doremi
1.0.0
การใช้งาน Pytorch ของ Doremi อัลกอริทึมสำหรับการเพิ่มประสิทธิภาพการผสมข้อมูลสำหรับชุดข้อมูลการสร้างแบบจำลองภาษา โมเดลภาษาขนาดใหญ่ที่ทันสมัยได้รับการฝึกฝนในหลาย ๆ โดเมน (เว็บ, หนังสือ, arxiv ฯลฯ ) แต่แต่ละโดเมนในการฝึกอบรมนั้นไม่ชัดเจนโดยเฉพาะอย่างยิ่งเนื่องจากรุ่นเหล่านี้จะถูกนำมาใช้สำหรับงานดาวน์สตรีมที่หลากหลาย Doremi ปรับแต่งส่วนผสมของข้อมูลให้แข็งแกร่งในการกระจายเป้าหมายโดยใช้การเพิ่มประสิทธิภาพที่แข็งแกร่งแบบกระจาย (DRO) Doremi ฝึกฝนโมเดลพร็อกซีขนาดเล็กโดยใช้ DRO ซึ่งมีน้ำหนักเพิ่มขึ้นหรือโดเมนที่มีน้ำหนักลดลงตามการสูญเสียส่วนเกินของโมเดลพร็อกซีเมื่อเทียบกับรูปแบบการอ้างอิงที่ผ่านการฝึกฝน รูปแบบการอ้างอิงให้การประเมินการสูญเสียที่ดีที่สุดที่ทำได้เพื่อหลีกเลี่ยงการมองโลกในแง่ร้ายสำหรับโดเมนเอนโทรปี / ฮาร์ดสูง ส่วนผสมของข้อมูลที่ปรับแล้วสามารถใช้ในการฝึกอบรมรุ่นที่ใหญ่กว่าได้อย่างมีประสิทธิภาพมากขึ้น ในกระดาษโมเดลพร็อกซี 280m สามารถปรับปรุงการฝึกอบรมของโมเดลพารามิเตอร์ 8B (ใหญ่กว่า 30 เท่า) ทำให้สามารถบรรลุประสิทธิภาพพื้นฐาน 8B 2.6X ได้เร็วขึ้น กราฟิกด้านล่างให้ภาพรวมของ Doremi ตรวจสอบรายละเอียดเพิ่มเติมเกี่ยวกับกระดาษ
ในฐานะที่เป็นกล่องสีดำ Codebase นี้เอาต์พุตน้ำหนักโดเมนที่ดีที่สุดให้ได้รับชุดข้อมูลข้อความ ส่วนประกอบที่มีประโยชน์อื่น ๆ : Dataloader ที่รวดเร็วและกลับมาใช้งานได้พร้อมการสุ่มตัวอย่างแบบถ่วงน้ำหนักระดับโดเมน, สายรัดการประเมินแบบดาวน์สตรีมแบบง่ายและ HuggingFace Trainer + Flashattention2 การรวม

ในการเริ่มต้นโปรดโคลน repo และติดตั้ง:
git clone [email protected]:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
