a PyTorch Tutorial to Sequence Labeling
1.0.0
이것은 순서 라벨링을위한 Pytorch 튜토리얼 입니다.
이것은 놀라운 Pytorch 라이브러리를 사용하여 멋진 모델을 직접 구현하는 것에 대해 작성하는 일련의 튜토리얼에서 두 번째입니다.
Pytorch, 재발 성 신경망에 대한 기본 지식이 가정됩니다.
Pytorch를 처음 사용하는 경우 먼저 Pytorch : 60 분 블리츠와 학습 Pytorch를 사용하여 딥 러닝을 읽으십시오.
질문, 제안 또는 수정 사항은 문제로 게시 할 수 있습니다.
Python 3.6 에서 PyTorch 0.4 사용하고 있습니다.
2020 년 1 월 27 일 : 두 개의 새로운 튜토리얼에 대한 작업 코드가 추가되었습니다.
목적
개념
개요
구현
훈련
자주 묻는 질문
각 단어를 실체, 연설의 일부 및 등으로 태그 할 수있는 모델을 구축하려면.

우리는 작업 인식 신경 언어 모델 용지로 Empower 시퀀스 라벨링을 구현할 것입니다. 이것은 대부분의 시퀀스 태그 모델보다 더 발전하지만 많은 유용한 개념을 배우게 될 것이며 매우 잘 작동합니다. 저자의 원래 구현은 여기에서 찾을 수 있습니다.
이 모델은 언어 모델과 동시에 교육하여 시퀀스 레이블링 작업을 증대하기 때문에 특별합니다.
시퀀스 라벨링 . 듀.
언어 모델 . 언어 모델링은 단어 나 문자 순서로 다음 단어 나 문자를 예측하는 것입니다. 신경 언어 모델은 텍스트 생성, 기계 번역, 이미지 캡션, 광학 문자 인식 및 귀하와 같은 다양한 NLP 작업에서 인상적인 결과를 얻습니다.
캐릭터 rnns . 텍스트에서 개별 문자로 작동하는 RNN은 기본 스타일과 구조를 포착하는 것으로 알려져 있습니다. 순서 라벨링 작업에서, 하위 단어 정보는 종종 엔티티 나 태그에 중요한 단서를 얻을 수 있기 때문에 특히 유용합니다.
멀티 태스킹 학습 . 모델을 훈련시키는 데 사용할 수있는 데이터 세트는 종종 작습니다. 모델을 돕기 위해 주석이나 수제 기능을 작성하는 것은 성가신 일뿐 만 아니라 모델이 유용한 다양한 도메인이나 설정에 적응할 수없는 경우가 많습니다. 불행히도 시퀀스 라벨링이 대표적인 예입니다. 이 문제를 완화하는 방법이 있습니다. 고관절에 결합 된 여러 모델을 공동으로 훈련하면 각 모델에 사용 가능한 정보가 최대화되어 성능이 향상됩니다.
조건부 임의의 필드 . 불연속 분류기는 단어에서 클래스 또는 레이블을 예측합니다. 조건부 임의의 필드 (CRF)는 당신을 더 잘 할 수 있습니다 - 그들은 단어뿐만 아니라 이웃에 따라 라벨을 예측합니다. 일련의 엔티티 또는 레이블에 패턴이 있기 때문에 의미가 있습니다. CRF는 순서 표지, 유전자 시퀀싱 또는 컴퓨터 비전에서 객체 감지 및 이미지 세분화에 대한 정렬 정보를 모델링하는 데 널리 사용됩니다.
Viterbi 디코딩 . 우리는 CRF를 사용하고 있기 때문에 단어 시퀀스에 대한 올바른 레이블 시퀀스를 예측할 때 각 단어에서 올바른 레이블을 예측하지는 않습니다. Viterbi Decoding은이 작업을 정확하게 수행하는 방법입니다. 조건부 랜덤 필드로 계산 된 점수에서 가장 최적의 태그 시퀀스를 찾으십시오.
고속도로 네트워크 . 완전히 연결된 층은 다른 위치에서 기능을 변환하거나 추출하기 위해 모든 신경망의 필수 요소입니다. 고속도로 네트워크는이를 달성하지만 정보가 변형에 걸쳐 방해받지 않도록합니다. 이것은 깊은 네트워크를 훨씬 더 효율적이거나 실행 가능하게 만듭니다.
이 섹션에서는이 모델에 대한 개요를 제시하겠습니다. 이미 익숙한 경우 구현 섹션 또는 주석 코드로 바로 건너 뛸 수 있습니다.
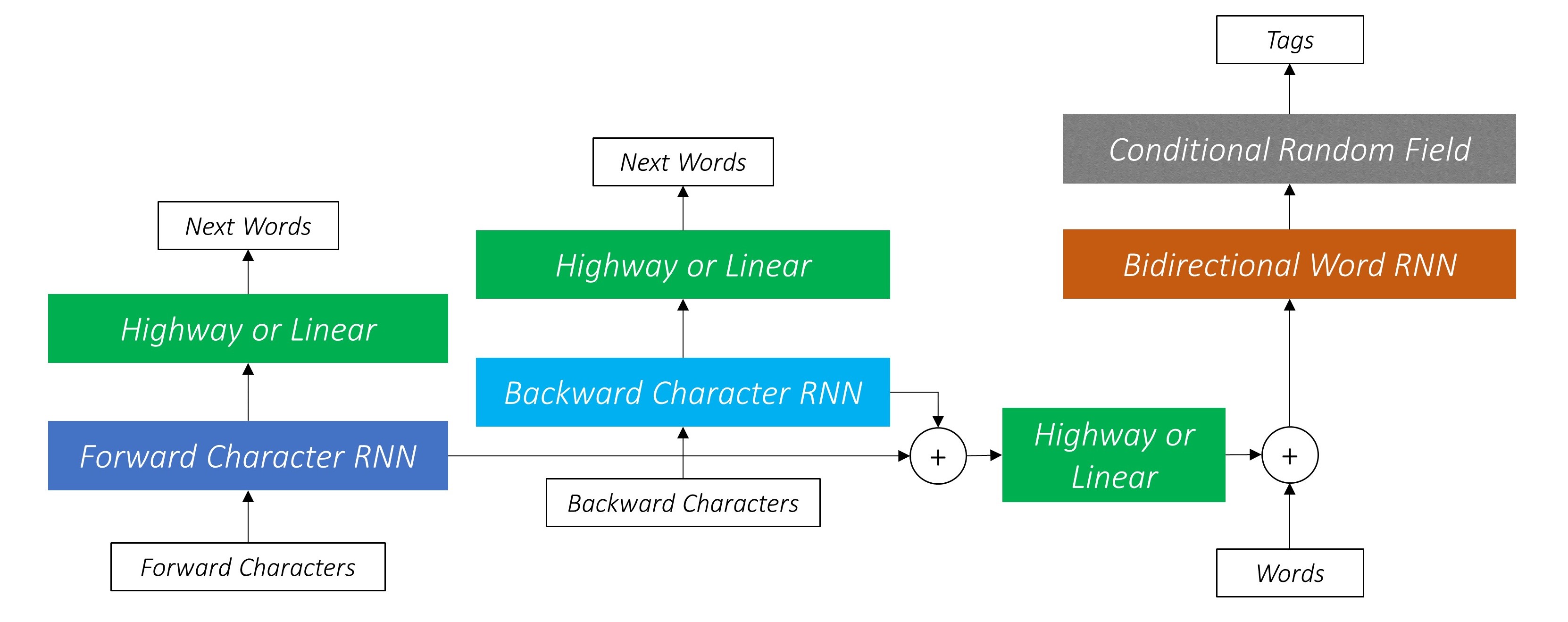
저자는 모델을 LSTM + CRF 조합으로 언어 모델을 공동 트레이닝하는 언어 모델 - 조건부 임의의 필드 라고 말합니다.
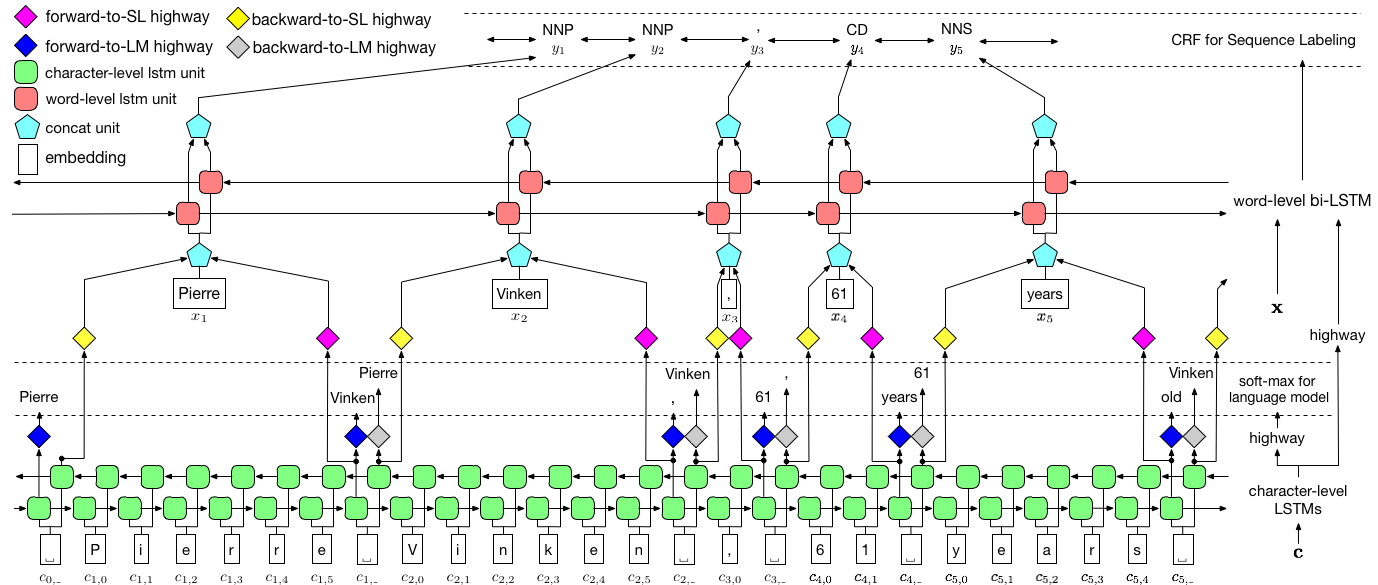
이 논문 의이 이미지는 전체 모델을 철저히 나타내지 만 현재 너무 복잡해 보이는지 걱정하지 마십시오. 우리는 구성 요소를 자세히 살펴보기 위해 그것을 분해합니다.
멀티 태스킹 학습은 두 개 이상의 작업에 대한 모델을 동시에 훈련시킬 때입니다.
일반적으로 우리는 이러한 작업 중 하나에 만 관심이 있습니다.이 경우 시퀀스 레이블링입니다.
그러나 신경망의 계층이 여러 기능을 수행하는 데 기여할 때, 기본 작업에 대해서만 훈련 된 경우보다 더 많은 것을 배웁니다. 이는 각 계층에서 추출 된 정보가 확장되어 모든 작업을 수용하기 때문입니다. 작업 할 정보가 더 있으면 기본 작업의 성능이 향상됩니다 .
