doremi
1.0.0
Implementasi PyTorch dari Doremi, sebuah algoritma untuk mengoptimalkan campuran data untuk set data pemodelan bahasa. Model bahasa besar modern dilatih di banyak domain (web, buku, arxiv, dll.), Tetapi berapa banyak dari setiap domain untuk dilatih tidak jelas, terutama karena model ini akan digunakan untuk berbagai tugas hilir (tidak ada distribusi target khusus untuk dioptimalkan). Doremi menyetel campuran data agar kuat ke distribusi target menggunakan optimasi yang kuat secara distribusi (DRO). Doremi melatih model proxy kecil menggunakan DRO, yang secara dinamis meningkatkan berat badan atau domain downweight berdasarkan kelebihan model proxy dibandingkan dengan model referensi pretrained. Model referensi memberikan perkiraan kerugian terbaik yang dapat dicapai untuk menghindari pesimis untuk entropi tinggi / domain keras. Campuran data yang disetel kemudian dapat digunakan untuk melatih model yang jauh lebih besar secara lebih efisien. Dalam makalah ini, model proxy 280m dapat meningkatkan pelatihan model parameter 8b (30x lebih besar), memungkinkannya untuk mencapai kinerja 8B baseline 2.6x lebih cepat. Grafik di bawah ini memberikan gambaran umum Doremi. Lihat kertas untuk lebih jelasnya.
Sebagai kotak hitam, basis kode ini menghasilkan bobot domain yang dioptimalkan memberikan dataset teks. Beberapa komponen bermanfaat lainnya: Dataloader yang cepat dan dapat dilanjutkan dengan pengambilan sampel tertimbang level domain, harta evaluasi hilir sederhana, dan pelatih huggingface + flashattention2 integrasi.

Untuk memulai, silakan klon repo dan instal:
git clone [email protected]:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
Kompilasi dalam scripts/setup_flash.sh dapat membutuhkan waktu yang signifikan (jam). Semua kode harus dijalankan dari direktori doremi terluar. Sebelum Anda mulai, tulis jalur ke direktori cache Anda, direktori data, dll dalam file constants.sh di direktori luar repo ini. Anda juga dapat menempatkan perintah aktivasi Conda atau VirtualEnv apa pun di sini. Berikut adalah contoh konten file constants.sh (disediakan sebagai file yang disebut sample_constants.sh ):
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # will be created by scripts/run_preprocess_pile.sh
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases key for logging
PARTITION=partition # for slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # if you installed doremi in venv
Berikut adalah cara menjalankan skrip sampel untuk preprocessing data pada tiang, yang memisahkan data tiang menjadi domain dan tokenize:
bash scripts/run_preprocess_pile.sh
Berikut adalah skrip sampel untuk menjalankan 120m baseline, proxy, dan model utama (semua 3 langkah dalam pipa Doremi), diuji pada satu node dengan 8 A100 GPU. Ini adalah versi kecil dari tiang pancang di koran. Script akan secara otomatis menjalankan evaluasi kebingungan dan beberapa shot:
bash scripts/run_pile.sh
Script ini berjalan untuk langkah 200 ribu, mengikuti kertas. Doremi menjalankan output domain bobot di direktori configs dengan nama file <RUN_NAME>.json .
Untuk menjalankan Doremi pada dataset Anda sendiri, berikan data preproses (tokenized) dalam format berikut:
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
di mana setiap direktori dalam (misalnya, domain_name_1 ) dapat dimuat melalui metode HuggingFace load_from_disk . Jika data Anda dalam format yang berbeda, Anda dapat menambahkan fungsi pemuatan data khusus di doremi/dataloader.py . Anda juga perlu menulis file konfigurasi dan menyimpannya ke configs/ dan menulis skrip run yang mirip dengan scripts/runs/run_pile_baseline120M.sh dan scripts/runs/run_pile_doremi120M.sh yang merujuk ke file konfigurasi. File config menentukan pemetaan dari nama domain ke berat campuran. Nama -nama tidak harus beres (Doremi akan selalu mengurutkan nama domain terlebih dahulu untuk menentukan pemesanan tetap) dan bobot tidak harus dinormalisasi.
