a PyTorch Tutorial to Sequence Labeling
1.0.0
これは、シーケンスラベル付けのPytorchチュートリアルです。
これは、驚くべきPytorchライブラリで自分でクールなモデルを実装することについて書いている一連のチュートリアルの2番目です。
Pytorchの基本的な知識、再発性ニューラルネットワークが想定されています。
Pytorchを初めて使用する場合は、最初にPytorchを使用して深い学習を読んでください。
質問、提案、または修正は問題として投稿できます。
Python 3.6でPyTorch 0.4使用しています。
2020年1月27日:2つの新しいチュートリアルの作業コードが追加されました - 超解像度と機械翻訳
客観的
概念
概要
実装
トレーニング
よくある質問
エンティティ、スピーチの一部など、文で各単語にタグを付けることができるモデルを構築するには。

タスク認識のニューラル言語モデルペーパーを使用して、エンパワーシーケンスラベル付けを実装します。これは、ほとんどのシーケンスタグ付けモデルよりも高度ですが、多くの有用な概念を学び、非常にうまく機能します。著者の元の実装はここにあります。
このモデルは、言語モデルと同時にトレーニングすることにより、シーケンスラベル付けタスクを強化するため、特別です。
シーケンスラベル付け。ああ。
言語モデル。言語モデリングとは、一連の単語またはキャラクターで次の単語またはキャラクターを予測することです。神経言語モデルは、テキスト生成、機械翻訳、画像キャプション、光学文字認識など、さまざまなNLPタスクにわたって印象的な結果を達成します。
文字RNNS 。テキスト内の個々の文字で動作するRNNは、基礎となるスタイルと構造をキャプチャすることが知られています。シーケンスラベル付けタスクでは、サブワード情報がエンティティまたはタグに重要な手がかりをもたらすことが多いため、特に便利です。
マルチタスク学習。モデルをトレーニングするために利用可能なデータセットは、多くの場合小さいです。モデルを支援するための注釈または手作りの機能を作成することは、面倒であるだけでなく、モデルが役立つ多様なドメインや設定に適応できないことがよくあります。残念ながら、シーケンスのラベルが典型的な例です。この問題を軽減する方法があります。股関節で結合された複数のモデルを共同でトレーニングすると、各モデルが利用できる情報が最大化され、パフォーマンスが向上します。
条件付きランダムフィールド。離散分類器は、クラスまたはラベルを単語で予測します。条件付きランダムフィールド(CRF)は、あなたをより良いことをすることができます - 彼らは単語だけでなく近所にも基づいてラベルを予測します。エンティティまたはラベルのシーケンスにパターンがあるため、これは理にかなっています。 CRFは、シーケンスラベル付け、遺伝子シーケンス、またはコンピュータービジョンにおけるオブジェクトの検出と画像セグメンテーションなど、順序付けられた情報をモデル化するために広く使用されています。
