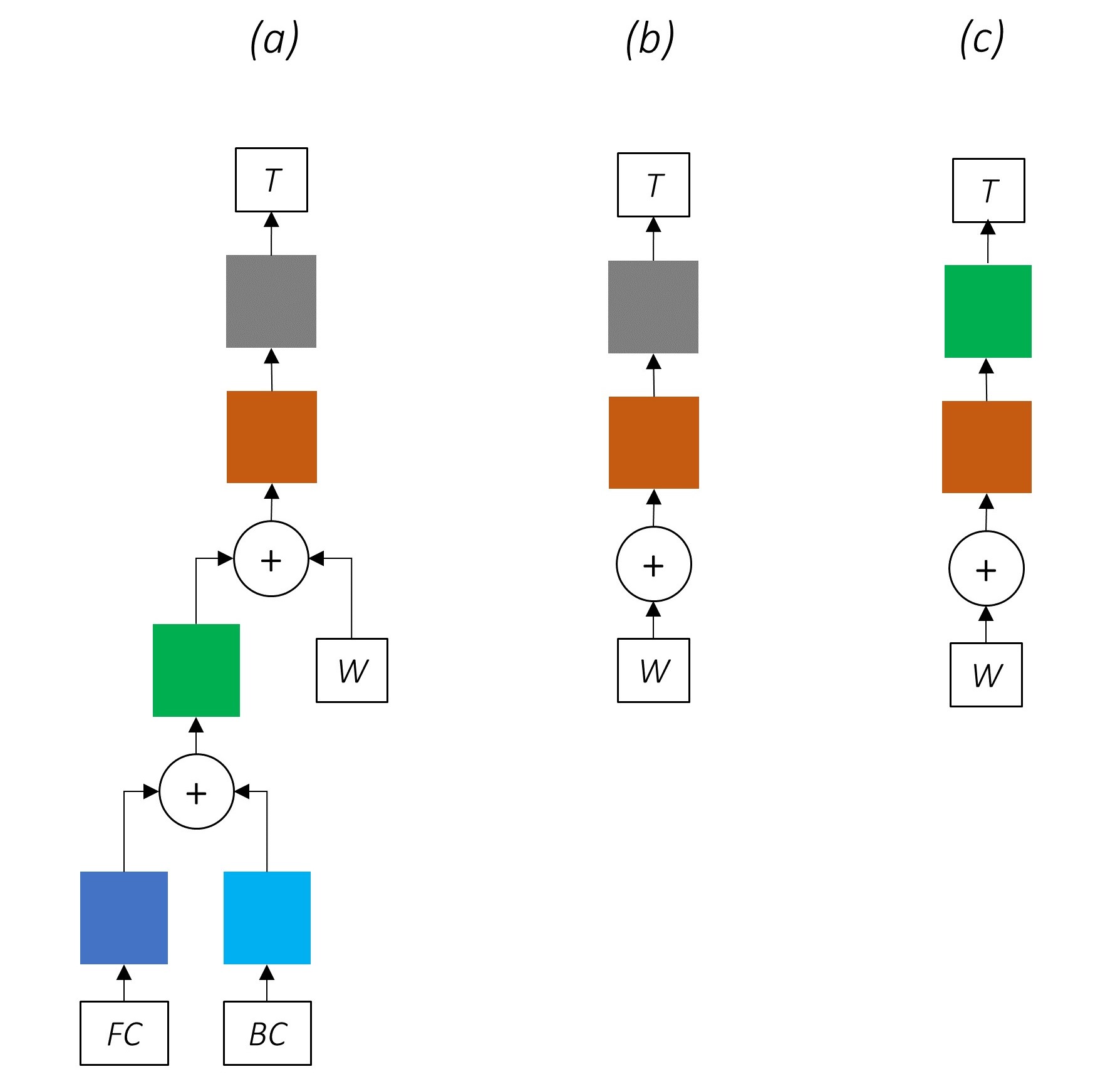
Tidak ada pembelajaran multi-tugas.
Menggunakan informasi tingkat karakter tanpa pelatihan bersama masih meningkatkan kinerja.
Tidak ada pembelajaran multi-tugas atau pemrosesan tingkat karakter.
Konfigurasi ini digunakan cukup umum di industri dan bekerja dengan baik.
Tidak ada pembelajaran multi-tugas, pemrosesan tingkat karakter, atau CRFing. Perhatikan bahwa lapisan linier atau jalan raya akan menggantikan yang terakhir.
Ini bisa bekerja dengan cukup baik, tetapi bidang acak bersyarat memberikan peningkatan kinerja yang cukup besar.
Ingat, kami tidak menggunakan lapisan linier yang hanya menghitung skor emisi. Entropi silang bukanlah metrik kerugian yang cocok.
Sebaliknya kita akan menggunakan kehilangan Viterbi yang, seperti entropi silang, adalah "kemungkinan log negatif". Tapi di sini kita akan mengukur kemungkinan urutan tag emas (benar), alih -alih kemungkinan tag yang benar pada setiap kata dalam urutan. Untuk menemukan kemungkinan, kami mempertimbangkan softmax di atas skor semua urutan tag.
Skor urutan tag t didefinisikan sebagai jumlah skor tag individu.

Misalnya, pertimbangkan skor CRF yang kami lihat sebelumnya -
Skor tag tag tag_2, tag_3, tag_3, <end> tag adalah jumlah nilai dalam warna merah, 4.85 + 6.79 + 3.85 + 3.52 = 19.01 .
Kehilangan viterbi kemudian didefinisikan sebagai
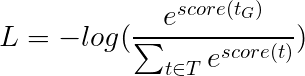
di mana t_G adalah urutan tag emas dan T mewakili ruang dari semua urutan tag yang mungkin.
Ini menyederhanakan -
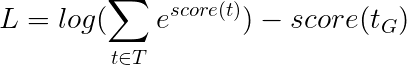
Oleh karena itu, kerugian Viterbi adalah perbedaan antara log-sum-exp dari skor dari semua urutan tag yang mungkin dan skor urutan tag emas , yaitu log-sum-exp(all scores) - gold score .
Decoding Viterbi adalah cara untuk membangun urutan tag yang paling optimal, mengingat tidak hanya kemungkinan tag pada kata tertentu (skor emisi), tetapi juga kemungkinan tag yang mempertimbangkan tag sebelumnya dan berikutnya (skor transisi).
Setelah Anda menghasilkan skor CRF dalam matriks L, m, m untuk urutan panjang L , kami mulai decoding.
Viterbi Decoding paling baik dipahami dengan contoh. Pertimbangkan lagi -
Untuk kata pertama dalam urutan, previous_tag hanya bisa <start> . Oleh karena itu, hanya pertimbangkan satu baris itu.
Ini juga merupakan skor kumulatif untuk setiap current_tag pada kata pertama.
