doremi
1.0.0
Doremi的Pytorch實現,一種用於優化語言建模數據集的數據混合物的算法。現代大型語言模型在許多領域(網絡,書籍,ARXIV等)上進行了培訓,但是每個要訓練的域都不清楚,尤其是因為這些模型將用於各種下游任務(沒有特定的目標分配以優化)。 Doremi使用分佈強大的優化(DRO)調整數據混合物以魯棒至目標分佈。 Doremi使用DRO訓練一個小的代理模型,該模型與預驗證的參考模型相比,該模型基於代理模型的多餘損失,動態重量或減肥域。參考模型提供了可實現的最佳損失的估計,以避免對高熵 /硬域的悲觀情緒。然後,調諧的數據混合物可用於更有效地訓練更大的模型。在本文中,280m代理模型可以改善8B參數模型的訓練(大30倍),從而使其能夠更快地達到基線8B性能2.6倍。下圖提供了Doremi的概述。查看紙張以獲取更多詳細信息。
作為黑匣子,該代碼庫給定文本數據集輸出優化的域權重。其他一些有用的組件:具有域級加權採樣,簡單的下游評估線束和HuggingFace Trainer + FlashAttention2集成的快速,可重新恢復的數據加載器。

要開始,請克隆回購併安裝它:
git clone [email protected]:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
scripts/setup_flash.sh中的彙編可能需要大量時間(小時)。所有代碼都應從最外層的doremi目錄運行。在開始之前,請在此存儲庫的外部目錄中的constants.sh文件中寫入高速緩存目錄,數據目錄等。您還可以在此處放置任何CONDA或VIRTAILENV激活命令。這是constants.sh文件內容的示例(以稱為sample_constants.sh的文件提供):
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # will be created by scripts/run_preprocess_pile.sh
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases key for logging
PARTITION=partition # for slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # if you installed doremi in venv
這是如何運行示例腳本以在堆上進行數據預處理的示例腳本,該腳本將樁的數據分隔為域並將其分開:
bash scripts/run_preprocess_pile.sh
這是一個示例腳本,可以運行1200m基線,代理和主型號(Doremi Pipeline中的所有3個步驟),並在一個帶有8個A100 GPU的一個節點上測試。這是論文中樁實驗的小版本。該腳本將自動運行困惑和幾次評估:
bash scripts/run_pile.sh
這些腳本按照論文運行200k步驟。 doremi運行使用文件名<RUN_NAME>.json中的configs目錄中的域權重。
要在您自己的數據集上運行doremi,請以以下格式提供預處理(令牌化)數據:
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
每個內部目錄(例如, domain_name_1 )可以通過huggingface的load_from_disk方法加載。如果您的數據以不同的格式,則可以在doremi/dataloader.py中添加自定義數據加載功能。您還需要編寫一個配置文件並將其保存到configs/和寫入運行腳本類似於腳本/runs/run_pile_baseline120m.sh and scripts/runs/run_pile_baseline120M.sh runs/ scripts/runs/run_pile_doremi120M.sh請參考配置文件。配置文件指定從域名到混合物重量的映射。名稱不必按順序(Doremi始終先對域名進行排序以確定固定訂購),並且不必將權重標準化。
--reweight_eps ) :紙張中使用的默認設置為1,儘管可以針對不同的數據集進行調整。通常,我們預計訓練期間的域重量會有些嘈雜,平均域的重量大多是光滑的。k步的梯度,則將針對先前迭代的陳舊域重量計算出k-1梯度( k=1不存在此問題)。請注意,該回購和論文之間存在一些差異,該論文是在Google上開發的,即:
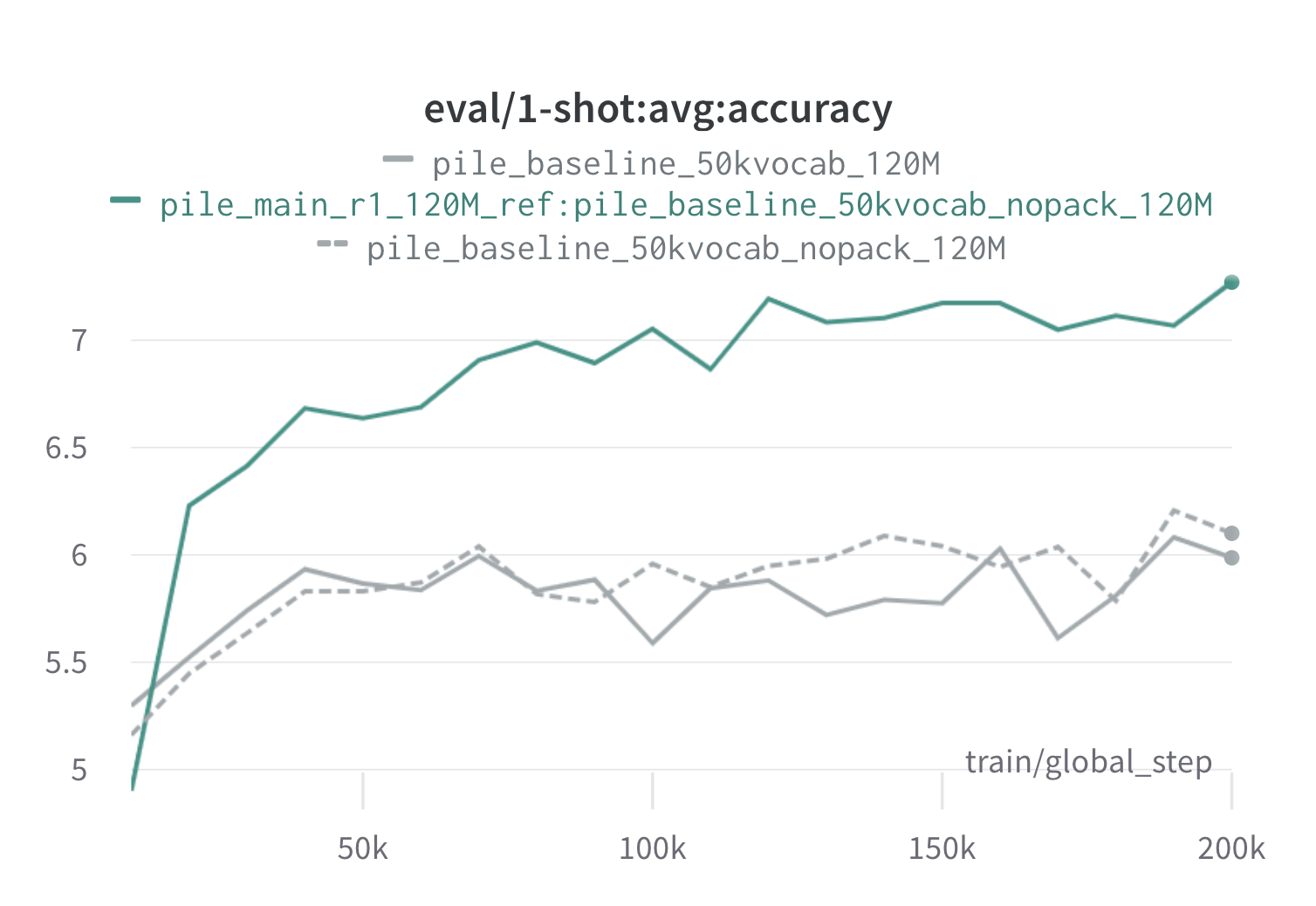
以下是使用120m代理和參考模型(帶有scripts/run_pile.sh )在樁上的一輪Doremi的結果。我們使用優化的權重訓練120m型號( configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json ),並將其與基線(灰色)進行比較。兩個基線代表了兩種略有不同的方法來計算樁中的基線域權重(Nopack計算每個文檔將每個文檔填充到上下文窗口長度後的每個域中的示例數,而PACK首先將文檔串聯到一個域中),這會產生相似的模型。經過doremi域重量訓練的模型在訓練期間很早就超過了基線的單桿性能,在所有任務中,在70k步長(快3倍)內。 DOREMI模型超過了20K步驟內的平均基線單球性能,在15/22域上改善或可比性的困惑,並改善了整個域的平均平均和最差的困惑。
如果這對您有用,請引用紙張:
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}


