doremi
1.0.0
言語モデリングデータセットのデータ混合を最適化するためのアルゴリズムであるDoremiのPytorch実装。最新の大規模な言語モデルは、多くのドメイン(Web、書籍、Arxivなど)でトレーニングされていますが、特にこれらのモデルはさまざまなダウンストリームタスクに使用されるため(最適化する特定のターゲット分布はありません)、訓練する各ドメインのどれだけが不明です。 Doremiは、分布的に堅牢な最適化(DRO)を使用して、データ混合物をターゲット分布に堅牢にするように調整します。 Doremiは、DROを使用して小型プロキシモデルをトレーニングします。DROは、前提条件の参照モデルと比較して、プロキシモデルの過剰損失に基づいて動的に高級またはダウンウェイトドメインを訓練します。参照モデルは、高エントロピー /ハードドメインに対して悲観的であることを避けるために達成可能な最良の損失の推定値を提供します。調整されたデータ混合物を使用して、はるかに大きなモデルをより効率的にトレーニングできます。このペーパーでは、280mのプロキシモデルが8Bパラメーターモデル(30倍大きい)のトレーニングを改善できるため、ベースライン8Bパフォーマンス2.6倍をより速く実現できます。以下のグラフィックは、Doremiの概要を示しています。詳細については、論文をご覧ください。
ブラックボックスとして、このコードベースは、テキストデータセットを与えられた最適化されたドメインの重みを出力します。他のいくつかの有用なコンポーネント:ドメインレベルの加重サンプリングを備えた高速で再開可能なデータローダー、単純なダウンストリーム評価ハーネス、およびハギングフェイストレーナー + Flashattention2統合。

開始するには、リポジトリをクローンしてインストールしてください。
git clone [email protected]:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
scripts/setup_flash.shのコンピレーションには、かなりの時間(時間)がかかる場合があります。すべてのコードは、最も外側のdoremiディレクトリから実行する必要があります。開始する前に、このリポジトリの外部ディレクトリのconstants.shファイルのキャッシュディレクトリ、データディレクトリなどへのパスを書き込みます。また、CondaまたはVirtualenv Activationコマンドをここに配置することもできます。 constants.shファイルの内容の例を次に示します( sample_constants.shというファイルとして提供):
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # will be created by scripts/run_preprocess_pile.sh
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases key for logging
PARTITION=partition # for slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # if you installed doremi in venv
パイルでプリプロシングするデータのためにサンプルスクリプトを実行する方法を次に示します。これにより、パイルデータをドメインに分離してトークン化します。
bash scripts/run_preprocess_pile.sh