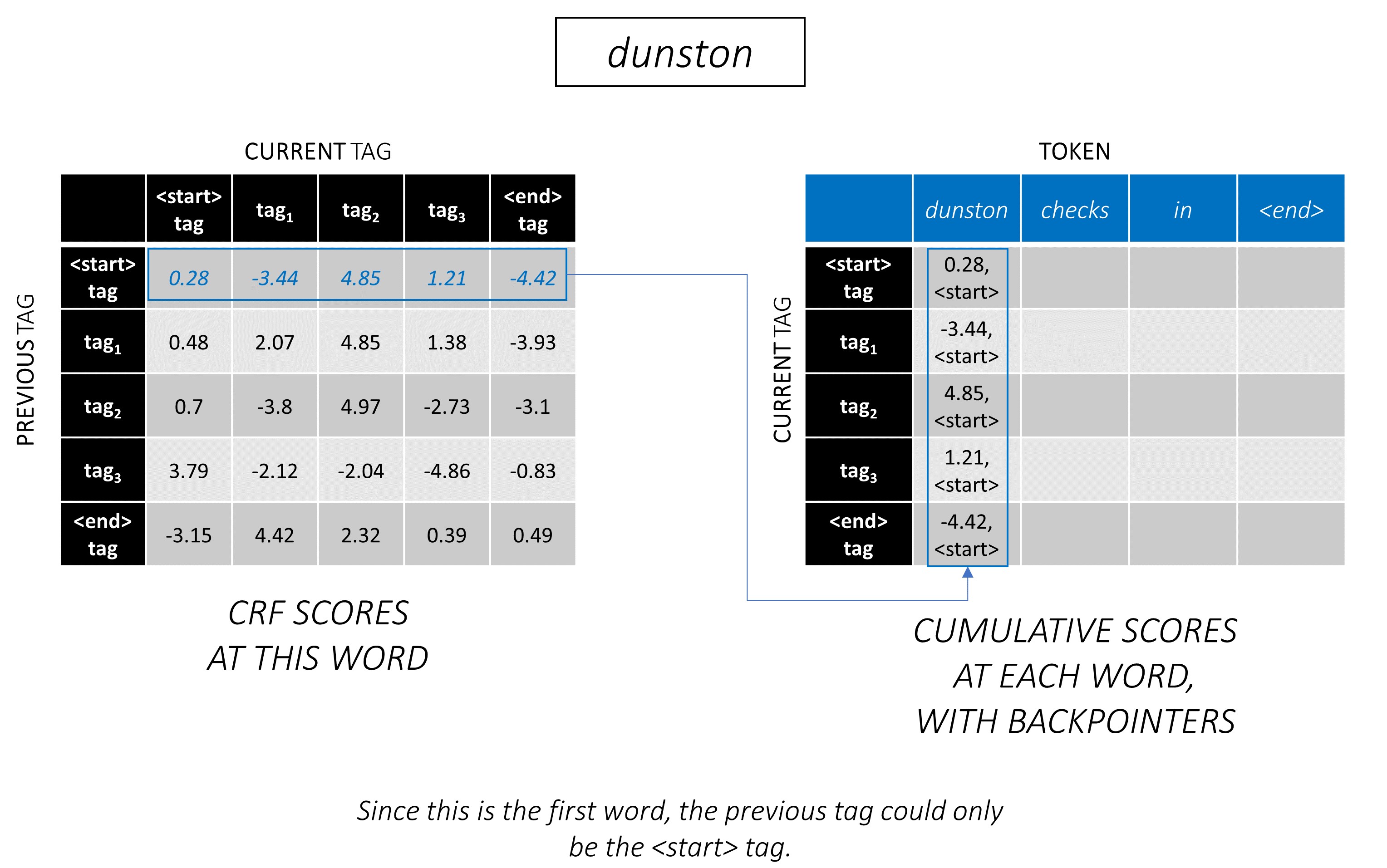
Kami juga akan melacak previous_tag yang sesuai dengan setiap skor. Ini dikenal sebagai backpointer . Pada kata pertama, mereka jelas semua tag <start> .
Pada kata kedua, tambahkan skor kumulatif sebelumnya ke skor CRF dari kata ini untuk menghasilkan skor kumulatif baru .
Perhatikan bahwa kata current_tag pertama yang pertama adalah kata previous_tag . Oleh karena itu, siarkan skor kumulatif kata pertama di sepanjang dimensi current_tag .
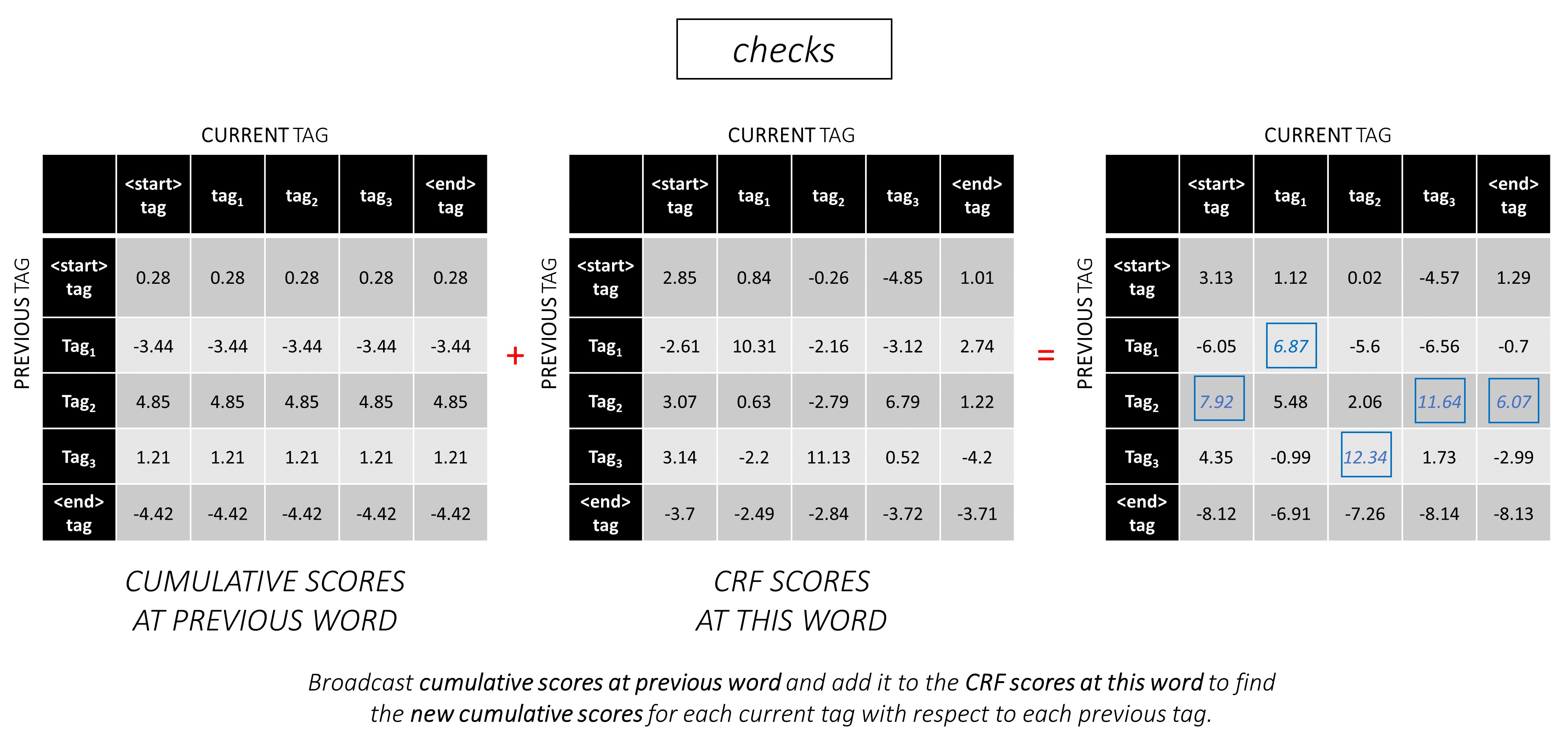
Untuk setiap current_tag , pertimbangkan hanya maksimum skor dari semua previous_tag s.