viterbiデコード。 CRFを使用しているため、単語シーケンスの適切なラベルシーケンスを予測しているので、各単語で正しいラベルを予測することはあまりありません。 ViterBiデコードは、まさにこれを行う方法です。条件付きランダムフィールドによって計算されたスコアから最も最適なタグシーケンスを見つけます。
高速道路ネットワーク。完全に接続されたレイヤーは、さまざまな場所で機能を変換または抽出するニューラルネットワークの定番です。 Highway Networksはこれを達成しますが、変換全体で情報が妨げられずに流れるようにします。これにより、ディープネットワークがはるかに効率的または実行可能になります。
このセクションでは、このモデルの概要を説明します。すでに慣れ親しんでいる場合は、実装セクションまたはコメントコードに直接スキップできます。
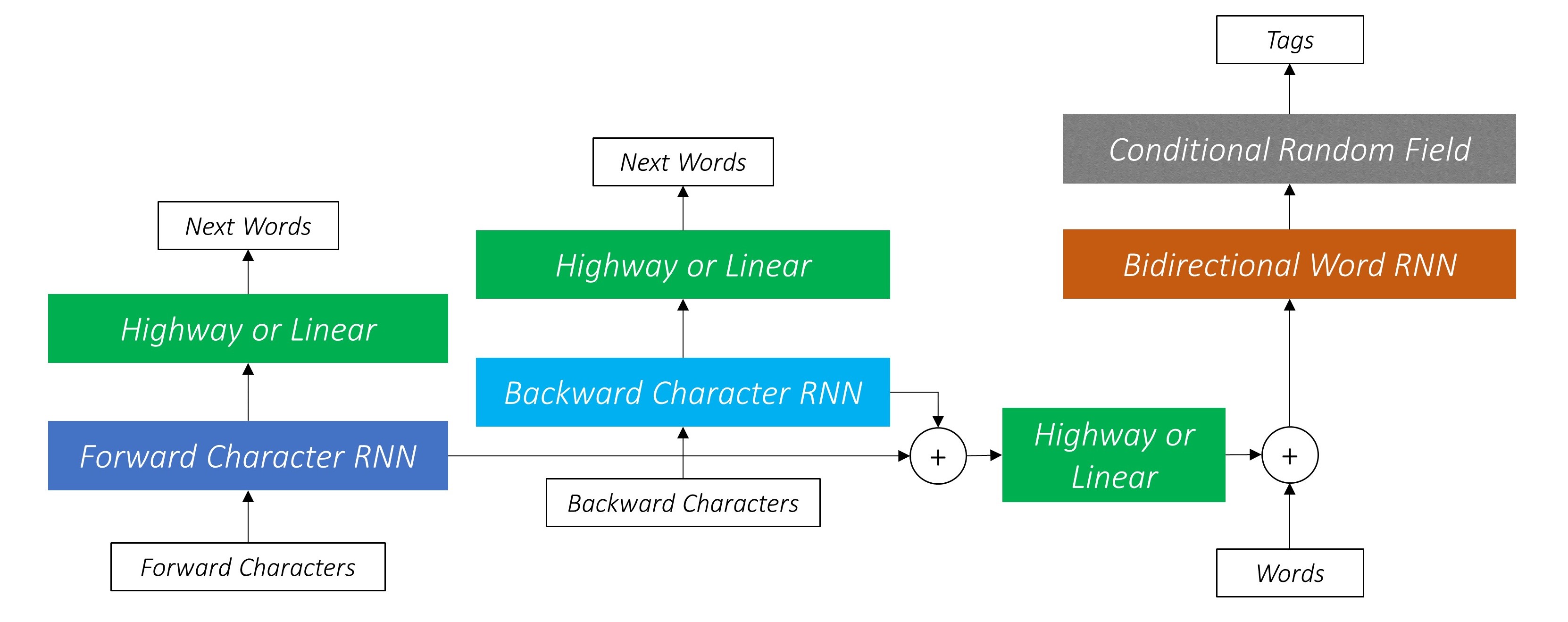
著者は、モデルを言語モデル - 長期記憶 - 条件付きランダムフィールドと呼びます。これは、LSTM + CRFの組み合わせを持つ共同トレーニング言語モデルを含むためです。
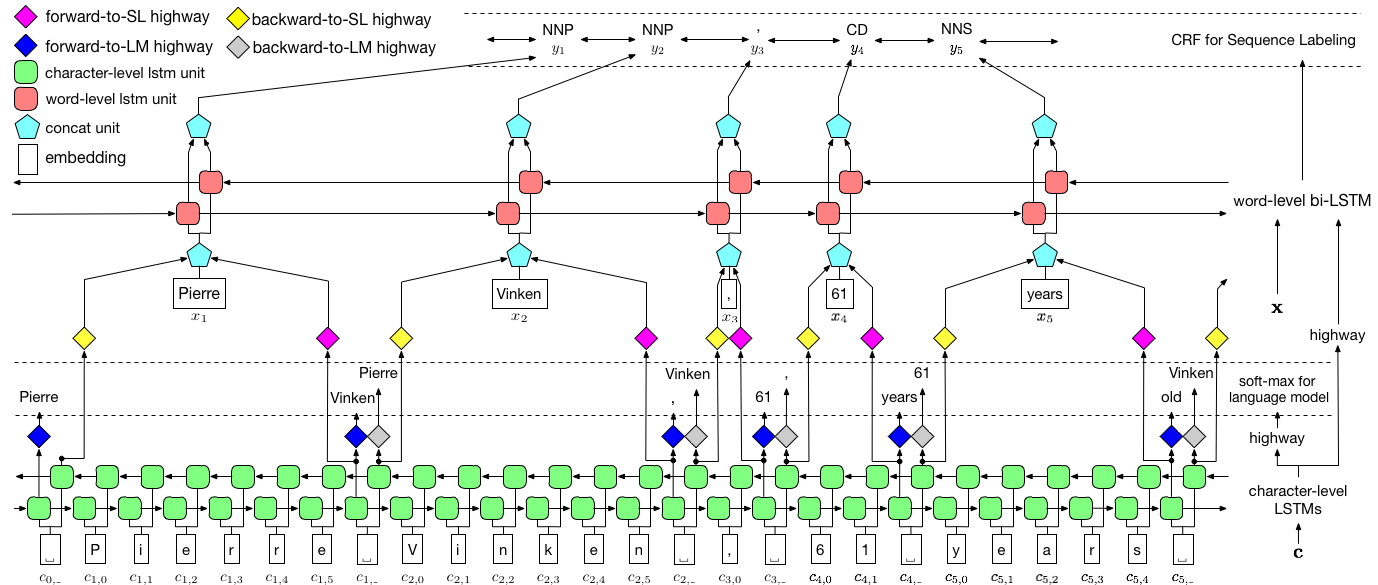
紙からのこの画像は、モデル全体を徹底的に表していますが、現時点では複雑すぎると思われても心配しないでください。それを分解して、コンポーネントを詳しく調べます。
マルチタスク学習とは、2つ以上のタスクでモデルを同時にトレーニングする場合です。
通常、これらのタスクの1つにのみ興味があります。この場合、シーケンスラベル付けです。
しかし、ニューラルネットワーク内のレイヤーが複数の機能の実行に貢献すると、主要なタスクのみで訓練した場合よりも多くのことを学びます。これは、各レイヤーで抽出された情報が拡張され、すべてのタスクが付属するためです。より多くの情報がある場合、主要なタスクのパフォーマンスが強化されます。
この方法で既存の機能を濃縮すると、シーケンスラベル付けに手作りの機能を使用する必要がなくなります。
マルチタスク学習中の総損失は、通常、個々のタスクの損失の線形組み合わせです。組み合わせのパラメーターは、更新可能な重みとして固定または学習できます。

個々の損失を集約しているため、複数のタスクで共有されている上流のレイヤーが、バックプロパゲーション中にすべてのタスクから更新を受信する方法を確認できます。
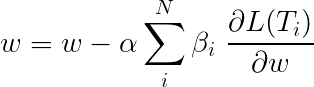
論文の著者は、単に損失( β=1 )を追加するだけで、同じことをします。
モデルを構成するタスクを見てみましょう。
3つあります。

これにより、サブワード情報を活用して、次の単語を予測します。
私たちは同じことを後方方向にします。 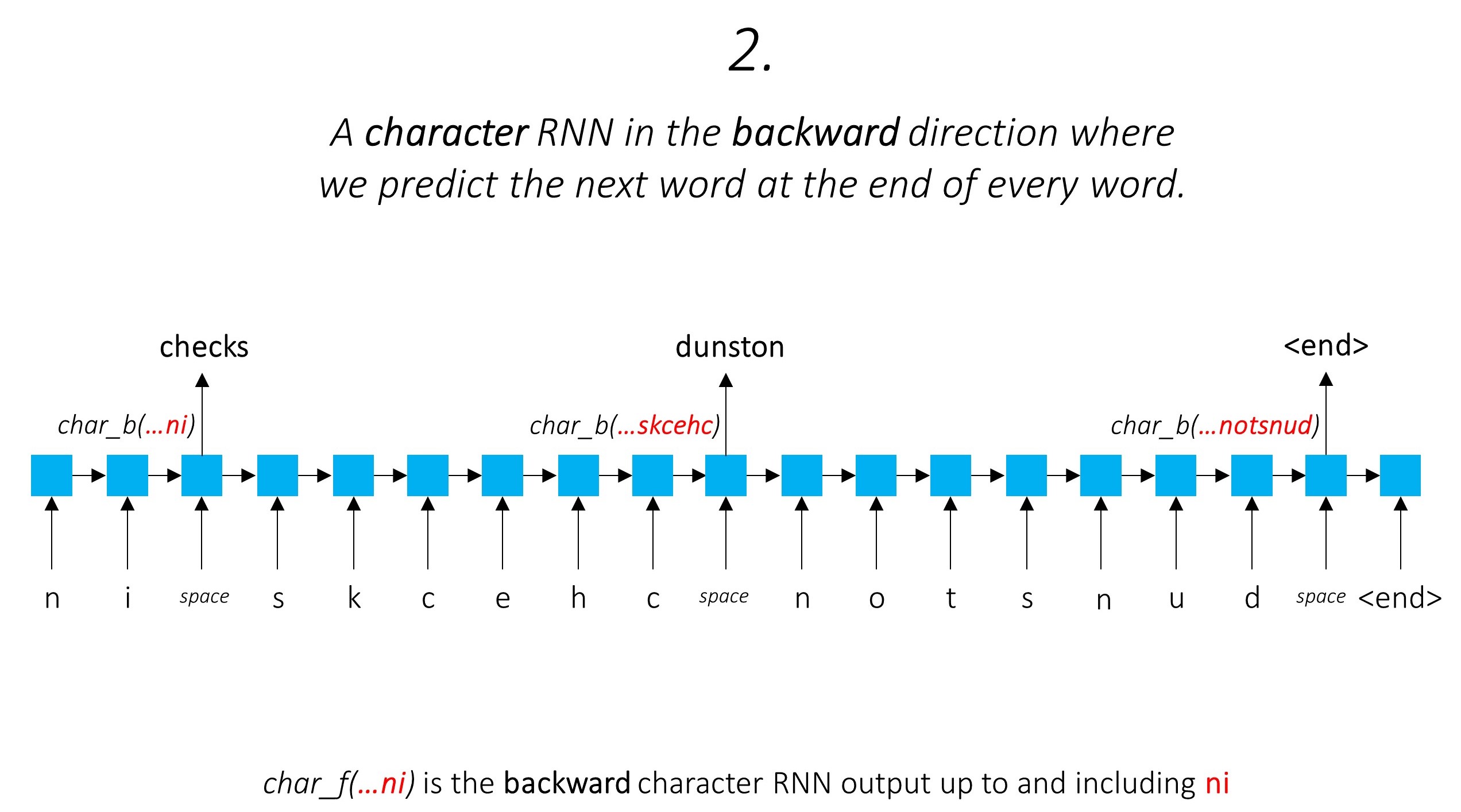
また、これら2つの文字RNNの出力をWord-RNNおよび条件付きランダムフィールド(CRF)への入力として使用して、シーケンスラベルの主要なタスクを実行します。 
