doremi
1.0.0
Pytorch -Implementierung von Doremi, einem Algorithmus zur Optimierung von Datenmischungen für Sprachmodellierungsdatensätze. Moderne Großsprachenmodelle werden in vielen Domänen (Web, Bücher, Arxiv usw.) geschult. Doremi stimmt das Datenmisch, das der Zielverteilung mithilfe der verteilt robusten Optimierung (DRO) robust ist. Doremi trainiert ein kleines Proxymodell mit DRO, das dynamisch in Gewicht oder Downgewichtet von Domänen auf der Grundlage des überschüssigen Verlusts des Proxy -Modells im Vergleich zu einem vorbereiteten Referenzmodell basieren. Das Referenzmodell liefert eine Schätzung des besten Verlusts, um nicht pessimistisch für hohe Entropie- / Hartbereiche zu sein. Das abgestimmte Datengemisch kann dann verwendet werden, um ein viel größeres Modell effizienter zu trainieren. In der Arbeit kann ein 280 m -Proxy -Modell das Training eines 8B -Parametermodells (30x größer) verbessern, sodass es die Basis -8b -Leistung von 2,6x schneller erreicht. Die folgende Grafik bietet einen Überblick über Doremi. Weitere Informationen finden Sie in der Zeitung.
Als schwarzes Feld gibt diese Codebasis optimierte Domänengewichte aus, die einen Textdatensatz haben. Einige andere nützliche Komponenten: Schnell, wiederauflösbarer Dataloader mit gewichteter Abtastung auf Domänenebene, einfachem nachgeschaltetem Eval-Kabelbaum und Integration von Huggingface Trainer + Flashattention2.

Bitte klonen Sie das Repo und installieren Sie es: Installieren Sie es:
git clone [email protected]:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
Die Kompilierung in scripts/setup_flash.sh kann erhebliche Zeit (Stunden) in Anspruch nehmen. Der gesamte Code sollte aus dem äußersten doremi -Verzeichnis ausgeführt werden. Schreiben Sie vor Beginn die Pfade in Ihre Cache -Verzeichnisse, Datenverzeichnisse usw. in einer constants.sh -Datei im äußeren Verzeichnis dieses Repo. Hier können Sie auch alle Conda- oder Virtualenv -Aktivierungsbefehle hier platzieren. Hier ist ein Beispiel für den Inhalt einer constants.sh -Datei (bereitgestellt als Datei namens sample_constants.sh ):
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # will be created by scripts/run_preprocess_pile.sh
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases key for logging
PARTITION=partition # for slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # if you installed doremi in venv
Hier erfahren Sie, wie Sie das Beispielskript für die Datenvorverarbeitung auf dem Stapel ausführen, das die Stapeldaten in Domänen aufteilt und es tokenisiert:
bash scripts/run_preprocess_pile.sh
Hier ist ein Beispielskript, um 120 m Baseline, Proxy und Hauptmodelle (alle 3 Schritte in der Doremi -Pipeline) auszuführen, die auf einem Knoten mit 8 A100 GPUs getestet wurden. Dies ist eine kleine Version der Stapelversuche im Papier. Das Skript wird automatisch verwirrt und nur wenige Schüsse-Bewertungen ausführen:
bash scripts/run_pile.sh
Diese Skripte werden für 200K -Schritte ausgeführt, und folgen dem Papier. Die Doremi -Ausführung gibt Domänengewichte im Verzeichnis configs mit Dateiname <RUN_NAME>.json aus.
Um Doremi in Ihrem eigenen Datensatz auszuführen, geben Sie im folgende Format vorverarbeitete (tokenisierte) Daten an:
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
load_from_disk jedes innere Verzeichnis ( domain_name_1 . Wenn sich Ihre Daten in einem anderen Format befinden, können Sie eine benutzerdefinierte Datenladefunktion in doremi/dataloader.py hinzufügen. Sie müssen auch eine Konfigurationsdatei schreiben und in configs/ und schreiben Sie Skripts aus scripts/runs/run_pile_baseline120M.sh und scripts/runs/run_pile_doremi120M.sh ähnelt und die sich auf die Konfigurationsdatei beziehen. Die Konfigurationsdatei gibt die Zuordnung vom Domänennamen zum Mischgewicht an. Die Namen müssen nicht in Ordnung sein (Doremi sortiert immer die Domain -Namen zuerst, um eine feste Bestellung zu bestimmen) und die Gewichte müssen nicht normalisiert werden.