이러한 방식으로 기존 기능을 풍부하게하면 서열 레이블링을 위해 수제 기능을 사용해야합니다.
멀티 태스킹 학습 중 총 손실은 일반적으로 개별 작업의 손실의 선형 조합입니다. 조합의 매개 변수는 업데이트 가능한 가중치로 고정되거나 배울 수 있습니다.

우리는 개별 손실을 집계하고 있기 때문에 여러 작업에서 공유하는 업스트림 계층이 역전 중에 모든 작업에서 업데이트를받는 방법을 알 수 있습니다.
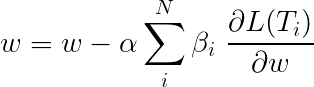
이 논문의 저자는 단순히 손실 ( β=1 )을 추가하면 우리는 동일하게 할 것입니다.
모델을 구성하는 작업을 살펴 보겠습니다.
세 가지 가 있습니다 .

이것은 하위 단어 정보를 활용하여 다음 단어를 예측합니다.
우리는 뒤로 방향으로 똑같이합니다. 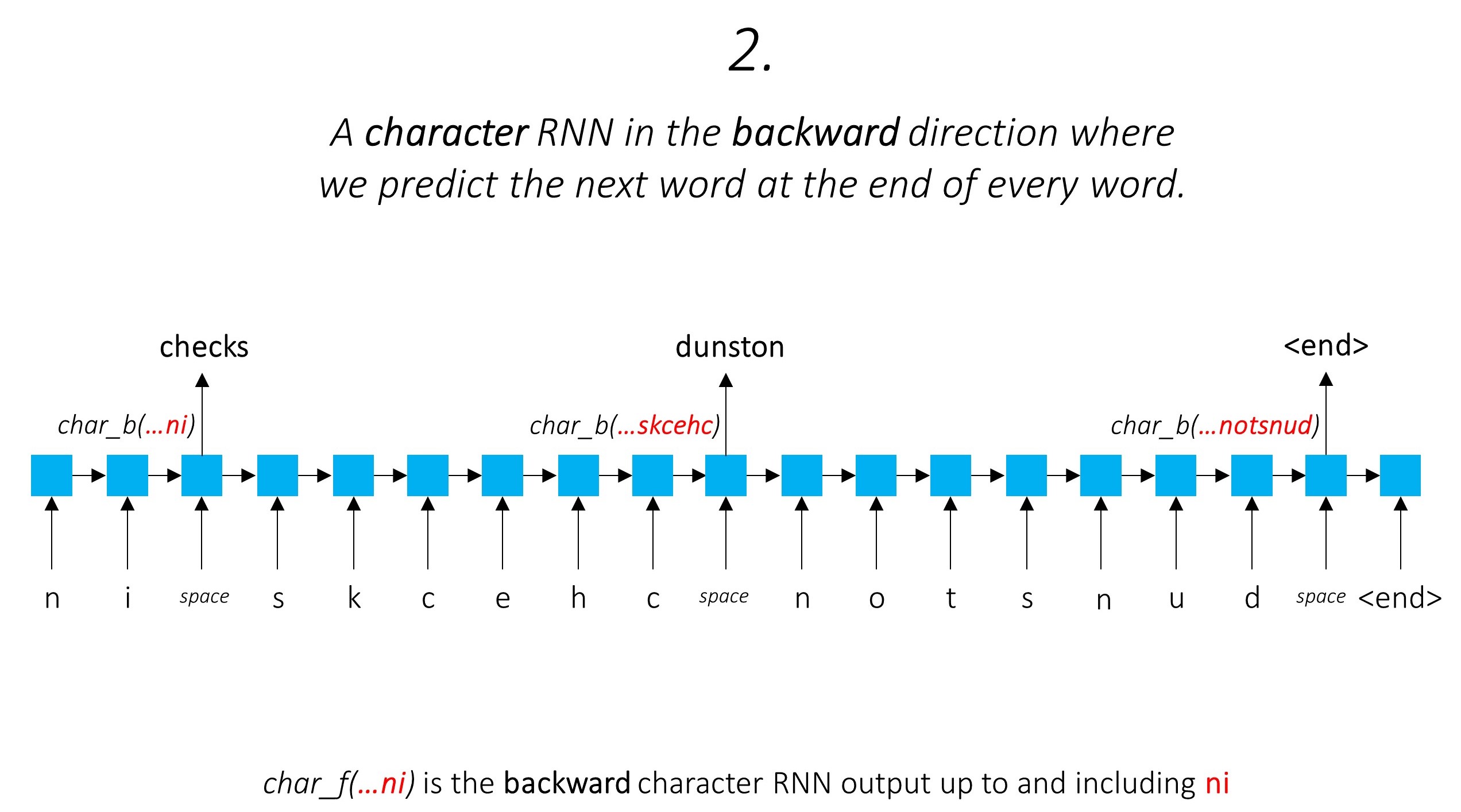
또한 이 두 문자 RNN 의 출력을 Word-RNN 에 대한 입력 및 조건부 랜덤 필드 (CRF) 로 사용하여 기본 서열 레이블링을 수행합니다. 
우리는 태깅 작업에서 하위 단어 정보를 사용하고 있습니다. 왜냐하면 태그의 일부 또는 엔티티의 일부에 관계없이 태그의 강력한 지표가 될 수 있기 때문입니다. 예를 들어, 형용사는 일반적으로 "-y"또는 "-ul"으로 끝나거나 종종 "-land"또는 "-burg"로 끝나는 것을 알 수 있습니다.
그러나 우리의 하위 단어 기능, 즉. 문자 RNN의 출력에는 추가 정보가 풍부합니다. 모델 1과 2로 인해 다음 단어를 앞뒤 방향으로 예측하는 데 필요한 지식이 있습니다.
따라서 시퀀스 태깅 모델은 두 가지를 모두 사용합니다
양방향 LSTM/RNN은 단어 수준과 문자 수준 모두에서 단어와 이웃에 대한 정보가 포함 된 각 단어의 새로운 기능으로 이러한 기능을 인코딩합니다. 이것은 조건부 랜덤 필드에 대한 입력을 형성합니다.
CRF가 없으면 단순히 단일 선형 레이어를 사용하여 양방향 LSTM의 출력을 각 태그의 점수로 변환했을 것입니다. 이들은 방출 점수 라고하며 단어가 특정 태그가 될 가능성을 나타냅니다.
CRF는 배출 점수뿐만 아니라 전이 점수 도 계산하며, 이는 이전 단어가 특정 태그라는 것을 고려할 때 특정 태그가 될 가능성입니다. 따라서 전환 점수는 한 태그에서 다른 태그로 전환 할 가능성을 측정합니다.
m 태그가있는 경우, 전환 점수는 다임션 m, m 의 행렬에 저장되며, 여기서 행은 이전 단어의 태그를 나타내고 열은 현재 단어의 태그를 나타냅니다. 위치 i, j 에서이 행렬의 값은 이전 단어의 i th 태그에서 현재 단어의 j th 태그로 전환 할 가능성 입니다. 배출 점수와 달리, 문장의 각 단어에 대해 전환 점수가 정의되지 않습니다. 그들은 글로벌입니다.
우리 모델에서 CRF 층은 각 단어에서 방출 및 전환 점수의 집계를 출력합니다.
길이 L 의 문장의 경우, 방출 점수는 L, m 텐서가 될 것입니다. 각 단어의 배출 점수는 이전 단어의 태그에 의존하지 않기 때문에 L, _, m 및 Broadcast (복사)이 방향을 따라 텐서를 방송 (복사)하여 L, m, m 텐서를 얻습니다.
전환 점수는 m, m 텐서입니다. 전환 점수는 글로벌이며 단어에 의존하지 않기 때문에 _, m, m 및 방송 (복사)과 같은 새로운 차원을 만들어이 방향을 따라 텐서를 방송 (복사)하여 L, m, m 텐서를 얻습니다.
이제 L, m, m Tensor의 총 점수를 얻기 위해 추가 할 수 있습니다. 위치 k, i, j 에서의 값은 k th 단어에서 j th 태그의 배출 점수의 집계 이고 이전 단어가 i th 태그라는 것을 고려할 때 k th 단어에서 j th 태그의 전이 점수의 집계이다.