การรวบรวมใน scripts/setup_flash.sh อาจใช้เวลาอย่างมาก (ชั่วโมง) รหัสทั้งหมดควรเรียกใช้จากไดเรกทอรี doremi นอกสุด ก่อนที่คุณจะเริ่มเขียนเส้นทางไปยังไดเรกทอรีแคชไดเรกทอรีข้อมูล ฯลฯ ในไฟล์ constants.sh ในไดเรกทอรีด้านนอกของ repo นี้ นอกจากนี้คุณยังสามารถวางคำสั่งการเปิดใช้งาน conda หรือ virtualenv ได้ที่นี่ นี่คือตัวอย่างของเนื้อหาของไฟล์ constants.sh (ให้เป็นไฟล์ที่เรียกว่า sample_constants.sh ):
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # will be created by scripts/run_preprocess_pile.sh
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases key for logging
PARTITION=partition # for slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # if you installed doremi in venv
นี่คือวิธีเรียกใช้สคริปต์ตัวอย่างสำหรับการประมวลผลข้อมูลล่วงหน้าบนเสาเข็มซึ่งแยกข้อมูลกองออกเป็นโดเมนและทำให้เป็นไปได้:
bash scripts/run_preprocess_pile.sh
นี่คือสคริปต์ตัวอย่างที่จะเรียกใช้พื้นฐาน 120m, พร็อกซีและโมเดลหลัก (ทั้งหมด 3 ขั้นตอนในท่อ Doremi) ทดสอบบนโหนดหนึ่งที่มี 8 A100 GPU นี่คือการทดลองเสาเข็มรุ่นเล็ก ๆ ในกระดาษ สคริปต์จะเรียกใช้ความงุนงงโดยอัตโนมัติและการประเมินผลไม่กี่ครั้ง:
bash scripts/run_pile.sh
สคริปต์เหล่านี้ทำงานสำหรับขั้นตอน 200k ตามกระดาษ Doremi รันเอาต์พุตของโดเมนน้ำหนักในไดเรกทอรี configs ด้วยชื่อไฟล์ <RUN_NAME>.json
ในการเรียกใช้ Doremi ในชุดข้อมูลของคุณเองให้ให้ข้อมูลที่ประมวลผลล่วงหน้า (โทเค็น) ในรูปแบบต่อไปนี้:
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
โดยที่ไดเรกทอรีภายในแต่ละตัว (เช่น domain_name_1 ) สามารถโหลดได้ผ่านวิธี load_from_disk ของ HuggingFace หากข้อมูลของคุณอยู่ในรูปแบบที่แตกต่างกันคุณสามารถเพิ่มฟังก์ชั่นการโหลดข้อมูลที่กำหนดเองใน doremi/dataloader.py คุณจะต้องเขียนไฟล์กำหนดค่าและบันทึกลงใน configs/ และเขียนสคริปต์เรียกใช้คล้ายกับ scripts/runs/run_pile_baseline120M.sh