a PyTorch Tutorial to Sequence Labeling
1.0.0
นี่คือ การสอน pytorch เพื่อการติดฉลากลำดับ
นี่เป็นครั้งที่สองในชุดของบทเรียนที่ฉันเขียนเกี่ยวกับ การใช้ โมเดลที่ยอดเยี่ยมด้วยตัวคุณเองด้วยห้องสมุด Pytorch ที่น่าตื่นตาตื่นใจ
ความรู้พื้นฐานของ pytorch เครือข่ายประสาทที่เกิดขึ้นซ้ำจะถือว่า
หากคุณยังใหม่กับ Pytorch ก่อนอื่นให้อ่านการเรียนรู้อย่างลึกซึ้งกับ Pytorch: Blitz 60 นาทีและการเรียนรู้ Pytorch พร้อมตัวอย่าง
คำถามคำแนะนำหรือการแก้ไขสามารถโพสต์เป็นปัญหา
ฉันใช้ PyTorch 0.4 ใน Python 3.6
27 ม.ค. 2020 : มีการเพิ่มรหัสการทำงานสำหรับสองบทเรียนใหม่-การแปลความละเอียดสูงและการแปลของเครื่อง
วัตถุประสงค์
แนวคิด
ภาพรวม
การดำเนินการ
การฝึกอบรม
คำถามที่พบบ่อย
เพื่อสร้างแบบจำลองที่สามารถติดแท็กแต่ละคำในประโยคที่มีเอนทิตีส่วนของการพูด ฯลฯ

เราจะใช้ การติดฉลากลำดับ Empower ด้วยกระดาษแบบจำลองภาษาประสาทที่รับรู้ นี่เป็นความก้าวหน้ามากกว่าโมเดลการติดแท็กลำดับส่วนใหญ่ แต่คุณจะได้เรียนรู้แนวคิดที่มีประโยชน์มากมาย - และใช้งานได้ดีมาก การใช้งานดั้งเดิมของผู้เขียนสามารถพบได้ที่นี่
โมเดลนี้มีความพิเศษเพราะจะเพิ่มงานการติดฉลากลำดับโดยการฝึกอบรม พร้อม กับแบบจำลองภาษา
การติดฉลากลำดับ DUH.
แบบจำลองภาษา การสร้างแบบจำลองภาษาคือการทำนายคำหรือตัวละครถัดไปในลำดับของคำหรือตัวละคร แบบจำลองภาษาประสาทได้รับผลลัพธ์ที่น่าประทับใจในงาน NLP ที่หลากหลายเช่นการสร้างข้อความการแปลด้วยเครื่องภาพคำบรรยายภาพการจดจำตัวละครแบบออพติคอลและสิ่งที่คุณมี
ตัวละคร rnns RNNs ที่ทำงานกับตัวละครแต่ละตัวในข้อความเป็นที่รู้จักกันในการจับสไตล์และโครงสร้างพื้นฐาน ในงานการติดฉลากลำดับพวกเขามีประโยชน์อย่างยิ่งเนื่องจากข้อมูลคำย่อยมักจะให้เบาะแสสำคัญต่อเอนทิตีหรือแท็ก
การเรียนรู้แบบหลายงาน ชุดข้อมูลที่มีอยู่ในการฝึกอบรมแบบจำลองมักจะเล็ก การสร้างคำอธิบายประกอบหรือคุณสมบัติที่ทำด้วยมือเพื่อช่วยโมเดลของคุณไม่เพียง แต่ยุ่งยาก แต่ยังไม่สามารถปรับให้เข้ากับโดเมนหรือการตั้งค่าที่หลากหลายซึ่งโมเดลของคุณอาจมีประโยชน์ การติดฉลากลำดับน่าเสียดายที่เป็นตัวอย่างสำคัญ มีวิธีลดปัญหานี้ - ร่วมกันฝึกอบรมหลายรุ่นที่เข้าร่วมที่สะโพกจะเพิ่มข้อมูลให้กับแต่ละรุ่นสูงสุดเพื่อปรับปรุงประสิทธิภาพ
เขตข้อมูลแบบสุ่มแบบมีเงื่อนไข ตัวแยกประเภทที่ไม่ต่อเนื่องทำนายชั้นเรียนหรือฉลากเป็นคำ เขตข้อมูลแบบสุ่มแบบมีเงื่อนไข (CRFs) สามารถทำได้ดีกว่า - พวกเขาทำนายฉลากตามคำไม่เพียง แต่ยังเป็นพื้นที่ใกล้เคียง ซึ่งสมเหตุสมผลเพราะ มี รูปแบบในลำดับของเอนทิตีหรือฉลาก CRFs ใช้กันอย่างแพร่หลายในการจำลองข้อมูลที่สั่งซื้อไม่ว่าจะเป็นสำหรับการติดฉลากลำดับการจัดลำดับยีนหรือแม้แต่การตรวจจับวัตถุและการแบ่งส่วนภาพในการมองเห็นคอมพิวเตอร์
