a PyTorch Tutorial to Sequence Labeling
1.0.0
Il s'agit d'un tutoriel Pytorch pour séquencer le marquage .
Ceci est le deuxième d'une série de tutoriels que j'écris sur la mise en œuvre de modèles sympas par vous-même avec l'incroyable bibliothèque Pytorch.
La connaissance de base des réseaux de neurones récurrentes pytorch est supposé.
Si vous êtes nouveau sur Pytorch, lisez d'abord l'apprentissage en profondeur avec Pytorch: un blitz de 60 minutes et l'apprentissage pytorch avec des exemples.
Des questions, des suggestions ou des corrections peuvent être affichées comme des problèmes.
J'utilise PyTorch 0.4 dans Python 3.6 .
27 janvier 2020 : le code de travail pour deux nouveaux tutoriels a été ajouté - Super-résolution et traduction automatique
Objectif
Concepts
Aperçu
Mise en œuvre
Entraînement
Questions fréquemment posées
Pour construire un modèle qui peut étiqueter chaque mot dans une phrase avec des entités, des parties de la parole, etc.

Nous mettrons en œuvre l' étiquetage de la séquence d'autonomisation avec un document de modèle de langue neuronale consciente des tâches . Ceci est plus avancé que la plupart des modèles de marquage de séquence, mais vous apprendrez de nombreux concepts utiles - et cela fonctionne extrêmement bien. L'implémentation originale des auteurs peut être trouvée ici.
Ce modèle est spécial car il augmente la tâche d'étiquetage des séquences en l'entraînant simultanément avec les modèles de langue.
Étiquetage de séquence . duh.
Modèles linguistiques . La modélisation du langage est de prédire le mot ou le caractère suivant dans une séquence de mots ou de caractères. Les modèles de langage neuronal obtiennent des résultats impressionnants sur une grande variété de tâches NLP comme la génération de texte, la traduction automatique, le sous-titrage de l'image, la reconnaissance optique des caractères et ce que vous avez.
RNNS de caractère . Les RNN opérant sur des caractères individuels dans un texte sont connus pour capturer le style et la structure sous-jacents. Dans une tâche d'étiquetage de séquence, ils sont particulièrement utiles car les informations de sous-mot peuvent souvent produire des indices importants sur une entité ou une balise.
Apprentissage multi-tâches . Les ensembles de données disponibles pour former un modèle sont souvent petits. La création d'annotations ou de fonctionnalités fabriquées à la main pour aider votre modèle est non seulement lourde, mais aussi souvent pas adaptable aux divers domaines ou paramètres dans lesquels votre modèle peut être utile. Le marquage de séquence, malheureusement, est un excellent exemple. Il existe un moyen d'atténuer ce problème - la formation conjointe de plusieurs modèles qui sont jointes à la hanche maximisera les informations disponibles pour chaque modèle, améliorant les performances.
Champs aléatoires conditionnels . Les classificateurs discrets prédisent une classe ou un étiquette en un mot. Les champs aléatoires conditionnels (CRF) peuvent vous faire mieux - ils prédisent des étiquettes en fonction non seulement du mot, mais aussi du quartier. Ce qui a du sens, car il existe des modèles dans une séquence d'entités ou d'étiquettes. Les CRF sont largement utilisés pour modéliser les informations ordonnées, que ce soit pour le marquage de séquence, le séquençage des gènes ou même la détection d'objets et la segmentation d'image dans la vision par ordinateur.
Décodage viterbi . Puisque nous utilisons les CRF, nous ne prédisons pas tant la bonne étiquette à chaque mot que nous prédisons la séquence d'étiquette droite pour une séquence de mots. Le décodage viterbi est un moyen de faire exactement cela - trouvez la séquence de balises la plus optimale à partir des scores calculés par un champ aléatoire conditionnel.
Réseaux routiers . Les couches entièrement connectées sont un aliment de base dans tout réseau de neurones pour transformer ou extraire des fonctionnalités à différents endroits. Les réseaux routiers accomplissent cela, mais permettent également aux informations de circuler sans entrave à travers les transformations. Cela rend les réseaux profonds beaucoup plus efficaces ou réalisables.
Dans cette section, je présenterai un aperçu de ce modèle. Si vous le savez déjà, vous pouvez passer directement à la section d'implémentation ou au code commenté.
Les auteurs appellent le modèle comme le modèle de langue - champ aléatoire à court terme à court terme - condition aléatoire car il implique des modèles de langage de formation de co-entraînement avec une combinaison LSTM + CRF .
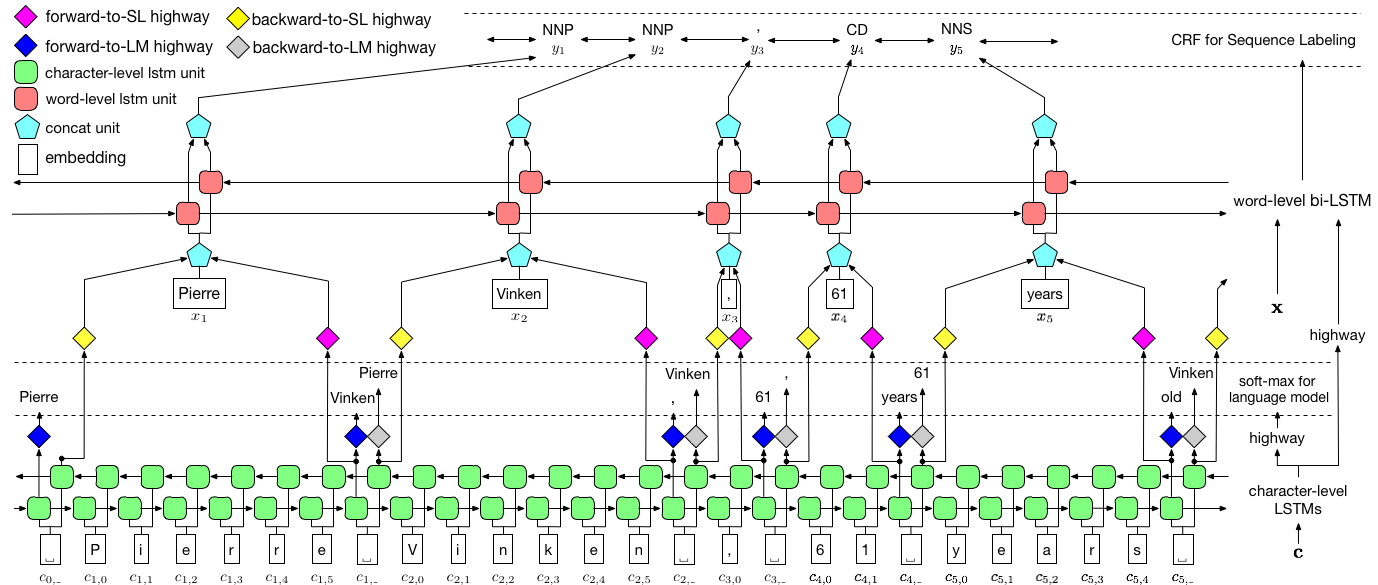
Cette image du papier représente complètement l'ensemble du modèle, mais ne vous inquiétez pas si elle semble trop complexe pour le moment. Nous allons le décomposer pour examiner de plus près les composants.
L'apprentissage multi-tâches, c'est lorsque vous formez simultanément un modèle sur deux tâches ou plus.
Habituellement, nous ne sommes intéressés que par l'une de ces tâches - dans ce cas, le marquage de séquence.
Mais lorsque les couches d'un réseau neuronal contribuent à remplir plusieurs fonctions, ils en apprennent plus qu'ils ne l'auraient fait s'ils ne s'étaient entraînés que sur la tâche principale. En effet, les informations extraites à chaque couche sont élargies pour accueillir toutes les tâches. Lorsqu'il y a plus d'informations avec lesquelles travailler, les performances de la tâche principale sont améliorées .
Enrichir les fonctionnalités existantes de cette manière supprime la nécessité d'utiliser des fonctionnalités fabriquées à la main pour l'étiquetage des séquences.
La perte totale pendant l'apprentissage multi-tâches est généralement une combinaison linéaire des pertes sur les tâches individuelles. Les paramètres de la combinaison peuvent être fixés ou appris comme des poids à jour.

Étant donné que nous agrégeons les pertes individuelles, vous pouvez voir comment les couches en amont partagées par plusieurs tâches recevraient des mises à jour de chacun d'eux pendant la rétropropagation.
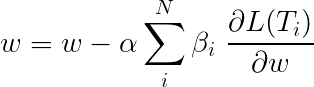
Les auteurs de l'article ajoutent simplement les pertes ( β=1 ), et nous ferons de même.
Jetons un coup d'œil aux tâches qui composent notre modèle.
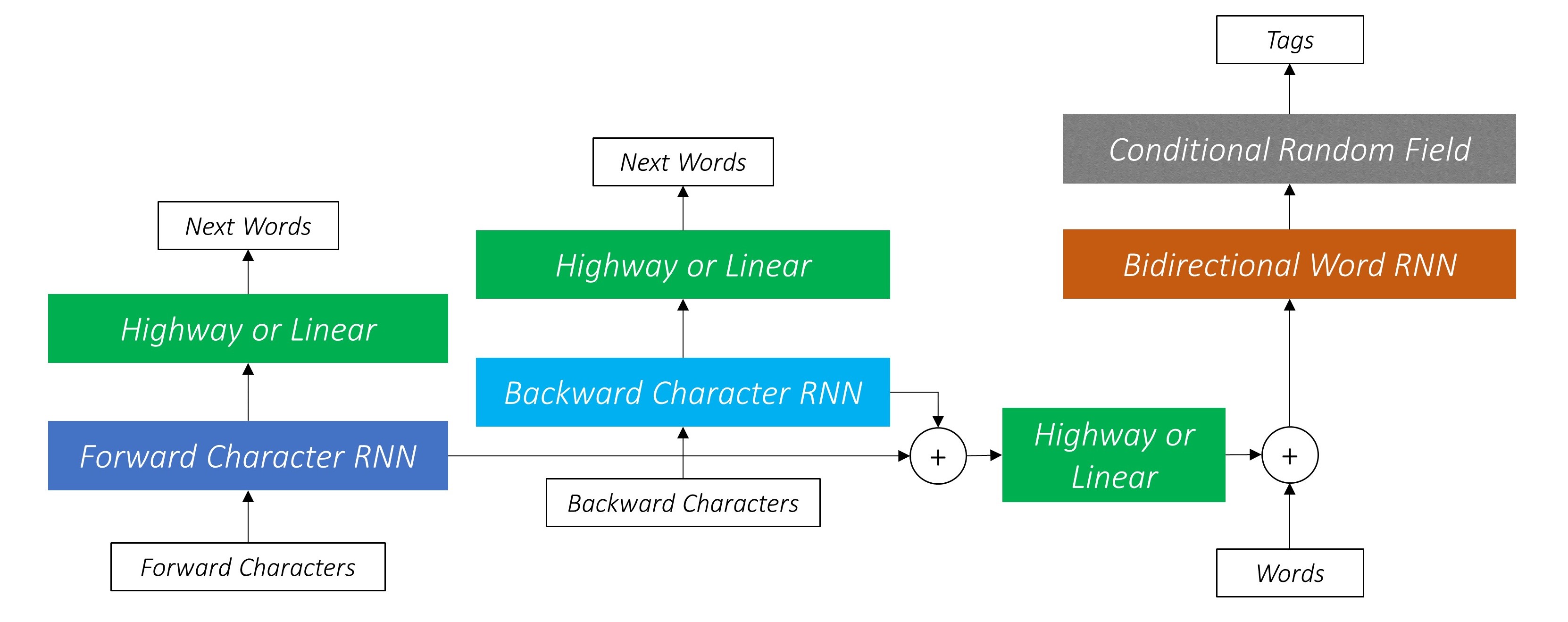
Il y en a trois .

