doremi
1.0.0
Pytorch Implémentation de Doremi, un algorithme pour optimiser les mélanges de données pour les ensembles de données de modélisation du langage. Les modèles modernes de grande langue sont formés sur de nombreux domaines (Web, livres, arxiv, etc.), mais la quantité de chaque domaine à former n'est pas claire, d'autant plus que ces modèles seront utilisés pour une variété de tâches en aval (aucune distribution cible particulière à optimiser). Doremi parcoure le mélange de données pour être robuste à la distribution cible en utilisant l'optimisation distribuée par distribution robuste (DRO). Doremi entraîne un petit modèle proxy utilisant DRO, qui inopporce dynamiquement ou les domaines des poids réduits basés sur la perte excédentaire du modèle proxy par rapport à un modèle de référence pré-étendu. Le modèle de référence fournit une estimation de la meilleure perte réalisable pour éviter d'être pessimiste pour les domaines d'entropie / durs élevés. Le mélange de données réglé peut ensuite être utilisé pour former un modèle beaucoup plus important plus efficacement. Dans l'article, un modèle proxy de 280 m peut améliorer la formation d'un modèle de paramètres 8B (30x plus grand), ce qui lui permet d'atteindre les performances de base 8B 2,6x plus rapidement. Le graphique ci-dessous donne un aperçu de Doremi. Consultez le journal pour plus de détails.
En tant que boîte noire, cette base de code obtient des poids de domaine optimisés compte tenu d'un ensemble de données de texte. Quelques autres composants utiles: un coader de données rapide et reprise avec un échantillonnage pondéré au niveau du domaine, un harnais d'évaluation simple en aval et une intégration Flashattention2 en aval.

Pour commencer, veuillez cloner le repo et l'installer:
git clone [email protected]:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
La compilation dans scripts/setup_flash.sh peut prendre un temps important (heures). Tout le code doit être exécuté à partir du répertoire doremi le plus extérieur. Avant de commencer, écrivez des chemins vers vos répertoires de cache, répertoires de données, etc. dans un fichier constants.sh dans le répertoire extérieur de ce repo. Vous pouvez également placer toutes les commandes d'activation Conda ou VirtualEnv ici. Voici un exemple du contenu d'un fichier constants.sh (fourni en tant que fichier appelé sample_constants.sh ):
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # will be created by scripts/run_preprocess_pile.sh
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases key for logging
PARTITION=partition # for slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # if you installed doremi in venv
Voici comment exécuter l'exemple de script pour le prétraitement des données sur la pile, qui sépare les données de la pile dans les domaines et les tokenise:
bash scripts/run_preprocess_pile.sh
Voici un exemple de script pour exécuter 120 m de base, proxy et modèles principaux (les 3 étapes du pipeline Doremi), testées sur un nœud avec 8 GPU A100. Il s'agit d'une petite version des expériences de pile dans le papier. Le script exécutera automatiquement la perplexité et l'évaluation à quelques coups:
bash scripts/run_pile.sh
Ces scripts fonctionnent pour 200 000 étapes, suivant le papier. Le DoreMi Exécute des poids du domaine dans le répertoire configs avec FileName <RUN_NAME>.json .
Pour exécuter Doremi sur votre propre ensemble de données, fournissez des données prétraitées (tokenisées) dans le format suivant:
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
où chaque répertoire intérieur (par exemple, domain_name_1 ) peut être chargé via la méthode load_from_disk de HuggingFace. Si vos données sont dans un format différent, vous pouvez ajouter une fonction de chargement de données personnalisée dans doremi/dataloader.py . Vous devrez également écrire un fichier de configuration et l'enregistrer dans configs/ et écrire des scripts RUN similaires aux scripts/runs/run_pile_baseline120M.sh et scripts/runs/run_pile_doremi120M.sh qui se réfèrent au fichier de configuration. Le fichier de configuration spécifie le mappage du nom de domaine au poids du mélange. Les noms ne doivent pas être en ordre (Doremi trie d'abord les noms de domaine pour déterminer une commande fixe) et les poids n'ont pas à être normalisés.
