doremi
1.0.0
Реализация Pytorch Doremi, алгоритм для оптимизации смесей данных для наборов данных для моделирования языка. Современные крупные языковые модели обучаются многим областям (веб -сайт, книги, arxiv и т. Д.), Но какая часть каждого домена для обучения неясно, тем более, что эти модели будут использоваться для различных задач вниз по течению (для оптимизации для оптимизации целевого распределения). Дореми настраивает смесь данных, которая будет надежной для целевого распределения, используя распределительную оптимизацию (DRO). Дореми обучает небольшую прокси -модель, используя DRO, которая динамически увеличивает вес или домены по снижению веса на основе избыточных потерь прокси -модели по сравнению с предварительной эталонной моделью. Справочная модель дает оценку наилучшей потери, достижимой, чтобы избежать того, чтобы быть пессимистичным для высоких энтропий / жестких доменов. Затем настраиваемая смесь данных может быть использована для более эффективной обучения гораздо большей модели. В статье модель прокси -сервера 280 м может улучшить подготовку модели параметра 8B (в 30 раз больше), что позволяет ей достичь базовой производительности 8b в 2,6x быстрее. На рисунке ниже представлен обзор Doremi. Проверьте статью для получения более подробной информации.
В качестве черного ящика эта кодовая база выводит оптимизированные веса доменов с учетом текстового набора данных. Некоторые другие полезные компоненты: быстрый, возобновляемый DataLoader с взвешенной выборкой на уровне домена, простым нисходящим жгутом Eval и Trainer + Trainer + Flashattention2.

Чтобы начать, пожалуйста, клонируйте репо и установите его:
git clone [email protected]:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
Компиляция в scripts/setup_flash.sh может занять значительное количество времени (часы). Весь код должен быть запущен из самого внешнего каталога doremi . Прежде чем начать, запишите пути в ваши каталоги кэша, каталоги данных и т. Д. В файле constants.sh во внешнем каталоге этого репо. Вы также можете разместить здесь любые команды активации Conda или VirtualENV. Вот пример содержимого файла constants.sh (предоставлен в виде файла с названием sample_constants.sh ):
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # will be created by scripts/run_preprocess_pile.sh
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases key for logging
PARTITION=partition # for slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # if you installed doremi in venv
Вот как запустить сценарий образца для предварительной обработки данных на куче, которая разделяет данные свай на домены и токенизирует его:
bash scripts/run_preprocess_pile.sh
Вот пример сценария для запуска базовой линии 120 м, прокси и основных моделей (все 3 шага в трубопроводе Doremi), протестированные на одном узле с 8 A100 графическими процессорами. Это небольшая версия экспериментов с кучами в бумаге. Сценарий автоматически запускается с недоумением и несколькими выстрелами:
bash scripts/run_pile.sh
Эти сценарии запускаются за шаги 200 тысяч, после бумаги. Doremi Run выводит веса доменов в каталоге configs с именем файла <RUN_NAME>.json .
Чтобы запустить Doremi в вашем собственном наборе данных, предоставьте предварительно обработанные (токенизированные) данные в следующем формате:
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
где каждый внутренний каталог (например, domain_name_1 ) может быть загружен с помощью метода haggingface load_from_disk . Если ваши данные находятся в другом формате, вы можете добавить функцию загрузки пользовательских данных в doremi/dataloader.py . Вам также нужно будет написать файл конфигурации и сохранить его в configs/ и записать Scripts, аналогичные scripts/runs/run_pile_baseline120M.sh и scripts/runs/run_pile_doremi120M.sh , которые относятся к файлу конфигурации. Файл конфигурации определяет отображение от доменного имени с весом миклера. Имена не обязательно должны быть в порядке (Дореми всегда будет сортировать доменные имена сначала, чтобы определить фиксированный порядок), и веса не должны быть нормализованы.