Cela exploite les informations de sous-mot pour prédire le mot suivant.
Nous faisons de même dans la direction arrière. 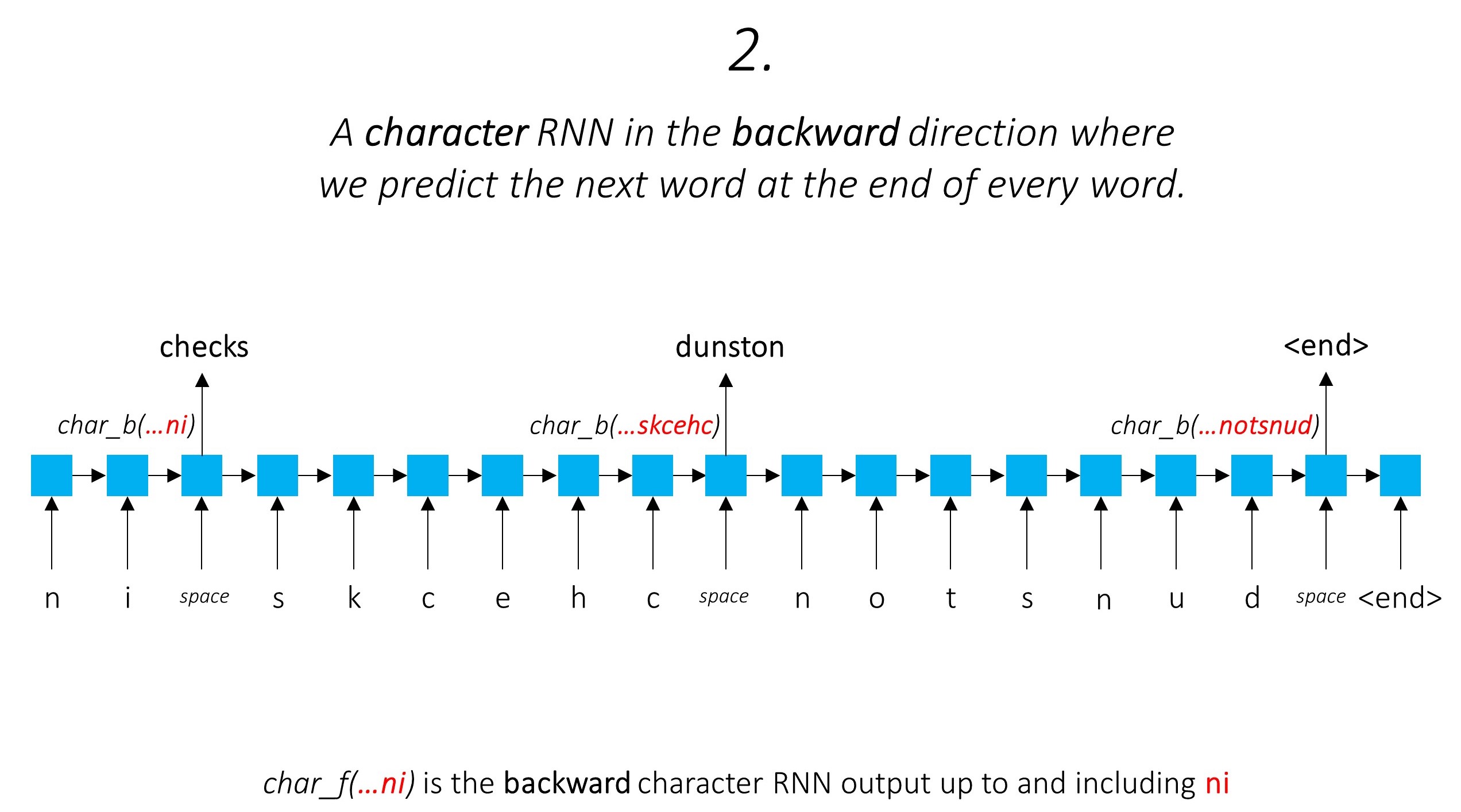
Nous utilisons également les sorties de ces deux caractéristiques RNN comme entrées de notre champ aléatoire Word-RNN et conditionnel (CRF) pour effectuer notre tâche principale de marquage de séquence. 
Nous utilisons des informations de sous-mot dans notre tâche de marquage car elle peut être un indicateur puissant des balises, qu'il s'agisse de parties de la parole ou des entités. Par exemple, il peut apprendre que les adjectifs se terminent généralement par "-y" ou "-ul", ou que les lieux se terminent souvent par "-Land" ou "-Burg".
Mais nos fonctionnalités de sous-mot, à savoir. Les sorties des RNN de caractère sont également enrichies avec des informations supplémentaires - les connaissances dont elle a besoin pour prédire le mot suivant dans les directions avant et arrière, en raison des modèles 1 et 2.
Par conséquent, notre modèle de marquage de séquence utilise les deux
Le LSTM / RNN bidirectionnel code ces fonctionnalités en nouvelles fonctionnalités à chaque mot contenant des informations sur le mot et son quartier, à la fois au niveau du mot et au niveau du caractère. Cela forme l'entrée dans le champ aléatoire conditionnel.
Sans CRF, nous aurions simplement utilisé une seule couche linéaire pour transformer la sortie du LSTM bidirectionnel en scores pour chaque balise. Ceux-ci sont appelés scores d'émission , qui sont une représentation de la probabilité que le mot soit une certaine étiquette.
Un CRF calcule non seulement les scores d'émission, mais aussi les scores de transition , qui sont la probabilité qu'un mot soit une certaine étiquette étant donné que le mot précédent était une certaine balise. Par conséquent, les scores de transition mesurent dans quelle mesure il est probable de passer d'une étiquette à l'autre.
S'il y a des étiquettes m , les scores de transition sont stockés dans une matrice de dimessions m, m , où les lignes représentent l'étiquette du mot précédent et les colonnes représentent l'étiquette du mot actuel. Une valeur dans cette matrice à la position i, j est la probabilité de passer de la balise i th au mot précédent à la balise j th au mot actuel . Contrairement aux scores d'émission, les scores de transition ne sont pas définis pour chaque mot de la phrase. Ils sont mondiaux.
Dans notre modèle, la couche CRF produit l' agrégat des scores d'émission et de transition à chaque mot .
Pour une phrase de longueur L , les scores d'émission seraient un tenseur L, m . Étant donné que les scores d'émission à chaque mot ne dépendent pas de la balise du mot précédent, nous créons une nouvelle dimension comme L, _, m et diffuse (copier) le tenseur dans cette direction pour obtenir un tenseur L, m, m
Les scores de transition sont un tenseur m, m Étant donné que les scores de transition sont globaux et ne dépendent pas du mot, nous créons une nouvelle dimension comme _, m, m et diffuser (copier) le tenseur dans cette direction pour obtenir un tenseur L, m, m .
Nous pouvons maintenant les ajouter pour obtenir les scores totaux qui sont un tenseur L, m, m Une valeur en position k, i, j est l' agrégat du score d'émission de l'étiquette j th au k mot et le score de transition de la tag j th au k th thème considérant que le mot précédent était l'étiquette i th.
