doremi
1.0.0
A implementação de Pytorch do Doremi, um algoritmo para otimizar as misturas de dados para conjuntos de dados de modelagem de idiomas. Modelos de idiomas grandes modernos são treinados em muitos domínios (web, livros, arxiv etc.), mas quanto de cada domínio treinar não é claro, especialmente porque esses modelos serão usados para uma variedade de tarefas a jusante (nenhuma distribuição de alvo específica para otimizar). Doremi sintoniza a mistura de dados para ser robusta para a distribuição de destino usando otimização distributária robusta (DRO). O Doremi treina um pequeno modelo de proxy usando DRO, que dinamicamente os domínios de peso ou baixo dinamicamente com base na perda de excesso do modelo de proxy em comparação com um modelo de referência pré -treinamento. O modelo de referência fornece uma estimativa da melhor perda possível para evitar ser pessimista para domínios de entropia alta / dura. A mistura de dados ajustada pode ser usada para treinar um modelo muito maior com mais eficiência. No artigo, um modelo de proxy de 280m pode melhorar o treinamento de um modelo de parâmetros 8B (30x maior), permitindo que ele atinja o desempenho da linha de base 8B 2,6x mais rápido. O gráfico abaixo fornece uma visão geral de Doremi. Confira o papel para mais detalhes.
Como uma caixa preta, esta base de código produz pesos otimizados do domínio, dado um conjunto de dados de texto. Alguns outros componentes úteis: Dataloader rápido e rápido com amostragem ponderada em nível de domínio, arreios de avaliação simples a jusante e integração do HuggingFace + Flashattion2.

Para começar, clone o repositório e instale -o:
git clone [email protected]:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
A compilação em scripts/setup_flash.sh pode levar uma quantidade significativa de tempo (horas). Todo o código deve ser executado no diretório doremi mais externo. Antes de começar, escreva caminhos para seus diretórios de cache, diretórios de dados, etc. em um arquivo constants.sh no diretório externo deste repositório. Você também pode colocar quaisquer comandos de ativação do CONDA ou VirtualENV aqui. Aqui está um exemplo do conteúdo de um arquivo constants.sh (fornecido como um arquivo chamado sample_constants.sh ):
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # will be created by scripts/run_preprocess_pile.sh
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases key for logging
PARTITION=partition # for slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # if you installed doremi in venv
Aqui está como executar o script de amostra para pré -processamento de dados na pilha, que separa os dados da pilha em domínios e o tokeniza:
bash scripts/run_preprocess_pile.sh
Aqui está um script de amostra para executar 120m de linha de base, proxy e modelos principais (todas as 3 etapas do pipeline Doremi), testadas em um nó com 8 GPUs A100. Esta é uma versão pequena dos experimentos de pilha no papel. O script executará automaticamente a perplexidade e a avaliação de poucas fotos:
bash scripts/run_pile.sh
Esses scripts são executados para 200 mil etapas, seguindo o artigo. O Doremi Run sai pesos de domínio no diretório configs com o nome do arquivo <RUN_NAME>.json .
Para executar o Doremi em seu próprio conjunto de dados, forneça dados pré -processados (tokenizados) no seguinte formato:
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
onde cada diretório interno (por exemplo, domain_name_1 ) pode ser carregado através do método load_from_disk do huggingface. Se seus dados estiverem em um formato diferente, você poderá adicionar uma função de carregamento de dados personalizada em doremi/dataloader.py . Você também precisará gravar um arquivo de configuração e salvá -lo para configs/ e gravar scripts de execução semelhantes aos scripts/runs/run_pile_baseline120M.sh e scripts/runs/run_pile_doremi120M.sh que se referem ao arquivo config. O arquivo de configuração especifica o mapeamento do nome do domínio para o peso da mistura. Os nomes não precisam estar em ordem (Doremi sempre classificará os nomes de domínio primeiro para determinar uma ordem fixa) e os pesos não precisam ser normalizados.
