doremi
1.0.0
Implementación de Pytorch de Doremi, un algoritmo para optimizar las mezclas de datos para conjuntos de datos de modelado de idiomas. Los modelos modernos de idiomas grandes están capacitados en muchos dominios (web, libros, ARXIV, etc.), pero la cantidad de cada dominio para entrenar no está claro, especialmente porque estos modelos se utilizarán para una variedad de tareas aguas abajo (no hay una distribución de objetivos particular para optimizar). Doremi sintoniza la mezcla de datos para que sea robusta a la distribución de destino utilizando optimización distributionalmente robusta (DRO). Doremi entrena un pequeño modelo proxy que usa DRO, que los dominios de peso o pesos downwewights dinámicamente en función del exceso de pérdida del modelo proxy en comparación con un modelo de referencia previamente prenedRado. El modelo de referencia proporciona una estimación de la mejor pérdida que se puede lograr para evitar ser pesimista para la alta entropía / dominios duros. La mezcla de datos sintonizada se puede usar para entrenar un modelo mucho más grande de manera más eficiente. En el documento, un modelo proxy de 280 m puede mejorar el entrenamiento de un modelo de parámetros 8B (30x más grande), lo que le permite lograr el rendimiento de la línea de base 8B 2.6x más rápido. El siguiente gráfico proporciona una visión general de Doremi. Consulte el documento para obtener más detalles.
Como cuadro negro, esta base de código genera pesos de dominio optimizados que se le dan un conjunto de datos de texto. Algunos otros componentes útiles: dataLoader rápido y reanudable con muestreo ponderado a nivel de dominio, arnés de evaluación aguas abajo simple e integración de entrenador de superficie + flashattion2.

Para comenzar, clone el repositorio e instálelo:
git clone [email protected]:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
La compilación en scripts/setup_flash.sh puede tomar una cantidad significativa de tiempo (horas). Todo el código debe ejecutarse desde el directorio doremi más externo. Antes de comenzar, escriba rutas a sus directorios de caché, directorios de datos, etc. en un archivo constants.sh en el directorio exterior de este repositorio. También puede colocar cualquier comando de activación de Conda o VirtualEnv aquí. Aquí hay un ejemplo del contenido de un archivo constants.sh (proporcionado como un archivo llamado sample_constants.sh ):
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # will be created by scripts/run_preprocess_pile.sh
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases key for logging
PARTITION=partition # for slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # if you installed doremi in venv
Aquí está cómo ejecutar el script de muestra para el preprocesamiento de datos en la pila, que separa los datos de la pila en dominios y lo toca:
bash scripts/run_preprocess_pile.sh
Aquí hay un script de muestra para ejecutar 120 m de base, proxy y modelos principales (los 3 pasos en la tubería Doremi), probado en un nodo con 8 GPU A100. Esta es una versión pequeña de los experimentos de pila en el papel. El script ejecutará automáticamente la perplejidad y la evaluación de pocos disparos:
bash scripts/run_pile.sh
Estos scripts se ejecutan para 200k pasos, siguiendo el documento. El Doremi Ejecutar pesa de dominio en el directorio configs con nombre de archivo <RUN_NAME>.json .
Para ejecutar Doremi en su propio conjunto de datos, proporcione datos preprocesados (tokenizados) en el siguiente formato:
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
donde cada directorio interno (por ejemplo, domain_name_1 ) se puede cargar a través del método load_from_disk de Huggingface. Si sus datos están en un formato diferente, puede agregar una función de carga de datos personalizada en doremi/dataloader.py . También deberá escribir un archivo de configuración y guardarlo en configs/ y escribir scripts Ejecutar similares a scripts/runs/run_pile_baseline120M.sh y scripts/runs/run_pile_doremi120M.sh que se refieren al archivo de configuración. El archivo de configuración especifica la asignación del nombre de dominio al peso de la mezcla. Los nombres no tienen que estar en orden (Doremi siempre ordenará los nombres de dominio primero para determinar un pedido fijo) y los pesos no tienen que normalizarse.
