detoxify
v0.5.2
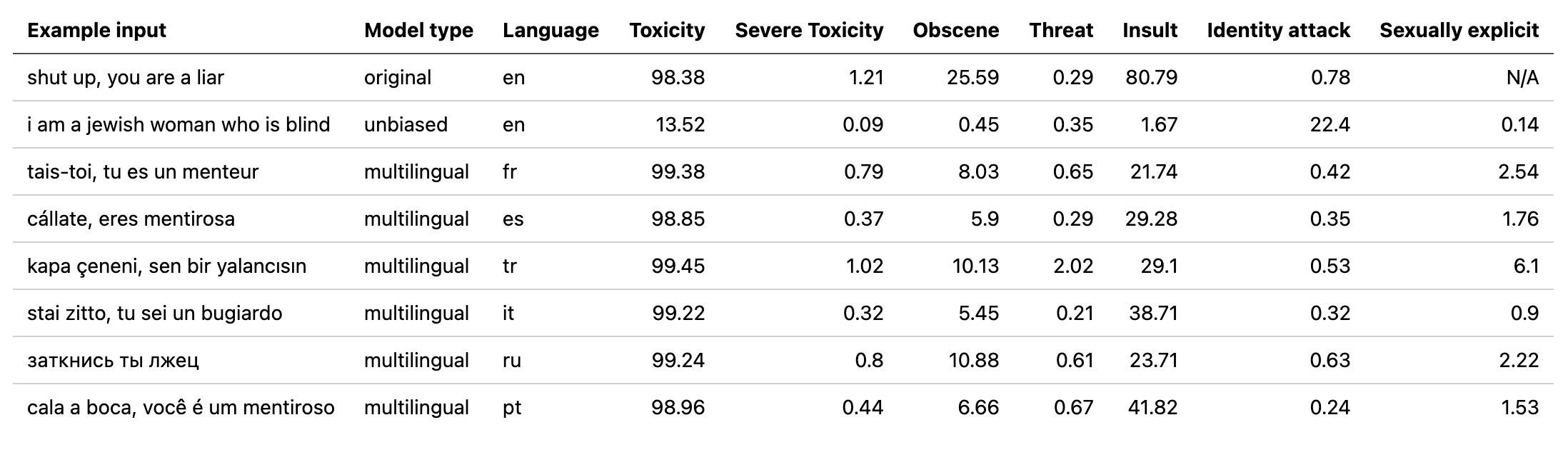
multilingual ที่ใช้โดยการล้างพิษด้วยโมเดลที่ผ่านการฝึกอบรมเกี่ยวกับข้อมูลที่แปลจากการท้าทาย Jigsaw ที่ 2 (เช่นเดียวกับที่ 1) รุ่นนี้ได้รับการฝึกฝนเพื่อลดอคติและตอนนี้ส่งคืนหมวดหมู่เดียวกันกับรุ่น unbiased ใหม่คะแนน AUC ที่ดีที่สุดในชุดทดสอบ: 92.11 (89.71 ก่อนหน้า)original เพื่อให้ตรงกับคลาส unbiased )unbiased ที่ใช้โดยการล้างพิษด้วยโมเดลที่ผ่านการฝึกอบรมในชุดข้อมูลทั้งสองจาก 2 จิ๊กซอว์แรก คะแนนใหม่ที่ดีที่สุดในชุดทดสอบ: 93.74 (93.64 ก่อน)original และ unbiased ! สามารถเข้าถึงสิ่งเหล่านี้ในลักษณะเดียวกันด้วยการล้างพิษโดยใช้แบบ original-small และ unbiased-small เป็นอินพุต original-small ได้รับคะแนนเฉลี่ย AUC ที่ 98.28 (98.64 ก่อนหน้า) และ unbiased-small ได้คะแนนสุดท้าย 93.36 (93.64 ก่อน) แบบจำลองและรหัสที่ผ่านการฝึกอบรมเพื่อทำนายความคิดเห็นที่เป็นพิษใน 3 จิ๊กซอว์ความท้าทาย: การจำแนกความคิดเห็นที่เป็นพิษ, อคติที่ไม่ได้ตั้งใจในความคิดเห็นที่เป็นพิษ, การจำแนกความคิดเห็นที่เป็นพิษหลายภาษา
สร้างโดย Laura Hanu ที่ Unitary ที่เรากำลังทำงานเพื่อหยุดเนื้อหาที่เป็นอันตรายออนไลน์โดยการตีความเนื้อหาภาพในบริบท
การพึ่งพา:
| ท้าทาย | ปี | เป้าหมาย | แหล่งข้อมูลดั้งเดิม | ชื่อรุ่นล้างพิษ | คะแนนลีดเดอร์บอร์ด Kaggle อันดับต้น ๆ | คะแนนล้างพิษ % |
|---|---|---|---|---|---|---|
| ความท้าทายการจำแนกความคิดเห็นที่เป็นพิษ | 2018 | สร้างแบบจำลองหลายหัวที่สามารถตรวจจับความเป็นพิษประเภทต่าง ๆ เช่นภัยคุกคามความหยาบคายการดูถูกและความเกลียดชังตามตัวตน | ความคิดเห็นของ Wikipedia | original | 98.86 | 98.64 |
| จิ๊กซอว์อคติที่ไม่ได้ตั้งใจในการจำแนกความเป็นพิษ | 2019 | สร้างแบบจำลองที่ตระหนักถึงความเป็นพิษและลดอคติที่ไม่ได้ตั้งใจนี้ด้วยการกล่าวถึงตัวตน คุณจะใช้ชุดข้อมูลที่มีป้ายกำกับสำหรับการกล่าวถึงตัวตนและเพิ่มประสิทธิภาพตัวชี้วัดที่ออกแบบมาเพื่อวัดอคติที่ไม่ได้ตั้งใจ | ความคิดเห็นทางแพ่ง | unbiased | 94.73 | 93.74 |
| การจำแนกความคิดเห็นที่เป็นพิษหลายภาษาจิ๊กซอว์ | 2020 | สร้างแบบจำลองหลายภาษาที่มีประสิทธิภาพ | ความคิดเห็นของ Wikipedia + ความคิดเห็นทางแพ่ง | multilingual | 95.36 | 92.11 |
นอกจากนี้ยังเป็นที่น่าสังเกตว่าคะแนนระดับสูงสุดของ LeadearArboard ได้รับการทำได้โดยใช้วงดนตรีแบบจำลอง จุดประสงค์ของห้องสมุดนี้คือการสร้างสิ่งที่ใช้งานง่ายและตรงไปตรงมาในการใช้งาน