--reweight_eps ) : настройка по умолчанию, используемому в статье, составляет 1, хотя это можно настроить для различных наборов данных. Как правило, мы ожидаем, что вес домена во время тренировки будут несколько шумными, а усредненные веса домен будут в основном гладкими.k шагов, будут вычислены градиенты k-1 с весами из несобственной области из предыдущей итерации (эта проблема не существует для k=1 ).Обратите внимание, что есть несколько различий между этим репо и статьей, которая была разработана в Google, а именно:
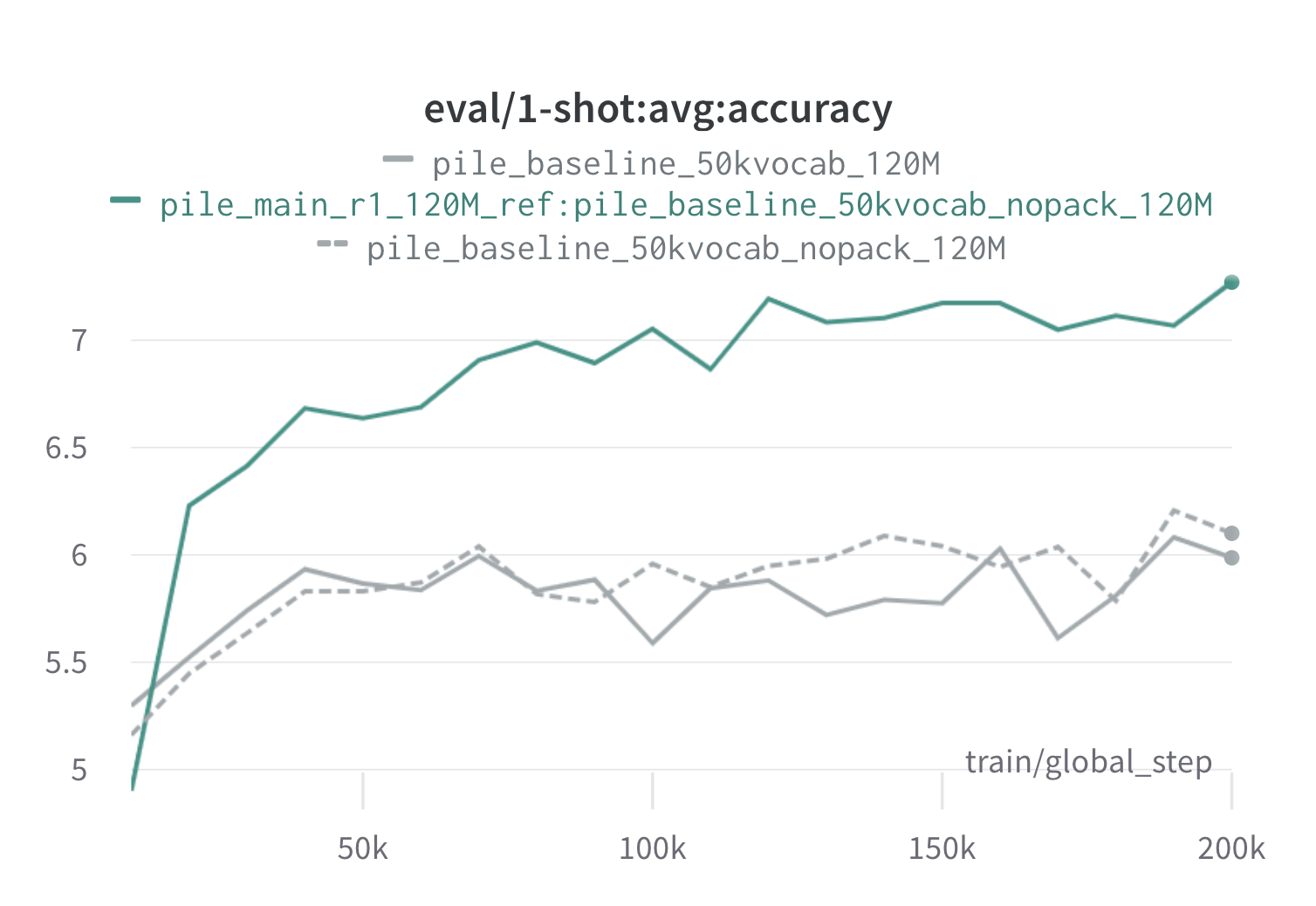
Ниже приведены результаты одного раунда дореми на куче с использованием 120 -метровых прокси и эталонных моделей (с scripts/run_pile.sh ). Мы тренируем модель 120 м, используя оптимизированные веса ( configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json ) и сравниваем ее с базовыми базами (серые). Два базовых показателя представляют два немного разных способов расчета базовых весов домены в куче (nopack считает количество примеров в каждом домене после прокладки каждого документа в длину окна контекста, тогда как упаковывает документы в пределах одного домена), которые создают схожие модели. Модель, обученная весам дореми долемы, превосходит базовую одноразовую производительность очень рано во время тренировок, в течение 70 тыс. Сталов (в 3 раза быстрее) во всех задачах. Модель Doremi превосходит среднюю базовую эксплуатацию в течение 20 тысяч шагов, имеет улучшенную или сопоставимую недоумение на доменах 15/22 и улучшает как равномерно усредненную, так и в худшем случае недоумение между доменами.
Если это было полезно для вас, пожалуйста, процитируйте газету:
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}


