doremi
1.0.0
언어 모델링 데이터 세트를위한 데이터 혼합물을 최적화하기위한 알고리즘 인 Doremi의 Pytorch 구현. 현대의 대형 언어 모델은 많은 도메인 (웹, 서적, ARXIV 등)에 대해 교육을 받았지만, 특히 훈련해야 할 각 도메인의 양은 불분명합니다. 특히 이러한 모델은 다양한 다운 스트림 작업 (최적화 할 특정 대상 분포가 없음)에 사용되기 때문입니다. Doremi는 분포 강력한 최적화 (DRO)를 사용하여 데이터 혼합물을 대상 분포에 강력하게 조정합니다. Doremi는 예정된 기준 모델과 비교하여 프록시 모델의 초과 손실을 기반으로 동적으로 업력 또는 다운 웨이트 도메인을 사용하여 DRO를 사용하여 작은 프록시 모델을 훈련시킵니다. 참조 모델은 높은 엔트로피 / 하드 도메인에 대해 비관적 인 존재를 피하기 위해 달성 할 수있는 최상의 손실의 추정치를 제공합니다. 그런 다음 조정 된 데이터 혼합물을 사용하여 훨씬 더 큰 모델을보다 효율적으로 훈련시킬 수 있습니다. 이 논문에서 280m 프록시 모델은 8b 매개 변수 모델 (30 배 더 큰)의 훈련을 향상시켜 기준 8b 성능을 2.6 배 더 빠르게 달성 할 수 있습니다. 아래 그래픽은 Doremi의 개요를 제공합니다. 자세한 내용은 논문을 확인하십시오.
블랙 박스로서,이 코드베이스는 텍스트 데이터 세트가 주어진 최적화 된 도메인 가중치를 출력합니다. 다른 유용한 구성 요소 : 도메인 레벨 가중 샘플링, 간단한 다운 스트림 평가 하네스 및 Huggingface Trainer + FlashAttention2 통합 기능이있는 빠르고 재개 가능한 데이터 로더.

시작하려면 Repo를 복제하고 설치하십시오.
git clone [email protected]:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
scripts/setup_flash.sh 의 컴파일에는 상당한 시간이 걸릴 수 있습니다 (시간). 모든 코드는 가장 바깥 쪽 doremi 디렉토리에서 실행되어야합니다. 시작하기 전에이 Repo의 외부 디렉토리의 constants.sh 파일로 캐시 디렉토리, 데이터 디렉토리 등에 대한 경로를 작성하십시오. 여기에 Conda 또는 VirtualEnV 활성화 명령을 배치 할 수도 있습니다. 다음은 constants.sh 파일의 내용의 예입니다 ( sample_constants.sh 라는 파일로 제공) :
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # will be created by scripts/run_preprocess_pile.sh
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases key for logging
PARTITION=partition # for slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # if you installed doremi in venv
파일에서 데이터 전처리를위한 샘플 스크립트를 실행하는 방법은 다음과 같습니다.
bash scripts/run_preprocess_pile.sh
다음은 8 A100 GPU로 하나의 노드에서 테스트 한 120m 기준선, 프록시 및 주요 모델 (Doremi 파이프 라인의 3 단계)을 실행하는 샘플 스크립트입니다. 이것은 논문의 작은 버전의 파일 실험입니다. 스크립트는 자동으로 당황스럽고 소수의 평가를 실행합니다.
bash scripts/run_pile.sh
이 스크립트는 논문을 따라 200k 단계로 실행됩니다. Doremi는 filename <RUN_NAME>.json 사용하여 configs 디렉토리에서 도메인 가중치를 출력합니다.
자신의 데이터 세트에서 Doremi를 실행하려면 다음 형식으로 전처리 된 (토큰 화) 데이터를 제공하십시오.
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
여기서 각 내부 디렉토리 (예 : domain_name_1 )는 Huggingface의 load_from_disk 메소드를 통해로드 할 수 있습니다. 데이터가 다른 형식이면 doremi/dataloader.py 에 사용자 정의 데이터로드 기능을 추가 할 수 있습니다. 또한 구성 파일을 작성하고 구성/run/run_baseline120m.sh와 유사한 configs/ scripts/runs/run_pile_baseline120M.sh 및 scripts/runs/run_pile_doremi120M.sh 와 유사한 실행 스크립트를 작성해야합니다. 구성 파일을 참조하십시오. 구성 파일은 도메인 이름에서 혼합 무게로의 매핑을 지정합니다. 이름을 순서대로 할 필요는 없습니다 (Doremi는 항상 고정 순서를 결정하기 위해 도메인 이름을 먼저 정렬합니다). 가중치를 정규화 할 필요는 없습니다.
--reweight_eps ) : 종이에 사용 된 기본 설정은 1이지만 다른 데이터 세트에 대해 조정할 수 있습니다. 일반적으로, 우리는 훈련 중 도메인 가중치가 다소 시끄럽고 평균 도메인 가중치가 대부분 매끄럽게 될 것으로 기대합니다.k 단계에 대한 그라디언트를 축적하면 이전 반복의 오래된 도메인 가중치에 대해 k-1 그라디언트가 계산됩니다 (이 문제는 k=1 의 경우 존재하지 않음).이 저장소와 논문에는 Google에서 개발 된 논문간에 몇 가지 차이가 있습니다.