タグ付けタスクでサブワード情報を使用しています。これは、スピーチの一部であろうとエンティティの一部であろうと、タグの強力な指標になる可能性があるためです。たとえば、形容詞は一般に「-y」または「-ul」で終わるか、しばしば「ランド」または「-burg」で終わることがわかります。
しかし、私たちのサブワード機能、つまり。キャラクターRNNの出力も追加情報が豊富に含まれています。モデル1と2のために、次の単語を前方方向と後方方向の両方で予測する必要があります。
したがって、シーケンスタグモデルは両方を使用します
双方向LSTM/RNNは、これらの機能を、単語レベルとキャラクターレベルの両方に、単語とその近隣に関する情報を含む各単語の新機能にエンコードします。これにより、条件付きランダムフィールドへの入力が形成されます。
CRFがなければ、単一の線形層を使用して、双方向LSTMの出力を各タグのスコアに変換しただけでした。これらは排出スコアとして知られています。これは、単語が特定のタグである可能性の表現です。
CRFは、排出スコアだけでなく、遷移スコアも計算します。これは、前の単語が特定のタグであることを考慮して、特定のタグである可能性があります。したがって、遷移スコアは、あるタグから別のタグに移行する可能性を測定します。
mタグがある場合、トランジションスコアはdimesionsions m, mのマトリックスに保存され、行は前の単語のタグを表し、列は現在の単語のタグを表します。位置i, j前の単語でのi Thタグから現在の単語のj Thタグに遷移する可能性があります。排出スコアとは異なり、文の各単語の遷移スコアは定義されていません。彼らはグローバルです。
私たちのモデルでは、CRF層は各単語の排出スコアと遷移スコアの集合体を出力します。
長さLの文の場合、排出スコアはL, mテンソルになります。各単語の排出スコアは前の単語のタグに依存しないため、この方向に沿ってL, _, m 、ブロードキャスト(コピー)などの新しい次元を作成して、 L, m, mテンソルを取得します。
遷移スコアはm, mテンソルです。遷移スコアはグローバルであり、単語に依存しないため、 _, m, m 、ブロードキャストなどの新しい次元を作成して、この方向に沿ってテンソルをブロードキャスト(コピー)してL, m, mテンソルを取得します。
これらを追加して、 L, m, mテンソルの合計スコアを取得できます。位置k, i, jの値は、 k thワードでのj Thタグの排出スコアの集合体であり、前の単語を考慮したk th単語でのj番目のタグの遷移スコアはi thタグでした。
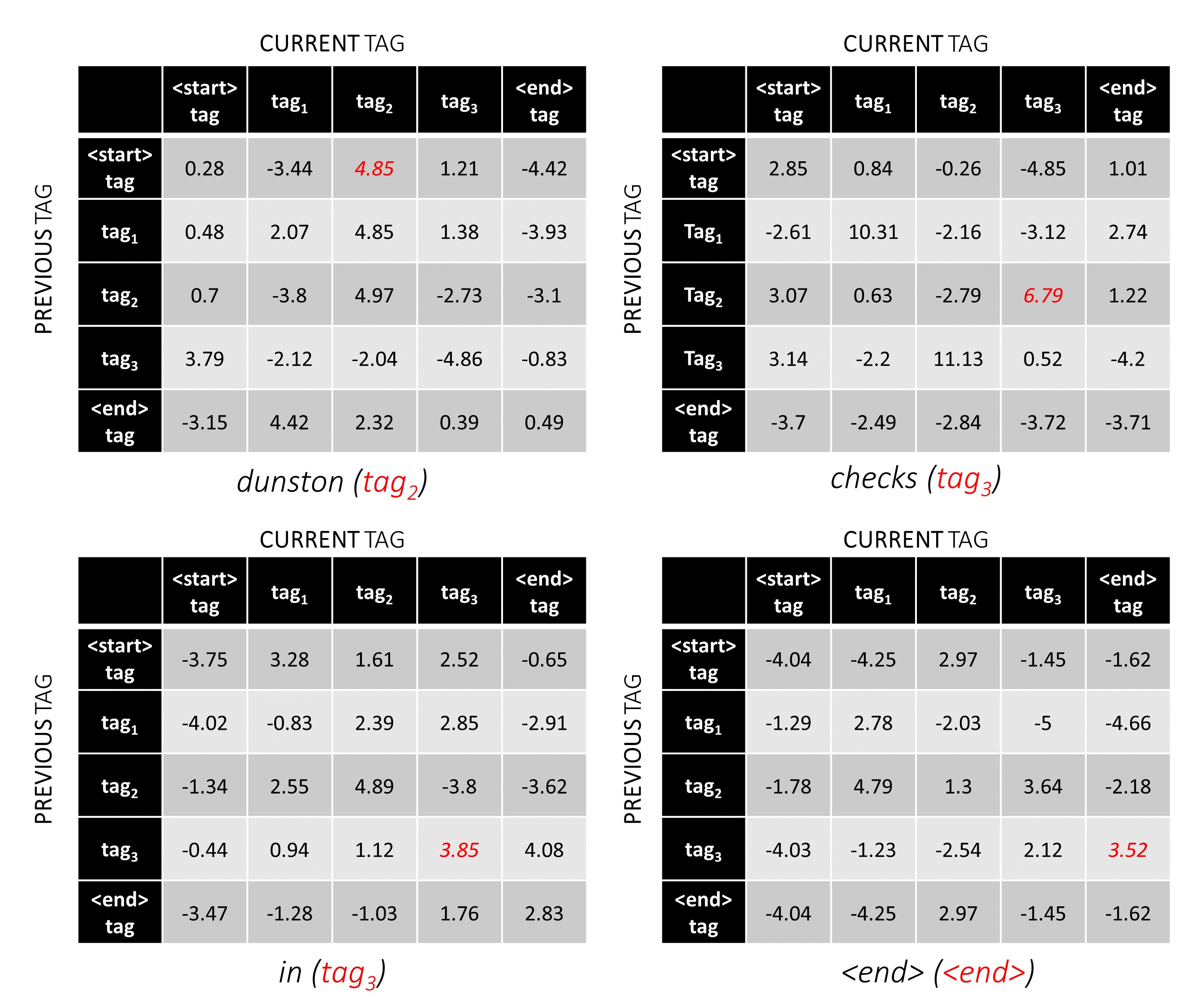
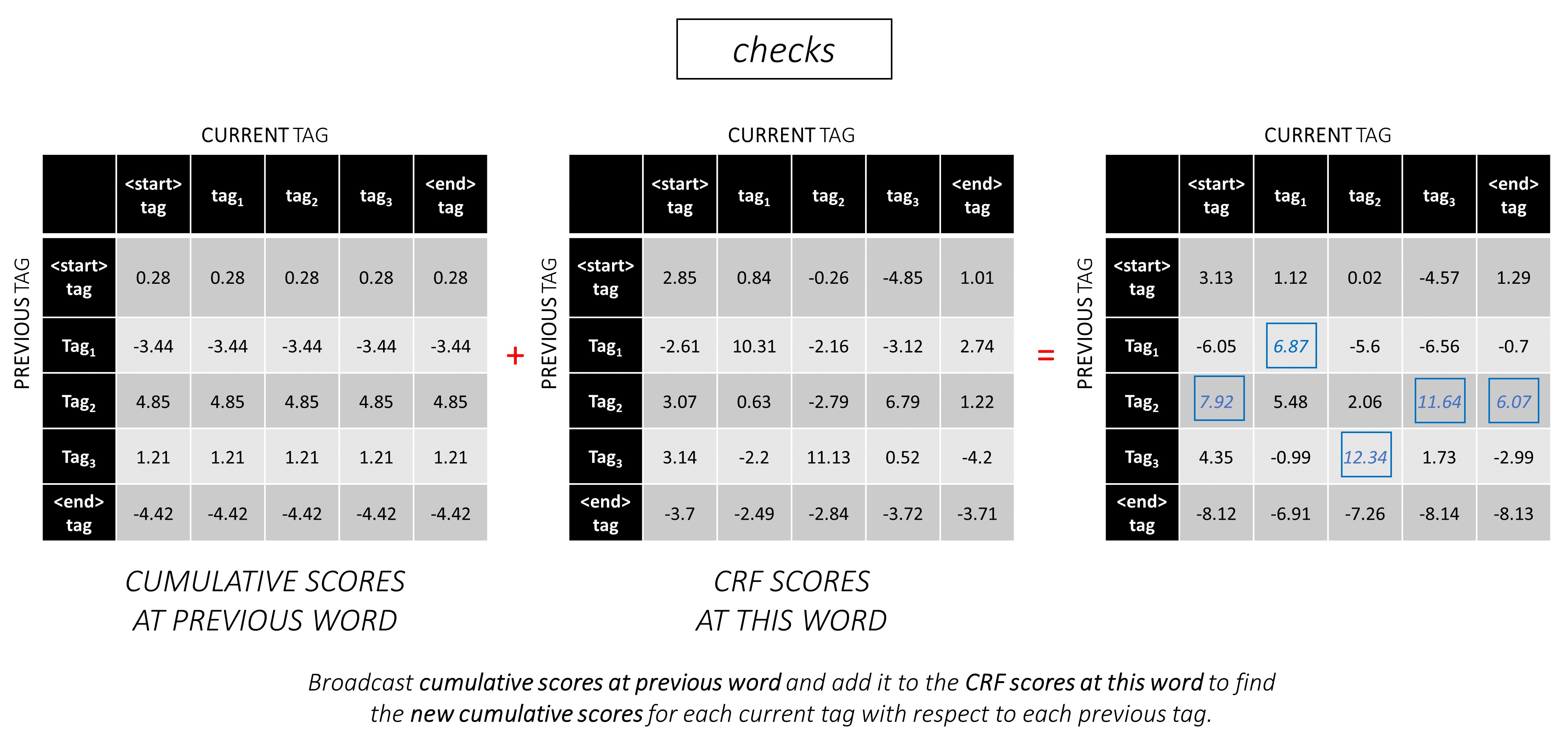
私たちの例では、 dunston checks in <end> 。合計で5つのタグがあると仮定した場合、合計スコアは次のようになります -
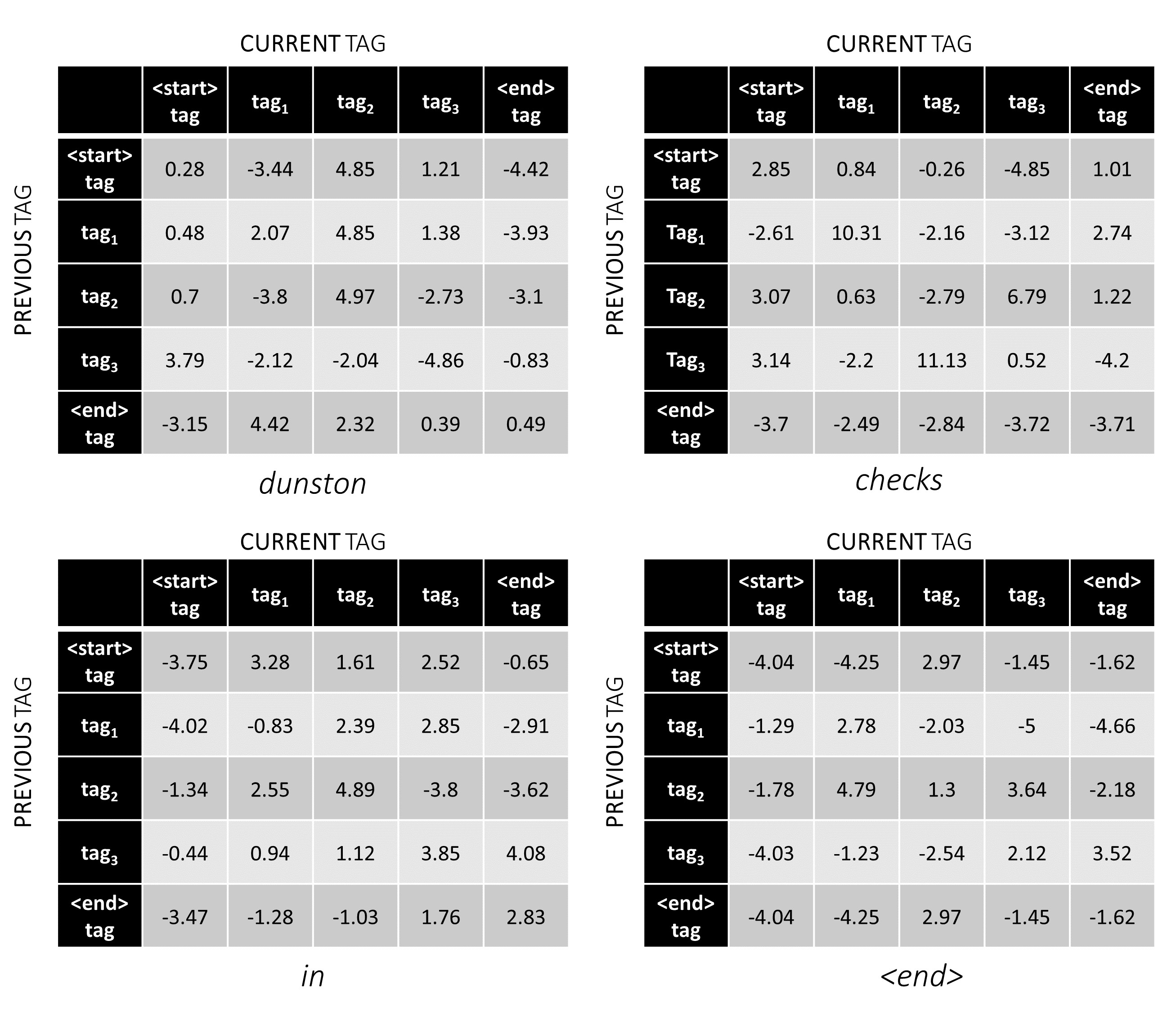
しかし、ちょっと待ってください、なぜ<start> end> <end>タグがあるのですか?私たちがそれに取り組んでいる間、なぜ私たちは<end>トークンを使用しているのですか?