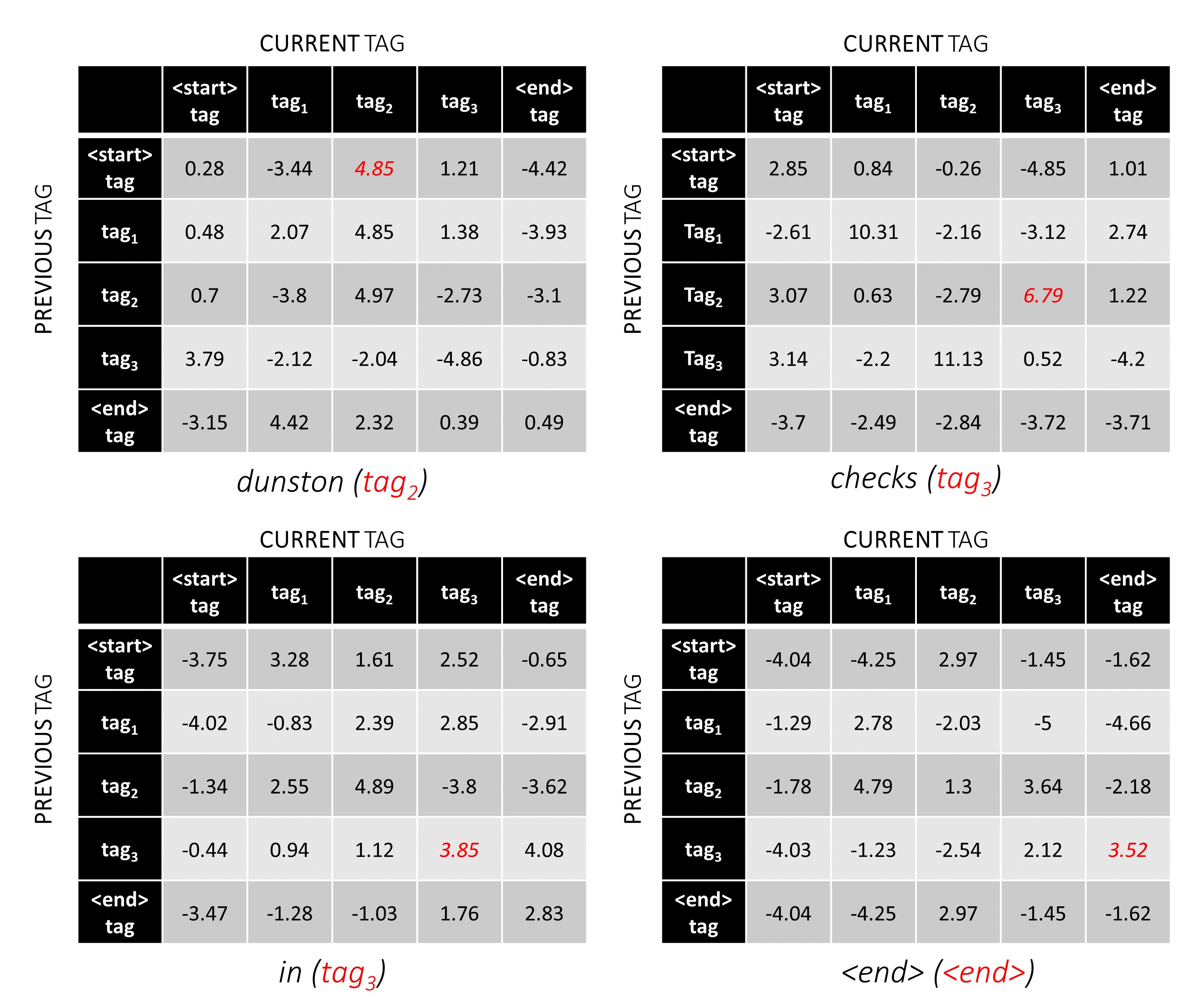
Pour notre exemple de phrase, dunston checks in <end> , si nous supposons qu'il y a 5 balises au total, les scores totaux ressembleraient à ceci -
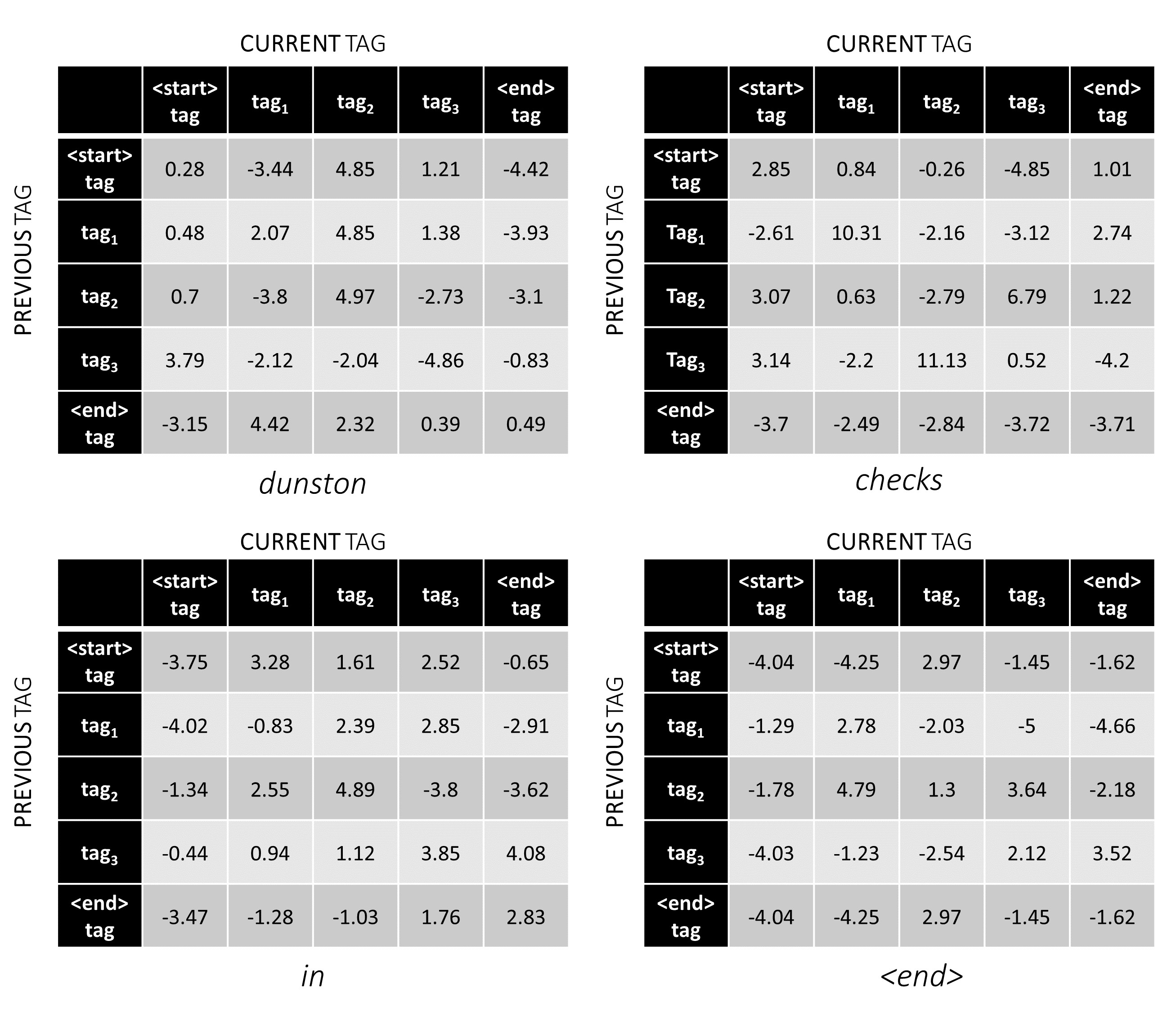
Mais attendez une minute, pourquoi y a-t-il des balises <start> end <end> ? Pendant que nous y sommes, pourquoi utilisons-nous un jeton <end> ?
<start> et <end> , <start> et <end> jetons Étant donné que nous modélissons la probabilité de transition entre les balises, nous incluons également une balise <start> et une balise <end> dans notre ensemble de balises.
Le score de transition d'une certaine balise étant donné que la balise précédente était une balise <start> représente la probabilité que cette balise soit la première balise d'une phrase . Par exemple, les phrases commencent généralement par des articles (a, an, le) ou des noms ou des pronoms.
Le score de transition de la balise <end> considérant une certaine balise précédente indique la probabilité que cette balise précédente soit la dernière étiquette d'une phrase .
Nous utiliserons un jeton <end> dans toutes les phrases et non un jeton <start> car les scores CRF totaux à chaque mot sont définis en ce qui concerne la balise du mot précédent , qui n'aurait aucun sens dans un jeton <start> .
La balise correcte du jeton <end> est toujours la balise <end> . La "balise précédente" du premier mot est toujours la balise <start> .
Pour illustrer, si notre exemple de phrase dunston checks in <end> avait les balises tag_2, tag_3, tag_3, <end> , les valeurs en rouge indiquent les scores de ces balises.
Nous utilisons généralement des couches linéaires activées pour transformer et traiter les sorties d'un RNN / LSTM.
Si vous connaissez les connexions résiduelles, nous pouvons ajouter l'entrée avant la transformation de la sortie transformée, créant un chemin pour le flux de données autour de la transformation.
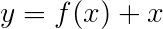
Ce chemin est un raccourci pour l'écoulement des gradients pendant la rétro-propagation, et aide à la convergence des réseaux profonds.
Un réseau routier est similaire à un réseau résiduel, mais nous utilisons une porte activée par Sigmoïd pour déterminer le rapport dans lequel l'entrée et la sortie transformée sont combinées .
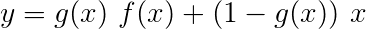
Étant donné que les RNN des caractères contribuent à plusieurs tâches, les réseaux routiers sont utilisés pour extraire des informations spécifiques à la tâche à partir de ses sorties.
Par conséquent, nous utiliserons les réseaux routiers à trois endroits de notre modèle combiné -
Dans un paramètre de co-formation naïf, où nous utilisons les sorties des RNN de caractère directement pour plusieurs tâches, c'est-à-dire sans transformation, la discordance entre la nature des tâches pourrait nuire aux performances.
Il pourrait maintenant être clair à quoi ressemble notre réseau combiné.
La suppression progressive des pièces de notre réseau entraîne des réseaux progressivement plus simples qui sont largement utilisés pour l'étiquetage des séquences.
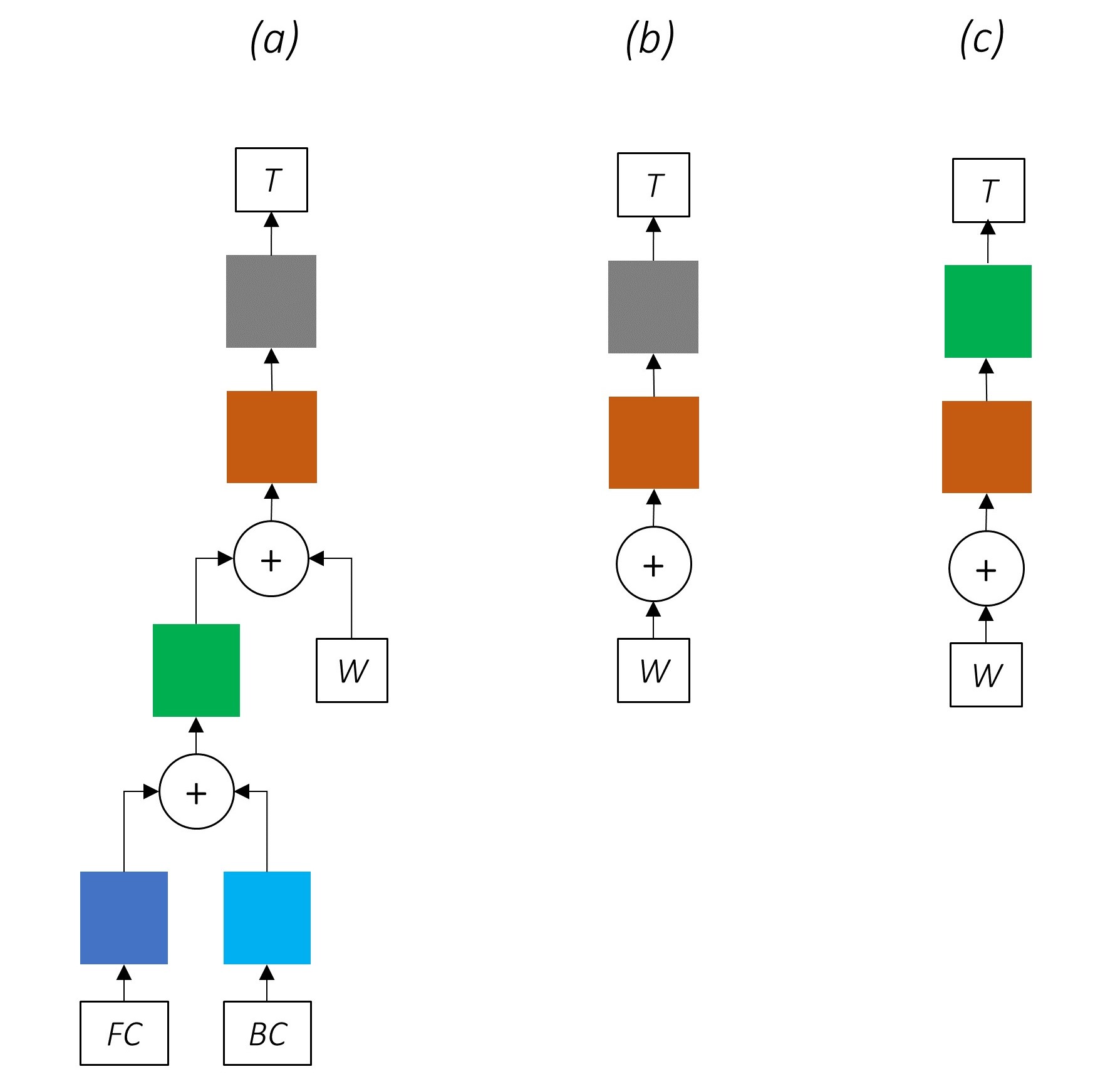
Il n'y a pas d'apprentissage multi-tâches.