การถอดรหัส Viterbi เนื่องจากเราใช้ CRFs เราไม่ได้ทำนายฉลากที่เหมาะสมมากนักในแต่ละคำในขณะที่เราทำนาย ลำดับ ฉลากที่เหมาะสมสำหรับลำดับคำ การถอดรหัส Viterbi เป็นวิธีการทำสิ่งนี้อย่างแน่นอน - ค้นหาลำดับแท็กที่ดีที่สุดจากคะแนนที่คำนวณโดยฟิลด์แบบสุ่มแบบมีเงื่อนไข
เครือข่ายทางหลวง เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์เป็นวัตถุดิบในเครือข่ายประสาทใด ๆ เพื่อแปลงหรือแยกคุณลักษณะในสถานที่ต่าง ๆ เครือข่ายทางหลวงทำสิ่งนี้ให้สำเร็จ แต่ยังอนุญาตให้ข้อมูลไหลผ่านการเปลี่ยนแปลงที่ไม่มีการเปลี่ยนแปลง สิ่งนี้ทำให้เครือข่ายลึกมีประสิทธิภาพหรือเป็นไปได้มากขึ้น
ในส่วนนี้ฉันจะนำเสนอภาพรวมของรุ่นนี้ หากคุณคุ้นเคยกับมันแล้วคุณสามารถข้ามไปยังส่วนการใช้งานหรือรหัสความคิดเห็นได้โดยตรง
ผู้เขียนอ้างถึงโมเดลเป็น แบบจำลองภาษา - หน่วยความจำระยะสั้นระยะยาว - ฟิลด์สุ่มแบบมีเงื่อนไข เนื่องจากเกี่ยวข้องกับ แบบจำลองภาษาการฝึกอบรมร่วมกับการรวมกันของ LSTM + CRF
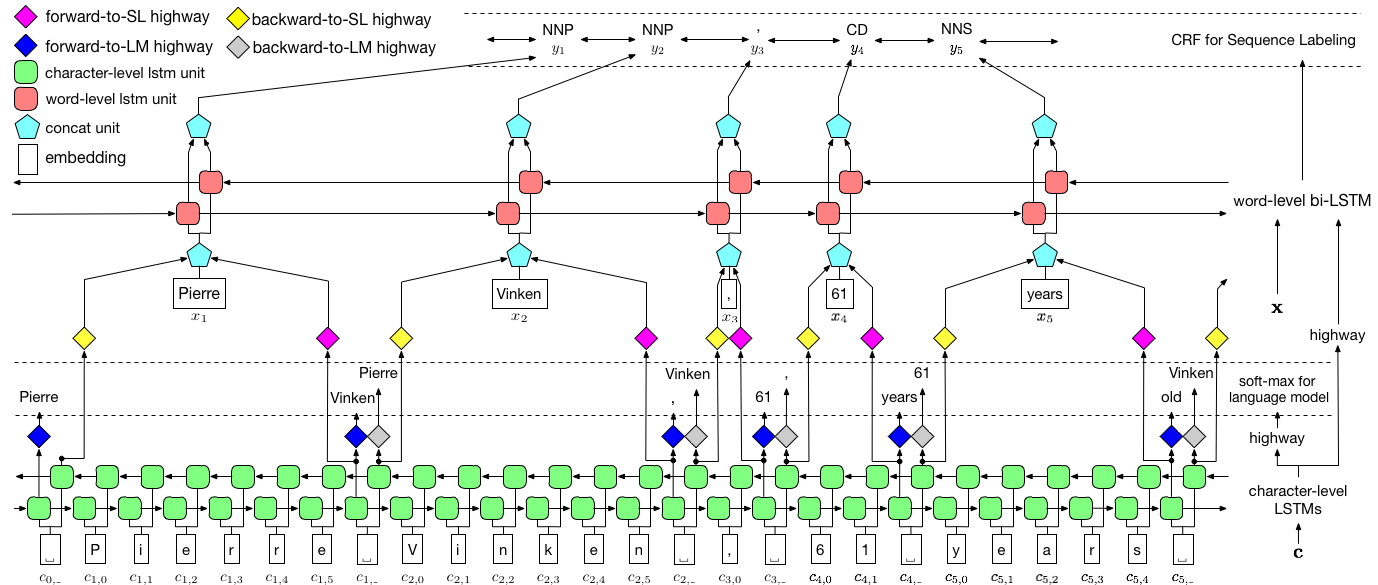
ภาพนี้จากกระดาษแสดงให้เห็นถึงทั้งรุ่นทั้งหมด แต่ไม่ต้องกังวลว่ามันจะซับซ้อนเกินไปในเวลานี้ เราจะทำลายมันเพื่อดูส่วนประกอบอย่างใกล้ชิด
การเรียนรู้แบบหลายงานคือเมื่อคุณฝึกอบรมแบบจำลองในสองงานขึ้นไป
โดยปกติแล้วเราจะสนใจเพียง หนึ่ง ในงานเหล่านี้เท่านั้น - ในกรณีนี้การติดฉลากลำดับ
แต่เมื่อเลเยอร์ในเครือข่ายประสาทมีส่วนช่วยในการทำหน้าที่หลายฟังก์ชั่นพวกเขาเรียนรู้มากกว่าที่พวกเขาจะได้รับหากพวกเขาได้รับการฝึกฝนเฉพาะในงานหลัก นี่เป็นเพราะข้อมูลที่สกัดในแต่ละเลเยอร์ถูกขยายเพื่อรองรับงานทั้งหมด เมื่อมีข้อมูลเพิ่มเติมที่จะทำงานด้วย ประสิทธิภาพในงานหลักจะได้รับการปรับปรุง
การเพิ่มคุณสมบัติคุณสมบัติที่มีอยู่ในลักษณะนี้จะช่วยขจัดความจำเป็นในการใช้คุณสมบัติที่ทำด้วยมือสำหรับการติดฉลากลำดับ
การสูญเสียทั้งหมด ในระหว่างการเรียนรู้แบบหลายงานมักจะเป็นการรวมกันเชิงเส้นของการสูญเสียในงานแต่ละงาน พารามิเตอร์ของชุดค่าผสมสามารถแก้ไขหรือเรียนรู้ได้ว่าเป็นน้ำหนักที่อัปเดตได้

เนื่องจากเรากำลังรวมการสูญเสียของแต่ละบุคคลคุณสามารถดูว่าเลเยอร์ต้นน้ำที่ใช้ร่วมกันโดยงานหลายรายการจะได้รับการอัปเดตจากทั้งหมดในระหว่างการ backpropagation
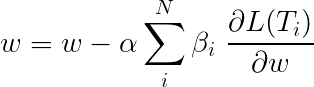
ผู้เขียนกระดาษ เพียงเพิ่มการสูญเสีย ( β=1 ) และเราจะทำเช่นเดียวกัน
มาดูงานที่ประกอบขึ้นเป็นแบบจำลองของเรา
มี สาม

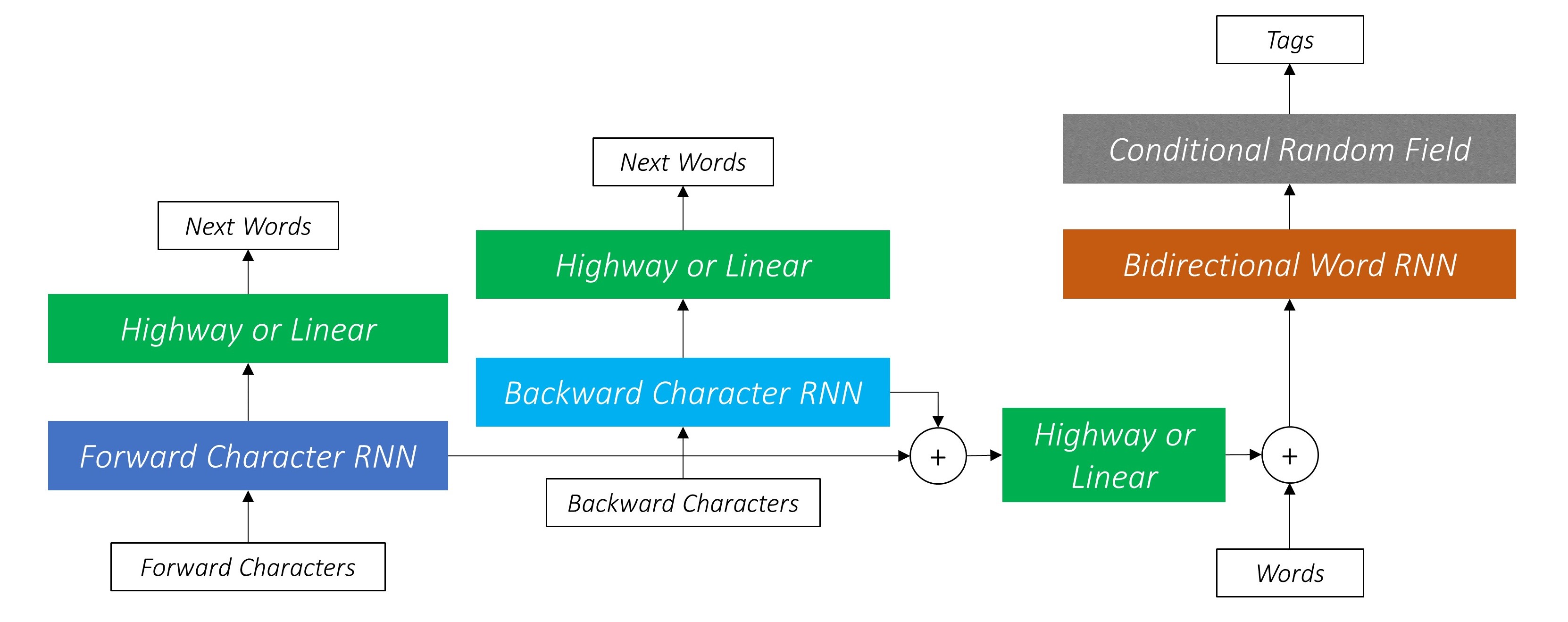
สิ่งนี้ใช้ประโยชน์จากข้อมูลคำย่อยเพื่อทำนายคำต่อไป
เราทำเช่นเดียวกันในทิศทางย้อนหลัง 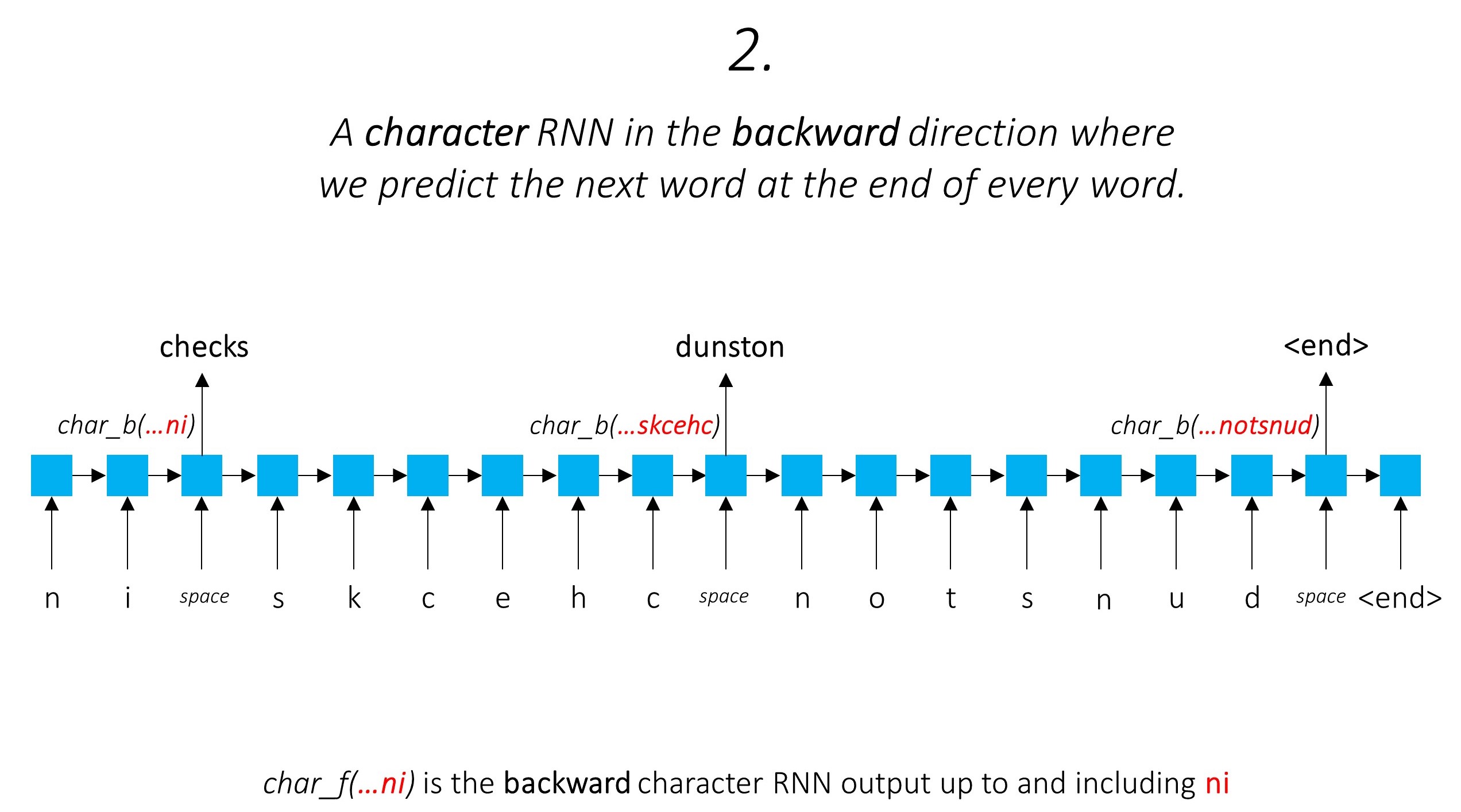
นอกจากนี้เรา ยัง ใช้เอาต์พุตของ อักขระ สองตัวนี้เป็นอินพุตไปยัง Word-RNN ของเราและ ฟิลด์สุ่มแบบมีเงื่อนไข (CRF) เพื่อดำเนินการหลักของการติดฉลากลำดับของเรา 