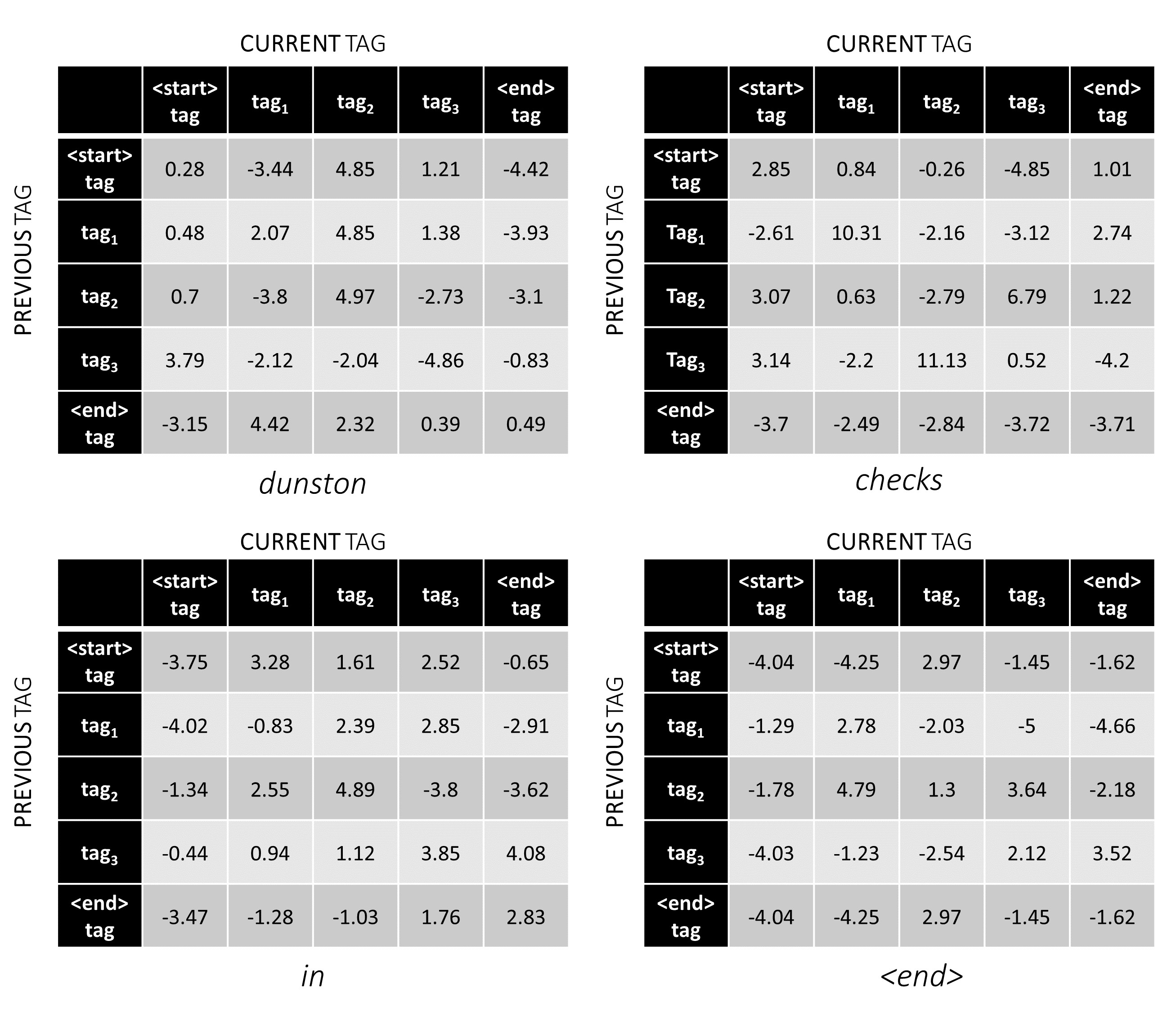
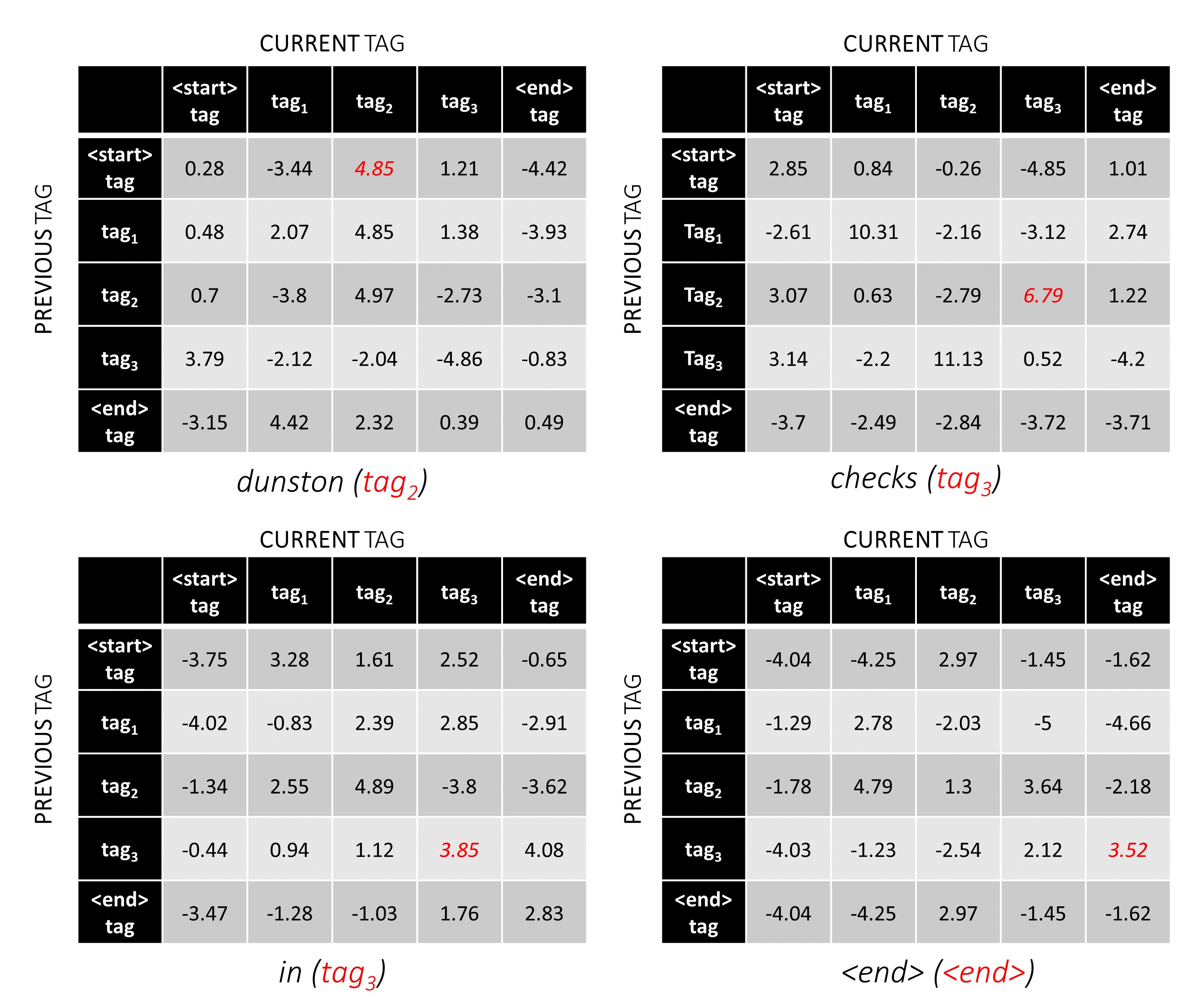
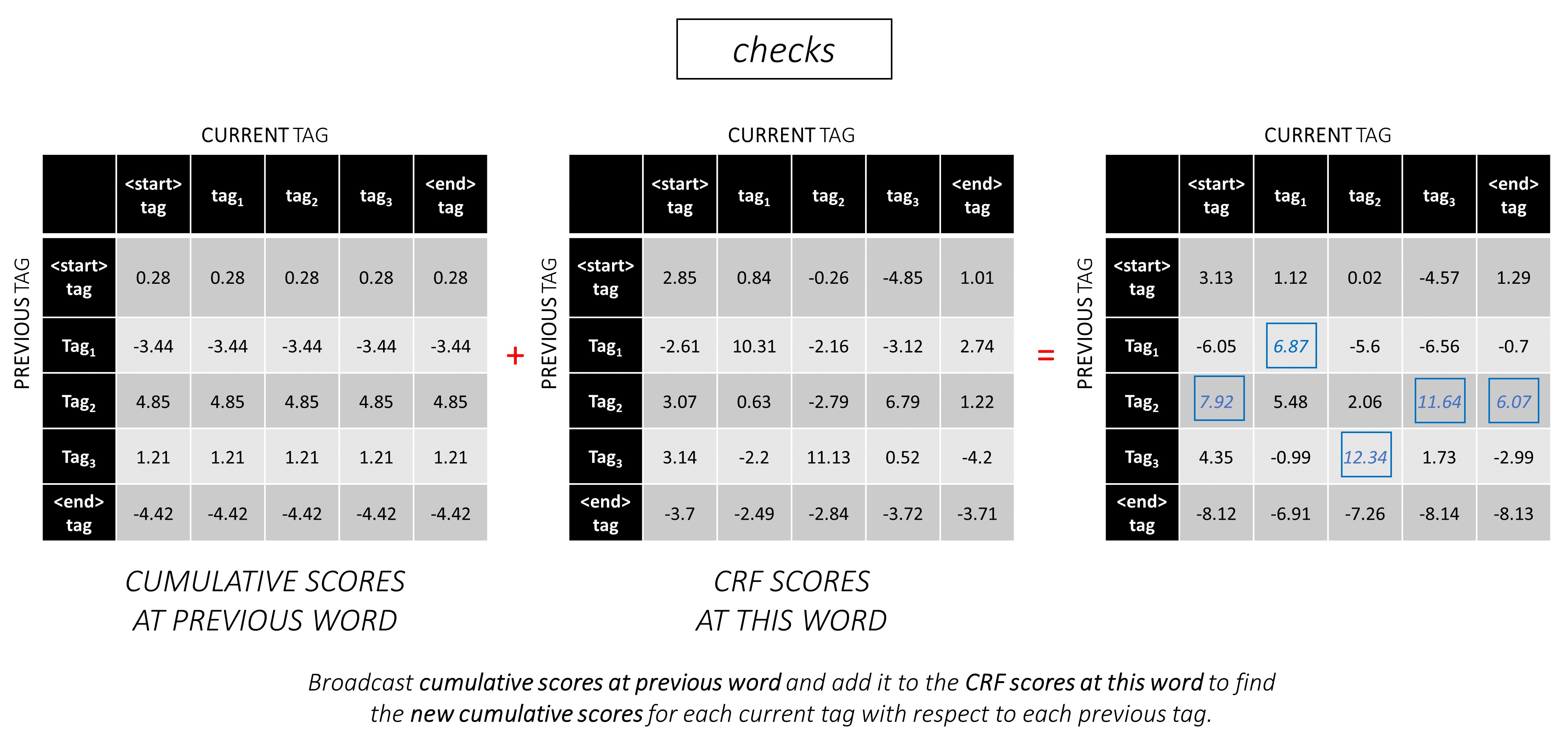
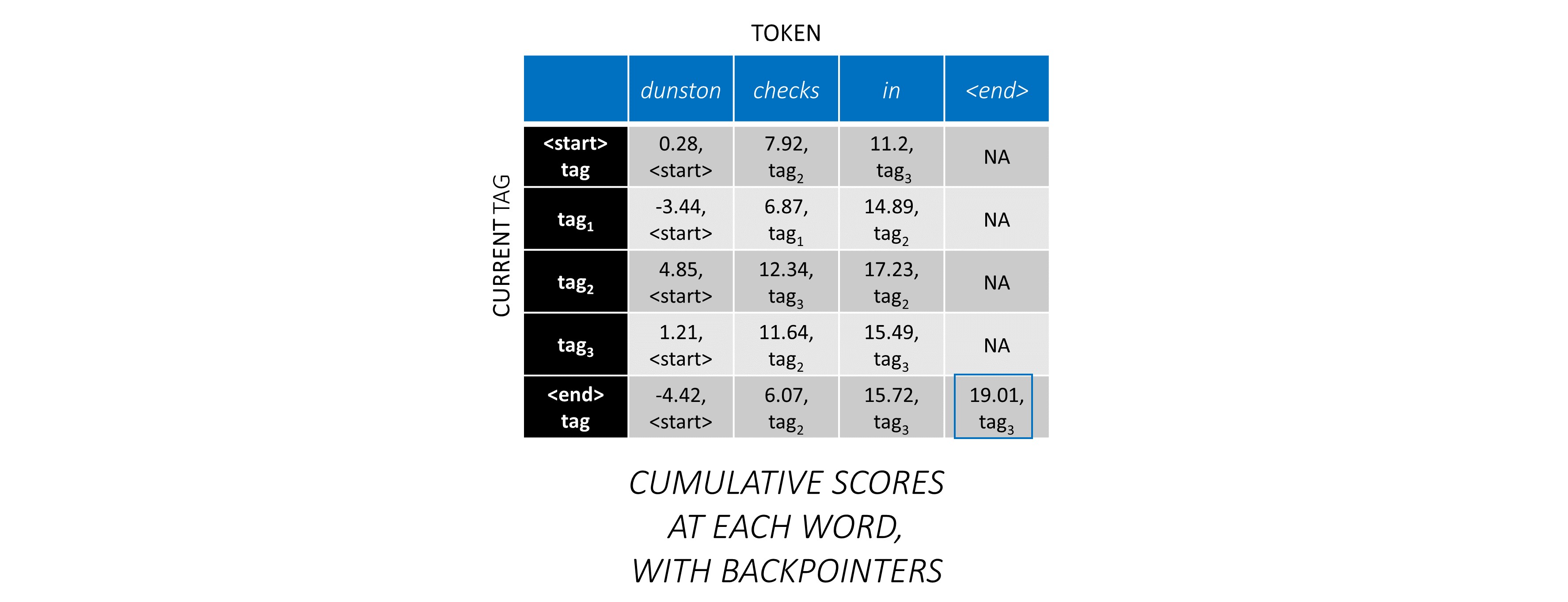
이 예제 문장 dunston checks in <end> , 총 5 개의 태그가 있다고 가정하면 총 점수는 다음과 같습니다.