<start>および<end>タグについて、 <start>および<end>トークンについてタグ間で移行する可能性をモデル化しているため、タグセットに<start>タグと<end>タグも含めています。
前のタグが<start>タグであることを考えると、特定のタグの遷移スコアは、このタグが文の最初のタグである可能性を表します。たとえば、文は通常、記事(a、an、the)または名詞または代名詞から始まります。
特定の以前のタグを考慮した<end>タグの遷移スコアは、この前のタグが文の最後のタグである可能性を示しています。
各単語の合計CRFスコアは前の単語のタグに関して定義されているため、 <start>トークン<start>はなく、すべての文で<end>トークンを使用します。
<end>トークンの正しいタグは、常に<end>タグです。最初の単語の「前のタグ」は、常に<start>タグです。
説明するために、例の文の場合、 dunston checks in <end>場合、Tags tag_2, tag_3, tag_3, <end>を持っていた場合、赤の値はこれらのタグのスコアを示しています。
通常、アクティブ化された線形層を使用して、RNN/LSTMの出力を変換および処理します。
残留接続に精通している場合は、変換された出力への変換の前に入力を追加して、変換の周りにデータフローのパスを作成できます。
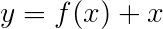
このパスは、バックプロパゲーション中の勾配の流れの近道であり、深いネットワークの収束に役立ちます。
高速道路ネットワークは残差ネットワークに似ていますが、シグモイド活性化ゲートを使用して、入力と変換された出力が組み合わされる比率を決定します。
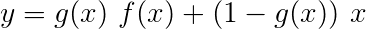
文字RNNは複数のタスクに貢献するため、ハイウェイネットワークは、その出力からタスク固有の情報を抽出するために使用されます。
したがって、複合モデルの3つの場所で高速道路ネットワークを使用します -
複数のタスクにキャラクターRNNの出力を直接使用する素朴な共同トレーニング設定では、つまり変換されていない場合、タスクの性質間の不一致はパフォーマンスを損なう可能性があります。
私たちの結合されたネットワークがどのように見えるかは今では明らかです。
ネットワークの部分を徐々に削除すると、シーケンスラベル付けに広く使用されているネットワークが徐々に簡単になります。
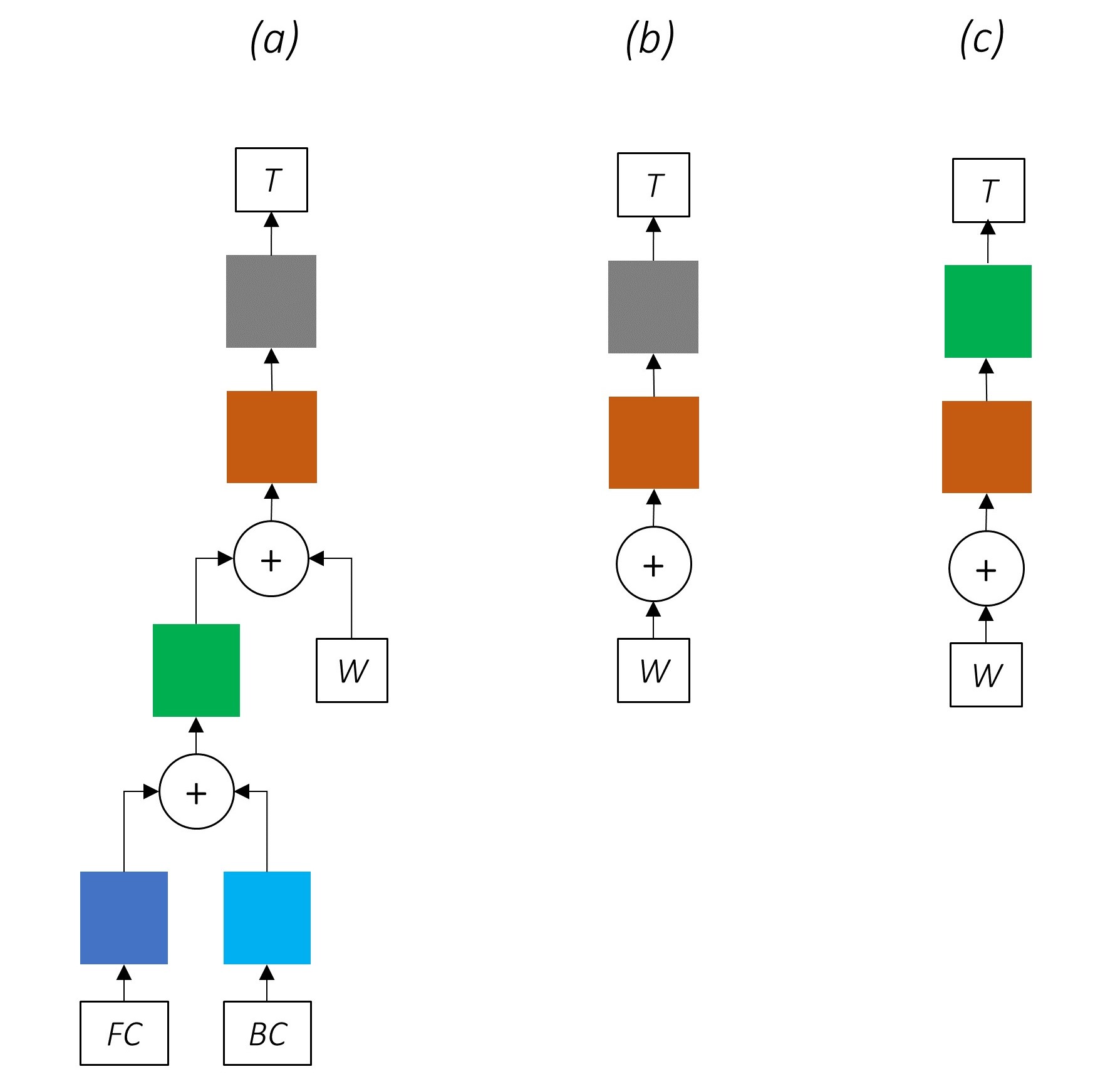
マルチタスク学習はありません。
共同トレーニングなしで文字レベルの情報を使用すると、パフォーマンスが向上します。
マルチタスク学習やキャラクターレベルの処理はありません。
この構成は、業界で非常に一般的に使用されており、うまく機能します。
マルチタスク学習、キャラクターレベルの処理、またはCRFINGはありません。線形または高速道路層が後者を置き換えることに注意してください。
これは適度にうまく機能する可能性がありますが、条件付きランダムフィールドはかなりのパフォーマンスブーストを提供します。
覚えておいてください、私たちは排出スコアのみを計算する線形層を使用していません。交差エントロピーは適切な損失メトリックではありません。
代わりに、クロスエントロピーのように、「負の対数可能性」であるViterBi損失を使用します。ただし、ここでは、シーケンス内の各単語で真のタグの可能性の代わりに、金(真の)タグシーケンスの可能性を測定します。可能性を見つけるために、すべてのタグシーケンスのスコア上のソフトマックスを検討します。
タグシーケンスtのスコアは、個々のタグのスコアの合計として定義されます。

たとえば、以前に見たCRFスコアを考えてみましょう -