L'utilisation d'informations au niveau des caractères sans co-formation améliore toujours les performances.
Il n'y a pas d'apprentissage multi-tâches ou de traitement au niveau des caractères.
Cette configuration est utilisée assez couramment dans l'industrie et fonctionne bien.
Il n'y a pas d'apprentissage multi-tâches, de traitement au niveau des caractères ou de CRFING. Notez qu'une couche linéaire ou routière remplacerait ce dernier.
Cela pourrait fonctionner assez bien, mais un champ aléatoire conditionnel fournit une augmentation importante des performances.
N'oubliez pas que nous n'utilisons pas de couche linéaire qui ne calcule que les scores d'émission. L'entropie croisée n'est pas une métrique de perte appropriée.
Au lieu de cela, nous utiliserons la perte Viterbi qui, comme l'entropie croisée, est une "vraisemblance de journal négatif". Mais ici, nous mesurerons la probabilité de la séquence de balises en or (vraie), au lieu de la probabilité de la vraie étiquette à chaque mot de la séquence. Pour trouver la probabilité, nous considérons le softmax sur les scores de toutes les séquences de balises.
Le score d'une séquence de balises t est défini comme la somme des scores des balises individuelles.

Par exemple, considérez les scores CRF que nous avons examinés plus tôt -
Le score de la séquence de balise tag_2, tag_3, tag_3, <end> tag est la somme des valeurs en rouge, 4.85 + 6.79 + 3.85 + 3.52 = 19.01 .
La perte de viterbi est ensuite définie comme
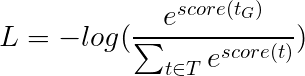
où t_G est la séquence de balises d'or et T représente l'espace de toutes les séquences de balises possibles.
Cela simplifie -
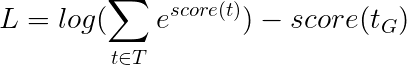
Par conséquent, la perte de Viterbi est la différence entre le log-sum-Exp des scores de toutes les séquences de balises possibles et le score de la séquence de balises d'or , IE log-sum-exp(all scores) - gold score .
Le décodage de viterbi est un moyen de construire la séquence de balises la plus optimale, compte tenu non seulement de la probabilité d'une étiquette sur un certain mot (scores d'émission), mais aussi de la probabilité d'une étiquette compte tenu des balises précédentes et suivantes (scores de transition).
Une fois que vous avez généré des scores CRF dans une matrice L, m, m pour une séquence de longueur L , nous commençons le décodage.
Le décodage de Viterbi est mieux compris avec un exemple. Considérez à nouveau -
Pour le premier mot de la séquence, le previous_tag ne peut être que <start> . Par conséquent, ne considérez qu'une seule ligne.
Ce sont également les scores cumulatifs pour chaque current_tag au premier mot.
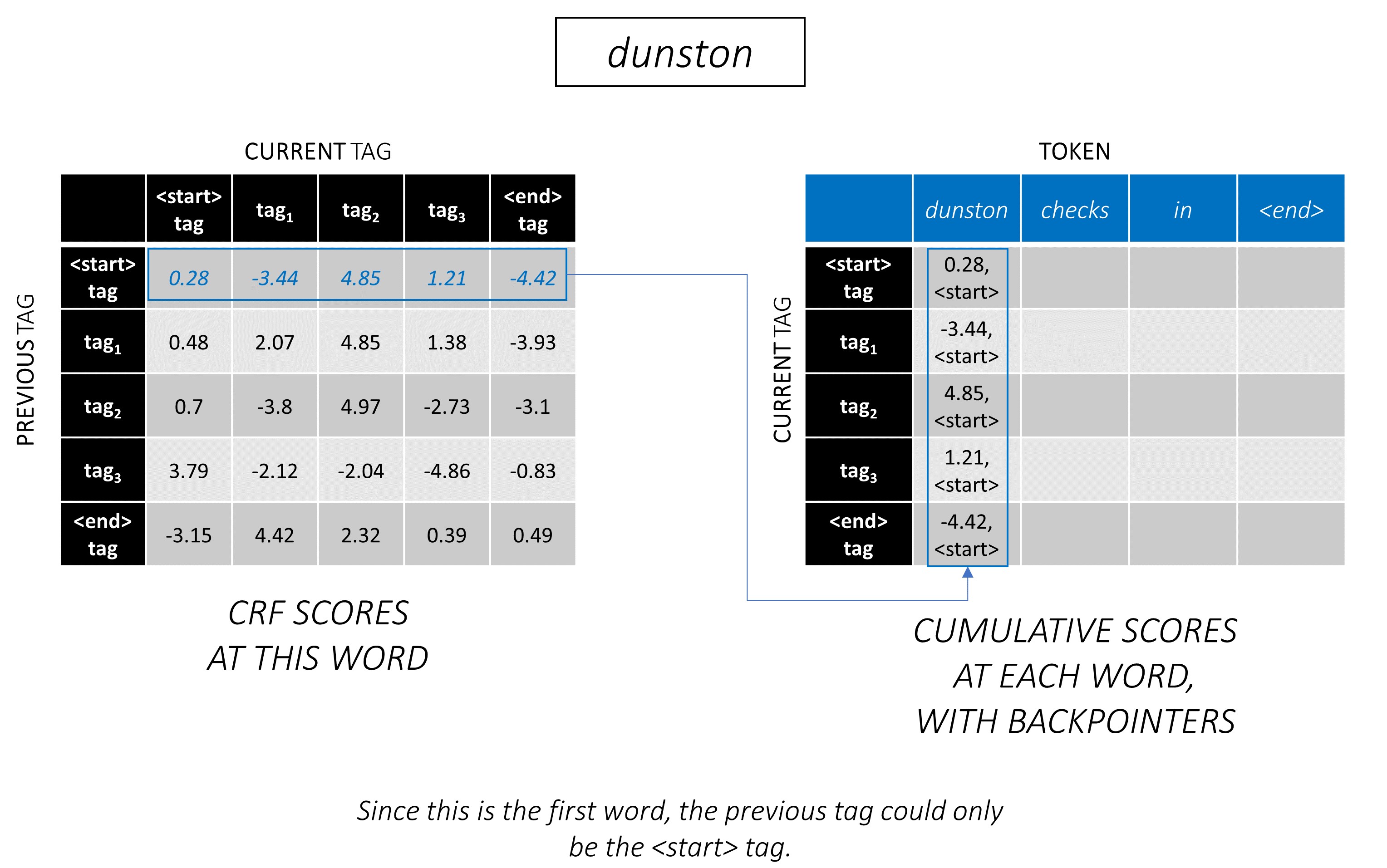
Nous garderons également une trace du previous_tag qui correspond à chaque score. Ceux-ci sont appelés carnets de retour . Au premier mot, ce sont évidemment toutes les balises <start> .
Au deuxième mot, ajoutez les scores cumulatifs précédents aux scores CRF de ce mot pour générer de nouveaux scores cumulatifs .
Notez que le premier mot current_tag s est le previous_tag du deuxième mot. Par conséquent, diffuser le score cumulatif du premier mot le long de la dimension current_tag .
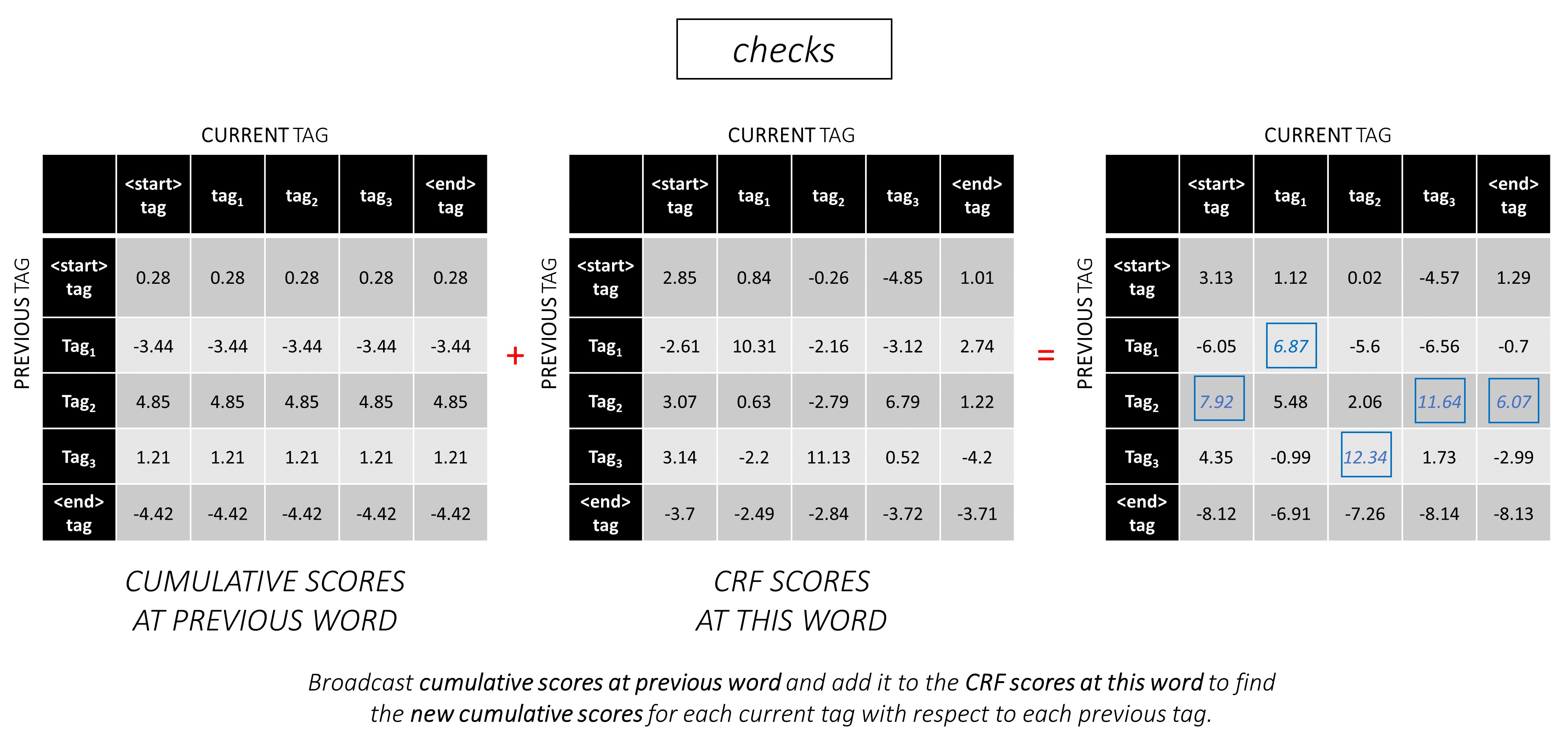
Pour chaque current_tag , considérez uniquement le maximum des scores de tous previous_tag s.