Simpan Backpointer, yaitu tag sebelumnya yang sesuai dengan skor maksimum ini.

Ulangi proses ini di kata ketiga.
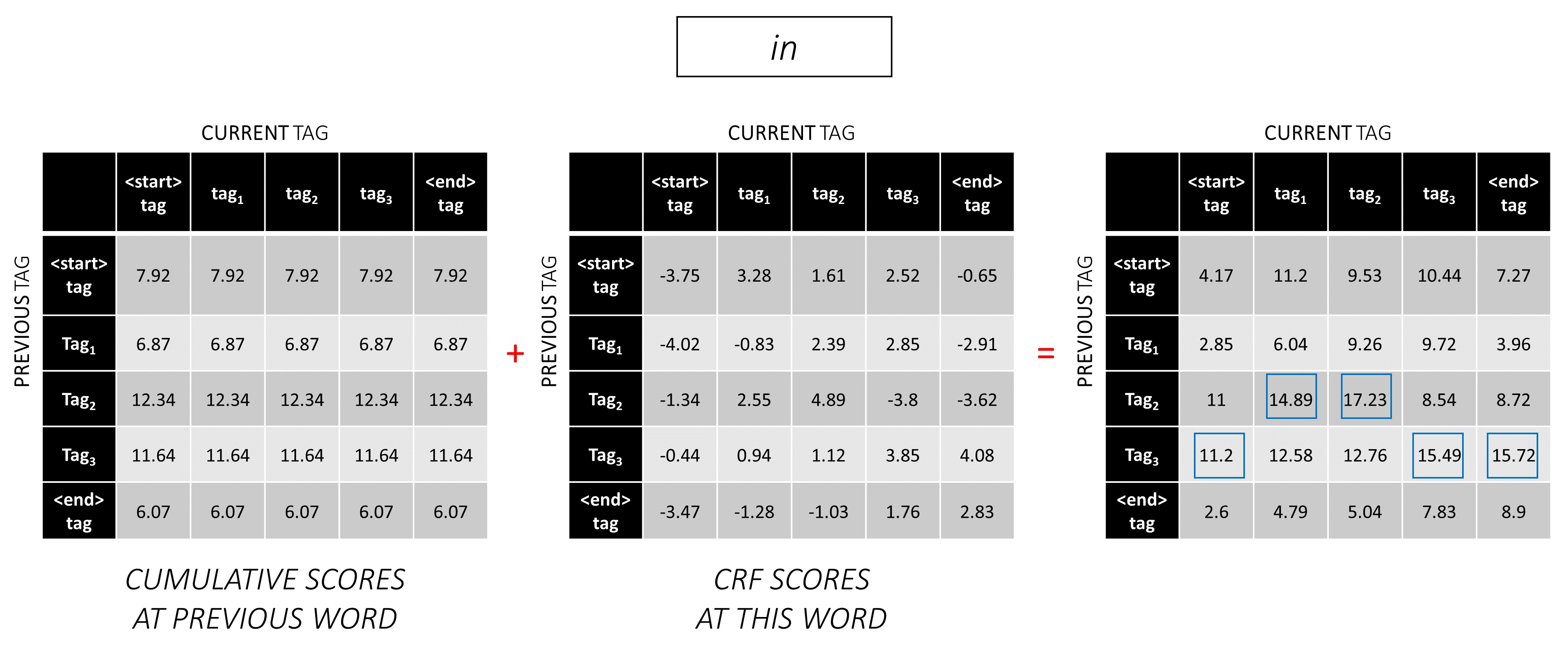
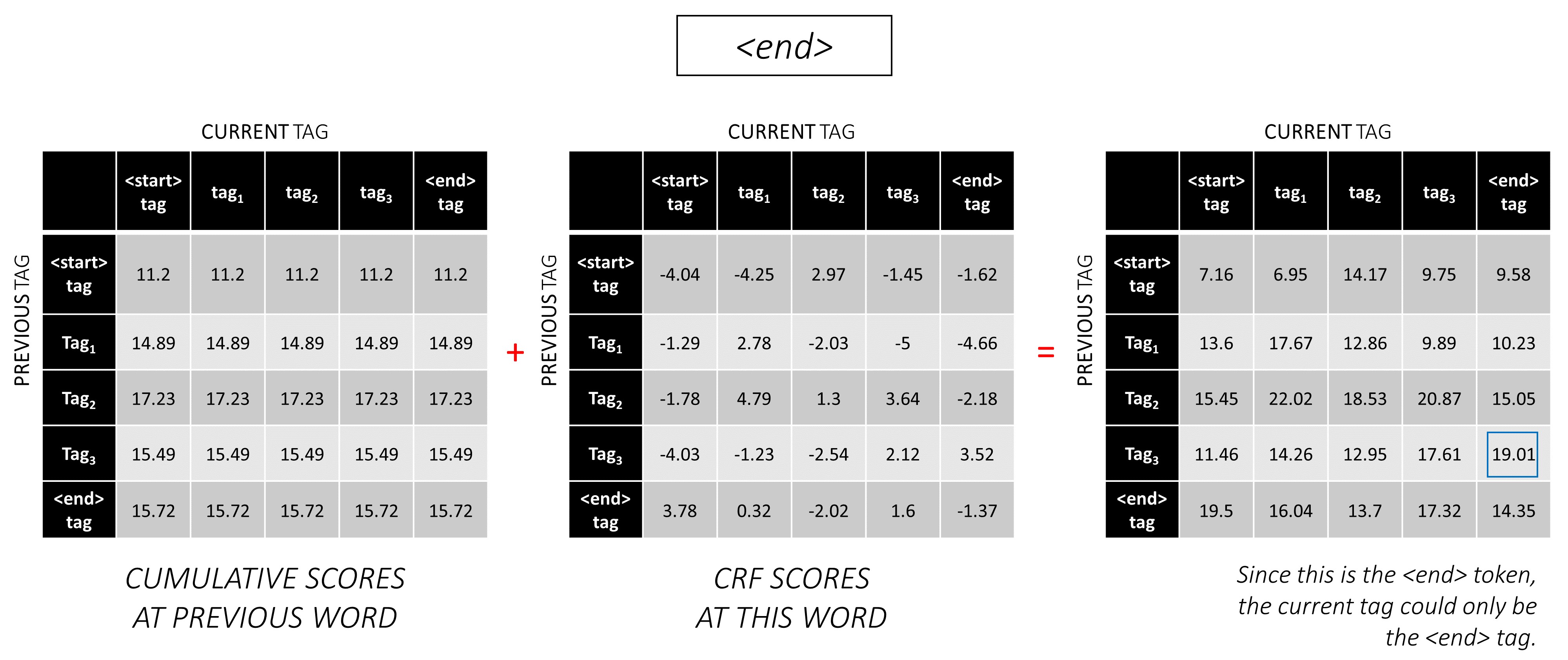
... dan kata terakhir, yang merupakan token <end> .
Di sini, satu -satunya perbedaan adalah Anda sudah tahu tag yang benar. Anda memerlukan skor maksimum dan backpointer hanya untuk tag <end> .