และ scripts/runs/run_pile_doremi120M.sh ซึ่งอ้างถึงไฟล์กำหนดค่า ไฟล์กำหนดค่าระบุการแมปจากชื่อโดเมนเป็นน้ำหนักผสม ชื่อไม่จำเป็นต้องอยู่ในลำดับ (Doremi จะเรียงลำดับชื่อโดเมนก่อนเสมอเพื่อกำหนดการสั่งซื้อคงที่) และน้ำหนักไม่จำเป็นต้องทำให้เป็นมาตรฐาน
--reweight_eps ) : การตั้งค่าเริ่มต้นที่ใช้ในกระดาษคือ 1 แม้ว่าจะสามารถปรับแต่งสำหรับชุดข้อมูลที่แตกต่างกัน โดยทั่วไปเราคาดว่าน้ำหนักของโดเมนในระหว่างการฝึกอบรมจะค่อนข้างมีเสียงดังและน้ำหนักของโดเมนเฉลี่ยจะราบรื่นเป็นส่วนใหญ่k จะมีการไล่ระดับสี k-1 ที่คำนวณจากน้ำหนักโดเมนเก่า ๆ จากการวนซ้ำก่อนหน้านี้ (ปัญหานี้ไม่มีอยู่สำหรับ k=1 )โปรดทราบว่ามีความแตกต่างเล็กน้อยระหว่าง repo นี้และกระดาษซึ่งพัฒนาขึ้นที่ Google คือ:
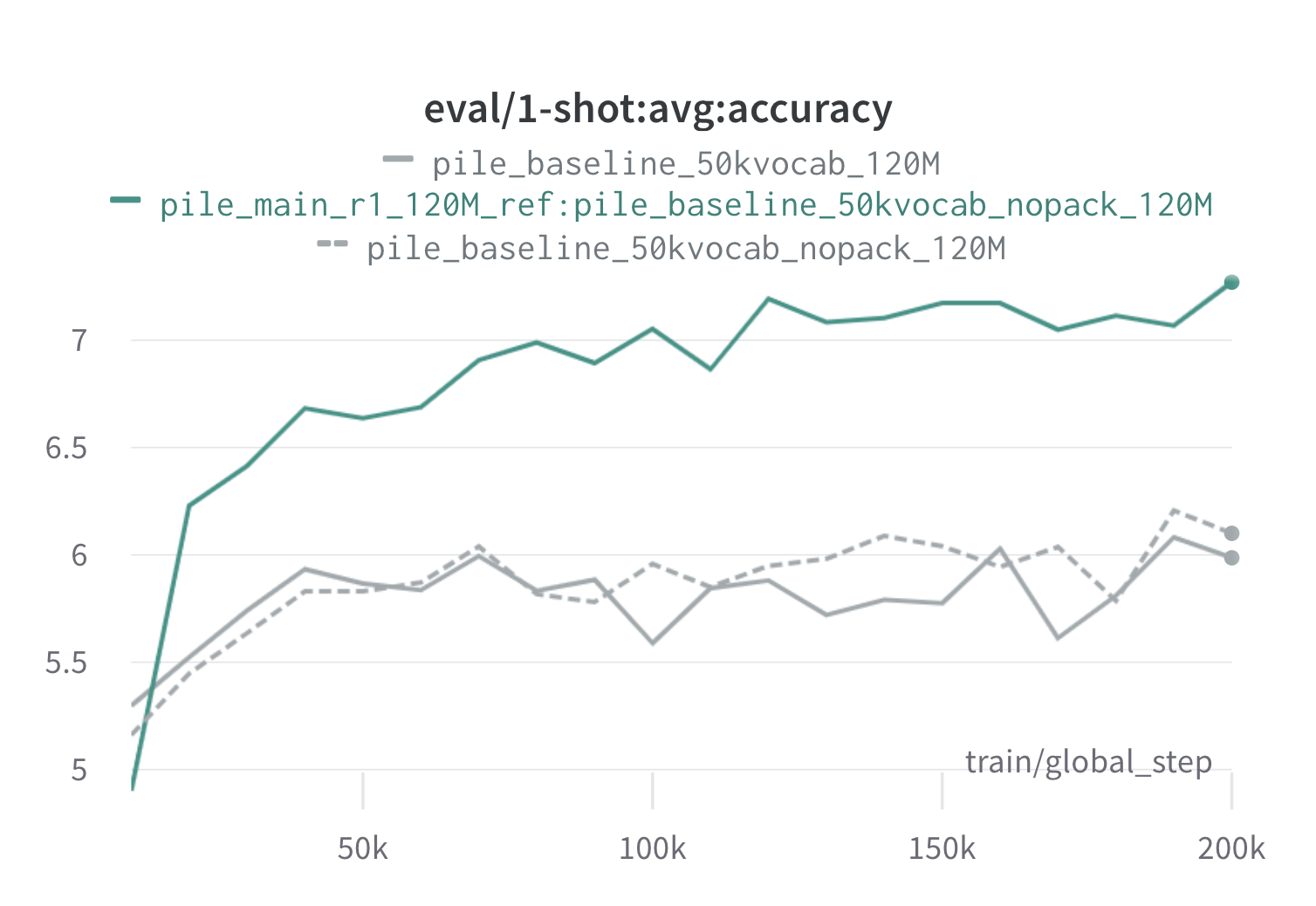
ด้านล่างนี้เป็นผลมาจาก Doremi หนึ่งรอบบนกองโดยใช้พร็อกซี 120m และโมเดลอ้างอิง (พร้อม scripts/run_pile.sh ) เราฝึกอบรมรุ่น 120m โดยใช้น้ำหนักที่ดีที่สุด ( configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json ) และเปรียบเทียบกับ baselines (สีเทา) baselines ทั้งสองเป็นตัวแทนสองวิธีที่แตกต่างกันเล็กน้อยในการคำนวณน้ำหนักโดเมนพื้นฐานในเสาเข็ม (Nopack นับจำนวนตัวอย่างในแต่ละโดเมนหลังจากการเติมเอกสารแต่ละฉบับกับความยาวหน้าต่างบริบท โมเดลที่ได้รับการฝึกฝนด้วยน้ำหนักโดเมน Doremi นั้นมีประสิทธิภาพสูงกว่าประสิทธิภาพการยิงหนึ่งครั้งในช่วงต้นของการฝึกซ้อมภายใน 70k ขั้นตอน (เร็วกว่า 3 เท่า) ในทุกงาน โมเดล Doremi มีประสิทธิภาพสูงกว่าค่าเฉลี่ยหนึ่งขั้นตอนภายใน 20K ขั้นตอนได้ปรับปรุงหรือเปรียบเทียบความงุนงงในโดเมน 15/22 และปรับปรุงทั้งความผันแปรเฉลี่ยและกรณีที่เลวร้ายที่สุดในโดเมน
หากสิ่งนี้มีประโยชน์สำหรับคุณโปรดอ้างอิงกระดาษ:
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}