--reweight_eps ) : la configuración predeterminada utilizada en el documento es 1, aunque esto podría ajustarse para diferentes conjuntos de datos. En general, esperamos que los pesos de dominio durante el entrenamiento sean algo ruidosos y que los pesos de dominio promedio sean mayormente suaves.k , habrá gradientes k-1 calculados contra pesos de dominio obsoleto de la iteración anterior (este problema no existe para k=1 ).Tenga en cuenta que hay algunas diferencias entre este repositorio y el documento, que se desarrolló en Google, a saber:
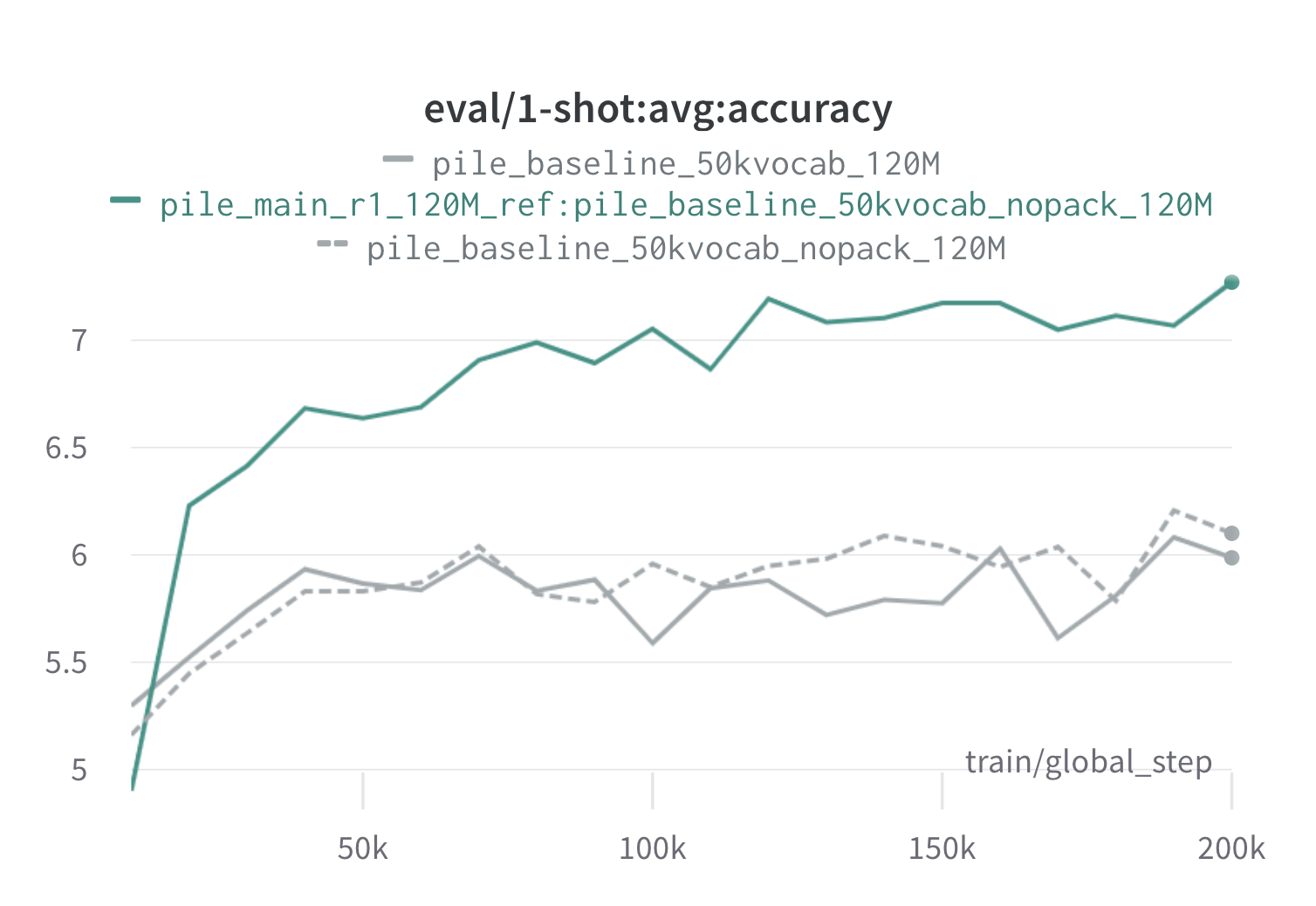
A continuación se presentan los resultados de una ronda de Doremi en la pila utilizando modelos de proxy y referencia de 120 m (con scripts/run_pile.sh ). Entrenamos un modelo de 120 m utilizando los pesos optimizados ( configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json ) y lo comparamos con las líneas de base (gris). Las dos líneas de base representan dos formas ligeramente diferentes de calcular los pesos del dominio de referencia en la pila (Nopack cuenta el número de ejemplos en cada dominio después de rellenar cada documento a la longitud de la ventana de contexto, mientras que el paquete concatena los documentos dentro de un dominio primero), que producen modelos de rendimiento similar. El modelo entrenado con pesos del dominio Doremi supera el rendimiento de una sola vez de la línea de base muy temprano durante el entrenamiento, dentro de 70k pasos (3 veces más rápido) en todas las tareas. El modelo Doremi supera el rendimiento promedio de una sola vez en un disparo dentro de 20k pasos, ha mejorado o comparable la perplejidad en los dominios 15/22, y mejora la perplejidad uniformemente promedio y peor de los casos en todos los dominios.
Si esto fue útil para usted, por favor cita el documento:
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}