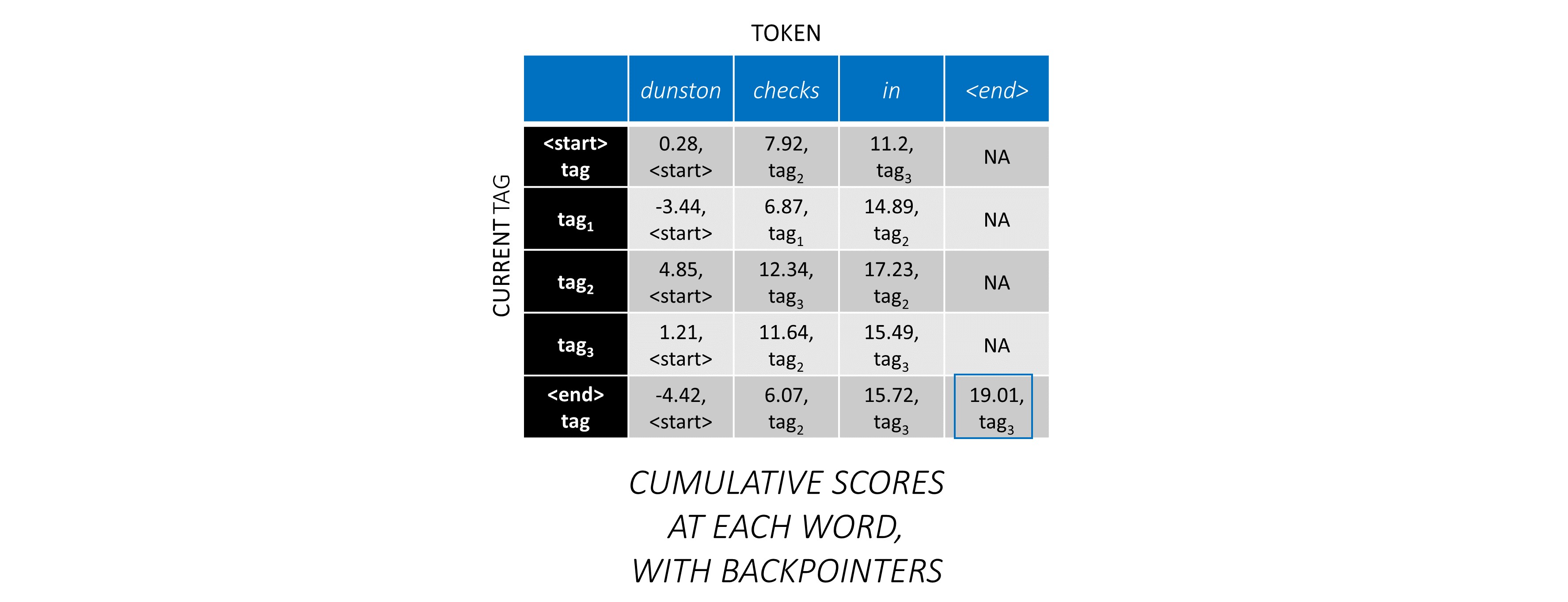
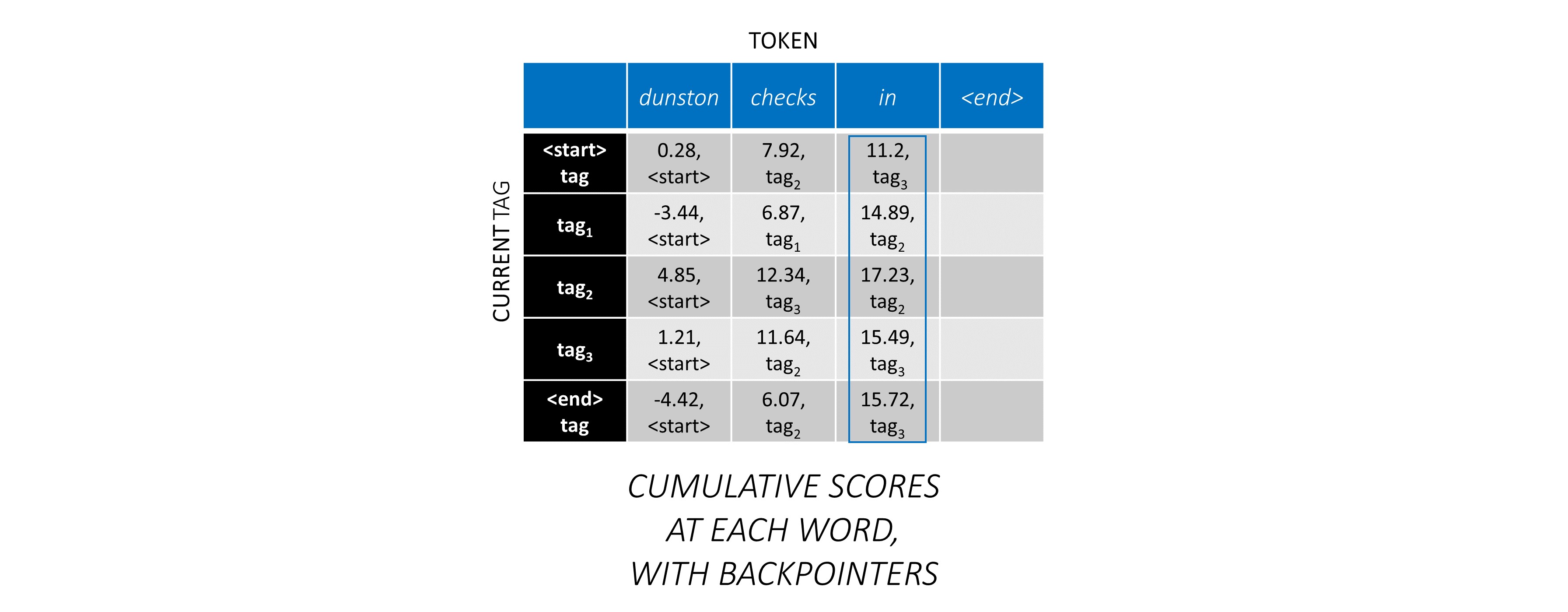
Sekarang setelah Anda mengumpulkan skor CRF di seluruh urutan, Anda melacak ke belakang untuk mengungkapkan urutan tag dengan skor setinggi mungkin .