これは、8 A100 GPUで1つのノードでテストされた120mのベースライン、プロキシ、およびメインモデル(Doremiパイプラインの3つのステップすべて)を実行するサンプルスクリプトです。これは、紙のパイル実験の小さなバージョンです。スクリプトは自動的に困惑と少数のショット評価を実行します。
bash scripts/run_pile.sh
これらのスクリプトは、論文に続いて200kステップで実行されます。 doremiは、fileName <RUN_NAME>.jsonを使用して、 configsディレクトリにドメインの重みを出力します。
独自のデータセットでDoremiを実行するには、次の形式で前処理された(トークン化された)データを提供します。
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
各内側のディレクトリ(例: domain_name_1 )は、huggingfaceのload_from_diskメソッドを介してロードできます。データが別の形式の場合、 doremi/dataloader.pyにカスタムデータ読み込み関数を追加できます。また、構成ファイルを書き込み、 configs/およびconfigs scripts/runs/run_pile_baseline120M.sh scripts/runs/run_pile_doremi120M.shと同様の実行スクリプトを作成するように保存する必要があります。構成ファイルは、ドメイン名から混合重量までのマッピングを指定します。名前を順番にする必要はありません(Doremiは常に最初にドメイン名をソートして固定順序を決定します)、重みを正規化する必要はありません。
--reweight_eps ) :ペーパーで使用されるデフォルト設定は1ですが、これは異なるデータセットで調整できます。一般的に、トレーニング中のドメインの重みはやや騒々しく、平均ドメインの重みがほとんど滑らかであると予想しています。kステップの勾配を蓄積すると、以前の反復から古いドメインの重みに対して計算されたk-1勾配があります(この問題はk=1には存在しません)。このレポと、Googleで開発された論文の間には、次のような違いがあることに注意してください。
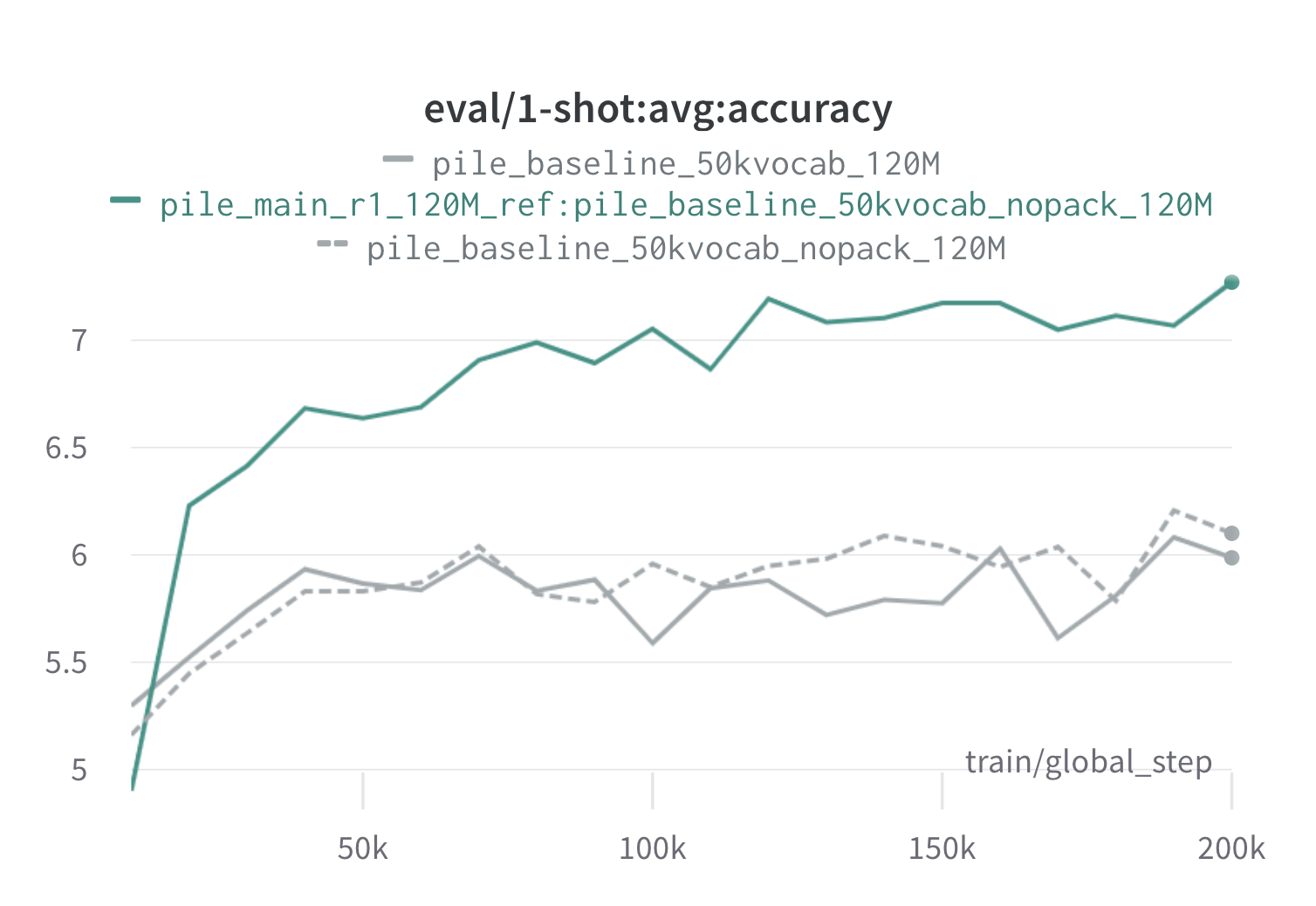
以下は、120mのプロキシモデルと参照モデル( scripts/run_pile.shを使用)を使用して、パイル上の1ラウンドのドレミの結果です。最適化された重み( configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json )を使用して120mモデルをトレーニングし、ベースライン(灰色)と比較します。 2つのベースラインは、パイル内のベースラインドメインの重みを計算する2つのわずかに異なる方法を表しています(NOPACKは、各ドキュメントをコンテキストウィンドウの長さにパディングした後、各ドメインの例の数をカウントしますが、パックは最初に1つのドメイン内のドキュメントを連結します)。 Doremiドメインウェイトで訓練されたモデルは、トレーニング中に非常に早い段階でベースラインのワンショットパフォーマンスを上回り、すべてのタスクで70Kステップ(3倍高速)以内にいます。 Doremiモデルは、20Kステップ以内の平均ベースラインワンショットパフォーマンスを上回り、15/22ドメインで改善または同等の困惑を講じ、ドメイン全体で均一に平均化されたものと最悪の困惑を改善します。
これがあなたに役立つなら、論文を引用してください:
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}