TAG Sequence tag_2, tag_3, tag_3, <end> tagのスコアは、赤の値の合計、 4.85 + 6.79 + 3.85 + 3.52 = 19.01 。
Viterbiの損失は次に定義されます
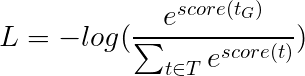
ここで、 t_Gはゴールドタグシーケンスであり、 Tすべての可能なタグシーケンスの空間を表します。
これは、
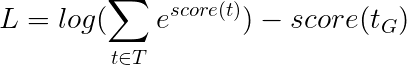
したがって、ViterBiの損失は、すべての可能なタグシーケンスのスコアのログサムEXPと、ゴールドタグシーケンスのスコア、つまりlog-sum-exp(all scores) - gold score違いです。
ViterBiデコードは、特定の単語(排出スコア)でのタグの可能性だけでなく、以前のタグと次のタグ(遷移スコア)を考慮したタグの可能性も考慮して、最も最適なタグシーケンスを構築する方法です。
L, m, mマトリックスでCRFスコアを生成すると、長さLのシーケンスを作成すると、デコードを開始します。
viterbiデコードは、例で最もよく理解されています。もう一度考えてみてください -
シーケンスの最初の単語では、 previous_tag <start>のみであることができます。したがって、その1つの行のみを考慮してください。
これらは、最初の単語の各current_tagの累積スコアでもあります。
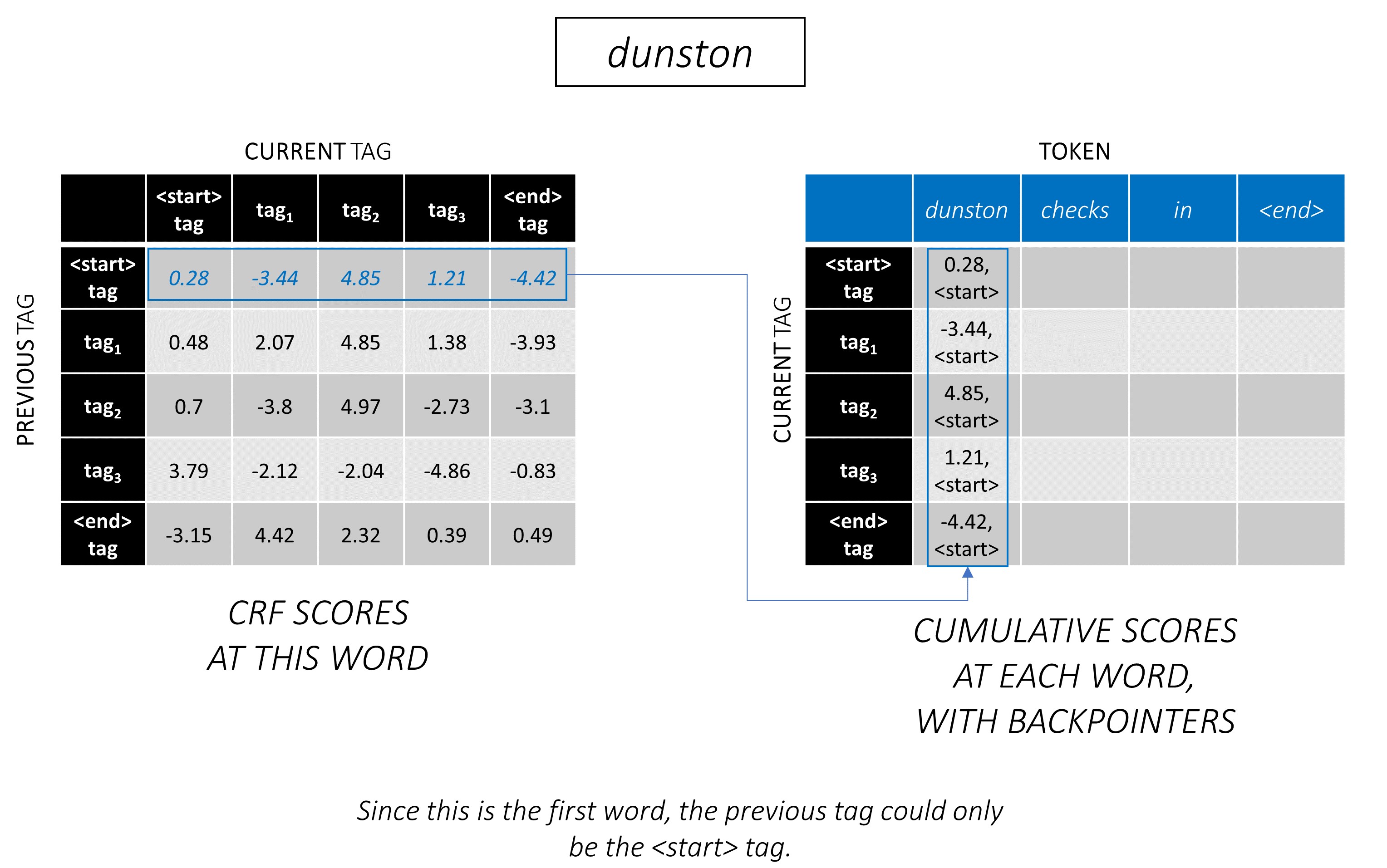
また、各スコアに対応するprevious_tagを追跡します。これらはバックポインターと呼ばれます。最初の言葉では、それらは明らかにすべて<start>タグです。
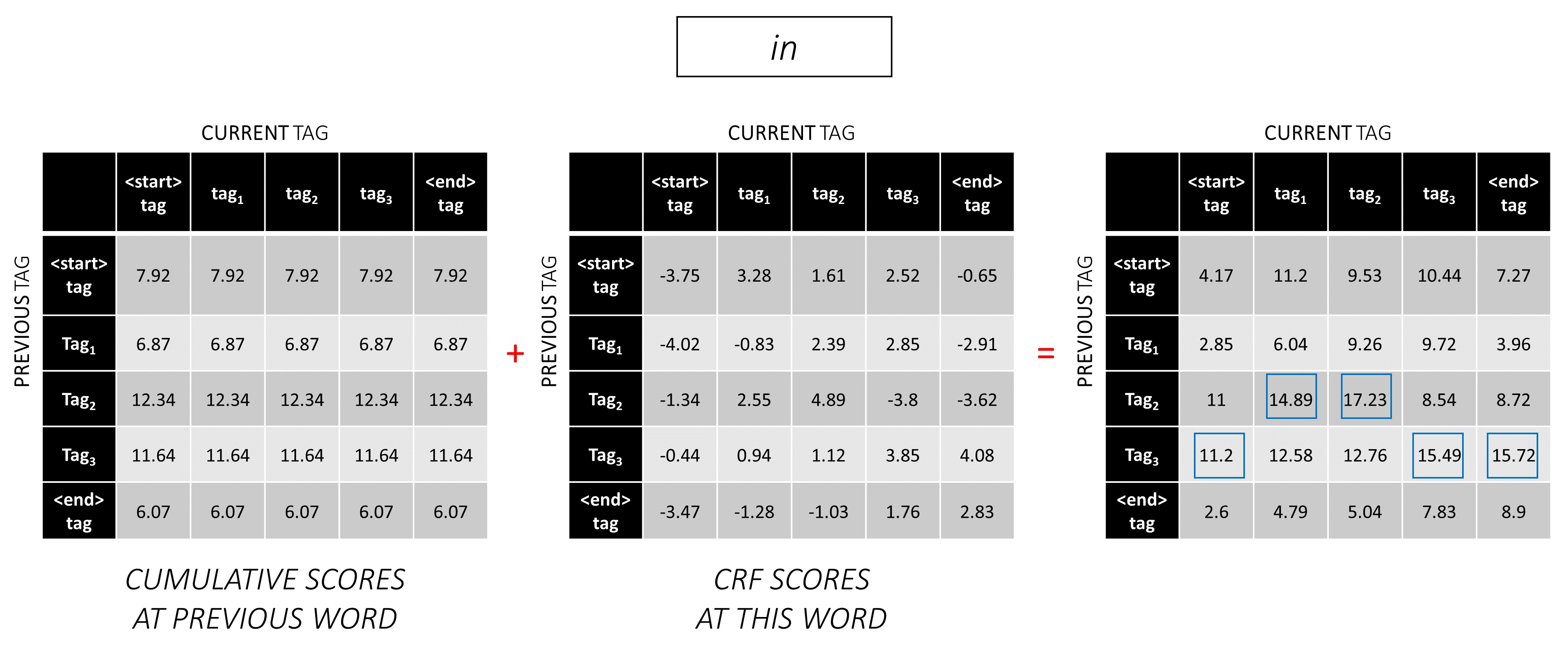
2番目の単語で、この単語のCRFスコアに以前の累積スコアを追加して、新しい累積スコアを生成します。
最初の単語のcurrent_tag sは2番目の単語のprevious_tag sであることに注意してください。したがって、 current_tagディメンションに沿って最初の単語の累積スコアをブロードキャストします。
current_tagごとに、すべてのprevious_tag _tagのスコアの最大値のみを検討してください。
バックポインター、つまり、これらの最大スコアに対応する以前のタグを保存します。

このプロセスを3番目の単語で繰り返します。
...そして最後の単語、 <end>トークンです。
ここで、唯一の違いは、あなたがすでに正しいタグを知っていることです。 <end>タグに対してのみ最大スコアとバックポインターが必要です。
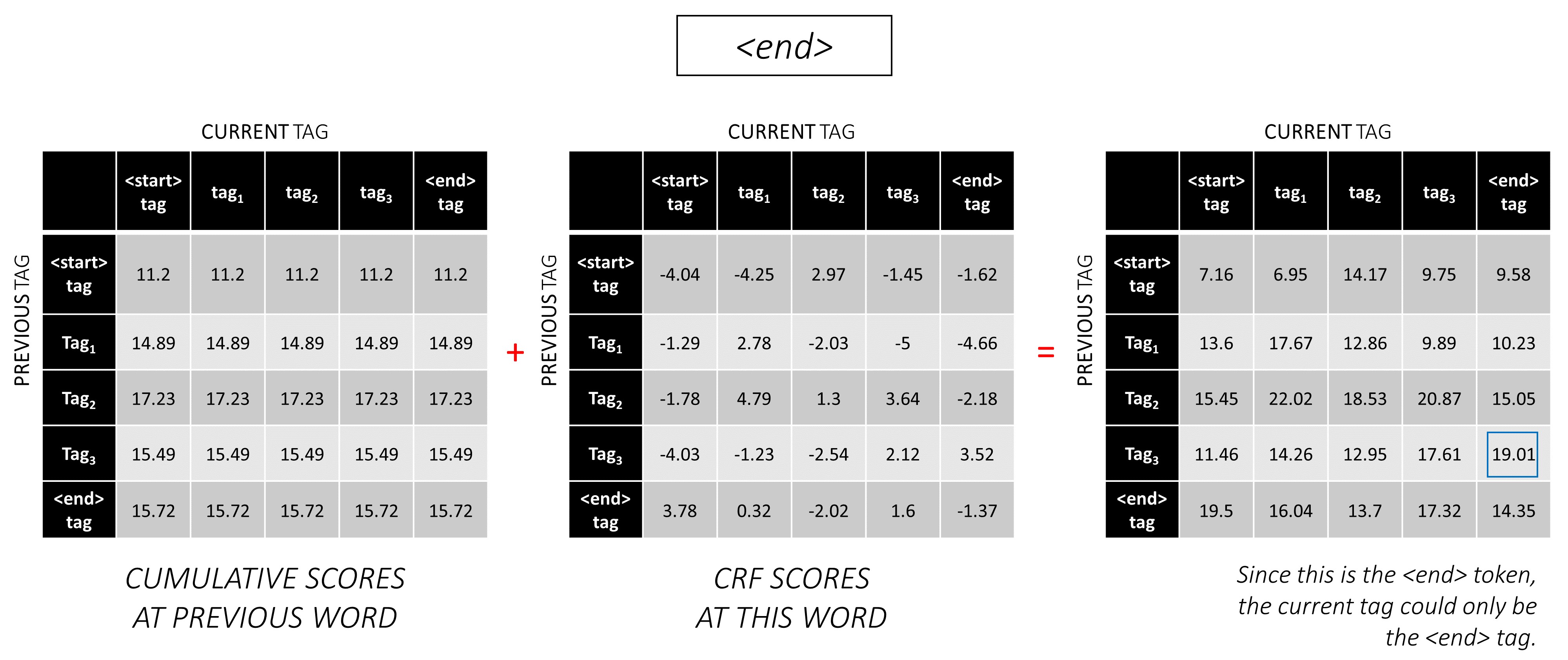
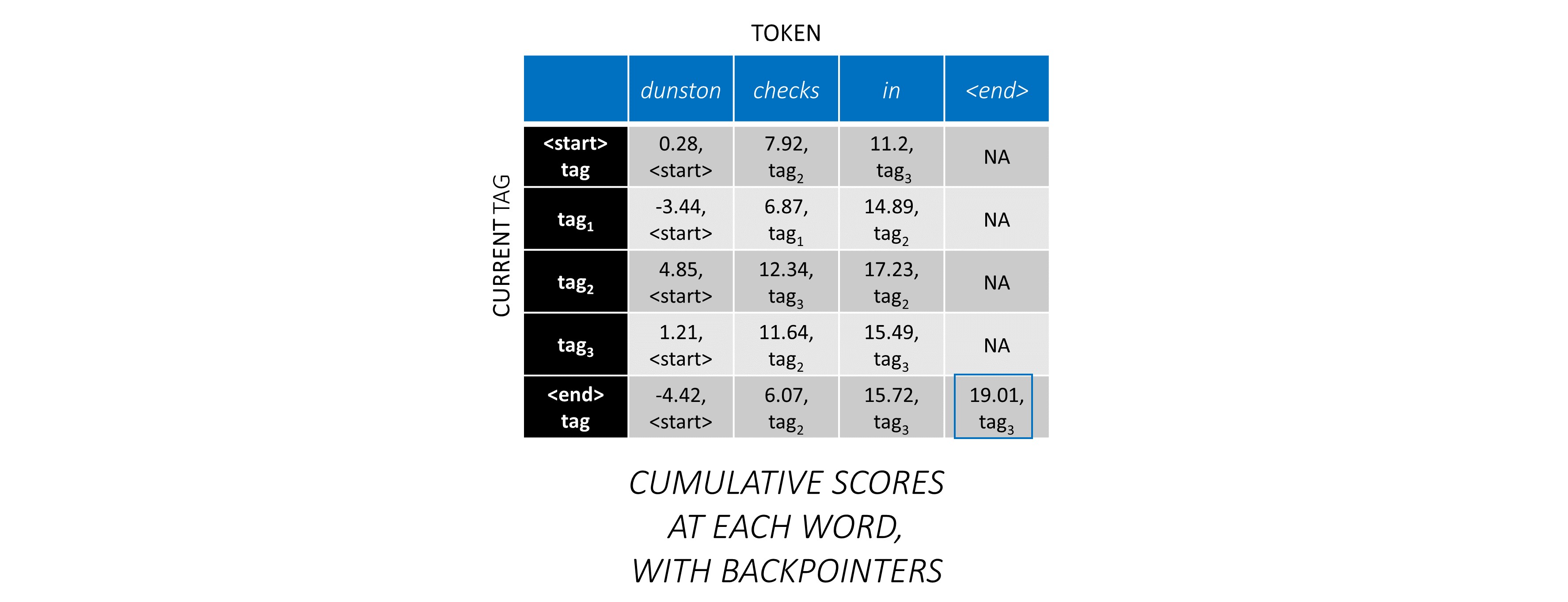
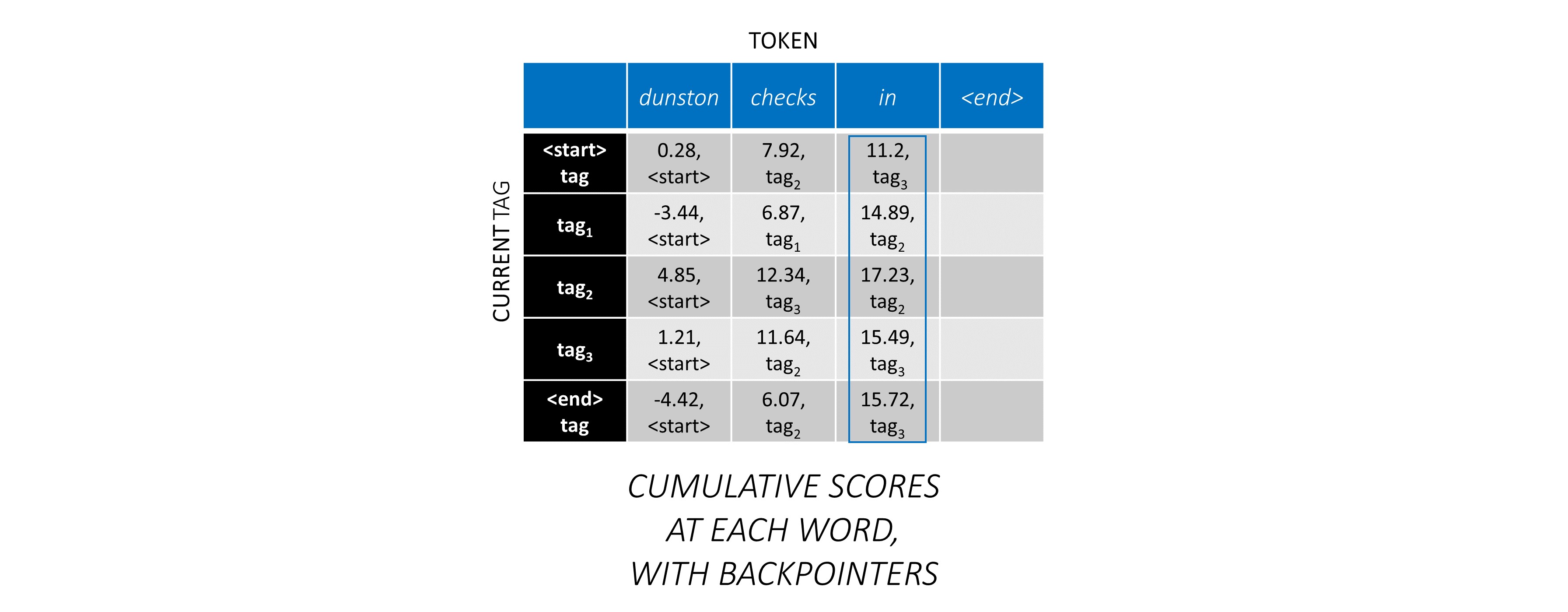
シーケンス全体にCRFスコアを蓄積したので、可能な限り最高のスコアでタグシーケンスを明らかにするために後方にトレースします。
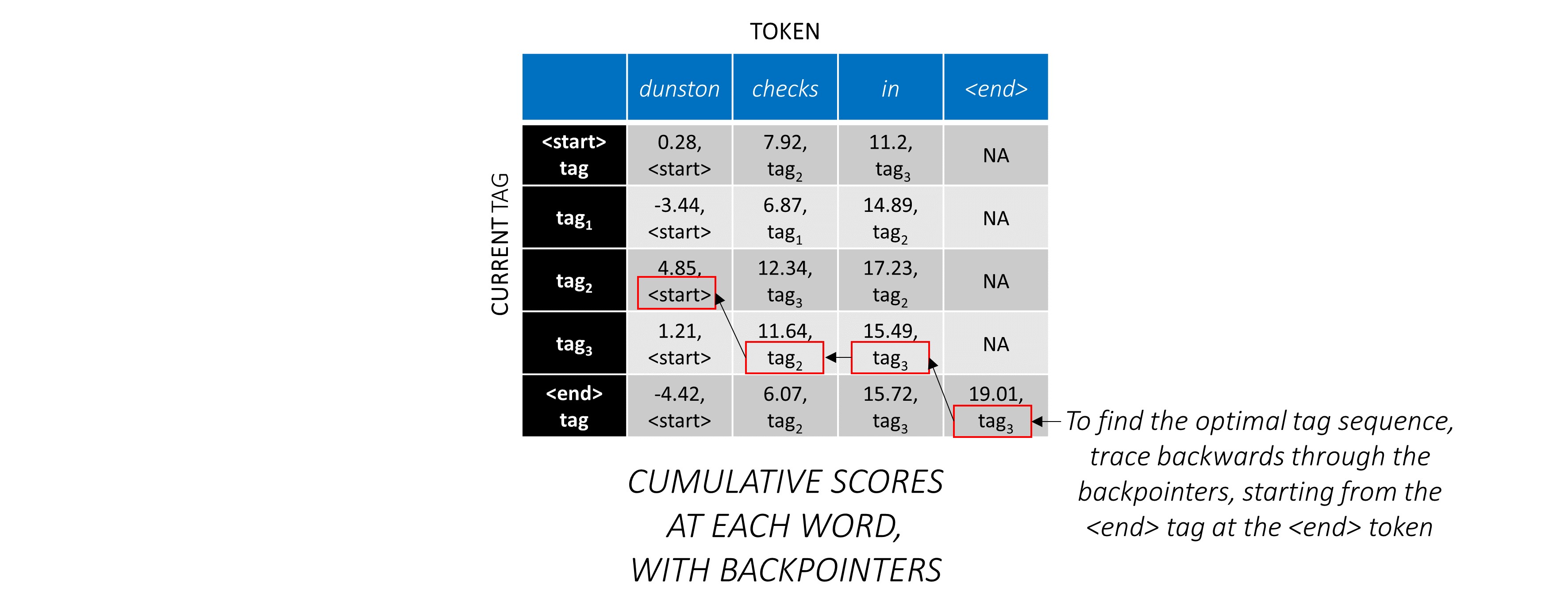
dunston checks in <end>あるtag_2 tag_3 tag_3 <end>であることがわかります。
以下のセクションでは、実装について簡単に説明します。
それらはいくつかのコンテキストを提供することを目的としていますが、詳細はコードから直接理解されるのが最もよくありますが、これは非常に重くコメントされています。
Conll 2003 NERデータセットを使用して、自分の結果を論文と比較しています。
これがスニペットです -
-DOCSTART- -X- O O
EU NNP I-NP I-ORG
rejects VBZ I-VP O
German JJ I-NP I-MISC
call NN I-NP O