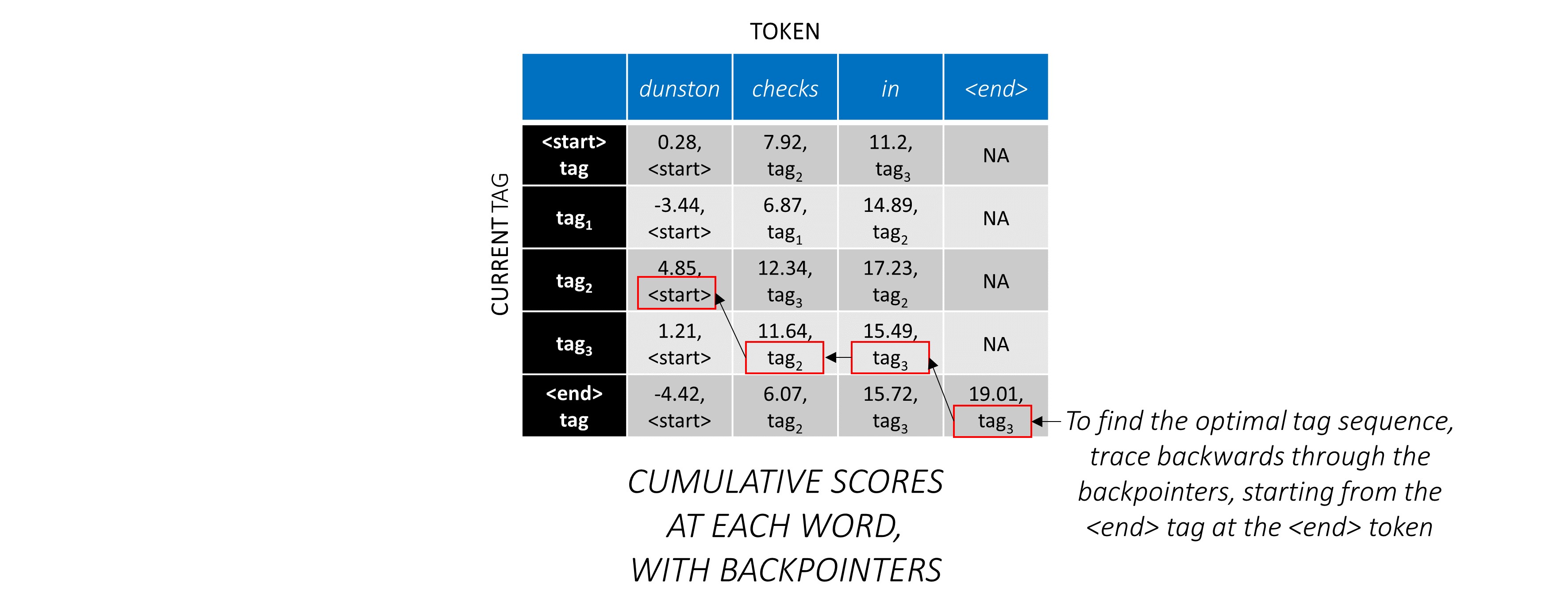
Kami menemukan bahwa urutan tag yang paling optimal untuk dunston checks in <end> adalah tag_2 tag_3 tag_3 <end> .
Bagian di bawah ini secara singkat menjelaskan implementasi.
Mereka dimaksudkan untuk memberikan beberapa konteks, tetapi detail paling baik dipahami langsung dari kode , yang cukup banyak dikomentari.
Saya menggunakan dataset NER CONLL 2003 untuk membandingkan hasil saya dengan kertas.
Ini cuplikan -
-DOCSTART- -X- O O
EU NNP I-NP I-ORG
rejects VBZ I-VP O
German JJ I-NP I-MISC
call NN I-NP O
to TO I-VP O
boycott VB I-VP O
British JJ I-NP I-MISC
lamb NN I-NP O
. . O O
Dataset ini tidak dimaksudkan untuk didistribusikan secara publik, meskipun Anda mungkin menemukannya di suatu tempat online.
Ada beberapa dataset publik online yang dapat Anda gunakan untuk melatih model. Ini mungkin tidak semua 100% manusia beranotasi, tetapi mereka cukup.
Untuk penandaan NER, Anda dapat menggunakan bank yang berarti Groningen.
Untuk penandaan POS, NLTK memiliki dataset kecil yang tersedia Anda dapat mengakses dengan nltk.corpus.treebank.tagged_sents() .
Anda harus mengonversinya ke format data CONLL 2003, atau memodifikasi kode yang dirujuk di bagian pipa data.
Kami akan membutuhkan delapan input.
Ini adalah urutan kata yang harus ditandai.
dunston checks in
Seperti yang dibahas sebelumnya, kami tidak akan menggunakan token <start> tetapi kami perlu menggunakan Token <end> .
dunston, checks, in, <end>
Karena kita melewati kalimat -kalimat sebagai tensor ukuran tetap, kita perlu membawakan kalimat (yang secara alami memiliki panjang yang bervariasi) dengan panjang yang sama dengan token <pad> .
dunston, checks, in, <end>, <pad>, <pad>, <pad>, ...
Selain itu, kami membuat word_map yang merupakan pemetaan indeks untuk setiap kata dalam korpus, termasuk token <end> , dan <pad> . Pytorch, seperti perpustakaan lainnya, membutuhkan kata -kata yang dikodekan sebagai indeks untuk mencari embeddings untuk mereka, atau untuk mengidentifikasi tempat mereka dalam skor kata yang diprediksi.
4381, 448, 185, 4669, 0, 0, 0, ...
Oleh karena itu, urutan kata yang diumpankan ke model harus merupakan Int intension N, L_w di mana N adalah batch_size dan L_w adalah panjang empuk dari urutan kata (biasanya panjang urutan kata terpanjang).
Ini adalah urutan karakter dalam arah maju.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' '
Kita membutuhkan <end> token dalam urutan karakter untuk mencocokkan token <end> dalam urutan kata. Karena kita akan menggunakan fitur-fitur tingkat karakter pada setiap kata dalam urutan kata, kita membutuhkan fitur tingkat karakter di <end> dalam urutan kata.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>
Kita juga perlu membawanya.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>, <pad>, <pad>, <pad>, ...
Dan menyandikannya dengan char_map .
29, 2, 12, 8, 7, 14, 12, 3, 6, 18, 1, 6, 21, 8, 3, 17, 12, 3, 60, 0, 0, 0, ...
Oleh karena itu, urutan karakter maju yang diumpankan ke model harus merupakan tensor Int dari dimensi N, L_c , di mana L_c adalah panjang empuk dari urutan karakter (biasanya panjang urutan karakter terpanjang).
Ini akan diproses sama dengan urutan maju, tetapi mundur. (Token <end> masih ada di akhir, secara alami.)
'n', 'i', ' ', 's', 'k', 'c', 'e', 'h', 'c', ' ', 'n', 'o', 't', 's', 'n', 'u', 'd', ' ', <end>, <pad>, <pad>, <pad>, ...
12, 17, 3, 8, 21, 6, 1, 18, 6, 3, 12, 14, 7, 8, 12, 2, 29, 3, 60, 0, 0, 0, ...
Oleh karena itu, urutan karakter mundur yang diumpankan ke model harus merupakan tensor Int N, L_c .
Penanda ini adalah posisi dalam urutan karakter di mana kami mengekstrak fitur ke -
Kami akan mengekstrak fitur di akhir setiap ruang ' ' dalam urutan karakter, dan di token <end> .
Untuk urutan karakter maju, kami mengekstrak di -
7, 14, 17, 18
Ini adalah poin setelah dunston , checks , in , <end> masing -masing. Dengan demikian, kami memiliki penanda untuk setiap kata dalam urutan kata , yang masuk akal. (Namun, dalam model bahasa, karena kami memprediksi kata berikutnya , kami tidak akan memprediksi pada penanda yang sesuai dengan <end> .)
Kami memberi ini dengan 0 s. Tidak peduli apa yang kita lakukan selama indeks yang valid. (Kami akan mengekstrak fitur di pembalut, tetapi kami tidak akan menggunakannya.)
7, 14, 17, 18, 0, 0, 0, ...
Mereka empuk ke panjang empuk urutan kata, L_w .
Oleh karena itu, penanda karakter maju yang diumpankan ke model harus merupakan Int intension N, L_w .
Untuk penanda dalam urutan karakter mundur, kami juga menemukan posisi dari setiap ruang ' ' dan token <end> .