하지만 잠깐만 요, 왜 <start> end <end> 태그가 있습니까? 우리가 그것에있는 동안, 우리는 왜 <end> 토큰을 사용하고 있습니까?
<start> 및 <end> 태그, <start> 및 <end> 토큰 태그 사이의 전환 가능성을 모델링하고 있기 때문에 태그 세트에 <start> 태그와 <end> 태그도 포함됩니다.
이전 태그가 <start> 태그 였다는 점에서 특정 태그의 전환 점수는 이 태그가 문장에서 첫 번째 태그 일 가능성을 나타냅니다. 예를 들어, 문장은 일반적으로 기사 (a, an, the) 또는 명사 또는 대명사로 시작합니다.
이전 태그를 고려한 <end> 태그의 전환 점수는 이 이전 태그의 가능성이 문장의 마지막 태그 일 가능성을 나타냅니다.
각 단어의 총 CRF 점수는 이전 단어 <start> 태그와 관련하여 정의되기 때문에 모든 문장에서 <end> 토큰 <start> 사용합니다.
<end> 토큰의 올바른 태그는 항상 <end> 태그입니다. 첫 번째 단어의 "이전 태그"는 항상 <start> 태그입니다.
예를 들어, 예제 문장 dunston checks in <end> tag_2, tag_3, tag_3, <end> 가있는 경우, 빨간색의 값은 이러한 태그의 점수를 나타냅니다.
우리는 일반적으로 활성화 된 선형 레이어를 사용하여 RNN/LSTM의 출력을 변환하고 처리합니다.
잔류 연결에 익숙한 경우 변환 전에 변환 된 출력에 입력을 추가하여 변환 주변의 데이터 흐름 경로를 만듭니다.
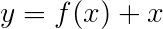
이 경로는 역전 동안 그라디언트의 흐름을위한 단축키이며, 깊은 네트워크의 수렴을 도와줍니다.
고속도로 네트워크는 잔류 네트워크와 유사하지만 Sigmoid 활성화 게이트를 사용하여 입력 및 변환 된 출력이 결합 된 비율을 결정합니다 .
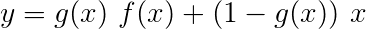
문자 RNN은 여러 작업에 기여하기 때문에 고속도로 네트워크는 출력에서 작업 별 정보를 추출하는 데 사용됩니다 .
따라서 우리는 결합 된 모델의 세 곳 에서 고속도로 네트워크를 사용할 것입니다.
순진한 공동 훈련 설정에서, 우리는 여러 작업에 대해 문자 RNN의 출력을 직접 사용하는 순진한 공동 훈련 설정에서, 즉 변환없이 작업의 특성 사이의 불일치가 성능을 손상시킬 수 있습니다.
이제 우리의 결합 된 네트워크의 모습이 분명 할 수 있습니다.
네트워크의 일부를 점차 제거하면 서열 레이블에 널리 사용되는 점진적으로 더 간단한 네트워크가 발생합니다.
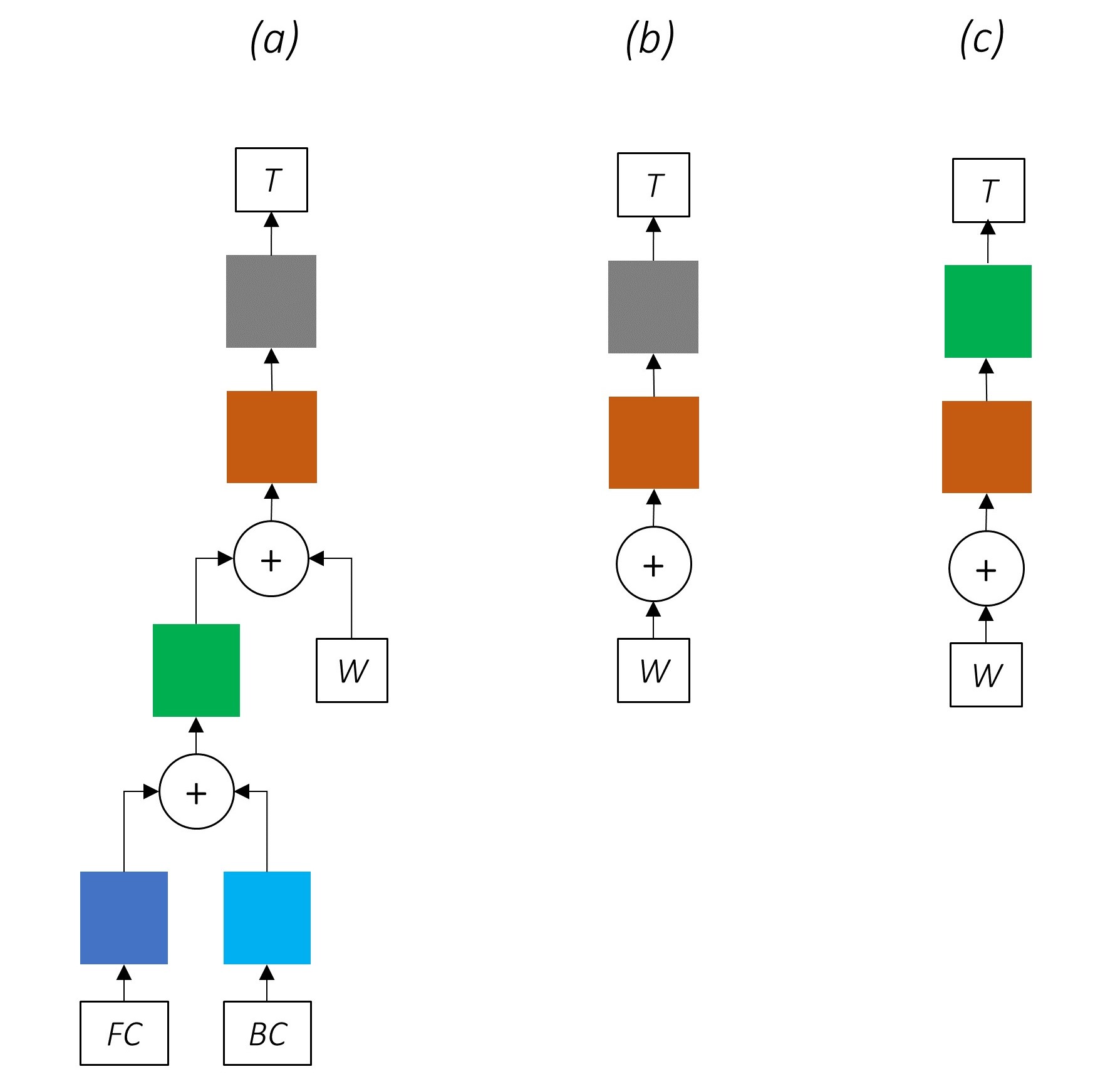
멀티 태스킹 학습은 없습니다.
공동 훈련없이 문자 수준 정보를 사용하면 여전히 성능이 향상됩니다.
멀티 태스킹 학습 또는 문자 수준 처리는 없습니다.
이 구성은 업계에서 매우 일반적으로 사용되며 잘 작동합니다.
멀티 태스킹 학습, 문자 수준 처리 또는 CRFING은 없습니다. 선형 또는 고속도로 층은 후자를 대체합니다.
이것은 합리적으로 잘 작동 할 수 있지만 조건부 임의의 필드는 상당한 성능 향상을 제공합니다.
방출 점수 만 계산하는 선형 레이어를 사용하지 않습니다. 크로스 엔트로피는 적합한 손실 메트릭이 아닙니다.
대신 우리는 크로스 엔트로피와 같이 "음의 로그 가능성"인 viterbi 손실을 사용할 것입니다. 그러나 여기서 우리는 순서대로 각 단어에서 실제 태그의 가능성 대신 금 (True) 태그 시퀀스의 가능성을 측정 할 것입니다. 가능성을 찾기 위해 모든 태그 시퀀스의 점수보다 SoftMax를 고려합니다.
태그 시퀀스 t 의 점수는 개별 태그의 점수의 합으로 정의됩니다.

예를 들어, 이전에 본 CRF 점수를 고려하십시오.
태그 시퀀스 tag_2, tag_3, tag_3, <end> tag 의 점수는 빨간색, 4.85 + 6.79 + 3.85 + 3.52 = 19.01 의 값의 합입니다.
그런 다음 Viterbi 손실은 다음과 같이 정의됩니다
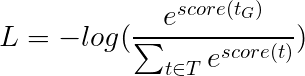
여기서 t_G 는 금 태그 시퀀스이고 T 가능한 모든 태그 시퀀스의 공간을 나타냅니다.
이것은 단순화 -
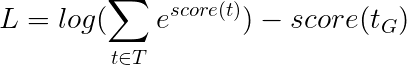
따라서, Viterbi 손실은 가능한 모든 태그 시퀀스의 점수의 로그 -Sum-EXP와 금 태그 시퀀스의 점수 , 즉 log-sum-exp(all scores) - gold score 차이입니다.
Viterbi 디코딩은 특정 단어 (방출 점수)에서 태그의 가능성뿐만 아니라 이전 및 다음 태그 (전환 점수)를 고려한 태그의 가능성을 고려할 때 가장 최적의 태그 시퀀스를 구성하는 방법입니다.
길이 L 시퀀스에 대해 L, m, m 매트릭스에서 CRF 점수를 생성하면 디코딩을 시작합니다.