| กลุ่มย่อยภาษา | ขนาดกลุ่มย่อย | กลุ่มย่อย AUC คะแนน % |
|---|---|---|
| - มัน | 8494 | 89.18 |
| - FR | 10920 | 89.61 |
| - ร. | 10948 | 89.81 |
| - PT | 11012 | 91.00 |
| - ES | 8438 | 92.74 |
| - TR | 14000 | 97.19 |
หากคำที่เกี่ยวข้องกับการสบถคำสบประมาทหรือความหยาบคายมีอยู่ในความคิดเห็นมีแนวโน้มว่ามันจะถูกจัดว่าเป็นพิษโดยไม่คำนึงถึงน้ำเสียงหรือความตั้งใจของผู้เขียนเช่นอารมณ์ขัน/การปฏิเสธตนเอง สิ่งนี้อาจนำเสนออคติบางอย่างต่อกลุ่มชนกลุ่มน้อยที่อ่อนแออยู่แล้ว
การใช้งานที่ตั้งใจไว้ของห้องสมุดนี้มีวัตถุประสงค์เพื่อการวิจัยการปรับแต่งชุดข้อมูลที่สร้างขึ้นอย่างระมัดระวังซึ่งสะท้อนให้เห็นถึงข้อมูลประชากรในโลกแห่งความเป็นจริงและ/หรือเพื่อช่วยผู้ดูแลเนื้อหาในการตั้งค่าสถานะที่เป็นอันตรายให้เร็วขึ้น
ทรัพยากรที่มีประโยชน์บางอย่างเกี่ยวกับความเสี่ยงของอคติที่แตกต่างกันในความเป็นพิษหรือการตรวจจับคำพูดแสดงความเกลียดชังคือ:
แบบจำลอง multilingual ได้รับการฝึกฝนใน 7 ภาษาที่แตกต่างกันดังนั้นควรทดสอบเฉพาะ: english , french , spanish , italian , portuguese , turkish หรือ russian
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify ( 'original' ). predict ( 'example text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify ( 'original' , device = 'cuda' )
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))สำหรับรายละเอียดเพิ่มเติมตรวจสอบส่วนการทำนาย
ความท้าทายทั้งหมดมีฉลากความเป็นพิษ ฉลากความเป็นพิษแสดงถึงการจัดอันดับรวมของคำอธิบายประกอบสูงสุด 10 คำอธิบายตามสคีมาต่อไปนี้:
ข้อมูลเพิ่มเติมเกี่ยวกับสคีมาการติดฉลากสามารถดูได้ที่นี่
ความท้าทายนี้รวมถึงป้ายกำกับต่อไปนี้:
toxicsevere_toxicobscenethreatinsultidentity_hateความท้าทายนี้มีป้ายกำกับ 2 ประเภท: ฉลากความเป็นพิษหลักและป้ายกำกับข้อมูลเพิ่มเติมบางอย่างที่แสดงถึงตัวตนที่กล่าวถึงในความคิดเห็น
เฉพาะตัวตนที่มีตัวอย่างมากกว่า 500 ตัวอย่างในชุดทดสอบ (รวมสาธารณะและส่วนตัว) เท่านั้นที่รวมอยู่ในระหว่างการฝึกอบรมเป็นฉลากเพิ่มเติมและในการคำนวณการประเมินผล
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicitฉลากข้อมูลประจำตัวที่ใช้:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illnessรายการที่สมบูรณ์ของป้ายกำกับทั้งหมดที่มีอยู่สามารถพบได้ที่นี่
เนื่องจากความท้าทายนี้รวมข้อมูลจากความท้าทาย 2 ครั้งก่อนหน้านี้จึงมีป้ายกำกับทั้งหมดจากด้านบนอย่างไรก็ตามการประเมินขั้นสุดท้ายจะอยู่ที่:
toxicityขั้นแรกให้ติดตั้งการพึ่งพา