Kami juga memastikan bahwa posisi -posisi ini berada dalam urutan kata yang sama seperti pada penanda maju . Penyelarasan ini memudahkan untuk menggabungkan fitur yang diekstraksi dari urutan karakter maju dan mundur, dan juga mencegah harus memesan ulang target dalam model bahasa.
17, 9, 2, 18
Ini adalah poin setelah notsnud , skcehc , ni , <end> masing -masing.
Kami pad dengan 0 s.
17, 9, 2, 18, 0, 0, 0, ...
Oleh karena itu, penanda karakter terbelakang yang diumpankan ke model harus merupakan Int dari dimensi N, L_w .
Mari kita asumsikan tag yang benar untuk dunston, checks, in, <end> adalah -
tag_2, tag_3, tag_3, <end>
Kami memiliki tag_map (berisi tag <start> , tag_1 , tag_2 , tag_3 , <end> ).
Biasanya, kami hanya akan menyandikannya secara langsung (sebelum padding) -
2, 3, 3, 5
Ini adalah pengkodean 1D , yaitu, posisi tag di peta tag 1D .
Tetapi output dari lapisan CRF adalah 2D m, m tensors pada setiap kata. Kami perlu menyandikan posisi tag dalam output 2D ini.
Posisi tag yang benar ditandai merah.
(0, 2), (2, 3), (3, 3), (3, 4)
Jika kita membuka gulungan skor ini menjadi tensor 1D m*m , maka posisi tag di tensor yang belum digulung akan
tag_map [ previous_tag ] * len ( tag_map ) + tag_map [ current_tag ] Oleh karena itu, kami mengkode tag_2, tag_3, tag_3, <end> sebagai
2, 13, 18, 19
Perhatikan bahwa Anda dapat mengambil indeks tag_map asli dengan mengambil modulus
t % len ( tag_map ) Mereka akan empuk ke panjang empuk urutan kata, L_w .
Oleh karena itu, tag yang diumpankan ke model harus merupakan tensor Int dimensi N, L_w .
Ini adalah panjang aktual dari urutan kata termasuk token <end> . Karena Pytorch mendukung grafik dinamis, kami hanya akan menghitung selama ini dan tidak di atas <pads> .
Oleh karena itu, panjang kata yang diumpankan ke model harus merupakan Int intension N .
Ini adalah panjang aktual dari urutan karakter termasuk token <end> . Karena Pytorch mendukung grafik dinamis, kami hanya akan menghitung selama ini dan tidak di atas <pads> .
Oleh karena itu, panjang karakter yang diumpankan ke model harus merupakan Int intension N .
Lihat read_words_tags() di utils.py .
Ini membaca file input dalam format CONLL 2003, dan mengekstrak urutan kata dan tag.
Lihat create_maps() di utils.py .
Di sini, kami membuat peta pengkodean untuk kata -kata, karakter, dan tag. We bin rare words and characters as <unk> s (unknowns).
Lihat create_input_tensors() di utils.py .
Kami menghasilkan delapan input yang dirinci dalam bagian input ke model.
Lihat load_embeddings() di utils.py .
Kami memuat embeddings pra-terlatih, dengan opsi untuk memperluas word_map untuk memasukkan kata-kata di luar corpus yang ada dalam kosakata yang menanamkan. Note that this may also include rare in-corpus words that were binned as <unk> s earlier.
Lihat WCDataset di datasets.py .
Ini adalah subclass dari Dataset Pytorch. Dibutuhkan metode __len__ yang didefinisikan, yang mengembalikan ukuran dataset, dan metode __getitem__ yang mengembalikan i ke delapan input ke model.
Dataset akan digunakan oleh Pytorch DataLoader di train.py untuk membuat dan memberi makan batch data ke model untuk pelatihan atau validasi.
Lihat Highway di models.py .
Transformasi adalah transformasi linier yang diaktifkan relu dari input. Gerbang adalah transformasi linier yang diaktifkan sigmoid dari input. Perhatikan bahwa kedua transformasi harus memiliki ukuran yang sama dengan input , untuk memungkinkan untuk menambahkan input dalam koneksi residual.
Atribut num_layers spesifik berapa banyak operasi koneksi-gate-gate-residual yang kami lakukan secara seri. Biasanya hanya satu yang cukup.
Kami menyimpan jumlah transformasi dan lapisan gerbang yang diperlukan di ModuleList() yang terpisah, dan menggunakan for untuk melakukan operasi berturut -turut.
Lihat LM_LSTM_CRF di models.py .
Pada awalnya, kami mengurutkan urutan karakter maju dan mundur dengan mengurangi panjang . Hal ini diperlukan untuk menggunakan pack_padded_sequence() agar LSTM hanya menghitung hanya pada waktu yang valid, yaitu panjang sebenarnya dari urutan.
Ingatlah untuk juga mengurutkan semua tensor lain dalam urutan yang sama.
Lihat dynamic_rnn.py untuk ilustrasi tentang bagaimana pack_padded_sequence() dapat digunakan untuk memanfaatkan kemampuan grafik dan batching dinamis Pytorch sehingga kami tidak memproses bantalan. Ini meratakan urutan yang diurutkan berdasarkan timestep sambil mengabaikan bantalan, dan LSTM menghitung hanya dengan ukuran batch efektif N_t di setiap waktu .
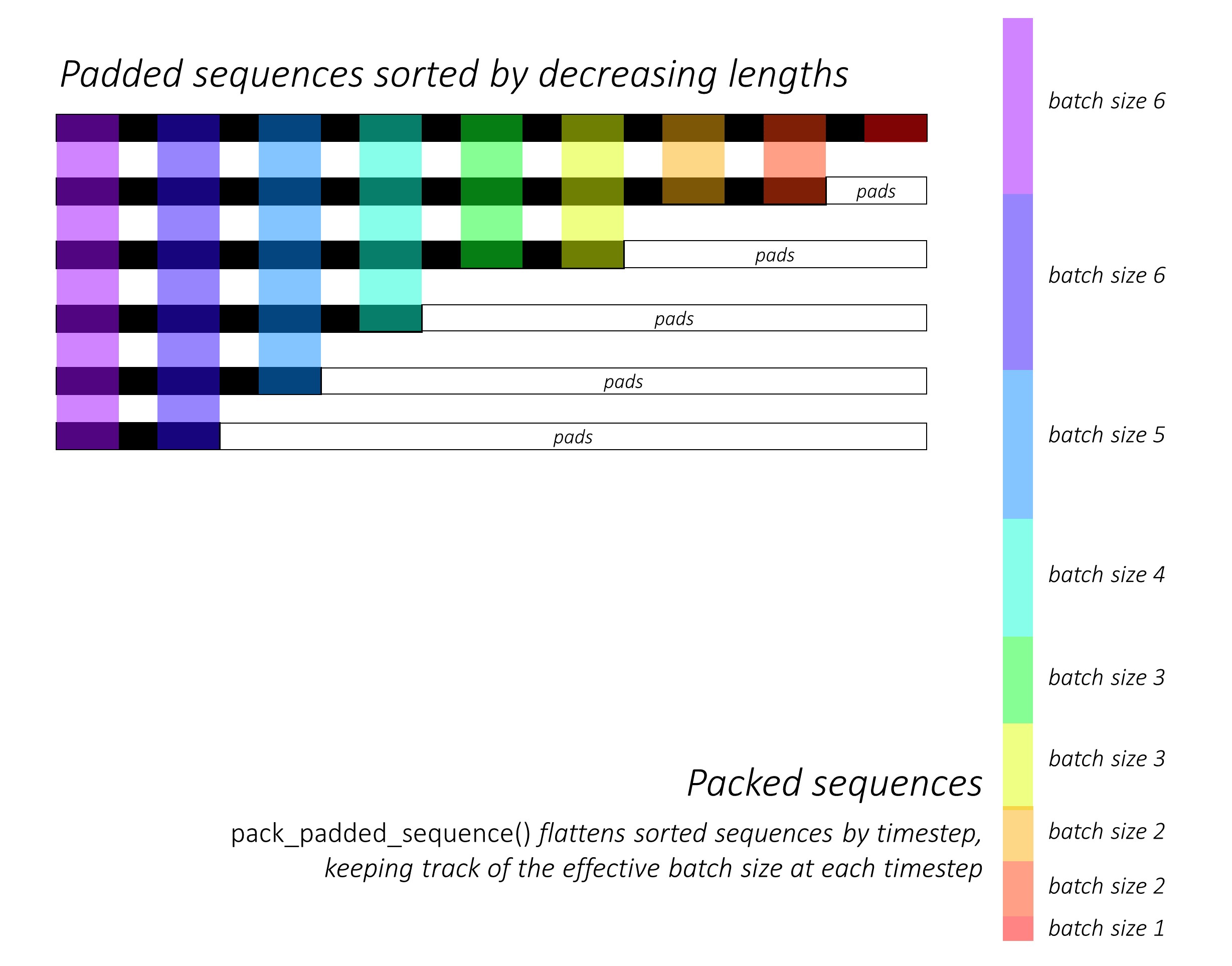
Penyortiran memungkinkan N_t teratas pada waktu mana pun untuk menyelaraskan dengan output dari langkah sebelumnya . Pada timestep ketiga, misalnya, kami hanya memproses 5 gambar teratas, menggunakan 5 output teratas dari langkah sebelumnya. Kecuali untuk penyortiran, semua ini ditangani secara internal oleh Pytorch, tetapi masih sangat berguna untuk memahami apa yang dilakukan pack_padded_sequence() sehingga kita dapat menggunakannya dalam skenario lain untuk mencapai tujuan yang serupa. (Lihat pertanyaan terkait tentang menangani urutan panjang variabel di bagian FAQ.)