เรากำลังใช้ข้อมูลคำย่อยในงานการติดแท็กของเราเพราะมันอาจเป็นตัวบ่งชี้ที่ทรงพลังของแท็กไม่ว่าจะเป็นส่วนหนึ่งของคำพูดหรือเอนทิตี ตัวอย่างเช่นอาจเรียนรู้ว่าคำคุณศัพท์มักจะจบลงด้วย "-y" หรือ "-ul" หรือสถานที่นั้นมักจะจบลงด้วย "-land" หรือ "-burg"
แต่คุณสมบัติย่อยของเรา ได้แก่ ผลลัพธ์ของตัวละคร RNNs นั้นได้รับการเสริมด้วยข้อมูล เพิ่มเติม - ความรู้ที่จำเป็นในการทำนายคำต่อไปทั้งในทิศทางไปข้างหน้าและข้างหลังเนื่องจากโมเดล 1 และ 2
ดังนั้นรูปแบบการติดแท็กลำดับของเราจึงใช้ทั้งสองอย่าง
LSTM/RNN แบบสองทิศทางเข้ารหัสคุณสมบัติเหล่านี้เป็นคุณสมบัติใหม่ในแต่ละคำที่มีข้อมูลเกี่ยวกับคำและพื้นที่ใกล้เคียงทั้งในระดับคำและระดับตัวละคร สิ่งนี้สร้างอินพุตไปยังฟิลด์สุ่มแบบมีเงื่อนไข
หากไม่มี CRF เราจะใช้เลเยอร์เชิงเส้นเดียวเพื่อแปลงเอาต์พุตของ LSTM แบบสองทิศทางเป็นคะแนนสำหรับแต่ละแท็ก สิ่งเหล่านี้เรียกว่า คะแนนการปล่อย ซึ่งเป็นตัวแทนของความน่าจะเป็นของคำว่าเป็นแท็กที่แน่นอน
CRF ไม่เพียง แต่คำนวณคะแนนการปล่อยมลพิษ แต่ยังรวมถึง คะแนนการเปลี่ยนแปลง ซึ่งเป็นโอกาสของคำที่เป็นแท็กที่แน่นอน เมื่อพิจารณา คำก่อนหน้านี้เป็นแท็กที่แน่นอน ดังนั้นคะแนนการเปลี่ยนแปลงจึงวัดว่ามันมีแนวโน้มที่จะเปลี่ยนจากแท็กหนึ่งไปอีกแท็กหนึ่ง
หากมีแท็ก m คะแนนการเปลี่ยนแปลงจะถูกเก็บไว้ในเมทริกซ์ของ Dimesions m, m โดยที่แถวแสดงแท็กของคำก่อนหน้าและคอลัมน์แสดงถึงแท็กของคำปัจจุบัน ค่าในเมทริกซ์นี้ที่ตำแหน่ง i, j คือ ความเป็นไปได้ที่จะเปลี่ยนจากแท็ก i th ที่คำก่อนหน้าเป็นแท็ก j th ที่คำปัจจุบัน ไม่ได้กำหนดคะแนนการเปลี่ยนแปลงคะแนนการเปลี่ยนแปลงไม่ได้ถูกกำหนดไว้สำหรับแต่ละคำในประโยค พวกเขาเป็นระดับโลก
ในโมเดลของเราเลเยอร์ CRF จะส่งผล รวมของคะแนนการปล่อยและการเปลี่ยนแปลงในแต่ละคำ
สำหรับประโยคความยาว L คะแนนการปล่อยจะเป็น L, m Tensor เนื่องจากคะแนนการปล่อยในแต่ละคำไม่ได้ขึ้นอยู่กับแท็กของคำก่อนหน้านี้เราจึงสร้างมิติใหม่เช่น L, _, m และออกอากาศ (คัดลอก) เทนเซอร์ตามทิศทางนี้เพื่อรับ L, m, m Tensor
คะแนนการเปลี่ยนแปลงคือ m, m Tensor เนื่องจากคะแนนการเปลี่ยนแปลงเป็นระดับโลกและไม่ได้ขึ้นอยู่กับคำเราจึงสร้างมิติใหม่เช่น _, m, m และออกอากาศ (คัดลอก) เทนเซอร์ไปตามทิศทางนี้เพื่อรับ L, m, m Tensor
ตอนนี้เราสามารถ เพิ่มพวกเขาเพื่อให้ได้คะแนนรวมซึ่งเป็นเทนเซอร์ L, m, m ค่าที่ตำแหน่ง k, i, j คือ การรวม ของคะแนนการปล่อยของแท็ก j th ที่ k th word และคะแนนการเปลี่ยนแปลงของแท็ก j th ที่คำ k th เมื่อพิจารณาคำก่อนหน้านี้คือแท็ก i th
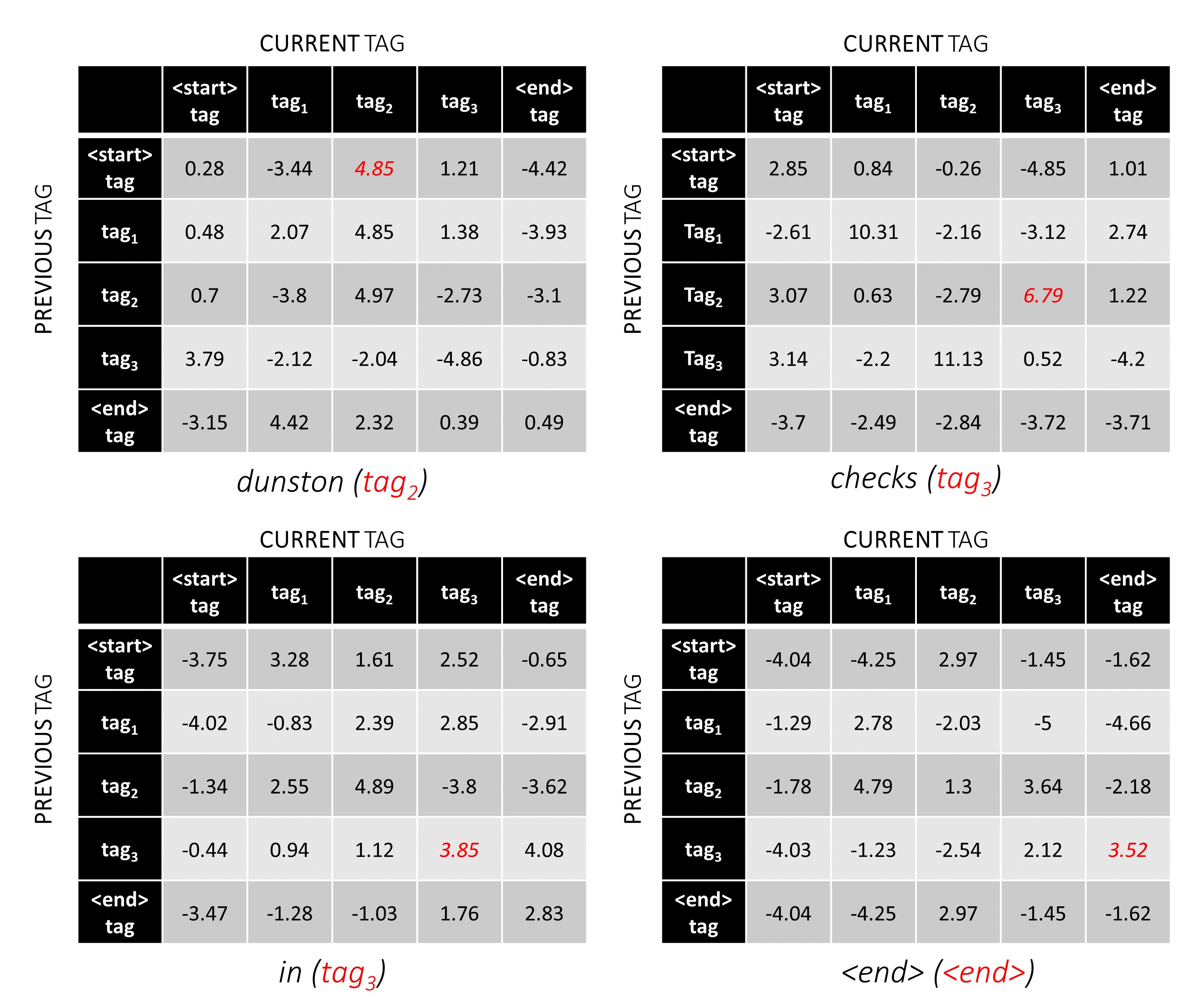
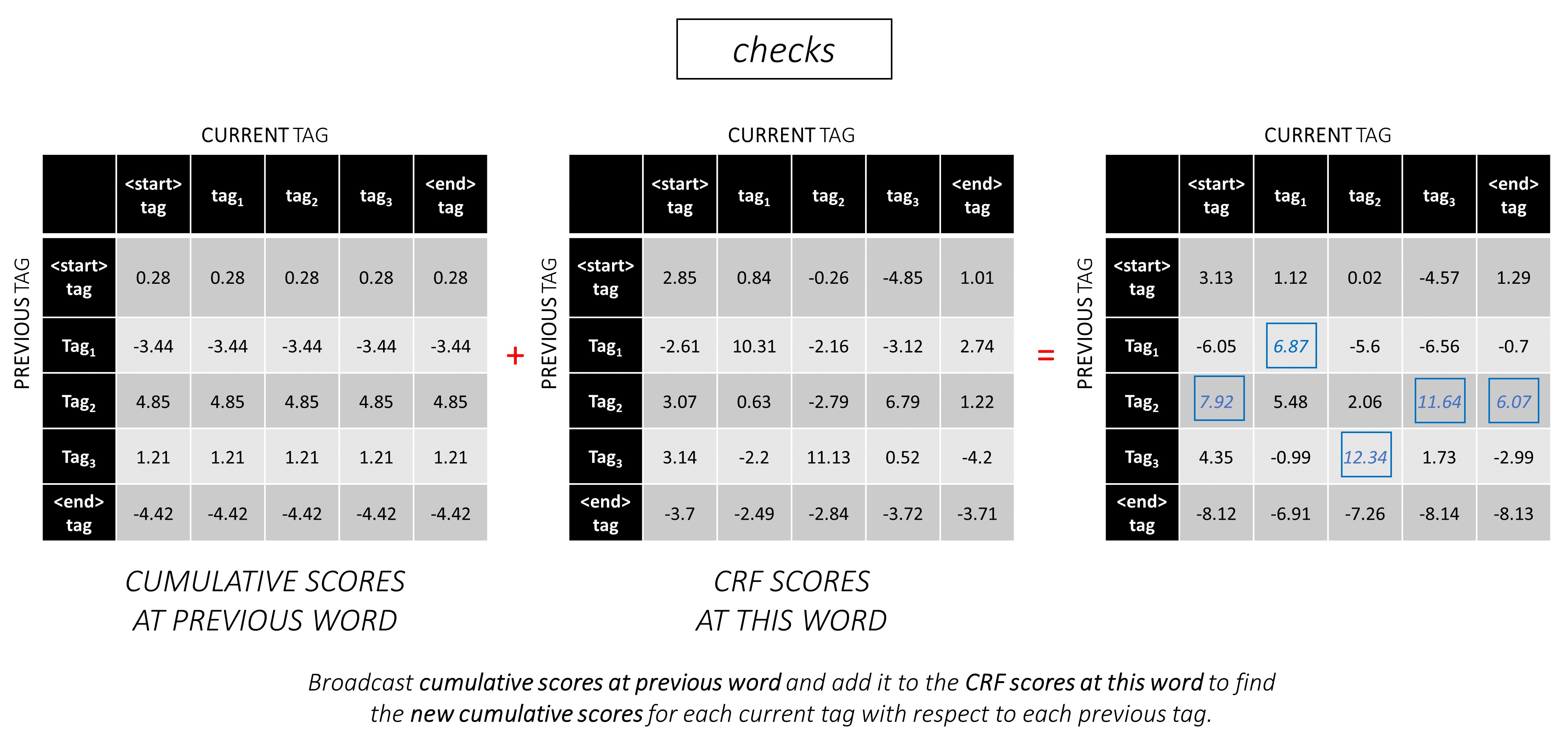
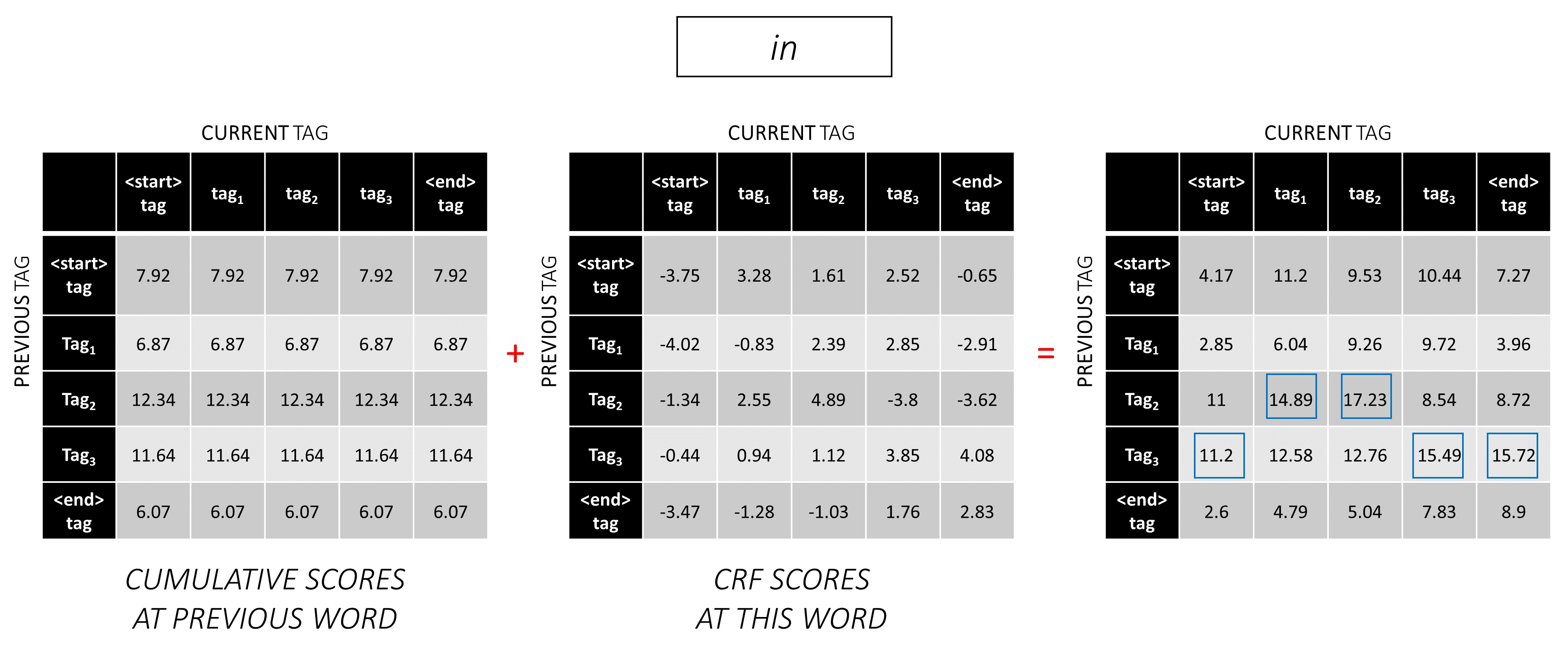
สำหรับตัวอย่างประโยคของเรา dunston checks in <end> หากเราสมมติว่ามีแท็กทั้งหมด 5 แท็กคะแนนรวมจะเป็นแบบนี้ -
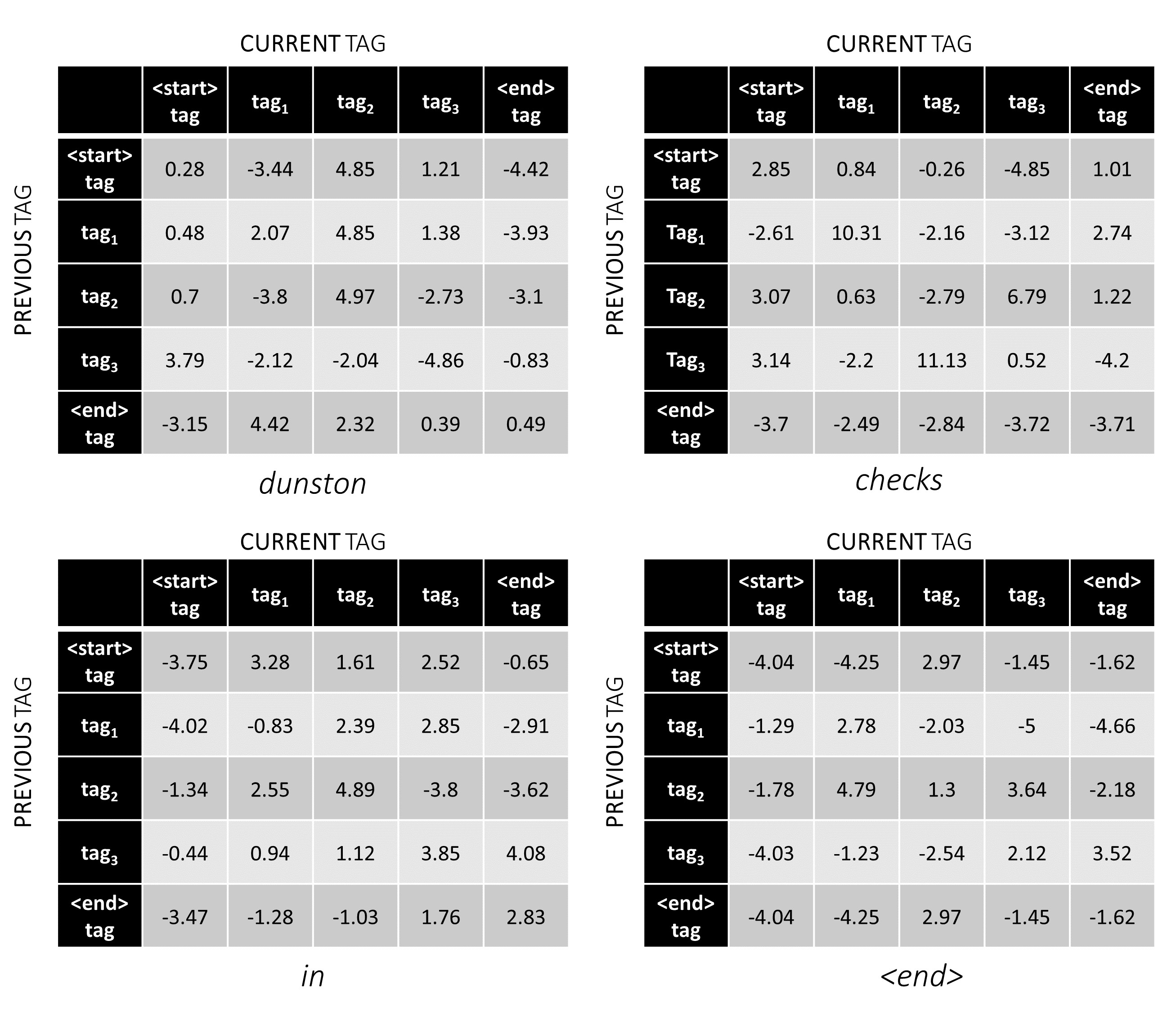
แต่เดี๋ยวก่อนทำไม <start> end <end> แท็ก? ในขณะที่เราอยู่ที่นี่ทำไมเราถึงใช้โทเค็น <end> ?