Stockez les roues à bord, c'est-à-dire les balises précédentes qui correspondent à ces scores maximaux.

Répétez ce processus au troisième mot.
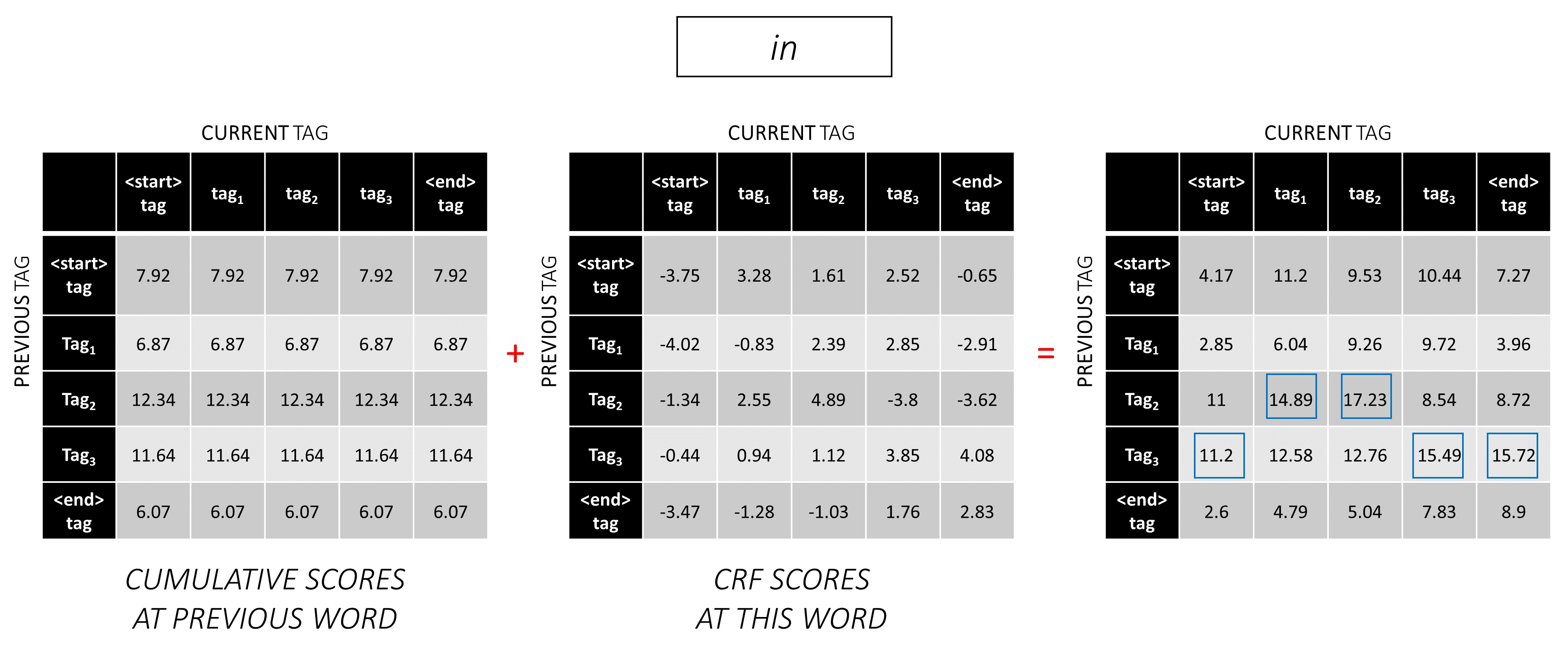
... et le dernier mot, qui est le <end> jeton.
Ici, la seule différence est que vous connaissez déjà la bonne balise. Vous avez besoin du score maximum et du sac à main uniquement pour la balise <end> .
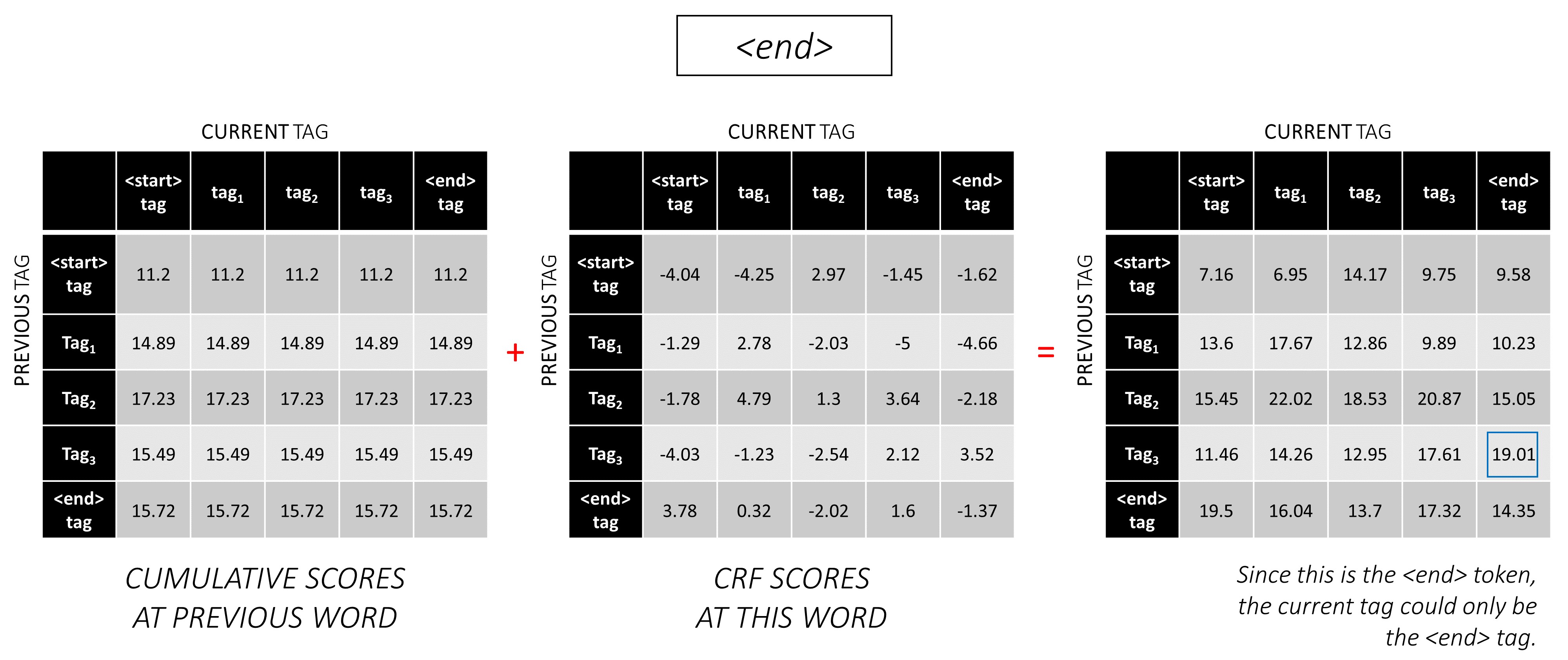
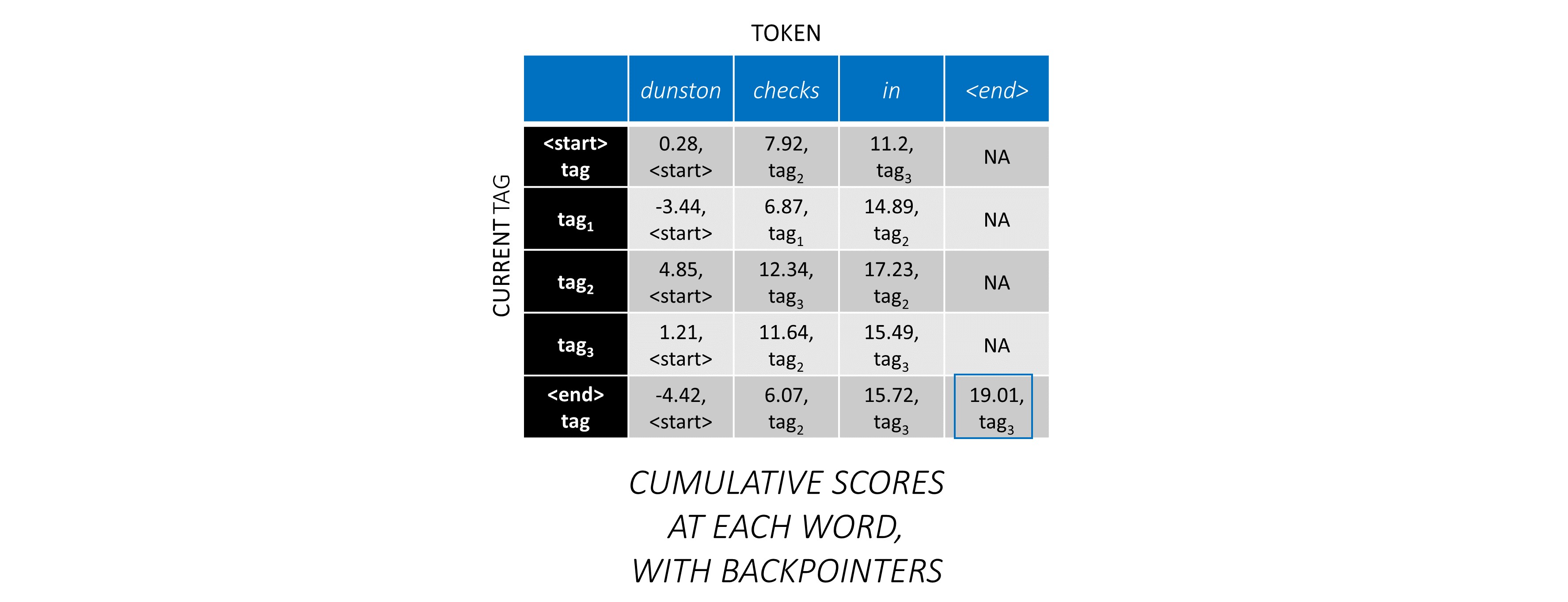
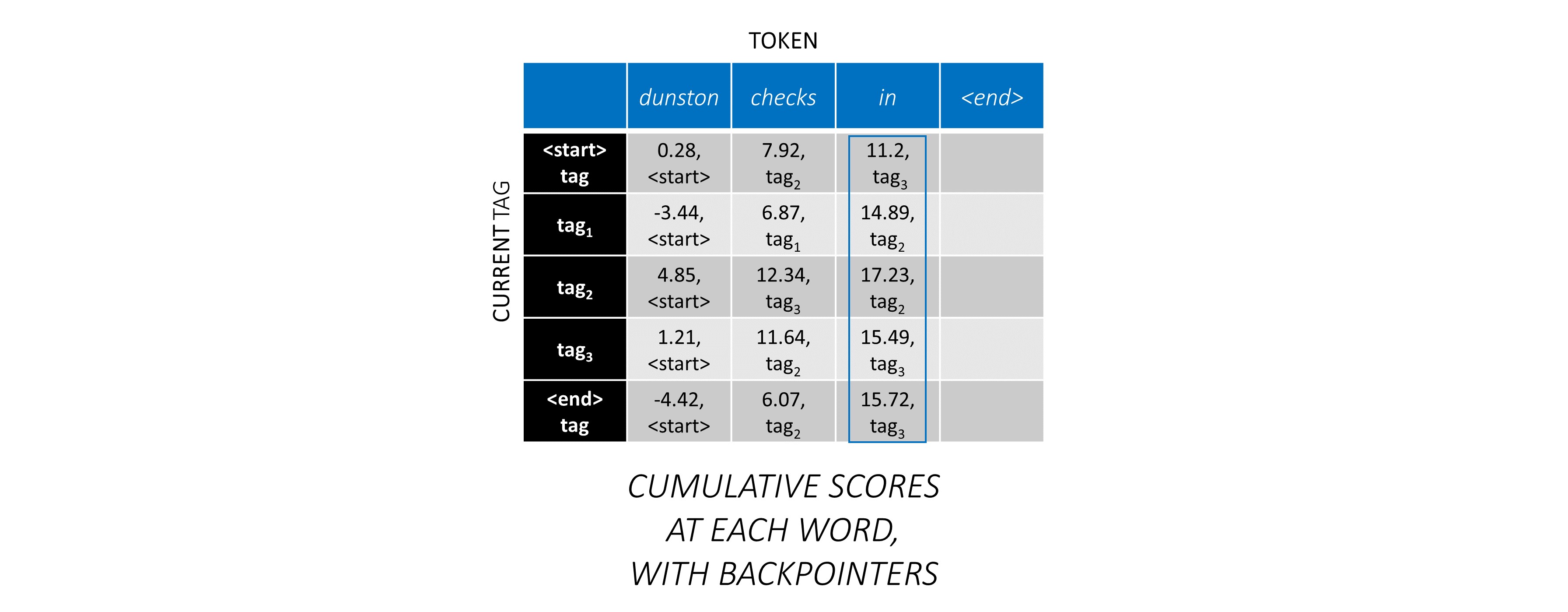
Maintenant que vous avez accumulé des scores CRF sur toute la séquence, vous tracez en arrière pour révéler la séquence de balises avec le score le plus élevé possible .