Setelah menyortir, kami masing -masing menerapkan packed_sequences ke depan dan ke belakang . Kami menggunakan pad_packed_sequence() untuk tidak memflat dan padam kembali output.
Kami hanya mengekstrak output pada penanda karakter maju dan mundur dengan gather . Fungsi ini sangat berguna untuk mengekstraksi hanya indeks tertentu dari tensor yang ditentukan dalam tensor terpisah.
Output yang diekstraksi ini diproses oleh lapisan jalan raya ke depan dan ke belakang sebelum menerapkan lapisan linier untuk menghitung skor di atas kosa kata untuk memprediksi kata berikutnya pada setiap penanda. Kami melakukan ini hanya selama pelatihan, karena tidak masuk akal untuk melakukan pemodelan bahasa untuk pembelajaran multi-tugas selama validasi atau inferensi. Atribut training model apa pun diatur dengan model.train() atau model.eval() di train.py . (Perhatikan bahwa ini terutama digunakan untuk mengaktifkan atau menonaktifkan lapisan putus sekolah dan norma dalam model Pytorch selama pelatihan dan inferensi masing-masing.)
Lihat LM_LSTM_CRF di models.py (lanjutan).
Kami juga mengurutkan urutan kata dengan mengurangi panjang , karena mungkin tidak selalu ada korelasi antara panjang urutan kata dan urutan karakter.
Ingatlah untuk juga mengurutkan semua tensor lain dalam urutan yang sama.
Kami menggabungkan output LSTM ke depan dan ke belakang pada penanda, dan menjalankannya melalui lapisan jalan raya ketiga . Ini akan mengekstraksi informasi sub-kata pada setiap kata yang akan kami gunakan untuk pelabelan urutan.
Kami menyatukan hasil ini dengan kata embeddings, dan menghitung output BLSTM di atas packed_sequence .
Setelah melumpuhkan kembali dengan pad_packed_sequence() , kami memiliki fitur yang kami butuhkan untuk memberi makan ke lapisan CRF.
Lihat CRF di models.py .
Anda mungkin menemukan lapisan ini secara mengejutkan langsung mengingat nilai yang ditambahkan ke model kami.
Lapisan linier digunakan untuk mengubah output dari BLSTM menjadi skor untuk setiap tag, yang merupakan skor emisi .
Tensor tunggal digunakan untuk menahan skor transisi . Tensor ini adalah Parameter model, yang berarti dapat diperbarui selama backpropagation, seperti bobot lapisan lainnya.
Untuk menemukan skor CRF, hitung skor emisi pada setiap kata dan tambahkan ke skor transisi , setelah menyiarkan baik seperti yang dijelaskan dalam ikhtisar CRF.
Lihat ViterbiLoss di models.py .
Kami menetapkan dalam ikhtisar kerugian Viterbi bahwa kami ingin meminimalkan perbedaan antara log-sum-exp dari skor dari semua urutan tag yang valid yang mungkin dan skor urutan tag emas , yaitu log-sum-exp(all scores) - gold score .
Kami menyimpulkan skor CRF dari setiap tag yang benar seperti yang dijelaskan sebelumnya untuk menghitung skor emas .
Ingat bagaimana kita mengkodekan urutan tag dengan posisi mereka dalam skor CRF yang belum digulung? Kami mengekstrak skor pada posisi ini dengan gather() dan menghilangkan bantalan dengan pack_padded_sequences() sebelum menjumlahkan.
Menemukan log-sum-exp dari skor dari semua urutan yang mungkin sedikit lebih rumit. Kami menggunakan for untuk mengulangi waktu. Di setiap timestep, kami mengumpulkan skor untuk setiap current_tag oleh -
current_tag untuk setiap previous_tag . Kami melakukan ini hanya pada ukuran batch yang efektif, yaitu untuk urutan yang belum selesai. (Urutan kami masih diurutkan dengan mengurangi panjang kata, dari model LM-LSTM-CRF .)current_tag , hitung log-sum-exp melalui previous_tag S untuk menemukan skor akumulasi baru di setiap current_tag . Setelah menghitung dengan panjang variabel dari semua urutan, kami dibiarkan dengan tensor dimensi N, m , di mana m adalah jumlah tag (saat ini). Ini adalah skor akumulasi log-sum-exp pada semua urutan yang memungkinkan di masing-masing tag m Namun, karena urutan yang valid hanya dapat diakhiri dengan tag <end> , jumlah hanya pada kolom <end> untuk menemukan log-sum-exp dari skor dari semua urutan yang valid yang mungkin .
Kami menemukan perbedaannya, log-sum-exp(all scores) - gold score .
Lihat ViterbiDecoder di inference.py .
Ini mengimplementasikan proses yang dijelaskan dalam ikhtisar decoding Viterbi.
Kami mengumpulkan skor dalam for untuk dengan cara yang mirip dengan apa yang kami lakukan di ViterbiLoss , kecuali di sini kami menemukan maksimum skor previous_tag untuk setiap current_tag , alih-alih menghitung log-sum-exp. Kami juga melacak previous_tag yang sesuai dengan skor maksimum ini dalam tensor backpointer.
Kami menempatkan tensor backpointer dengan tag <end> karena ini memungkinkan kami untuk melacak ke belakang di atas pembalut, akhirnya tiba di tag <end> yang sebenarnya , dimana backtracing yang sebenarnya dimulai.