<start> และ <end> แท็ก <start> และ <end> โทเค็น เนื่องจากเรากำลังสร้างแบบจำลองโอกาสในการเปลี่ยนระหว่างแท็กเราจึงรวมแท็ก <start> และแท็ก <end> ในแท็กชุดของเรา
คะแนนการเปลี่ยนแปลงของแท็กบางอย่างเนื่องจากแท็กก่อนหน้านี้เป็นแท็ก <start> หมายถึง ความน่าจะเป็นของแท็กนี้เป็นแท็ก แรก ในประโยค ตัวอย่างเช่นประโยคมักจะเริ่มต้นด้วยบทความ (a, an,) หรือคำนามหรือคำสรรพนาม
คะแนนการเปลี่ยนแปลงของแท็ก <end> เมื่อพิจารณาแท็กก่อนหน้านี้บ่งบอกถึง ความน่าจะเป็นของแท็กก่อนหน้านี้เป็นแท็ก สุดท้าย ในประโยค
เราจะใช้โทเค็น <end> ในทุกประโยคและไม่ใช่โทเค็น <start> เนื่องจากคะแนน CRF ทั้งหมดในแต่ละคำนั้นถูกกำหนดไว้ด้วยความเคารพต่อแท็กของคำ ก่อนหน้านี้ ซึ่งจะไม่สมเหตุสมผลที่โทเค็น <start>
แท็กที่ถูกต้องของโทเค็น <end> คือแท็ก <end> เสมอ "แท็กก่อนหน้า" ของคำแรกคือแท็ก <start> เสมอ
เพื่อแสดงให้เห็นว่าหากตัวอย่างประโยคของเรา dunston checks in <end> มีแท็ก tag_2, tag_3, tag_3, <end> , ค่าในสีแดงหมายถึงคะแนนของแท็กเหล่านี้
โดยทั่วไปเราใช้เลเยอร์เชิงเส้นที่เปิดใช้งานเพื่อแปลงและประมวลผลเอาต์พุตของ RNN/LSTM
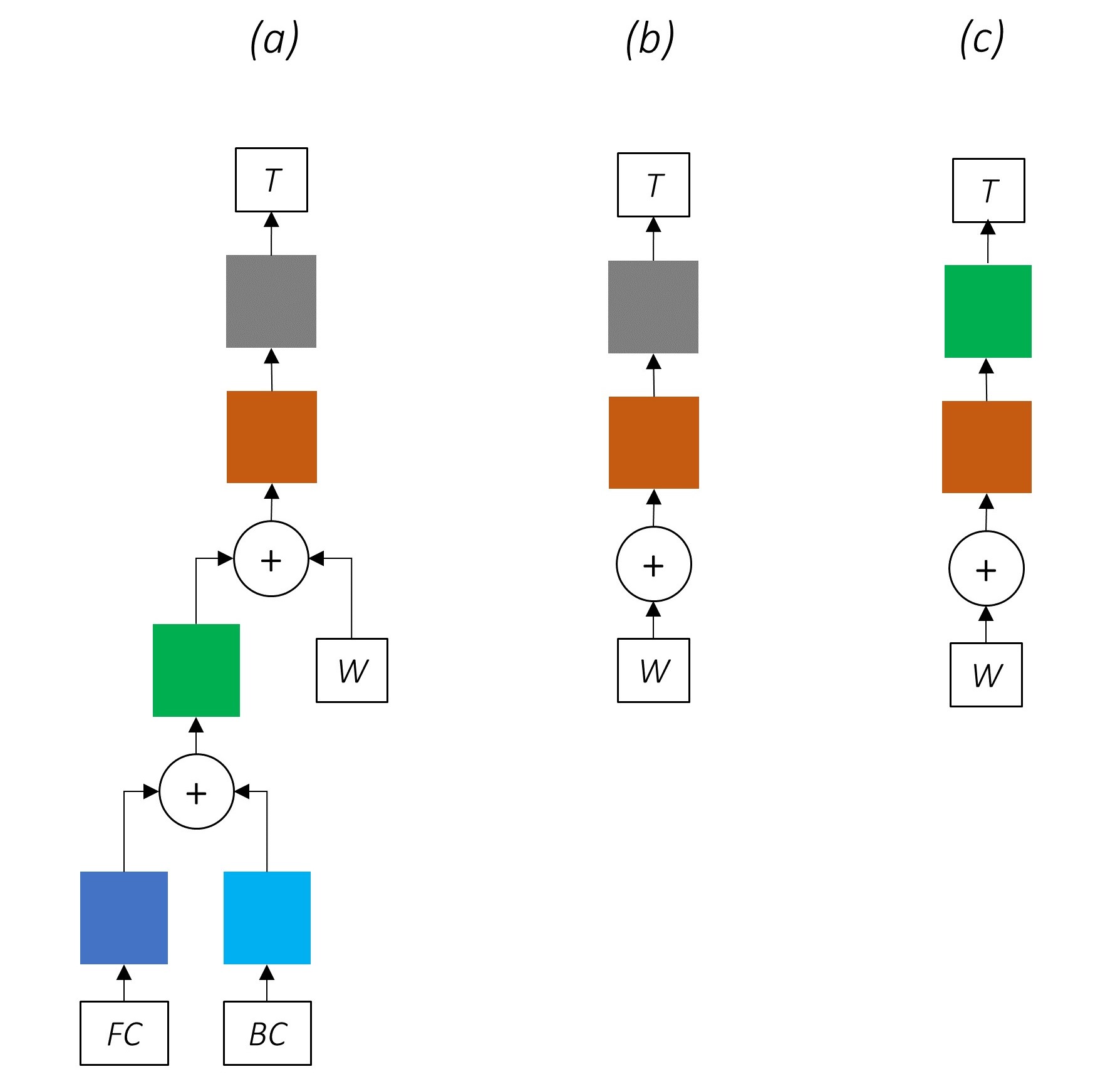
หากคุณคุ้นเคยกับการเชื่อมต่อที่เหลือเราสามารถเพิ่มอินพุตก่อนการแปลงเป็นเอาต์พุตที่แปลงแล้วสร้างเส้นทางสำหรับการไหลของข้อมูลรอบ ๆ การแปลง
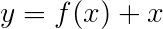
เส้นทางนี้เป็นทางลัดสำหรับการไหลของการไล่ระดับสีในระหว่างการ backpropagation และช่วยในการบรรจบกันของเครือข่ายลึก
เครือข่ายทางหลวง มีความคล้ายคลึงกับเครือข่ายที่เหลือ แต่เราใช้ เกตที่เปิดใช้งาน Sigmoid เพื่อกำหนดอัตราส่วนที่อินพุตและเอาต์พุตแปลงถูกรวมเข้าด้วยกัน
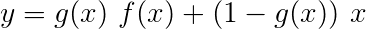
เนื่องจากตัวละคร RNNs มีส่วนร่วมในการทำงานหลายอย่าง เครือข่ายทางหลวงจึงใช้สำหรับการแยกข้อมูลเฉพาะงาน จากผลลัพธ์ของมัน
ดังนั้นเราจะใช้เครือข่ายทางหลวงใน สามสถานที่ ในโมเดลรวมของเรา -
ในการตั้งค่าการฝึกอบรมร่วมที่ไร้เดียงสาซึ่งเราใช้เอาต์พุตของตัวละคร RNNs โดยตรงสำหรับงานหลายงานเช่นโดยไม่มีการเปลี่ยนแปลงความไม่ลงรอยกันระหว่างธรรมชาติของงานอาจส่งผลกระทบต่อประสิทธิภาพการทำงาน
ตอนนี้อาจชัดเจนว่าเครือข่ายรวมของเราเป็นอย่างไร
การลบชิ้นส่วนของเครือข่ายของเราอย่างต่อเนื่องในเครือข่ายที่ง่ายขึ้นอย่างต่อเนื่องซึ่งใช้กันอย่างแพร่หลายสำหรับการติดฉลากลำดับ
ไม่มีการเรียนรู้แบบหลายงาน
การใช้ข้อมูลระดับอักขระโดยไม่ต้องฝึกอบรมยังคงปรับปรุงประสิทธิภาพ
ไม่มีการเรียนรู้แบบหลายงานหรือการประมวลผลระดับตัวละคร
การกำหนดค่านี้ใช้ค่อนข้างทั่วไปในอุตสาหกรรมและทำงานได้ดี
ไม่มีการเรียนรู้แบบหลายงานการประมวลผลระดับตัวละครหรือ CRFing โปรดทราบว่าชั้นเชิงเส้นหรือทางหลวงจะแทนที่หลัง
สิ่งนี้สามารถทำงานได้ดีพอสมควร แต่ฟิลด์แบบสุ่มแบบมีเงื่อนไขช่วยเพิ่มประสิทธิภาพที่มีขนาดใหญ่
โปรดจำไว้ว่าเราไม่ได้ใช้เลเยอร์เชิงเส้นที่คำนวณเฉพาะคะแนนการปล่อย Cross Entropy ไม่ใช่ตัวชี้วัดการสูญเสียที่เหมาะสม
แต่เราจะใช้ การสูญเสีย Viterbi ซึ่งเช่น Cross Entropy เป็น "โอกาสในการบันทึกเชิงลบ" แต่ที่นี่เราจะวัดความน่าจะเป็นของลำดับแท็กทองคำ (จริง) แทนที่จะเป็นโอกาสของแท็กที่แท้จริงในแต่ละคำในลำดับ เพื่อค้นหาโอกาสเราจะพิจารณา Softmax เหนือคะแนนของลำดับแท็กทั้งหมด
คะแนนของลำดับแท็ก t ถูกกำหนดเป็นผลรวมของคะแนนของแต่ละแท็ก

ตัวอย่างเช่นพิจารณาคะแนน CRF ที่เราดูก่อนหน้านี้ -
คะแนนของลำดับแท็ก tag_2, tag_3, tag_3, <end> tag คือผลรวมของค่าเป็นสีแดง, 4.85 + 6.79 + 3.85 + 3.52 = 19.01
การสูญเสีย Viterbi นั้นถูกกำหนดเป็น
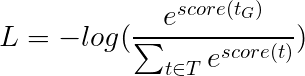
โดยที่ t_G คือลำดับแท็กทองคำและ T หมายถึงพื้นที่ของลำดับแท็กที่เป็นไปได้ทั้งหมด
สิ่งนี้ทำให้ง่ายขึ้น -
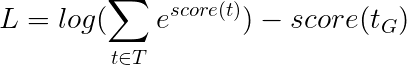
ดังนั้นการสูญเสีย Viterbi คือ ความแตกต่างระหว่าง log-sum-exp ของคะแนนของลำดับแท็กที่เป็นไปได้ทั้งหมดและคะแนนของลำดับแท็กทองคำ เช่น log-sum-exp(all scores) - gold score
การถอดรหัส Viterbi เป็นวิธีการสร้างลำดับแท็กที่ดีที่สุดโดยพิจารณาไม่เพียง แต่ความน่าจะเป็นของแท็กในคำที่แน่นอน (คะแนนการปล่อย) แต่ยังรวมถึงความน่าจะเป็นของแท็กที่พิจารณาแท็กก่อนหน้าและถัดไป (คะแนนการเปลี่ยนแปลง)