--reweight_eps ) : Pengaturan default yang digunakan dalam kertas adalah 1, meskipun ini dapat disetel untuk set data yang berbeda. Secara umum, kami berharap bobot domain selama pelatihan agak bising dan bobot domain rata -rata sebagian besar halus.k , akan ada gradien k-1 yang dihitung dengan bobot domain basi dari iterasi sebelumnya (masalah ini tidak ada untuk k=1 ).Perhatikan bahwa ada beberapa perbedaan antara repo ini dan kertas, yang dikembangkan di Google, yaitu:
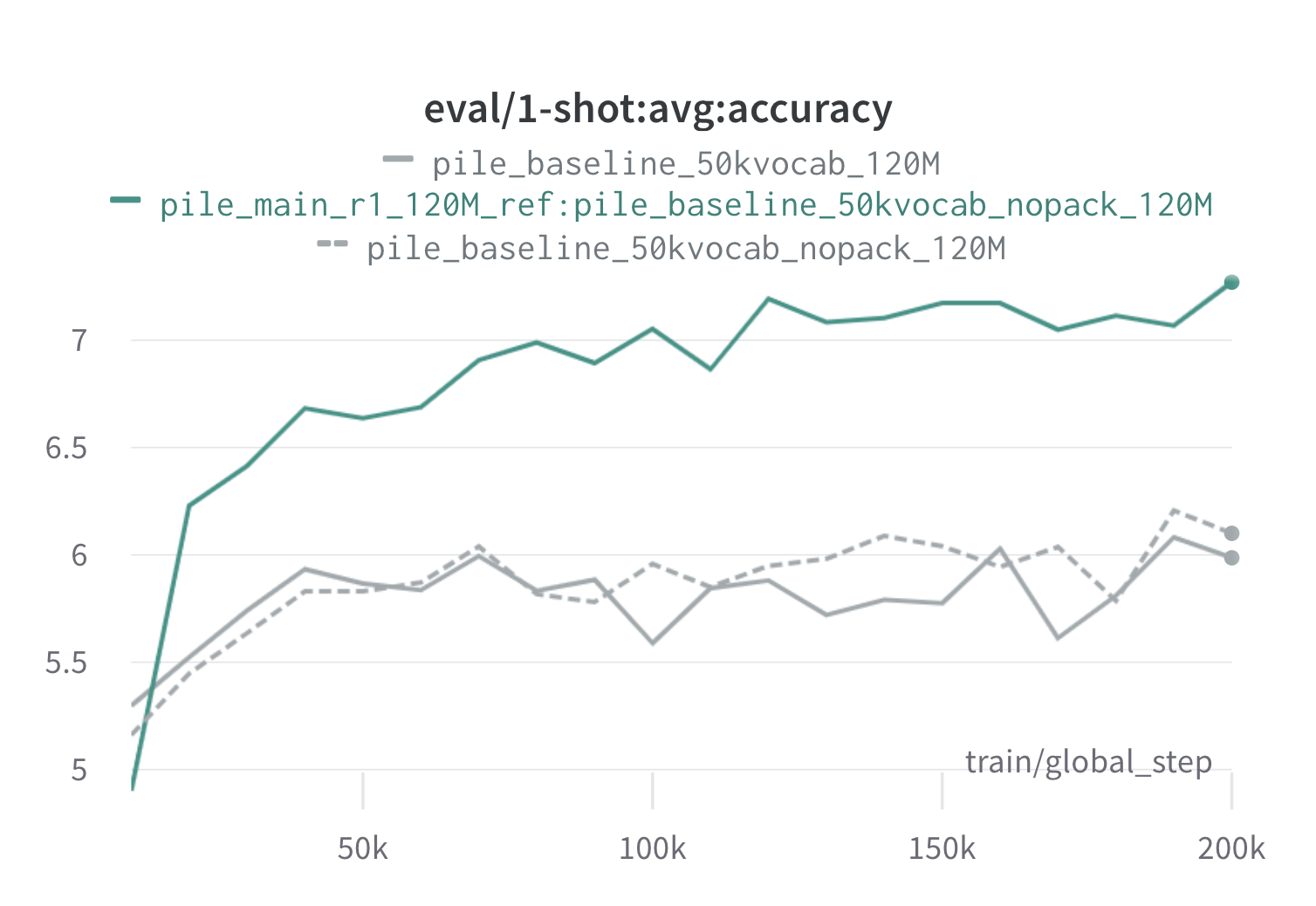
Di bawah ini adalah hasil dari satu putaran Doremi di tumpukan menggunakan 120m proxy dan model referensi (dengan scripts/run_pile.sh ). Kami melatih model 120m menggunakan bobot yang dioptimalkan ( configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json ) dan membandingkannya dengan garis dasar (abu -abu). Dua garis dasar mewakili dua cara yang sedikit berbeda untuk menghitung bobot domain dasar di tumpukan (Nopack menghitung jumlah contoh di setiap domain setelah memadukan setiap dokumen ke panjang jendela konteks, sedangkan paket menggabungkan dokumen dalam satu domain pertama), yang menghasilkan model kinerja yang serupa. Model yang dilatih dengan bobot domain Doremi melampaui kinerja satu-shot awal yang sangat awal selama pelatihan, dalam 70 ribu langkah (3x lebih cepat) di semua tugas. Model Doremi melampaui kinerja satu-shot baseline rata-rata dalam langkah 20k, telah meningkatkan atau kebingungan yang sebanding pada domain 15/22, dan meningkatkan rata-rata seragam dan kebingungan terburuk di seluruh domain.
Jika ini berguna bagi Anda, silakan kutip kertas:
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}