--reweight_eps ) : Die im Papier verwendete Standardeinstellung beträgt 1, obwohl dies für verschiedene Datensätze abgestimmt werden kann. Im Allgemeinen erwarten wir, dass die Domänengewichte während des Trainings etwas laut sind und die gemittelten Domänengewichte größtenteils glatt sind.k Schritte sammeln, werden k-1 Gradienten aus der vorherigen Iteration mit abgestandenen Domänengewichten berechnet (dieses Problem existiert nicht für k=1 ).Beachten Sie, dass es einige Unterschiede zwischen diesem Repo und dem Papier gibt, das bei Google entwickelt wurde, nämlich:
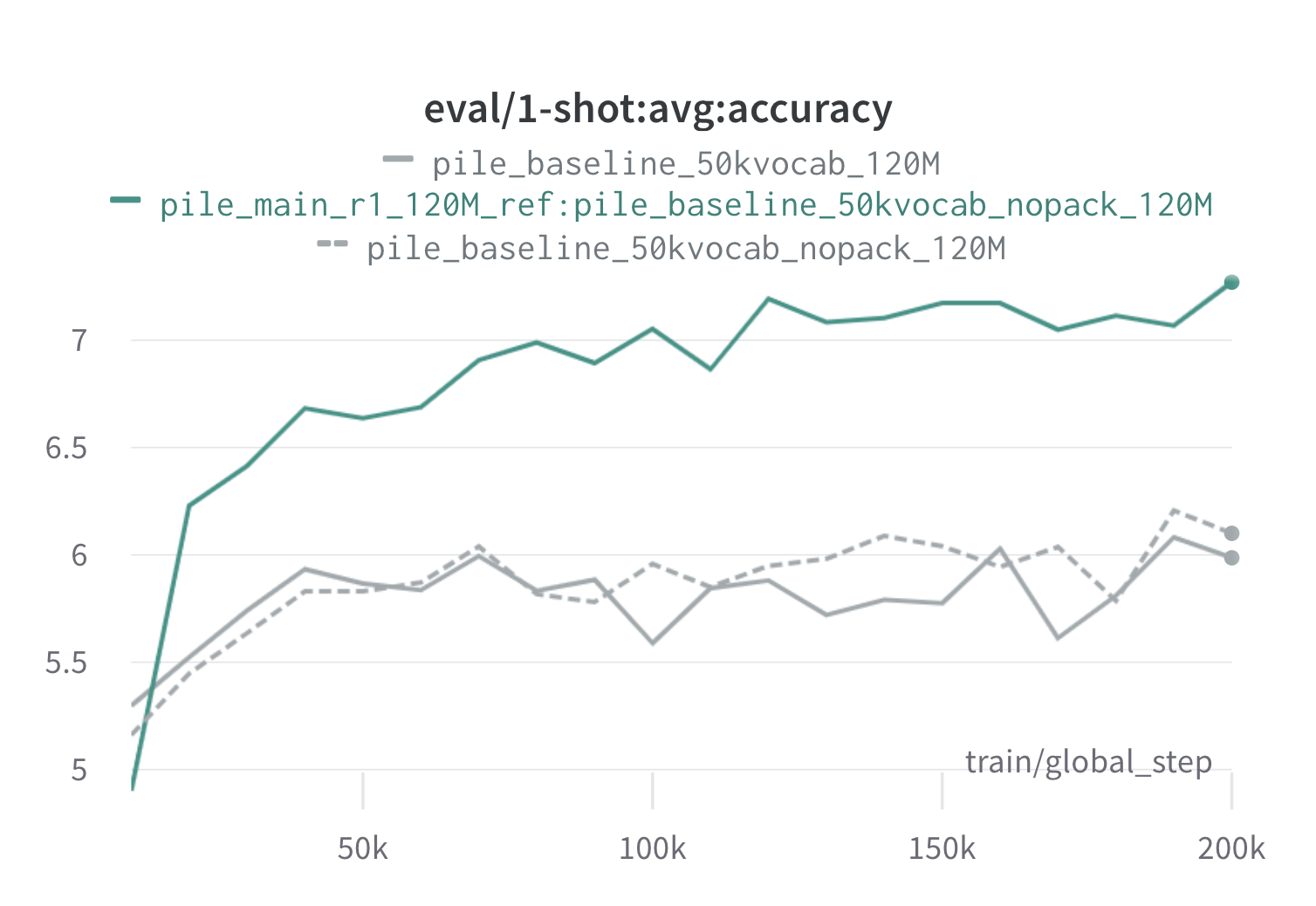
Im Folgenden finden Sie Ergebnisse aus einer Runde Doremi auf dem Stapel mit 120 -m -Proxy- und Referenzmodellen (mit scripts/run_pile.sh ). Wir trainieren ein 120 -m -Modell mit den optimierten Gewichten ( configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json ) und vergleichen es mit den Baselines (grau). Die beiden Basislinien stellen zwei leicht unterschiedliche Möglichkeiten zur Berechnung der Basisdomänengewichte im Stapel dar (NOPACK zählt die Anzahl der Beispiele in jeder Domäne nach dem Auffüllen jedes Dokuments in die Kontextfensterlänge, während Pack die Dokumente zuerst in einer Domäne verkettet werden), die ähnliche Leistungsmodelle erzeugen. Das mit Doremi-Domänengewichten ausgebildete Modell übertrifft die Ein-Schuss-Basisleistung sehr früh während des Trainings innerhalb von 70 km Schritten (3x schneller) über alle Aufgaben. Das Doremi-Modell übertrifft die durchschnittliche One-Shot-Leistung in 20.000 Schritten, hat auf 15/22-Domänen verbessert oder vergleichbar und verbessert sowohl eine durchschnittliche als auch die schlechteste Verwirrung der Kasenteile über die Domänen hinweg.
Wenn dies für Sie nützlich war, zitieren Sie bitte das Papier:
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}


