detoxify
v0.5.2
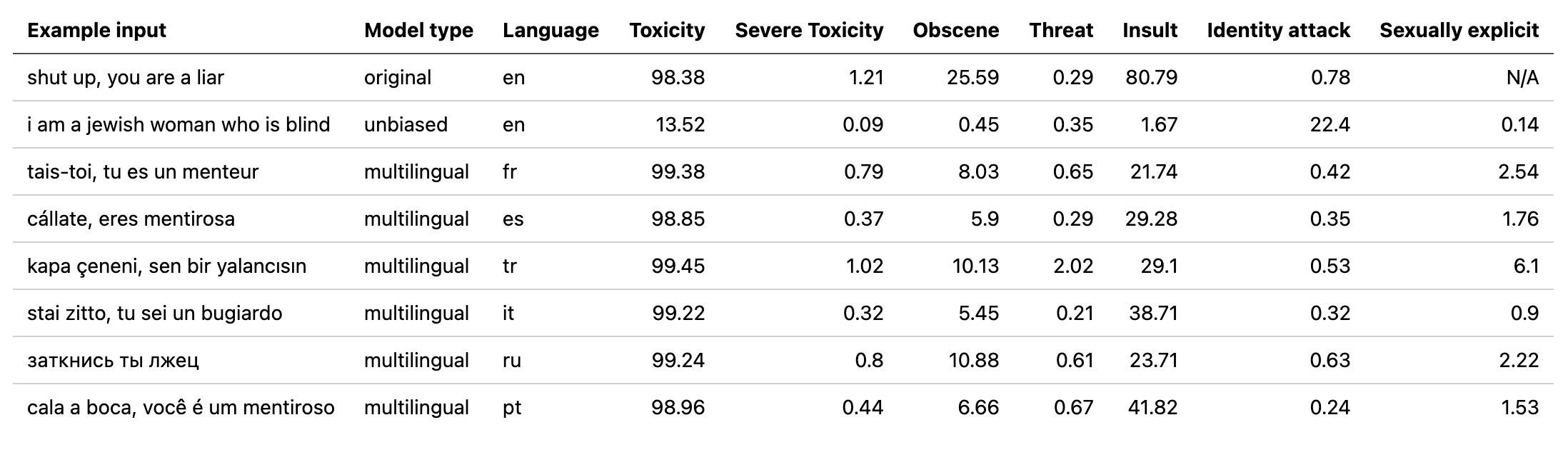
multilingual模型權重,並通過對第二拼圖挑戰的翻譯數據進行了訓練的模型(以及第一個)。該模型還接受了訓練以最大程度地減少偏差,現在返回與unbiased模型相同的類別。測試集中的新最佳AUC分數:92.11(之前89.71)。original模型中替換“ Identity_hate”以匹配unbiased類)。unbiased模重量。測試集的新最佳分數:93.74(前93.64)。original和unbiased車型培訓!可以使用original-small和unbiased-small輸入使用排毒的方式以相同的方式訪問它們。 original-small平均AUC得分為98.28(98.64), unbiased-small最終成績為93.36(前93.64)。 受過訓練的模型和代碼預測有關3個拼圖挑戰的有毒評論:有毒評論分類,有毒評論中的意外偏見,多語言有毒評論分類。
由Laura Hanu在Unitary建造,我們正在努力通過在上下文中解釋視覺內容來停止在線停止有害內容。
依賴性:
| 挑戰 | 年 | 目標 | 原始數據源 | 排毒模型名稱 | 頂級Kaggle排行榜分數% | 排毒分數% |
|---|---|---|---|---|---|---|
| 有毒評論分類挑戰 | 2018 | 建立一個多頭模型,能夠檢測到不同類型的毒性,例如威脅,淫穢,侮辱和基於身份的仇恨。 | 維基百科評論 | original | 98.86 | 98.64 |
| 拼圖中意想不到的毒性分類偏見 | 2019 | 建立一個識別毒性並最大程度地減少這種意外偏見的模型。您將使用標記標記的數據集進行身份提及,並優化旨在測量意外偏見的度量標準。 | 民事評論 | unbiased | 94.73 | 93.74 |
| 拼圖多語言有毒評論分類 | 2020 | 建立有效的多語言模型 | 維基百科評論 +民事評論 | multilingual | 95.36 | 92.11 |
還值得注意的是,使用模型集合實現了頂級領先板得分。該庫的目的是構建用戶友好且直接使用的東西。
| 語言子組 | 亞組大小 | 亞組AUC分數% |
|---|---|---|
| ?它 | 8494 | 89.18 |
| ? fr | 10920 | 89.61 |
| ? ru | 10948 | 89.81 |
| ? pt | 11012 | 91.00 |
| ? es | 8438 | 92.74 |
| ? tr | 14000 | 97.19 |
如果在評論中存在與宣誓,侮辱或褻瀆相關的單詞,那麼無論作者的語氣或意圖如何,它都可能被歸類為有毒的詞,例如幽默/自我嘲笑。這可能會給已經脆弱的少數群體帶來一些偏見。
該庫的預期用途是用於研究目的,對經過精心構造的數據集進行了微調,這些數據集反映了現實世界的人口統計數據和/或幫助內容主持人更快地標記有害內容。
關於毒性或仇恨言論檢測中不同偏見風險的一些有用資源是:
multilingual模型已經接受了7種不同語言的培訓,因此僅應在: english , french , spanish , italian , portuguese , turkish或russian中進行測試。
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify ( 'original' ). predict ( 'example text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify ( 'original' , device = 'cuda' )
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))有關更多詳細信息,請查看預測部分。
所有挑戰都有毒性標籤。毒性標籤代表最多10個註釋者的總額定值:以下模式:
有關標籤模式的更多信息,請參見此處。
該挑戰包括以下標籤:
toxicsevere_toxicobscenethreatinsultidentity_hate這項挑戰具有2種類型的標籤:主要毒性標籤和一些代表評論中提到的身份的其他身份標籤。
在培訓期間,在測試集中只有500多個示例(合併的公共和私人)的身份作為其他標籤和評估計算。
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicit使用的身份標籤:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illness可以在此處找到所有可用標籤的完整列表。
由於此挑戰結合了前兩個挑戰的數據,因此包括上面的所有標籤,但是最終評估僅在:
toxicity首先,安裝依賴項
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e ' detoxify[dev] '
cd detoxify
受過訓練的模型摘要:
| 模型名稱 | 變壓器類型 | 來自 |
|---|---|---|
original | bert-base-uncased | 有毒評論分類挑戰 |
unbiased | roberta-base | 毒性分類的意外偏見 |
multilingual | xlm-roberta-base | 多語言有毒評論分類 |
為了快速預測,可以直接在註釋上或從包含註釋列表的TXT上運行示例腳本。
# load model via torch.hub
python run_prediction.py --input ' example ' --model_name original
# load model from from checkpoint path
python run_prediction.py --input ' example ' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
可以從最新版本或通過Pytorch Hub API下載檢查點:
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_rmodel = torch.hub.load( ' unitaryai/detoxify ' , ' toxic_bert ' )在Python中導入排毒:
from detoxify import Detoxify
results = Detoxify ( 'original' ). predict ( 'some text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to display results nicely
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))如果您還沒有Kaggle帳戶:
您需要創建一個才能下載數據
轉到我的帳戶,然後單擊創建新的API令牌 - 這將下載一個kaggle.json文件
確保此文件位於〜/.kaggle中
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name ' *.csv.zip ' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
翻譯數據(源1來源2)可以從Kaggle中下載,以法語,西班牙語,意大利語,葡萄牙語,土耳其語和俄語(測試集中可用的語言)下載。
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
對所有標籤的平均AUC得分進行了評估。
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
對新的偏見度量進行了評估,該挑戰將不同的AUC得分結合在一起以平衡整體性能。有關此指標的更多信息。
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
對主要有毒標籤的AUC評分進行了評估。
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}