เมื่อคุณสร้างคะแนน CRF ในเมทริกซ์ L, m, m สำหรับลำดับความยาว L เราเริ่มถอดรหัส
การถอดรหัส Viterbi เป็นตัวอย่างที่ดีที่สุด พิจารณาอีกครั้ง -
สำหรับคำแรกในลำดับ previous_tag จะเป็น <start> เท่านั้น ดังนั้นพิจารณาเพียงหนึ่งแถว
เหล่านี้ยังเป็นคะแนนสะสมสำหรับแต่ละ current_tag ในคำแรก
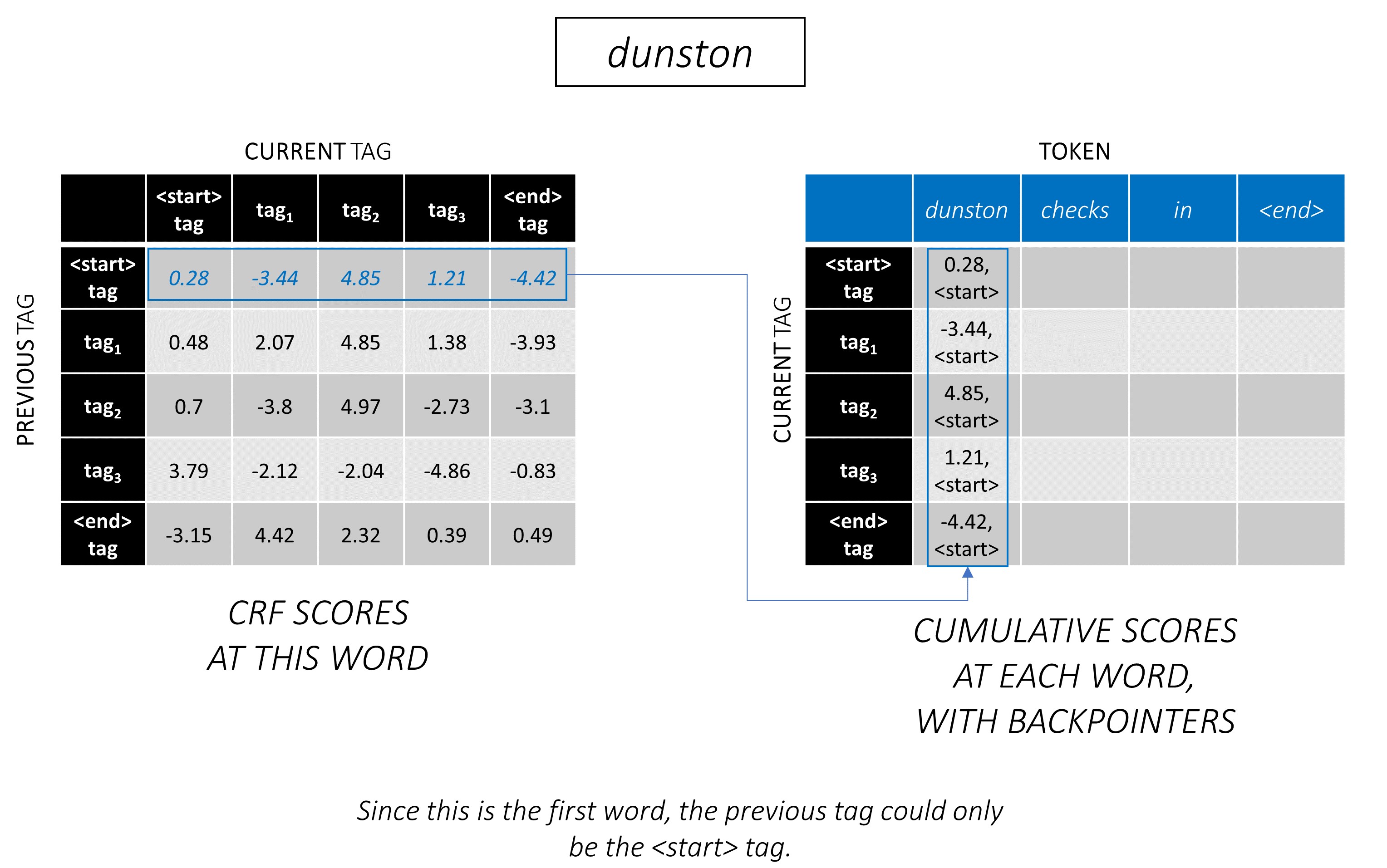
นอกจากนี้เรายังจะติดตาม _tag previous_tag ที่สอดคล้องกับแต่ละคะแนน สิ่งเหล่านี้เรียกว่า backpointers ในคำแรกพวกเขาเห็นได้ชัดว่าทั้งหมด <start> แท็ก
ในคำที่สอง เพิ่มคะแนนสะสมก่อนหน้านี้ในคะแนน CRF ของคำนี้เพื่อสร้างคะแนนสะสมใหม่
โปรดทราบว่า current_tag s ของคำแรกเป็นคำที่สองของคำ previous_tag s ดังนั้นให้ออกอากาศคะแนนสะสมของคำแรกตามมิติ current_tag
สำหรับแต่ละ current_tag ให้พิจารณาเฉพาะคะแนนสูงสุดของคะแนนจากทั้งหมด previous_tag s
เก็บ backpointers เช่นแท็กก่อนหน้านี้ที่สอดคล้องกับคะแนนสูงสุดเหล่านี้

ทำซ้ำกระบวนการนี้ที่คำที่สาม
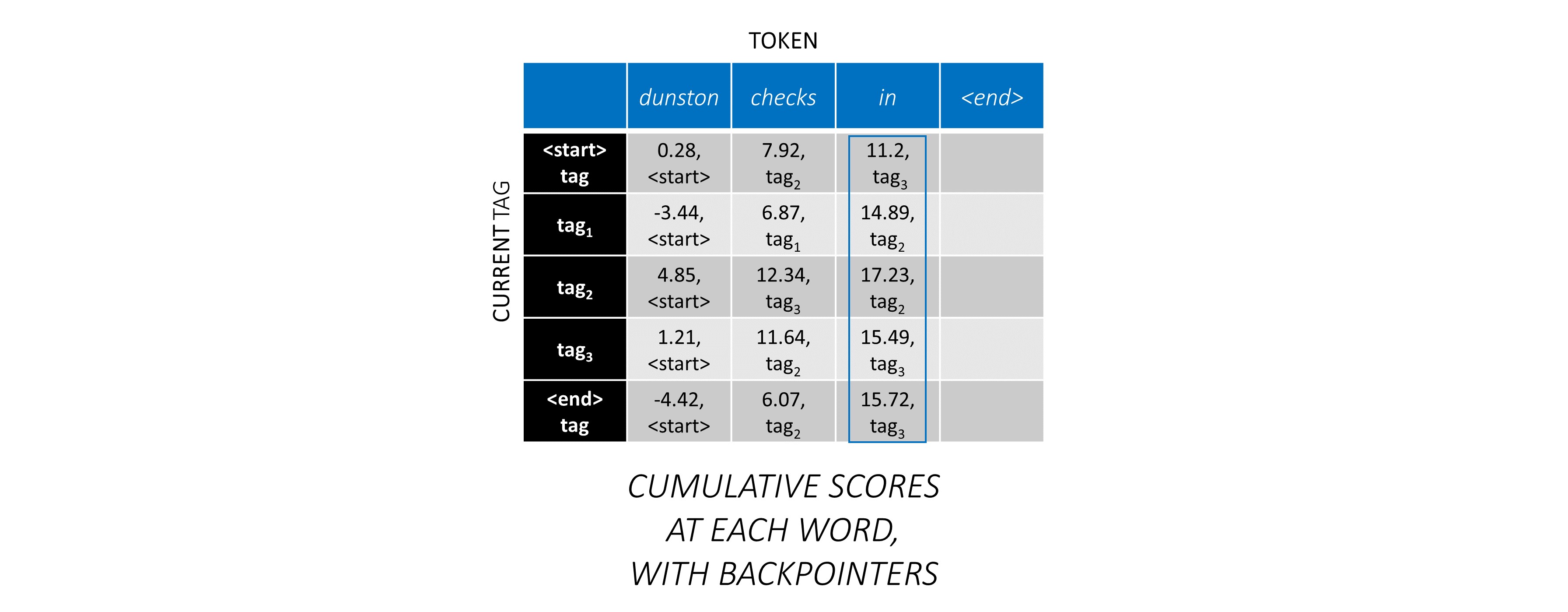
... และคำสุดท้ายซึ่งเป็นโทเค็น <end>
ที่นี่ความแตกต่างเพียงอย่างเดียวคือคุณ รู้แท็กที่ถูกต้องแล้ว คุณต้องการคะแนนสูงสุดและ backpointer สำหรับแท็ก <end> เท่านั้น
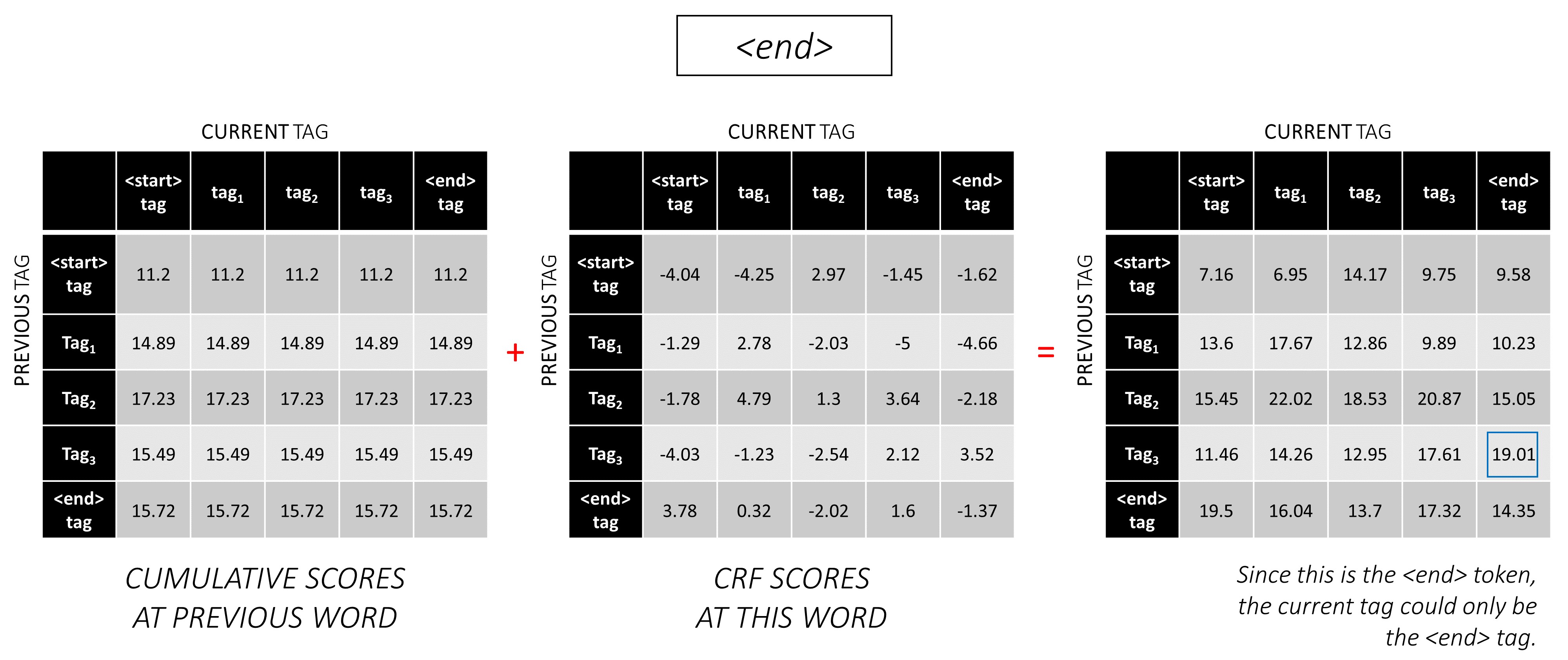
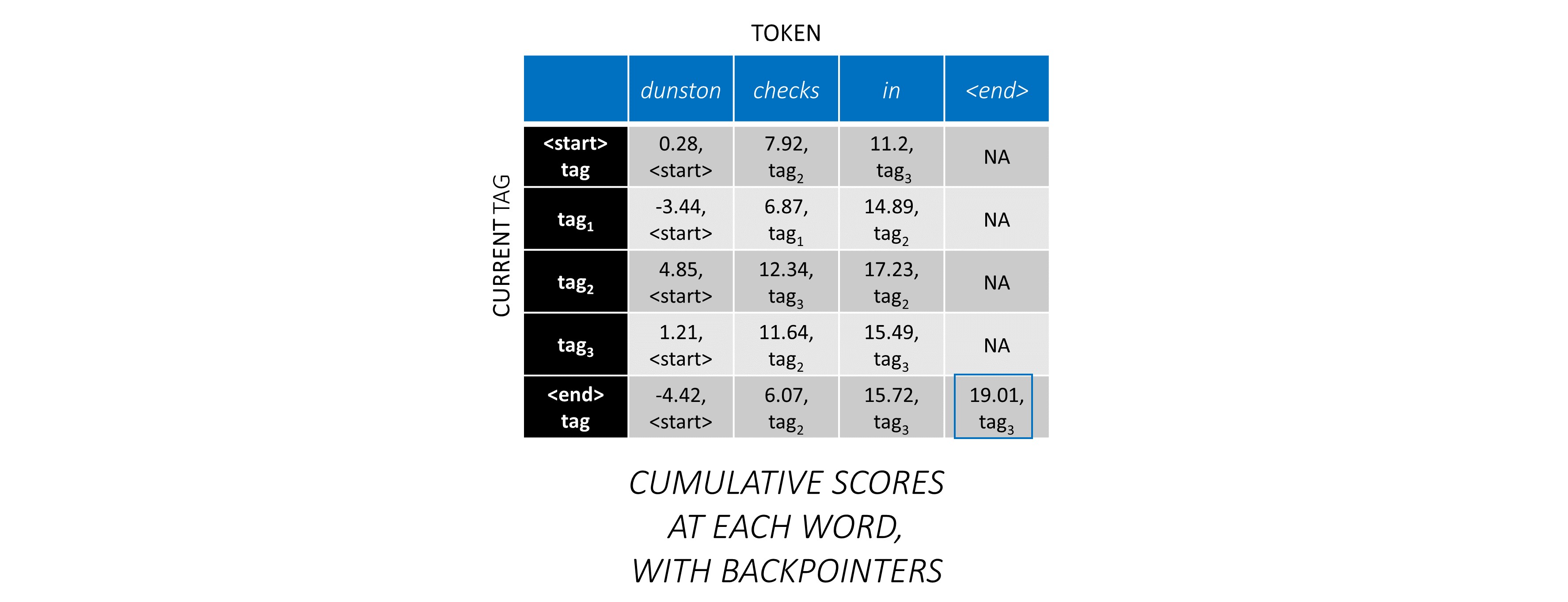
ตอนนี้คุณสะสมคะแนน CRF ทั่วทั้งลำดับ คุณจะติดตาม ย้อนกลับ เพื่อเปิดเผยลำดับแท็กด้วยคะแนนสูงสุดที่เป็นไปได้
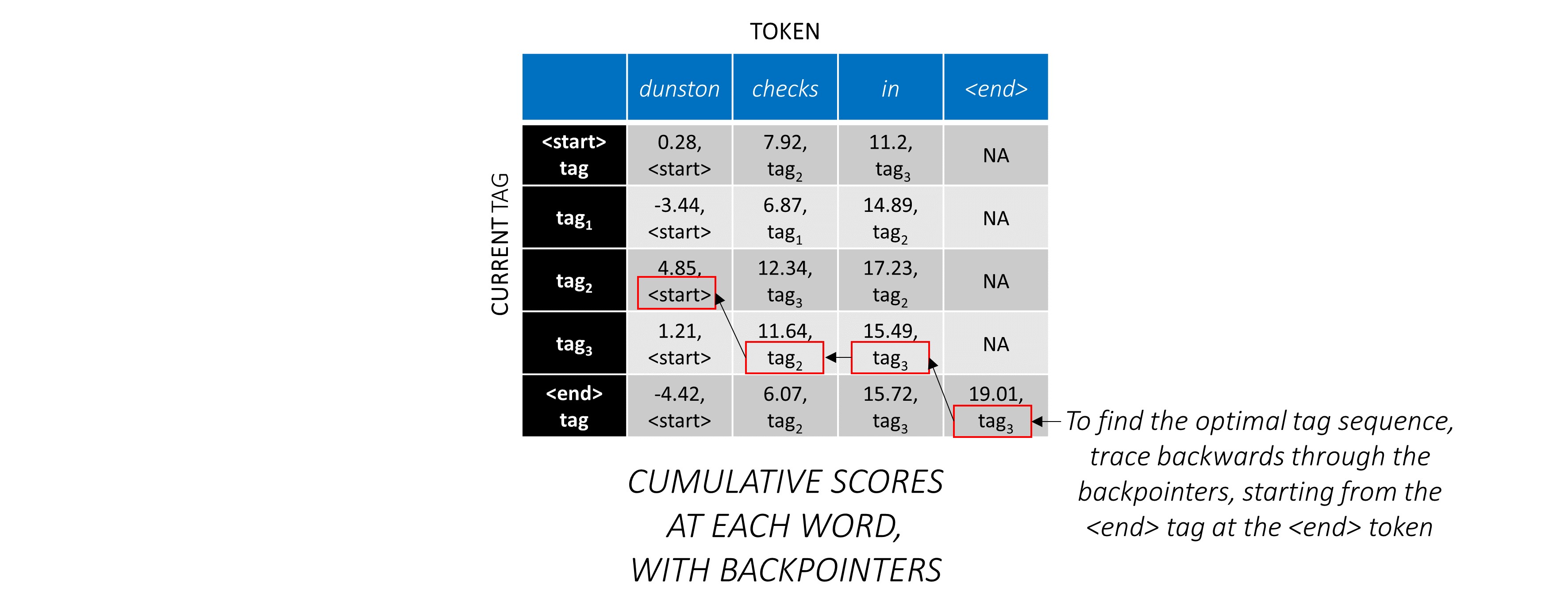
เราพบว่าลำดับแท็กที่ดีที่สุดสำหรับ dunston checks in <end> คือ tag_2 tag_3 tag_3 <end>
ส่วนด้านล่างอธิบายการใช้งานสั้น ๆ
พวกเขามีความหมายที่จะให้บริบทบางอย่าง แต่ รายละเอียดเป็นที่เข้าใจได้ดีที่สุดโดยตรงจากรหัส ซึ่งมีความคิดเห็นค่อนข้างมาก
ฉันใช้ชุดข้อมูล Conll 2003 NER เพื่อเปรียบเทียบผลลัพธ์ของฉันกับกระดาษ
นี่คือตัวอย่าง -
-DOCSTART- -X- O O
EU NNP I-NP I-ORG
rejects VBZ I-VP O
German JJ I-NP I-MISC
call NN I-NP O
to TO I-VP O
boycott VB I-VP O
British JJ I-NP I-MISC
lamb NN I-NP O
. . O O
ชุดข้อมูลนี้ไม่ได้หมายถึงการกระจายสาธารณะแม้ว่าคุณอาจพบว่ามันออนไลน์อยู่ที่ไหนสักแห่ง
มีชุดข้อมูลสาธารณะหลายชุดที่คุณสามารถใช้ในการฝึกอบรมรุ่น สิ่งเหล่านี้อาจไม่ใช่คำอธิบายประกอบของมนุษย์ 100% แต่ก็เพียงพอแล้ว
สำหรับการติดแท็ก ner คุณสามารถใช้ธนาคาร Groningen หมายถึง
สำหรับการติดแท็ก POS NLTK มีชุดข้อมูลขนาดเล็กคุณสามารถเข้าถึงได้ด้วย nltk.corpus.treebank.tagged_sents()
คุณอาจต้องแปลงเป็นรูปแบบข้อมูลของ Conll 2003 NER หรือแก้ไขรหัสที่อ้างอิงในส่วนของ Data Pipeline
เราจะต้องมีอินพุตแปดครั้ง
นี่คือลำดับคำที่ต้องติดแท็ก
dunston checks in
ตามที่กล่าวไว้ก่อนหน้านี้เราจะไม่ใช้โทเค็น <start> แต่เรา จะ ต้องใช้โทเค็น <end>
dunston, checks, in, <end>
เนื่องจากเราผ่านประโยครอบ ๆ เป็นเทนเซอร์ขนาดคงที่เราจำเป็นต้องใช้ประโยค (ซึ่งเป็นธรรมชาติที่มีความยาวแตกต่างกัน) ความยาวเท่ากันด้วยโทเค็น <pad>
dunston, checks, in, <end>, <pad>, <pad>, <pad>, ...
นอกจากนี้เรายังสร้าง word_map ซึ่งเป็นการแมปดัชนีสำหรับแต่ละคำในคลังข้อมูลรวมถึง <end> และ <pad> โทเค็น Pytorch เช่นเดียวกับห้องสมุดอื่น ๆ ต้องการคำที่เข้ารหัสเป็นดัชนีเพื่อค้นหาการฝังตัวสำหรับพวกเขาหรือเพื่อระบุสถานที่ของพวกเขาในคะแนนคำที่คาดการณ์ไว้
4381, 448, 185, 4669, 0, 0, 0, ...
ดังนั้น ลำดับคำที่ป้อนเข้ากับโมเดลจะต้องเป็นเทนเซอร์ Int ของขนาด N, L_w โดยที่ N คือ batch_size และ L_w เป็นความยาวเบาะของลำดับคำ (โดยปกติความยาวของลำดับคำที่ยาวที่สุด)
นี่คือลำดับตัวละครในทิศทางไปข้างหน้า
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' '
เราต้องการ <end> โทเค็นในลำดับอักขระเพื่อให้ตรงกับโทเค็น <end> ในลำดับคำ เนื่องจากเราจะใช้คุณสมบัติระดับตัวละครในแต่ละคำในลำดับคำเราจึงต้องมีคุณสมบัติระดับตัวละครที่ <end> ในลำดับคำ
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>
เรายังต้องติดพวกเขา
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>, <pad>, <pad>, <pad>, ...
และเข้ารหัสด้วย char_map
29, 2, 12, 8, 7, 14, 12, 3, 6, 18, 1, 6, 21, 8, 3, 17, 12, 3, 60, 0, 0, 0, ...