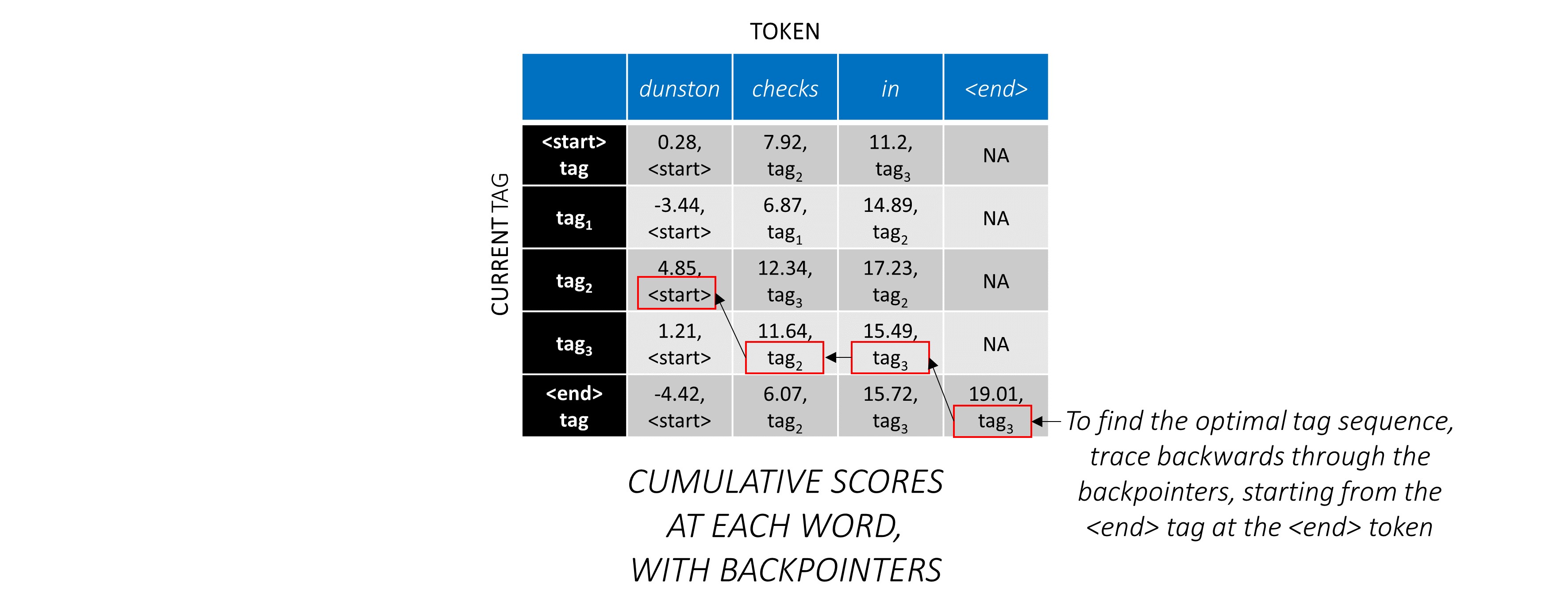
Nous constatons que la séquence de balises la plus optimale pour dunston checks in <end> est tag_2 tag_3 tag_3 <end> .
Les sections ci-dessous décrivent brièvement la mise en œuvre.
Ils sont censés fournir un certain contexte, mais les détails sont mieux compris directement à partir du code , qui est assez fortement commenté.
J'utilise l'ensemble de données CONLL 2003 NER pour comparer mes résultats avec le papier.
Voici un extrait -
-DOCSTART- -X- O O
EU NNP I-NP I-ORG
rejects VBZ I-VP O
German JJ I-NP I-MISC
call NN I-NP O
to TO I-VP O
boycott VB I-VP O
British JJ I-NP I-MISC
lamb NN I-NP O
. . O O
Cet ensemble de données n'est pas censé être distribué publiquement, bien que vous puissiez le trouver quelque part en ligne.
Il existe plusieurs ensembles de données publics en ligne que vous pouvez utiliser pour former le modèle. Ceux-ci ne sont peut-être pas tous annotés à 100%, mais ils sont suffisants.
Pour le marquage NER, vous pouvez utiliser la banque de sens Groningen.
Pour le marquage POS, NLTK dispose d'un petit ensemble de données, vous pouvez accéder à nltk.corpus.treebank.tagged_sents() .
Vous devrez soit le convertir au format de données CONLL 2003 NER, soit modifier le code référencé dans la section du pipeline de données.
Nous aurons besoin de huit entrées.
Ce sont les séquences de mots qui doivent être marquées.
dunston checks in
Comme discuté précédemment, nous n'utiliserons pas de jetons <start> mais nous devrons utiliser des jetons <end> .
dunston, checks, in, <end>
Puisque nous passons les phrases en tant que tenseurs de taille fixe, nous devons remplir des phrases (qui sont naturellement de longueur variable) à la même longueur avec les jetons <pad> .
dunston, checks, in, <end>, <pad>, <pad>, <pad>, ...
De plus, nous créons un word_map qui est un mappage d'index pour chaque mot dans le corpus, y compris les jetons <end> et <pad> . Pytorch, comme d'autres bibliothèques, a besoin de mots codés comme des indices pour rechercher des incorporations pour eux, ou pour identifier leur place dans les scores de mots prévus.
4381, 448, 185, 4669, 0, 0, 0, ...
Par conséquent, les séquences de mots alimentées au modèle doivent être un tenseur Int de dimensions N, L_w où N est le Batch_size et L_w est la longueur rembourrée des séquences de mots (généralement la longueur de la séquence de mots la plus longue).
Ce sont les séquences de caractères dans la direction avant.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' '
Nous avons besoin de jetons <end> dans les séquences de caractères pour correspondre au jeton <end> dans les séquences de mots. Étant donné que nous allons utiliser des fonctionnalités au niveau des caractéristiques à chaque mot de la séquence de mots, nous avons besoin de fonctionnalités au niveau des caractères à <end> dans la séquence de mots.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>
Nous devons également les remplir.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>, <pad>, <pad>, <pad>, ...
Et encodez-les avec un char_map .
29, 2, 12, 8, 7, 14, 12, 3, 6, 18, 1, 6, 21, 8, 3, 17, 12, 3, 60, 0, 0, 0, ...
Par conséquent, les séquences de caractères avant alimentées au modèle doivent être un tenseur Int de dimensions N, L_c , où L_c est la longueur rembourrée des séquences de caractères (généralement la longueur de la séquence de caractères la plus longue).
Cela serait traité de la même manière que la séquence avant, mais en arrière. (Les <end> jetons seraient toujours à la fin, naturellement.)
'n', 'i', ' ', 's', 'k', 'c', 'e', 'h', 'c', ' ', 'n', 'o', 't', 's', 'n', 'u', 'd', ' ', <end>, <pad>, <pad>, <pad>, ...
12, 17, 3, 8, 21, 6, 1, 18, 6, 3, 12, 14, 7, 8, 12, 2, 29, 3, 60, 0, 0, 0, ...
Par conséquent, les séquences de caractères arrière alimentées au modèle doivent être un tenseur Int de dimensions N, L_c .
Ces marqueurs sont des positions dans les séquences de caractères où nous extractons les fonctionnalités pour -
Nous extraire les fonctionnalités à la fin de chaque espace ' ' dans la séquence de caractères et au jeton <end> .
Pour la séquence de caractères avant, nous extraissons à -
7, 14, 17, 18
Ce sont des points après dunston , checks , in , <end> respectivement. Ainsi, nous avons un marqueur pour chaque mot de la séquence de mots , ce qui a du sens. (Dans les modèles de langue, cependant, puisque nous prédisons le mot suivant , nous ne prédirons pas au marqueur qui correspond à <end> .)
Nous les remplaçons avec 0 s. Peu importe ce que nous remplissons tant que ce sont des indices valides. (Nous allons extraire des fonctionnalités sur les coussinets, mais nous ne les utiliserons pas.)
