doremi
1.0.0
تنفيذ Pytorch لـ Doremi ، وهي خوارزمية لتحسين خلائط البيانات لمجموعات بيانات نمذجة اللغة. يتم تدريب نماذج اللغة الكبيرة الحديثة على العديد من المجالات (الويب ، والكتب ، و Arxiv ، وما إلى ذلك) ، ولكن مقدار كل مجال للتدريب غير واضح ، خاصة وأن هذه النماذج سيتم استخدامها لمجموعة متنوعة من المهام المصب (لا يوجد توزيع مستهدف معين لتحسينه). يقوم Doremi بإلغاء مزيج البيانات ليكون قويًا للتوزيع المستهدف باستخدام التحسين القوي توزيليًا (DRO). تدرب Doremi نموذجًا صغيرًا للوكيل باستخدام DRO ، والذي يزداد وزنًا ديناميكيًا أو مجالات لأسفل على أساس الخسارة الزائدة لنموذج الوكيل مقارنةً بنموذج مرجعي مسبق. يوفر النموذج المرجعي تقديرًا لأفضل خسارة يمكن تحقيقها لتجنب أن تكون متشائمة للنطاقات العالية / الصلبة. يمكن بعد ذلك استخدام خليط البيانات المضبط لتدريب نموذج أكبر بكثير بشكل أكثر كفاءة. في الورقة ، يمكن أن يحسن نموذج وكيل 280 مترًا من تدريب نموذج المعلمة 8B (أكبر 30x) ، مما يسمح له بتحقيق أداء 8B الأساسي 2.6x بشكل أسرع. يوفر الرسم أدناه نظرة عامة على Doremi. تحقق من الورقة لمزيد من التفاصيل.
بصفتها مربعًا أسود ، تقوم قاعدة الكود هذه بإخراج أوزان المجال المحسنة مع مجموعة بيانات نصية. بعض المكونات الأخرى المفيدة: Dataloader سريعة الاستخدام مع أخذ عينات مرجحة على مستوى المجال ، وتسخير Eval Simple في اتجاه المصب ، وتكامل Huggingface + Flashattention2.

للبدء ، يرجى استنساخ الريبو وتثبيته:
git clone [email protected]:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
قد يستغرق التجميع في scripts/setup_flash.sh وقتًا كبيرًا من الوقت (ساعات). يجب تشغيل جميع الكود من دليل doremi الخارجي. قبل أن تبدأ ، اكتب مسارات إلى أدلة ذاكرة التخزين المؤقت ، دلائل البيانات ، إلخ في ملف constants.sh في الدليل الخارجي لهذا الريبو. يمكنك أيضًا وضع أي أوامر تنشيط Conda أو VirtualEnv هنا. فيما يلي مثال على محتويات ملف constants.sh (يتم توفيره كملف يسمى sample_constants.sh ):
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # will be created by scripts/run_preprocess_pile.sh
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases key for logging
PARTITION=partition # for slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # if you installed doremi in venv
فيما يلي كيفية تشغيل البرنامج النصي للبيانات المسبقة على الوبر ، الذي يفصل بيانات الوبر إلى مجالات وترميزها:
bash scripts/run_preprocess_pile.sh
فيما يلي نموذج نصي لتشغيل خط الأساس 120 متر ، والوكيل ، والموديلات الرئيسية (جميع الخطوات الثلاثة في خط أنابيب Doremi) ، تم اختباره على عقدة واحدة مع 8 A100 وحدات معالجة الرسومات. هذه نسخة صغيرة من تجارب الوبر في الورقة. سيقوم البرنامج النصي تلقائيًا بتشغيل الحيرة وتقييم القليل من اللقطة:
bash scripts/run_pile.sh
تعمل هذه البرامج النصية لمدة 200 ألف خطوة ، باتباع الورقة. يقوم Doremi Run بإخراج أوزان المجال في دليل configs مع اسم الملف <RUN_NAME>.json .
لتشغيل Doremi على مجموعة البيانات الخاصة بك ، توفير بيانات (رمزية) معالجة مسبقًا بالتنسيق التالي:
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
حيث يمكن تحميل كل دليل داخلي (على سبيل المثال ، domain_name_1 ) من خلال طريقة load_from_disk الخاصة بـ HuggingFace. إذا كانت بياناتك بتنسيق مختلف ، فيمكنك إضافة وظيفة تحميل بيانات مخصصة في doremi/dataloader.py . ستحتاج أيضًا إلى كتابة ملف تكوين وحفظه configs/ وكتابة البرامج النصية التي تشبه scripts/runs/run_pile_baseline120M.sh والبرامج scripts/runs/run_pile_doremi120M.sh التي تشير إلى ملف التكوين. يحدد ملف التكوين التعيين من اسم المجال إلى وزن الخليط. لا يجب أن تكون الأسماء بالترتيب (ستقوم Doremi دائمًا بفرز أسماء المجال أولاً لتحديد طلب ثابت) ولا يجب تطبيع الأوزان.