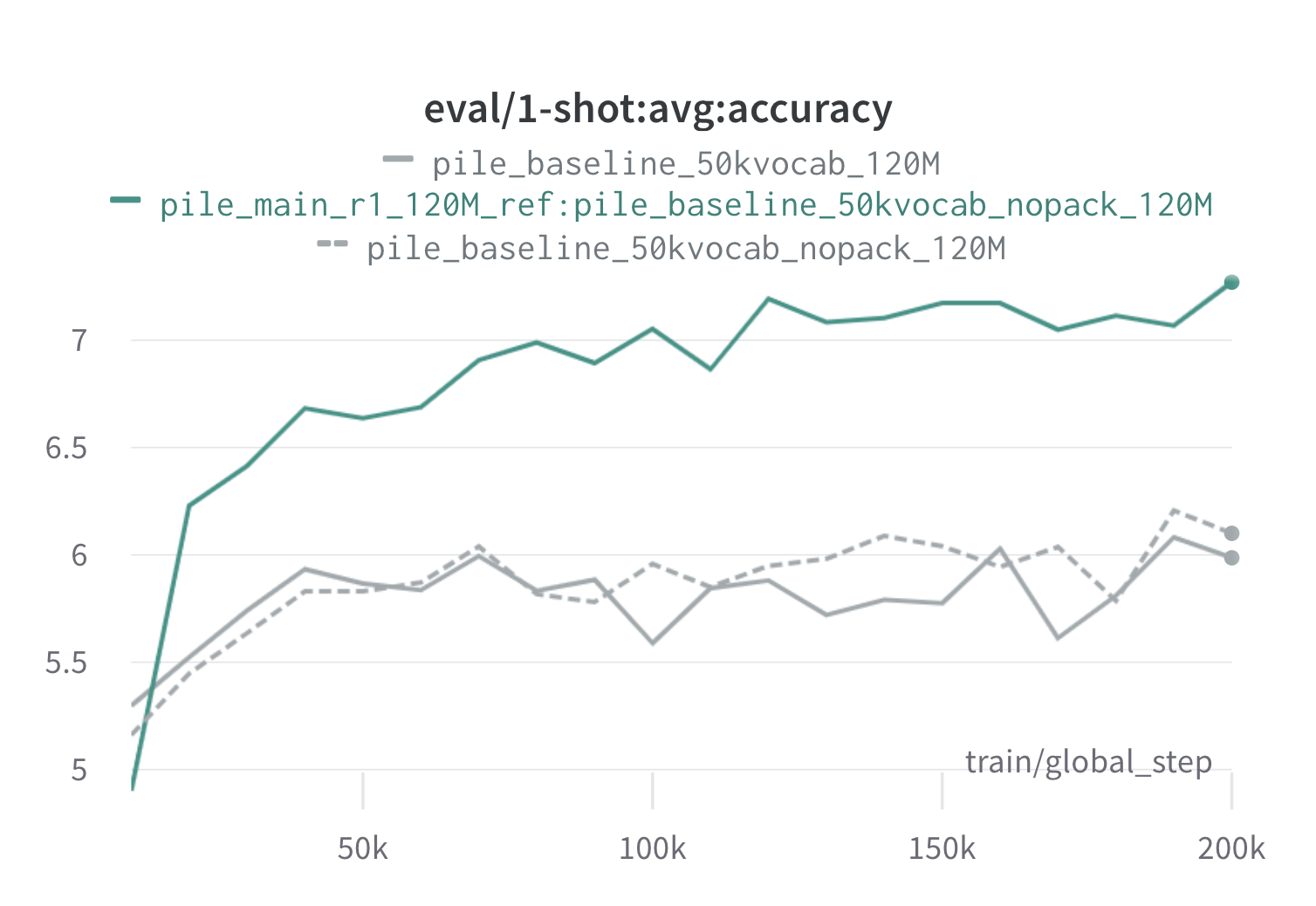
아래는 120m 프록시 및 참조 모델 ( scripts/run_pile.sh )을 사용하여 파일의 한 라운드의 도레미의 결과입니다. 최적화 된 가중치 ( configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json )를 사용하여 120m 모델을 훈련시키고 기준 (그레이)과 비교합니다. 두 기준선은 파일에서 기준 도메인 가중치를 계산하는 두 가지 약간 다른 방법을 나타냅니다 (Nopack은 각 문서가 컨텍스트 창 길이로 패딩 한 후 각 도메인의 예수를 계산하는 반면, 팩은 하나의 도메인 내에서 문서를 먼저 연결하는 반면, 유사한 성능 모델을 생성합니다. Doremi 도메인 가중치로 훈련 된이 모델은 훈련 중에 매우 일찍 기준 1 샷 성능을 능가합니다. Doremi 모델은 20K 단계 내에서 평균 기준 1- 샷 성능을 능가하고 15/22 도메인에서 개선되거나 비교할 수있는 당혹감을, 도메인에서 균일하게 평균화 된 최악의 당혹감을 향상시킵니다.
이것이 당신에게 유용하다면, 논문을 인용하십시오.
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}