Viterbi 디코딩은 예를 통해 가장 잘 이해됩니다. 다시 고려하십시오 -
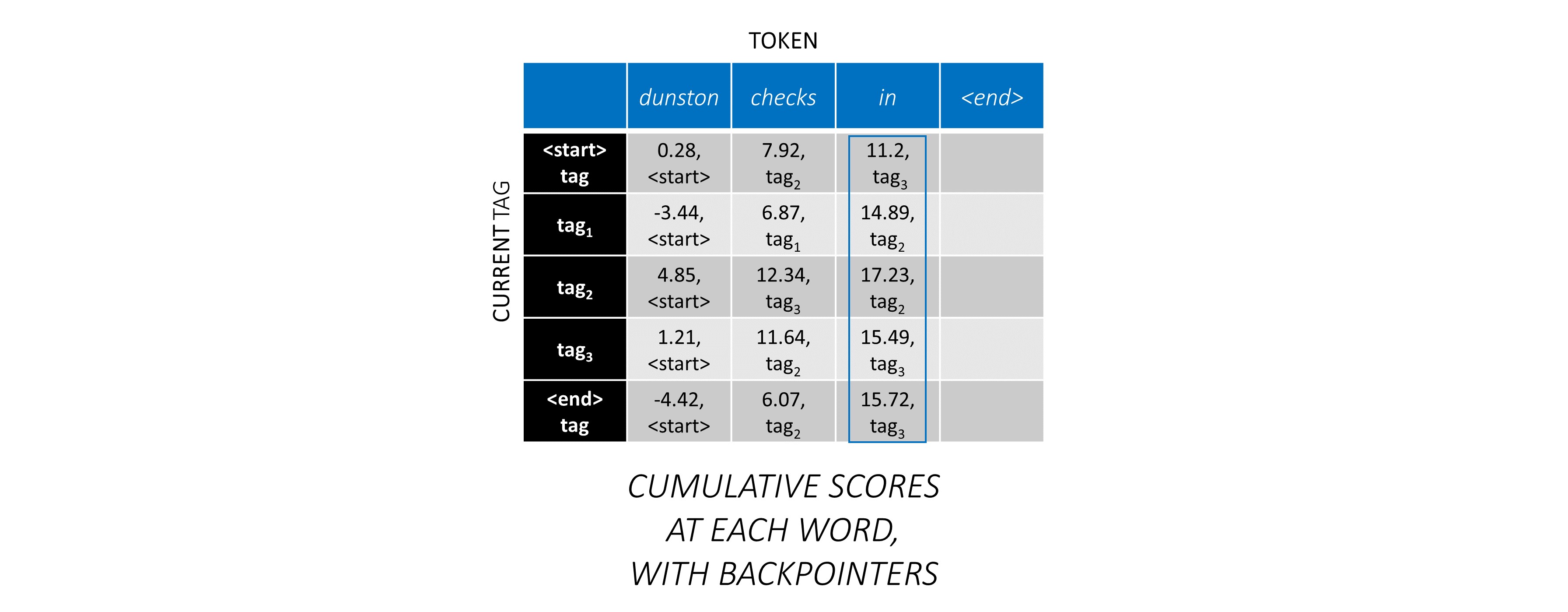
순서대로 첫 번째 단어의 경우 previous_tag 는 <start> 만 될 수 있습니다. 따라서 한 행만 고려하십시오.
이것들은 또한 첫 번째 단어에서 각 current_tag 에 대한 누적 점수입니다.
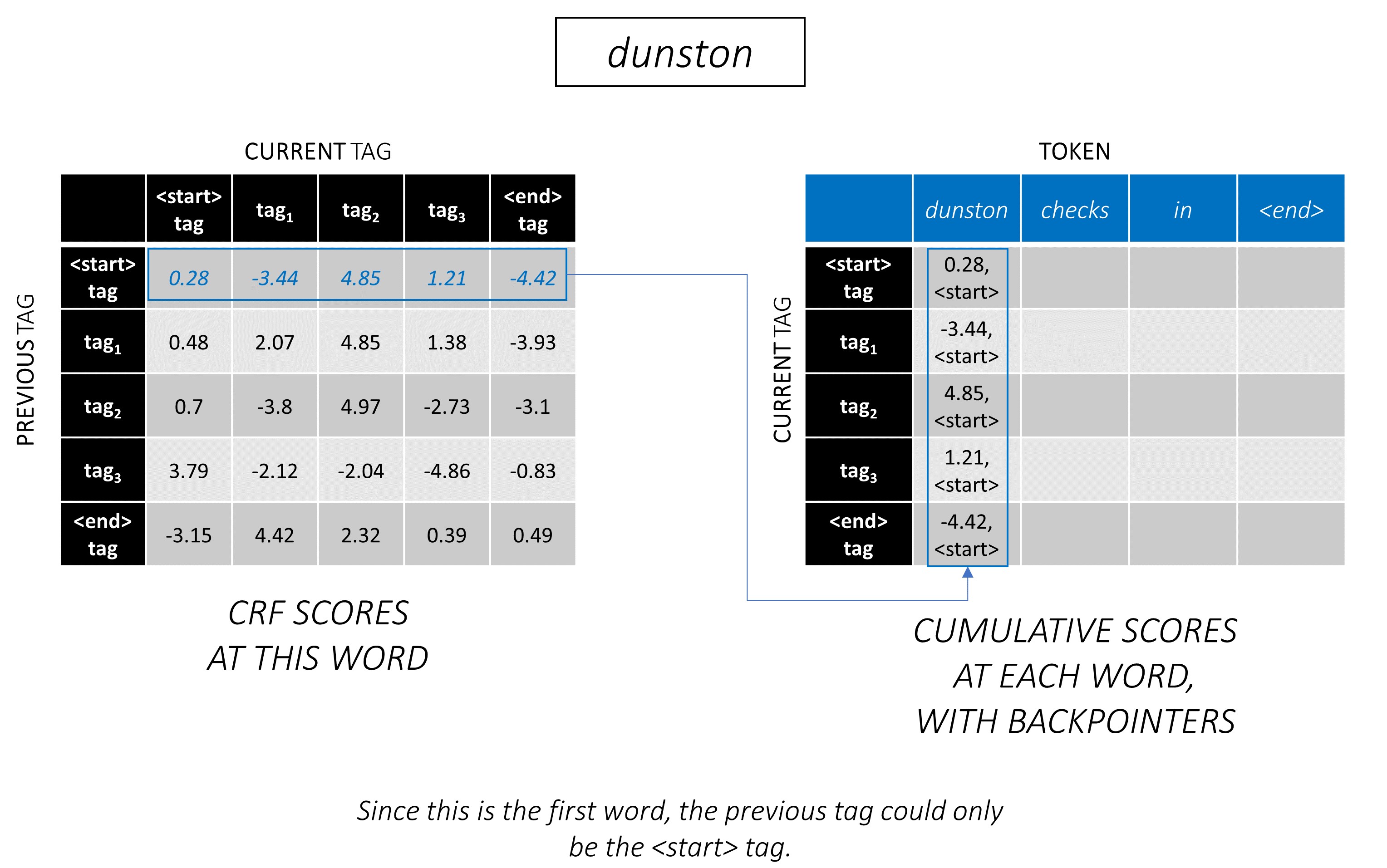
또한 각 점수에 해당하는 previous_tag 를 추적합니다. 이것들을 배포기 라고합니다. 첫 번째 단어에서는 분명히 모든 <start> 태그입니다.
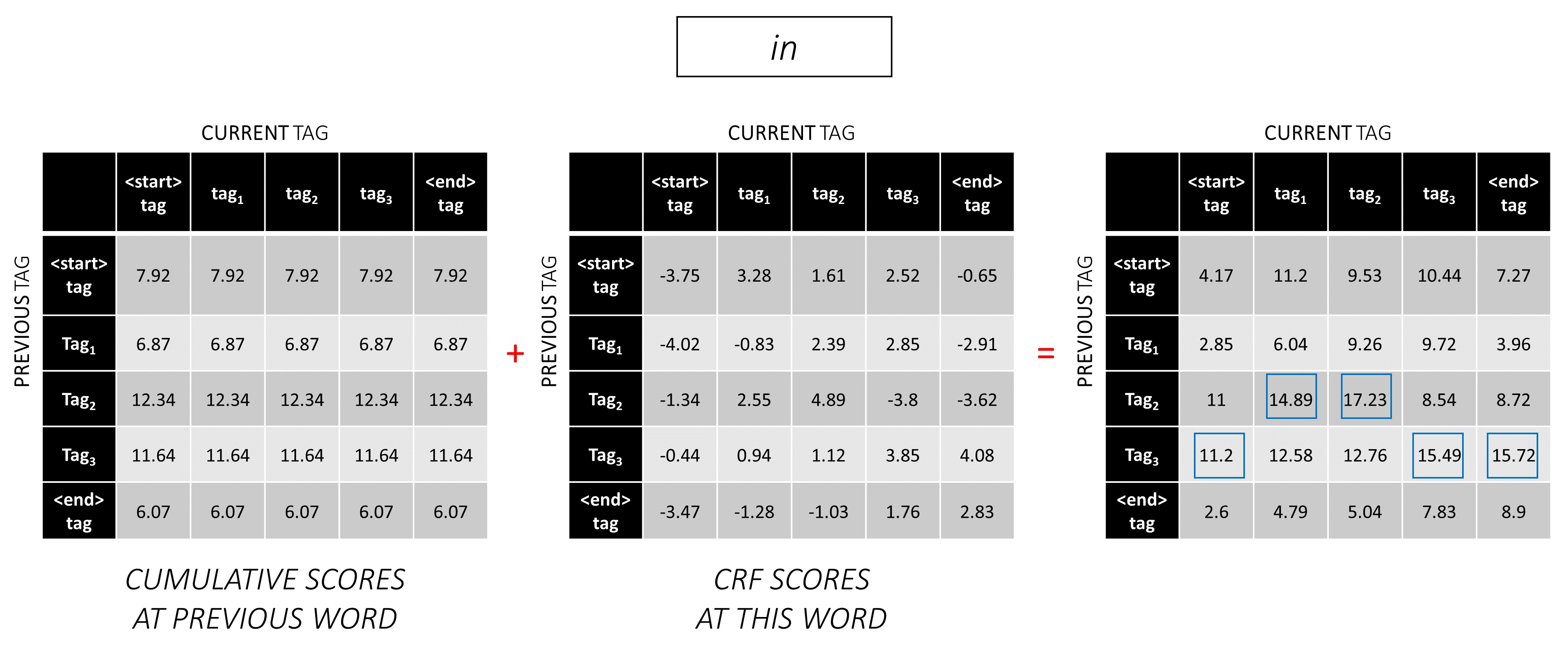
두 번째 단어에서는 이전 누적 점수를이 단어의 CRF 점수에 추가하여 새로운 누적 점수를 생성합니다 .
첫 번째 단어의 current_tag s는 두 번째 단어의 previous_tag s입니다. 따라서 current_tag Dimension을 따라 첫 번째 단어의 누적 점수를 방송합니다.
각각의 current_tag 에 대해, 모든 previous_tag 의 점수의 최대 값 만 고려하십시오.
배포기를 저장하십시오. 즉, 이러한 최대 점수에 해당하는 이전 태그.

세 번째 단어 에서이 과정을 반복하십시오.
... 그리고 마지막 단어는 <end> 토큰입니다.
여기서 유일한 차이점은 이미 올바른 태그를 알고 있다는 것입니다. <end> 태그에 대해서만 최대 점수와 백포인이 필요합니다.