ดังนั้น ลำดับอักขระไปข้างหน้าที่ป้อนเข้ากับโมเดลจะต้องเป็นเทนเซอร์ Int ของมิติ N, L_c โดยที่ L_c คือความยาวเบาะของลำดับอักขระ (โดยปกติความยาวของลำดับอักขระที่ยาวที่สุด)
สิ่งนี้จะถูกประมวลผลเช่นเดียวกับลำดับไปข้างหน้า แต่ย้อนกลับ (โทเค็น <end> จะยังคงอยู่ในตอนท้ายตามธรรมชาติ)
'n', 'i', ' ', 's', 'k', 'c', 'e', 'h', 'c', ' ', 'n', 'o', 't', 's', 'n', 'u', 'd', ' ', <end>, <pad>, <pad>, <pad>, ...
12, 17, 3, 8, 21, 6, 1, 18, 6, 3, 12, 14, 7, 8, 12, 2, 29, 3, 60, 0, 0, 0, ...
ดังนั้น ลำดับอักขระย้อนหลังที่ป้อนเข้ากับโมเดลจะต้องเป็นเทนเซอร์ Int ของมิติ N, L_c
เครื่องหมายเหล่านี้เป็น ตำแหน่งในลำดับตัวละคร ที่เราแยกฟีเจอร์ให้ -
เราจะแยกฟีเจอร์ในตอนท้ายของทุกพื้นที่ ' ' ในลำดับตัวละครและที่โทเค็น <end>
สำหรับลำดับตัวละครไปข้างหน้าเราแยกที่ -
7, 14, 17, 18
นี่คือคะแนนหลังจาก dunston , checks , in , <end> ตามลำดับ ดังนั้นเราจึงมี เครื่องหมายสำหรับแต่ละคำในลำดับคำ ซึ่งสมเหตุสมผล (ในรูปแบบภาษาอย่างไรก็ตามเนื่องจากเรากำลังทำนายคำ ต่อไป เราจะไม่ทำนายที่เครื่องหมายซึ่งสอดคล้องกับ <end> )
เราวางสิ่งเหล่านี้ด้วย 0 วินาที ไม่สำคัญว่าเราจะทำอะไรตราบเท่าที่พวกเขาเป็นดัชนีที่ถูกต้อง (เราจะแยกฟีเจอร์ที่แผ่นรอง แต่เราจะไม่ใช้มัน)
7, 14, 17, 18, 0, 0, 0, ...
พวกเขาจะเบาะตามความยาวเบาะของลำดับคำ, L_w
ดังนั้น เครื่องหมายของตัวละครไปข้างหน้าที่ป้อนเข้ากับโมเดลจะต้องเป็นเทนเซอร์ Int ของมิติ N, L_w
สำหรับเครื่องหมายในลำดับตัวละครย้อนหลังเราจะพบตำแหน่งของทุกพื้นที่ ' ' และโทเค็น <end>
นอกจากนี้เรายังตรวจสอบให้แน่ใจว่า ตำแหน่งเหล่านี้อยู่ในลำดับ คำ เดียวกันกับในเครื่องหมายไปข้างหน้า การจัดตำแหน่งนี้ทำให้คุณลักษณะที่แยกออกจากลำดับอักขระไปข้างหน้าและย้อนกลับและยังป้องกันไม่ให้สั่งซื้อเป้าหมายในแบบจำลองภาษาอีกครั้ง
17, 9, 2, 18
นี่คือคะแนนหลังจาก notsnud , skcehc , ni , <end> ตามลำดับ
เราติดกับ 0 วินาที
17, 9, 2, 18, 0, 0, 0, ...
ดังนั้น เครื่องหมายอักขระย้อนหลังที่ป้อนเข้ากับโมเดลจะต้องเป็นเทนเซอร์ Int ของมิติ N, L_w
สมมติว่าแท็กที่ถูกต้องสำหรับ dunston, checks, in, <end> คือ -
tag_2, tag_3, tag_3, <end>
เรามี tag_map (มีแท็ก <start> , tag_1 , tag_2 , tag_3 , <end> )
โดยปกติเราจะเข้ารหัสพวกเขาโดยตรง (ก่อนที่จะมีช่องว่าง) -
2, 3, 3, 5
นี่คือการเข้ารหัส 1D เช่นตำแหน่งแท็กในแผนที่แท็ก 1D
แต่ เอาต์พุตของเลเยอร์ CRF คือ 2D m, m Tensors ในแต่ละคำ เราจะต้องเข้ารหัสตำแหน่งแท็กในเอาต์พุต 2D เหล่านี้
ตำแหน่งแท็กที่ถูกต้องถูกทำเครื่องหมายเป็นสีแดง
(0, 2), (2, 3), (3, 3), (3, 4)
หากเราคลายคะแนนเหล่านี้ลงในเทนเซอร์ 1D m*m แล้วตำแหน่งแท็กในเทนเซอร์ที่ไม่ได้ควบคุมจะเป็น
tag_map [ previous_tag ] * len ( tag_map ) + tag_map [ current_tag ] ดังนั้นเราจึงเข้ารหัส tag_2, tag_3, tag_3, <end> AS
2, 13, 18, 19
โปรดทราบว่าคุณสามารถดึงดัชนี tag_map ดั้งเดิมได้โดยใช้โมดูลัส
t % len ( tag_map ) พวกเขาจะได้รับเบาะตามความยาวเบาะของลำดับคำ, L_w
ดังนั้น แท็กที่ป้อนเข้ากับโมเดลจะต้องเป็นเทนเซอร์ Int ของมิติ N, L_w
นี่คือความยาวที่แท้จริงของลำดับคำรวมถึงโทเค็น <end> เนื่องจาก Pytorch รองรับกราฟแบบไดนามิกเราจะคำนวณความยาวเหล่านี้เท่านั้นและไม่เกิน <pads>
ดังนั้น ความยาวของคำที่ป้อนไปยังแบบจำลองจะต้องเป็นเทนเซอร์ Int ของมิติ N
นี่คือความยาวที่แท้จริงของลำดับอักขระรวมถึงโทเค็น <end> เนื่องจาก Pytorch รองรับกราฟแบบไดนามิกเราจะคำนวณความยาวเหล่านี้เท่านั้นและไม่เกิน <pads>
ดังนั้น ความยาวของตัวละครที่ป้อนเข้ากับโมเดลจะต้องเป็นเทนเซอร์ Int ของมิติ N
ดู read_words_tags() ใน utils.py
สิ่งนี้จะอ่านไฟล์อินพุตในรูปแบบ Conll 2003 และแยกลำดับคำและแท็ก
ดู create_maps() ใน utils.py
ที่นี่เราสร้างแผนที่การเข้ารหัสสำหรับคำอักขระและแท็ก เราใช้คำพูดและตัวละคร <unk> ยากเป็น s (ไม่ทราบ)
ดู create_input_tensors() ใน utils.py
เราสร้างแปดอินพุตที่มีรายละเอียดในส่วนอินพุตไปยังส่วนรุ่น
ดู load_embeddings() ใน utils.py
เราโหลดการฝังตัวที่ผ่านการฝึกอบรมมาแล้วโดยมีตัวเลือกในการขยาย word_map เพื่อรวมคำที่อยู่นอกเมือง Corpus ที่มีอยู่ในคำศัพท์ฝัง Note that this may also include rare in-corpus words that were binned as <unk> s earlier.