--reweight_eps ) : a configuração padrão usada no papel é 1, embora isso possa ser ajustado para diferentes conjuntos de dados. Geralmente, esperamos que os pesos do domínio durante o treinamento sejam um tanto barulhentos e os pesos médios do domínio são mais suaves.k , haverá gradientes k-1 calculados contra pesos de domínio obsoleto da iteração anterior (esse problema não existe para k=1 ).Observe que existem algumas diferenças entre este repo e o artigo, que foi desenvolvido no Google, a saber:
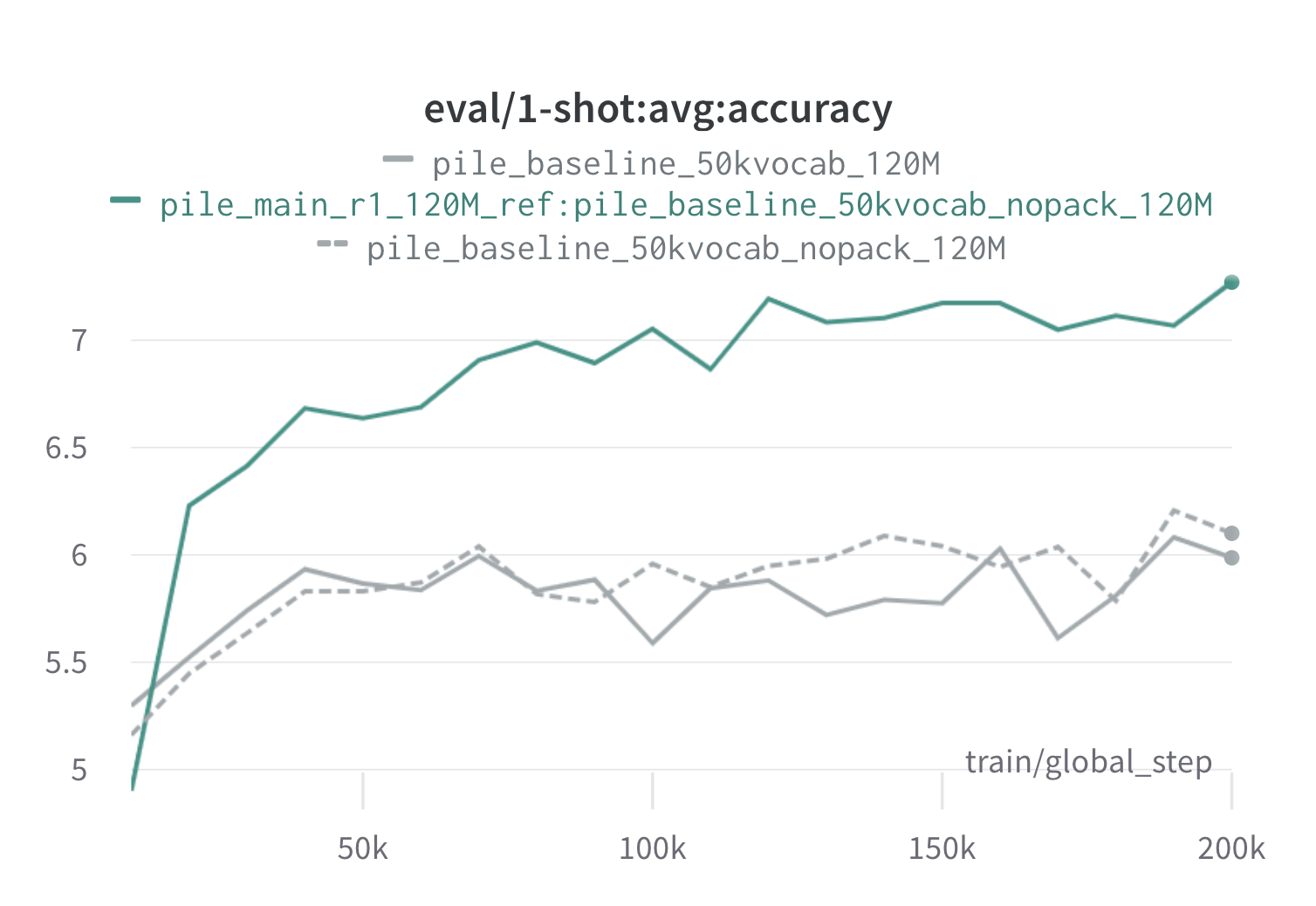
Abaixo estão os resultados de uma rodada de Doremi na pilha usando modelos de proxy e referência de 120m (com scripts/run_pile.sh ). Treinamos um modelo de 120m usando os pesos otimizados ( configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json ) e comparamos com as linhas de base (cinza). As duas linhas de base representam duas maneiras ligeiramente diferentes de calcular os pesos do domínio da linha de base na pilha (o NOPACK conta o número de exemplos em cada domínio após a preenchimento de cada documento para o comprimento da janela de contexto, enquanto o empacota concatena os documentos em um domínio primeiro), que produzem modelos de desempenho semelhante. O modelo treinado com os pesos do domínio Doremi ultrapassa o desempenho de uma fila de linha de base muito cedo durante o treinamento, dentro de 70 mil passos (3x mais rápido) em todas as tarefas. O modelo Doremi ultrapassa o desempenho médio da linha de base basal em 20 mil etapas, melhorou ou comparável perplexidade em domínios 15/22 e melhora a média de média uniformemente e a pior perplexidade entre os domínios.
Se isso foi útil para você, cite o papel:
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}