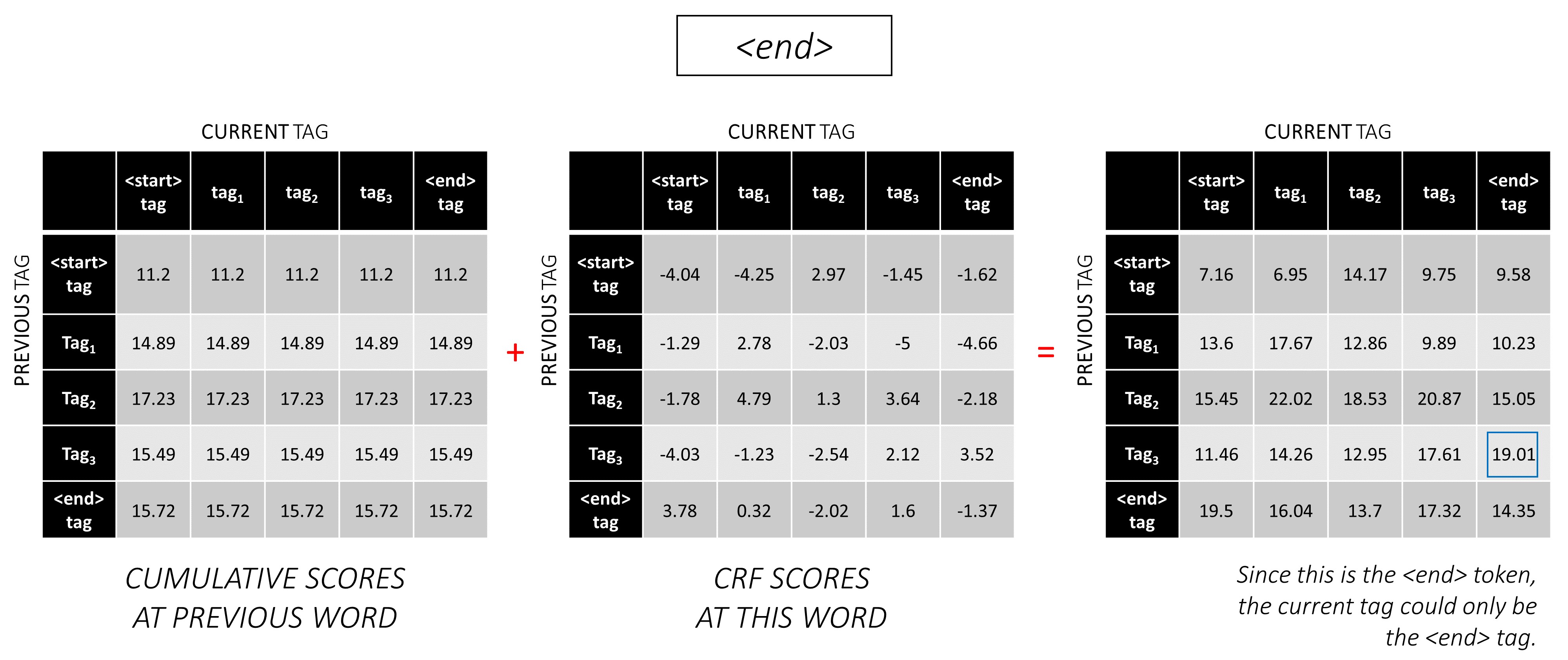
이제 전체 시퀀스에서 CRF 점수를 누적 했으므로, 가능한 가장 높은 점수로 태그 시퀀스를 공개하기 위해 뒤로 추적합니다 .
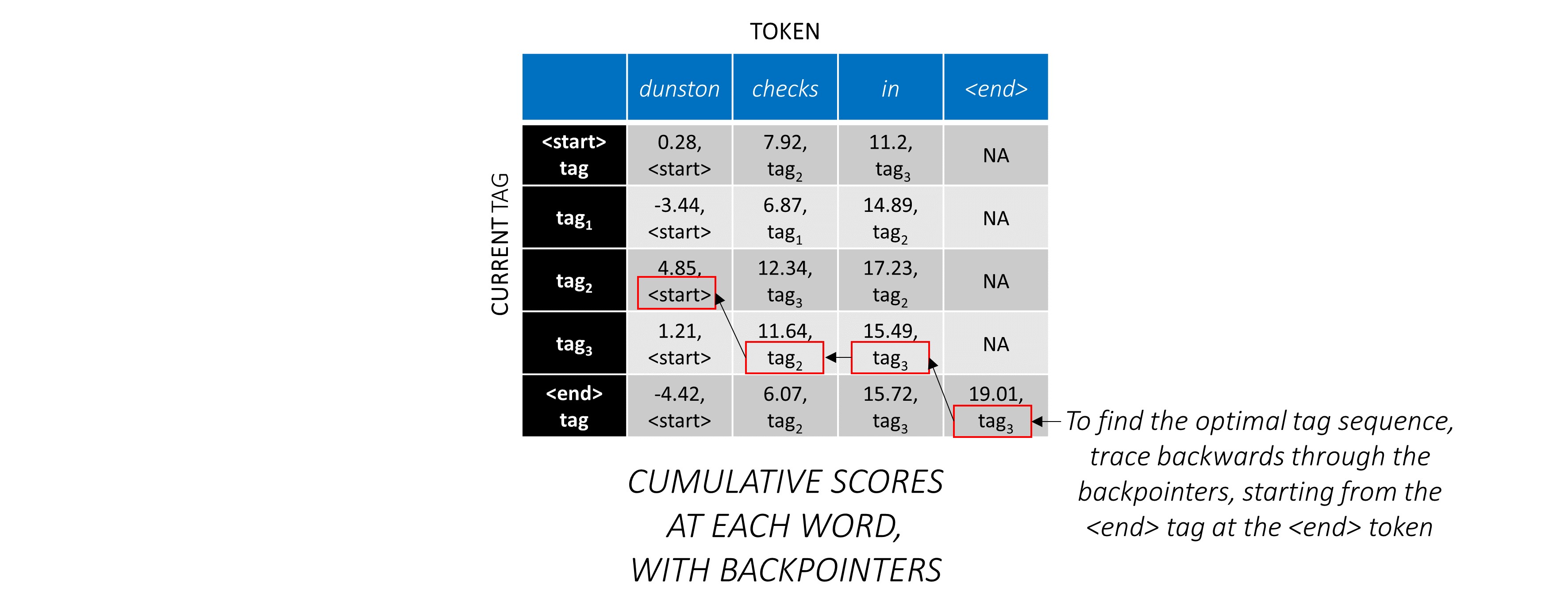
dunston checks in <end> 대한 가장 최적의 태그 시퀀스는 tag_2 tag_3 tag_3 <end> 입니다.
아래 섹션은 구현을 간단히 설명합니다.
그것들은 어떤 맥락을 제공하기위한 것이지만, 세부 사항은 코드에서 직접 이해되는 것이 가장 좋습니다 .
Conll 2003 NER 데이터 세트를 사용하여 결과와 논문을 비교합니다.
여기 스 니펫이 있습니다.
-DOCSTART- -X- O O
EU NNP I-NP I-ORG
rejects VBZ I-VP O
German JJ I-NP I-MISC
call NN I-NP O
to TO I-VP O
boycott VB I-VP O
British JJ I-NP I-MISC
lamb NN I-NP O
. . O O
이 데이터 세트는 온라인에서 어딘가에 찾을 수 있지만 공개적으로 배포 할 수는 없습니다.
온라인으로 모델을 훈련시키는 데 사용할 수있는 몇 가지 공개 데이터 세트가 있습니다. 이것들은 모두 100% 인간 주석이 아니지만 충분합니다.
NER 태깅의 경우 Groningen 의미 은행을 사용할 수 있습니다.
POS 태깅의 경우 NLTK에는 nltk.corpus.treebank.tagged_sents() 로 액세스 할 수있는 작은 데이터 세트가 있습니다.
Conll 2003 NER 데이터 형식으로 변환하거나 데이터 파이프 라인 섹션에서 참조 된 코드를 수정해야합니다.
8 개의 입력이 필요합니다.
이것들은 태그가 있어야하는 단어 시퀀스입니다.
dunston checks in
앞에서 논의한 바와 같이, 우리는 <start> 토큰을 사용하지 않지만 <end> 토큰을 사용해야 합니다 .
dunston, checks, in, <end>
우리는 고정 크기의 텐서로 문장을 전달하기 때문에 <pad> 토큰으로 문장 (자연스럽게 다양한 길이)을 동일한 길이로 패드해야합니다.
dunston, checks, in, <end>, <pad>, <pad>, <pad>, ...
또한 <end> 및 <pad> 토큰을 포함하여 코퍼스의 각 단어에 대한 인덱스 매핑 인 word_map 만듭니다. Pytorch는 다른 라이브러리와 마찬가지로 다른 라이브러리와 마찬가지로 임베딩을 찾거나 예측 된 단어 점수에서 자신의 위치를 식별하기위한 지수로 인코딩 된 단어가 필요합니다.
4381, 448, 185, 4669, 0, 0, 0, ...
따라서 모델에 공급 된 단어 시퀀스는 치수 N, L_w 의 Int 텐서 여야하며, 여기서 N 은 batch_size이고 L_w 단어 시퀀스의 패딩 길이 (일반적으로 가장 긴 단어 시퀀스의 길이)입니다.
이것들은 전방 방향의 캐릭터 시퀀스입니다.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' '
단어 시퀀스의 <end> 토큰과 일치하려면 문자 시퀀스에 <end> 토큰이 필요합니다. 우리는 단어 시퀀스의 각 단어에서 문자 수준 기능을 사용하기 때문에 단어 시퀀스에서 <end> 에 문자 수준 기능이 필요합니다.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>
우리는 또한 그들을 패드해야합니다.
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>, <pad>, <pad>, <pad>, ...
char_map 으로 그들을 인코딩하십시오.
29, 2, 12, 8, 7, 14, 12, 3, 6, 18, 1, 6, 21, 8, 3, 17, 12, 3, 60, 0, 0, 0, ...
따라서, 모델에 공급 된 전방 문자 시퀀스는 치수 N, L_c 의 Int 텐서 여야하며 , 여기서 L_c 는 문자 시퀀스의 패딩 길이 (일반적으로 가장 긴 문자 시퀀스의 길이)입니다.
이것은 전방 시퀀스와 동일하지만 뒤로 처리됩니다. ( <end> 토큰은 여전히 자연스럽게 끝날 것입니다.)
'n', 'i', ' ', 's', 'k', 'c', 'e', 'h', 'c', ' ', 'n', 'o', 't', 's', 'n', 'u', 'd', ' ', <end>, <pad>, <pad>, <pad>, ...
12, 17, 3, 8, 21, 6, 1, 18, 6, 3, 12, 14, 7, 8, 12, 2, 29, 3, 60, 0, 0, 0, ...
따라서 모델에 공급 된 후진 문자 시퀀스는 치수 N, L_c 의 Int 여야합니다 .
이 마커는 특징을 추출하는 문자 시퀀스의 위치 입니다.
우리는 모든 공간의 끝 ' ' <end> 끝 부분에서 특징을 추출합니다.
전방 문자 순서를 위해, 우리는 -에서 추출합니다.
7, 14, 17, 18
dunston 이후 각각 <end> in checks 입니다. 따라서 우리는 단어 시퀀스에 각 단어에 대한 마커가 있습니다. (그러나 언어 모델에서는 다음 단어를 예측하기 때문에 <end> 에 해당하는 마커를 예측하지 않을 것입니다.)
우리는 이것을 0 초로 채 웁니다. 유효한 지수만큼 우리가 무엇을 배치하는지는 중요하지 않습니다. (패드에서 기능을 추출하지만 사용하지는 않습니다.)
7, 14, 17, 18, 0, 0, 0, ...
그들은 단어 시퀀스의 L_w 길이에 패딩됩니다.
따라서 모델에 공급 된 전방 문자 마커는 Int N, L_w 의 텐서 여야합니다 .
후진 문자 시퀀스의 마커의 경우, 우리는 마찬가지로 모든 ' ' 의 위치를 찾아 <end> 토큰을 찾습니다.
또한 이러한 위치가 전방 마커에서와 동일한 단어 순서가 되도록합니다. 이러한 정렬을 사용하면 전방 및 후진 문자 시퀀스에서 추출 된 기능을보다 쉽게 연결하고 언어 모델에서 목표를 다시 주문해야합니다.
17, 9, 2, 18
이것은 각각 notsnud , skcehc , ni , <end> 이후의 지점입니다.