Lihat train.py .
Parameter untuk model (dan melatihnya) berada di awal file, sehingga Anda dapat dengan mudah memeriksa atau memodifikasinya jika Anda ingin.
Untuk melatih model Anda dari awal , jalankan file ini -
python train.py
Untuk melanjutkan pelatihan di pos pemeriksaan , arahkan ke file yang sesuai dengan parameter checkpoint di awal kode.
Perhatikan bahwa kami melakukan validasi di akhir setiap zaman pelatihan.
Anda akan melihat kami memangkas input pada setiap batch dengan panjang urutan maksimum dalam batch itu . Ini jadi kami tidak memiliki lebih banyak bantalan di setiap batch yang sebenarnya kami butuhkan.
Tapi kenapa? Meskipun RNN dalam model kami tidak menghitung di atas bantalan, lapisan linier masih melakukannya . Cukup lurus untuk mengubah ini - lihat pertanyaan terkait tentang menangani urutan panjang variabel di bagian FAQ.
Untuk tutorial ini, saya pikir sedikit komputasi tambahan atas beberapa bantalan sepadan dengan keterusterangan karena tidak harus melakukan banyak operasi - jalan raya, CRF, lapisan linier lainnya, rangkaian - pada packed_sequence .
Dalam skenario multi-tugas, kami telah memilih untuk menjumlahkan kehilangan entropi silang dari dua tugas pemodelan bahasa dan kehilangan viterbi dari tugas pelabelan urutan.
Meskipun kami meminimalkan jumlah kerugian ini , kami sebenarnya hanya tertarik untuk meminimalkan kerugian viterbi karena meminimalkan jumlah kerugian ini . Kehilangan Viterbi yang mencerminkan kinerja pada tugas utama.
Kami menggunakan pack_padded_sequence() untuk menghilangkan bantalan di mana pun diperlukan.
Seperti di koran, kami menggunakan skor F1 rata-rata makro sebagai kriteria untuk stopping awal . Secara alami, menghitung skor F1 memerlukan viterbi mendekode skor CRF untuk menghasilkan urutan tag optimal kami.
Kami menggunakan pack_padded_sequence() untuk menghilangkan bantalan di mana pun diperlukan.
Saya telah mengikuti parameter dalam implementasi penulis sedekat mungkin.
Saya menggunakan ukuran batch 10 kalimat. Saya menggunakan keturunan gradien stokastik dengan momentum. Tingkat pembelajaran membusuk setiap zaman. Saya menggunakan embeddings 100d sarung tangan pretrained tanpa menyempurnakan.
Butuh sekitar 80 -an untuk melatih satu zaman di Titan X (Pascal).
Skor F1 pada set validasi mencapai 91% di sekitar zaman 50, dan memuncak pada 91.6% pada Epoch 171. Saya menjalankannya dengan total 200 zaman. Ini cukup dekat dengan hasil di koran.
Anda dapat mengunduh model pretrained ini di sini.
Bagaimana kita memutuskan apakah kita membutuhkan <start> dan <end> token untuk model yang menggunakan sekuens?
Jika ini tampaknya membingungkan pada awalnya, itu akan dengan mudah menyelesaikan dirinya sendiri ketika Anda berpikir tentang persyaratan model yang Anda rencanakan untuk dilatih.
Untuk pelabelan urutan dengan CRF, Anda memerlukan token <end> ( atau token <start> ; lihat pertanyaan berikutnya) karena bagaimana skor CRF disusun.
Dalam tutorial saya yang lain tentang captioning gambar, saya menggunakan kedua token <start> dan <end> . Model perlu mulai mendekodekan di suatu tempat , dan belajar untuk mengenali kapan harus berhenti mendekode selama inferensi.
Jika Anda melakukan klasifikasi teks, Anda tidak akan membutuhkan keduanya.
Bisakah kita meminta CRF menghasilkan skor current_word -> next_word alih -alih previous_word -> current_word ?
Ya. Dalam hal ini Anda akan menyiarkan skor emisi seperti L, m, _ , dan Anda akan memiliki token <start> dalam setiap kalimat alih -alih token <end> . Tag yang benar dari token <start> akan selalu menjadi tag <start> . "Tag berikutnya" dari kata terakhir akan selalu menjadi tag <end> .
Saya pikir previous word -> current word sedikit lebih baik karena ada model bahasa dalam campuran. Sangat cocok untuk dapat memprediksi token <end> pada kata nyata terakhir, dan karena itu belajar untuk mengenali kapan kalimat selesai.
Mengapa kita menggunakan kosakata yang berbeda untuk input tagger urutan dan output model bahasa?
Model bahasa akan belajar memprediksi hanya kata -kata yang telah dilihatnya selama pelatihan. Ini benar-benar tidak perlu, dan pemborosan komputasi dan memori yang sangat besar, untuk menggunakan lapisan linier-softmax dengan kata-kata tambahan ~ 400.000 out-of-corpus dari file embedding yang tidak akan pernah diprediksi untuk diprediksi.
Tetapi kita dapat menambahkan kata -kata ini ke lapisan input bahkan jika model tidak pernah melihatnya selama pelatihan. Ini karena kami menggunakan embeddings pra-terlatih di input. Tidak perlu melihatnya karena makna kata -kata dikodekan dalam vektor -vektor ini. Jika ditemui chimpanzee sebelumnya, kemungkinan besar itu tahu apa yang harus dilakukan dengan orangutan .
Apakah itu ide yang baik untuk menyempurnakan embeddings kata pra-terlatih yang kita gunakan dalam model ini?
Saya menahan diri untuk tidak menyempurnakan karena sebagian besar kosa kata input tidak ada dalam corpus. Most embeddings will remain the same while a few are fine-tuned. If fine-tuning changes these embeddings sufficiently, the model may not work well with the words that weren't fine-tuned. In the real world, we're bound to encounter many words that weren't present in a newspaper corpus from 2003.
What are some ways we can construct dynamic graphs in PyTorch to compute over only the true lengths of sequences?
If you're using an RNN, simply use pack_padded_sequence() . PyTorch will internally compute over only the true lengths. See dynamic_rnn.py for an example.
If you want to execute an operation (like a linear transformation) only on the true timesteps, pack_padded_sequences() is still the way to go. This flattens the tensor by timestep while removing the pads. You can perform your operation on this flattened tensor, and then use pad_packed_sequence() to unflatten it and re-pad it with 0 s.
Similarly, if you want to perform an aggregation operation, like computing the loss, use pack_padded_sequences() to eliminate the pads.
If you want to perform timestep-wise operations, you can take a leaf out of how pack_padded_sequences() works, and compute only on the effective batch size at each timestep with a for loop to iterate over the timesteps. We did this in the ViterbiLoss and ViterbiDecoder . I also used an LSTMCell() in this fashion in my image captioning tutorial.
Dunston Checks In ? Benar-benar?
I had no memory of this movie for twenty years. I was trying to think of a short sentence that would be easier to visualize in this tutorial and it just popped into my mind riding a wave of 90s nostalgia.

I wish I hadn't googled it though. Damn, the critics were harsh, weren't they? This gem was overwhelmingly and universally panned. I'm not sure I'd disagree if I watched it now, but that just goes to show the world is so much more fun when you're a kid.
Didn't have to worry about LM-LSTM-CRFs or nuthin...