--reweight_eps ) : le paramètre par défaut utilisé dans le papier est 1, bien que cela puisse être réglé pour différents ensembles de données. Généralement, nous nous attendons à ce que les poids du domaine pendant l'entraînement soient quelque peu bruyants et que les poids moyens du domaine soient principalement lisses.k étapes, il y aura des gradients k-1 calculés contre les poids du domaine périmé de l'itération précédente (ce problème n'existe pas pour k=1 ).Notez qu'il existe quelques différences entre ce dépôt et le document, qui a été développé chez Google, à savoir:
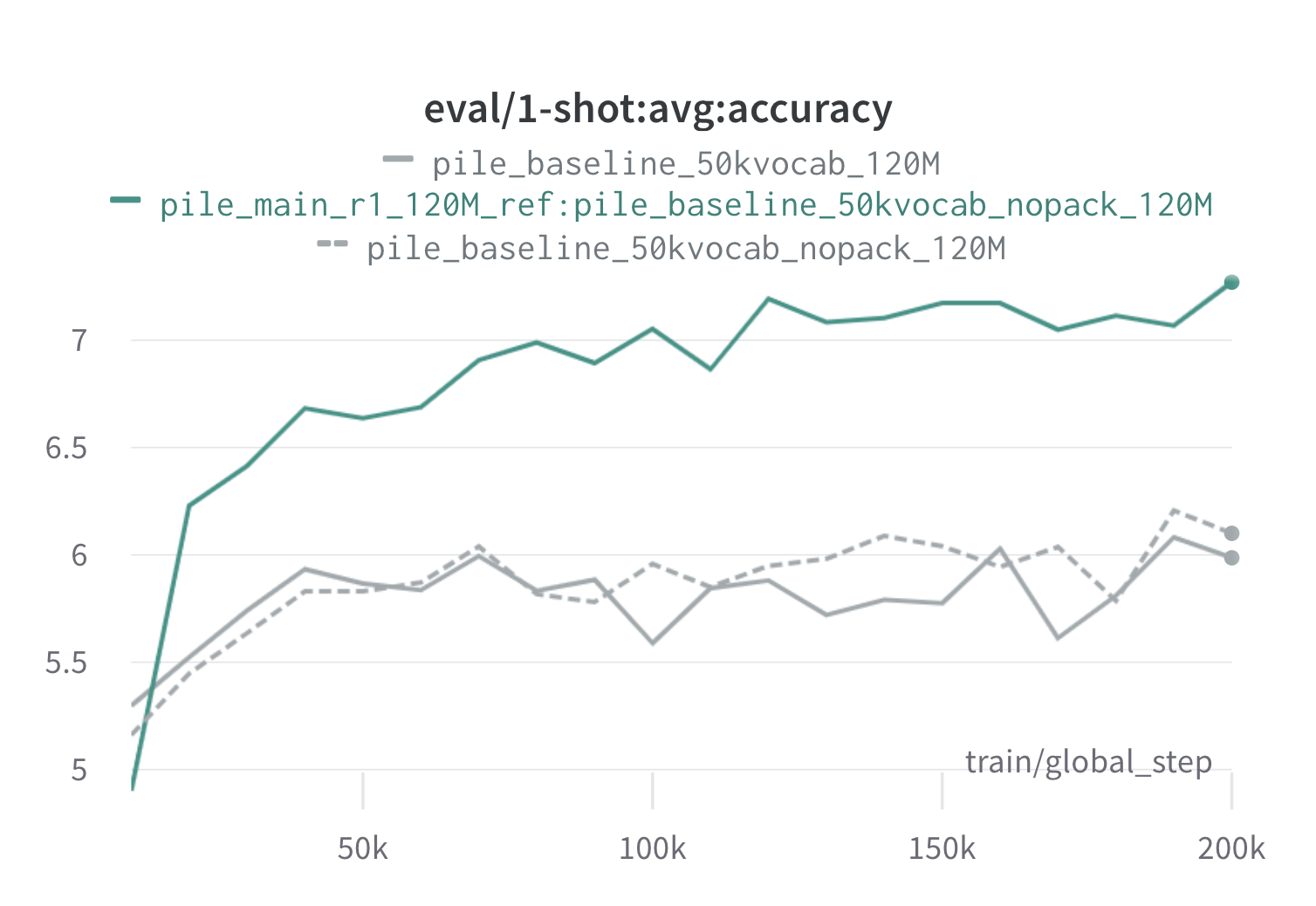
Vous trouverez ci-dessous les résultats d'un tour de Doremi sur le pieu en utilisant des modèles proxy et de référence de 120 m (avec scripts/run_pile.sh ). Nous formons un modèle de 120 m en utilisant les poids optimisés ( configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json ) et le comparons aux lignes de base (gris). Les deux lignes de base représentent deux façons légèrement différentes de calculer les poids de domaine de base dans la pile (Nopack compte le nombre d'exemples dans chaque domaine après le rembourrage de chaque document sur la longueur de la fenêtre de contexte, tandis que Pack concaTène les documents dans un domaine en premier), qui produisent des modèles similaires. Le modèle formé avec des poids de domaine Doremi dépasse les performances à un coup de base très tôt pendant l'entraînement, dans les 70 000 étapes (3x plus rapidement) dans toutes les tâches. Le modèle Doremi dépasse les performances moyennes à un coup de base dans les étapes de 20k, a une perplexité améliorée ou comparable sur les domaines 15/22 et améliore à la fois une perplexité moyenne et pire des cas à travers les domaines.
Si cela vous était utile, veuillez citer le papier:
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}