to TO I-VP O
boycott VB I-VP O
British JJ I-NP I-MISC
lamb NN I-NP O
. . O O
このデータセットは、公開されていることを意図したものではありませんが、オンラインでどこかで見つけることができます。
モデルのトレーニングに使用できるいくつかのパブリックデータセットがオンラインであります。これらはすべて100%人間の注釈が付いているわけではありませんが、十分です。
NERタグ付けには、Groningen Meaning Bankを使用できます。
POSタグ付けの場合、nltkには小さなデータセットがありますnltk.corpus.treebank.tagged_sents()でアクセスできます。
CONLL 2003 NERデータ形式に変換するか、データパイプラインセクションで参照されているコードを変更する必要があります。
8つの入力が必要です。
これらは、タグ付けする必要がある単語シーケンスです。
dunston checks in
前述のように、 <start>トークンは使用しませんが、 <end>トークンを使用する必要があります。
dunston, checks, in, <end>
文は固定サイズのテンソルとして渡されるため、 <pad>トークンを使用して、文(当然さまざまな長さの長さ)を同じ長さに埋める必要があります。
dunston, checks, in, <end>, <pad>, <pad>, <pad>, ...
さらに、コーパス内の各<pad>のインデックスマッピングであるword_mapを作成します<end> Pytorchは、他のライブラリと同様に、インデックスとしてエンコードされた単語を必要とし、それらの埋め込みを検索したり、予測された単語スコアでその場所を特定したりします。
4381, 448, 185, 4669, 0, 0, 0, ...
したがって、モデルに供給された単語シーケンスは、寸法N, L_wのIntテンソルでなければなりません。ここで、 Nはbatch_size、 L_wは単語シーケンスのパッド付き長さ(通常は最長の単語シーケンスの長さ)です。
これらは、前方向の文字シーケンスです。
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' '
単語シーケンスの<end>トークンを一致させるには、文字シーケンスの<end>トークンが必要です。単語シーケンスの各単語で文字レベルの機能を使用するため、単語シーケンスの<end>で文字レベルの機能が必要です。
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>
また、パッドする必要があります。
'd', 'u', 'n', 's', 't', 'o', 'n', ' ', 'c', 'h', 'e', 'c', 'k', 's', ' ', 'i', 'n', ' ', <end>, <pad>, <pad>, <pad>, ...
char_mapでそれらをエンコードします。
29, 2, 12, 8, 7, 14, 12, 3, 6, 18, 1, 6, 21, 8, 3, 17, 12, 3, 60, 0, 0, 0, ...
したがって、モデルに供給された前方文字シーケンスは、寸法N, L_cのIntテンソルでなければなりません。ここで、 L_cは文字シーケンスのパッド付き長さ(通常は最も長い文字シーケンスの長さ)です。
これは、フォワードシーケンスと同じで処理されますが、後方に処理されます。 ( <end>トークンはまだ最後にあります。
'n', 'i', ' ', 's', 'k', 'c', 'e', 'h', 'c', ' ', 'n', 'o', 't', 's', 'n', 'u', 'd', ' ', <end>, <pad>, <pad>, <pad>, ...