우리는 0 초로 패드합니다.
17, 9, 2, 18, 0, 0, 0, ...
따라서 모델에 공급 된 후진 문자 마커는 치수 N, L_w 의 Int 여야합니다 .
dunston, checks, in, <end> 의 올바른 태그를 가정 해 봅시다.
tag_2, tag_3, tag_3, <end>
tag_map (tags <start> , tag_1 , tag_2 , tag_3 , <end> 포함)이 있습니다.
일반적으로, 우리는 단지 (패딩하기 전에) 직접 인코딩합니다.
2, 3, 3, 5
1D 태그 맵의 1D 인코딩, 즉 태그 위치입니다.
그러나 CRF 층의 출력은 각 단어에서 2D m, m 텐서입니다 . 이 2D 출력에서 태그 위치를 인코딩해야합니다.
올바른 태그 위치는 빨간색으로 표시됩니다.
(0, 2), (2, 3), (3, 3), (3, 4)
이 점수를 1D m*m 텐서로 풀면 끊어지지 않은 텐서의 태그 위치는 다음과 같습니다.
tag_map [ previous_tag ] * len ( tag_map ) + tag_map [ current_tag ] 따라서 우리는 tag_2, tag_3, tag_3, <end> 를 인코딩합니다
2, 13, 18, 19
모듈러스를 복용하여 원래 tag_map 지수를 검색 할 수 있습니다.
t % len ( tag_map ) 그것들은 단어 시퀀스의 패딩 길이, L_w 에 패딩 될 것입니다.
따라서 모델에 공급되는 태그는 치수 N, L_w 의 Int 여야합니다 .
<end> 토큰을 포함한 단어 시퀀스의 실제 길이입니다. Pytorch는 동적 그래프를 지원하므로 <pads> 통해서가 아닌이 길이에 대해서만 계산합니다.
따라서 모델에 공급되는 단어 길이는 N 의 Int 가되어야합니다 .
이것들은 <end> 토큰을 포함한 문자 시퀀스의 실제 길이입니다. Pytorch는 동적 그래프를 지원하므로 <pads> 통해서가 아닌이 길이에 대해서만 계산합니다.
따라서 모델에 공급 된 문자 길이는 Int N 의 텐서 여야합니다 .
utils.py 의 read_words_tags() 참조하십시오.
Conll 2003 형식의 입력 파일을 읽고 단어 및 태그 시퀀스를 추출합니다.
utils.py 의 create_maps() 참조하십시오.
여기서는 단어, 문자 및 태그에 대한 인코딩 맵을 만듭니다. We bin rare words and characters as <unk> s (unknowns).
utils.py 의 create_input_tensors() 참조하십시오.
모델 섹션에 대한 입력에 자세한 8 개의 입력을 생성합니다.
utils.py 의 load_embeddings() 참조하십시오.
우리는 미리 훈련 된 임베딩을로드하고, 임베딩 어휘에 존재하는 코퍼스 외 단어를 포함하도록 word_map 을 확장 할 수있는 옵션을로드합니다. Note that this may also include rare in-corpus words that were binned as <unk> s earlier.
datasets.py 의 WCDataset 참조하십시오.
이것은 Pytorch Dataset 의 서브 클래스입니다. 데이터 세트의 크기를 반환하는 __len__ 메소드와 i 개의 입력을 모델에 반환하는 __getitem__ 메소드가 필요합니다.
Dataset train.py 의 Pytorch DataLoader 에서 교육 또는 검증을 위해 모델에 데이터 배치를 생성하고 공급하기 위해 사용됩니다.
models.py 의 Highway 참조하십시오.
변환은 입력의 릴루 활성화 선형 변환입니다. 게이트 는 입력의 시그 모이 드-활성화 선형 변환이다. 잔류 연결에 입력을 추가 할 수 있도록 두 변환은 입력과 동일한 크기 여야합니다 .
num_layers 속성은 직렬로 수행하는 변환-게이트-반응 연결 작업의 수를 지정합니다. 보통 하나만 충분합니다.
필요한 수의 변환 및 게이트 레이어를 별도의 ModuleList() S에 저장하고 연속적인 작업을 수행하기 위해 for 를 사용합니다.
models.py 의 LM_LSTM_CRF 참조하십시오.
바로 그 때, 우리는 길이를 감소시켜 앞뒤로 문자 시퀀스를 분류합니다 . LSTM이 유효한 타임 스텝, 즉 시퀀스의 실제 길이 만 계산하려면 pack_padded_sequence() 사용해야합니다.
같은 순서로 다른 모든 텐서를 정렬해야합니다.
pack_padded_sequence() 사용하여 Pytorch의 동적 그래프 및 배치 기능을 활용하여 패드를 처리하지 않도록 dynamic_rnn.py 참조하십시오. 패드를 무시하는 동안 타임 스텝으로 정렬 된 시퀀스를 평평하게하고 LSTM은 각 타임 스텝에서 유효 배치 크기 N_t 에 대해서만 계산합니다 .
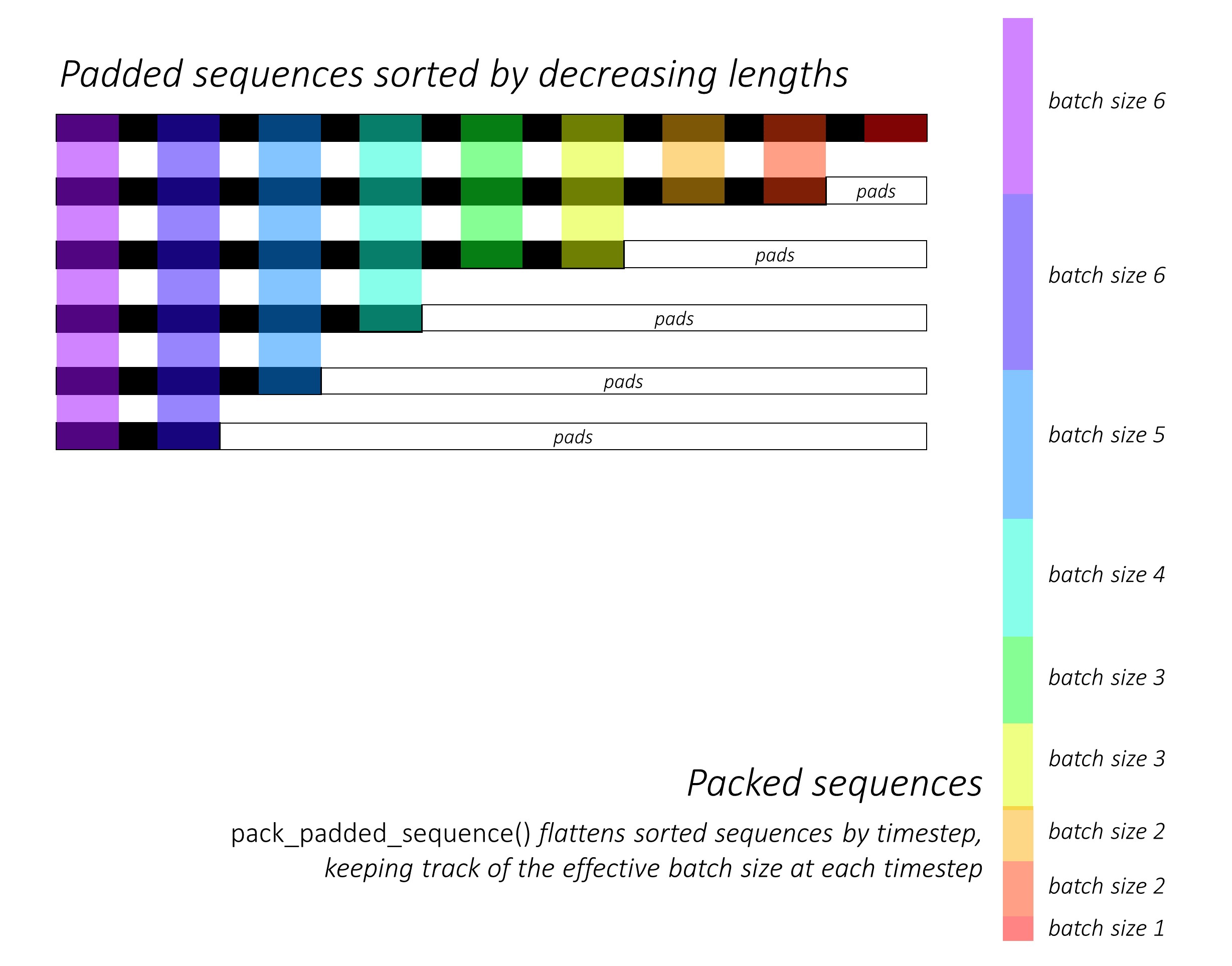
정렬을 통해 모든 타임 스텝에서 상단 N_t 이전 단계의 출력과 정렬 할 수 있습니다 . 예를 들어 세 번째 타임 스텝에서는 이전 단계의 상위 5 개의 출력을 사용하여 상위 5 개의 이미지 만 처리합니다. 정렬을 제외 하고이 모든 것은 Pytorch에 의해 내부적으로 처리되지만 pack_padded_sequence() 무엇을하는지 이해하는 것이 여전히 유용하여 다른 시나리오에서 사용하여 비슷한 끝을 달성 할 수 있습니다. (FAQ 섹션에서 가변 길이 시퀀스를 처리하는 것에 대한 관련 질문을 참조하십시오.)
정렬하면, 우리는 각각 포워드 및 후진 LSTM을 전방 및 후진 packed_sequences 적용합니다 . 우리는 pad_packed_sequence() 사용하여 출력을 방해하지 않고 다시 패딩합니다.
우리는 gather 으로 앞뒤로 문자 마커에서 출력 만 추출합니다 . 이 기능은 별도의 텐서에 지정된 텐서에서 특정 지수 만 추출하는 데 매우 유용합니다.
이 추출 된 출력은 각 마커에서 다음 단어를 예측하기 위해 어휘를 통해 점수를 계산하기 위해 선형 레이어를 적용하기 전에 선형 및 후진 고속도로 층에 의해 처리됩니다 . 검증 또는 추론 중에 멀티 태스킹 학습을위한 언어 모델링을 수행하는 것은 의미가 없기 때문에 훈련 중에만이 작업을 수행합니다. 모든 모델의 training 속성은 train.py 의 model.train() 또는 model.eval() 으로 설정됩니다. (이것은 주로 훈련 및 추론 동안 Pytorch 모델에서 드롭 아웃 및 배치 노르마 층을 활성화 또는 비활성화하는 데 주로 사용됩니다.)
models.py (계속)의 LM_LSTM_CRF 참조하십시오.
우리는 또한 단어 시퀀스의 길이와 문자 시퀀스 사이에 항상 상관 관계가 없기 때문에 길이를 줄이면 단어 시퀀스를 정렬합니다 .
같은 순서로 다른 모든 텐서를 정렬해야합니다.
우리는 마커에서 앞뒤로 문자 LSTM 출력을 연결하고 세 번째 고속도로 레이어를 통해 실행합니다 . 이렇게하면 서열 레이블링에 사용할 각 단어에서 하위 단어 정보가 추출됩니다.