ดู WCDataset ใน datasets.py
นี่คือคลาสย่อยของ Dataset Pytorch มันต้องการวิธี __len__ ที่กำหนดซึ่งส่งคืนขนาดของชุดข้อมูลและวิธี __getitem__ ซึ่งส่งคืนชุด i Th แปดอินพุตไปยังโมเดล
Dataset จะถูกใช้โดย pytorch DataLoader ใน train.py เพื่อสร้างและป้อนแบทช์ข้อมูลไปยังแบบจำลองสำหรับการฝึกอบรมหรือการตรวจสอบความถูกต้อง
ดู Highway ใน models.py
การแปลง คือการแปลงเชิงเส้นที่เปิดใช้งานแบบ relu ของอินพุต ประตู คือการแปลงเชิงเส้นที่เปิดใช้งาน sigmoid ของอินพุต โปรดทราบว่า การแปลงทั้งสองจะต้องมีขนาดเท่ากันกับอินพุต เพื่ออนุญาตให้เพิ่มอินพุตในการเชื่อมต่อที่เหลือ
แอตทริบิวต์ num_layers ระบุจำนวนการดำเนินการเชื่อมต่อกับการแปลง-เกต-เกตที่เราดำเนินการเป็นอนุกรม โดยปกติแล้วเพียงหนึ่งเดียวก็เพียงพอ
เราจัดเก็บจำนวนเลเยอร์การแปลงและเกตที่จำเป็นใน ModuleList() และใช้ A for for เพื่อดำเนินการต่อเนื่อง
ดู LM_LSTM_CRF ใน models.py
ในตอนแรกเรา เรียงลำดับลำดับตัวละครไปข้างหน้าและข้างหลังโดยลดความยาว สิ่งนี้จำเป็นต้องใช้ pack_padded_sequence() เพื่อให้ LSTM คำนวณเฉพาะเวลาที่ถูกต้องเท่านั้นเช่นความยาวที่แท้จริงของลำดับ
อย่าลืมจัดเรียงเทนเซอร์อื่น ๆ ทั้งหมดในลำดับเดียวกัน
ดู dynamic_rnn.py สำหรับภาพประกอบว่า pack_padded_sequence() สามารถใช้ประโยชน์จากการใช้กราฟและความสามารถในการแบทช์แบบไดนามิกของ Pytorch เพื่อที่เราจะได้ไม่ประมวลผลแผ่น มันแบนลำดับที่จัดเรียงตาม timestep ในขณะที่เพิกเฉยต่อแผ่นและ LSTM คำนวณเฉพาะขนาดแบทช์ที่มีประสิทธิภาพ N_t ในแต่ละช่วงเวลา
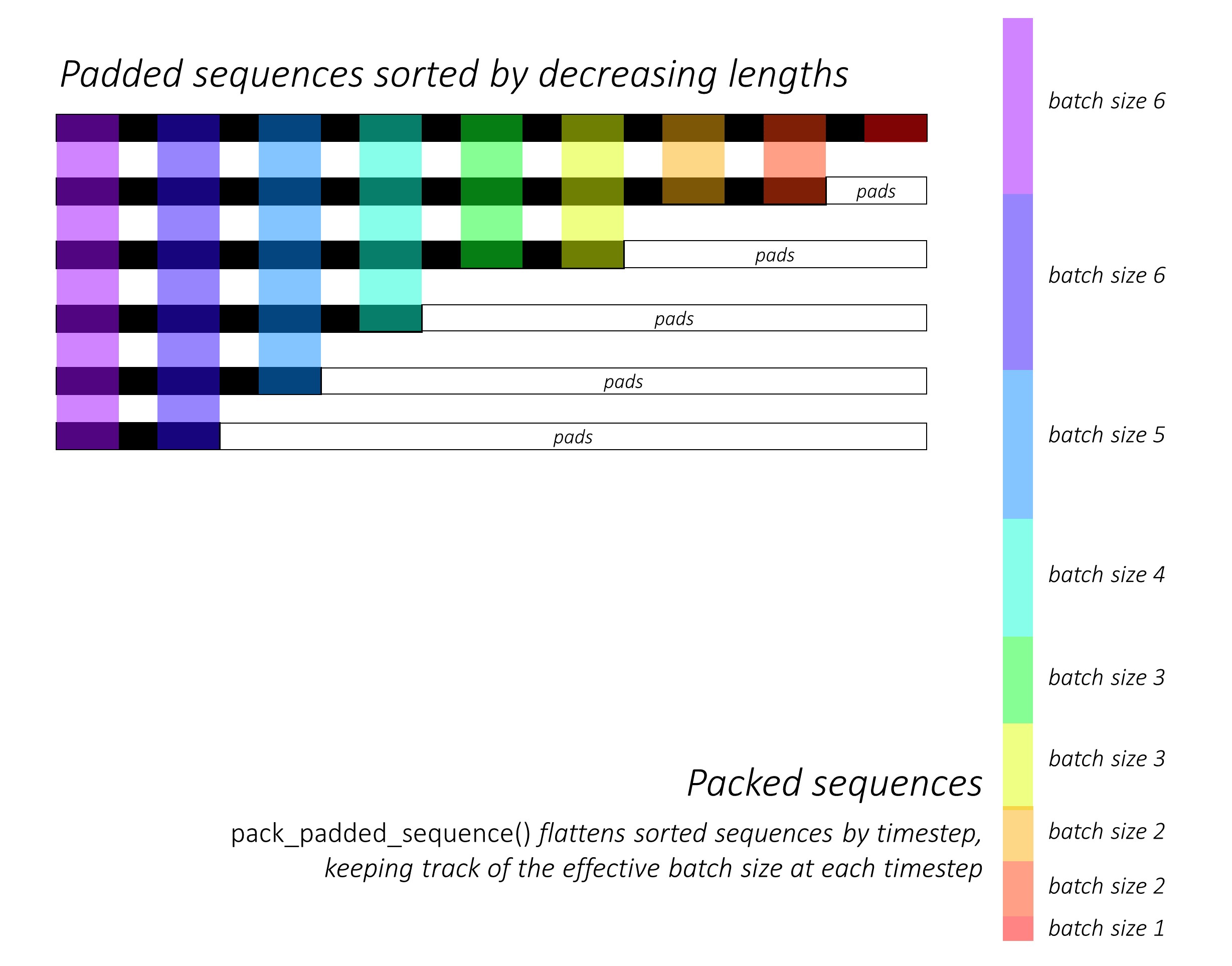
การเรียงลำดับอนุญาตให้ N_t บนสุดที่กำหนดเวลาใด ๆ ให้สอดคล้องกับเอาต์พุตจากขั้นตอนก่อนหน้า ตัวอย่างเช่นครั้งที่สามเราจะประมวลผลเฉพาะภาพ 5 อันดับแรกโดยใช้เอาต์พุต 5 อันดับแรกจากขั้นตอนก่อนหน้า ยกเว้นการเรียงลำดับทั้งหมดนี้ได้รับการจัดการภายในโดย Pytorch แต่ก็ยังมีประโยชน์มากที่จะเข้าใจสิ่งที่ pack_padded_sequence() ทำเพื่อให้เราสามารถใช้มันในสถานการณ์อื่น ๆ เพื่อให้ได้สิ้นสุดที่คล้ายกัน (ดูคำถามที่เกี่ยวข้องเกี่ยวกับการจัดการลำดับความยาวตัวแปรในส่วนคำถามที่พบบ่อย))
เมื่อเรียงลำดับเรา จะใช้ LSTMS ไปข้างหน้าและย้อนกลับในการส่งต่อและ packed_sequences กลับ ตามลำดับ เราใช้ pad_packed_sequence() เพื่อ unflatten และ pad outputs อีกครั้ง
เรา สกัดเฉพาะเอาต์พุตที่เครื่องหมายตัวละครไปข้างหน้าและข้างหลัง ด้วย gather ฟังก์ชั่นนี้มีประโยชน์มากสำหรับการแยกดัชนีบางอย่างจากเทนเซอร์ที่ระบุไว้ในเทนเซอร์แยกต่างหาก
เอาต์พุตสกัดเหล่านี้จะถูกประมวลผลโดยเลเยอร์ทางหลวงไปข้างหน้าและด้านหลัง ก่อนที่จะใช้ เลเยอร์เชิงเส้นเพื่อคำนวณคะแนนมากกว่าคำศัพท์ สำหรับการทำนายคำถัดไปที่แต่ละเครื่องหมาย เราทำสิ่งนี้ในระหว่างการฝึกอบรมเท่านั้นเนื่องจากไม่มีเหตุผลที่จะทำการสร้างแบบจำลองภาษาสำหรับการเรียนรู้แบบหลายงานในระหว่างการตรวจสอบความถูกต้องหรือการอนุมาน คุณลักษณะ training ของโมเดลใด ๆ ถูกตั้งค่าด้วย model.train() หรือ model.eval() ใน train.py (โปรดทราบว่าสิ่งนี้ใช้เป็นหลักในการเปิดใช้งานหรือปิดการใช้งานชั้นกลางคันและเลเยอร์แบทช์-norm ในรูปแบบ pytorch ในระหว่างการฝึกอบรมและการอนุมานตามลำดับ)
ดู LM_LSTM_CRF ใน models.py (ต่อ)
นอกจากนี้เรายัง เรียงลำดับลำดับคำโดยลดความยาว เนื่องจากอาจไม่มีความสัมพันธ์ระหว่างความยาวของลำดับคำและลำดับตัวละคร
อย่าลืมจัดเรียงเทนเซอร์อื่น ๆ ทั้งหมดในลำดับเดียวกัน
เรา เชื่อมต่อเอาท์พุท LSTM ตัวละครไปข้างหน้าและข้างหลังที่เครื่องหมายและเรียกใช้ผ่านชั้นทางหลวงที่สาม สิ่งนี้จะแยกข้อมูลคำย่อยในแต่ละคำซึ่งเราจะใช้สำหรับการติดฉลากลำดับ
เรา เชื่อมต่อผลลัพธ์นี้ด้วยคำที่ฝังและคำนวณเอาต์พุต BLSTM ผ่าน packed_sequence
เมื่อทำการเสริมด้วย pad_packed_sequence() เรามีคุณสมบัติที่เราต้องป้อนไปยังชั้น CRF
ดู CRF ใน models.py
คุณอาจพบว่าเลเยอร์นี้ตรงไปตรงมาอย่างน่าประหลาดใจเมื่อพิจารณาค่าที่เพิ่มเข้าไปในโมเดลของเรา
เลเยอร์เชิงเส้นใช้ในการแปลงเอาต์พุตจาก BLSTM เป็นคะแนนสำหรับแต่ละแท็กซึ่งเป็น คะแนนการปล่อย
เทนเซอร์เดียวใช้เพื่อเก็บ คะแนนการเปลี่ยนแปลง เทนเซอร์นี้เป็น Parameter ของโมเดลซึ่งหมายความว่าสามารถอัปเดตได้ในระหว่างการ backpropagation เช่นเดียวกับน้ำหนักของชั้นอื่น ๆ
ในการค้นหาคะแนน CRF ให้คำนวณคะแนนการปล่อยในแต่ละคำและเพิ่มลงในคะแนนการเปลี่ยนแปลง หลังจากออกอากาศทั้งสองตามที่อธิบายไว้ในภาพรวม CRF
ดู ViterbiLoss ใน models.py
เราก่อตั้งขึ้นในภาพรวมการสูญเสีย Viterbi ที่เราต้องการลด ความแตกต่างระหว่าง log-sum-exp ของคะแนนของลำดับแท็กที่ถูกต้องทั้งหมดที่เป็นไปได้และคะแนนของลำดับแท็กทองคำ เช่น log-sum-exp(all scores) - gold score
เรารวมคะแนน CRF ของแต่ละแท็กจริงตามที่อธิบายไว้ก่อนหน้านี้เพื่อคำนวณ คะแนนทองคำ
จำได้ไหมว่าเราเข้ารหัสลำดับแท็กด้วยตำแหน่งของพวกเขาในคะแนน CRF ที่ไม่ได้ควบคุมได้อย่างไร เราสกัดคะแนนที่ตำแหน่งเหล่านี้ด้วย gather() และกำจัดแผ่นอิเล็กโทรดด้วย pack_padded_sequences() ก่อนการรวม
การค้นหา บันทึกการส่งผลกระทบของคะแนนของลำดับที่เป็นไปได้ทั้งหมด นั้นมีความยุ่งยากเล็กน้อย เราใช้ A for loop เพื่อวนซ้ำช่วงเวลา ในแต่ละช่วงเวลาเรา สะสมคะแนนสำหรับแต่ละ current_tag โดย -
current_tag สำหรับแต่ละ previous_tag _tag เราทำสิ่งนี้ด้วยขนาดแบทช์ที่มีประสิทธิภาพเท่านั้นเช่นลำดับที่ยังไม่เสร็จ (ลำดับของเรายังคงเรียงลำดับโดยลดความยาวของคำจากรุ่น LM-LSTM-CRF )current_tag ให้คำนวณ log-sum-exp มากกว่า _tag s previous_tag เพื่อค้นหาคะแนนสะสมใหม่ที่แต่ละ current_tag หลังจากคำนวณผ่านความยาวตัวแปรของลำดับทั้งหมดเราจะถูกทิ้งให้อยู่กับเทนเซอร์ของขนาด N, m โดยที่ m คือจำนวนแท็ก (ปัจจุบัน) เหล่านี้เป็นคะแนนสะสม Sum-EXP มากกว่าลำดับที่เป็นไปได้ทั้งหมดที่ลงท้ายด้วยแท็ก m แต่ละแท็ก อย่างไรก็ตามเนื่องจากลำดับที่ถูกต้องสามารถลงท้ายด้วยแท็ก <end> รวมเฉพาะคอลัมน์ <end> เท่านั้นเพื่อค้นหาบันทึก -exp-exp ของคะแนนของลำดับที่ถูกต้องทั้งหมดที่เป็นไปได้ทั้งหมด
เราพบความแตกต่าง log-sum-exp(all scores) - gold score
ดู ViterbiDecoder ใน inference.py .py
สิ่งนี้ใช้กระบวนการที่อธิบายไว้ในภาพรวมการถอดรหัส Viterbi
เราสะสมคะแนนใน for วนรอบในลักษณะที่คล้ายกับสิ่งที่เราทำใน ViterbiLoss ยกเว้นที่นี่เรา พบคะแนนสูงสุดของคะแนน _tag previous_tag สำหรับแต่ละ current_tag แทนการคำนวณ log-sum-exp นอกจากนี้เรายัง ติดตาม _tag previous_tag ที่สอดคล้องกับคะแนนสูงสุดนี้ ใน backpointer tensor
เรา วางตัวเทนเซอร์ backpointer ด้วยแท็ก <end> เพราะสิ่งนี้ช่วยให้เราสามารถติดตามย้อนหลังบนแผ่นรองในที่สุดก็มาถึงแท็ก <end> จริงแล้ว การย้อนกลับที่เกิดขึ้น จริง จะเริ่มขึ้น
ดู train.py