12, 17, 3, 8, 21, 6, 1, 18, 6, 3, 12, 14, 7, 8, 12, 2, 29, 3, 60, 0, 0, 0, ...
したがって、モデルに供給された後方文字シーケンスは、寸法N, L_cのIntテンソルでなければなりません。
これらのマーカーは、特徴を抽出する文字シーケンスの位置です。
キャラクターシーケンスのすべてのスペース' 'および<end>トークンで機能を抽出します。
フォワード文字シーケンスの場合、
7, 14, 17, 18
これらは、それぞれdunston 、 checks 、 <end> in後のポイントです。したがって、単語シーケンスに各単語のマーカーがありますが、これは理にかなっています。 (ただし、言語モデルでは、次の単語を予測しているため、 <end>に対応するマーカーでは予測しません。)
これらを0秒でパッドします。有効なインデックスである限り、私たちが何をパッドしても関係ありません。 (パッドで機能を抽出しますが、使用しません。)
7, 14, 17, 18, 0, 0, 0, ...
それらは、単語シーケンスのパッド入りの長さ、 L_wにパッドで埋められています。
したがって、モデルに供給された前方文字マーカーは、寸法N, L_wのIntテンソルでなければなりません。
後方文字シーケンスのマーカーの場合、同様に、すべての' 'の位置と<end>トークンを見つけます。
また、これらの位置が前方マーカーと同じ語順であることを確認します。このアラインメントにより、順方向および後方の文字シーケンスから抽出された特徴を連結しやすくなり、言語モデルのターゲットを再注文することも防ぎます。
17, 9, 2, 18
これらは、それぞれnotsnud 、 skcehc 、 ni 、 <end>の後のポイントです。
0秒でパッドします。
17, 9, 2, 18, 0, 0, 0, ...
したがって、モデルに供給された後方文字マーカーは、寸法N, L_wのIntテンソルでなければなりません。
dunston, checks, in, <end>を想定しましょう。
tag_2, tag_3, tag_3, <end>
tag_map (tags <start> 、 tag_1 、 tag_2 、 tag_3 、 <end>を含む)があります。
通常、私たちはそれらを直接エンコードするだけです(パディングの前に) -
2, 3, 3, 5
これらは、 1Dタグマップの1Dエンコーディング、つまりタグ位置です。
ただし、 CRF層の出力は、各単語の2D m, mテンソルです。これらの2D出力でタグ位置をエンコードする必要があります。
正しいタグ位置は赤でマークされています。
(0, 2), (2, 3), (3, 3), (3, 4)
これらのスコアを1D m*mテンソルに展開すると、展開されたテンソルのタグ位置は次のとおりです。
tag_map [ previous_tag ] * len ( tag_map ) + tag_map [ current_tag ]したがって、 tag_2, tag_3, tag_3, <end> asをエンコードします
2, 13, 18, 19
モジュラスを取得して、元のtag_mapインデックスを取得できることに注意してください
t % len ( tag_map )それらは、単語シーケンスのパッド入りの長さ、 L_wにパッドで埋められます。
したがって、モデルに供給されたタグは、寸法N, L_wのIntテンソルでなければなりません。
これらは、 <end>トークンを含む単語シーケンスの実際の長さです。 Pytorchは動的グラフをサポートしているため、これらの長さでのみ計算され、 <pads>ではなく計算されます。
したがって、モデルに供給された単語の長さは、寸法NのIntでなければなりません。
これらは、 <end>トークンを含む文字シーケンスの実際の長さです。 Pytorchは動的グラフをサポートしているため、これらの長さでのみ計算され、 <pads>ではなく計算されます。
したがって、モデルに供給される文字の長さは、寸法NのIntテンソルでなければなりません。
utils.pyのread_words_tags()を参照してください。
これにより、入力ファイルがCONLL 2003形式で読み取り、単語とタグシーケンスを抽出します。
utils.pyのcreate_maps()参照してください。
ここでは、単語、文字、タグのエンコードマップを作成します。まれ<unk>単語とキャラクターがs(未知数)としてビンします。
utils.pyのcreate_input_tensors()参照してください。
入力からモデルセクションに詳述されている8つの入力を生成します。
utils.pyのload_embeddings()を参照してください。
事前に訓練された埋め込みをロードします。Word_Map word_map拡張して、埋め込み語彙に存在するコルパスの単語を含めるオプションがあります。 Note that this may also include rare in-corpus words that were binned as <unk> s earlier.
datasets.pyのWCDatasetを参照してください。
これは、Pytorch Datasetのサブクラスです。データセットのサイズを返す__len__メソッドと、8つの入力のiセットをモデルに返す__getitem__メソッドが必要です。
Dataset 、 train.pyのPytorch DataLoaderによって使用され、トレーニングまたは検証のためにモデルにデータのバッチを作成およびフィードします。
models.pyのHighwayを参照してください。
変換は、入力の再起動線形変換です。ゲートは、入力のシグモイド活性化線形変換です。両方の変換が入力と同じサイズでなければならないことに注意して、残差接続に入力を追加できることに注意してください。
num_layers 、特定のnum_layersの属性を属性に属性に起因します。通常、1つだけで十分です。
必要な数の変換とゲートレイヤーを個別のModuleList()に保存し、a a for使用して連続した操作を実行します。
models.pyのLM_LSTM_CRFを参照してください。
まさに最初に、長さを減らすことにより、前方および後方の文字シーケンスを並べ替えます。これは、LSTMが有効なタイムステップのみ、つまりシーケンスの真の長さを計算するためにpack_padded_sequence()を使用するために必要です。
他のすべてのテンソルを同じ順序で並べ替えることも忘れないでください。
pack_padded_sequence()を使用してPytorchの動的グラフとバッチ機能を利用して、パッドを処理しないように活用する方法のイラストについては、 dynamic_rnn.py参照してください。パッドを無視しながら、タイムステップでソートされたシーケンスを平らにし、 LSTMは各タイムステップの有効なバッチサイズN_tのみを計算します。
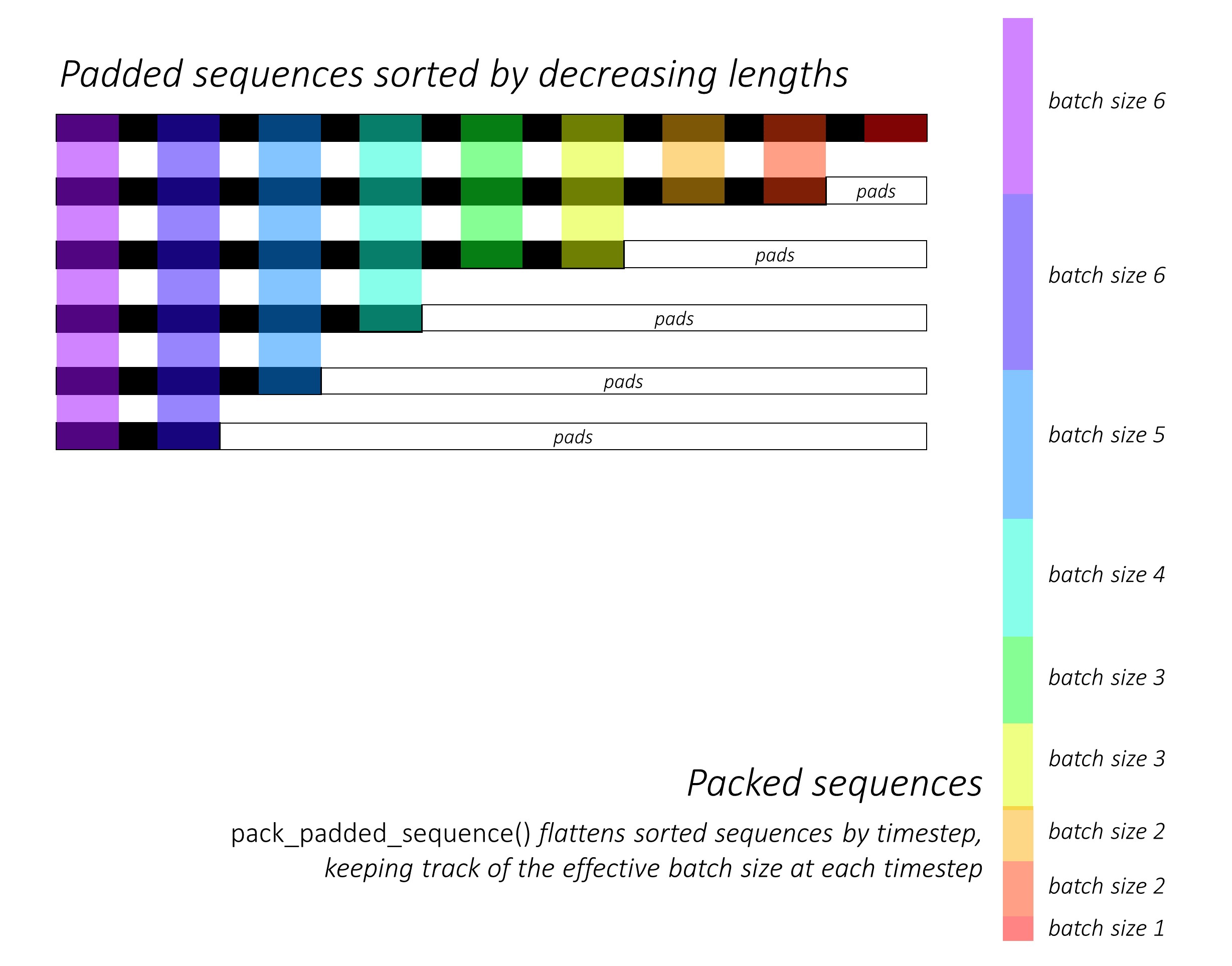
ソートにより、任意のタイムステップのトップN_t前のステップからの出力に合わせることができます。たとえば、3番目のTimestepでは、前のステップの上位5つの出力を使用して、上位5つの画像のみを処理します。ソートを除いて、これはすべてPytorchによって内部的に処理されますが、 pack_padded_sequence()が行うことを理解することは非常に便利です。そのため、他のシナリオで使用して同様の目的を達成できます。 (FAQSセクションの変数長シーケンスの処理に関する関連する質問を参照してください。)
ソートすると、それぞれ前方および後方のLSTMSを順方向と後方のpacked_sequencesに適用します。 pad_packed_sequence()を使用して、出力を解除して再パッドします。
順方向と後方の文字マーカーでの出力のみを集めますgatherこの関数は、別のテンソルで指定されているテンソルから特定のインデックスのみを抽出するのに非常に役立ちます。
これらの抽出された出力は、線形層を適用する前に、前方および後方の高速道路層によって処理され、各マーカーで次の単語を予測するために語彙上のスコアを計算します。検証または推論中にマルチタスク学習のために言語モデリングを実行することは意味がないため、トレーニング中にのみこれを行います。任意のモデルのtraining属性は、 train.pyのmodel.train()またはmodel.eval()で設定されます。 (これは主に、トレーニングと推論中にそれぞれPytorchモデルでドロップアウトおよびバッチノーム層を有効または無効にするために使用されることに注意してください。)
models.pyのLM_LSTM_CRF参照してください(続き)。
また、単語シーケンスの長さと文字シーケンスの間に常に相関があるとは限らないため、長さを減らすことによって単語シーケンスを並べ替えます。
他のすべてのテンソルを同じ順序で並べ替えることも忘れないでください。
マーカーで前方および後方の文字LSTM出力を連結し、3番目の高速道路層を通過します。これにより、シーケンスラベル付けに使用する各単語でサブワード情報が抽出されます。
この結果を埋め込みという単語と連結し、BLSTM出力をpacked_sequenceで計算します。
pad_packed_sequence()を再パッジすると、CRFレイヤーにフィードする必要がある機能があります。
models.pyのCRFを参照してください。
このレイヤーは、モデルに追加される値を考慮すると、驚くほど簡単です。
線形層を使用して、出力をBLSTMから各タグのスコアに変換するために使用されます。これは排出スコアです。
単一のテンソルを使用して、遷移スコアを保持します。このテンソルはモデルのParameterです。つまり、他の層の重みと同様に、バックプロパゲーション中に更新可能です。
CRFスコアを見つけるには、CRFの概要に記載されているように両方をブロードキャストした後、各単語で排出スコアを計算し、トランジションスコアに追加します。
models.pyのViterbiLoss参照してください。
Viterbiの損失の概要で、すべての可能な有効なタグシーケンスのスコアのログサムエクスポとゴールドタグシーケンスのスコア、すなわちlog-sum-exp(all scores) - gold scoreの違いを最小限に抑えることを確立しました。
前述のように、各真のタグのCRFスコアを合計して、ゴールドスコアを計算します。
[タグ]シーケンスがどのように展開されたCRFスコアに位置を掲載したかを覚えていますか?これらのポジションでSCOREをgather()で抽出し、合計する前にpack_padded_sequences()でパッドを排除します。
考えられるすべてのシーケンスのスコアのログサムエクスポを見つけることは、わずかに難しいです。 forループを使用して、タイムステップを繰り返します。各タイムステップで、各current_tagのスコアを蓄積します-
previous_tag current_tagの蓄積されたスコアを見つけます。これは、効果的なバッチサイズのみで行います。つまり、まだ完了していないシーケンスについてです。 (私たちのシーケンスは、 LM-LSTM-CRFモデルから単語の長さを減らすことによってまだソートされています。)current_tagについて、log-sum-expをprevious_tag _tagsで計算して、各current_tagで新しい蓄積されたスコアを見つけます。すべてのシーケンスの可変長さで計算した後、寸法N, mのテンソルが残されます。ここで、 m (現在の)タグの数です。これらは、各mタグで終了するすべての可能なシーケンスにわたるログサムEXP蓄積されたスコアです。ただし、有効なシーケンスは<end>タグでのみ終了できるため、 <end>列のみで合計して、すべての可能な有効なシーケンスのスコアのログサムEXPを見つけます。