우리는 이 결과를 단어 임베딩과 연결하고 packed_sequence 통해 BLSTM 출력을 계산합니다.
pad_packed_sequence() 로 다시 패딩하면 CRF 레이어에 공급해야 할 기능이 있습니다.
models.py 의 CRF 참조하십시오.
이 레이어가 모델에 추가되는 값을 고려할 때 놀랍게도 간단하다는 것을 알 수 있습니다.
선형 레이어는 출력을 BLSTM에서 각 태그의 점수로 변환하는 데 사용됩니다. 이는 방출 점수 입니다.
단일 텐서는 전환 점수를 유지하는 데 사용됩니다. 이 텐서는 모델의 Parameter 이며, 이는 다른 층의 무게와 마찬가지로 역설 중에 업데이트 할 수 있음을 의미합니다.
CRF 점수를 찾으려면 CRF 개요에 설명 된 바와 같이 방송 후 각 단어에서 배출 점수를 계산하고 전환 점수에 추가하십시오 .
models.py 의 ViterbiLoss 참조하십시오.
Viterbi 손실 개요에서 가능한 모든 유효한 태그 시퀀스의 점수의 로그 -Sum-EXP와 금 태그 시퀀스의 점수 , 즉 log-sum-exp(all scores) - gold score 의 점수의 차이를 최소화하려는 것을 확립했습니다.
골드 점수를 계산하기 위해 앞에서 설명한대로 각 실제 태그의 CRF 점수를 요약합니다.
Unrolled CRF 점수에서 태그 시퀀스를 어떻게 인코딩 한 방법을 기억하십니까? 우리는 gather() 사용하여 이러한 위치에서 점수를 추출하고 합산하기 전에 pack_padded_sequences() 로 패드를 제거합니다.
가능한 모든 시퀀스의 점수의 로그 -Sum-EXP를 찾는 것은 약간 까다 롭습니다. 우리는 for 를 사용하여 타임 스텝을 반복합니다. 각 타임 스텝에서 우리는 각각의 current_tag 에 대한 점수를 - -
previous_tag _tag에 대한 각 current_tag 의 누적 점수를 찾습니다. 우리는 효과적인 배치 크기, 즉 아직 완료되지 않은 시퀀스에 대해서만이 작업을 수행합니다. (우리의 시퀀스는 여전히 LM-LSTM-CRF 모델에서 단어 길이를 줄임으로써 정렬됩니다.)current_tag 에 대해, previous_tag 를 통해 로그 -sum-exp를 계산하여 각 current_tag 에서 새 축적 된 점수를 찾으십시오. 모든 시퀀스의 가변 길이를 계산 한 후, 우리는 치수 N, m 의 텐서가 남아 있습니다. 여기서 m (현재) 태그 수입니다. 이들은 각 m 태그에서 끝나는 모든 가능한 시퀀스에 비해 로그 SUM-EXP 축적 점수입니다. 그러나 유효한 시퀀스는 <end> 태그로만 끝날 수 있기 때문에 <end> 열에 대해서만 합하여 가능한 모든 유효한 시퀀스의 점수의 로그 -Sum-exp를 찾습니다 .
log-sum-exp(all scores) - gold score 차이를 찾습니다.
inference.py 에서 ViterbiDecoder 참조하십시오.
이것은 Viterbi 디코딩 개요에 설명 된 프로세스를 구현합니다.
우리는 ViterbiLoss 에서 한 것과 유사한 방식으로 for 의 점수를 축적합니다. 여기서는 로그 -sum-exp를 계산하는 대신 각 current_tag 에 대한 previous_tag 점수의 최대 값을 찾습니다 . 우리는 또한 백포인 텐서 의이 최대 점수에 해당하는 previous_tag 추적합니다 .
우리는 <end> 태그로 백포인 텐서를 패드로 패드로 패드 위로 뒤로 추적 할 수 있기 때문에 실제 <end> 태그에 도착하여 실제 백로 트레이싱 이 시작됩니다.
train.py 참조하십시오.
모델 (및 교육)의 매개 변수는 파일의 시작 부분에 있으므로 원하는 경우 쉽게 확인하거나 수정할 수 있습니다.
모델을 처음부터 훈련 시키 려면이 파일을 실행하십시오.
python train.py
체크 포인트에서 교육을 재개 하려면 코드 시작시 checkpoint 매개 변수가있는 해당 파일을 가리 킵니다.
우리는 모든 훈련 시대의 끝에서 검증을 수행합니다.
각 배치의 입력을 해당 배치의 최대 시퀀스 길이로 다듬습니다 . 이것은 우리가 실제로 필요한 각 배치에 더 많은 패드를 가지고 있지 않기 때문에.
하지만 왜? 우리 모델의 RNN은 패드를 통해 계산하지 않지만 선형 레이어는 여전히 그렇습니다 . 이것을 변경하는 것은 똑바로 똑바로 사용됩니다 - FAQ 섹션에서 변수 길이 시퀀스를 처리하는 것에 대한 관련 질문을 참조하십시오.
이 튜토리얼의 경우 일부 패드에 대한 약간의 추가 계산은 고속도로, CRF, 기타 선형 레이어, packed_sequence 등의 수많은 작업을 수행 할 필요가 없다는 간단한 가치가 있다고 생각했습니다.
멀티 태스크 시나리오에서는 두 언어 모델링 작업에서 크로스 엔트로피 손실과 시퀀스 라벨링 작업에서 Viterbi 손실을 요약하기로 결정했습니다.
우리는 이러한 손실의 합을 최소화하고 있지만 실제로 이러한 손실의 합을 최소화함으로써 Viterbi 손실을 최소화하는 데만 관심이 있습니다. 기본 작업에 대한 성능을 반영하는 Viterbi 손실입니다.
우리는 pack_padded_sequence() 사용하여 필요한 곳마다 패드를 제거합니다.
논문에서와 마찬가지로, 우리는 매크로 평균 F1 점수를 조기 스톱의 기준으로 사용합니다. 당연히 F1 점수를 계산하려면 Viterbi가 최적의 태그 시퀀스를 생성하기 위해 CRF 점수를 디코딩해야합니다.
우리는 pack_padded_sequence() 사용하여 필요한 곳마다 패드를 제거합니다.
저자 구현의 매개 변수를 최대한 밀접하게 따랐습니다.
나는 10 문장의 배치 크기를 사용했습니다. 나는 운동량으로 확률 론적 구배 출신을 사용했다. 학습 속도는 모든 시대에 부패되었습니다. 나는 미세 조정없이 100D 글러브 사전에 사전 임베딩을 사용했습니다.
타이탄 X (Pascal)에서 하나의 에포크를 훈련시키는 데 약 80 대가 걸렸습니다.
검증 세트의 F1 점수는 Epoch 50 주위에서 91% 기록했으며 Epoch 171에서 91.6% 로 정점에 도달했습니다. 나는 총 200 개의 에포크를 위해 그것을 실행했습니다. 이것은 종이의 결과에 매우 가깝습니다.
이 사기꾼 모델을 여기에서 다운로드 할 수 있습니다.
시퀀스를 사용하는 모델에 <start> 및 <end> 토큰이 필요한지 어떻게 결정합니까?
이것이 처음에 혼란스러워 보이면 훈련하려는 모델의 요구 사항에 대해 생각할 때 쉽게 해결 될 것입니다.
CRF를 사용한 시퀀스 라벨링의 경우 CRF 점수가 어떻게 구성되는지에 따라 <end> 토큰 ( 또는 <start> 토큰; 다음 질문 참조)이 필요합니다.
이미지 캡션에 대한 다른 튜토리얼에서 <start> 와 <end> 토큰을 모두 사용했습니다. 이 모델은 어딘가에 디코딩을 시작하고 추론 중에 디코딩을 중단 할시 기를 배우는 법을 배워야했습니다.
텍스트 분류를 수행하는 경우 어느 것도 필요하지 않습니다.
crf가 current_word -> next_word scores 대신 previous_word -> current_word score를 생성 할 수 있습니까?
예. 이 경우 L, m, _ 와 같은 배출 점수를 방송하고 <end> 토큰 대신 모든 문장에서 <start> 토큰이 있습니다. <start> 토큰의 올바른 태그는 항상 <start> 태그입니다. 마지막 단어의 "다음 태그"는 항상 <end> 태그입니다.
나는 previous word -> current word 규칙이 믹스에 언어 모델이 있기 때문에 약간 더 좋다고 생각합니다. 마지막 실제 단어에서 <end> 토큰을 예측할 수 있도록 아주 잘 맞아 문장이 완료 될 때 인식하는 법을 배웁니다.
Sequence Tagger의 입력 및 언어 모델 출력에 다른 어휘를 사용하는 이유는 무엇입니까?
언어 모델은 훈련 중에 본 단어 만 예측하는 법을 배웁니다. 임베딩 파일에서 ~ 40 만 건의 코퍼스 외부 단어가있는 선형-소프트 마스 레이어를 사용하는 것은 실제로 불필요하고 계산과 메모리의 막대한 낭비입니다.
그러나 모델이 훈련 중에는 절대로 보이지 않더라도이 단어를 입력 계층에 추가 할 수 있습니다 . 입력에서 미리 훈련 된 임베딩을 사용하기 때문입니다. 단어의 의미 가이 벡터에서 인코딩되어 있기 때문에 볼 필요가 없습니다. 이전에 chimpanzee 만났다면 orangutan 으로 무엇을 해야할지 알고있을 것입니다.
이 모델에서 사용하는 미리 훈련 된 단어 임베딩을 미세 조정하는 것이 좋은 생각입니까?
대부분의 입력 어휘가 코퍼스 내에 있지 않기 때문에 미세 조정을 자제합니다. Most embeddings will remain the same while a few are fine-tuned. If fine-tuning changes these embeddings sufficiently, the model may not work well with the words that weren't fine-tuned. In the real world, we're bound to encounter many words that weren't present in a newspaper corpus from 2003.
What are some ways we can construct dynamic graphs in PyTorch to compute over only the true lengths of sequences?
If you're using an RNN, simply use pack_padded_sequence() . PyTorch will internally compute over only the true lengths. See dynamic_rnn.py for an example.
If you want to execute an operation (like a linear transformation) only on the true timesteps, pack_padded_sequences() is still the way to go. This flattens the tensor by timestep while removing the pads. You can perform your operation on this flattened tensor, and then use pad_packed_sequence() to unflatten it and re-pad it with 0 s.
Similarly, if you want to perform an aggregation operation, like computing the loss, use pack_padded_sequences() to eliminate the pads.
If you want to perform timestep-wise operations, you can take a leaf out of how pack_padded_sequences() works, and compute only on the effective batch size at each timestep with a for loop to iterate over the timesteps. We did this in the ViterbiLoss and ViterbiDecoder . I also used an LSTMCell() in this fashion in my image captioning tutorial.
Dunston Checks In ? 정말?
I had no memory of this movie for twenty years. I was trying to think of a short sentence that would be easier to visualize in this tutorial and it just popped into my mind riding a wave of 90s nostalgia.

I wish I hadn't googled it though. Damn, the critics were harsh, weren't they? This gem was overwhelmingly and universally panned. I'm not sure I'd disagree if I watched it now, but that just goes to show the world is so much more fun when you're a kid.
Didn't have to worry about LM-LSTM-CRFs or nuthin...