7, 14, 17, 18, 0, 0, 0, ...
Ils sont rembourrés à la longueur rembourrée des séquences de mots, L_w .
Par conséquent, les marqueurs de caractères directs alimentés au modèle doivent être un tenseur Int de dimensions N, L_w .
Pour les marqueurs dans les séquences de caractère en arrière, nous trouvons également les positions de chaque espace ' ' et du <end> jeton.
Nous nous assurons également que ces positions sont dans le même ordre des mots que dans les marqueurs avant . Cet alignement facilite les fonctionnalités concaténées extraites des séquences de caractères avant et arrière, et empêche également de réorganiser les cibles dans les modèles de langue.
17, 9, 2, 18
Ce sont des points après notsnud , skcehc , ni , <end> respectivement.
Nous remplissons avec 0 s.
17, 9, 2, 18, 0, 0, 0, ...
Par conséquent, les marqueurs de caractères arrière alimentés au modèle doivent être un tenseur Int de dimensions N, L_w .
Supposons les bonnes balises pour dunston, checks, in, <end> sont -
tag_2, tag_3, tag_3, <end>
Nous avons un tag_map (contenant les balises <start> , tag_1 , tag_2 , tag_3 , <end> ).
Normalement, nous les coderions directement (avant le rembourrage) -
2, 3, 3, 5
Ce sont des encodages 1D , c'est-à-dire des positions de balises dans une carte de balise 1D .
Mais les sorties de la couche CRF sont des tenseurs 2D m, m à chaque mot. Nous aurions besoin de coder les positions de balise dans ces sorties 2D .
Les positions de balise correctes sont marquées en rouge.
(0, 2), (2, 3), (3, 3), (3, 4)
Si nous déroulons ces scores en un tenseur 1D m*m , alors les positions d'étiquette dans le tenseur déroulé seraient
tag_map [ previous_tag ] * len ( tag_map ) + tag_map [ current_tag ] Par conséquent, nous encodons tag_2, tag_3, tag_3, <end> comme
2, 13, 18, 19
Notez que vous pouvez récupérer les indices tag_map d'origine en prenant le module
t % len ( tag_map ) Ils seront rembourrés à la longueur rembourrée des séquences de mots, L_w .
Par conséquent, les balises fournies au modèle doivent être un tenseur Int de dimensions N, L_w .
Ce sont les longueurs réelles des séquences de mots, y compris les jetons <end> . Étant donné que Pytorch prend en charge les graphiques dynamiques, nous ne calculerons que sur ces longueurs et non sur les <pads> .
Par conséquent, les longueurs de mots fournies au modèle doivent être un tenseur Int de dimensions N .
Ce sont les longueurs réelles des séquences de caractères, y compris les jetons <end> . Étant donné que Pytorch prend en charge les graphiques dynamiques, nous ne calculerons que sur ces longueurs et non sur les <pads> .
Par conséquent, les longueurs de caractère alimentées au modèle doivent être un tenseur Int des dimensions N .
Voir read_words_tags() dans utils.py .
Cela lit les fichiers d'entrée au format Conll 2003 et extrait les séquences de mot et de balises.
Voir create_maps() dans utils.py .
Ici, nous créons des cartes d'encodage pour les mots, les caractères et les balises. We bin rare words and characters as <unk> s (unknowns).
Voir create_input_tensors() dans utils.py .
Nous générons les huit entrées détaillées dans la section des entrées à modèle.
Voir load_embeddings() dans utils.py .
Nous chargeons des incorporations pré-formées, avec la possibilité d'étendre le word_map pour inclure des mots hors ducorpus présents dans le vocabulaire d'intégration. Notez que cela peut également inclure de rares mots en corpus qui ont été regroupés comme <unk> plus tôt.
Voir WCDataset dans datasets.py .
Il s'agit d'une sous-classe de Dataset Pytorch. Il a besoin d'une méthode __len__ définie, qui renvoie la taille de l'ensemble de données et une méthode __getitem__ qui renvoie le jeu i th des huit entrées du modèle.
L' Dataset sera utilisé par un Pytorch DataLoader dans train.py pour créer et alimenter les lots de données au modèle de formation ou de validation.
Voir Highway dans models.py .
Une transformation est une transformation linéaire activée par relu de l'entrée. Une porte est une transformation linéaire activée par sigmoïde de l'entrée. Notez que les deux transformations doivent être de la même taille que l'entrée , pour permettre d'ajouter l'entrée dans une connexion résiduelle.
L'attribut num_layers Spécifie le nombre d'opérations de connexion de transform-gate-résiduel que nous effectuons en série. Habituellement, un seul est suffisant.
Nous stockons le nombre requis de couches de transformation et de porte dans ModuleList() distincts, et utilisons une boucle for boucle pour effectuer des opérations successives.
Voir LM_LSTM_CRF dans models.py .
Au tout début, nous trierons les séquences de caractères avant et arrière en diminuant les longueurs . Ceci est nécessaire pour utiliser pack_padded_sequence() afin que le LSTM puisse calculer uniquement les timelles valides, c'est-à-dire la véritable longueur des séquences.
N'oubliez pas de trier également tous les autres tenseurs dans le même ordre.
Voir dynamic_rnn.py pour une illustration de la façon dont pack_padded_sequence() peut être utilisé pour profiter des capacités graphiques dynamiques et de lots dynamiques de Pytorch afin que nous ne traitions pas les pads. Il aplatit les séquences triées par étapes horlogères tout en ignorant les pads, et le LSTM calcule uniquement la taille effective du lot N_t à chaque étalage .
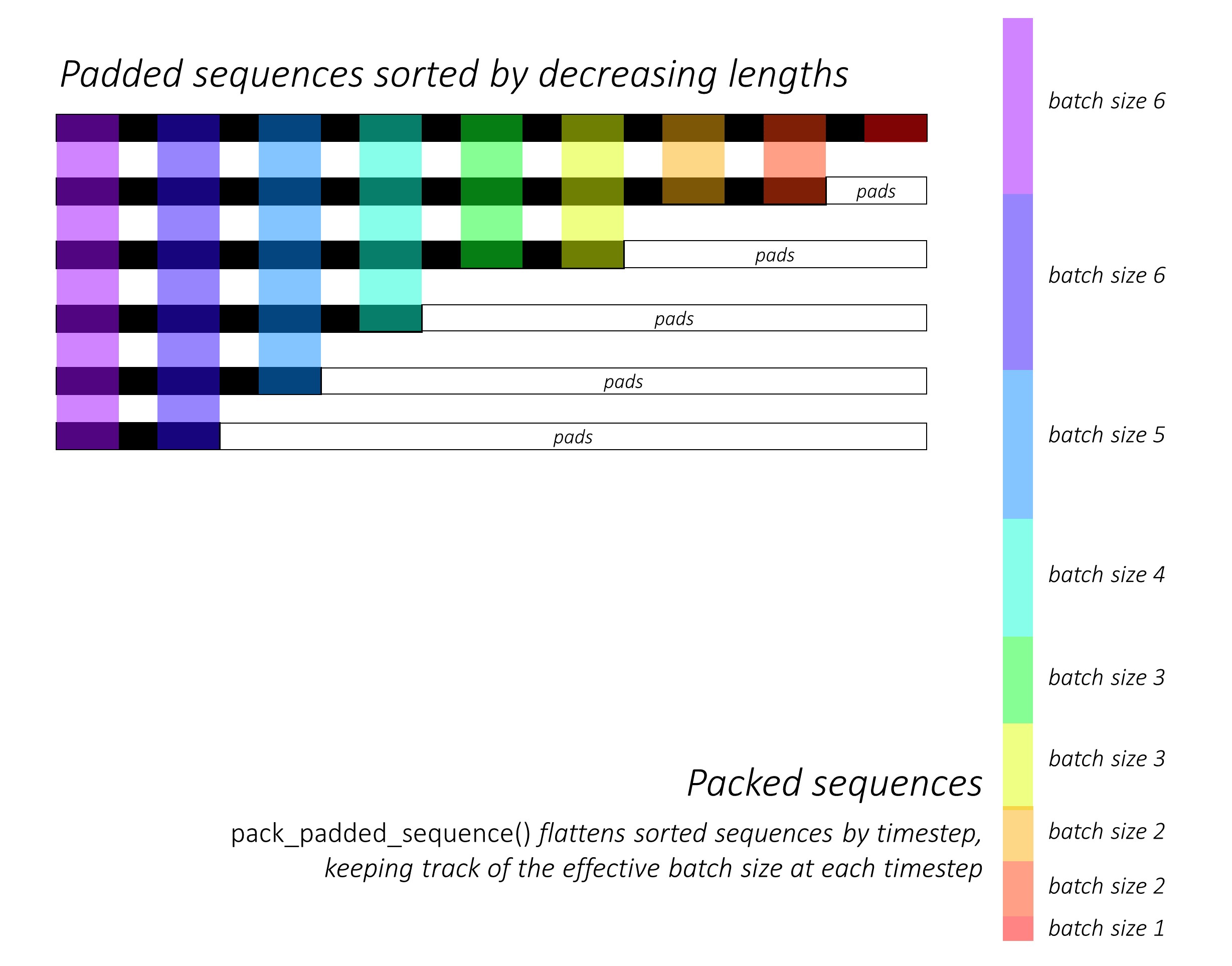
Le tri permet au N_t supérieur à n'importe quel étalage pour s'aligner sur les sorties de l'étape précédente . Au troisième temps, par exemple, nous ne traitons que les 5 meilleures images, en utilisant les 5 premières sorties de l'étape précédente. À l'exception du tri, tout cela est géré en interne par Pytorch, mais il est toujours très utile de comprendre ce que pack_padded_sequence() le fait pour que nous puissions l'utiliser dans d'autres scénarios pour atteindre des fins similaires. (Voir la question connexe sur la gestion des séquences de longueurs variables dans la section FAQ.)
Lors du tri, nous appliquons les LSTM vers l'avant et vers l'arrière sur les packed_sequences avant et vers l'arrière respectivement. Nous utilisons pad_packed_sequence() pour ne pas expliquer et re-pad les sorties.
Nous extraissons uniquement les sorties aux marqueurs de caractère avant et arrière avec gather . Cette fonction est très utile pour extraire uniquement certains indices d'un tenseur spécifié dans un tenseur séparé.
Ces sorties extraites sont traitées par les couches d'autoroute avant et arrière avant d'appliquer une couche linéaire pour calculer les scores sur le vocabulaire pour prédire le mot suivant à chaque marqueur. Nous ne le faisons que pendant la formation, car il n'a aucun sens d'effectuer une modélisation du langage pour l'apprentissage multi-tâches pendant la validation ou l'inférence. L'attribut training de tout modèle est défini avec model.train() ou model.eval() dans train.py . (Notez que cela est principalement utilisé pour activer ou désactiver le décrochage et les couches de norme par lots dans un modèle pytorch pendant la formation et l'inférence respectivement.)