違い、 log-sum-exp(all scores) - gold scoreあります。
inference.pyのViterbiDecoder参照してください。
これは、ViterBiデコードの概要に記載されているプロセスを実装します。
log-sum-expを計算する代わりに、各current_tagの最大previous_tagスコアを見つけることを除いて、 ViterbiLossで行った方法と同様の方法で、 forループのスコアを蓄積します。また、バックポインターテンソルのこの最大スコアに対応するprevious_tagを追跡します。
バックポインターテンソルを<end>タグでパッドします。これにより、パッドの上に後方にトレースし、最終的に実際の<end>タグに到達し、実際のバックトレースが始まるためです。
train.pyを参照してください。
モデルのパラメーター(およびトレーニング)はファイルの先頭にあるため、必要に応じて簡単に確認または変更できます。
モデルをゼロからトレーニングするには、このファイルを実行するだけです。
python train.py
チェックポイントでトレーニングを再開するには、コードの先頭にcheckpointパラメーターを使用して対応するファイルを指します。
すべてのトレーニングエポックの終わりに検証を実行することに注意してください。
各バッチの入力をそのバッチの最大シーケンス長にトリミングすることに気付くでしょう。これは、実際に必要な各バッチにこれ以上のパッドがないことです。
しかし、なぜ?私たちのモデルのRNNはパッドの上で計算されませんが、線形層はまだ実行されます。これを変更するのは非常にまっすぐです。FAQSセクションの変数長シーケンスの処理に関する関連する質問を参照してください。
このチュートリアルでは、いくつかのパッドに対する少し余分な計算は、 packed_sequenceで、高速道路、CRF、その他の線形層、連結などを多数の操作を実行する必要がないという簡単なことであると考えました。
マルチタスクシナリオでは、2つの言語モデリングタスクからのクロスエントロピー損失と、シーケンスラベル付けタスクからのViterBi損失を要約することを選択しました。
これらの損失の合計を最小限に抑えていますが、実際には、これらの損失の合計を最小限に抑えることにより、ViterBiの損失を最小限に抑えることにのみ関心があります。主要なタスクのパフォーマンスを反映するのは、ViterBiの損失です。
pack_padded_sequence()を使用して、必要に応じてパッドを排除します。
論文のように、早期停止の基準としてマクロ平均F1スコアを使用します。当然のことながら、F1スコアを計算するには、ViterBiがCRFスコアをデコードして最適なタグシーケンスを生成する必要があります。
pack_padded_sequence()を使用して、必要に応じてパッドを排除します。
著者の実装のパラメーターにできるだけ密接に従いました。
10文のバッチサイズを使用しました。私は勢いで確率的勾配降下を採用しました。学習率はエポックごとに崩壊しました。私は微調整せずに100Dグローブの前処理された埋め込みを使用しました。
タイタンX(Pascal)で1つのエポックを訓練するのに約80年代かかりました。
検証セットのF1スコアは、エポック50の周りで91%に達し、エポック171で91.6%でピークに達しました。私は合計200エポックで実行しました。これは、論文の結果にかなり近いです。
この前提型モデルはこちらからダウンロードできます。
シーケンスを使用するモデルに<start>および<end>トークンが必要かどうかをどのように判断しますか?
これが最初に混乱しているように見える場合、トレーニングを計画しているモデルの要件について考えると、簡単に解決できます。
CRFを使用したシーケンスラベル付けの場合、CRFスコアがどのように構造化されているかのため、 <end>トークン(または<start>トークン、次の質問を参照)が必要です。
画像キャプションに関する他のチュートリアルでは、 <start>と<end>トークンの両方を使用しました。モデルは、どこかでデコードを開始し、推論中にデコードを停止するタイミングを認識することを学ぶ必要がありました。
テキスト分類を実行している場合は、どちらも必要ありません。
crfにcurrent_word -> next_word previous_word -> current_word生成することはできますか?
はい。この場合L, m, _などの排出スコアをブロードキャストし、 <end>トークンの代わりにすべての文に<start>トークンがあります。 <start>の正しいタグは、常に<start>タグです。最後の単語の「次のタグ」は、常に<end>タグです。
ミックスに言語モデルがあるため、 previous word -> current word慣習はわずかに優れていると思います。 It fits in quite nicely to be able to predict the <end> token at the last real word, and therefore learn to recognize when a sentence is complete.
Why are we using different vocabularies for the sequence tagger's inputs and language models' outputs?
The language models will learn to predict only those words it has seen during training. It's really unnecessary, and a huge waste of computation and memory, to use a linear-softmax layer with the extra ~400,000 out-of-corpus words from the embedding file it will never learn to predict.
But we can add these words to the input layer even if the model never sees them during training. This is because we're using pre-trained embeddings at the input. It doesn't need to see them because the meanings of words are encoded in these vectors. If it's encountered a chimpanzee before, it very likely knows what to do with an orangutan .
Is it a good idea to fine-tune the pre-trained word embeddings we use in this model?
I refrain from fine-tuning because most of the input vocabulary is not in-corpus. Most embeddings will remain the same while a few are fine-tuned. If fine-tuning changes these embeddings sufficiently, the model may not work well with the words that weren't fine-tuned. In the real world, we're bound to encounter many words that weren't present in a newspaper corpus from 2003.
What are some ways we can construct dynamic graphs in PyTorch to compute over only the true lengths of sequences?
If you're using an RNN, simply use pack_padded_sequence() . PyTorch will internally compute over only the true lengths. See dynamic_rnn.py for an example.
If you want to execute an operation (like a linear transformation) only on the true timesteps, pack_padded_sequences() is still the way to go. This flattens the tensor by timestep while removing the pads. You can perform your operation on this flattened tensor, and then use pad_packed_sequence() to unflatten it and re-pad it with 0 s.
Similarly, if you want to perform an aggregation operation, like computing the loss, use pack_padded_sequences() to eliminate the pads.
If you want to perform timestep-wise operations, you can take a leaf out of how pack_padded_sequences() works, and compute only on the effective batch size at each timestep with a for loop to iterate over the timesteps. We did this in the ViterbiLoss and ViterbiDecoder . I also used an LSTMCell() in this fashion in my image captioning tutorial.
Dunston Checks In ?本当に?
I had no memory of this movie for twenty years. I was trying to think of a short sentence that would be easier to visualize in this tutorial and it just popped into my mind riding a wave of 90s nostalgia.

I wish I hadn't googled it though. Damn, the critics were harsh, weren't they? This gem was overwhelmingly and universally panned. I'm not sure I'd disagree if I watched it now, but that just goes to show the world is so much more fun when you're a kid.
Didn't have to worry about LM-LSTM-CRFs or nuthin...