พารามิเตอร์สำหรับโมเดล (และการฝึกอบรม) อยู่ที่จุดเริ่มต้นของไฟล์ดังนั้นคุณสามารถตรวจสอบหรือแก้ไขได้อย่างง่ายดายหากคุณต้องการ
ใน การฝึกอบรมโมเดลของคุณตั้งแต่เริ่มต้น เพียงแค่เรียกใช้ไฟล์นี้ -
python train.py
ใน การกลับมาฝึกอบรมที่จุดตรวจสอบ ให้ชี้ไปที่ไฟล์ที่เกี่ยวข้องกับพารามิเตอร์ checkpoint ที่จุดเริ่มต้นของรหัส
โปรดทราบว่าเราทำการตรวจสอบความถูกต้องในตอนท้ายของการฝึกอบรมทุกครั้ง
คุณจะสังเกตเห็นว่าเรา ตัดแต่งอินพุตในแต่ละชุดให้เป็นความยาวลำดับสูงสุดในชุดนั้น นี่คือดังนั้นเราจึงไม่มีแผ่นรองในแต่ละชุดที่เราต้องการ
แต่ทำไม? แม้ว่า RNNs ในโมเดลของเราจะไม่คำนวณบนแผ่นรอง แต่ ชั้นเชิงเส้นยังคงทำ มันค่อนข้างตรงไปตรงมาที่จะเปลี่ยนสิ่งนี้ - ดูคำถามที่เกี่ยวข้องเกี่ยวกับการจัดการลำดับความยาวตัวแปรในส่วนคำถามที่พบบ่อย
สำหรับบทช่วยสอนนี้ฉันคิด packed_sequence การคำนวณเพิ่มเติมเล็กน้อยเหนือแผ่นบางส่วนนั้นคุ้มค่ากับความตรงไปตรงมาของการไม่ต้องทำการผ่าตัด - ทางหลวง, CRF, เลเยอร์เชิงเส้นอื่น ๆ
ในสถานการณ์จำลองหลายงานเราได้เลือกที่จะรวมการสูญเสียเอนโทรปีข้ามจากงานสร้างแบบจำลองภาษาสองแบบและการสูญเสีย Viterbi จากงานการติดฉลากลำดับ
แม้ว่าเราจะ ลดผลรวมของการสูญเสียเหล่านี้ให้น้อยที่สุด แต่เราก็สนใจที่จะลดการสูญเสีย Viterbi โดยอาศัยการลดผลรวมของการสูญเสียเหล่านี้ให้น้อยที่สุด มันคือการสูญเสีย Viterbi ซึ่งสะท้อนถึงประสิทธิภาพในงานหลัก
เราใช้ pack_padded_sequence() เพื่อกำจัดแผ่นทุกที่จำเป็น
เช่นเดียวกับในกระดาษเราใช้ คะแนน F1 ที่มีค่าเฉลี่ยแมโครเป็นเกณฑ์สำหรับการหยุดก่อน โดยธรรมชาติแล้วการคำนวณคะแนน F1 นั้นต้องการการถอดรหัสคะแนน CRF เพื่อสร้างลำดับแท็กที่ดีที่สุดของเรา
เราใช้ pack_padded_sequence() เพื่อกำจัดแผ่นทุกที่จำเป็น
ฉันได้ติดตามพารามิเตอร์ในการใช้งานของผู้เขียนอย่างใกล้ชิดที่สุด
ฉันใช้ขนาดแบทช์ 10 ประโยค ฉันใช้การไล่ระดับสีแบบสุ่มด้วยโมเมนตัม อัตราการเรียนรู้ลดลงทุกยุค ฉันใช้ถุงมือ 100D pretrained embeddings โดยไม่ต้องปรับแต่ง
ใช้เวลาประมาณ 80 ในการฝึกฝนยุคหนึ่งบน Titan X (Pascal)
คะแนน F1 ในชุดการตรวจสอบความถูกต้องสูงถึง 91% รอบ Epoch 50 และสูงสุดที่ 91.6% ใน Epoch 171 ฉันวิ่งไปรวม 200 Epochs นี่ค่อนข้างใกล้เคียงกับผลลัพธ์ในกระดาษ
คุณสามารถดาวน์โหลดรุ่นที่ผ่านการฝึกอบรมนี้ได้ที่นี่
เราจะตัดสินใจได้อย่างไรว่าเราต้องการ <start> และ <end> โทเค็นสำหรับโมเดลที่ใช้ลำดับหรือไม่?
หากสิ่งนี้ดูเหมือนจะสับสนในตอนแรกมันจะแก้ไขตัวเองได้อย่างง่ายดายเมื่อคุณคิดถึงข้อกำหนดของโมเดลที่คุณวางแผนจะฝึกอบรม
สำหรับการติดฉลากลำดับด้วย CRF คุณต้องใช้โทเค็น <end> ( หรือ โทเค็น <start> ; ดูคำถามถัดไป) เนื่องจากคะแนน CRF มีโครงสร้างอย่างไร
ในบทช่วยสอนอื่น ๆ ของฉันเกี่ยวกับคำบรรยายภาพฉันใช้ ทั้ง <start> และ <end> โทเค็น แบบจำลองที่จำเป็นในการเริ่มถอดรหัส ที่ไหนสักแห่ง และเรียนรู้ที่จะรับรู้ว่าจะหยุดการถอดรหัส เมื่อใด ในระหว่างการอนุมาน
หากคุณกำลังดำเนินการจำแนกประเภทข้อความคุณจะไม่จำเป็น
เราสามารถให้ CRF สร้างคะแนน current_word -> next_word แทนคะแนน previous_word -> current_word ได้หรือไม่?
ใช่. ในกรณีนี้คุณจะออกอากาศคะแนนการปล่อยเช่น L, m, _ และคุณจะมีโทเค็น <start> ในทุกประโยคแทนที่จะเป็นโทเค็น <end> แท็กที่ถูกต้องของโทเค็น <start> จะเป็นแท็ก <start> เสมอ "แท็กถัดไป" ของคำสุดท้ายจะเป็นแท็ก <end> เสมอ
ฉันคิดว่า previous word -> current word ดีกว่าเล็กน้อยเพราะมีแบบจำลองภาษาในการผสม มันเหมาะอย่างยิ่งที่จะสามารถทำนายโทเค็น <end> ในคำจริงสุดท้ายและดังนั้นจึงเรียนรู้ที่จะรับรู้เมื่อประโยคเสร็จสมบูรณ์
เหตุใดเราจึงใช้คำศัพท์ที่แตกต่างกันสำหรับอินพุตของ Sequence Tagger และเอาต์พุตของโมเดลภาษา?
แบบจำลองภาษาจะเรียนรู้ที่จะทำนายเฉพาะคำเหล่านั้นที่เห็นในระหว่างการฝึกอบรม มันไม่จำเป็นจริง ๆ และการคำนวณและหน่วยความจำที่เสียไปอย่างมากในการใช้เลเยอร์เชิงเส้น-ซอฟท์แม็กซ์ที่มีคำพิเศษ ~ 400,000 นอกคอร์ปัสจากไฟล์ฝังตัวมันจะไม่เรียนรู้ที่จะทำนาย
แต่เรา สามารถ เพิ่มคำเหล่านี้ลงในเลเยอร์อินพุตได้แม้ว่าโมเดลจะไม่เห็นพวกเขาในระหว่างการฝึกอบรม นี่เป็นเพราะเราใช้การฝังตัวที่ผ่านการฝึกอบรมมาก่อนที่อินพุต ไม่ จำเป็น ต้องเห็นพวกเขาเพราะความหมายของคำถูกเข้ารหัสในเวกเตอร์เหล่านี้ หากพบลิง chimpanzee มาก่อนมันน่าจะรู้ว่าจะทำอย่างไรกับ orangutan
เป็นความคิดที่ดีที่จะปรับแต่งคำที่ผ่านการฝึกอบรมมาก่อนที่เราใช้ในรุ่นนี้หรือไม่?
ฉันละเว้นจากการปรับแต่งเพราะคำศัพท์ส่วนใหญ่ไม่ได้เป็นใน Corpus Most embeddings will remain the same while a few are fine-tuned. If fine-tuning changes these embeddings sufficiently, the model may not work well with the words that weren't fine-tuned. In the real world, we're bound to encounter many words that weren't present in a newspaper corpus from 2003.
What are some ways we can construct dynamic graphs in PyTorch to compute over only the true lengths of sequences?
If you're using an RNN, simply use pack_padded_sequence() . PyTorch will internally compute over only the true lengths. See dynamic_rnn.py for an example.
If you want to execute an operation (like a linear transformation) only on the true timesteps, pack_padded_sequences() is still the way to go. This flattens the tensor by timestep while removing the pads. You can perform your operation on this flattened tensor, and then use pad_packed_sequence() to unflatten it and re-pad it with 0 s.
Similarly, if you want to perform an aggregation operation, like computing the loss, use pack_padded_sequences() to eliminate the pads.
If you want to perform timestep-wise operations, you can take a leaf out of how pack_padded_sequences() works, and compute only on the effective batch size at each timestep with a for loop to iterate over the timesteps. We did this in the ViterbiLoss and ViterbiDecoder . I also used an LSTMCell() in this fashion in my image captioning tutorial.
Dunston Checks In ? จริงหรือ
I had no memory of this movie for twenty years. I was trying to think of a short sentence that would be easier to visualize in this tutorial and it just popped into my mind riding a wave of 90s nostalgia.

I wish I hadn't googled it though. Damn, the critics were harsh, weren't they? This gem was overwhelmingly and universally panned. I'm not sure I'd disagree if I watched it now, but that just goes to show the world is so much more fun when you're a kid.
Didn't have to worry about LM-LSTM-CRFs or nuthin...