Voir LM_LSTM_CRF dans models.py (suite).
Nous trierons également les séquences de mots en diminuant les longueurs , car il n'y a peut-être pas toujours de corrélation entre les longueurs des séquences de mots et les séquences de caractères.
N'oubliez pas de trier également tous les autres tenseurs dans le même ordre.
Nous concatenons les sorties LSTM de caractère avant et vers l'arrière sur les marqueurs et l'exécutons à travers la troisième couche routière . Cela extrait les informations de sous-mot à chaque mot que nous utiliserons pour l'étiquetage des séquences.
Nous concatenons ce résultat avec le mot incorporation et calculons les sorties BSTM sur le packed_sequence .
Lors du re-pading avec pad_packed_sequence() , nous avons les fonctionnalités dont nous avons besoin pour nourrir la couche CRF.
Voir CRF dans models.py .
Vous pouvez constater que cette couche est étonnamment simple compte tenu de la valeur qu'elle ajoute à notre modèle.
Une couche linéaire est utilisée pour transformer les sorties du BLSTM en scores pour chaque balise, qui sont les scores d'émission .
Un seul tenseur est utilisé pour maintenir les scores de transition . Ce tenseur est un Parameter du modèle, ce qui signifie qu'il est mis à jour pendant la rétropropagation, tout comme les poids des autres couches.
Pour trouver les scores CRF, calculez les scores d'émission à chaque mot et ajoutez-le aux scores de transition , après avoir diffusé les deux comme décrit dans la vue d'ensemble du CRF.
Voir ViterbiLoss dans models.py .
Nous avons établi dans la vue d'ensemble de la perte Viterbi que nous voulons minimiser la différence entre le log-sum-Exp des scores de toutes les séquences de balises valides possibles et le score de la séquence de balises d'or , c'est-à-dire log-sum-exp(all scores) - gold score .
Nous additionnons les scores CRF de chaque étiquette vraie comme décrit précédemment pour calculer le score d'or .
Rappelez-vous comment nous avons codé des séquences de balises avec leurs positions dans les scores CRF déroulés? Nous extractons les scores à ces positions avec gather() et éliminons les coussinets avec pack_padded_sequences() avant de résumer.
Trouver le log-sum-Exp des scores de toutes les séquences possibles est légèrement plus délicat. Nous utilisons une for pour itérater sur les horaires. À chaque pas de temps, nous accumuons des scores pour chaque current_tag par -
current_tag pour chaque previous_tag . Nous le faisons uniquement à la taille efficace du lot, c'est-à-dire pour les séquences qui ne sont pas encore terminées. (Nos séquences sont toujours triées en diminuant les longueurs des mots, à partir du modèle LM-LSTM-CRF .)current_tag , calculez le log-sum-Exp sur le previous_tag s pour trouver les nouveaux scores accumulés sur chaque current_tag . Après avoir calculé sur les longueurs variables de toutes les séquences, nous nous retrouvons avec un tenseur de dimensions N, m , où m est le nombre de balises (de courant). Ce sont les scores accumulés log-sum-Exp sur toutes les séquences possibles se terminant dans chacune des m tags. Cependant, comme les séquences valides ne peuvent se terminer qu'avec la balise <end> , résume uniquement la colonne <end> pour trouver le log-sum-Exp des scores de toutes les séquences valides possibles .
Nous trouvons la différence, log-sum-exp(all scores) - gold score .
Voir ViterbiDecoder dans inference.py .
Cela met en œuvre le processus décrit dans la vue d'ensemble du décodage Viterbi.
Nous accumulons les scores dans une for pour une manière similaire à ce que nous avons fait dans ViterbiLoss , sauf ici que nous trouvons le maximum des scores previous_tag pour chaque current_tag , au lieu de calculer le log-sum-exp. Nous gardons également une trace du previous_tag qui correspond à ce score maximal dans un tenseur de routoir.
Nous remplissons le tenseur du routoir avec des balises <end> car cela nous permet de retracer vers l'arrière sur les coussinets, arrivant finalement à la balise <end> réelle , après quoi le backtracage réel commence.
Voir train.py .
Les paramètres du modèle (et la formation) sont au début du fichier, vous pouvez donc facilement les vérifier ou les modifier si vous le souhaitez.
Pour former votre modèle à partir de zéro , exécutez simplement ce fichier -
python train.py
Pour reprendre la formation à un point de contrôle , indiquez le fichier correspondant avec le paramètre de checkpoint au début du code.
Notez que nous effectuons la validation à la fin de chaque époque d'entraînement.
Vous remarquerez que nous coupez les entrées à chaque lot aux longueurs de séquence maximale de ce lot . C'est ainsi que nous n'avons pas plus de pads dans chaque lot dont nous avons réellement besoin.
Mais pourquoi? Bien que les RNN de notre modèle ne calculent pas les coussinets, les couches linéaires le font toujours . Il est assez direct de changer cela - voir la question connexe sur la gestion des séquences de longueurs variables dans la section FAQS.
Pour ce tutoriel, j'ai pensé qu'un peu de calcul supplémentaire sur certains pads valait la simplicité de ne pas avoir à effectuer une multitude d'opérations - autoroute, CRF, autres couches linéaires, concaténations - sur une packed_sequence .
Dans le scénario multi-tâches, nous avons choisi de résumer les pertes d'entropie croisée des deux tâches de modélisation de la langue et la perte Viterbi de la tâche d'étiquetage de séquence.
Même si nous minimisons la somme de ces pertes , nous ne souhaitons en fait que minimiser la perte de Viterbi en vertu de la minimisation de la somme de ces pertes . C'est la perte Viterbi qui reflète les performances de la tâche principale.
Nous utilisons pack_padded_sequence() pour éliminer les pads partout où nécessaire.
Comme dans le journal, nous utilisons le score F1 à moyens macroérés comme critère pour le début . Naturellement, le calcul du score F1 nécessite un décodage de viterbi les scores CRF pour générer nos séquences de balises optimales.
Nous utilisons pack_padded_sequence() pour éliminer les pads partout où nécessaire.
J'ai suivi les paramètres de l'implémentation des auteurs aussi étroitement que possible.
J'ai utilisé une taille de lot de 10 phrases. J'ai utilisé une descente de gradient stochastique avec un élan. Le taux d'apprentissage a été décomposé à chaque époque. J'ai utilisé des incorporations pré-entraînées au gant 100D sans réglage fin.
Il a fallu environ 80 pour entraîner une époque sur un Titan X (Pascal).
Le score F1 sur l'ensemble de validation a atteint 91% autour de l'époque 50 et a culminé à 91.6% sur l'époque 171. Je l'ai exécuté pour un total de 200 époques. Ceci est assez proche des résultats du papier.
Vous pouvez télécharger ce modèle pré-entraîné ici.
Comment décidons-nous si nous avons besoin de jetons <start> et <end> pour un modèle qui utilise des séquences?
Si cela semble déroutant au début, cela se résoudra facilement lorsque vous réfléchissez aux exigences du modèle que vous prévoyez de vous entraîner.
Pour l'étiquetage des séquences avec un CRF, vous avez besoin du jeton <end> ( ou du jeton <start> ; voir la question suivante) en raison de la structure des scores CRF.
Dans mon autre tutoriel sur le sous-titrage de l'image, j'ai utilisé les jetons <start> et <end> . Le modèle devait commencer à décoder quelque part et apprendre à reconnaître quand arrêter le décodage pendant l'inférence.
Si vous effectuez une classification de texte, vous n'auriez pas besoin de non.
Pouvons-nous avoir le CRF générer des scores current_word -> next_word au lieu des scores previous_word -> current_word ?
Oui. Dans ce cas, vous diffuriez les scores d'émission comme L, m, _ , et vous auriez un jeton <start> dans chaque phrase au lieu d'un <end> jeton. La balise correcte du jeton <start> serait toujours la balise <start> . La "balise suivante" du dernier mot serait toujours la balise <end> .
Je pense que le previous word -> current word est légèrement meilleure car il existe des modèles de langage dans le mix. Il s'intègre très bien pour être en mesure de prédire le <end> jeton au dernier véritable mot, et donc d'apprendre à reconnaître quand une phrase est terminée.
Pourquoi utilisons-nous des vocabulaires différents pour les entrées du tagger de séquence et les sorties des modèles de langage?
Les modèles de langue apprendront à prédire uniquement les mots qu'il a vus pendant la formation. Il est vraiment inutile, et un énorme gaspillage de calcul et de mémoire, d'utiliser une couche linéaire-SoftMax avec les mots supplémentaires de ~ 400 000 mots hors ducorpus du fichier d'incorporation qu'il n'apprendra jamais à prédire.
Mais nous pouvons ajouter ces mots à la couche d'entrée même si le modèle ne les voit jamais pendant la formation. En effet, nous utilisons des intérêts pré-formés à l'entrée. Il n'a pas besoin de les voir parce que les significations des mots sont codées dans ces vecteurs. S'il a déjà rencontré un chimpanzee , il sait très probablement quoi faire avec un orangutan .
Est-ce une bonne idée d'affiner les incorporations de mots pré-formées que nous utilisons dans ce modèle?
Je m'abstiens de régler les ajustements car la majeure partie du vocabulaire d'entrée n'est pas en corpus. Most embeddings will remain the same while a few are fine-tuned. If fine-tuning changes these embeddings sufficiently, the model may not work well with the words that weren't fine-tuned. In the real world, we're bound to encounter many words that weren't present in a newspaper corpus from 2003.
What are some ways we can construct dynamic graphs in PyTorch to compute over only the true lengths of sequences?
If you're using an RNN, simply use pack_padded_sequence() . PyTorch will internally compute over only the true lengths. See dynamic_rnn.py for an example.
If you want to execute an operation (like a linear transformation) only on the true timesteps, pack_padded_sequences() is still the way to go. This flattens the tensor by timestep while removing the pads. You can perform your operation on this flattened tensor, and then use pad_packed_sequence() to unflatten it and re-pad it with 0 s.
Similarly, if you want to perform an aggregation operation, like computing the loss, use pack_padded_sequences() to eliminate the pads.
If you want to perform timestep-wise operations, you can take a leaf out of how pack_padded_sequences() works, and compute only on the effective batch size at each timestep with a for loop to iterate over the timesteps. We did this in the ViterbiLoss and ViterbiDecoder . I also used an LSTMCell() in this fashion in my image captioning tutorial.
Dunston Checks In ? Vraiment?
I had no memory of this movie for twenty years. I was trying to think of a short sentence that would be easier to visualize in this tutorial and it just popped into my mind riding a wave of 90s nostalgia.

I wish I hadn't googled it though. Damn, the critics were harsh, weren't they? This gem was overwhelmingly and universally panned. I'm not sure I'd disagree if I watched it now, but that just goes to show the world is so much more fun when you're a kid.
Didn't have to worry about LM-LSTM-CRFs or nuthin...