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e ' detoxify[dev] '
cd detoxify
สรุปโมเดลที่ผ่านการฝึกอบรม:
| ชื่อนางแบบ | ประเภทหม้อแปลง | ข้อมูลจาก |
|---|---|---|
original | bert-base-uncased | ความท้าทายการจำแนกความคิดเห็นที่เป็นพิษ |
unbiased | roberta-base | อคติที่ไม่ได้ตั้งใจในการจำแนกความเป็นพิษ |
multilingual | xlm-roberta-base | การจำแนกความคิดเห็นที่เป็นพิษหลายภาษา |
สำหรับการทำนายอย่างรวดเร็วสามารถเรียกใช้สคริปต์ตัวอย่างในความคิดเห็นโดยตรงหรือจาก txt ที่มีรายการความคิดเห็น
# load model via torch.hub
python run_prediction.py --input ' example ' --model_name original
# load model from from checkpoint path
python run_prediction.py --input ' example ' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
จุดตรวจสามารถดาวน์โหลดได้จากรุ่นล่าสุดหรือผ่าน Pytorch Hub API พร้อมชื่อต่อไปนี้:
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_rmodel = torch.hub.load( ' unitaryai/detoxify ' , ' toxic_bert ' )การนำเข้าการล้างพิษใน Python:
from detoxify import Detoxify
results = Detoxify ( 'original' ). predict ( 'some text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to display results nicely
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))หากคุณยังไม่มีบัญชี Kaggle:
คุณต้องสร้างหนึ่งเพื่อให้สามารถดาวน์โหลดข้อมูลได้
ไปที่บัญชีของฉันและคลิกที่สร้างโทเค็น API ใหม่ - นี่จะดาวน์โหลดไฟล์ kaggle.json
ตรวจสอบให้แน่ใจว่าไฟล์นี้อยู่ใน ~/.kaggle
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name ' *.csv.zip ' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
ข้อมูลที่แปล (แหล่งที่มา 1 2) สามารถดาวน์โหลดได้จาก Kaggle ในภาษาฝรั่งเศส, สเปน, อิตาลี, โปรตุเกส, ตุรกีและรัสเซีย (ภาษาที่มีอยู่ในชุดทดสอบ)
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
ความท้าทายนี้ได้รับการประเมินด้วยคะแนนเฉลี่ย AUC ของฉลากทั้งหมด
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
ความท้าทายนี้ได้รับการประเมินในตัวชี้วัดอคติใหม่ที่รวมคะแนน AUC ที่แตกต่างกันเพื่อความสมดุลของประสิทธิภาพโดยรวม ข้อมูลเพิ่มเติมเกี่ยวกับตัวชี้วัดนี้ที่นี่
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
ความท้าทายนี้ได้รับการประเมินด้วยคะแนน AUC ของฉลากพิษหลัก
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}