--reweight_eps ) : الإعداد الافتراضي المستخدم في الورقة هو 1 ، على الرغم من أنه يمكن ضبطه لمجموعات البيانات المختلفة. بشكل عام ، نتوقع أن تكون أوزان المجال أثناء التدريب صاخبة إلى حد ما وأن تكون أوزان المجال المتوسطة سلسة في الغالب.k ، فسيكون هناك تدرجات k-1 محسوبة ضد أوزان المجال التي لا معنى لها من التكرار السابق (هذه المشكلة لا توجد لـ k=1 ).لاحظ أن هناك بعض الاختلافات بين هذا الريبو والورقة ، والتي تم تطويرها في Google ، وهي:
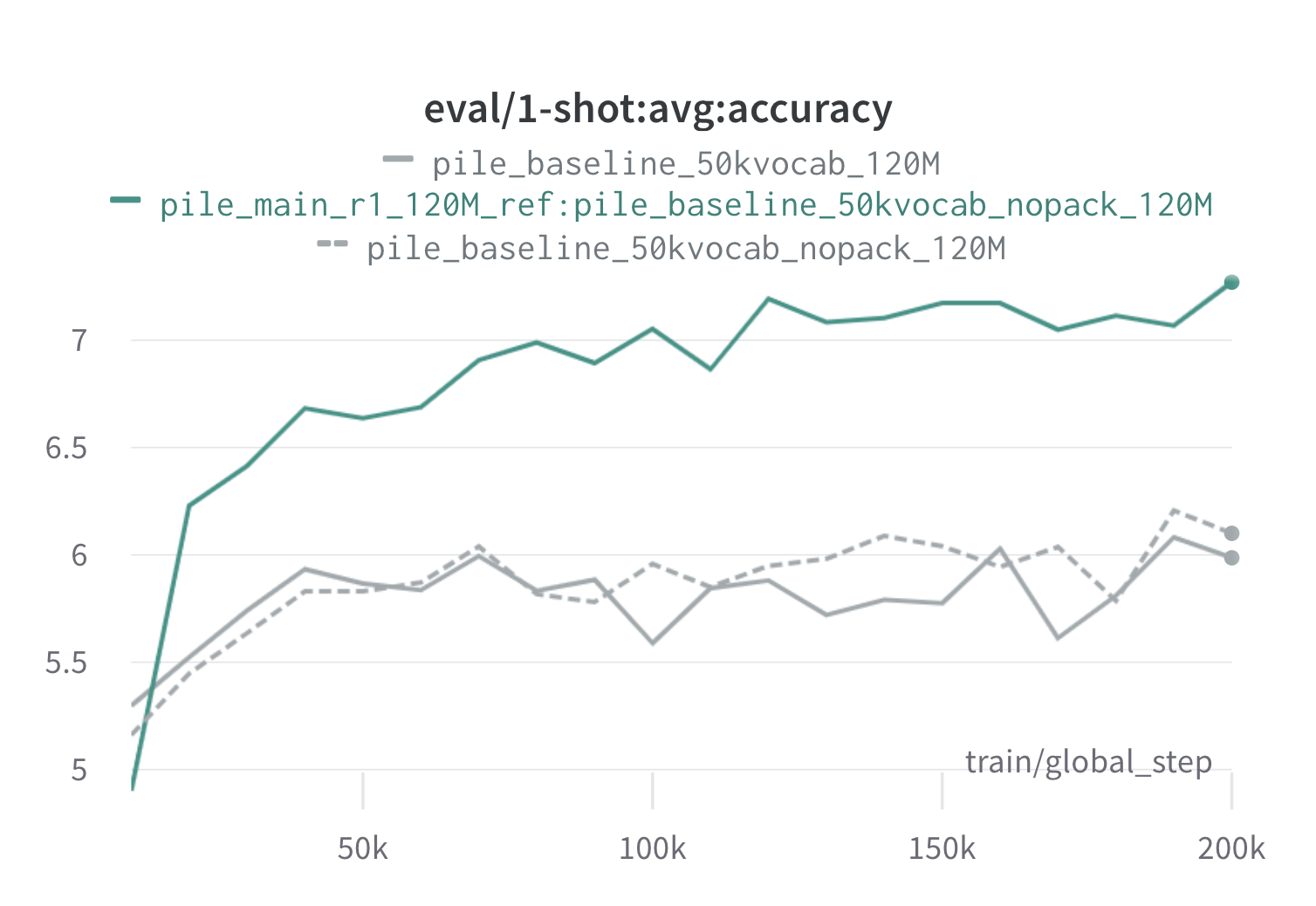
فيما يلي نتائج من جولة واحدة من doremi على الوبر باستخدام نماذج وكيل 120 متر مرجعية (مع scripts/run_pile.sh ). نقوم بتدريب طراز 120 مترًا باستخدام الأوزان المحسنة ( configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json ) ومقارنتها بالأساس (رمادي). يمثل خطوط الأساس اثنين من طريقتين مختلفتين قليلاً لحساب أوزان مجال خط الأساس في الوبر (يحسب Nopack عدد الأمثلة في كل مجال بعد حشوة كل مستند إلى طول نافذة السياق ، في حين أن حزم يسلط المستندات داخل مجال واحد أولاً) ، والتي تنتج نماذج متشابهة الأداء. يتجاوز النموذج الذي تم تدريبه مع أوزان مجال Doremi الأداء الأساسي لقطة واحدة في وقت مبكر جدًا أثناء التدريب ، ضمن خطوة 70 ألفًا (3x أسرع) في جميع المهام. يتجاوز نموذج Doremi متوسط أداء خط الأساس واحد في خطوة 20 ألف خطوة ، وقد تحسن أو محير مماثل في 15/22 مجالات ، ويحسن كل من الحيرة المتوسطة المتوسطة وأسوأ الحالات عبر المجالات.
إذا كان هذا مفيدًا لك ، فيرجى الاستشهاد بالورقة:
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}


